How do operators specifically propose a new state for continuous parameters?

Pavel Rinkman
Hello, everyone!
Recently, I have gotten stuck with some points of BEAST work algorithm. I will try to describe my view beneath, please, could you specify my mistakes & help to fathom BEAST?
I am very thankful for your help in advance!
BEAST mcmc run consists of a chain of states, that begins from the initial state from xml-file.
New states is proposed by operator classes, namely usually one new parameter per time. The specific operator is defined randomly, & in proportion to operators weights. Looking ahead, if its proposal is not accepted, the chain counter moves a step forwards, & next step new operator will be chose randomly again.
Transition & clock rates, frequencies, invariant sites proportion, gamma shape, & all other continuous parameters, for which we choose different distributions, boundaries, & initial values as prior are proposed by ScaleOperator.
Also each parameter has a scale factor (I do not consider their tuning during analysis here). New value is proposed the next way:
- scale factor, β∈(0; 1], defines an interval [β; 1/β]
- which is multiplied by the current state value, x. So, it gets [xβ; x/β].
- the point is drawn from the interval in accordance with relative probability density over it as this parameter distribution scope.
Thus for x = 80; β = 0.5; & OneOnX distribution BEAST takes a point from the green area (between 40 & 160) in proportion to probability density, doesn’t it?
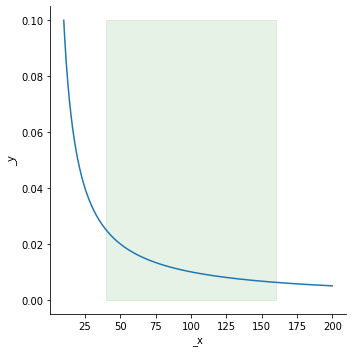
This moment is the most confused for me. Does it happen the way describing above or the distribution is defined over [β; 1/β], & then a drawn value is multiplied by x?
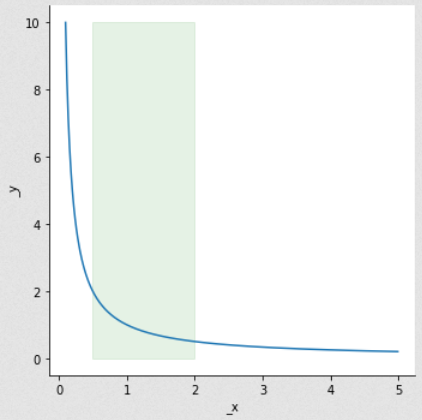
I have read a source code of ScaleOperator class (at least for the first BEAST) & noticed that it take a random value on [β; 1/β] through MathUtils.nextDouble(), that is just random.nextDouble() which is just a uniform, isn’t it? How ScaleOperator intermediate with distributions classes?
If this has differences between BEAST 1 & 2, I am very interested to have known them.
Best regards,

Remco Bouckaert
On 17/05/2022, at 5:57 AM, Pavel Rinkman <pavel....@gmail.com> wrote:help to fathom BEAST?
I am very thankful for your help in advance!
BEAST mcmc run consists of a chain of states, that begins from the initial state from xml-file.
New states is proposed by operator classes, namely usually one new parameter per time. The specific operator is defined randomly, & in proportion to operators weights. Looking ahead, if its proposal is not accepted, the chain counter moves a step forwards, & next step new operator will be chose randomly again.
Transition & clock rates, frequencies, invariant sites proportion, gamma shape, & all other continuous parameters, for which we choose different distributions, boundaries, & initial values as prior are proposed by ScaleOperator.
Also each parameter has a scale factor (I do not consider their tuning during analysis here). New value is proposed the next way:
- scale factor, β∈(0; 1], defines an interval [β; 1/β]
- which is multiplied by the current state value, x. So, it gets [xβ; x/β].
- the point is drawn from the interval in accordance with relative probability density over it as this parameter distribution scope.
Thus for x = 80; β = 0.5; & OneOnX distribution BEAST takes a point from the green area (between 40 & 160) in proportion to probability density, doesn’t it?
Pavel Rinkman

babarlelephant
Remco Bouckaert
On 3/06/2022, at 2:09 AM, Pavel Rinkman <pavel....@gmail.com> wrote:If I understand correctly, the proposal kernel (operator in the BEAST glossology) suggests a new state from uniform distribution on the slice [β; 1/β], where β is a scale factor, doesn't it?
And the sole way for the prior distribution to impact on the new state is to be a part of common prior estimation for eventual posterior (or joint) estimation of the state, isn't it?
Remco Bouckaert
On 5/06/2022, at 1:12 PM, babarlelephant <acx...@gmail.com> wrote:Hi, interesting discussion. I wonder if there are some toy demos somewhere,like 30 lines of java instanciating a few BEAST classes (with a few comments to help reading the source of the relevant methods),setting most parameters to a fixed value (population size, JC69, clockrate, tip dates..),and running a MCMC to optimize a small tree, just its topology and the dates of 5 internal nodes? Finally drawing the best tree.
Pavel Rinkman
Remco Bouckaert
--
You received this message because you are subscribed to the Google Groups "beast-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to beast-users...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/beast-users/43bc8f34-30ee-4d41-9248-17955da58989n%40googlegroups.com.