Cursor/rendering position bug handling unicode devanagari characters

Paul.W Harvey
Normally I happily live in a 7-bit ASCII world, but recently I've
become involved in writing unicode tests for a perl project, Foswiki.
I think I've discovered a cursor positioning/rendering bug in vim 7.2
with devanagari script (used for Hindi language).
Here's the offending line (also at http://pastebin.com/tWSTnAdw):
my @test = ( 'wiki', 'â日本語é', 'çमानक हिन्दीà' );
1. The problem is with the devanagari characters. There's only six of
them: but 9-ish (3 extraneous circle things) are displayed
2. Go to end of line
3. Observe that cursor doesn't go completely to end of line. Cursor goes
to closing quote ' only
4. Move cursor left, character-at-a-time (arrow or h)
5. Before you've reached the Kanji characters, one of the devanagari
characters is replaced with an extraneous ')'
I'm using gnome-terminal with these envars set:
GDM_LANG="en_AU.utf8"
LANG="en_AU.utf8"
nano, cat and less all seem to work fine.
My vim is from debian-testing, output of vim --version begins with:
VIM - Vi IMproved 7.3 (2010 Aug 15, compiled May 7 2011 15:00:54)
Included patches: 1-154
Modified by pkg-vim-m...@lists.alioth.debian.org
Compiled by bui...@brahms.debian.org
Huge version with GTK2-GNOME GUI. Features included (+) or not (-):
+arabic +autocmd +balloon_eval +browse ++builtin_terms +byte_offset
+cindent
+clientserver +clipboard +cmdline_compl +cmdline_hist +cmdline_info
+comments
+conceal +cryptv +cscope +cursorbind +cursorshape +dialog_con_gui +diff
+digraphs +dnd -ebcdic +emacs_tags +eval +ex_extra +extra_search +farsi
+file_in_path +find_in_path +float +folding -footer +fork() +gettext
-hangul_input +iconv +insert_expand +jumplist +keymap +langmap +libcall
+linebreak +lispindent +listcmds +localmap +lua +menu +mksession
+modify_fname
+mouse +mouseshape +mouse_dec +mouse_gpm -mouse_jsbterm +mouse_netterm
-mouse_sysmouse +mouse_xterm +multi_byte +multi_lang -mzscheme
+netbeans_intg
-osfiletype +path_extra +perl +persistent_undo +postscript +printer
+profile
+python -python3 +quickfix +reltime +rightleft +ruby +scrollbind +signs
+smartindent -sniff +startuptime +statusline -sun_workshop +syntax
+tag_binary
+tag_old_static -tag_any_white +tcl +terminfo +termresponse +textobjects
+title
+toolbar +user_commands +vertsplit +virtualedit +visual +visualextra
+viminfo
+vreplace +wildignore +wildmenu +windows +writebackup +X11 -xfontset +xim
+xsmp_interact +xterm_clipboard -xterm_save
Cheers
--
Paul.W...@csiro.au, Ph: (02) 6246 5105
Informatics Technologist - www.taxonomy.org.au
Centre for Australian National Biodiversity Research

ZyX
characters»,
sent 10:52:42 03 July 2011, Sunday
by Paul.W Harvey:
Confirmed, but what exactly happens depends on the terminal: I observe different
bugs in yakuake (konsole) and urxvtc. Some problems happen in gvim, but they are
not that large: only when I switch from last but one character before last «'»
to previous one I get additional thick black line to the left of last character
before «'», which disappears once I redraw or hide this text by placing another
window (X window, not gvim one) on it and then unhide it.
By the way, in console semicolon turns into colon because it is for some reason
moved some pixels down: even when displayed using `xclip -o -sel clip'.
Editing of this line in zsh happens almost normally compared to vim: in konsole
moving the cursor causes characters to change their vertical position and,
sometimes, their shape, in urxvtc there are no problems at all, but almost all
characters from the last string appear as rectangles.
Original message:

Bram Moolenaar
Paul W. Harvey wrote:
> Normally I happily live in a 7-bit ASCII world, but recently I've
> become involved in writing unicode tests for a perl project, Foswiki.
>
> I think I've discovered a cursor positioning/rendering bug in vim 7.2
> with devanagari script (used for Hindi language).
>
> Here's the offending line (also at http://pastebin.com/tWSTnAdw):
>
> my @test = ( 'wiki', 'â日本語é', 'çमानक हिन्दीà' );
>
> 1. The problem is with the devanagari characters. There's only six of
> them: but 9-ish (3 extraneous circle things) are displayed
> 2. Go to end of line
> 3. Observe that cursor doesn't go completely to end of line. Cursor goes
> to closing quote ' only
> 4. Move cursor left, character-at-a-time (arrow or h)
> 5. Before you've reached the Kanji characters, one of the devanagari
> characters is replaced with an extraneous ')'
>
> I'm using gnome-terminal with these envars set:
> GDM_LANG="en_AU.utf8"
Please try this in an xterm, in utf-8 mode. If it's still wrong there
it might be a Vim bug. If it's OK in xterm it's probably a
gnome-terminal bug.
> nano, cat and less all seem to work fine.
>
> My vim is from debian-testing, output of vim --version begins with:
>
> VIM - Vi IMproved 7.3 (2010 Aug 15, compiled May 7 2011 15:00:54)
> Included patches: 1-154
[...]
--
"After a few years of marriage a man can look right at a woman
without seeing her and a woman can see right through a man
without looking at him."
- Helen Rowland
/// Bram Moolenaar -- Br...@Moolenaar.net -- http://www.Moolenaar.net \\\
/// sponsor Vim, vote for features -- http://www.Vim.org/sponsor/ \\\
\\\ an exciting new programming language -- http://www.Zimbu.org ///
\\\ help me help AIDS victims -- http://ICCF-Holland.org ///

Benjamin R. Haskell
> Reply to message «Cursor/rendering position bug handling unicode devanagari characters»,
> sent 10:52:42 03 July 2011, Sunday
> by Paul.W Harvey:
>
>> Hi there,
>>
>> Normally I happily live in a 7-bit ASCII world, but recently I've
>> become involved in writing unicode tests for a perl project, Foswiki.
>>
>> I think I've discovered a cursor positioning/rendering bug in vim 7.2
>> with devanagari script (used for Hindi language).
>>
>> Here's the offending line (also at http://pastebin.com/tWSTnAdw):
>>
>> my @test = ( 'wiki', 'â日本語é', 'çमानक हिन्दीà' );
>>
>> 1. The problem is with the devanagari characters. There's only six of
>> them: but 9-ish (3 extraneous circle things) are displayed
>> 2. Go to end of line
>> 3. Observe that cursor doesn't go completely to end of line. Cursor
>> goes to closing quote ' only
>> 4. Move cursor left, character-at-a-time (arrow or h)
>> 5. Before you've reached the Kanji characters, one of the devanagari
>> characters is replaced with an extraneous ')'
>>
>> I'm using gnome-terminal with these envars set:
>> GDM_LANG="en_AU.utf8"
>> LANG="en_AU.utf8"
>>
>> nano, cat and less all seem to work fine.
>>
>> My vim is from debian-testing, output of vim --version begins with:
>>
>> [...trimmed...]
>>
>> Cheers
>>
>> --
>> Paul.W...@csiro.au, Ph: (02) 6246 5105
>> Informatics Technologist - www.taxonomy.org.au
>> Centre for Australian National Biodiversity Research
>
> Confirmed, but what exactly happens depends on the terminal: I observe
> different bugs in yakuake (konsole) and urxvtc. Some problems happen
> in gvim, but they are not that large: only when I switch from last but
> one character before last «'» to previous one I get additional thick
> black line to the left of last character before «'», which disappears
> once I redraw or hide this text by placing another window (X window,
> not gvim one) on it and then unhide it.
>
> By the way, in console semicolon turns into colon because it is for
> some reason moved some pixels down: even when displayed using `xclip
> -o -sel clip'.
>
> Editing of this line in zsh happens almost normally compared to vim:
> in konsole moving the cursor causes characters to change their
> vertical position and, sometimes, their shape, in urxvtc there are no
> problems at all, but almost all characters from the last string appear
> as rectangles.
I originally wrote this¹ up (on the web since email's the wrong place
for HTML and images) in response to a post «Complex Scripts in
Vim/gVim»², but figured it was appropriate here, since Devanāgarī is the
topic again. The summary is that you're probably not going to be happy
with the way vim (g- or terminal) displays Devanāgarī at this point in
time, especially if you really have to read/write it (instead of just
viewing it as a sequence of characters for Unicode testing).
Various things sidetracked me, preventing me from sending the response
originally. I didn't have a nice way to edit the annotations³ I tried
to play with (never finished all of them). I tried and failed to get
LuaTeX to find the Devanāgarī fonts (from what I've seen, it's good
about handling the diacritics).
Takeaways beyond the pessimistic ones above:
Chrome seems to render the Devanāgarī text snippet from that thread
reasonably well. The shiro-rekha (line above) is unbroken, the
diacritics are in the right places in the Devanāgarī AFAICT (but not the
double-diacritics on the Latin chars).
I'd welcome suggestions. E.g. re: ZyX's comment that yakuake looked
okay, the sample from before⁴ looked completely wrong in Konsole, but
I'll try again once Paludis updates a zillion things (haven't up'ed my
system in a long time) and I can install yakuake. Comments on the fonts
I ended up using are in my Yudit preferences⁵. I'm also on Gentoo, so
specific packages that made the new sample look fine in yakuake would be
particularly useful for me.
--
Best,
Ben
¹: http://benizi.com/vim/devanagari/
²: https://groups.google.com/d/topic/vim_dev/zPLhQ_AwFGI/discussion
³: http://code.google.com/p/jquery-image-annotate/
⁴: http://benizi.com/vim/devanagari/snippet.txt
⁵: http://benizi.com/vim/devanagari/yudit-hindi.properties.html#fonts
Paul.W Harvey
On 04/07/11 02:30, Bram Moolenaar wrote:
> Please try this in an xterm, in utf-8 mode. If it's still wrong there
> it might be a Vim bug. If it's OK in xterm it's probably a
> gnome-terminal bug.
The fault persists with xterm.
- Created the problem line of text using gedit, saved test.txt
- from gnome-terminal, xterm -r -en UTF-8 -e vim test.txt
- Observed the previously reported behaviour in vim
- from gnome-terminal, xterm -r -en UTF-8 -e nano a.txt
- Observed proper behaviour in nano
It's worth noting that the Kanji characters seem fine.
I'm ignorant of writing systems in general, especially devanagari
script, but I seems that vim is incorrectly rendering modifier/diacratic
marks as separate chars instead of combining them into the
modified/marked character.
This would explain why the cursor falls short of the last few chars
rendered when trying to go to end of line.

Paul
On Jul 4, 6:51 am, "Benjamin R. Haskell" <v...@benizi.com> wrote:
... snip
> for HTML and images) in response to a post «Complex Scripts in
> Vim/gVim»², but figured it was appropriate here, since Devanāgarī is the
> topic again. The summary is that you're probably not going to be happy
> with the way vim (g- or terminal) displays Devanāgarī at this point in
> time, especially if you really have to read/write it (instead of just
> viewing it as a sequence of characters for Unicode testing).
I wonder how nano is working, though - because even if the script
isn't rendered properly, at least its cursor-character/rendering seems
to track properly, whereas in vim I do not feel confident editing any
lines containing Devanāgarī.
Anyway, I've been using vim for 8 years now and this is the first bug
that's ever affected me, so I appreciate the wonderful work you all
do.
Cheers
Benjamin R. Haskell
> Hi Benjamin,
>
> On Jul 4, 6:51 am, "Benjamin R. Haskell" wrote:
> ... snip
>> I originally wrote this¹ up (on the web since email's the wrong place
>> for HTML and images) in response to a post «Complex Scripts in
>> Vim/gVim»², but figured it was appropriate here, since Devanāgarī is
>> the topic again. The summary is that you're probably not going to be
>> happy with the way vim (g- or terminal) displays Devanāgarī at this
>> point in time, especially if you really have to read/write it
>> (instead of just viewing it as a sequence of characters for Unicode
>> testing).
>
> So, this is a known issue. Thank you for these detailed answers.
>
> I wonder how nano is working, though - because even if the script
> isn't rendered properly, at least its cursor-character/rendering seems
> to track properly, whereas in vim I do not feel confident editing any
> lines containing Devanāgarī.
Is nano consistent for you under gnome-terminal? Did you try the sample
from the previous thread¹?
Neither it nor your pastebin sample² works for me in nano under
gnome-terminal. For your sample, I get the "three extraneous circle
things" (three combining characters that couldn't be rendered properly)
in both nano and vim: apparently Unicode code points U+093e (Devanagari
Vowel Sign AA), U+093f (Devanagari Vowel Sign I), and U+0940 (Devanagari
Vowel Sign II).
It might be useful to know what fonts you've got installed that are
covering these characters. A quick first pass:
fc-list :lang=hi | sort
--
Best,
Ben
¹: http://benizi.com/vim/devanagari/snippet.txt
²: http://pastebin.com/DMvM7Fx9
Paul.W Harvey
> Is nano consistent for you under gnome-terminal? Did you try the sample
> from the previous thread¹?
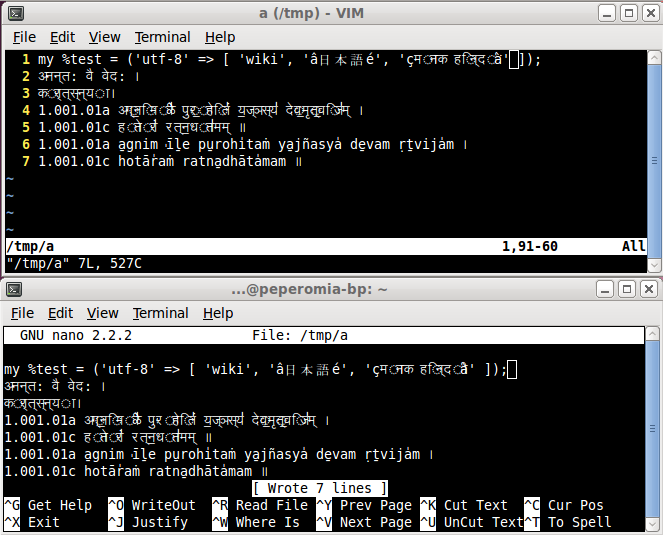
I've attached a screenshot (also at http://imagebin.org/161344) showing
that both editors actually corrupt the script in the same way visually,
as you have observed.
gedit displays fine.
The difference with nano is that unlike vim, I can reliably position my
cursor within the text and the movement, user input is rendered in an
unsurprising way.
Of course, the script is still rendered wrong in nano, I'm just talking
about the mis-match between my user input and the rendered result.
The simplest consistency test is just seeing where each editor thinks
the "end of line" is. The screenshot shows nano's cursor at the end of
the rendered line. Vim's idea of where the end of line is, falls short
of the rendered text.
It's almost as if vim's behaviour indicates its "internal" understanding
of the character grid (if that's what you call it) is correct (the
cursor seems to move over the correct number of chars), but some of
those chars are taking up more than one cell each when rendered.
~$ fc-list :lang=hi | sort
FreeSans:style=Medium,obyčejné,Mittel,µεσαία,Normal,Medio,Gemiddeld,odmiana
zwykła,Обычный,navadno,Vừa
gargi:style=Medium
Lohit Hindi:style=Regular
- Paul
{kind=link}
Bram Moolenaar
Paul W. Harvey wrote:
> On 04/07/11 02:30, Bram Moolenaar wrote:
> > Please try this in an xterm, in utf-8 mode. If it's still wrong there
> > it might be a Vim bug. If it's OK in xterm it's probably a
> > gnome-terminal bug.
>
> The fault persists with xterm.
>
> - Created the problem line of text using gedit, saved test.txt
> - from gnome-terminal, xterm -r -en UTF-8 -e vim test.txt
> - Observed the previously reported behaviour in vim
> - from gnome-terminal, xterm -r -en UTF-8 -e nano a.txt
> - Observed proper behaviour in nano
>
> It's worth noting that the Kanji characters seem fine.
>
> I'm ignorant of writing systems in general, especially devanagari
> script, but I seems that vim is incorrectly rendering modifier/diacratic
> marks as separate chars instead of combining them into the
> modified/marked character.
>
> This would explain why the cursor falls short of the last few chars
> rendered when trying to go to end of line.
I have no idea why the modifier chars aren't handled correctly, is there
something special about them?
One last thing to check is the 'ambiwidth' option. That's an annoying
Unicode feature, requiring a manual setting.
--
hundred-and-one symptoms of being an internet addict:
245. You use Real Audio to listen to a radio station from a distant
city rather than turn on your stereo system.
Paul.W Harvey
On 04/07/11 22:28, Bram Moolenaar wrote:
> I have no idea why the modifier chars aren't handled correctly, is there
> something special about them?
Okay, I've found some fascinating doc on this subject:
http://sites.google.com/site/ocropus/old-documentation/documentation/indic-scripts
हि is indeed two separate unicode chars, they are:
* 'ह' devanagari letter ha http://graphemica.com/0939
* 'ि' devanagari vowel sign i http://graphemica.com/093F
> One last thing to check is the 'ambiwidth' option. That's an annoying
> Unicode feature, requiring a manual setting.
I tried settings of double/single, but it still displayed 'ह' as two
separate characters rather than one.
Probably it's "too hard" to make vim render this sequence as a single
character (unless you guys have developers that use and care about this
script); but perhaps it might be possible to get reliable cursor
behaviour inside devanagari strings
- PH
Charles Campbell
consistently!); however, using "$" sends the cursor to the semicolon at
the end of the line. I do see that the cursor does not go to the end of
line with vim running under either gnome-terminal or xterm.
Regards,
Chip Campbell