Skip to first unread message

JEESUN NAM
May 8, 2018, 5:25:11 AM5/8/18
to unitex-...@googlegroups.com
Dear all,
In the Muse project, http://dicora.hufs.ac.kr/board/board_view.php?view_id=30&board_name=resources&page=1
our Dicora Group at Hankuk University of Foreign Studies revised the Unitex/GramLab tagging of a 9000-word Korean corpus and removed all ambiguity (Nam, 2018). For this task, we used the text-automaton editor implemented in Unitex by Maxime Petit and Marwin Damis. Such revision was a very repetitive task, and how much comfort the editor provides to users like us makes a huge difference. Here are a few suggestions for enhancing it.
1) Zoom
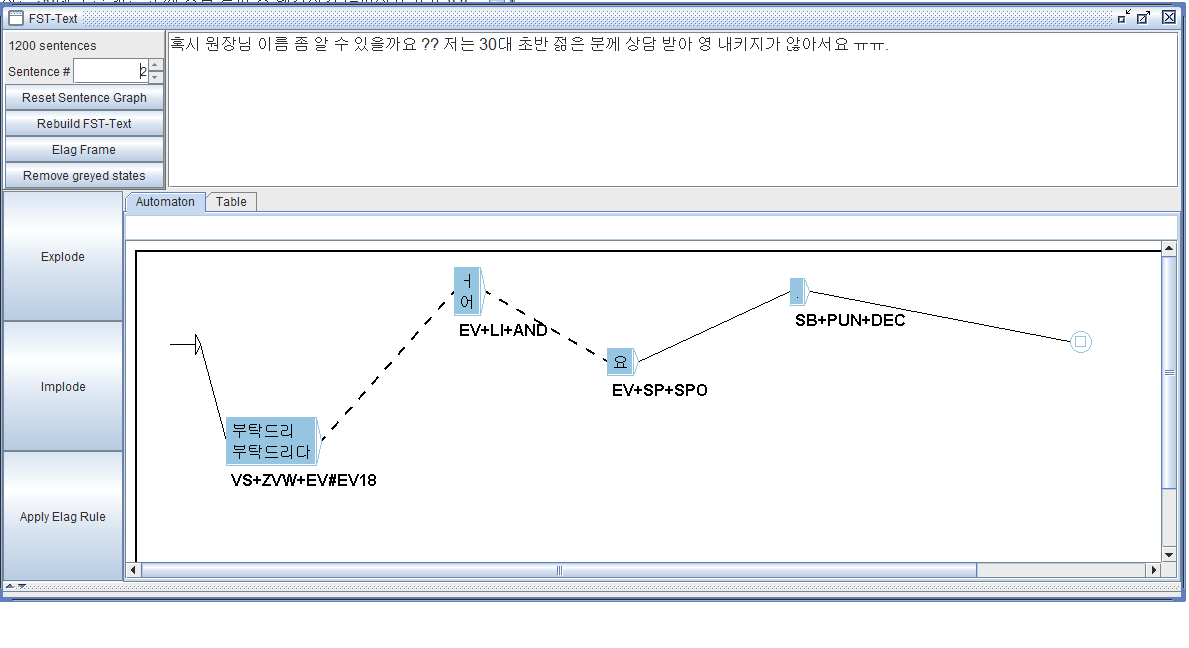
The text-automaton editor displays a sliding window of a few words of the text automaton. On a laptop screen, this window is uncomfortably small: annotators have to move the horizontal scroll bar all the time. It would be fantastic to be able to zoom in and out of the text automaton easily, maybe with the scroll wheel. (Presently, the scroll wheel scrolls up and down, but this is less useful than zooming in and out, and you can also do it with the vertical scroll bar.)
2) Increase height of text-automaton frame inside FST-Text window
In the FST-Text window, the upper vertical menu (Revert to last save, Undo, Redo, Save, Elag frame, Remove greyed states) occupies a lot of space, which reduces the height of the text-automaton frame. When there are many parallel paths in the automaton, annotators have to scroll up and down. If the upper vertical menu was displayed horizontally, between the title bar and the sentence frame, This would save space for the text-automaton frame below. (The sentence frame would be smaller in height, but it has usually much more space than necessary for the sentence, and anyway a vertical scroll bar appears when needed.)
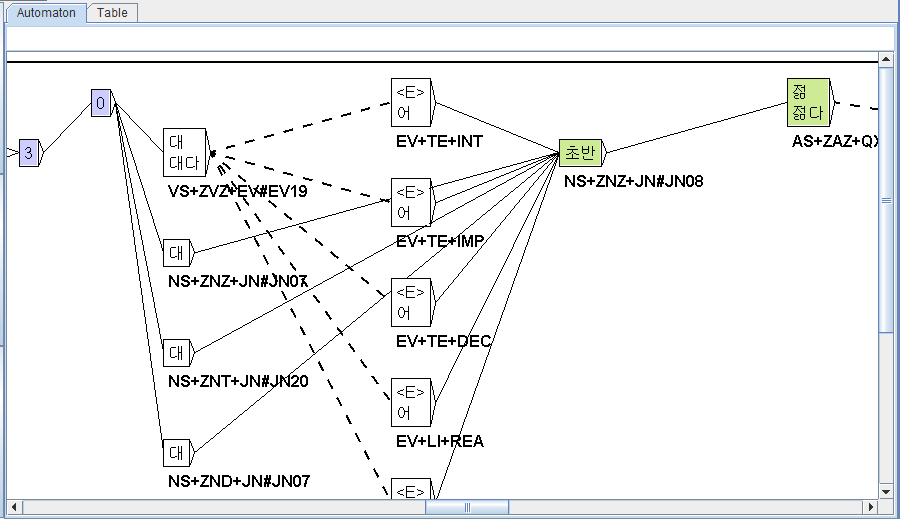
3) Visual marking of unambiguously tagged parts
We tested various forms of visual marking of unambiguously tagged parts and of untagged parts in the text automaton (issue 59 in the developers' site https://github.com/UnitexGramLab/gramlab-ide/issues/59). Thanks to Marwin Damis for implementing our best choice. For the moment, it only applies to Korean texts. We suggest extending it to all languages:
Boxes for untagged tokens: lavender blue (CCCCFF) background inside.
Boxes for unambiguously tagged items: light green (CCEB94) background inside; lines as thick as normal boxes; no bold characters inside.
Entirely unambiguously tagged sentences: cornflower blue (99C9E4) background in boxes (except for untagged tokens); box frames are cornflower blue; transitions and empty boxes are black, not yellow.
We would be pleased to know about other users' view about these suggestions.
Best,
Nam Jeesun
Reference
Nam, Jeesun, 2018, An introduction to the methodology of implementing Korean electronic dictionaries for corpus analysis, Yok-rak publishing company (in Korean).

{kind=link}
{kind=link}
Alexis Neme
Jun 23, 2018, 6:06:21 AM6/23/18
to unitex-...@googlegroups.com
Hi Jeesun,
(hi Cristian, hi Eric)
I am also interested to annotated Arabic text with the text-automaton tool in Unitex.
As I see jeesun's main critics to the tool are related to visualisation and ergonomic.
horizontally: almost 8 words/segments fit in the automaton-window, => not enough context for the annotators, only 4 words in Arabic if there is agglutinated segments
vertically: 6 ambiguities fit vertically in the automaton_window => not enough to select the right ambiguity:
Here two suggestions for the IDE_JAVA team, expressed in a SCRUM stories (new features description)
SCRUM Story for automaton windows:
As a corpus annotator, I should be able to increase the H-size and the V-size of the automaton windows;
so the annotator will have more confort in the automaton windows.
( for example: F11 will visualise only the automaton window in full screen and hide the top window-sentence)
SCRUM Story for ergonomic windows:
As a corpus annotator, I should be able to use mouse-and-keyboard_shortcut to scroll or access any functionality for annotation, so the annotator will have more confort in the handling the automaton visualisation and the related menu for annotations.
( even if the fokus is not in the sentence counter:
arrow-up/down must move to previous/next sentence;
CTRL-arrow-up/down must move to 10th previous/next sentence;
arrow-Left/Right must slide the window 4 words in the same sentence;
CTRL-arrow-Left/Right must slide the window 8 words in the same sentence; etc ;
The IDE-java developers (Maxim-Marvin) are able to propose better choices (visualisation/ergonomic) since they experiment this topic more than us (linguists and annotators).
(thanks Maxim and Marvin, for this find_replace box, it is very useful)
It is a fact that Unitex has a lot of good tools for lexicon (lately Leximir) and for grammar formalization (excellent graph tools);
But, little effort has been spent to create and develop a good annotation tool in Unitex (see Treebank from LDC ).
In order to meet the expectation of linguists and annotators, there is a lot to do in Unitex .
finally, an annotated disambiguated corpus is an essential and critical resource for statistical approaches compatible with the tagset used in Unitex annotations.
Kind regards
Alexis
Reply all
Reply to author
Forward
0 new messages