Main problem of TiddlyWiki site - is bad Google indexation.

Siniy-Kit
onclick="window.open('https://tiddlywiki.com/#KaTeX%20Plugin')"">KaTeX Plugin</a> Siniy-Kit
Google can index only multipage .....

@TiddlyTweeter

TonyM
You are not talking to yourself. I belive I understand your concerns. Something similar was raised recently. I have not worked with static sites which I believe are the key to improving tiddlywiki appearence in search results.
It seems to me nessasary for implementations that demand a searchable presence on the internet.
Is this your concern?
I am confident there is a solution and in fact believe I have a good idea how to, and believe tiddlywiku has what we need.
Could you state what you need, not a solution or a possible solution just what you want to happen?
I think this will help us proceed.
Regards
Tony
@TiddlyTweeter
... static sites which I believe are the key to improving tiddlywiki appearence in search results.
TonyM
Imagin you have a fantastic tiddlywiki, all its bells and whistles, it is served or single file and you put it up on the internet. The search engins dont load your wiki just the files they can see. They missout on seeing what an interactive user sees.
A bach export of all html that an interactive user may see into to html pages stored along side your wiki online and ensure the search engins can see this content and index it.
Now if as a result of a search engin some one arrives at such a static page, any attempt to interact with that page opens the interactive tiddlywiki transparently would work.
Add a feature to generate new static pages for updates, and I belive the problem will be solved. It just a matter of putting the right files and links online for the search engins to use.
Regards
Tony
@TiddlyTweeter
1 -- HOW will Siniy-Kit get his dynamic shops known?
2 -- The route of having to go static first does NOT look optimal between one-more-click and "don't bother".
Siniy-Kit
понедельник, 7 января 2019 г., 15:06:24 UTC+3 пользователь TonyM написал:

h0p3
* https://philosopher.life/#2019.01.01%20-%20TWGGF%3A%20Google's%20Incentives
I've waited a while to respond to this. I might as well join.
Imho, Google's indexing isn't just poor for https://tiddlywiki.com/ but for all TWs. I grant SEO can be improved for TW, but I am not convinced this problem is going to be solved anytime soon (and most likely not at all).
I'm fairly cynical about the matter. Google has enormous incentives to punish us for not channeling and packaging content into mobile/cache-friendly formats, static tooling, oversimplified atoms of content, and models which maximize their profits. Given their dominance, they can force others to play by their rules, and you won't defeat them on their own turf. They aim to optimize how we build their walled-garden for them,<<ref "l">> track and model users efficiently, and control the masses through a world-class advertisement machine.<<ref "t">> They don't want you to own your identities except insofar as it benefits them. They don't want you to have dynamic control over your data because it's not price efficient for them (static is cheaper to handle) and they also want you to pay (directly or indirectly) for the privilege of using services on or built in virtue of their infrastructure instead.<<ref "a">>
TW embodies the hacker ethic: it is antithetical to Google's ends (and the means to those ends). They have no incentive to enable the decentralization of information power except insofar as it has asymmetrically disrupted their competition. I expect we will continue to be punished for trying to own our data with a tool like TW. Perhaps that will change one day; TW would need to become mainstream enough for them to find it worth specifically parsing, mapping, etc.<<ref "p">>
If SEO matters to you, you are likely relegated to using TW as a CMS or development environment but never as the complete final product. It is possible that TW still isn't the best pick there either.
I hate to say it, but I think TW is the wrong tool for the job even if that's not TW's fault.
---
<<footnotes "l" "They want to be the sole lense through which you see and use the internet (and more).">>
<<footnotes "t" "~85% of their revenue is generated through advertisement. I'm tinfoil-hat enough to believe that's only most of the equation.">>
<<footnotes "a" "Dynamic control over your data, which they are fighting against, is a necessary condition to achieving several forms of digital autonomy.">>
TonyM
TonyM
XML sitemaps
Google introduced the Sitemaps protocol so web developers can publish lists of links from across their sites. The basic premise is that some sites have a large number of dynamic pages that are only available through the use of forms and user entries. The Sitemap files contains URLs to these pages so that web crawlers can find them. Bing, Google, Yahoo and Ask now jointly support the Sitemaps protocol.
Since the major search engines use the same protocol,[2] having a Sitemap lets them have the updated page information. Sitemaps do not guarantee all links will be crawled, and being crawled does not guarantee indexing.[3] Google Webmaster Tools allow a website owner to upload a sitemap that Google will crawl, or they can accomplish the same thing with the robots.txt file.[4]
Regards
Siniy-Kit
среда, 9 января 2019 г., 3:58:51 UTC+3 пользователь TonyM написал:

Thomas Elmiger
It would be interesting to test different settings for TW URL generation and browser history manipulation. My guess is, that appending #tiddlernames to internal links and actually use/insert them in the URL could help.
Maybe other optimisations would be possible with little effort, e.g.
* integration of description meta info in the head
* text on preload page
* generation of XML sitemap with all possible deep links
Cheers,
Thomas
1 https://www.google.com/search?q=does+Google+index+Javascript&oq=does+Google+index+Javascript
@TiddlyTweeter
How can we best assist Google robots index TW correctly?

Archizona V
Thomas Elmiger
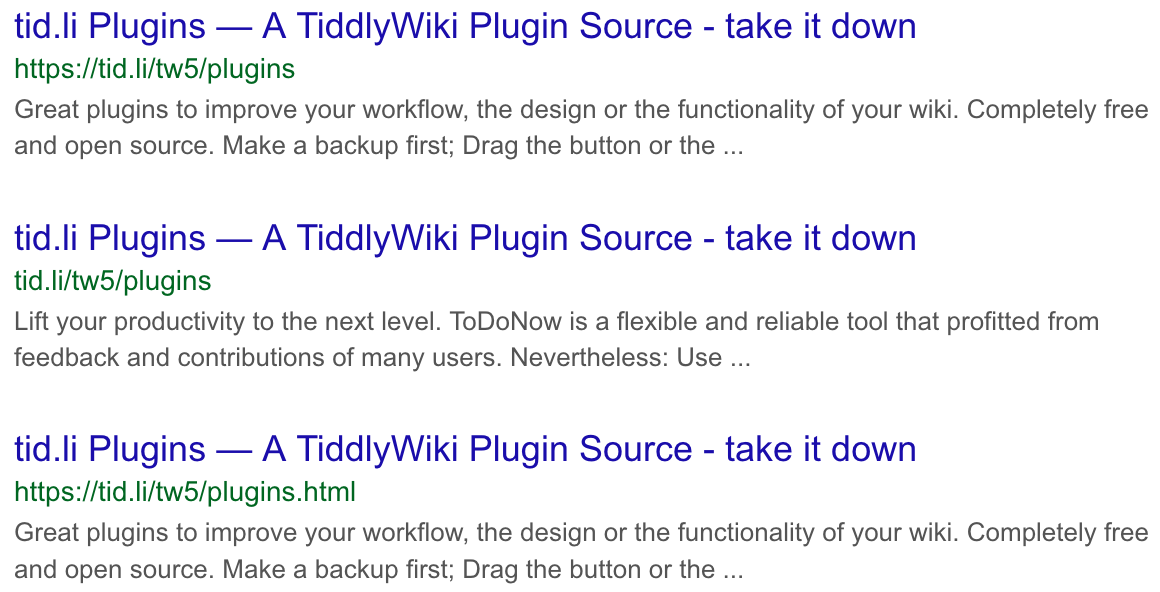
https://www.google.com/search?q=site%3Atid.li%2Ftw5%2Fplugins
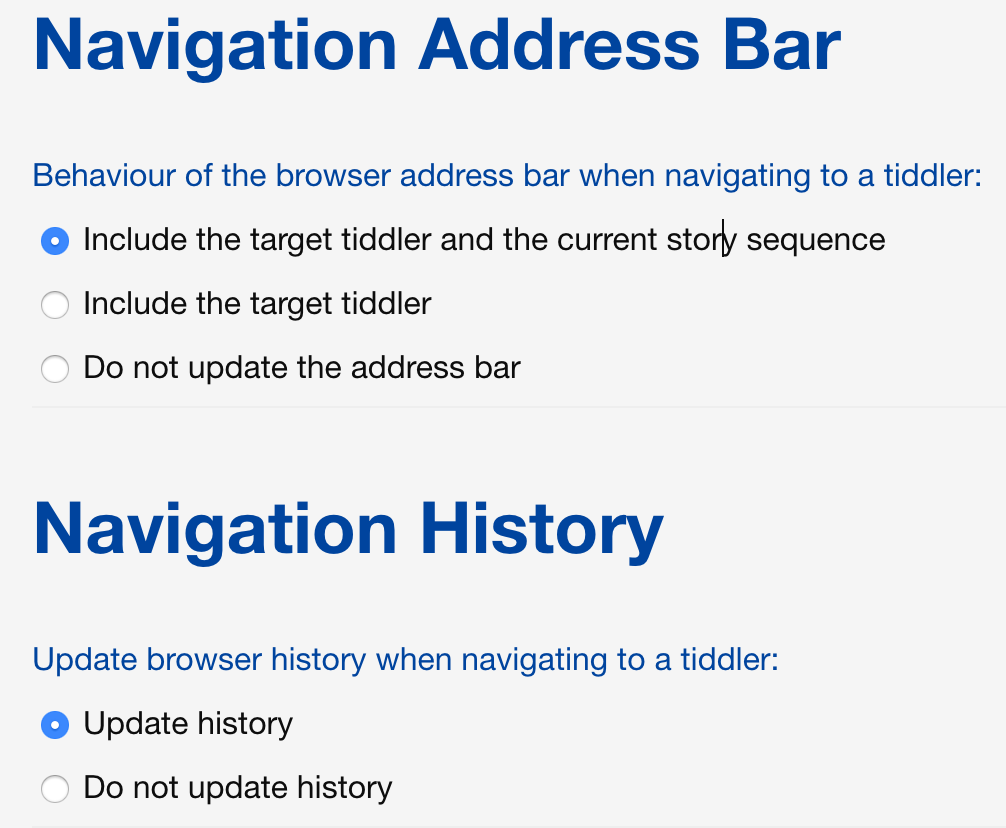
- Include the target tiddler and the current story sequence
- Update history
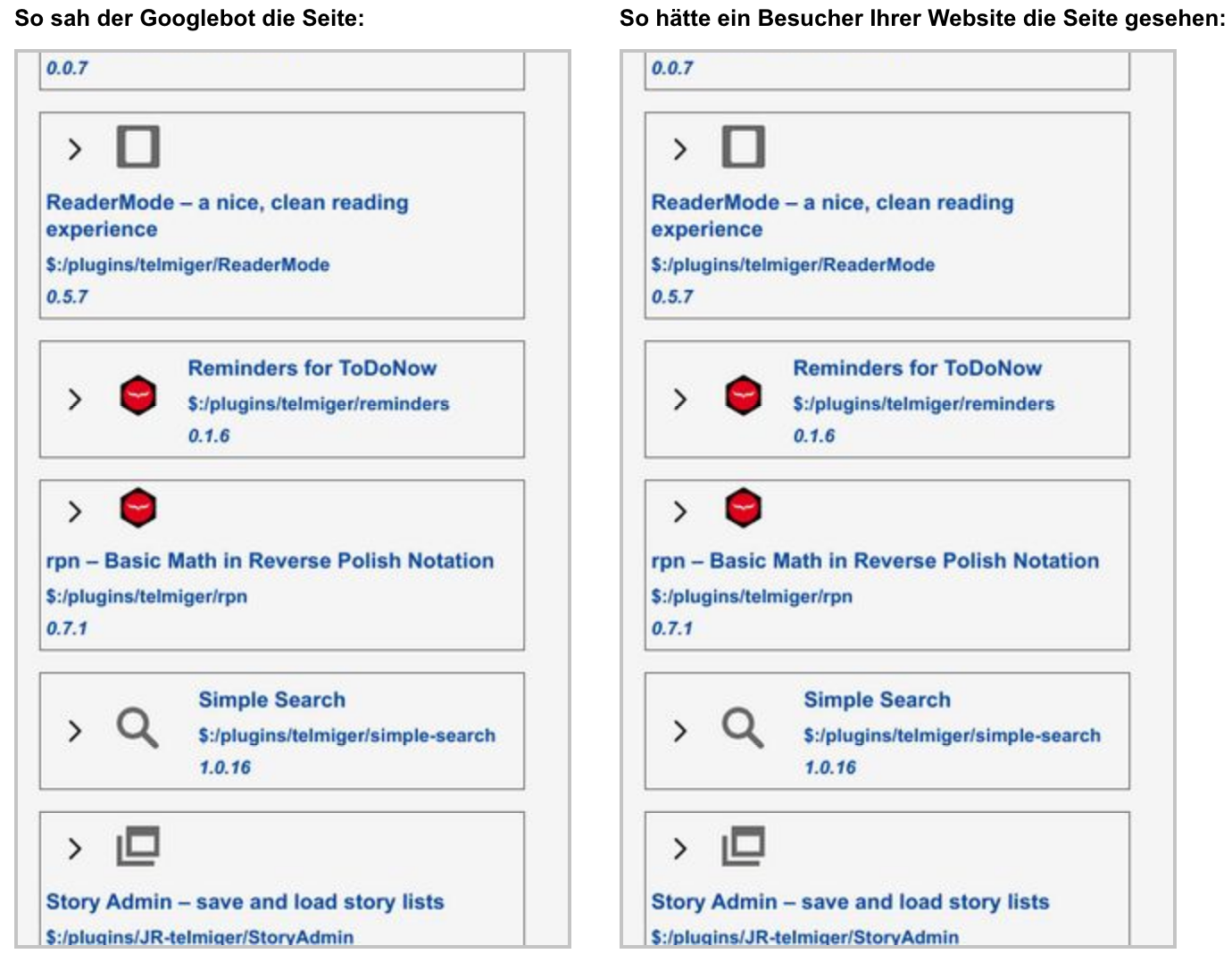
Thomas, can we change #tiddlername to ?tiddlername view? Google don't like # in Url?
--
You received this message because you are subscribed to a topic in the Google Groups "TiddlyWiki" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/tiddlywiki/MhVsFURHpoM/unsubscribe.
To unsubscribe from this group and all its topics, send an email to tiddlywiki+...@googlegroups.com.
To post to this group, send email to tiddl...@googlegroups.com.
Visit this group at https://groups.google.com/group/tiddlywiki.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/f968685e-b168-4a82-ac2a-6e9fe263472f%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Thomas Elmiger
TonyM
Thanks so much for undertaking this analysis. I look forward to the outcomes.
Tony
Thomas Elmiger
@TiddlyTweeter

Arlen Beiler
--
You received this message because you are subscribed to the Google Groups "TiddlyWiki" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tiddlywiki+...@googlegroups.com.
To post to this group, send email to tiddl...@googlegroups.com.
Visit this group at https://groups.google.com/group/tiddlywiki.
To view this discussion on the web visit https://groups.google.com/d/msgid/tiddlywiki/f41ca853-30ab-446e-8d1b-7721802d05c2%40googlegroups.com.
TonyM
TiddlyWiki's experimental single tiddler per page, read-only view uses a simplified page layout, and implements links between tiddlers, but there are no other interactive features. Compared to a full TiddlyWiki user interface, it is very lightweight and usable even over very slow connections.
Alongside serving the full interactive wiki at the path / (e.g. http://127.0.0.1:8080/), TiddlyWiki serves each tiddler at the path /<url-encoded-tiddler-title>. For example:
Ordinary,
non-system tiddlers are rendered through a special view template while
system tiddlers are rendered through a template that returns the raw
text of the rendered output. In this way ordinary tiddlers can be
browsed by end users while system tiddlers can be included in their raw
form to use them as JS, HTML or CSS templates. Additionally these
defaults can be overwritten on a per tiddler basis by specifying the _render_type and _render_template fields accordingly.