Platoon discussion: questions and suggestions

Christos Tsirigotis
I'm starting a thread in order to discuss the designing and development of the Platoon.
Platoon is a mini-framework whose purpose is to provide Theano users with training algorithms implemented for multi-gpu/multi-node infrastructures.
Here I would like to pose questions about its current state, discuss its purpose in specific and its responsibilities in the ecosystem, ask for new features to be included and discuss overall about is design and implementation details.
Without further introduction, I am posing my own questions about its current state and afterwards I will suggest changes in its requirements.
1
Implementation uses posix_ipc.ExistentialError in 4 places in channel.py. I am not sure I understand what its purpose is. It is used once when the Controller unlinks_semaphore and once when a Worker unlinks_shared_memory, both before creating each of those and when destroying them. Is it for clearing out (for sure) previously declared semaphores/shared memories with the same name?
2
What does _mmap function do?
3
I notice that a zmq push socket (asocket) is used in order to deliver minibatches from the controller to workers with a single publisher and multiple subscribers to the same topic (port). I believe that this is costly, especially for large minibatches, because in order to make multi-process/multi-gpu computation (1 process = 1 gpu), batches will be copied to O(n) worker processes and from there to O(n) devices. This introduces a lot of latency I think. So I suggest the following:
- Introduce a general dataset distribution API in platoon:
- Senario 1 - user samples minibatch in Controller and distributes the same minibatch to every gpu:
- Minibatch is generates in Controller
- Find a broadcast algorithm in order to drop copy-time to processes to O(logn), or if worker number is insufficient use O(n).
- Assign multiple-gpus to one worker and using nccl framework:
- Assign a local (per worker) nccl CommWorld
- upload from worker to a single gpu in localCommWorld
- and from there broadcast it to every other gpu in its own localCommWorld
- This solution will tackle temporarily with the problem that nccl support very limited multi-node. Design so as to be able to use the optimized nccl broadcast in general when nccl gets updated to include this.
- Even better I think, one can use a gpu to generate the minibatch (I don't know how well gpu global memory will hold in this case)
- Decide a sampling distribution in Controller and that seeding mechanism CuRAND uses
- Generate a seed in Controller and distribute it to workers
- Workers deliver it to a single gpu and gpu generates minibatch
- minibatch is broadcasted to localCommWorld
- Senario 2 - user wants every gpu to get a different sample-minibatch:
- Use current strategy, or
- When memory insufficient in gpu:
- Each worker holds an array of initially random seeds for each gpu and updates it (using a concrete user-desired distribution)
- In each step each worker generates a minibatch for each gpu using its corresponding seed
- Distributes with O(n) to each gpu.
- When memory sufficient, each gpu is distributed a random seed with which it generates its own minibatch.
4
Another suggestion, I think that platoon current design is driven to match how EASGD works very much. This may introduce difficulties when one includes a new algorithm with different "sync" logic that EASGD or even if a user wants to use platoon as an experimentation platform for distributed optimization algorithm designing. For example, there may be algorithms with no central particles, with different particle "stabilization" ways than having a single central particle like Downpour or EASGD. Let's say that one wants to experiment using an algorithm in which the particles interact with each other instead of a central particle. For this reason, I think top syncronization abstraction needs to be revised so as not to include operations between master and local particles, but to provide a "template" of distributed optimization algorithm to be filled. The user will need to fill the template with:
- The way to distribute samples of the dataset.
- The way that local particles update themselves in each update step.
- A synchronization condition rule.
- The way that local particles interchange information with each other (thus synchronizing)
- A condition rule to finish the algorithm.
Implementations of (1) will use the mechanics which will be developed in 2.
Implementations of (2) can be wrappers of functions of non-parallel optimization algorithms (e.g. adadelta, rmsprop, adam, nesterov's etc) using Theano with libgpuarray/pygpu backend.
Implementations of (3) can be a simple periodic rule or a schedule of periods or an exotic one (let's say entropy-based) or whatever.
Implementations of (4) will be the Downpour or EASGD mechanism, or a simpler one and will be the one that characterizes actually the algorithmic template of the inherited abstraction.
Implementations of (5) can be again something like the (3).
Splitting responsibilities like this, would allow to build independent reusable codebase, to create quickly many variations of algorithms, to minimize user coding and disengage hyperparameters from a concrete usable algorithm (something that defines all (1,2,3,4 and 5)) to be managed in the place (1, 2, 3, 4 or 5) where they are actually used.
In order for this to work well, implementations of (4), apart from the definition of the "synchronization" rule as it is defined now, will need to define routines built upon controller or worker communication helper functions which will tell a concrete controller or worker how to act on (4).
What do you think about these thoughts? Most probably, the notion of a controller and a worker will have to change/be augmented to apply such changes (i.e. a worker can be related to one or a group of devices), but the handling of the communication layer will remain their responsibility.
Because most probably I have not expressed my thoughts well enough, if you want I can write a diagram to be a flexible reference on what we will be discussing.
- - - - - - - - - - -
tl;dr: In case you agree that we need to discuss upon platoon API in general, I propose to organize a web meeting in order to discuss and decide on. Do you agree?
Christos

Frédéric Bastien
Hello to everyone!
I'm starting a thread in order to discuss the designing and development of the Platoon.
Platoon is a mini-framework whose purpose is to provide Theano users with training algorithms implemented for multi-gpu/multi-node infrastructures.
Here I would like to pose questions about its current state, discuss its purpose in specific and its responsibilities in the ecosystem, ask for new features to be included and discuss overall about is design and implementation details.
Without further introduction, I am posing my own questions about its current state and afterwards I will suggest changes in its requirements.
1
Implementation uses posix_ipc.ExistentialError in 4 places in channel.py. I am not sure I understand what its purpose is. It is used once when the Controller unlinks_semaphore and once when a Worker unlinks_shared_memory, both before creating each of those and when destroying them. Is it for clearing out (for sure) previously declared semaphores/shared memories with the same name?
- a lock
3
I notice that a zmq push socket (asocket) is used in order to deliver minibatches from the controller to workers with a single publisher and multiple subscribers to the same topic (port). I believe that this is costly, especially for large minibatches, because in order to make multi-process/multi-gpu computation (1 process = 1 gpu), batches will be copied to O(n) worker processes and from there to O(n) devices. This introduces a lot of latency I think. So I suggest the following:
Implementations of (2) can be wrappers of functions of non-parallel optimization algorithms (e.g. adadelta, rmsprop, adam, nesterov's etc) using Theano with libgpuarray/pygpu backend.
Implementations of (3) can be a simple periodic rule or a schedule of periods or an exotic one (let's say entropy-based) or whatever.
Implementations of (4) will be the Downpour or EASGD mechanism, or a simpler one and will be the one that characterizes actually the algorithmic template of the inherited abstraction.
Implementations of (5) can be again something like the (3).
Splitting responsibilities like this, would allow to build independent reusable codebase, to create quickly many variations of algorithms, to minimize user coding and disengage hyperparameters from a concrete usable algorithm (something that defines all (1,2,3,4 and 5)) to be managed in the place (1, 2, 3, 4 or 5) where they are actually used.
In order for this to work well, implementations of (4), apart from the definition of the "synchronization" rule as it is defined now, will need to define routines built upon controller or worker communication helper functions which will tell a concrete controller or worker how to act on (4).
What do you think about these thoughts? Most probably, the notion of a controller and a worker will have to change/be augmented to apply such changes (i.e. a worker can be related to one or a group of devices), but the handling of the communication layer will remain their responsibility.
Because most probably I have not expressed my thoughts well enough, if you want I can write a diagram to be a flexible reference on what we will be discussing.
- - - - - - - - - - -
tl;dr: In case you agree that we need to discuss upon platoon API in general, I propose to organize a web meeting in order to discuss and decide on. Do you agree?
--
Christos
---
You received this message because you are subscribed to the Google Groups "theano-dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to theano-dev+...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Christos Tsirigotis
Considering the platoon API changes: In order to make it usable in multi-node, as well as make it an easy distributed training framework to experiment on, I propose the following:
In general the changes will introduce:
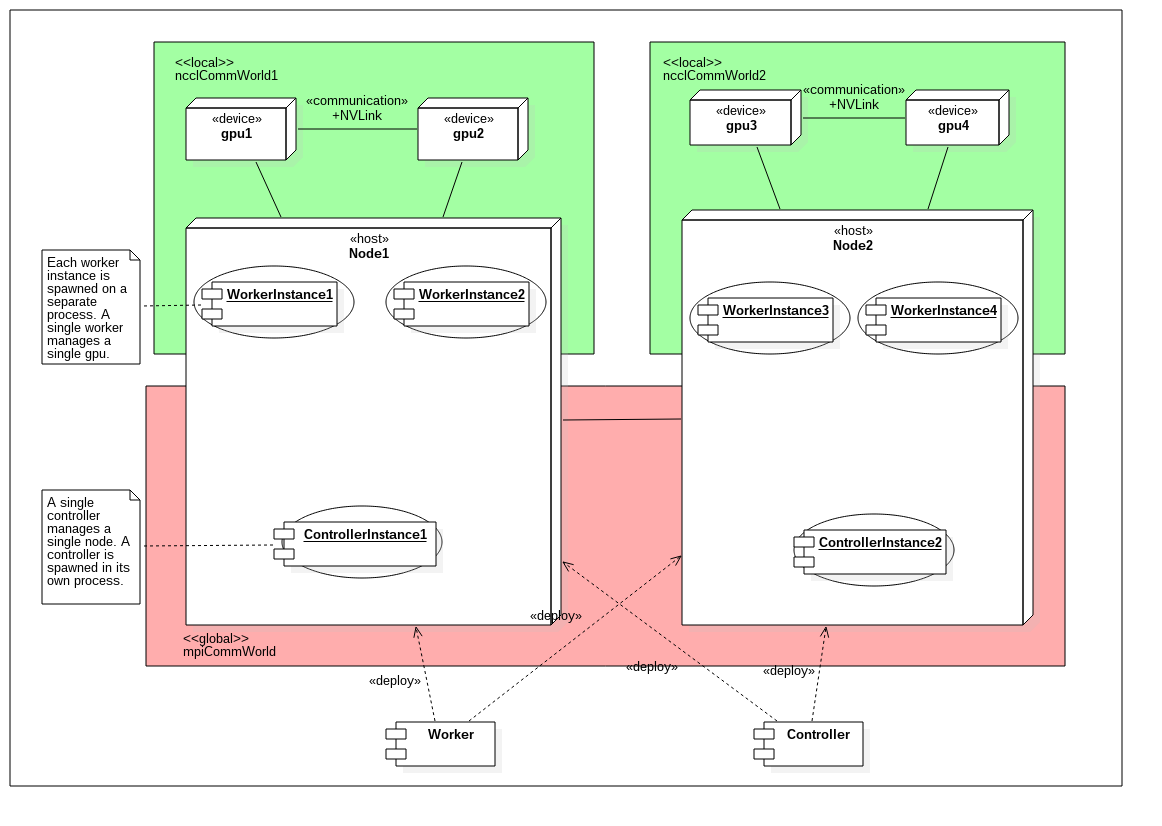
- A ncclCommWorld for intra-node communication and a mpiCommWorld for inter-node communication.
- Exposing a Theano-compatible interface for distributed collectives (e.g. worker.all_reduce(...) ).
- Reversing the control flow between the sync rule and the worker (the sync rule will call worker's functions and not the other way around - so as to compose `Worker` class only with communication related issues).
- A class which corresponds to a distributed (or not) generic training method which implies a sync rule method plus a general training flow.
- 4 classes to be implemented which correspond to a `Sampler`, `LocalOptimizingDynamics`, a `SyncingCondition` and a `FinishingCondition`.
- Removing ParamSyncRule class (or keeping it for usage when nccl is not available).
Explaining changes in `Worker`:
Each node spawns a single Controller instance in its process. Each node spawns also N Worker instances in their own processes. As before, the controller manages and co-ordinates the N worker and each worker corresponds to a single gpu device on the node.
For `init_worlds`:
- For each node, Workers ask to register to a Controller
- Controllers from every node register once as ranks to a global mpiCommWorld
- and then in each node, a Controller will organize workers in its node and return a unique id to each one.
- Workers then register as ranks to a local ncclCommWorld and set their own device (this is done in Theano)
For `new_shared_mem`:
This is going to be current `init_shared_params` with 2 differences:
- No `param_sync_rule` will be registered.
- A dictionary will be used to have the `params` (Theano variable) point to the newly-created corresponding host shared memory. Also, (posix) locks for `params` will be created for each call to `new_shared_mem` in collaboration with the Controller. These locks for each param can be used from Worker's API to `lock_params(params, timeout)` or `unlock_params(params)` for the specific host shared memory which corresponds to `params`.
For a collective, such as `all_reduce`:
- AllReduce will be called from pygpu interface for the local ncclCommWorld that the worker is registered to.
- then once for any worker (thus the first worker that reaches the lock):
- the `destination` of pygpu/nccl `AllReduce` is copied to its corresponding host shared memory.
- this worker asks for the Controller to participate in an AllReduce collective (with the same operation and data type as pygpu/nccl AllReduce
- Controller calls AllReduce for the global mpiCommWorld with the corresponding host shared memory as src and dest (is this possible?) and responds to the worker.
- All workers will asychronously copy from host shared memory to their gpu destination.
These are the "major" changes in worker/controller.
Considering the other changes, I will ask you to read platoon/generic_training.py in my clone.
Please begin from: line 239
I tried to express my thoughts as an interface and as documentation, please ask me for further explaination.
I post 2 diagrams with my thoughts on the communication, the Worker/Controller and the generic training class suite.
And also, in the attachment exists the diagram file from staruml.
I feel like I should explain more about decisions in this proposal.
Please let's all who are interested, organize a web meeting in order to discuss changes towards multi-node.
Christos

{kind=link}
{kind=link}
Arnaud Bergeron
The point of platoon was to have a light-weight library that you can plug in to your existing script/framework and add multi-device training. What you are proposing is essentially its own mini-framework for training. It requires people to adapt their interface for dataset iteration, gradient updates, and lose control over their whole training loop.
Christos Tsirigotis
Arnaud Bergeron
Well, it's not necessary to use the proposed framework as a whole. One who has already some things implemented can try to use, if he wants, a Sampler or a Condition as a standalone. Also because this design expects that the worker is instanciated by user's code, someone can use the worker still by itself without using the implied flow of GenericTraining's train. Nevertheless, someone, who starts building a trainer, can use the class and all the required object types to create and experiment with reusable & fast (due to the multi-gpu/node interface) training "parts" which can be combined in any ways. Finally, someone who wishes not to adapt code or use the 'train' function, can still use the 'sync' function alone. It stays a mini-framework in a sense that does not enforce the user to use its ways but will provide reusable helpers.
I agree with the callback injection!
:)
I would like to include also a 'validate' function and a 'make_validation_sample' as well.
I will rewrite lstm example accordingly, as a proof of concept.
Also as I expect to use this thing to experiment with various dynamics and also implement existing ones, how does one unit test a gradient descent???
Frédéric Bastien
Christos Tsirigotis
Well, it's not necessary to use the proposed framework as a whole. One who has already some things implemented can try to use, if he wants, a Sampler or a Condition as a standalone. Also because this design expects that the worker is instanciated by user's code, someone can use the worker still by itself without using the implied flow of GenericTraining's train. Nevertheless, someone, who starts building a trainer, can use the class and all the required object types to create and experiment with reusable & fast (due to the multi-gpu/node interface) training "parts" which can be combined in any ways. Finally, someone who wishes not to adapt code or use the 'train' function, can still use the 'sync' function alone. It stays a mini-framework in a sense that does not enforce the user to use its ways but will provide reusable helpers.As long as that stays possible, then it should be ok. But we might have to underline this in the docs so that people don't feel like they have to buy the whole thing.
I agree with the callback injection!
:)
I would like to include also a 'validate' function and a 'make_validation_sample' as well.One of the things to watch for is that if we are doing synchronous training, then it might be wrth it to distribute the validation and test. Otherwise it's going to the one worker doing it and the others twiddling their thumbs.
Yeap, I also think it should be in the same philosophy as the `GenericTraining`. `Sampler`s distribute (?using workers) and deliver validation/test datasets, `GenericTraining`s or `Validator`s (for example) work locally per node on their data and extract statistics and then they sync to combine them into global statistics.
I will rewrite lstm example accordingly, as a proof of concept.Good idea.
Also as I expect to use this thing to experiment with various dynamics and also implement existing ones, how does one unit test a gradient descent???It's not really possible to "unit test" gradient descent. You can test the individual parts, but it will require some integration tests that train a known model to some degree of accuracy.
To unsubscribe from this group and stop receiving emails from it, send an email to theano-dev+unsubscribe@googlegroups.com.
--
---
You received this message because you are subscribed to the Google Groups "theano-dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to theano-dev+unsubscribe@googlegroups.com.
Christos Tsirigotis
Hi,This is great, but first, wrap nccl in libgpuarray and use it before changing too much thing and working on multi-node.
agree :)
For the multi-node, we need to think about it. I think it is not duplicate effort with Theano-MPI, as Theano-MPI is about model-parallelism and this project about data parallelism only.
Fred
Each particle in a process/gpu gets the whole model and so it has opinion for every model parameter. Thus, I also think it's not duplicate effort. Plus, Platoon can also serve as a distributed dynamics framework itself (EASGD is such an example), except data parallelism.
Christos
Christos
To unsubscribe from this group and stop receiving emails from it, send an email to theano-dev+unsubscribe@googlegroups.com.
--
---
You received this message because you are subscribed to the Google Groups "theano-dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to theano-dev+unsubscribe@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.