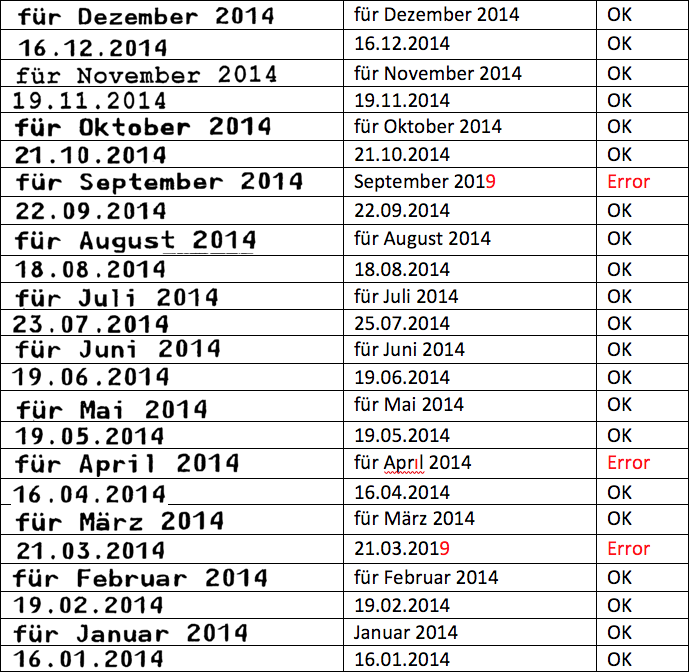
Tesseract 4 sometimes confuses a 4 with a 9
145 vistas
Ir al primer mensaje no leído

p1146182017...@googlemail.com
8 dic 2018, 8:18:42 a.m.8/12/2018
para tesseract-ocr
Hi,
I started using Tesseract 4.0.0 (with LTSM) recently and it works amazingly well—much better than Affinity and Nuance that were bundled with my ScanSnap scanner.
However, with certain documents, there’s the issue that the digit “4” occasionally gets recognized as a “9”. Example below.
I’ve read in the Wiki that you can fine-tune for certain characters. Is this the way to go here? Or is there maybe an easier/better approach? At first glance, the fine-tuning approach seemed to be a bit complicated to me, so before I wrap my head around this, I’d appreciate if you could give my some guidance if this is the right thing to do here.
This is my command-line:
tesseract "$1" "${1%.*}" -l best/deu --tessdata-dir "$DIR/tessdata" --psm 11 --oem 1 txt pdf
The documents are 1200 DPI (monochrome).
Thanks,
Aaron
p1146182017...@googlemail.com
8 dic 2018, 8:58:27 a.m.8/12/2018
para tesseract-ocr
I meant to write ABBYY FineReader, not Affinity.

Lorenzo Bolzani
8 dic 2018, 9:30:41 a.m.8/12/2018
para tesser...@googlegroups.com
If the text is very small, like less than 20/30px, you can try to upscale it and see if it helps.
Otherwise fine tuning is the only alternative I know of.
If you use https://github.com/OCR-D/ocrd-train it is quite simple once you have the crops and the corresponding text. I did it a few times and the results are very good.
--
You received this message because you are subscribed to the Google Groups "tesseract-ocr" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-oc...@googlegroups.com.
To post to this group, send email to tesser...@googlegroups.com.
Visit this group at https://groups.google.com/group/tesseract-ocr.
To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/be6229ab-591d-44a3-9b54-3e9984d267ed%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
p1146182017...@googlemail.com
10 dic 2018, 3:46:15 a.m.10/12/2018
para tesseract-ocr
The characters have a height of ~100px, so this shouldn’t be the issue.
Responder a todos
Responder al autor
Reenviar
0 mensajes nuevos