
Alberto

andy
Io ci lavorerei volentieri, soprattutto con qualcuno che mastica di mappe (che però a SOD19 non manca). Bisognerebbe capire che dati abbiamo, se a Milano c'è qualcosa di simile ai quartiers o no; e se magari l'area metropolitana ha dei dati a livello più ampio (i 3 milioni di abitanti della grande Milano invece del 1.3 milioni del Comune. Qualcuno ha qualche idea? Andrea forse? Tommaso, quando senti il Comune puoi buttargliela lì?
website: https://medium.com/tantotanto
38° 7' 48" N, 13° 21' 9" E, EPSG:4326
___________________
"cercare e saper riconoscere chi e cosa,
in mezzo all’inferno, non è inferno,
e farlo durare, e dargli spazio"
Italo Calvino

Daniele Crespi
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/CAHEdGZM-PjabjjN__d5HgOi2FEAVykm%2Bdqa9JCGXU3sL%2BYEAFg%40mail.gmail.com.
Per altre opzioni visita https://groups.google.com/d/optout.

Maurizio Napolitano
Alberto

Marco Brandizi
- concordare un unico modello di dati (in qualunque formato, anche una serie di template CSV), da applicare ad ogni dataset, assumendo che ce ne sarà uno per città, più eventualmente modellare un po' di cose comuni/generali (es, valori aggregati su tutte le città).
- sviluppare un template di analisi che, dato un/a dataset/città, produce automaticamente una serie di tabelle, grafici, report, senza dover lavorare a mano su ogni dataset.
- eventualmente in seguito, pensare a qualche analisi aggregata su tutti i dataset.
In alternativa, se deciderete di lavorare ad un solo caso/città, potreste comunque farlo pensando alla prospettiva di automatizzare l'analisi e i report, passandogli ogni volta un dataset diverso (non è molto difficile, basta adottare alcuni accorgimenti tipo che non si scrivono file path direttamente negli script, ma in un file di configurazione).
Ciao,
Marco
A Trento non sembra ci sia segregazione! Bravo, comunque, sei assunto per l'hackathon di Milano :-)
Daniele, aiutami a capire. Posso chiedere di tirare su dati apposta? Davvero? A chi?
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/924fa61d-f31f-43c9-8164-83a189f176e1%40googlegroups.com.
Per altre opzioni visita https://groups.google.com/d/optout.
Marco Brandizi <marco.b...@gmail.com>
http://www.marcobrandizi.info
Alberto
Marco Brandizi
M.
Grazie, Marco, ottima idea... ma alla fine dipenderà moltissimo da come sono i dati, come sempre. Per esempio, A Bruxelles c'è la provenienza "UE a 13", che io non mi ricordo neanche quali paesi fossero. Probabilmente a Milano questa cosa non c'è. Standardizzare è sempre dura.
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/d00e825b-edcb-41a9-9e69-af853014aef2%40googlegroups.com.
Per altre opzioni visita https://groups.google.com/d/optout.
Maurizio Napolitano
Grazie, Marco, ottima idea... ma alla fine dipenderà moltissimo da come sono i dati, come sempre. Per esempio, A Bruxelles c'è la provenienza "UE a 13", che io non mi ricordo neanche quali paesi fossero. Probabilmente a Milano questa cosa non c'è. Standardizzare è sempre dura.
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/d00e825b-edcb-41a9-9e69-af853014aef2%40googlegroups.com.
Maurizio Napolitano
A Trento non sembra ci sia segregazione! Bravo, comunque, sei assunto per l'hackathon di Milano :-)

Tommaso Dradi
Popolazione: residenti per cittadinanza e quartiere
Il dataset contiene i dati anagrafici della popolazione residente distinta per anno (al 31/12), età, sesso, cittadinanza e quartiere. Avvertenza: si consiglia l'importazione dei file scaricati mediante pacchetti statistici o software per la gestione di database (DataBase Management System), in quanto i file possono superare il numero massimo di record supportato dai fogli elettronici.
Territorio: localizzazione dei quartieri della città (Nuclei d'Identità Locale - NIL)
I NIL - Nuclei d'Identità Locale rappresentano aree definibili come quartieri di Milano, in cui è possibile riconoscere quartieri storici e di progetto, con caratteristiche differenti gli uni dagli altri. Vengono introdotti dal PGT (Piano di Governo del Territorio) come un insieme di ambiti, connessi tra loro da infrastrutture e servizi per la mobilità, il verde. Sono sistemi di vitalità urbana: concentrazioni di attività commerciali locali, giardini, luoghi di aggregazione, servizi; ma sono anche 88 nuclei di identità locale da potenziare e progettare ed attraverso cui organizzare piccoli e grandi servizi (Piano dei Servizi).
Il sistema di coordinate utilizzato è EPSG:32632 WGS 84 / UTM zone 32N
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/CAFYQUmb63VwvYJ9UX46%3DBCBnG9YtdVpOs-8s7e9OW1M8yoqZOg%40mail.gmail.com.
Alberto
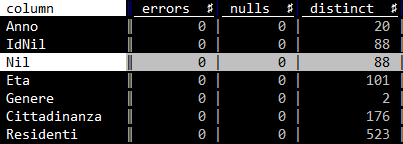
- posso avere un volontario che mastichi un po' di QGIS e mi dà una mano? Perché io devo ripartire da zero e non ce la posso fare :-)
- i dati però sembrano avere qualche problema.
{'Anno': 1999, 'IdNil': 1, 'Nil': 'Duomo', 'Eta': '0', 'Genere': 'Femmine', 'Cittadinanza': 'Cinese, Rep. Popolare', 'Residenti': 1}
Una roba del genere è un po' difficile da gestire. Sembrerebbe rappresentare due records, uno relativo a quattro femmine peruviane di 36 anni che vivono a Sarpi, e l'altro relativo a una femmina polacca, anche lei di 36 anni, che vive anche lei a Sarpi. I records che tirano su un errore perché gli manca il nome del campo sono 1,136,905 su 2,136,904.
andy
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/0a3c2f75-24df-43bb-a017-c445e8cd89e1%40googlegroups.com.
Per altre opzioni visita https://groups.google.com/d/optout.
andy
Alberto
Alberto

Giovan Battista Vitrano
Giovan Battista Vitrano

Matteo Brunati
Il giorno sabato 11 maggio 2019 17:04:31 UTC+2, Giovan Battista Vitrano ha scritto:
Alberto
Giovan Battista Vitrano
Giovan Battista Vitrano
Milano e Palermo: le mappe della distribuzione della popolazione straniera residente nel 2018
Daniele Crespi
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/63e5cb3c-f4ba-4d42-81bb-55a10bcfc2ea%40googlegroups.com.

Alberto Cottica
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/CABT_80RTYNKB7Joif93AjQfe-VmRUwMdHYhkAT8T%3DSXPN%3D6NQA%40mail.gmail.com.
andy
Scusami per la brevità, ti sto scrivendo dal cellulare.
website: https://medium.com/tantotanto
38° 7' 48" N, 13° 21' 9" E EPSG:4326
--
Matteo Brunati
Alberto

Marco Scarselli
--
Hai ricevuto questo messaggio perché sei iscritto al gruppo "Spaghetti Open Data" di Google Gruppi.
Per annullare l'iscrizione a questo gruppo e non ricevere più le sue email, invia un'email a spaghettiopend...@googlegroups.com.
Visita questo gruppo all'indirizzo https://groups.google.com/group/spaghettiopendata.
Per visualizzare questa discussione sul Web, visita https://groups.google.com/d/msgid/spaghettiopendata/85ec8b96-3735-4476-a24d-3b8570041af4%40googlegroups.com.