Character representations
208 views
Skip to first unread message

Neil Hodgson
May 2, 2012, 9:49:46 PM5/2/12
to scintilla...@googlegroups.com
Sometimes it is difficult to distinguish similar characters and characters that you don't recognize may be present in a file. Perhaps you need to distinguish the Greek Omega character from the Ohm symbol. It would help these and other situations if there was a way to change the representations to be distinguishable or carry more information.
I wrote an experimental implementation of this, where the 'character blob' technique used for control characters was extended to other characters. It looks like http://www.scintilla.org/CharacterRepresentations.png
The character blob code was initially designed for ASCII mnemonics which are upper-case Roman characters and normally fit into a constrained area - other characters, depending on font, may not fit into the blob. The example looks OK in Segoe UI but not in some other fonts. The feature could be limited to a limited range of characters or an (optional?) alternate appearance chosen such as underlines, overlines or bracketing symbols.
Enabling this will entail a performance cost as, when it is active, there will have to be a look-up for each character in the layout and drawing code.
Substituting representations for individual characters instead of arbitrary strings allows these representations to implement the normal functionality for drawing and selection. Allowing representations for arbitrary strings would enable displaying ";-)" as a smiley character but there does not appear to be sufficient benefit. Checking for arbitrary strings is likely to perform much slower. An application that wants to display smiley characters can replace the ";-)" with a private use character and set the representation of that character.
Another possibility would be to use images to represent characters like the green bars and red slash in http://www.scintilla.org/CharacterImage.png
A patch that implements this is attached. There is no API so the representations are hard-coded in the Editor constructor. The set of characters with representations implemented is "ΩΩ℧ƿǷᚹ℃℉". The implementation performs poorly in space and time but optimization will depend on which features are needed.
I don't plan on committing this for at least a couple of releases since the functionality as well as implementation needs to be refined further.
Neil

Ferdinand Prantl
May 3, 2012, 3:07:59 AM5/3/12
to scintilla...@googlegroups.com
I may still stick to using a well-designed font for improving the display clarity. Programmer's fonts were always designed for that (O and 0; difficult to distinguish in the gmail editor :-) It needs no additional code and even the character substitution would not look appealing to the user without a nice font... The substitution should be off by default.
Drawing images characters or character groups sounds interesting. Although I use Scintilla as a programmer's editor I can imagine editing a source text with something like in-place preview; as yuo say, smileys, or ellipsis or other rendering changes done by engines like Markdown, e.g. I wonder if this would be pluggable like syntax-highlighting in lexers today.
--- Ferda
On Thu, May 3, 2012 at 3:49 AM, Neil Hodgson <nyama...@me.com> wrote:
Sometimes it is difficult to distinguish similar characters and characters that you don't recognize may be present in a file. Perhaps you need to distinguish the Greek Omega character from the Ohm symbol. It would help these and other situations if there was a way to change the representations to be distinguishable or carry more information.
[snip]

Philippe Lhoste
May 3, 2012, 6:39:07 AM5/3/12
to scintilla...@googlegroups.com
On 03/05/2012 03:49, Neil Hodgson wrote:
> Sometimes it is difficult to distinguish similar characters and characters that you don't
> recognize may be present in a file. Perhaps you need to distinguish the Greek Omega
> character from the Ohm symbol. It would help these and other situations if there was a way
> to change the representations to be distinguishable or carry more information.
>
> I wrote an experimental implementation of this, where the 'character blob' technique used
> for control characters was extended to other characters. It looks like
> http://www.scintilla.org/CharacterRepresentations.png
Interesting idea, and it can be quite useful for some languages like Scala which can use a
> Sometimes it is difficult to distinguish similar characters and characters that you don't
> recognize may be present in a file. Perhaps you need to distinguish the Greek Omega
> character from the Ohm symbol. It would help these and other situations if there was a way
> to change the representations to be distinguishable or carry more information.
>
> I wrote an experimental implementation of this, where the 'character blob' technique used
> for control characters was extended to other characters. It looks like
> http://www.scintilla.org/CharacterRepresentations.png
large subset of Unicode as coding symbols...
Now, the textual representation (the name of the character) is a bit too much, since it
would need a quite large Unicode database to feed it... Well, if it is optional, it is OK.
Personally, I have softwares like BabelMap, or sites like FileFormat (eg.
http://www.fileformat.info/info/unicode/char/9e9f/index.htm page) to give extended
information on a character.
Perhaps a simple hexa display (a bit like what Firefox displays when it has no glyph
corresponding to the code point, but bigger!) is enough in most cases.
--
Philippe Lhoste
-- (near) Paris -- France
-- http://Phi.Lho.free.fr
-- -- -- -- -- -- -- -- -- -- -- -- -- --
Neil Hodgson
May 3, 2012, 7:06:22 PM5/3/12
to scintilla...@googlegroups.com
Ferdinand Prantl:
Programmer's fonts were always designed for that (O and 0; difficult to distinguish in the gmail editor :-)
With Unicode, there are many more similar characters like 'Ω' and 'Ω'. And 'o', 'о', and 'ο'.
It needs no additional code and even the character substitution would not look appealing to the user without a nice font... The substitution should be off by default.
It would be controlled by the application which provides the representations. Probably implemented as a mode similar to View | Whitespace.
Neil
Philippe Lhoste
May 4, 2012, 5:06:40 AM5/4/12
to scintilla...@googlegroups.com
On 04/05/2012 01:06, Neil Hodgson wrote:
> Ferdinand Prantl:
>> Programmer's fonts were always designed for that (O and 0; difficult to distinguish in
>> the gmail editor :-)
>
> With Unicode, there are many more similar characters like 'Ω' and 'Ω'. And 'o', 'о', and 'ο'.
Indeed, I still wonder, with the plan to make URLs using Unicode, if they manage to
> Ferdinand Prantl:
>> Programmer's fonts were always designed for that (O and 0; difficult to distinguish in
>> the gmail editor :-)
>
> With Unicode, there are many more similar characters like 'Ω' and 'Ω'. And 'o', 'о', and 'ο'.
distinguish http://stackoverflow.com from http://stackоverflοw.com for example...
I hope so, otherwise it is an open door for scams.
If I understood correctly (I haven't looked at the patch...), Scintilla doesn't provide
the mapping of a char to its representation (although I suppose it can do it if asked to
show a simple hexa code) but it is provided by the application (in the case of char
descriptions, for example), right?
Neil Hodgson
May 4, 2012, 5:27:18 AM5/4/12
to scintilla...@googlegroups.com
Philippe Lhoste:
> If I understood correctly (I haven't looked at the patch...), Scintilla doesn't provide the mapping of a char to its representation (although I suppose it can do it if asked to show a simple hexa code) but it is provided by the application (in the case of char descriptions, for example), right?
The patch is very early and incomplete. My initial thought was to not have any representations built in but for them all to be set by the application. It may be sensible to have a built-in hex mode but even then you'd want the application to be able to decide which characters are displayed in hex and which are shown normally. As an example, you may want the standard ASCII 'o' shown as 'o' but the Greek and Cyrillic characters that look like 'o' displayed in hex.
Neil
> If I understood correctly (I haven't looked at the patch...), Scintilla doesn't provide the mapping of a char to its representation (although I suppose it can do it if asked to show a simple hexa code) but it is provided by the application (in the case of char descriptions, for example), right?
Neil
Neil Hodgson
Jul 14, 2013, 1:09:05 AM7/14/13
to scintilla...@googlegroups.com
About 15 months ago, I mentioned a potential feature to display particular characters in a special way similar to the way that control characters are currently shown. The feature wasn't incorporated into Scintilla.
There has been more need for this demonstrated since then. One example is this feature request for a visible Zero Width Space (ZWSP U+200B):
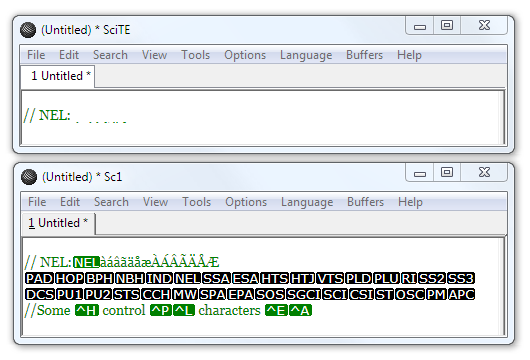
Another issue struck me recently. While Scintilla makes the normal (C0) control characters visible, it does not do so for the C1 control characters (U+0080 .. U+009F). http://en.wikipedia.org/wiki/C0_and_C1_control_codes . They commonly display as slim or zero-width spaces but with DirectWrite the NEL character (Next Line U+0085) causes the drawing position to drop down one line appearing as the top example in this image with just the tips of accents visible:
The second example in the image shows the NEL made visible so the trailing characters appear in their correct positions. The next 2 lines show all 32 C1 control characters displayed using their mnemonics.
This is the third set of character blobs (after C0 and UTF-8 invalid bytes) so has become unwieldy to implement: it would be better to include a generic mechanism to choose which characters need representations and what those representations should be. Some may prefer, for example, to display control characters as shown on the last line instead of as mnemonics. Drawing styles other than the inverted blob may also be wanted.
There is some performance impact to this as the measurement and drawing code will look up each character in the representations map. This could be minimised by using unordered_map instead of map but that may cause problems with older compilers even though unordered_map was included in C++ TR1 published in 2007.
This won't be incorporated into 3.3.4 which I expect to release in about a week but could go into the release after that.
Neil
Neil Hodgson
Jul 14, 2013, 9:45:58 PM7/14/13
to scintilla...@googlegroups.com
Here's a diff for anyone who wants to examine this potential feature.
The main API is SCI_SETREPRESENTATION(const char *encodedCharacter, const char *representation).
Other APIs may be implemented later to clear representations, set up defaults for control characters, and for queries.
Neil
The main API is SCI_SETREPRESENTATION(const char *encodedCharacter, const char *representation).
Other APIs may be implemented later to clear representations, set up defaults for control characters, and for queries.
Neil
Neil Hodgson
Jul 23, 2013, 2:51:29 AM7/23/13
to scintilla...@googlegroups.com
The character representations feature is now included in Scintilla.
The previously implemented display of control characters and invalid bytes in UTF-8 is now performed through this mechanism. C1 control characters (U+0080 .. U+009F) in UTF-8 are now displayed as mnemonics.
APIs are available for applications to choose representations for characters:
SCI_SETREPRESENTATION(const char *encodedCharacter, const char *representation)
SCI_GETREPRESENTATION(const char *encodedCharacter, char *representation)
SCI_CLEARREPRESENTATION(const char *encodedCharacter)
SCI_CLEARREPRESENTATION(const char *encodedCharacter)
This can be used, for example, to display an ambiguous character in a special way. The Ohm sign Ω U+2126 can be displayed like [U+2126 Ω] with
SCI_SETREPRESENTATION("\xe2\x84\xa6", "U+2126 \xe2\x84\xa6")
Another use is to temporarily show invisible characters like zero-width space.
The standard representations for control characters can be replaced if desired.
Available from the Mercurial repository:
hg clone http://hg.code.sf.net/p/scintilla/code scintilla
and from
http://www.scintilla.org/wscite.zip Windows executable
Performance and portability notes:
This feature requires examining every character and looking up its representation when laying out or displaying lines. It originally used an unordered_map (hash table) instead of a map since finding a character in an unordered_map is faster. The unordered_map class was added to C++ in C++11 but was originally documented in C++ TR1 in 2007 so has been available with most compilers for years. Its the details of that availability that caused too much trouble.
On Windows with Microsoft Visual C++, unordered_map was included with an update to Visual C++ 2008 but this update was not made available with the free 'Express' edition. Its probably too early to sacrifice VC++ 2008 as some important software, including Python 2.7 require it.
On OS X, using libstdc++, as Scintilla currently does, unordered_map is available as std::tr1::unordered_map and the header is tr1/unordered_map. The future is libc++ where the tr1 can be ignored, but libc++ doesn't work on OS X 10.6. Scintilla currently supports 10.5+ and again, its too early to drop 10.6.
Using gcc, as on Linux, the --std=c++0x option must be set. However, one of the supported platforms, PySide, does not work with --std=c++0x. The next version, PySide 1.2.0, will but that is not widely distributed as yet. BTW, the setting to make Qt projects use the c++0x option is:
*-g++*:QMAKE_CXXFLAGS += --std=c++0x
If just one of these issues had occurred, there'd be an #ifdef or similar workaround (and one was checked in for a while) but the number of problems made me believe that using unordered_map now would be a support sink. Similar issues will recur for using C++11 regex.
To avoid a full retrieval from the map for each character, there is an extra array indexed by the first byte of a character indicating whether there are any entries in the map starting with that byte value. This avoids deep checks for visible ASCII characters, unless they have representations added by the application which would be unusual. This check may be extended in the future if there are any slow-downs observed with particular types of files, such as Asian text.
Neil

JLuc Pass Eco
Jul 23, 2013, 3:38:40 AM7/23/13
to scintilla...@googlegroups.com, nyama...@me.com
Le jeudi 3 mai 2012 03:49:46 UTC+2, Neil Hodgson a écrit :
> Sometimes it is difficult to distinguish similar characters and characters that you don't recognize may be present in a file. Perhaps you need to distinguish the Greek Omega character from the Ohm symbol.
> Sometimes it is difficult to distinguish similar characters and characters that you don't recognize may be present in a file. Perhaps you need to distinguish the Greek Omega character from the Ohm symbol.
> I don't plan on committing this for at least a couple of releases since the functionality as well as implementation needs to be refined further.
Does it enable to see the soft hyphens on screen and to distinguish special spaces ?
I use geany to edit scribus documents, but not seing soft hyphens makes it feels like working blindly. Having the ability to have invisible characters displayed visibly would be a great help. Same with distinguishing special spaces.
Neil Hodgson
Jul 23, 2013, 5:09:33 AM7/23/13
to scintilla...@googlegroups.com
JLuc Pass Eco:
> Does it enable to see the soft hyphens on screen and to distinguish special spaces ?
Yes, that should be possible with this feature.
Neil
> Does it enable to see the soft hyphens on screen and to distinguish special spaces ?
Neil
Neil Hodgson
Aug 9, 2013, 2:51:32 AM8/9/13
to scintilla...@googlegroups.com
The character representation feature caused slow display of files containing many control characters such as executable files. Not that Scintilla is meant for displaying executable files - that's what hex editors are for. An update has been committed that prevents this slowness.
Also fixed a problem with representations not being set up in some cases and simplified the code.
https://sourceforge.net/p/scintilla/bugs/1511/
Neil
Also fixed a problem with representations not being set up in some cases and simplified the code.
https://sourceforge.net/p/scintilla/bugs/1511/
Neil
Reply all
Reply to author
Forward
0 new messages