Scope of redesigned collections

martin odersky
collection architectures:
https://github.com/lampepfl/dotty/issues/818
The issue lists some requirements for a design to be acceptable. Since
then there has been a discussion about several points that are all
outside the requirements outlined in #818. I think it's worthwhile to
discuss these, but do not think #818 is the proper place to do it.
That's why I would like to continue the discussion here.
- Martin
--
Martin Odersky
EPFL
martin odersky
>> We gloss over the mutabile/immutable distinction
> We probably want mutable collections to not have the same API as the immutable ones. One large problem with the current mutable collections is that by inheriting all the immutable methods, it's
neigh impossible to figure out where the "useful" mutable methods are.
e.g. Buffers append/remove is what you generally care about, but
they're lost in the huge sea of immutable methods you basically never
want. The same applies to mutable.Set, mutable.Queue, etc.
> By that logic, ArrayBuffer probably shouldn't be a collection, and perhaps making it convertible to one through .view or .iterator is enough?
If we take this idea to its logical conclusion, we should abandon
`map` and friends on arrays because they are also mutable. This would
render obsolete virtually every Scala book in existence. Besides, it
would be counter-productive. Map and friends are perfectly good
methods on arrays.
So if we do not want to go there, where to draw the line?
- Martin
Martin Odersky
EPFL

Haoyi Li
--
You received this message because you are subscribed to the Google Groups "scala-debate" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scala-debate...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
martin odersky
the same operations?
There's the other valid use case where you build up a mutable
collection and once it is fully constructed want to use it as if it
was immutable. Copying to make it immutable is not permitted for
performance reasons. How would be support that?
- Martin
Martin Odersky
EPFL
Haoyi Li
the same operations?

Aleksandar Prokopec
On Monday, 5 October 2015 22:54:03 UTC+2, Haoyi Li wrote:
> But, what about ResizableArray. It looks like an array, so why deny it
the same operations?
Good question. Do people use it? I count 220 occurrences on github in Scala files vs 370895 occurrences for "Seq" vs 48,532 occurrences for "ArrayBuffer", so I'd argue the added weirdness in that case won't affect too many people> There's the other valid use case where you build up a mutablecollection and once it is fully constructed want to use it as if itwas immutable. Copying to make it immutable is not permitted forperformance reasons. How would be support that?
To play the devils advocate with what Martin said: we don't need to copy a mutable collection to make it immutable, we could just freeze it, i.e. disallow further updates.
Another possibility would be to go the Rust way, and use ownership types to ensure that iteration and mutation don't happen at the same time.
@Haoyi LI:
I'm still not sure what is the root cause why we would want to remove operations on mutable collections (and from the sentence "Buffers append/remove is what you generally care about, but they're lost in the huge sea of immutable methods you basically never want", it's not clear to me which ones you want to see removed).
Could you clarify?
Isn't that what the XXXBuilder classes like VectorBuilder are for? If you want a builder you use a builder collection, not a mutable collection. Unless we're getting rid of builders?
There is more to mutable collections than just the builder pattern in which elements are monotonically added.
Maps and sets (although not in the strawman proposal) support remove and conditional removes.
Haoyi Li
> I'm still not sure what is the root cause why we would want to remove operations on mutable collections (and from the sentence "Buffers append/remove is what you generally care about, but they're lost in the huge sea of immutable methods you basically never want", it's not clear to me which ones you want to see removed).
Aleksandar Prokopec
On Monday, 5 October 2015 23:26:13 UTC+2, Haoyi Li wrote:
> To play the devils advocate with what Martin said: we don't need to copy a mutable collection to make it immutable, we could just freeze it, i.e. disallow further updates.Re-sending what I sent to martin to the list, I must've forgotten to reply-allWould an explicit wrapper work in that case? e.g.def freeze(myArray: Array[T]): IndexedSeq[T]This "want to turn mutable collection into immutable one with zero copy" use case happens, but I'd guess happens a lot less than the use case of "want to use mutable collection as mutable collection and not accidentally call expensive immutable methods", so we can optimize the common case to make it impossible to accidentally call immutable methods, while providing a short one-function helper to make the other use case convenient too
Agreed about the two use-cases.
> Another possibility would be to go the Rust way, and use ownership types to ensure that iteration and mutation don't happen at the same time.I'd love if this was the case but I doubt it will happen in next 2 years =PCould you clarify?
> I'm still not sure what is the root cause why we would want to remove operations on mutable collections (and from the sentence "Buffers append/remove is what you generally care about, but they're lost in the huge sea of immutable methods you basically never want", it's not clear to me which ones you want to see removed).Basically everything that returns a new collection should not be part of the mutable API by default.
I like the part here where you say "by default". :)
If we consider bulk operations (i.e. map, filter, flatMap, sorted, ...) and other copying operations (:+, +:, and similar smiley methods) dangerous because they incur serious performance penalties, we could disallow them on mutable collections.
But, I'm sure that some people have valid use cases where they find these methods useful, and they should be able to enable them via import of a decorator or a typeclass.
This design seems to go hand-in-hand with what implicit decorators currently in the strawman proposal.
(as a side note, I find it funny how we go at great lengths to prevent our users from shooting themselves in the foot)
The whole point of using mutable collections is to mutate them in place and not re-allocate all the time. If I wanted to re-allocate all over the place I'd just use an immutable collection. The number of times I've actually wanted to call map, filter, etc. on a mutable collection in the last 3 years has been zero.
Still, people sometimes return e.g. ArrayBuffers from interface methods that declare that they return a Seq - and ArrayBuffers are one of the more efficient sequence implementations.
And once you have an immutable view (Seq) of a mutable collection (ArrayBuffer), it's easy to do that mistake.
Note that the current strawman says ArrayBuffer extends Seq.
Should a conversion from a mutable collection to a sequence also be enabled through an explicitly imported implicit conversion?
As an exercise, compare:Compare mutable.ArrayBuffer:with java.util.ArrayList:Get a stopwatch and answer the following questions:- How do I remove every element satisfying some predicate from mutable.ArrayBuffer, in place?- How do I remove every element satisfying some predicate from java.util.ArrayList, in place?- How do sort the mutable.ArrayBuffer by some predicate, in place?-How do sort the java.util.ArrayList by some predicate, in place?Time how long it takes you to answer each question (how to do it, or if it cannot be done) by browsing the list of methods.For me it takes >10x as long to answer each one for mutable.ArrayBuffer, due to the huge pile of "useless" copying methods.SPOILER BELOWIt turns out you can't perform either operation on a mutable.ArrayBuffer, which is pretty surprising given these are very common operations to want to do on any mutable collection.
This could be addressed with another family of decorator methods that are specific to mutable collections.
Is that what you would propose?
Haoyi Li
Aleksandar Prokopec
> But, I'm sure that some people have valid use cases where they find these methods useful,Let's skip the hypotheticals and ask: who are these people and what are their use cases? In theory everything is useful to someone somewhere maybe. In the end there's always an empirical judgement of how many people you think will want this functionality. "Non-zero, maybe" isn't satisfactory =PCould we kick of community builds with instrumentation via Abide to see what the actual usage numbers on the various APIs are? That would help give us something concrete to talk about, and perhaps suggest alternatives for the use cases we do find.
> as a side note, I find it funny how we go at great lengths to prevent our users from shooting themselves in the footWhile Scala's immutable collections are nice, Scala's mutable collections API is one of the most easily-foot-shooting APIs I know of. 100s of methods you don't want, barely any methods you want, missing several methods you *do* want.Python, Java, and many other languages provide more ergonomic mutable collections. Let's not be too proud of ourselves =D
Python, for example, also has mutable lists and dictionaries, and for-comprehensions that copy those collections.
> Should a conversion from a mutable collection to a sequence also be enabled through an explicitly imported implicit conversion?What's wrong with just an explicit conversion?def freeze(input: mutable.Seq[T]): immutable.Seq[T]Not everything needs to be an implicit.

Simon Ochsenreither
This feels like a great recipe for a Python 2/Python3 disaster: Too many small, subtle changes which will bite people with not enough associated benefit to encourage strong adoption.
If we really want to do something, I would probably prefer working on Josh's views, despite not being enamored about it: At least it's made clear that they are provisional band-aids.
But the scope just means that we will have the same discussion a few years down the road, and I prefer breaking people's code once, not twice.
martin odersky
- Martin
Haoyi Li
--
Aleksandar Prokopec
On Tuesday, 6 October 2015 00:34:14 UTC+2, Haoyi Li wrote:
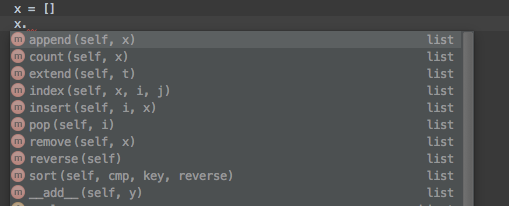
> Why do you say they are more ergonomic? In which ways?Here's what you get when you want the methods on a python list:A small number of operations, basically all of which are useful to everyone who wants a mutable list. And all can be understood by anyone who has ever programmed before, without reading any docs!
That's a bit unfair comparison, because it does not include Python's built-in functions, many of which are list-related:
https://docs.python.org/2/library/functions.html
That adds more functions to the table.
Plus, there's Python's itertools, which has more list-related methods:
https://docs.python.org/2/library/itertools.html
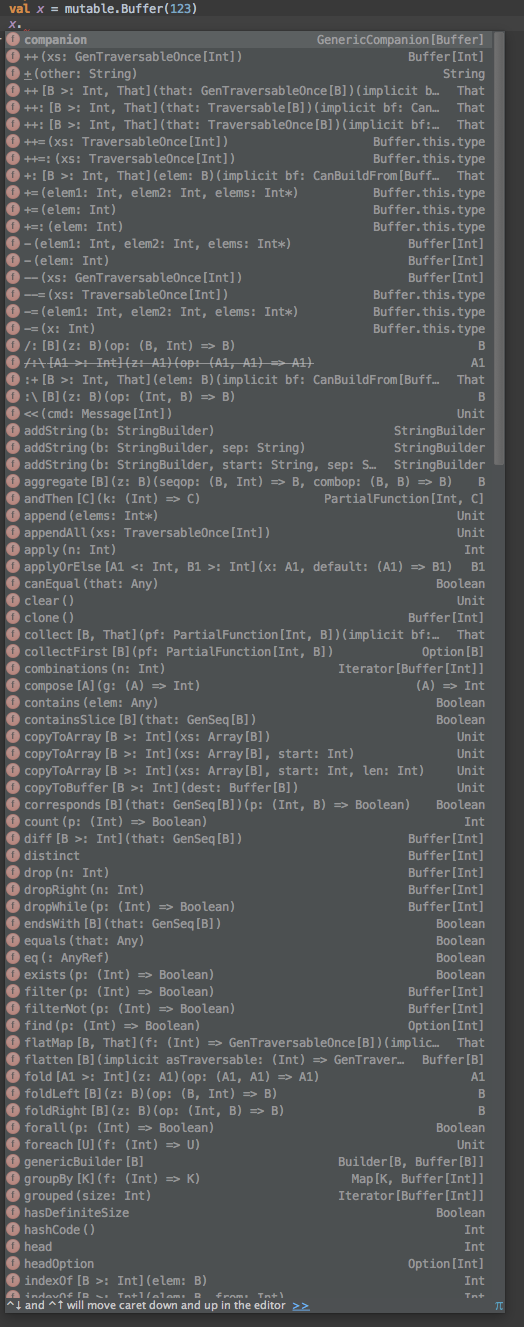
Here's what you get when you ask for the methods on a scala mutable buffer:How many of these are methods that someone can call on a mutable buffer without horrendous performance implications? Less than half. In fact, methods which look very similar (++ and ++=) have totally different semantics and performance implications.
A couple of remarks here:
1. There are many use-cases where one deals with small collections, comprised of several elements, where performance implications are less important.
2. There are use-cases where copying is less expensive than the actual useful work performed on the collection.
3. Non-strict map, flatMap, filter, ... could reduce or eliminate performance overhead due to copying.
4. The optimizer could fuse many of these operations, or eliminate copying, in particular those where a copying bulk operations is followed by a fold.
As an exercise, can you give me which methods on that list will result in O(n) copying of the whole collection, which is basically what you never want?
I'm not excluding that you might be right about "basically what you never want", but as you pointed out yourself - we would need numbers to make definite claims about this.
Simon Ochsenreither
- address the issue that everyone rolls their own "collection-like" API, because the API makes unnecessary prescriptions about how things need to work
- support efficient execution by default, leading to a slow-but-convenient API (which would have already fallen into disuse if views ever worked reliably), which repeats all the mistakes we already made
- reduce the duplication within the API by keeping views as an inconvenient, more verbose API (which adds roughly as much boilerplate as Java Streams, so why not just give up and use Java Streams instead?)
- understand that assigning labels about forcing/non-forcing is not meaningful for most use-cases and produces unnecessary complexity
- separate between the composition of operations and its input, meaning we are ignoring all the lessons learned in Slick
- offer any thought regarding macro-based implementations, meaning we are discarding the opportunity to improve on LINQ's crude approach
I'm not sure if it makes sense trying to salvage the request for strawmen, but I think
- removing requirement (6), demanding instead that there is only a single API that works, instead of having an inefficient, convenient and an efficient, but inconvenient one
- clarifying that (1) doesn't mean that every operation has to start executing implicitly
- adding Table[T] (as a representation of a database table as an input source) and some RDD-like type (as a representation of a distributed data source)
Otherwise it feels we are just swapping some well-known disadvantages against other well-known disadvantages.
Simon Ochsenreither
wouldn't this issue just disappear in a design where those general operations returned some kind of View[T]/Stream[T]/..., while the mutable, in-place operations returned the data-structure itself?
I didn't consider your requirements to be that important (it's certainly an annoying issue), but I think the approach I'm imagining would deal very well with your pain points.
Bye,
Simon

Matthew de Detrich

Rex Kerr
}
}
--
Martin Odersky
EPFL
Simon Ochsenreither
(Although I believe the things I suggested could count as game-changers, it's clear that the technology to pull it off is not there yet.)
martin odersky
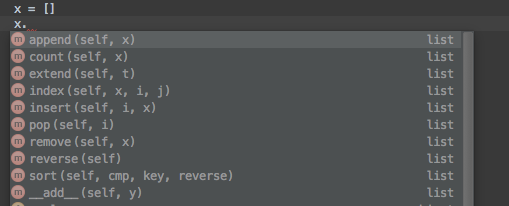
On Tuesday, 6 October 2015 00:34:14 UTC+2, Haoyi Li wrote:> Why do you say they are more ergonomic? In which ways?Here's what you get when you want the methods on a python list:A small number of operations, basically all of which are useful to everyone who wants a mutable list. And all can be understood by anyone who has ever programmed before, without reading any docs!
That's a bit unfair comparison, because it does not include Python's built-in functions, many of which are list-related:
https://docs.python.org/2/library/functions.html
That adds more functions to the table.
Plus, there's Python's itertools, which has more list-related methods:
https://docs.python.org/2/library/itertools.html
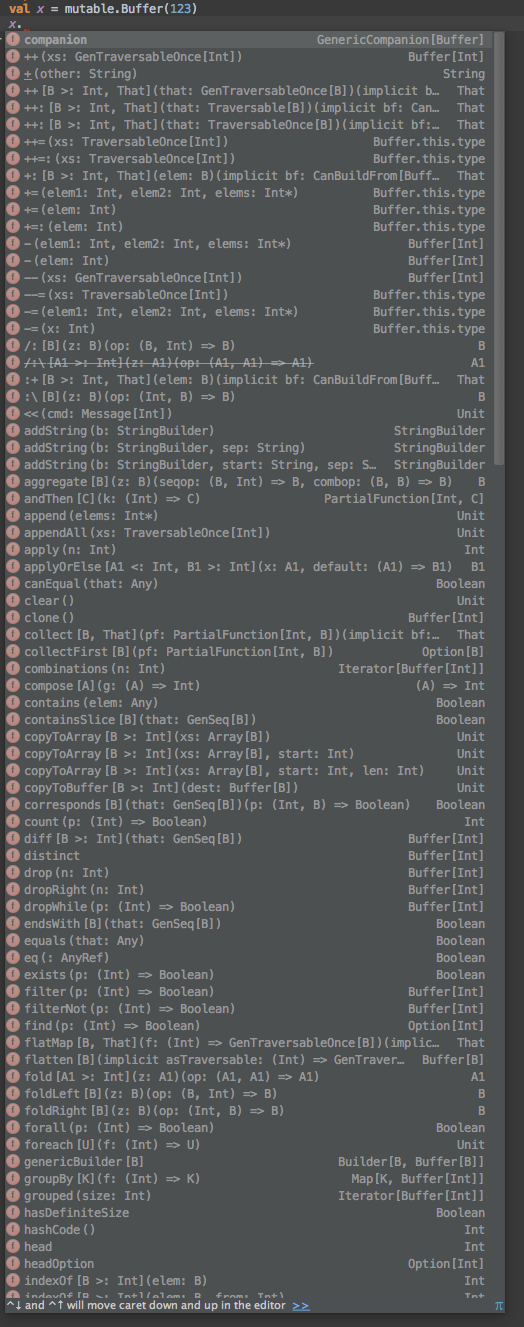
Here's what you get when you ask for the methods on a scala mutable buffer:How many of these are methods that someone can call on a mutable buffer without horrendous performance implications? Less than half. In fact, methods which look very similar (++ and ++=) have totally different semantics and performance implications.
EPFL
Aleksandar Prokopec
People commonly use a primitive type parameter and silently incur the cost of boxing:
def addNums(b: new ArrayBuffer[Int]) {
b += 1
b += 2
b += 3
}
Since we applied specialization to Function0,1,2,..., I see no reason why collections such as array buffers would not specialize for a specific set of primitive types.
The common problem here is instantiating arrays, which typical collections (buffers, hash maps, hash tries, queues, heaps) do a lot and which specialization doesn't support in the generic context. The way some rogue collection frameworks solved this in the past is by introducing a custom ClassTag-gy type-class that knows how to instantiate arrays.
martin odersky
> I think we shouldn't do a relatively minor redesign now. Instead, I think
> we should basically stay the course, which is to continue to clean up
> especially problematic cases that trip people up. We've deprecated many of
> the weirdest and least-used collections, and can keep doing so to make the
> library cleaner and more consistent.
>
> The reason I suggest to stay the course is that I don't think we can do a
> major redesign at this point. Although there have been some advances in
> structuring collections operations, for the most part we don't yet have the
> tools to do dramatically better without also making some things dramatically
> worse. There's no game-changer being proposed even in the most radical
> redesigns.
- We cannot get enough improvement while staying within requirement 1.
or:
- We do not yet know enough to do a big step forward at the present time.
If it's the first, then I would argue that collections will _never_ be
rewritten. Changing typical use of collections amounts to doing a new
language. Collections are simply too intertwined with the language
proper. Think about it: If you fundamentally changed collection
operations, how many books and other teaching materials about Scala
would survive? The Haskell people are just living through a minor
version of that and it's not pretty.
If it's the second (i.e. we need more time), then there's still
nothing to stop us from starting the discussion now. In fact, if this
should arrive in 2.13, we have about 2 years to do it, or if we miss
that release, almost 4 years. That looks like plenty of time to me,
*if we start the experiments now*. That's what I was trying to achieve
with the strawman initiative.
I completely agree that we have to co-develop strawman proposals with
advances in specialization and inlinings. In fact that gives us a
chance to advance these areas with much more confidence than if there
were no collection prototypes to guide and benchmark the developments
in these areas.
Cheers
- Martin
Martin Odersky
EPFL
martin odersky
controversies:
https://twitter.com/headinthebox/status/650965940427997184
Haskell did a relatively minor rearrangement of their type class
hierarchy, but it does affect a lot of user code.
The answer to have two collection libraries, a legacy one and a modern
one is also problematic:
- Scala the language knows about collections. Examples: varargs map
to Seqs. Is that legacy Seqs or modern Seqs? Which "cons" do you get
when you pattern match with "::". And so on.
- We would increase rather than decrease bloat.
- We would confuse users even more.
So, nothing is easy, but some things are doable.
- Martin
Martin Odersky
EPFL
Haoyi Li
martin odersky
EPFL

Rüdiger Klaehn
continue cleaning up the existing collections and do a major redesign
as a clean break in a different namespace. Otherwise we will have to
repeat almost all of the design decisions for backwards compatibility,
which kind of defeats the purpose of a redesign.
For the cleanup of the existing collections:
1. can we please somehow deal with the fact that filterKeys and
mapValues returns a view? Just adding mapValuesNow to make it clear
that mapValues is lazy might be the best we can do given backwards
compatibility. But something needs to be done.
https://issues.scala-lang.org/browse/SI-4776
2. What about just ripping out parallel collections and all the
complexity they produce? I have not seen many usages of them in the
wild. Maybe it would be possible to add .par as an enhancement method,
or use java streams. But the complexity added by having parallel
collections intermingled with normal collections is staggering.
For the major redesign in a different namespace (the first could also
be retrofitted into existing collections):
1. I think we should make update methods more usable/composable. E.g.,
in an IndexedSeq[T], the most fundamental update method should not
take a value but a transform function. The normal update can be
implemented in terms of this:
def updateWith(i: Int, f: T => T): Self
def update(index: Int, value: T): Self = updateWith(index, _ => value)
The same goes for maps, obviously.
def updateWith(key: K, f: Opt[V] => Opt[V]): Self
def update(key: K, value: V): Self = updateWith(key, _ => Opt(value))
2. The notion of cooperative equality should not be mixed with real
equality. I can see that it is useful to check HashSet(1,2,3) for
similarity with SortedSet(1,2,3). But this should be done with a
different operator. I have been experimenting a bit with this in
spire. See this presentation from scala.world: http://t.co/rnghan35kJ
Haoyi Li
Aleksandar Prokopec
On October 6, 2015 10:08:02 AM GMT+02:00, "Rüdiger Klaehn" <rkl...@gmail.com> wrote:
>I have to agree with Rex and Viktor. I think it would be best to
>continue cleaning up the existing collections and do a major redesign
>as a clean break in a different namespace. Otherwise we will have to
>repeat almost all of the design decisions for backwards compatibility,
>which kind of defeats the purpose of a redesign.
>
>For the cleanup of the existing collections:
>
>1. can we please somehow deal with the fact that filterKeys and
>mapValues returns a view? Just adding mapValuesNow to make it clear
>that mapValues is lazy might be the best we can do given backwards
>compatibility. But something needs to be done.
>https://issues.scala-lang.org/browse/SI-4776
>
>2. What about just ripping out parallel collections and all the
>complexity they produce? I have not seen many usages of them in the
>wild. Maybe it would be possible to add .par as an enhancement method,
>or use java streams. But the complexity added by having parallel
>collections intermingled with normal collections is staggering.
I think we have the solution there - parallel collections can be a thin wrapper on top of collections, the way this was done in ScalaBlitz (scala-blitz.github.io). There, parallel operations are just decorators on top of std lib collections, with parallelism controlled by implicit Schedulers. The implementation is non-intrusive, and doesn't introduce extra complexity into the base collection API.
Sent from my Android device with K-9 Mail. Please excuse my brevity.

Dmitry Petrashko
Even more, I believe that `map` `filter` and `reduce` and most operations actually should be agnostic from the source of elements that they get.
But I take your point that there are some operations missing on mutable collections.
Gladly, now we have decorators and we can introduce different operations for mutable and immutable collections,
the operations that you suggest can be introduced in this very way.
@odersky. filterReplace is less IDE-friendly than inPlaceFilter due to autocomplete
-Dmitry

Francois
I have recently opened an issue inviting strawman designs for new collection architectures: https://github.com/lampepfl/dotty/issues/818 The issue lists some requirements for a design to be acceptable. Since then there has been a discussion about several points that are all outside the requirements outlined in #818. I think it's worthwhile to discuss these, but do not think #818 is the proper place to do it. That's why I would like to continue the discussion here. - Martin
And I don't care if it breaks and if I have to sed 10000s of line of code, if the goal is clear and substentially better.
To be even clearer, now with almost a decade of scala behind me, I much prefer explicit behaviour (even if they are backed by hard concept) that I can control, explain to junior, and reflect upon than a big collection with anything and everything on it, and 1000 little corner cases to explain to other (the first one beeing "seriously, myCol.filter(...).map(...).filter(...).map(...).flatMap(...) is not optimized ???").
One last thing : Scala in 2015 does not have to prove the same thing as the Scala of 2005, quite the opposite. Scala is known and looked upon for its design choices. Moreover immutability is now broadly accepted to be the best choice most of the time, in most language, even in Java, (even in PHP!).
So there is nothing weird in having a purelly immutable, optimized collection by defaults. I would thing that it's likelly the contrary.
Not sure it helps, and sorry if it is not the case.
-- Francois ARMAND http://rudder-project.org http://www.normation.com
Francois
Cheers,

William Harvey
I gave a talk on his redesigned collections API a few months ago, and threw together some (very crude) slides here. I encourage everyone to take a look.
Cheers,
William

Christian Helmbold
:+, :\, ++:, or &~
are hard to read and even harder to google. Such method names encourage
developers to create their own scary symbolic methods what in turn
hurts the reputations of Scala and leads to bad code.Christian
Simon Ochsenreither
- We cannot get enough improvement while staying within requirement (1).
Maybe you could clarify requirement (1): If I have List(1,2,3).map(...), does requirement (1) mean that:
- The result needs to be a List again
- The evaluation has to be started immediately
Or does it just mean that existing code looking like that should keep compiling/doing the same with minimal interaction?
If it is the former case, I think keeping the collection library at the current level of life-support is the right decision.
We then should make it clear that the API is frozen, and people shouldn't expect further improvements.
This will encourage third-parties to innovate where we don't want to.
If it's the second (i.e. we need more time), then there's still
nothing to stop us from starting the discussion now. In fact, if this
should arrive in 2.13, we have about 2 years to do it, or if we miss
that release, almost 4 years. That looks like plenty of time to me,
*if we start the experiments now*. That's what I was trying to achieve
with the strawman initiative.
While this is true, given the restrictions I don't see that there would be enough worthwhile improvements (even four years down the road) which would excuse even minor breakages in compatibility.
martin odersky
<simon.och...@gmail.com> wrote:
>> - We cannot get enough improvement while staying within requirement (1).
>
>
> Maybe you could clarify requirement (1): If I have List(1,2,3).map(...),
> does requirement (1) mean that:
>
> The result needs to be a List again
> The evaluation has to be started immediately
>
> Or does it just mean that existing code looking like that should keep
> compiling/doing the same with minimal interaction?
>
>
> If it is the former case, I think keeping the collection library at the
> current level of life-support is the right decision.
> We then should make it clear that the API is frozen, and people shouldn't
> expect further improvements.
> This will encourage third-parties to innovate where we don't want to.
>
>> If it's the second (i.e. we need more time), then there's still
>> nothing to stop us from starting the discussion now. In fact, if this
>> should arrive in 2.13, we have about 2 years to do it, or if we miss
>> that release, almost 4 years. That looks like plenty of time to me,
>> *if we start the experiments now*. That's what I was trying to achieve
>> with the strawman initiative.
>
>
> While this is true, given the restrictions I don't see that there would be
> enough worthwhile improvements (even four years down the road) which would
> excuse even minor breakages in compatibility.
>
first. It could be that the conclusion in the end is, no, it's not
worth it. But I think we should try and evaluate the evidence before
reaching that conclusion.
- Martin
Simon Ochsenreither
Yes to both.
Then let's just give up.
That's a very pessimistic sentiment! Let's see the strawman proposals
first. It could be that the conclusion in the end is, no, it's not
worth it. But I think we should try and evaluate the evidence before
reaching that conclusion.
The way the request for proposals is worded predetermines the result: It will be a race to the bottom looking for the least useless change possible, while more ambitious approaches are excluded from the get go. Then all concerns will be discarded with the notion of "well, that was the best design we received, and we _have_ to do something, right, so let's just cram this into the standard library!", because no one who believes a more ambitious approach is necessary will bother to sit down and flesh out his proposal.
I think no one assumes that more breaking changes doesn't diminish the chances for a proposal to be adopted, but even if not adopted, they serve as an inspiration for other designs "what X does here is great, can I adopt this approach in my design Y without the breakage caused in X?".
If there were substantially better designs given the constraints, I think we would have already seen PRs in the last few years. I think there are plenty of people out there who thought long and hard about this issues: the available design space is well-explored in terms of "problems we won't be able to solve with these restrictions" by now. I believe that adding another few months/years of consideration won't change that, it will just waste people's time. Time people could use to come up with their own "not-officialy-sanctioned" libraries.
Expecting to see different results given the same restrictions and fixed inputs? ... I think it's unlikely that this will work.
martin odersky
I get it that you are a skeptic, but your tone could be a lot less
dismissive. It's not fun for me to discuss on this level, so I will
stop doing it.
I encourage you nevertheless to come up with a concrete proposal
whether it conforms to the requirements or not. Proposals are good,
overly negative attitudes aren't.
- Martin
>> That's a very pessimistic sentiment! Let's see the strawman proposals
>> first. It could be that the conclusion in the end is, no, it's not
>> worth it. But I think we should try and evaluate the evidence before
>> reaching that conclusion.
>
>
> The way the request for proposals is worded predetermines the result: It
> will be a race to the bottom looking for the least useless change possible,
> while more ambitious approaches are excluded from the get go.
> design we received, and we _have_ to do something, right, so let's just cram
> this into the standard library!", because no one who believes a more
> ambitious approach is necessary will bother to sit down and flesh out his
> proposal.
>
> I think no one assumes that more breaking changes doesn't diminish the
> chances for a proposal to be adopted, but even if not adopted, they serve as
> an inspiration for other designs "what X does here is great, can I adopt
> this approach in my design Y without the breakage caused in X?".
>
> If there were substantially better designs given the constraints, I think we
> would have already seen PRs in the last few years. I think there are plenty
> of people out there who thought long and hard about this issues: the
> available design space is well-explored in terms of "problems we won't be
> able to solve with these restrictions" by now. I believe that adding another
> few months/years of consideration won't change that, it will just waste
> people's time. Time people could use to come up with their own
> "not-officialy-sanctioned" libraries.
>
> Expecting to see different results given the same restrictions and fixed
> inputs? ... I think it's unlikely that this will work.
>

virtualeyes
Which may in fact be the best way forward, practically speaking, but doesn't jibe with Dotty and the scala compiler overhaul (i.e. new compiler, same-ish collections).
Rex Kerr
Rüdiger Klaehn
Nobody stops us from putting an incompatible proposal on github. And
in fact there are quite a few. I am very happy that the topic is being
discussed.
Here is a gist of a more typeclass-based collection library (which is
definitely non-compatible):
https://gist.github.com/rklaehn/0f9271b2fc6ceeae699a
The basic idea is to use imports to specify which methods you want on
your collections.
import syntax._
import ops.`O(1)`._
Array(1,2,3).xSize
// List(1,2,3).xSize // does not compile because it is O(N)
// Stream(1,2,3).xSize // does not compile because it is possibly
non-terminating
import ops.`O(N)`._
List(1,2,3).xSize // does compile due to the O(n) import
// Stream(1,2,3).xSize // does not compile because possibly
non-terminating methods are not included in O(N)
import ops.NonTerminating._
Stream(1,2,3).xSize // does compile due to the NonTerminating import
import ops.All._
// like scala collections

Seth Tisue
"ambitious" proposals are ruled out by definition
martin odersky
proposal to the #818 issue:
https://github.com/lampepfl/dotty/issues/818
I believe this shows that one *can* significantly improve collections
while staying in the same usage patterns. I am looking forward to see
other alternatives, both within and outside of the requirements
outlined in #818.
show skeptics that one can
-

Naftoli Gugenheim
But, what about ResizableArray. It looks like an array, so why deny it
the same operations?
There's the other valid use case where you build up a mutable
collection and once it is fully constructed want to use it as if it
was immutable. Copying to make it immutable is not permitted for
performance reasons. How would be support that?
- Martin
On Mon, Oct 5, 2015 at 10:30 PM, Haoyi Li <haoy...@gmail.com> wrote:
>> So if we do not want to go there, where to draw the line?
>
> I say we draw the line between Arrays and everything else. They're already
> weird special things (reified generics, rubbish toString, rubbish equality,
> ...), so IMHO it's perfectly fine to have them be weird-special mutable
> objects with immutable operations. They're not even really collections in
> the first place!
>
> After that, immutable.* operations on mutable.T forall T in {Seq, Set, Map,
> Buffer, Queue, PriorityQueue, ...} should be all killed.
>
> On Mon, Oct 5, 2015 at 1:23 PM, martin odersky <martin....@epfl.ch>
> wrote:
>>
>> Here is a first response to
>>
>> >> We gloss over the mutabile/immutable distinction
>>
>> > We probably want mutable collections to not have the same API as the
>> > immutable ones. One large problem with the current mutable collections is
>> > that by inheriting all the immutable methods, it's
>> neigh impossible to figure out where the "useful" mutable methods are.
>> e.g. Buffers append/remove is what you generally care about, but
>> they're lost in the huge sea of immutable methods you basically never
>> want. The same applies to mutable.Set, mutable.Queue, etc.
>>
>> > By that logic, ArrayBuffer probably shouldn't be a collection, and
>> > perhaps making it convertible to one through .view or .iterator is enough?
>>
>> If we take this idea to its logical conclusion, we should abandon
>> `map` and friends on arrays because they are also mutable. This would
>> render obsolete virtually every Scala book in existence. Besides, it
>> would be counter-productive. Map and friends are perfectly good
>> methods on arrays.
>> So if we do not want to go there, where to draw the line?
>>
>> - Martin
>>
>>
>>
>>
>> On Mon, Oct 5, 2015 at 10:18 PM, martin odersky <martin....@epfl.ch>
>> wrote:
>> > I have recently opened an issue inviting strawman designs for new
>> > collection architectures:
>> >
>> > https://github.com/lampepfl/dotty/issues/818
>> >
>> > The issue lists some requirements for a design to be acceptable. Since
>> > then there has been a discussion about several points that are all
>> > outside the requirements outlined in #818. I think it's worthwhile to
>> > discuss these, but do not think #818 is the proper place to do it.
>> > That's why I would like to continue the discussion here.
>> >
>> > - Martin
>> >
>> >
>> >
>> > --
>> > Martin Odersky
>> > EPFL
>>
>>
>>
>> --
>> Martin Odersky
>> EPFL
Naftoli Gugenheim
(as a side note, I find it funny how we go at great lengths to prevent our users from shooting themselves in the foot)
Naftoli Gugenheim
I wanted to bring up specialization as well - I think that it will be relevant even with the AST fusion.
People commonly use a primitive type parameter and silently incur the cost of boxing:
def addNums(b: new ArrayBuffer[Int]) {
b += 1
b += 2
b += 3
}
Since we applied specialization to Function0,1,2,..., I see no reason why collections such as array buffers would not specialize for a specific set of primitive types.
The common problem here is instantiating arrays, which typical collections (buffers, hash maps, hash tries, queues, heaps) do a lot and which specialization doesn't support in the generic context. The way some rogue collection frameworks solved this in the past is by introducing a custom ClassTag-gy type-class that knows how to instantiate arrays.

Russ P.
On Tuesday, October 6, 2015 at 1:08:05 AM UTC-7, rklaehn wrote:
I have to agree with Rex and Viktor. I think it would be best to
continue cleaning up the existing collections and do a major redesign
as a clean break in a different namespace. Otherwise we will have to
repeat almost all of the design decisions for backwards compatibility,
which kind of defeats the purpose of a redesign.
For the cleanup of the existing collections:
1. can we please somehow deal with the fact that filterKeys and
mapValues returns a view? Just adding mapValuesNow to make it clear
that mapValues is lazy might be the best we can do given backwards
compatibility. But something needs to be done.
https://issues.scala-lang.org/browse/SI-4776
2. What about just ripping out parallel collections and all the
complexity they produce? I have not seen many usages of them in the
wild. Maybe it would be possible to add .par as an enhancement method,
or use java streams. But the complexity added by having parallel
collections intermingled with normal collections is staggering.
Naftoli Gugenheim
On Tue, Oct 6, 2015 at 9:48 AM, Haoyi Li <haoy...@gmail.com> wrote:For example, I want:- in-place filter,- in-place sort,- in-place distinct,- in-place drop,- in-place dropWhile,- in-place takeYes, these would be good to have. But maybe under different names?Otherwise we get into the non-sensical situation that filter copies on arrays (which it has to, there's no way around it!) yet destroys on ResizableArrays and ArrayBuffers. But we could use a systematic naming scheme for these. E.g.filterReplace, sortReplace, ...orfilter_!, sort_!, ...- Martin
Naftoli Gugenheim
I actually like that most operations on scala collections work the same between mutable and immutable collections.
Naftoli Gugenheim
And I don't care if it breaks and if I have to sed 10000s of line of code, if the goal is clear and substentially better.
Naftoli Gugenheim
2. What about just ripping out parallel collections and all the
complexity they produce? I have not seen many usages of them in the
wild. Maybe it would be possible to add .par as an enhancement method,
or use java streams. But the complexity added by having parallel
collections intermingled with normal collections is staggering.
Rip out parallel collections? Are you serious? That would squander one of the main advantages of functional programming in Scala!I just started using parallel collections, and they couldn't be simpler to use. How hard is it to add ".par"? Oh, yes, I will concede that first eliminating all the vars can be a non-trivial task, but it is usually not that bad once you get the hang of it.I am also finding that the speedup I get with parallel collections is not as much as I had hoped for, but that should change when I get a CPU with more cores.
virtualeyes
However, let's not forget the impact of current scala and the standard library on, for example, mobile devices (i.e. where the trend is on a serious uptick in terms of users). With 2.12 Java 8 will be required, which means we're all-in on ScalaJS as Google/Android will always lag behind in terms of supported version(s) of Java.
Anyone who has taken ScalaJS for a spin will quickly see that the generated source file *after* Closure compiler optimization is quite large, in the 160KB range off the bat (i.e. that's "hello world"). Much of this weight is due to ScalaJS mirroring Scala and the standard library, which as everyone knows is not by any means lightweight. Combine this with the fact that ScalaJS performs whole program optimization, we have the problem of gaining adoption in the overall JS ecosystem -- who will want to pay the weight "tax" by depending on large ScalaJS libraries that can't be shared modularly (i.e. we can't break out the ScalaJS runtime like say, jQuery; each ScalaJS application brings the *entire* scala collections train with it).
Compare that with OCaml and js_of_ocaml, the generated js source files are *tiny*. Sure, ML + tiny standard lib helps immensely -- the point is moving toward a smaller core...somehow, 818 will surely help in this regard, just not sure how much.
virtualeyes
Saying that, I'm all for anything that reduces the standard library footprint; if removing parallel collections aids this effort, +1
Naftoli Gugenheim
That reminded me of the work by Paul Phillips on something similar, and that: https://github.com/paulp/psp-std/blob/master/doc/views.md seems to be desirable goals of a redesigned scala collection.
Cheers,
-- Francois ARMAND http://rudder-project.org http://www.normation.com
Naftoli Gugenheim
Simon,
I get it that you are a skeptic, but your tone could be a lot less
dismissive. It's not fun for me to discuss on this level, so I will
stop doing it.
I encourage you nevertheless to come up with a concrete proposal
whether it conforms to the requirements or not. Proposals are good,
overly negative attitudes aren't.
- Martin
>> That's a very pessimistic sentiment! Let's see the strawman proposals
>> first. It could be that the conclusion in the end is, no, it's not
>> worth it. But I think we should try and evaluate the evidence before
>> reaching that conclusion.
>
>
> The way the request for proposals is worded predetermines the result: It
> will be a race to the bottom looking for the least useless change possible,
> while more ambitious approaches are excluded from the get go.
Sorry, this is ridicuThen all
Russ Paielli
Can we try to make scala a bit more democratic please?
martin odersky
framework for such discussion with the invitation for a strawman
proposal. Without it, it's much harder to evaluate and proposals
constructively and to compare alternatives.
What I was objecting to was mails from Simon and others who said that
we should not even have the discussion, because everything is futile
anyway. And to the tone of those messages, because, frankly, I am
doing this because I want to, not because somebody asked me to. If I
don't have fun anymore discussing because the responses are so
negative and accusing in a personal way I'm done here.
As I wrote, the requirements I listed were not meant to exclude
anybody from proposing things but to reassure the world at large that
the Scala they know will not be wiped out by what we plan. If people
want to explore something more radical, it would be good to see that
also in the framework of the strawman. Then we can see what breaking
changes are proposed and what other advantages we could hope to gain.
What the requirements provide is an idea what is necessary so that
something can replace the collections in the standard library. But one
can also look at collections outside stdlib, which can be radically
different.
It would in particular be great to see:
- the current status with CanBuildFrom augmented by transducer-like views
in the way Josh proposed them,
- a version of Bill Venners's latest thinking (thanks, Bill, for
volunteering one!)
- a version of psp collections,
- variants of my initial strawman. Dmitry is going to propose one
where most operations migrate from iterators to views.
- and, hopefully, it will not stop there and we will see others as well.
Also needed: More tests. The test I wrote is still very rudimentary.
It would be great to see contributions from the people on this list. I
think the best way to contribute is via pull requests to
lampepfl/dotty on github.
Thanks
- Martin
martin odersky
>> > will be a race to the bottom looking for the least useless change
>> > possible,
>> > while more ambitious approaches are excluded from the get go.
>>
>> Sorry, this is ridicuThen all
>
>
> I don't know what you meant to write, but if you look on twitter, there are
> some very smart people, who we have to thank for for a lot of where scala is
> today, that are not chiming in because they don't think there's a point.
>
bottom", as well as the suggestion that the wording of the request was
done in order to predetermine the result. This in my mind was a
ridiculous accusation, because it did not correspond at all to how I
see things from my side. I then thought better of it and realized that
maybe I had not explained enough what the role of the requirements
was. So I tried to explain that better in my follow-up mails.
Twitter discussions: Miles and others have stated explicitly that they
do not want a standard library. So of course they will not get
involved in improving it. I think that's a pity, it would be great to
see wider discussion about the ideas and design trade-offs.
- Martin
martin odersky
> But we could use a systematic naming scheme for these.
Sounds fine; I'm sure we'll be able to come up with a reasonable name if we decided this was something we wanted to do =)I guess the last thing I have to contribute to this theme (mutable vs immutable collections) is the following:Mutable collections are used very differently from immutable ones. Most languages make the mistake of freezing mutable collections and calling them "immutable" while still leaving all the operations the same. From a Scala background we think it's ridiculous, because we know how nice to use immutable collections with a proper immutable API, v.s. something like Guava's ImmutableList.In that case end up with immutable collections which are the worst of both worlds: expensive to update (no structural sharing) and clunky to use, with random methods that blow up with exceptions (which nobody wants), but people still use them because immutability is sometimes that valuable.On the other hand, Scala has made the exact same mistake: we have taken our immutable API, chucked it on a set of mutable collections, and called it a day. Nevermind that the performance characteristics are all wrong, the use-cases are different, the styles of use are different.As a result, we have a mutable collections that are the worst of both worlds: expensive to update (because all the operators copy!) or clunky to use (because you're back to while-loops), with random methods that'll blow-up in execution time (which nobody wants), but people sometimes use them because perf is sometimes that valuableIn reality, using mutable collections is a style in-of-itself, and not a subset-or-super-of the style of using immutable collections. For example.- With mutable collections, get-and-remove is one of the most common things to do. In Javascript it's called .shift, in Python .pop. In Scala it's missing entirely.- With mutable collections, you do things in-place. You sort it in-place, you filter it in-place, you do everything in place.- Even if you didn't care about perf and wanted to use the existing collections filter/sort/etc. operations on a val b: mutable.Buffer, you couldn't! You'd need a var b: mutable.Buffer, which is twice as much mutability as anyone really needs and probably will get you yelled at during code review.- Since we already have immutable collections satisfying the convenient-if-maybe-expensive use case, the mutable collections only really satisfy the remaining must-be-relatively-performant use case.- Thus, while for "convenient-if-maybe-expensive" you usually don't care too much about the implementation or how long it takes, with mutable collections you care exactly about the implementation of every operation and its performance characteristics- Following from that, maybe it's OK to have hundreds (!!!) of operations on dozens of immutable collections, since even if we don't know how they work we don't care. With mutable collections, though, you want the opposite: a small set of operations on a small set of collections, so that you can fully understand how every operation works, and how much every operation costs, on the mutable collection that's in front of you.With mutable collections, you don't want a sprawl of methods for every convenience, abstracted away for maximum re-use. Maybe that's the goal for the immutable collections, and that's fine, but the mutable collections are their own world. Scala's current mutable collections are about as elegant as Guava's immutable collections are in Java: clunky, expensive, and missing tons of useful functionality while still exposing methods which definitely do not do what you want.
On Tue, Oct 6, 2015 at 12:54 AM, martin odersky <martin....@epfl.ch> wrote:
On Tue, Oct 6, 2015 at 9:48 AM, Haoyi Li <haoy...@gmail.com> wrote:
> That's a bit unfair comparison, because it does not include Python's built-in functions, many of which are list-relatedI count:12 itertools methods,12 list-related methods in builtins (excluding constructors)9 methods on lists3 operators (+, *, [])I may have missed one or two, but that's roughly it, 36 methods.I count 203 methods in http://www.scala-lang.org/api/current/index.html#scala.collection.mutable.ArrayBuffer> I'd like to challenge that. Buffer has 130+ methods defined on it. I don't think there are 65 methods among them that have horrendous performance implications.I'm defining "horrendous" here to be "O(n) when you can do something similar in O(less than n) with mutable collections", because that's about the upper bound on how bad performance can be on a collection.Here's the rough breakdown of how I'd classify the first ~120 methods I found in the Scaladoc before my fingers got tiredRoughly, I said something is "Bad" if it takes a O(n) copy to do something that in a mutable collection you really don't want to copy (that's the whole point of using a mutable collection!), "Inherited" is all the partialfunction stuff, and "???" is stuff that IMHO really has no business being there for non-perf reasons.Bad and ??? add up to 40/120, so 1/3 instead of 1/2. Perhaps someone with stronger fingers can do a more complete analysis. That's 1/3 stuff that IMHO shouldn't be there.Going through has revealed a few things to me:- The Querying methods on sequences apply just as well to mutable and immutable sequences. Things which return a T or Option[T], there is nothing to be gained writing it yourself. We can and should share all these with the immutable collections.- The Transformation methods on mutable.Seqs really should be in-place-transforms, in contrast to those on immutable.Seqs which should return new ones. This mirrors how ++= and += are in-place appends on mutable vs new Seqs on immutable (Despite what it might seem, this fact is totally not-transparent to a user and has bitten me more than once)..
For example, I want:- in-place filter,- in-place sort,- in-place distinct,- in-place drop,- in-place dropWhile,- in-place take
Yes, these would be good to have. But maybe under different names?Otherwise we get into the non-sensical situation that filter copies on arrays (which it has to, there's no way around it!) yet destroys on ResizableArrays and ArrayBuffers. But we could use a systematic naming scheme for these. E.g.filterReplace, sortReplace, ...orfilter_!, sort_!, ...- Martin
methods. Doing things in-place because of performance is why we're using mutable buffers in the first place after all! It's annoying to have to re-implement all these in-place ops ad-hoc with while-loops all the time.map, collect and flatMap obviously cant be done in-place, but when working with mutable buffers you tend to just use foreach and do everything in the side effect for performance.> - Should ArrayBuffer support map, flatMap, filter? I believe the answer is yes, because otherwise we render for comprehensions over ArrayBuffers impossible.I don't se why for-comprehensions over ArrayBuffers are something that is a goal in of itself. When I use ArrayBuffers, it's because I *don't* want excessive copying and allocations. If I *do* want copying and allocations, I'd be willing call freeze() or something before my for-comprehension and make it explicit.> - If it supports filter, then why not also support partition and scan? They are just variants of filter, after all.I'd want an in-place filter, and maybe a semi-in-place partition. In fact I've wanted it multiple times, and now I've found out Java 8 has it! Scan is hard to say, but if I'm working with mutable.Buffer I'd probably avoid using it entirely and just rely on foreach + side effects for perf. Or If I don't care about perf I'd be willing to call .toList and copy the whole thing to get access to these methods> - What about ++? Why forbid concatenating two resizable arrays into one?> - What about zip? It's clearly useful and it clearly constructs a new collection.I've never called map, flatMap, filter, partition, scan ++ or zip on a mutable.Buffer in three years, including a lot of time spend writing fairly-high-performance stuff in Metascala/Scalatags/uPickle/etc. using mutable.Buffer all over the place.I call those methods a *lot* otherwise, when using immutable collections. But the only reason I end up using mutable.Buffers is for performance, so I end up writing manual while-loops because these methods are too expensive. I'd love if there were in-place versions I could use, but there aren't, so it's back to while loops.--------------------------------------------------------------------------------------------------------------------------------Anyway, this is all just based on my experience as one amateur person writing Scala part time for fun =D So perhaps it's not worth taking too seriously. Other people may have different experiences. It would be nice to have actual method-usage stats from the community build and from real-world code-bases, but I do not have sufficient $s/PhDs to pull that off.Without numbers, we could argue in circles forever about how "clearly useful" things are and even if people get convinced and we have consensus we're all still blindOn Mon, Oct 5, 2015 at 11:45 PM, martin odersky <martin....@epfl.ch> wrote:On Tue, Oct 6, 2015 at 1:29 AM, Aleksandar Prokopec <aleksanda...@gmail.com> wrote:
On Tuesday, 6 October 2015 00:34:14 UTC+2, Haoyi Li wrote:> Why do you say they are more ergonomic? In which ways?Here's what you get when you want the methods on a python list:A small number of operations, basically all of which are useful to everyone who wants a mutable list. And all can be understood by anyone who has ever programmed before, without reading any docs!
That's a bit unfair comparison, because it does not include Python's built-in functions, many of which are list-related:
https://docs.python.org/2/library/functions.html
That adds more functions to the table.
Plus, there's Python's itertools, which has more list-related methods:
https://docs.python.org/2/library/itertools.html
Here's what you get when you ask for the methods on a scala mutable buffer:How many of these are methods that someone can call on a mutable buffer without horrendous performance implications? Less than half. In fact, methods which look very similar (++ and ++=) have totally different semantics and performance implications.I'd like to challenge that. Buffer has 130+ methods defined on it. I don't think there are 65 methods among them that have horrendous performance implications.Let's look at it in more detail, and things get fuzzy:- we have already established that arrays should get the full complement of immutable methods.- ResizableArray is like array, so why draw the boundary there?- ResizableArray is not used a lot because most people use ArrayBuffer to get a resizable array. So maybe ArrayBuffer needs to support these immutable operations as well?In more detail:- Should ArrayBuffer support map, flatMap, filter? I believe the answer is yes, because otherwise we render for comprehensions over ArrayBuffers impossible.- If it supports filter, then why not also support partition and scan? They are just variants of filter, after all.- What about ++? Why forbid concatenating two resizable arrays into one?- What about zip? It's clearly useful and it clearly constructs a new collection.And so on. So what operations do we want to throw out? Probably the most "dubious" one are +, +:, :+, -, which copy the collection while adding or removing a single element. There are few situations where these make sense. And maybe we should indeed phase them out for mutable collections. I think, arguably, doing a + instead of += on a mutable collection counts as "exotic use" and could be deprecated. But note that these operations are even more often misused for immutable collections. xs :+ x on lists is one of the most common rookie mistakes in Scala.Cheers- Martin
A couple of remarks here:
1. There are many use-cases where one deals with small collections, comprised of several elements, where performance implications are less important.
2. There are use-cases where copying is less expensive than the actual useful work performed on the collection.
3. Non-strict map, flatMap, filter, ... could reduce or eliminate performance overhead due to copying.
4. The optimizer could fuse many of these operations, or eliminate copying, in particular those where a copying bulk operations is followed by a fold.
As an exercise, can you give me which methods on that list will result in O(n) copying of the whole collection, which is basically what you never want?
I'm not excluding that you might be right about "basically what you never want", but as you pointed out yourself - we would need numbers to make definite claims about this.
Here are a few that you don't want to ever call if you want mutable-seq performance++++:+:---collectdiffdistinctdropdropRightdropWhilefilterfilterNotflatMapgroupBygroupedHere are a few that you *do* want++=+=collectFirstappendappendAllfold{Left, Right}forallforeachcountclear()Here are a few which are just wtf:<<(cmd: Message[Int])+(other: String)addString(b: StringBuilder)On Mon, Oct 5, 2015 at 3:16 PM, Simon Ochsenreither <simon.och...@gmail.com> wrote:Given the scope, I would strongly suggest abandoning the collection redesign. It doesn't address the pain points we should worry about, and the restrictions mean it is at best yet-another temporary measure.
This feels like a great recipe for a Python 2/Python3 disaster: Too many small, subtle changes which will bite people with not enough associated benefit to encourage strong adoption.
If we really want to do something, I would probably prefer working on Josh's views, despite not being enamored about it: At least it's made clear that they are provisional band-aids.
But the scope just means that we will have the same discussion a few years down the road, and I prefer breaking people's code once, not twice.
--Martin Odersky
EPFL
--Martin Odersky
EPFL
EPFL

Alec Zorab
Twitter discussions: Miles and others have stated explicitly that they
do not want a standard library. So of course they will not get
involved in improving it. I think that's a pity, it would be great to
see wider discussion about the ideas and design trade-offs.

Julien Richard-Foy
On Tuesday, October 6, 2015 at 11:57:47 PM UTC+2, Martin wrote:
To get the ball started I have added a link to a first strawman
proposal to the #818 issue:
https://github.com/lampepfl/dotty/issues/818
martin odersky
>> Twitter discussions: Miles and others have stated explicitly that they
>> do not want a standard library. So of course they will not get
>> involved in improving it. I think that's a pity, it would be great to
>> see wider discussion about the ideas and design trade-offs.
>
>
> I don't want to put words into Miles' (or anyone else's mouth) but I don't
> think that anyone objects to typesafe, scala-lang, epfl or any other
> "official" organisation producing a standard library with collections etc
> in. I think (again, my interpretation) the objection is that by coupling
> things like collections, parsers, xml, parallel collections, actors et al to
> the language as a whole, you massively reduce the ability, freedom and
> incentive to improve matters. Akka is the notable exception here, of course,
> where the community explicitly rejected the stdlib implementation and did
> their own thing, eventually killing off the built in package.
>
to great lengths to make the transition from Scala actors to Akka as
smooth as possible. They included Philipp Haller, the original author
of scala actors. Talk about community service!
I would like to see that in other places as well. You mention xml. Can
we *please* have an xml library that is independent of the language
and uses string interpolation instead? I have been clamoring for that
for years but nothing has been developed so far. Parser combinators is
the same thing. It would be great to have a separate module which
improves on the current state.
So, I think we are all in agreement that modularizing the stdlib is
the right way to go. Also, that the language and library should be
disentangled, with xml being obviously the biggest (but not the only)
culprit here. The collection work will be an important step towards
this, because only if we have shallow class hierarchies with few
methods in base traits we can start thinking about alternative
implementations.
To caricature a bit: In the old days (i.e. pre 2008), Scala was a tiny
language with a tiny community. Every contribution was welcome and we
did not give much thought to modularizing things, because the codebase
was small. That's how much of the stuff in the standard library ended
up there. Collections were then redesigned around 2010, and I think,
despite some shortcomings overall the effort was reasonably
successful. But lots of other parts were just left as they were. Not
because some entity (scala-lang, Typesafe, EPFL, ...) thinks they are
great but because nobody stepped forward improving them.
I hope this is about to change now, with your help. We have the SLIP
process for sheperding new libraries. There are already several
efforts under way, including a new I/O library and transducer-based
views. I hope many readers of this list will participate and
contribute. Head over to scala/slip on Gitter to get started.
Thanks
- Martin
> If collection, concurrent, io, math, sys and util were all separate packages
> outside the standard library, what would that cost people in real terms?
> Sure, in plenty of cases some people will pull some or maybe all of them
> back in, but the added freedom it offer to the community to adapt and
> improve on this functionality.
>
> There is also, I think, much to be said for providing an explicit
> distinction between scala the language and scala the library. It seems a
> shame to have developed such a flexible language that allows us to adapt it
> and use it in so many different ways and then immediately shackle it to a
> set of standard tools that restrict its use.
>
Dmitry Petrashko
https://github.com/lampepfl/dotty/pull/819
It has 4 changes that are applied to Martin’s version,
and I believe they could be discussed independently:
https://github.com/dotty-staging/dotty/commit/48afa750b803eca44eb295c8889c2c3612c29529
Gets rid of view class. View is a simple type alias to `() => Iterator[A]`.
This points the major difference between Iterators and views: iterators are consumed by
any usage, while views are reusable.
https://github.com/dotty-staging/dotty/commit/52816883cd6a86a59cd92efdc482cf441aecd8aa
Makes `.view` method be a decorator. This is done in order to decouple views from collection hierarchy
and make implementation of custom collections easier. It would also allow to modularise collections library
to a higher degree. I believe that the very same should be done for `.par`.
https://github.com/dotty-staging/dotty/commit/b77ab7c7a9f42df8996a3e3d814abc0406b2cca6
Makes Iterators have only `next` and `hasNext` methods. The motivation could be found in this code sample:
def intersectionIsEmpty[A](it1: Iterator[A], it2: Iterator[A]) =
!(it1 exists (it2 contains _))
Which was taken from old bug in Dotty codebase https://github.com/dotty-staging/dotty/commit/03ec379926f1f900f09c50dd038fba86feae70f6
I believe that this code simply should not compile: both `contains` and `exists` have no side effects on
mutable and immutable collections, but it has a silent side-effect on Iterators. It does not follow principle
of least surprise, I would actually say that this is one of most surprising methods for new-comments that
felt the joy of ”you can use the same methods on parallel, mutable and immutable collections”
when they discover that there is ”but be very careful if you use those methods on iterators”.
Ok, so what the change does: it moves all consuming methods from Iterator[A], to a decorator over View[A], that is, to () => Iterator[A].
This follows the patch that makes difference in use-cases of Iterator[A] and View[A] more obvious, that I started in previous commit.
https://github.com/dotty-staging/dotty/commit/5244c5cf1f3d2ff2917a09e9760f9ad887ca4ce0
Extracts a `LengthType` from all the signatures for documentation purposes & makes it be Long for big-data needs.
This change has a problem with compatibility with ScalaJs, as they simulate Longs.
-Dmitry
Alec Zorab
Dmitry Petrashko
It produces an iterator for every single operation on a view.
It was also the case of Martin's original operations on views,
though it was wrapped it in 2 more closures.
Francois
Haoyi Li
> Parser combinators is
the same thing. It would be great to have a separate module which
improves on the current state.
If you really are interested, such a thing exists http://lihaoyi.github.io/fastparse/
It's almost drop-in except a lot better to use. Not to mention 4-10x slowdown vs hand-rolled instead of the scala-parser-combinator's 400x
martin odersky
>> Parser combinators is
> the same thing. It would be great to have a separate module which
> improves on the current state.
>
> If you really are interested, such a thing exists
> http://lihaoyi.github.io/fastparse/
>
> It's almost drop-in except a lot better to use. Not to mention 4-10x
> slowdown vs hand-rolled instead of the scala-parser-combinator's 400x
>
It would be great to see fastparse as a module in the stdlib! If you
want contribute it that would be much appreciated. The best way to get
things rolling is via Slip: https://github.com/scala/slip
- Martin
Martin Odersky
EPFL
Rüdiger Klaehn
> To get the ball started I have added a link to a first strawman
> proposal to the #818 issue:
>
> https://github.com/lampepfl/dotty/issues/818
>
Iterator#reverse are defined in iterator. You might as well have size
then. Why not have them as enhancement methods that can be imported or
not?
Dmitry Petrashko
allow to make index type be Long on JVM and Int on JavaScript.
This is done by defining a value class:
https://github.com/lampepfl/dotty/commit/3c6ed1f23e2da86a4cb870bf91931b9bfc4925ab
that has arithmetic operations on it, and implicit conversions from Int and to Long.

Daniel Armak
Simon Ochsenreither
Is there a compiled list of all the problems (or missing features) of the current collections? I know about a bunch of them personally or because they've been mentioned here, but I don't know what other problems people may agree on.
I commented with a list in this thread. So far proposals score a 0/6 and I don't expect that to change much, so it's probably not the list people agree on. :-)
Aleksandar Prokopec
Aleksandar Prokopec
On Wednesday, 7 October 2015 06:52:17 UTC+2, nafg wrote:
On Tue, Oct 6, 2015 at 3:28 AM Aleksandar Prokopec <aleksanda...@gmail.com> wrote:I wanted to bring up specialization as well - I think that it will be relevant even with the AST fusion.
People commonly use a primitive type parameter and silently incur the cost of boxing:
def addNums(b: new ArrayBuffer[Int]) {
b += 1
b += 2
b += 3
}
Since we applied specialization to Function0,1,2,..., I see no reason why collections such as array buffers would not specialize for a specific set of primitive types.
The common problem here is instantiating arrays, which typical collections (buffers, hash maps, hash tries, queues, heaps) do a lot and which specialization doesn't support in the generic context. The way some rogue collection frameworks solved this in the past is by introducing a custom ClassTag-gy type-class that knows how to instantiate arrays.
How does this relate to miniboxing?
I'm not sure if miniboxing solved the array creation problem (?).
But when I say specialization, I mean rely on some solid technique that helps boxing - it could be miniboxing if it's mature enough.
--
Martin Odersky
EPFL
--
You received this message because you are subscribed to the Google Groups "scala-debate" group.
Seth Tisue
It would be great to see fastparse as a module in the stdlib!
Francois
Is there a compiled list of all the problems (or missing features) of the current collections? I know about a bunch of them personally or because they've been mentioned here, but I don't know what other problems people may agree on.
Thanks!
Daniel Armak
http://fr.slideshare.net/extempore/a-scala-corrections-library
Add the impossibility^Wextrem difficulty for anybody to add his own implementation of collection.
--On Wed, Oct 7, 2015 at 7:13 PM, Dmitry Petrashko <darkd...@gmail.com> wrote:
In https://github.com/lampepfl/dotty/pull/819 I've added changes that
allow to make index type be Long on JVM and Int on JavaScript.
This is done by defining a value class:
https://github.com/lampepfl/dotty/commit/3c6ed1f23e2da86a4cb870bf91931b9bfc4925ab
that has arithmetic operations on it, and implicit conversions from Int and to Long.
--
You received this message because you are subscribed to the Google Groups "scala-debate" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scala-debate...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
You received this message because you are subscribed to the Google Groups "scala-debate" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scala-debate...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Matthew Pocock
The flip is that I'd like to be able to provide my own implementations of the collections classes. Want an implementation of Set[String] that's backed by some funky compressed trie? No problem - write the trie implementation and provide a witness for Set[String]. This sort of thing is complex to the point of impossible with the current library design.
Oh, and the mutable and immutable collections need to have separate APIs, and where it makes sense, different names for the mutable/immutable operations. I almost never use mutable collections, and when I do it usually ends up being with Java interoperability, and I end up using the Java ones.
I have recently opened an issue inviting strawman designs for new
collection architectures:
https://github.com/lampepfl/dotty/issues/818
The issue lists some requirements for a design to be acceptable. Since
then there has been a discussion about several points that are all
outside the requirements outlined in #818. I think it's worthwhile to
discuss these, but do not think #818 is the proper place to do it.
That's why I would like to continue the discussion here.
- Martin
--
Martin Odersky
EPFL
--
You received this message because you are subscribed to the Google Groups "scala-debate" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scala-debate...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
martin odersky
<turingate...@gmail.com> wrote:
> I would love to see a reworked collections library to decouple API from
> implementation. Most of the API needs to be decoupled from the
> implementation hierarchy. For example, several variance issues go away if
> the collections have an implicit conversion to A => B rather than extending
> it. What I'd like to see is a series of traits that define classes of
> collections, and separately from this, a series of structural classes, with
> these two layers glued together with typeclasses. I'd like to define a
> function as operating on some type S <: Set, without needing to know
> anything more about S, aware that it will have a uniqueness guarantee
> according to S#Equality. I'd like to define a function as operating on some
> CL <: ConsList, knowing that head/tail/:: are constant-time operations.
>
A question: If one writes
val xs: Seq[T] = myConsList
would you then expect `xs.tail` to be still a constant time operation?
- Martin
EPFL
Matthew Pocock
On Fri, Oct 9, 2015 at 2:31 PM, Matthew Pocock
Hi Matthew,
A question: If one writes
val xs: Seq[T] = myConsList
would you then expect `xs.tail` to be still a constant time operation?
I would hope that a 'best effort' is made to keep this operation constant-time, but no, there's no longer a guarantee, as we've decided to throw away the knowledge that this is a cons list. We've weakened the contract by widening the type. It may have even invoked some referentially-transparent implicit conversion so that we're strictly not dealing with the same in-memory instances.
- Martin

Roland Kuhn
9 okt 2015 kl. 16:07 skrev Matthew Pocock <turingate...@gmail.com>:On 9 October 2015 at 14:28, martin odersky <martin....@epfl.ch> wrote:On Fri, Oct 9, 2015 at 2:31 PM, Matthew Pocock
Hi Matthew,
A question: If one writes
val xs: Seq[T] = myConsList
would you then expect `xs.tail` to be still a constant time operation?
I would hope that a 'best effort' is made to keep this operation constant-time, but no, there's no longer a guarantee, as we've decided to throw away the knowledge that this is a cons list. We've weakened the contract by widening the type. It may have even invoked some referentially-transparent implicit conversion so that we're strictly not dealing with the same in-memory instances.
--Matthew
- Martin
Dr Matthew PocockTuring ate my hamster LTDmailto: turingate...@gmail.comIntegrative Bioinformatics Group, School of Computing Science, Newcastle Universitymailto: matthew...@ncl.ac.ukgchat: turingate...@gmail.comirc.freenode.net: drdozerskype: matthew.pococktel: (0191) 2566550mob: +447535664143
--
You received this message because you are subscribed to the Google Groups "scala-debate" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scala-debate...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Rüdiger Klaehn
> Hi Matthew,
>
> 9 okt 2015 kl. 16:07 skrev Matthew Pocock <turingate...@gmail.com>:
>
>
>
> On 9 October 2015 at 14:28, martin odersky <martin....@epfl.ch> wrote:
>>
>> On Fri, Oct 9, 2015 at 2:31 PM, Matthew Pocock
>> Hi Matthew,
>>
>> A question: If one writes
>>
>> val xs: Seq[T] = myConsList
>>
>> would you then expect `xs.tail` to be still a constant time operation?
>
>
> I would hope that a 'best effort' is made to keep this operation
> constant-time, but no, there's no longer a guarantee, as we've decided to
> throw away the knowledge that this is a cons list. We've weakened the
> contract by widening the type. It may have even invoked some
> referentially-transparent implicit conversion so that we're strictly not
> dealing with the same in-memory instances.
>
>
> This sends a shiver down my spine: object allocation is an effect that needs
> to be visible, otherwise I cannot reason about the runtime resource usage of
> my programs. A collections library that does unprovoked allocations is
> rather useless to me.
>
In situations where you really care about performance so much that you
are worried about object allocations, you must know the type of your
collection precisely. If you have code that works with generic Seq[T],
you have no information whatsoever about the performance
characteristics of e.g. tail. For many operations like size you do not
even know if they will terminate. So I would argue that once you cast
a specific collection to a Seq, you already lose the ability to reason
about performance.
I would really love to be able to opt-in to slow operations, and have
only the operations present by default that are "native" to the
specific collection. But I don't see how this would even be possible
with an object oriented approach where everything extends from Seq and
Seq has lots of methods.
Besides, an approach where not every collection is-a Seq, but just can
be treated as a Seq by means of an implicit conversion would integrate
non-scala types such as java.lang.String and Arrays much more
naturally.
Matthew Pocock
This sends a shiver down my spine: object allocation is an effect that needs to be visible, otherwise I cannot reason about the runtime resource usage of my programs. A collections library that does unprovoked allocations is rather useless to me.
I'd prefer to see [C : ConsList] to witness that C has the ConsList operations. In that case, [C : Seq] wouldn't trigger a re-allocation of your instance.
To motivate why I want this kind of design, I often find myself needing tiny sets. It is efficient to implement these with List[T] and an auxiliary for insert that does a linear scan over what is already in the list. I would love to be able to newtype this and throw it at all the existing library methods that do set things. If there was a SetKernel and a ConsListKernel and so on that provided the fundamental operations that some type must provide to behave like one of those things, then I could make my ListySet and provide SetKernel[ListySet] and everything would work. The trick is to get these kernels right. Now, I obviously don't want APIs designed to accept List to by accident accept ListySet, but with the current design of the collections API I can't do anything about this.
Roland Kuhn
> I would really love to be able to opt-in to slow operations, and have
> only the operations present by default that are "native" to the
> specific collection. But I don't see how this would even be possible
> with an object oriented approach where everything extends from Seq and
> Seq has lots of methods.
>
> Besides, an approach where not every collection is-a Seq, but just can
> be treated as a Seq by means of an implicit conversion would integrate
> non-scala types such as java.lang.String and Arrays much more
> naturally.
Regards,
Simon Ochsenreither
To motivate why I want this kind of design, I often find myself needing tiny sets. It is efficient to implement these with List[T] and an auxiliary for insert that does a linear scan over what is already in the list.
Isn't this how the collection library already operates? (Thinking of https://github.com/scala/scala/blob/2.11.x/src/library/scala/collection/immutable/Set.scala#L148 )

sreque
1) Implement data structures as classes (or possibly traits) that expose all the necessary implementation details for optimal performance. Other than that, these classes don't expose anything.
2) Implement sub-classes of these data structure classes (or possibly classses that mix in "data structure traits") that implement the OO traits directly (Seq/Map/Set/etc.)
3) Implement type-classes that implement the "OO" interfaces using implicits over the data structure classes/traits.
You could then compare usage patterns between the two styles of virtual method dispatch, but within the confines of a single code base. This would also allow to experiment with Li Haoyi's suggestion that mutable data structures only implement operations that make sense for mutable types (mapInPlace, filterInPlace, etc.). The core data structure classes don't implement any higher level methods. You can therefore experiment with various sub-classes that implement different subsets of higher level collections APIs.
Sean
Haoyi Li
Here's another thought: how hard would it be to make collections primitive-specialized, and backed by primitive arrays?
That may need us to take classtags here or there (we could fall back to Array[Any] if we can't find one) but seems like it would reduce the memory usage of e.g. primitive mutable.Buffers by several X, not to mention cache-coherence improvements now they don't need to do so much pointer-chasing.
That kind of perf/memory boost alone could be sufficient to justify overhauling the collections library

Kevin Wright
mail: kevin....@scalatechnology.com
gtalk / msn : kev.lee...@gmail.com
Matthew Pocock
Daniel Armak
Part of the pressure to rework collections is coming from the android dev community
Dmitry Petrashko
The typeclass argument with specializing collections does not help much, as the biggest thing you want specialized is storage. And as long as you want to be able to abstract over the underlying type that collection is specialized for, I do not see how type-classes help to reduce bytecode size here.
When discussing specialization we should also consider dynamic on-demand specialization. Because if you do normal specialization, than you are unlikely to ever consider specialization of Function2, or Product3, as 1000 classes will need to be generated upfront.
But if instead specialization is done lazily or on-demand you could have only the versions that are used in the program.
Project Vallhala is considering bringing specialization to JVM, and I am working on Dotty Linker that should be able to specialize common Scala code. Truffle\Graal could also be of help here one day.
Given this, I would actually prefer to try to come up with good collection design, that is geared towards developer experience and not towards performance.
If we have good collections with operations that have clear semantics it would make optimizing them substantially easier and performance could be obtained later by general optimizations. Even for current collections we have a precedent: http://scala-blitz.github.io/home/documentation/optimize.html
-Dmitry
Simon Ochsenreither
Given this, I would actually prefer to try to come up with good collection design, that is geared towards developer experience and not towards performance.
If we have good collections with operations that have clear semantics it would make optimizing them substantially easier and performance could be obtained later by general optimizations.
+1!
Scala >= 2.12 will be an issue on Android, although I hope it will become easier and more straightforward for third-party developers to write converters to Java 6/dex with TASTY. I fear there will be a gap where we don't have a good Android story in Scala.
With Valhalla it will probably become completely impossible to close the gap between OpenJDK and Android, if Google keeps up its non-development of Android. I'm wondering whether it makes more sense to just use Scala.js for mobile these days ...
Matthew Pocock
With Valhalla it will probably become completely impossible to close the gap between OpenJDK and Android, if Google keeps up its non-development of Android. I'm wondering whether it makes more sense to just use Scala.js for mobile these days ...
--You received this message because you are subscribed to the Google Groups "scala-debate" group.
To unsubscribe from this group and stop receiving emails from it, send an email to scala-debate...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.

Erik Bruchez
Haoyi Li

Jon Pretty
I've finally got round to reading/skimming through this thread, and I'm happy to see the debate it's stimulating: I think the framework for discussion is very useful, whilst acknowledging that it's going to be impossible to satisfy everyone (so it's no surprise that people are questioning it). But I'd much rather waste some time failing having given it our best shot, than give up now, be stuck with the current design and forever speculate about whether we could have done better.
But I think we might be able to do a bit better to accommodate some of the concerns raised.
Ideologically, I'm in agreement with Miles about keeping the standard library minimal, and allowing (potentially multiple, competing) open-source projects to fill the gaps. But pragmatically, I'm aware that the only serious contender to the standard library collections is Paul's, and I'm not aware that that's had any adoption. The evidence, at least for something as fundamental (or difficult to get right) as collections, does not support the notion that open-source libraries will just emerge.
From my point of view, the biggest problem with having collections as part of the standard library is that they're tied to the release schedule of Scala and its binary compatibility guarantees, which is too slow for innovation to take place. So, could we make a "blessed" release of collections with each major release of Scala, but continue to make subsequent full releases (i.e. not just snapshots, milestones or RCs) of a separate collections library as they continue to evolve independently from the compiler, which users could choose to pull in if desired.
The proposals I've seen so far seem to mostly support the idea of separating the collections' data structures from the APIs which operate on them. So, do you think it would be possible to fix the data structure implementations for each major Scala release, while allowing more frequent releases of the API? As I understand it, the interactions between compiler and user code would have no dependencies on the collections API, but maybe that's naïve...
I don't currently have any plans to do any work on a collections library (I have no time), but if I did, I'd be interested in experimenting with things like dependent types and tracking effects. These are the sorts of ideas that are almost certainly too experimental to be in standard library, but a separation of implementation and API would make them much easier to experiment with alternative APIs, whilst retaining interoperability.
Cheers,
Jon
Francois
I have recently opened an issue inviting strawman designs for new collection architectures: https://github.com/lampepfl/dotty/issues/818 The issue lists some requirements for a design to be acceptable. Since then there has been a discussion about several points that are all outside the requirements outlined in #818. I think it's worthwhile to discuss these, but do not think #818 is the proper place to do it. That's why I would like to continue the discussion here. - Martin
For the sum-up, I'm not sure about any big consensus for now, safe perhaps that immutable and mutable collection are different beasts, with different API, different use cases and expectation from their users.
An other idea that come back is that even if a completly different collection API seems out of reach given Scala adoption, reasonable incompabilities between existing collection API and a new one are not only torable, but perhaps a good thing to clear strangeness and really take advantage of a redisgn.
So, for the proposal, I'm aware of:
- Martin filrst proposal:
- Dmitry Petrashko (DarkDimius) variation on Martin proposal:
- Paul psp-collection:
- Daniel Spiewak proposition:
- Josh Suereth's viewducer:
- Bill Venners Scalatic-collection WIP:
And for other blogs/talks on the subjects:
- Paul famous one:
- Bill Venners scala world slides about Scalactic-collection :
- Lex Spoon blog:
I'm almost sure that people from typelevel had produced some code
or discussion on the subject, but I can't find back them right
now.
Any other link to discussion about the subject would be
appreciated!

Eric Richardson
Bill Venners - https://www.youtube.com/watch?v=UBjzbkhvYTU
Paul Phillips - https://www.youtube.com/watch?v=uiJycy6dFSQ
Eric

David Hagen
What I think makes designing a good collections library so hard is the diversity of features that a collection may support. Most features are of the type “can I do X efficiently/safely”. I was inspired by this discussion to catalog the different ways that one might want to traverse a collection, that is get every element and do something with it. I was surprised how well my thoughts aligned with the current design of Scala. I am by no means an expert on programming language design, but I thought I would copy ideas in here in case anyone was interested.
· Can I get an immutable sequence of the collection’s elements?
o This is allowed to take O(n) time. The collection may be infinite if the elements can be constructed as a lazy collection in substantially less than O(n).
o This operation makes no sense for infinite collections.
o Example: An actor-based array that cannot wait for user code, even user code passed through foreach, but it can give a copy of the current state.
o This is the only well-behaved operation that traverses mutable collections.
· Does the collection have a foreach?
o This is allowed to take O(k) time for processing the first k elements.*
o An eager fold and a foreach are isomorphic. I would use the name foreach because it makes it clear that this does not terminate on infinite collections.
o Despite the appearance of a relationship between elements and foreach, they actually have no hierarchy. Foreach cannot be implemented from elements because it may take O(n) to execute the first element. Elements cannot be implemented from foreach because it may never return. However, elements is the intersection between finite and foreach.
o Example: A mutable collection that can’t wait for user code, but can freeze its elements in O(1) time, can freeze and then run foreach of the frozen elements. This collection can even be infinite.
o If the function changes the shape of the collection (number/location of elements), this operation is not well-behaved. If an effect system is in place, an eager fold that took only pure functions would be well-behaved.
· Does the collection have a lazy fold?
o This is allowed O(n) time.
o Obviously, this requires cooperation from the function doing the folding to actually be lazy.
o This is a subtype of foreach. We can implement foreach using lazy fold, but not vice versa because it may not be safe to pause folding the collection (e.g. the collection is mutable).
o If we allowed O(k) time for the first k elements, this would be identical to head/tail, but a collection where finding the first element is not cheap would be excluded.
o Example: A rotated sorted array, which can be traversed in O(n) time, but takes O(n) to find the first element.
· Can I get each next element one at a time so that I can iterate on my own terms?
o Each call to next is allowed O(1) time**
o Example: A stream from a TPM will continue to produce elements, but cannot store or expose the state necessary to implement tail.
o Example: A truly random stream, which has to state to set.
· When getting the head element, can I also keep the tail state so that I can iterate the collection as many times as I like?
o Each call to head or tail is allowed O(1) time**
o This is a subtype of next because it is trivial to implement next from head.
· Can I get a random element?
o This is allowed O(1) time**
o I suppose this is also well-behaved in the face of mutable collections, because it puts all the responsibility for getting the next element on the user. If the user shrinks the collection, it is on him if he tries to get an element outside the bounds.
* There are many intricacies with the time constraint on foreach. For finite collections, we would expect this to take O(n) to complete. But what about infinite collections? That would leave no constraint on how long it takes to produce a value. Do we say it takes O(k) to process the first k entries? Then the Scala Vector wouldn’t be allowed because it gives the first element in O(log n) time. Should a dense bit set be allowed to have a foreach? It cannot produce elements in O(n) time. If not, then either Set cannot have an O(n) foreach or a dense bit set cannot be a Set. Perhaps a dense bit set should be an InSet only, not an ExSet. A dense bit set produces elements in O(capacity), so perhaps what exactly n refers to needs to be relaxed. Maybe this operation is just so abstract, it shouldn’t have a time constraint at all!
** There is some weird stuff to deal with regarding the time constraint of single elements. Lots of immutable collections use tree structures to provide efficient access and update. But here efficient means O(log n), which would put it out of the running for operations expected to take O(1). But most interestingly, it has been shown empirically that memory access is not O(1) anyway, but more like O(sqrt n), which means that everything less than O(sqrt n), like O(log n), is pretty much the same.
*** Because we are dealing with traits, everywhere it says subtype could instead be a conversion to an implicit class that provides the subtype functionality.
David Hagen

Adam Voss
On Monday, October 5, 2015 at 3:18:38 PM UTC-5, Martin wrote:
I have recently opened an issue inviting strawman designs for new
collection architectures:
https://github.com/lampepfl/dotty/issues/818
The issue lists some requirements for a design to be acceptable. Since
then there has been a discussion about several points that are all
outside the requirements outlined in #818. I think it's worthwhile to
discuss these, but do not think #818 is the proper place to do it.
That's why I would like to continue the discussion here.
- Martin
--
Martin Odersky
EPFL
Naftoli Gugenheim
Yes, an equality typeclass is very sorely missed. However as has been discussed, there is an impedance mismatch between properly typed equality and JVM equality, which makes coming up with a satisfactory solution that doesn't break anything very hard.
--