Software to decrypt ancient Indian maths from classical texts
84 views
Skip to first unread message

Anunad Singh
Feb 21, 2017, 9:19:43 AM2/21/17
to sanskrit-p...@googlegroups.com
Software to decrypt ancient Indian maths from classical texts
indiatoday.intoday.in/story/software-to-decrypt-ancient-indian-maths-from-classical-texts/1/880920.html
indiatoday.intoday.in/story/software-to-decrypt-ancient-indian-maths-from-classical-texts/1/880920.html

Shreevatsa R
Feb 23, 2017, 3:23:21 AM2/23/17
to sanskrit-programmers
I took a look at this. It is one of the "Research Communications" published in Current Science Volume 112 (i.e., 2017), issue 3 (of 10 February 2017), titled "Coding the encoded: automatic decryption of kaTapayAdi and AryabhaTa’s systems of numeration".
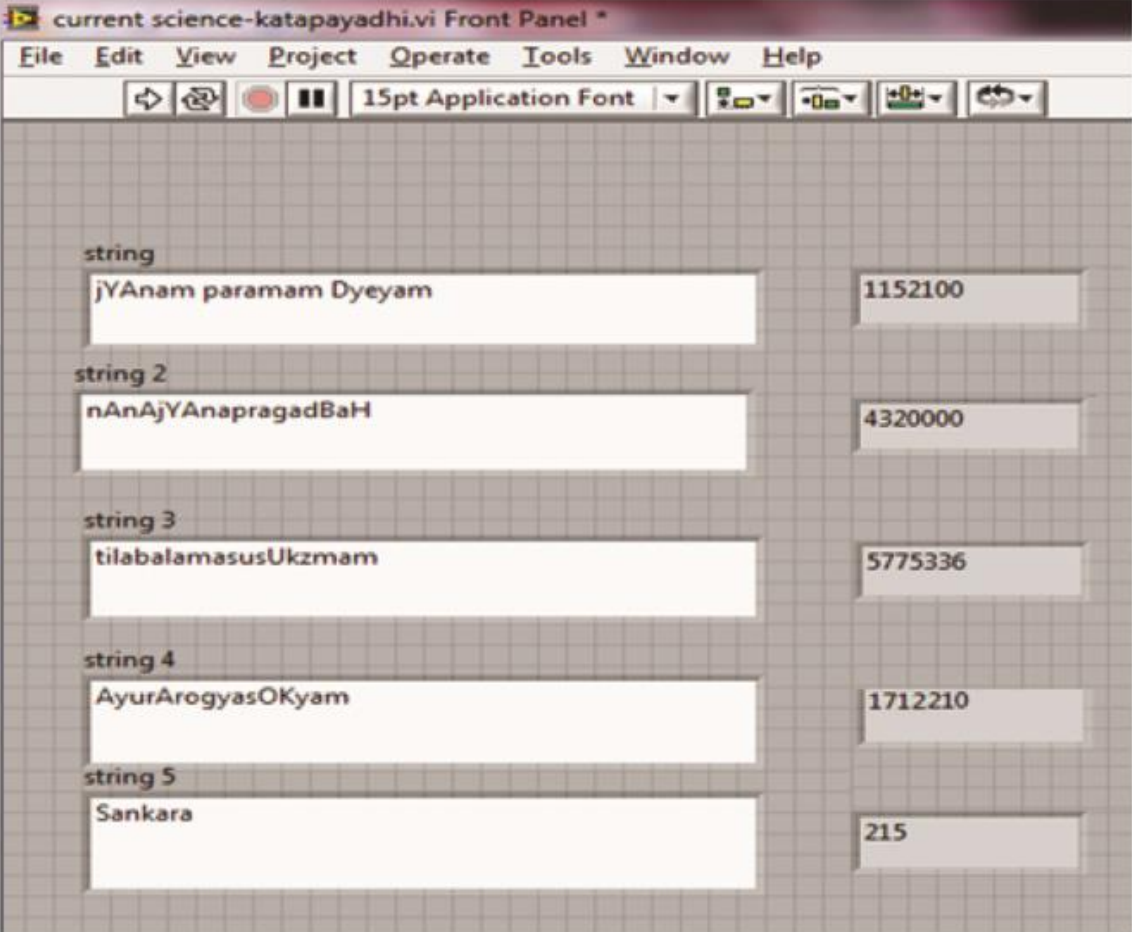
The thing they've implemented is a function to translate text in the kaṭapayādi (or Āryabhaṭa's) system into digits:
For some reason they implemented this lookup in a software program called LabVIEW. (I hadn't seen it before: this seems to be an unusual way to program by joining blocks, which reminds me of Scratch.) Well, whatever works for them I guess.
One of their examples is strange: to illustrate the numbers 25 and 250 in the kaṭapayādi system, they use (in ITRANS) the words "ksharA" and "aksharA", i.e. kśarā (क्शरा) and akśarā (अक्शरा). The sound क्श is unusual in Sanskrit, so perhaps they could have chosen a better example. (Of course, Āryabhaṭa's system regularly generates unpronounceable stuff, so this may not be worth complaining about.)
They cite decent and relevant references (though Kim Plofker is cited as "Kim, P." rather than "Plofker, K."). They use SLP1 in their code (as you can see in their screenshot above).
Anyway, good for them that they got a paper out of it. :-) Hope they continue to work on Sanskrit-related programming, and move on to more things that can be useful to more people.
On Tue, Feb 21, 2017 at 6:19 AM, Anunad Singh <anu...@gmail.com> wrote:
Software to decrypt ancient Indian maths from classical texts
indiatoday.intoday.in/story/software-to-decrypt-ancient-indian-maths-from-classical-texts/1/880920.html
--
You received this message because you are subscribed to the Google Groups "sanskrit-programmers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sanskrit-programmers+unsub...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
Anunad Singh
Feb 24, 2017, 6:10:50 AM2/24/17
to sanskrit-p...@googlegroups.com
Shreevatsa ji,
I also read the paper at the given site. After reading it, this is what I understand-3) The newspaper title 'Software to decrypt ancient Indian maths from classical texts' can mislead people.
-- अनुनाद

विश्वासो वासुकिजः (Vishvas Vasuki)
Jan 22, 2020, 7:23:15 PM1/22/20
to sanskrit-programmers, asdof...@gmail.com
Just recalled this thread and found this useful - http://indicjs.github.io/katapayadi/ .
(cc : Akshay S Dinesh - please see https://groups.google.com/forum/#!searchin/sanskrit-programmers/katapayadi|sort:date/sanskrit-programmers/N7B_mbhe68M/up8kBxQpAAAJ for context.)
--
You received this message because you are subscribed to the Google Groups "sanskrit-programmers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sanskrit-program...@googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
--
--
Vishvas /विश्वासः
Vishvas /विश्वासः
Shreevatsa R
Jan 22, 2020, 8:10:46 PM1/22/20
to sanskrit-programmers
On Fri, 24 Feb 2017 at 03:10, Anunad Singh <anu...@gmail.com> wrote:
Some years back a thought came to my mind to write a program which, given a number, will produce all the corresponding कटपयादि words present in a list (dictionary). This could be useful, for example, for converting a new born baby's date-of-birth to his/her name. But I have not been able to do this due to laziness. This could be useful to poets also.
Anunad ji, this is a good idea :-)
Question for this list: what's a convenient place to get a large list of Sanskrit word forms? (Containing e.g. "रामस्य" and "भवेत्".)
[I remember a mention a while ago but have forgotten... I also remember there used to a reference page or wiki I could look up for this, but I've forgotten that too :)]

Akshay S Dinesh
Jan 22, 2020, 8:59:40 PM1/22/20
to विश्वासो वासुकिजः (Vishvas Vasuki), sanskrit-programmers
Yes. Word to number is extremely simple and the linked software sounds like it is built just for the paper.
Number to word requires a dictionary of words (or names). If a freely licensed dictionary is available, the katapayadi number of each word can be precomputed and used for lookup.
Thanks for the mention of my code.
विश्वासो वासुकिजः (Vishvas Vasuki)
Jan 18, 2024, 6:51:10 AMJan 18
to sanskrit-programmers, Hrishikesh Terdalkar
namaste hRShIkesh
would like to be able to use a python library to decode sankhyas, if there is one (with capabilities like https://sanskrit.iitk.ac.in/jnanasangraha/sankhya/ ). Could you publish, if you have one?

Hrishikesh Terdalkar
Jan 18, 2024, 1:06:17 PMJan 18
to विश्वासो वासुकिजः (Vishvas Vasuki), sanskrit-programmers
नमः।
सङ्ख्यापद्धतिः नाम यन्त्रं प्रकाशितं कर्तुम् इच्छामि।
तत्र किञ्चित् कार्यम् आवश्यकम् (code cleaning etc.)
तद्विषयकम् एकं शोधपत्रम् अपि प्रकाशयिष्यामि इति चिन्तनम् अस्ति।
प्रायः अग्रिमे मासे करिष्यामि।
हृषीकेशः

shantanu oak
Jan 19, 2024, 12:00:21 AMJan 19
to sanskrit-programmers
In the mean time you can use poor man's katapayadi found here...
-- Shantanu
Reply all
Reply to author
Forward
0 new messages