Jupyter notebook by default?

Jeroen Demeyer
7.0 release? I don't really have an opinion on the matter.
Pros:
* Nice tracebacks!
* The Jupyter notebook is a mature well-maintained project, unlike
SageNB. It is widely used in the "scientific Python" community.
* Availability of other Jupyter kernels besides Sage.
Cons:
* Less compatible with Sage: Sage interacts don't work, some graphics
don't work.
* Certain features of SageNB are missing: live documentation,
sharing/publishing of worksheets.
* It clutters the file system with .ipynb files.
Don't cares:
* It's just a default choice, both options remain available.

Emmanuel Charpentier
Pros :
* The python debugger works in the IPython notebook. Damn useful !
* Some extensions developed for Python worksheets run in Sage worksheets.
Cons :
* (Currently) no standard way to create a cell in another language, as allowed by the Sage notebook's magics such as %maxima : in the current implementation, they create separate instances of interpreters, which do not return to the worksheet, even when explicitely terminated. Exceptions :
- Python (creates a separate subprocess)
- R, if rpy2 is young enough (but the interpreter used in %%R cells is different of the one used by r.... functions. This MUST be fixed).
* The lack of interacts is a sore point. But I hear there is work on this front...
I don't see what you mean when you say that live documentation is missing. You can access the online help by typing a function name and a question mark, and a pager will open on the right page. And the "help" menu contains a load of links to the manuals and tutorials (this should be extended, by the way...)
And I find that the "cluttering" of the filesystem (i.e. one worksheet, one file) is much saner that the Sage notebook "solution" (one worksheet, a $#!+load of anonymous files hidden in an invisble directory).
Hoping that my two cents may help,
--
Emmanuel Charpentier

William Stein
<emanuel.c...@gmail.com> wrote:
> A few addenda :
>
> Pros :
> * The python debugger works in the IPython notebook. Damn useful !
> * Some extensions developed for Python worksheets run in Sage worksheets.
>
> Cons :
> * (Currently) no standard way to create a cell in another language, as
> allowed by the Sage notebook's magics such as %maxima : in the current
> implementation, they create separate instances of interpreters, which do not
> return to the worksheet, even when explicitely terminated. Exceptions :
> - Python (creates a separate subprocess)
> - R, if rpy2 is young enough (but the interpreter used in %%R cells is
> different of the one used by r.... functions. This MUST be fixed).
> * The lack of interacts is a sore point. But I hear there is work on this
> front...
>
> I don't see what you mean when you say that live documentation is missing.
> You can access the online help by typing a function name and a question
> mark, and a pager will open on the right page. And the "help" menu contains
> a load of links to the manuals and tutorials (this should be extended, by
> the way...)
>
manual, tutorial, etc., of Sage as live, auto-converted worksheets.
This is very useful for people learning Sage. You don't have to copy
paste from the docs -- you directly play with them. This was a very
cool feature Dorian Raymer added to the Sage notebook in maybe 2007 or
2008. There was some work on trying to create something similar at
the Berkeley sage days.
> And I find that the "cluttering" of the filesystem (i.e. one worksheet, one
> file) is much saner that the Sage notebook "solution" (one worksheet, a
> $#!+load of anonymous files hidden in an invisble directory).
with in 2006, when we were planning to have *everything* stored in a
database, which was the sort of standard way to make websites back
then...)
>
> Hoping that my two cents may help,
>
> --
> Emmanuel Charpentier
>
>
>
> Le vendredi 18 décembre 2015 11:35:53 UTC+1, Jeroen Demeyer a écrit :
>>
>> Should the Jupyter notebook be the default notebook for the next Sage
>> 7.0 release? I don't really have an opinion on the matter.
>>
>>
>> Pros:
>>
>> * Nice tracebacks!
>> * The Jupyter notebook is a mature well-maintained project, unlike
>> SageNB. It is widely used in the "scientific Python" community.
>> * Availability of other Jupyter kernels besides Sage.
>>
>>
>> Cons:
>>
>> * Less compatible with Sage: Sage interacts don't work, some graphics
>> don't work.
>> * Certain features of SageNB are missing: live documentation,
>> sharing/publishing of worksheets.
>> * It clutters the file system with .ipynb files.
>>
>>
>> Don't cares:
>>
>> * It's just a default choice, both options remain available.
>
> You received this message because you are subscribed to the Google Groups
> "sage-devel" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to sage-devel+...@googlegroups.com.
> To post to this group, send email to sage-...@googlegroups.com.
> Visit this group at https://groups.google.com/group/sage-devel.
> For more options, visit https://groups.google.com/d/optout.
--
William (http://wstein.org)

Volker Braun
On Friday, December 18, 2015 at 11:35:53 AM UTC+1, Jeroen Demeyer wrote:
* Certain features of SageNB are missing: live documentation,
sharing/publishing of worksheets.
* It clutters the file system with .ipynb files.

Dima Pasechnik
On Friday, 18 December 2015 15:27:29 UTC, Volker Braun wrote:
IMHO the Jupyter/IPython notebook is a clear winner, no real contest.Nobody prevents you form using SageNB for existing worksheets or the live documentation; But if you start a new worksheet today then you really should be using Jupyter.
On Friday, December 18, 2015 at 11:35:53 AM UTC+1, Jeroen Demeyer wrote:* Certain features of SageNB are missing: live documentation,
sharing/publishing of worksheets.IMHO sharing is already better, you can just upload the ipynb file anywhere (including http://gist.github.com or any other pastebin) and then share it using the http://nbviewer.ipython.org service. For example:
Some care will need to be taken, so that we don't have to deal with complaints of kind
" I run 'sage -n', and all my worksheets are gone!!! Help!!! "
William Stein
>
>
> On Friday, 18 December 2015 15:27:29 UTC, Volker Braun wrote:
>>
>> IMHO the Jupyter/IPython notebook is a clear winner, no real contest.
>>
>> Nobody prevents you form using SageNB for existing worksheets or the live
>> documentation; But if you start a new worksheet today then you really should
>> be using Jupyter.
>>
>>
>> On Friday, December 18, 2015 at 11:35:53 AM UTC+1, Jeroen Demeyer wrote:
>>>
>>> * Certain features of SageNB are missing: live documentation,
>>> sharing/publishing of worksheets.
>>
>>
>> IMHO sharing is already better, you can just upload the ipynb file
>> anywhere (including http://gist.github.com or any other pastebin) and then
>> share it using the http://nbviewer.ipython.org service. For example:
>>
>> http://nbviewer.ipython.org/url/sagepad.org/pub/sage-test.ipynb
>
>
> Some care will need to be taken, so that we don't have to deal with
> complaints of kind
>
> " I run 'sage -n', and all my worksheets are gone!!! Help!!! "
automatic and safe migration step that would take care of this
problem, even if the notebook format changed completely (which
happened). I always wrote that code to do the migration, even though
it was a lot of work. Somebody should write something like that for
sagenb to jupyter.
-- William
>
>
>>
>>
>>
>>> * It clutters the file system with .ipynb files.
>>
>>
>> and .ipynb_checkpoints hidden directories. See also:
>> http://trac.sagemath.org/19746
>>
>>
Volker Braun
William Stein
> The ticket already has a notice printed that tells you how to run the old
> SageNB
>
> Realistically, since we are switching to a model where notebooks are
> individual files there is always going to be somebody who won't read the
> hints. We'll have to do *that* switch anyways and it isn't going to be any
> easier if we wait.
they are stored as a directory tree in the filesystem. The .sws file
that you get when you click "File --> Download" in sagenb is a file.
It represents almost exactly the same information as an ipynb file.
It is feasible to run a script that you automatically convert the
~/.sage/sagenb* (or whatever) directory into a collection of Jupyter
notebooks, say ~/.sage/jupyter. This would make life much easier for
users who have collections of notebooks. The hard part is
functionality that doesn't map from sagenb to jupyter, e.g.,
interacts, % modes, etc., etc.,
I wrote an sws parser, which is here in case anybody takes up
automating the above conversion (I won't):
https://github.com/sagemathinc/smc/blob/master/src/smc_pyutil/smc_pyutil/sws2sagews.py
The
>
>
> On Sunday, December 20, 2015 at 7:52:46 PM UTC+1, Dima Pasechnik wrote:
>>
>>
>>
>> On Friday, 18 December 2015 15:27:29 UTC, Volker Braun wrote:
>>>
>>> IMHO the Jupyter/IPython notebook is a clear winner, no real contest.
>>>
>>> Nobody prevents you form using SageNB for existing worksheets or the live
>>> documentation; But if you start a new worksheet today then you really should
>>> be using Jupyter.
>>>
>>>
>>> On Friday, December 18, 2015 at 11:35:53 AM UTC+1, Jeroen Demeyer wrote:
>>>>
>>>> * Certain features of SageNB are missing: live documentation,
>>>> sharing/publishing of worksheets.
>>>
>>>
>>> IMHO sharing is already better, you can just upload the ipynb file
>>> anywhere (including http://gist.github.com or any other pastebin) and then
>>> share it using the http://nbviewer.ipython.org service. For example:
>>>
>>> http://nbviewer.ipython.org/url/sagepad.org/pub/sage-test.ipynb
>>
>>
>> Some care will need to be taken, so that we don't have to deal with
>> complaints of kind
>>
>> " I run 'sage -n', and all my worksheets are gone!!! Help!!! "
>>
>>
>>>
>>>
>>>
>>>> * It clutters the file system with .ipynb files.
>>>
>>>
>>> and .ipynb_checkpoints hidden directories. See also:
>>> http://trac.sagemath.org/19746
>>>
>>>
Volker Braun
Notebooks in sagenb are basically individual files; it's just that
they are stored as a directory tree in the filesystem.
https://github.com/sagemathinc/smc/blob/master/src/smc_pyutil/smc_pyutil/sws2sagews.py
William Stein
> On Sunday, December 20, 2015 at 10:27:39 PM UTC+1, William wrote:
>>
>> Notebooks in sagenb are basically individual files; it's just that
>> they are stored as a directory tree in the filesystem.
>
>
> Yes, what I meant was: SageNB doesn't show a filesystem view so nobody is
> going to know *where* they are stored in the file system.
>
> Whereas Jupyter notebooks are always displayed as files. And the average
> user isn't going to find ~/.sage/jupyter with the jupyter file browser. In
> fact, if that is not a subdirectory of the directory where Jupyter is
> launched then you cannot open it. And you don't want a ton of converted
> notebooks dumped in the current directory either. Realistically, any
> notebook converter will have to be manually invoked.
before, as I mentioned. I'll not press this any further.
> And thats not going to
> get easier by delaying when we change the defaults.
we delay changing the defaults until after such a converter is
written.
>
>>
>> https://github.com/sagemathinc/smc/blob/master/src/smc_pyutil/smc_pyutil/sws2sagews.py
>
>
> And its easy to programmatically generate new IPython notebooks:
> http://nbviewer.ipython.org/gist/fperez/9716279
>
Volker Braun

Nils Bruin
It will be much easier for our users to actually *use* a converter if
we delay changing the defaults until after such a converter is
written.
++1 (OK, I guess that's an error in most language).
It's going to be a relatively unpleasant surprise for people if they start up the "sage notebook" and find a different notebook. We could possibly alleviate the problem of lack of information by somehow guessing if this is the first time this user starts up sage ipython notebook (and perhaps only if we detect there is evince of a sagenb) and startup with a document that explains how to do migration.
If the default changes, then most users will assume they are supposed to change with it (and we should only do this once we think users should change, e.g., when interacts work)
At the very least there should be a method to:
- start the classic notebook
- save a collection of worksheets (sagenb)
- convert them to ipynb, at least in a way that works for "simple" worksheets. Attached files etc. are obviously going to be an issue.
If we don't have a tool that makes it straightforward to do this migration then we're not ready to change defaults, in my opinion.
Volker Braun
different notebook. We could possibly alleviate the problem of lack of information by somehow guessing if this is the first time this user starts up sage ipython notebook
If the default changes, then most users will assume they are supposed to change with it (and we should only do this once we think users should change, e.g., when interacts work)
At the very least there should be a method to:
- start the classic notebook
Jeroen Demeyer
> Interacts DO work. Its just Jupyter interacts and not SageNB interacts.
consistent than the Jupyter @interact API. Unfortunately, I am not able
to convince upstream Jupyter (really: ipywidgets) that this is the case.
See https://github.com/ipython/ipywidgets/issues/238
It's true that ipywidgets might be able to do more fancy stuff (like
support for game controllers), but the basic stuff works better in SageNB.
Jeroen.

John H Palmieri
I think we need a migration tool and a deprecation warning: "The old Sage notebook is deprecated in favor of Jupyter notebooks. For information about converting old-style notebooks to Jupyter notebooks, see ... To use Jupyter notebooks now, run 'sage -notebook=jupyter'." Then the next version of Sage can change the default behavior.
--
John
Nils Bruin
On Monday, December 21, 2015 at 5:16:44 AM UTC+1, Nils Bruin wrote:different notebook. We could possibly alleviate the problem of lack of information by somehow guessing if this is the first time this user starts up sage ipython notebookThats inconsistent UX, now you open different notebooks on different computers / accounts. Unless you mean: print help to the terminal. The ticket does that already.
The reason why I expect that printing on the terminal is insufficient, is because most notebook users will not look there at all: they're just looking at the browser that pops up. There are quite some precedents for informational pop-ups: firefox and chrome are usually quite insistent on start-up to ask you about migrating information to themselves and/or selecting them as default browser.
We could make the UX more consistent by "preinstalling" a migration ipy notebook. In fact, that notebook could include code to open and read the sagenb worksheets (jupyter kernels don't run chrooted by default, right? so their code can still access HOME/.sagenb) and help with translating the worksheets.
The main scenario is that of single-user notebooks. multi-user setups don't translate easily to jupyter anyway, so a more manual translation approach will be required anyway.
Volker Braun
We could make the UX more consistent by "preinstalling" a migration ipy notebook.
In fact, that notebook could include code to open and read the sagenb worksheets (jupyter kernels don't run chrooted by default, right? so their code can still access HOME/.sagenb)

kcrisman
> > And thats not going to get easier by delaying when we change the defaults.
Volker Braun
Regardless of how "useful" or awesome the Jupyter notebook is and how many people in scientific computing are using it, there is a substantial ecosystem now designed around the Sage notebook proper
kcrisman
And we are not removing it for all the legacy reasons that you listed. This thread is about what format new notebooks are supposed to be. Anybody who prefers SageNB can still use SageNB
But the fact is: Its unmaintained/-able, and the longer we wait the more painful it'll be to switch. How is waiting another year going to help? Because by then there will be another book explaining how to use SageNB? Do you think the book author is going to be happy that we never made it clear that SageNB is on the way out? SageNB is an evolutionary dead end, and the only question is how deep into that hole do we want to go.

David Roe
And we are not removing it for all the legacy reasons that you listed. This thread is about what format new notebooks are supposed to be. Anybody who prefers SageNB can still use SageNBBut how easy will that be? It already sounds like sagenb notebooks are not really portable to Jupyter.But the fact is: Its unmaintained/-able, and the longer we wait the more painful it'll be to switch. How is waiting another year going to help? Because by then there will be another book explaining how to use SageNB? Do you think the book author is going to be happy that we never made it clear that SageNB is on the way out? SageNB is an evolutionary dead end, and the only question is how deep into that hole do we want to go.As William said, the answer is to either find a way to make them port, or to find a way to gracefully detect that someone has existing sagenb worksheets (perhaps slightly more gracefully than just checking DOT_SAGENB since that doesn't mean they actually did anything) and either ask to upgrade to Jupyter worksheets, if that's possible, or make it very easy to change a default setting.
Could there be an environment variable DEFAULT_SAGE_NOTEBOOK that one could have incredibly explicit instructions for how to use? (Would making an alias work in this context? Not in the sage: notebook() situation, I guess.)But it has to be idiot-proof. Imagine the following conversation at the Sage table:Customer (yes they are customers!): Will I ever have any problems with upgrading?Sage rep: Yep, we will make it so all your old stuff is never upgradeable with essentially no warning other than some cryptic command line thing you don't even see because you only look at your browser!Customer: I didn't hear you right, I think? You mean, "we'll support legacy stuff so long it will make Microsoft look good." I mean, I don't want to still be using .doc in 2020.Sage rep: Nope, we're sort of the opposite; we won't have any 'compatibility mode' nor any incentive to upgrade your old documents; you either go to the new one - oh, by the way, it doesn't do everything the old one does yet - or you just stick with the old kind forever.Yup, I see that as a real winner. And of course this conversation can happen again whenever the next new hit comes out in five years, which it no doubt will.Writing up a very accessible (perhaps even linked to in the warning) translation guide to getting started in Jupyter would be good too. As much as there might be a bigger ecosystem for them, that is not a very compelling argument to me; otherwise we should all be using RStudio and shiny, and well basically just using R for everything. How many of those zillions of easy-to-search sample worksheets are about something like calculating elliptic curve invariants or a nice demo for a graph theory course? Probably just a tiny proportion of the ones about data science or scientific computing.On a separate note, I'm wondering how changing the default will impact those running servers. Which is a higher knowledge crowd but also one who might not be reading sage-devel (in fact likely isn't). Basically, I'm asking about any worst-case scenarios when someone upgrades from (say) 6.7 to 7.2 at the end of a school year and either doesn't read the 'release notes', doesn't even know there are release notes, or our release notes are so minimal as to be useless, or something. (I assume that commercial software has that problem of non-reading too.)
--
Volker Braun
How many of those zillions of easy-to-search sample worksheets are about something like calculating elliptic curve invariants or a nice demo for a graph theory course?
William Stein
--
You received this message because you are subscribed to the Google Groups "sage-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sage-devel+...@googlegroups.com.
To post to this group, send email to sage-...@googlegroups.com.
Visit this group at https://groups.google.com/group/sage-devel.
For more options, visit https://groups.google.com/d/optout.
--
kcrisman
You still haven't understood that this is about how to create new notebooks. We have the legacy support covered by shipping the old notebook. Also, I don't recall Microsoft bundling a free copy of word 2007 with word 2010, you are comparing apples and oranges.
William Stein
It's not "the usual F/LOSS problem", it's the usual problem of a
volunteer project with almost no funding. There is a ton of high
quality well funded FLOSS software out there that doesn't have this
problem (e.g., Firefox, Chromium, parts of OS X, the swift language,
...)
For better or worse, I think we just have to acknowledge the reality of the
situation, and move on and do a very bad job in the above
regards compared to the well funded alternatives until/if we do
eventually get funding. Right now, it is best of the Sage project
focuses squarely on its core competence, which is research level pure
mathematics, (and I hope also undergrad math teaching).
I think there is no question that if some group popped up and
implemented all the automated backwards compatibility, and other nice
things that you describe above, all very good quality, and with proper
review on trac, then Volker would smile and merge it in seconds.
Implementing this stuff we want is precisely what is nearly
impossibly hard for any sane research mathematician to justify
spending serious time on.
For now, let's just move on, make Jupyter (which just got $6,000,000
in funding recently) the default, and deal with the pain and continued
failure to grow. Maybe someday things will be different.
-- William
--
William (http://wstein.org)

Jonathan
William, Volker, et al...
I think you misunderstand Karl. He has stated what is ideal, but I think from his messages that he understands we do not have the manpower within the group of people who can commit time to Sage to make his ideal happen.
What he is asking is that you avoid doing this transition in a manner that blindsides many people who are using Sage (especially for teaching using servers they maintain). If ipynb is going to be the default it needs to launch the first time with messages on the command line and in the browser that explain how to use the Old notebook if necessary and with some advice on conversion, if any exists. It would also be nice to have a brief list of key notebook features that do not yet work in ipynb. I suggest language like:
WARNING!! If you have been using Sagemath using the Sagenotebook (default prior to ____) for interactive Sagemath sessions in a browser, you should be aware that Sagenotebook is no longer the default. The default is ipynb (web link..). You can launch the older Sagenotebook as described below. However, unless you need the following features which do not yet exist in ipynb we recommend you use the new ipynb, as it has better support: ___list of missing features___. To use the the old default ...
Regards,
Jonathan
Volker Braun
I'm adding a Jupyter notebook extension to the sagenb exporter (https://github.com/vbraun/ExportSageNB) to hook into the GUI. So my proposal would be that the initial window will be something like this:

On Friday, December 18, 2015 at 11:35:53 AM UTC+1, Jeroen Demeyer wrote:
Should the Jupyter notebook be the default notebook for the next Sage
7.0 release? I don't really have an opinion on the matter.
Pros:
* Nice tracebacks!
* The Jupyter notebook is a mature well-maintained project, unlike
SageNB. It is widely used in the "scientific Python" community.
* Availability of other Jupyter kernels besides Sage.
Cons:
* Less compatible with Sage: Sage interacts don't work, some graphics
don't work.
* Certain features of SageNB are missing: live documentation,
sharing/publishing of worksheets.
* It clutters the file system with .ipynb files.
Jonathan
Jonathan
Emmanuel Charpentier
Le dimanche 3 janvier 2016 03:52:35 UTC+1, Jonathan a écrit :
This looks like you are on the correct track. I would just urge you to indicate what features of Sagenb are not available yet.
A few things pop to my mind. I already signaled some f them (some might say I ranted about them), but I think that they are stumbling blocks.
- "other language" cells : %maxima and %r (possibly other interpreters such as %octave) do not work as expected. Both %maxima and %r open new instances of their respective interpreters and enter an REPL that cannot be exited (even with an explicit "quit();" or "q('no')". In other words, they never return.
- r("<some call to R graphics>") doesn't display anything in the Jupyter notebook, even when bracketed by r.png() and r.dev_off(). You have to save (r.dev_copy()) the graph and display it in the notebook explicitely. Annoying...
- The latex (mathjax) interface seems to have a few Jupyter-specific quirks. For example, I have been unable to use a "$\frac{a}{b}$" tick marker in a Sage jupyter worksheet. I suspect that the Jupyter notebook doesn't use the (user-configurable) Latex configuration of Sage n the same way as the Sage notebook does.
- I noted that plot3d seems to call a Web-based utility for some plots (one sees messages related to loading data flashing in the region where the jsmol (?) result will be displayed). This might implu that these finctions might be unusable on an unconnected system (I didn't check that yet...).
- In the current implementation, one cannot use some of the features the default 3D renderer (jsmol ?). For example, when one attempts animation, a right-click displays the relevant options, but one cannot activate them.
I think things are close to the point that the only significant thing will be interacts. If plotly is installed, I think good interactive 2D and 3D graphs will be available.
- Interacts : In a Python worksheet, ipywidgets offers a nice interactive framework, ... which turns out no be non obvious to use from a Sage worksheet. A replacement and/or a compatibility layer are needed. (Even if we offer a replacement, a compatibility layer might be useful to ease transition/conversion of old sagenb worksheets).
Yet another interact interface ? That might be interesting if and only if the "new" interface has significantl enhancements over the "old" one...
HTH,
--
Emmanuel Charpentier
Jeroen Demeyer
> * Interacts : In a Python worksheet, ipywidgets offers a nice
> from a Sage worksheet. A replacement and/or a compatibility layer
> are needed. (Even if we offer a replacement, a compatibility layer
> might be useful to ease transition/conversion of old sagenb worksheets).
usable within Sage. This now works using the git master for ipywidgets
(which is not in Sage yet).
Unfortunately, the API of @interact has some significant differences
between SageNB and Jupyter. IMHO, that of SageNB makes more sense but I
have not been able to convince upstream Jupyter of this fact. Jupyter
might have more fancy stuff (like a game controller widget), but fewer
basic "just works" stuff.
I think that a compatibility layer might be possible, but I don't know
if it can cover all features of SageNB interacts.
Jeroen.
Emmanuel Charpentier
- (Very ?) serious : no %cython cells, and no "obvious" shortcut to get them. The "semi-obvious" replacement (%%writefile + load()) is not *that* obvious to realize "cleanly" (no left-over files, etc...). a cell magic would be (more than) nice
- Annoying more than serious : no obvious way to get rid of the "sage:" and "... " prompts when cutting-and-pasting from examples. Not a problem for Sage function, but this pasted medley of code and prompts won't load() cleanly from a file ('indentation error').
HTH,
--
Emmanuel Charpentier
Volker Braun
- "other language" cells : %maxima and %r (possibly other interpreters such as %octave) do not work as expected. Both %maxima and %r open new instances of their respective interpreters and enter an REPL that cannot be exited (even with an explicit "quit();" or "q('no')". In other words, they never return
Emmanuel Charpentier
Le dimanche 3 janvier 2016 16:33:36 UTC+1, Volker Braun a écrit :
On Sunday, January 3, 2016 at 2:41:51 PM UTC+1, Emmanuel Charpentier wrote:
- "other language" cells : %maxima and %r (possibly other interpreters such as %octave) do not work as expected. Both %maxima and %r open new instances of their respective interpreters and enter an REPL that cannot be exited (even with an explicit "quit();" or "q('no')". In other words, they never return
Interactive line magics obviously can't work in the browser like on the command line
The lack of appropriate cell magics (%%maxima) is just an existing bug on the commandline.
Indeed. We should have %%maxima, %%r , %%pari, etc...
[ BTW : that's not really a bug, but rather a design conflict : the original %mode functions were designed to switch (for an indefinite scope) the behaviour of the REPL.This was transposed in the Sage notebook as what amounts to the equivalent of Jupyter's cell magics (scope defined as the current cell). Whereas line magics are, as far as I understand, Jupyter-specific... We can't be consistent across notebooks without redefining our "mode switch" magics as "cell magics", and rename them with "%%"... ]
Of course if you care about it then send in a patch.
I do and I plan to. Therefore, I'm trying to understand how to add such magics to Jupyter. I'm currently swimming (drowning...) on my source tree in order to understand how this should be done. The difficulty is not the code itself, but how to package it as a magic.
Same question about %cython (which should become %%cython ?), with another difficulty : how to define the function in the global namespace as in the command line or Sage notebook... The relevant compile_and_load() function returns a module (from which one can of course import *, which would mimic the current Sage notebook behavior) ; the point is to do this automatically from the magic function).
On the plus side, the jupyter notebook comes with an official R kernel available as Sage optional package: sage -r r_jupyter.
Indeed ! And that's appreciable (and apprecied). The same could be done for various Sage-inclu(ded-dable) languages (pari, octave) for which a Jupyter kernel exists (see this list). Maxima is a special case : the existing Maxima-Jupyter kernel wont't adapt to our ECL-compiled implementation (I asked)...
BTW, your r_jupyter package doesn't appear in the output of sage -installed, nor in the output of sage -optional...
--
Emmanuel Charpentier
William Stein
<emanuel.c...@gmail.com> wrote:
> Dear Volker,
>
> Le dimanche 3 janvier 2016 16:33:36 UTC+1, Volker Braun a écrit :
>>
>> On Sunday, January 3, 2016 at 2:41:51 PM UTC+1, Emmanuel Charpentier
>> wrote:
>>>
>>> "other language" cells : %maxima and %r (possibly other interpreters such
>>> as %octave) do not work as expected. Both %maxima and %r open new instances
>>> of their respective interpreters and enter an REPL that cannot be exited
>>> (even with an explicit "quit();" or "q('no')". In other words, they never
>>> return
>>
>> Interactive line magics obviously can't work in the browser like on the
>> command line
>>
>>
>> The lack of appropriate cell magics (%%maxima) is just an existing bug on
>> the commandline.
>
>
> Indeed. We should have %%maxima, %%r , %%pari, etc...
>
> [ BTW : that's not really a bug, but rather a design conflict : the original
> %mode functions were designed to switch (for an indefinite scope) the
> behaviour of the REPL.This was transposed in the Sage notebook as what
> amounts to the equivalent of Jupyter's cell magics (scope defined as the
> current cell). Whereas line magics are, as far as I understand,
> Jupyter-specific... We can't be consistent across notebooks without
> redefining our "mode switch" magics as "cell magics", and rename them with
> "%%"... ]
%foo <stuff on the line>
and a cell mode is
%foo(optional, arguments)
<rest of the cell>
In SMC %foo is just foo('... rest of line or cell...'), with some
optional hooks (e.g., support foo.eval for backwards compat with
sage). So a "magic" is much less magic -- just define any function
that takes a string as input, and you've written one.
I don't use %% anywhere.
I don't care what you do with Jupyter, but I'm sticking with this
design for cell modes, and definitely won't change.
-- William
Volker Braun
In case you are curious, in SageMathCloud worksheets a line mode is
%foo <stuff on the line>
and a cell mode is
%foo(optional, arguments)
<rest of the cell>
Jeroen Demeyer
> how to define the function in the global namespace
> as in the command line or Sage notebook... The relevant
> compile_and_load() function returns a module (from which one can of
> course import *, which would mimic the current Sage notebook behavior) ;
> the point is to do this automatically from the magic function).
support in the magic function.
This is part of http://trac.sagemath.org/ticket/18083
Volker Braun
[ BTW : that's not really a bug, but rather a design conflict : the original %mode functions were designed to switch (for an indefinite scope) the behaviour of the REPL.This was transposed in the Sage notebook as what amounts to the equivalent of Jupyter's cell magics (scope defined as the current cell). Whereas line magics are, as far as I understand, Jupyter-specific... We can't be consistent across notebooks without redefining our "mode switch" magics as "cell magics", and rename them with "%%"... ]
Emmanuel Charpentier
Le dimanche 3 janvier 2016 21:23:56 UTC+1, Volker Braun a écrit :
On Sunday, January 3, 2016 at 5:36:30 PM UTC+1, Emmanuel Charpentier wrote:[ BTW : that's not really a bug, but rather a design conflict : the original %mode functions were designed to switch (for an indefinite scope) the behaviour of the REPL.This was transposed in the Sage notebook as what amounts to the equivalent of Jupyter's cell magics (scope defined as the current cell). Whereas line magics are, as far as I understand, Jupyter-specific... We can't be consistent across notebooks without redefining our "mode switch" magics as "cell magics", and rename them with "%%"... ]IMHO we should just switch the interface line magics to work like other line magics in Jupyter/IPython, and also SMC: Take the rest of the line as string and evaluate
As stated, that would break the compatibility with SMC magics that William just declared intangible (and always "cell magic"). This could be (more or less) restored if the magic function had access to the current interface. Pseudo-Python ahead :
args, input=(RestOfTheFirstLline(), RestOfTheCell())
if(SMC):
ReturnAndPrint(magicfun(input))
if(commandline): ## In that case, by definition, input==None
if(restofthefirstline=""):
switchREPLuntilEOFOrOtherMagic(magicfun())
else:
ReturnAndPrint(magicfun(args))
else: ## Jupyter
ProcessOptions(args)
ReturnAndPrint(magicfun(input, ProcessedOptions))
The difficulty is, of course, that the same part of the command structure (the rest of the first line) would mean two different things :
- source code to execute in a command line
- possible options to be passed to a cell magic in Jupyter (some interface, already supported (rpy2, the IRkernel for R) already use this convention !).
Furthermore, I supposed that SMC ignored the rest of the first line. This is what the %r magic does
%r print(2+2)
print(3+2)
## prints [1] 5, even if the pasted result is a bit more complicated :
︡3c5a5418-14e0-46fe-a34d-3fa7a0eb1b7d︡︡{"stdout":"[1] 4","done":false}︡{"stdout":" 5\n","done":false}︡{"done":true}
︠68da460a-f070-4758-9fbb-667f85c4819es︠
but not the %maxima magic :
%maxima diff(log(x),x)
integrate(arctan(x),x)
## prints 1/x on one line, then x*arctan(x) - 1/2*log(x^2 + 1) on the next line, but again the reality is a bit more complicated :
︡410cbb81-a181-4e01-92a0-0c3e28da800a︡︡{"stdout":"1/x","done":false}︡{"stdout":"\n","done":false}︡{"stdout":"x*arctan(x) - 1/2*log(x^2 + 1)\n","done":false}︡{"done":true}
︠e820fb8a-cd58-4173-9d99-95dd022e4a6f︠
Therefore, we have a specification/consistency problem, to be solved BEFORE the coding problem(s).
We should also specify what happens with the computed results : are they just displayed in the output cell and kept in the target interpreterv instance ? (In that case, we should be damn sure that we vcan get the results back by other means, such as r() after an %r cell, or maxima() after a %maxima computation). Or should we try to return something ? If so, how ?
We should also specify how to pass data to the called interpreter, and back to Sage. At least in the case of r(), it is hard to get anything else than string representations. One point of using %R is that this dat interchange problem is at least treated consistently.
Note that the "coding problems" are not that small : ensuring that r(...), %r, %R and %%R "speak" to the same instance of R does not seem trivial (at least for my midget capacities)...
Example for IPython default magic:sage: %system ls Makefile['Makefile']Example for how we currently handle line magics on the commandline (BAD: we just forget about the argument)sage: %gap 1+1;--> Switching to Gap <--gap: ^C--> Exiting back to Sage <--Expected behavoir of %gap 1+1; is to be likesage: gap('1+1;')2On the commandline ONLY line magics without arguments could still switch the interface
Should we open a ticket for this, or should we continue to discuss the specificatin here, opening tickets for the actual coding ?
HTH (but doubting it...),
--
Emmanuel Charpentier
Volker Braun
Note that the "coding problems" are not that small : ensuring that r(...), %r, %R and %%R "speak" to the same instance of R does not seem trivial
William Stein
<emanuel.c...@gmail.com> wrote:
>
>
> Le dimanche 3 janvier 2016 21:23:56 UTC+1, Volker Braun a écrit :
>>
>> On Sunday, January 3, 2016 at 5:36:30 PM UTC+1, Emmanuel Charpentier
>> wrote:
>>>
>>> [ BTW : that's not really a bug, but rather a design conflict : the
>>> original %mode functions were designed to switch (for an indefinite scope)
>>> the behaviour of the REPL.This was transposed in the Sage notebook as what
>>> amounts to the equivalent of Jupyter's cell magics (scope defined as the
>>> current cell). Whereas line magics are, as far as I understand,
>>> Jupyter-specific... We can't be consistent across notebooks without
>>> redefining our "mode switch" magics as "cell magics", and rename them with
>>> "%%"... ]
>>
>>
>> IMHO we should just switch the interface line magics to work like other
>> line magics in Jupyter/IPython, and also SMC: Take the rest of the line as
>> string and evaluate
>
>
> As stated, that would break the compatibility with SMC magics that William
> just declared intangible (and always "cell magic").
guys are coming up with in this thread is compatible with SMC Sage
worksheets. SMC provides both Sage worksheets and Jupyter notebooks
on an equal footing; each has its pros and cons, and will continue to
be fully supported (likely with a converter between them, that at
least converts what can be converted).
> You received this message because you are subscribed to the Google Groups
> "sage-devel" group.
> To unsubscribe from this group and stop receiving emails from it, send an
> email to sage-devel+...@googlegroups.com.
> To post to this group, send email to sage-...@googlegroups.com.
> Visit this group at https://groups.google.com/group/sage-devel.
> For more options, visit https://groups.google.com/d/optout.
--
kcrisman
> As stated, that would break the compatibility with SMC magics that William
> just declared intangible (and always "cell magic").
Just to be clear: I don't care whether or not whatever design you
guys are coming up with in this thread is compatible with SMC Sage
worksheets. SMC provides both Sage worksheets and Jupyter notebooks
on an equal footing; each has its pros and cons, and will continue to
be fully supported (likely with a converter between them, that at
least converts what can be converted).
William Stein
Thank you Jonathan for clarifying what I thought was obvious in what I was saying.> As stated, that would break the compatibility with SMC magics that William
> just declared intangible (and always "cell magic").
Just to be clear: I don't care whether or not whatever design you
guys are coming up with in this thread is compatible with SMC Sage
worksheets. SMC provides both Sage worksheets and Jupyter notebooks
on an equal footing; each has its pros and cons, and will continue to
be fully supported (likely with a converter between them, that at
least converts what can be converted).
I would be interested in why SMC provides Sage worksheets if Jupyter is so *clearly* the most superior option. [Rhetorical question]
And what of the long-term in Sage itself - would an eventual "SMC personal edition" become the default? [Not rhetorical but probably too far in the future to speculate]
--
You received this message because you are subscribed to the Google Groups "sage-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sage-devel+...@googlegroups.com.
To post to this group, send email to sage-...@googlegroups.com.
Visit this group at https://groups.google.com/group/sage-devel.
For more options, visit https://groups.google.com/d/optout.
kcrisman
> As stated, that would break the compatibility with SMC magics that William
> just declared intangible (and always "cell magic").
Just to be clear: I don't care whether or not whatever design you
guys are coming up with in this thread is compatible with SMC Sage
worksheets. SMC provides both Sage worksheets and Jupyter notebooks
on an equal footing; each has its pros and cons, and will continue to
be fully supported (likely with a converter between them, that at
least converts what can be converted).
I would be interested in why SMC provides Sage worksheets if Jupyter is so *clearly* the most superior option. [Rhetorical question]Weird question, given that I literally just wrote "Sage worksheets and Jupyter notebooks on an equal footing; each has its pros and cons, and will continue to be fully supported". There are many ways in which Sage worksheets are superior to Jupyter notebooks, and some very nontrivial subtle new things I've been working on the last month that will lead to more...
And what of the long-term in Sage itself - would an eventual "SMC personal edition" become the default? [Not rhetorical but probably too far in the future to speculate]No clue. There's no legal or technical reason it couldn't happen... This year it likely won't as SMC is still changing way too much.
William Stein
> The question wasn't for you, but for all those who early in this thread said
> how awesome Jupyter was. But thank you for confirming.
exclusively, and remain a little ignorant of the other one. There are
notable exceptions though, like Jason Grout who works a huge amount on
Jupyter development now (for pay!), but is also very knowledgable
about Sage. Personally, I'm looking at Jupyter-related stuff today,
since I'm rewriting (again) how synchronized editing works, and trying
to address various issue...
One example of a subtle feature in Sage (notebook and worksheets) not
in Jupyter, which I was just reminded of, is output limiting. In Sage
there are numerous rules/options to deal with people doing stuff like:
while True:
print "hi!"
... which is exactly what students will tend to do by accident...
Jupyter doesn't deal with this, but it might not be too hard to
implement in theory. One of the main problems is figuring out what
the arbitrary rate limiting defaults "should" be; it's arbitrary, and
depends a lot on whether everything is local, over the web, etc. so
getting a bunch of people to agree is hard, which might mean they will
never implement anything.
Another basic -- and much harder to implement(!) -- subtle feature of
the sage notebook (and SMC) that Jupyter doesn't have is the
following. Try typing
import time
for i in range(10):
time.sleep(1)
print i
and closing your browser half way through. In Sagenb (and sagews)
it'll compute all the output and put it in the browser, where you'll
find it later when you visit the page. In Jupyter, all the output
that appears when you aren't observing the computation is lost. I
remember in maybe 2006 or 2007 implementing this and that it was very
important to researchers -- you can just start:
for n in range(100):
print n, important_function_of(n)
and come back tomorrow and see the result -- researchers *love* to be
able to do that without having to worry. With Jupyter, you have no
choice but to create a file, and output each result to that file, then
look in the file later; this is a bigger cognitive load.
Implementing the above (recording all output without the browser
client open) requires adding a slightly nontrivial idea to how
Jupyter is implemented, so I don't think it's likely to be really
easy.
Don't worry -- I've repeatedly mentioned the above differences to many
Jupyter developers, and I'm sure they will get addressed, since there
are a ton of people working on Jupyter.
Anyway, there are many subtle differences... Everything can be worked
around, of course.
>
>>>
>>> And what of the long-term in Sage itself - would an eventual "SMC
>>> personal edition" become the default? [Not rhetorical but probably too far
>>> in the future to speculate]
>>
>>
>> No clue. There's no legal or technical reason it couldn't happen... This
>> year it likely won't as SMC is still changing way too much.
>
>
> So technical reason in the sense that even if someone did it, it would
> require a lot of maintenance to keep up with official SMC.
>
> +++
>
> On a less sarcastic note (and my apologies for that) I'm wondering what the
> status of Jupyterhub (the multi-user Jupyter, right?) is right now. Active
> development, but so is HURD... not that I am expecting it to take 30 years
> to produce! Just curious if there are any inside scoops. Proper migration
> of entire servers being possible would be a much bigger reason to change the
> default.
>
Volker Braun
William Stein
> I'd also be more than happy to ship the personal SMC edition with sage when
> its ready; But sticking with the essentially unsupported SageNB for 1+years
> just to wait&see is not a sane plan. Even then, jupyter notebooks are a
> forward-safe choice so we have nothing to gain from waiting while people
> write new SageNB notebooks.
matter what, which makes Jupyter notebooks even safer.
> As for the Jupyter wishlist, proper output capture would also be nice. Right
> now only the Python-internal stdout is captured, but for example
>
> sage: cython(r'printf("test\n")')
> test
>
> yields no output in Jupyter.
>
> There are at least two different multi-user Jupyter versions that are of
> interest; the authenticated (via unix account, much better than SageNB)
> jupyterhub and the anonymous https://tmpnb.org (try it now if you haven't
> seen it)
moment I write this, there are 59 jupyter notebooks running on SMC --
see "Running Instances" here:
https://cloud.sagemath.com/b97f6266-fe6f-4b40-bd88-9798994a04d1/raw/metrics/metrics.html
Volker Braun
kcrisman
I'd also be more than happy to ship the personal SMC edition with sage when its ready; But sticking with the essentially unsupported SageNB for 1+years just to wait&see is not a sane plan. Even then, jupyter notebooks are a forward-safe choice so we have nothing to gain from waiting while people write new SageNB notebooks.As for the Jupyter wishlist, proper output capture would also be nice. Right now only the Python-internal stdout is captured, but for examplesage: cython(r'printf("test\n")')testyields no output in Jupyter.There are at least two different multi-user Jupyter versions that are of interest; the authenticated (via unix account, much better than SageNB) jupyterhub and the anonymous https://tmpnb.org (try it now if you haven't seen it)

Jason Grout
On Sunday, December 20, 2015 at 5:25:52 PM UTC-7, Volker Braun wrote:
If you start Jupyter in ~/foo then you cannot open notebooks in ~/.sage/jupyter. Thats just how it is.On Monday, December 21, 2015 at 1:12:57 AM UTC+1, William wrote:I clearly don't agree with that, since that's never been the case
before, as I mentioned. I'll not press this any further.
Jason Grout
On Tuesday, January 5, 2016 at 8:17:45 AM UTC-7, William wrote:
One example of a subtle feature in Sage (notebook and worksheets) not
in Jupyter, which I was just reminded of, is output limiting. In Sage
there are numerous rules/options to deal with people doing stuff like:
while True:
print "hi!"
... which is exactly what students will tend to do by accident...
Jupyter doesn't deal with this, but it might not be too hard to
implement in theory. One of the main problems is figuring out what
the arbitrary rate limiting defaults "should" be; it's arbitrary, and
depends a lot on whether everything is local, over the web, etc. so
getting a bunch of people to agree is hard, which might mean they will
never implement anything.
Jason Grout

Jonathan Frederic
Jason Grout
---------- Forwarded message ----------
From: Jonathan Frederic <jon.f...@gmail.com>
Date: Tue, Jan 5, 2016 at 11:42 AM
Subject: Re: [sage-devel] Re: Jupyter notebook by default?
To: Jason Grout <grout...@gmail.com>
Cc: sage-devel <sage-...@googlegroups.com>
Jason,Thanks for pulling me in on this.William,
I agree, getting a bunch of people to agree on stuff can seem impossible. However, you mention Sage offers a couple options to mitigate output overflows, can you point me to those options? The Jupyter Notebook should provide multiple options too - this will also make it easier for everyone to agree.Also, in you experience, which of these options work the best?
I was thinking initially of doing something simple, like hard limiting data/time, then printing an error if that's exceeded. In the Jupyter Notebook, we have to worry about- Too many messages sent on the websocket- The notebook json file growing too large and consequently becoming unopenable- Too much data being appended to the DOM, crashing the browserThanks!-Jon
On Tue, Jan 5, 2016 at 10:19 AM, Jason Grout <grout...@gmail.com> wrote:
William Stein
(cross-posting to ipython-dev)Jon,At the recent San Francisco meetings, we talked about this. What do you think about:1. keeping track of the size of the io messages sent from any specific kernel execution2. When the total size of io reaches some specific size (user-configurable), transmitting a special "throwing away output, but here's how to save the output to a file if you want in the future, or how to increase the limit" message3. keep a running buffer of the last bit of output attempted to be sent, and send it when the execution finishes (so basically a ring buffer that overwrites the oldest message)This:* allows small output through* provides an explanatory message* provides the last bit of output as wellOne thing to figure out: a limit on size of output that is text may not be appropriate for output that is images, etc.
Jeroen Demeyer
> FYI, Sylvain Corlay is making some changes to ipywidgets to bring them
> more into line with the Sage syntax. He said in the Jupyter dev meeting
> just now that he'll be making a PR today.
https://github.com/ipython/ipywidgets/issues/238 that @ellisonbg was the
main person who needed to be convinced.
Jeroen.
kcrisman
Jason Grout
Jeroen.
Jason Grout
I know this is now hijacking the thread... but if we are on those lines, when it comes to "too much output", making sure that this is something that can allow people to easily see and compare an "old" "too much output" to a "new" "too much output" after evaluating a cell/command a second/several time/s would be very helpful - we've had numerous requests along those lines. Doubtless this is already in the works though - nice to hear from you, Jason! :)
--
kcrisman
On Tuesday, January 5, 2016 at 5:18:27 PM UTC-5, Jason Grout wrote:
I'm not sure exactly what you mean here. Can you give an example?
Volker Braun
Jeroen Demeyer
> And certainly nobody wants a piece of
> their output discarded in a long-running computation.
should still be available somehow.

Min RK
On Wednesday, January 6, 2016 at 10:05:32 AM UTC+1, Volker Braun wrote:
IMHO output capture into a web browser isn't really different from the scrollback buffer of a terminal. We obviously enjoy the infinite scrollback but do not want an unbounded drawing surface in the terminal (= dom nodes in the web browser). And certainly nobody wants a piece of their output discarded in a long-running computation.The technical implementation is virtual scrolling, this is what the terminal does and this is how the browser should do it, too.
Jon mentioned that there are a few levels for large output to cause problems. The lowest bar is putting the output on the page, which is by far the easiest to hit, causing an unresponsive browser. This is the level that can be addressed by virtual scrolling / truncating output in UI. Fortunately, it’s also the easiest one to implement.
If we truncate instead of virtual-scroll, then we have a choice for whether truncated output is included in the document or not, which alleviates the problem of opening notebooks that have a problematic amount of output. But it’s putting that on the page that’s ~always the problem, not loading the notebook JSON itself, so I’m somewhat less concerned about that.
The next level where it can cause problems is the output coming over the network in the first place. We can throttle this in the notebook server, as was implemented for 4.2 months ago. Again, this moves the bar for when output causes trouble, but isn’t a complete solution. Dumping truncated output to a file is complicated a bit by the separations we have in place, but it should be doable.
-MinRK
Volker Braun
If we truncate instead of virtual-scroll, then we have a choice for whether truncated output is included in the document or not, which alleviates the problem of opening notebooks that have a problematic amount of output
MinRK
On Wednesday, January 6, 2016 at 11:55:36 AM UTC+1, Min RK wrote:If we truncate instead of virtual-scroll, then we have a choice for whether truncated output is included in the document or not, which alleviates the problem of opening notebooks that have a problematic amount of output
There is no fundamental problem with large amounts of output (really, any content), and there is essentially only a single way to do it right:The view (dom) needs only a fixed number of dom nodes for a virtual scroll.The in-browser view model can lazily load the current scroll position, with a suitable cache. Fixed amount of browser JS memory.The server can just mmap the output file, or alternatively seek around in the file. With a suitable index. Fixed amount of server-side memory.
The kernel has to block if the notebook server can't append output fast enough, thats normal flow control just like in a pipe. Fixed memory usage in the kernel.
--
You received this message because you are subscribed to a topic in the Google Groups "sage-devel" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/sage-devel/8erxWppKxXM/unsubscribe.
To unsubscribe from this group and all its topics, send an email to sage-devel+...@googlegroups.com.
Volker Braun
Files aren't used for output. The filesystem should only be involved, if at all, in the exceptional case of output overflow.
MinRK
Thanks Jason for cross-posting.
Since the issue of funding was brought up, I think supporting projects like this is exactly the sort of thing we should be doing with the funding we have, whether the work sits on the Jupyter or Sage side (I assume there will be both). It’s a bit tricky to keep track of all the points in an email thread, but if we could aggregate the things that are blockers and the things that would be nice, especially changes you need from Jupyter, we should be able to start ticking boxes.
A summary of what I’ve seen so far:
- sage interacts
- language cells
- document conversion from sagenb to ipynb
- low-level output capturing
- gracefully handling large output
Some comments:
Re: language cells, I assume it’s referring to things like %%bash, %%R, and %%cython. While these look similar, there is a significant difference in how they are implemented. For instance, the R magic (provided by rpy2) runs an R interpreter in-memory, and talks to it, capturing output, etc.. Where many of these magics, such as bash, ruby, perl, come from is some “script magic” machinery in IPython, which populates the default magics with shortcuts to running a script in a given interpreter. They are essentially shortcuts to cat <cell> | <interpreter>. It’s not a fundamental limitation, or anything dire like that. If sage has an implementation of running code in a persistent alternate interpreter, then it should not be much work to represent that in magics, since cell magics are any Python functions called with two string arguments (the rest of the line and the cell), and can be defined at any time, for instance:
def mymagic(line, cell):
do_stuff_with(cell)
get_ipython().register_magic_function(mymagic, 'cell')
Re: output capturing, Thomas Kluyver and I were at CERN last month working on the Cling kernel, and one of the things we did was C-level capturing of output. Now that we have that working, integrating it into the IPython kernel should not be much work, and if it’s really important, libraries can use the same technique themselves without waiting for IPython to catch up.
Interacts are perhaps the hardest piece. I think it should be doable to get sage’s own interacts working in the notebook, rather than forcing people to adopt the much more basic interact provided by the IPython widgets.
I can’t speak to the UI transition part of the problem whenever you change defaults, which is a big challenge, but I think we can at least mitigate most of the things on the Jupyter side that are getting in your way.
-MinRK
_______________________________________________
IPython-dev mailing list
IPyth...@scipy.org
https://mail.scipy.org/mailman/listinfo/ipython-dev

Thierry
On Thu, Jan 07, 2016 at 11:48:05AM +0100, MinRK wrote:
[...]
> - document conversion from sagenb to ipynb
We should probably better focus on a good rst2ipynb translator.
Indeed, there is a "sage -sws2rst" command already. This will have the
benefit to be helpful for more people than just Sage users, and help us
going towards Jupyter live documentation i.e. ipynb files connected
together with a bit of sphinx (i dont' know if it is possible to add a
navigation bar to ipynb worksheets, or use frames, or whatever ?).
Moreover, all the developpers i met during tutorials and schools write
their tutorials in .rst, simply because it is human writeable, it is easy
to copy-paste from existing Sage doctests and tutorials, and can be easily
versionned/shared/imported.
Though json is far better than tar.bz or xml from the human point of view,
it is still too verbose to be considered as a source format for
worksheets, moreover from my little experience, people who write tutorials
prefer to use an editor/IDE/whatever than a webpage.
With pandoc and notedown, it is easy to do basic translation rst -> md ->
ipynb. The main remaining task is to let the code blocks clever, that is:
::
sage: a = 1
sage: 2*a
2
sage: 1+1
2
should be translated in ipynb as (simplified)
cell:
type: code
language: sage
input:
a = 1
2*a
output:
2
cell:
type: code
language: sage
input:
1+1
output:
2
which is not the case when piping pandoc and notedown (we obtain a single
input block, and the `sage:` are not removed).
Another separate hook could deal with Sage specific tweaks (e.g. `blah`
for :math:`blah`)
Ciao,
Thierry
kcrisman
MinRK
These all sound like awesome ideas to me for moving more *robustly* to a sws -> ipynb transition! Would attached files work properly (or at all)? I'm only asking out of ignorance.
--
You received this message because you are subscribed to a topic in the Google Groups "sage-devel" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/sage-devel/8erxWppKxXM/unsubscribe.
To unsubscribe from this group and all its topics, send an email to sage-devel+...@googlegroups.com.
Volker Braun
On Sunday, January 3, 2016 at 4:33:36 PM UTC+1, Volker Braun wrote:
Interactive line magics obviously can't work in the browser like on the command lineThe lack of appropriate cell magics (%%maxima) is just an existing bug on the commandline.
Volker Braun


Henri Girard
Le vendredi 18 décembre 2015 11:35:53 UTC+1, Jeroen Demeyer a écrit :
Should the Jupyter notebook be the default notebook for the next Sage
7.0 release? I don't really have an opinion on the matter.
Pros:
* Nice tracebacks!
* The Jupyter notebook is a mature well-maintained project, unlike
SageNB. It is widely used in the "scientific Python" community.
* Availability of other Jupyter kernels besides Sage.
Cons:
* Less compatible with Sage: Sage interacts don't work, some graphics
don't work.
* Certain features of SageNB are missing: live documentation,
sharing/publishing of worksheets.
* It clutters the file system with .ipynb files.
Don't cares:
* It's just a default choice, both options remain available.
kcrisman
* You have to learn markdown to do anything useful in plain old text.
Don't tell me this isn't a con. (If it's not accurate, please tell me! I just couldn't figure out how to get
Now, I know enough md to get by. Lots of people use it. Lots of *other* people (see, I used it!) would rather have at least SOME whizzy-wig capability. 'Cuz why else does the interface I'm using right now in Google Groups have things like this or this or even bullet lists to click (perhaps they use TinyMCE themselves)? It should be just as much about reducing learning curves as the "right" solution. I hate having to remember if links are [like this](url) or (this)[url] or even [url like this] (oh wait, that's the Trac style). Google lets me do this with a simple click.
To be productive on this front and not just complain, I did a fair amount of searching for wysiwyg or tinymce and jupyter and found almost nothing. Could this be a replacement? https://github.com/bollwyvl/nb-wysiwyg I also found this nice article which (correctly) claims "Why is Markdown better? Well, it’s worth saying that maybe it isn't. Mainly, it’s not actually a question of better or worse, but of what’s in front of you and of who you are. A definitive answer depends on the user and on that user’s goals and experience. These Notebooks don't use Markdown because it's definitely better, but rather because it's different and thus encourages users to think about their work differently." But not everyone, especially those instructors in a hurry, have time to think about that on a first try. If they end up writing a book I hope they do! But if they just want to make an example for class it's a bit much.
Hopefully Jupyter will be able to have an option to have wysiwyg eventually, though I understand that might conflict with their design goals. In which case their design goals are not really for non-programmers.
Practical example, lest someone think I'm beating up on a straw notebook interface:
Someone makes an awesome 3d plot in Jupyter with vectors and parametric things in red, blue, and green, labeling different things. Now in the main body of their text they want the same output, so they can talk about green tangent vectors, blue normal vectors, and red curves, or something, in those colors. Lovely stuff. They Google how to do this in md and get:
http://stackoverflow.com/questions/19746350/how-does-one-change-color-in-markdown-cells-ipython-notebook
Result: the text stays all black for the presentation they have to do in ten minutes.
Jason Grout
--
You received this message because you are subscribed to the Google Groups "sage-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sage-devel+...@googlegroups.com.
Jason Grout
William Stein
> Another con I just discovered:
> * You have to learn markdown to do anything useful in plain old text.
>
> Don't tell me this isn't a con. (If it's not accurate, please tell me! I
> just couldn't figure out how to get
>
> Now, I know enough md to get by. Lots of people use it. Lots of *other*
> people (see, I used it!) would rather have at least SOME whizzy-wig
> capability. 'Cuz why else does the interface I'm using right now in Google
> Groups have things like this or this or even bullet lists to click (perhaps
> they use TinyMCE themselves)? It should be just as much about reducing
> learning curves as the "right" solution. I hate having to remember if links
> are [like this](url) or (this)[url] or even [url like this] (oh wait, that's
> the Trac style). Google lets me do this with a simple click.
editing markdown in Sage worksheets, and also a realtime preview
markdown editor for md files. Two screenshots attached. I also fully
implemented a realtime WYSIWYG editor for html and markdown a year
ago, but decided it wasn't up to my standards (getting realtime sync
to fully work well was surprisingly challenging), so I
disabled/removed it. Prosemirror was closed source at that time, or
I would have integrated it in SMC instead of writing my own version of
it, then giving up, and running out of time. Maybe later.
--
William (http://wstein.org)
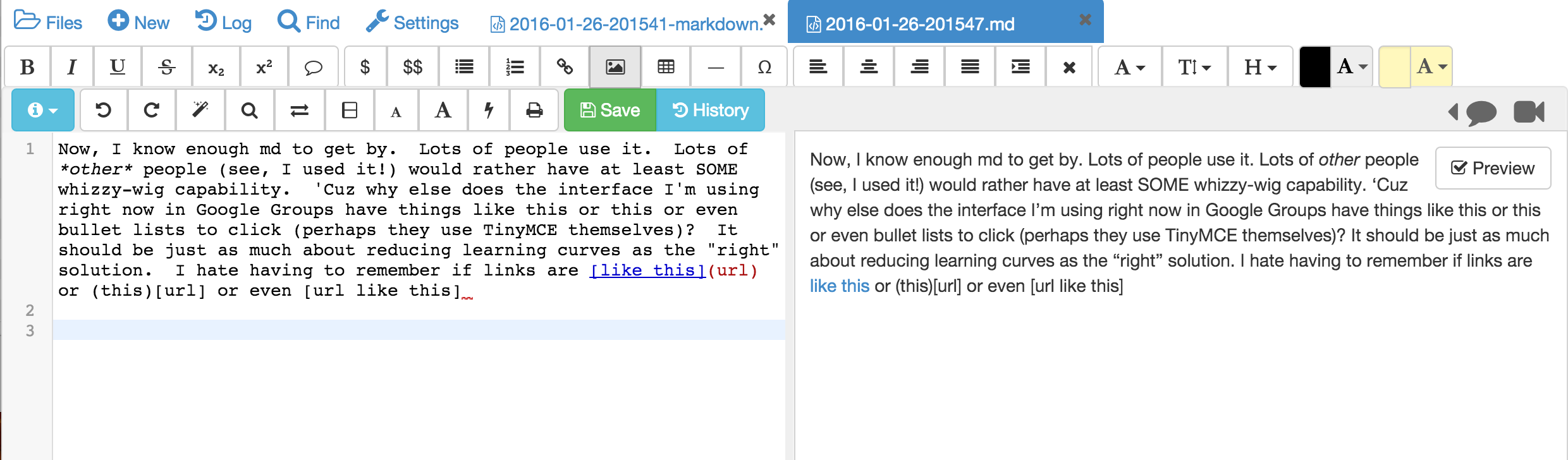{kind=link}
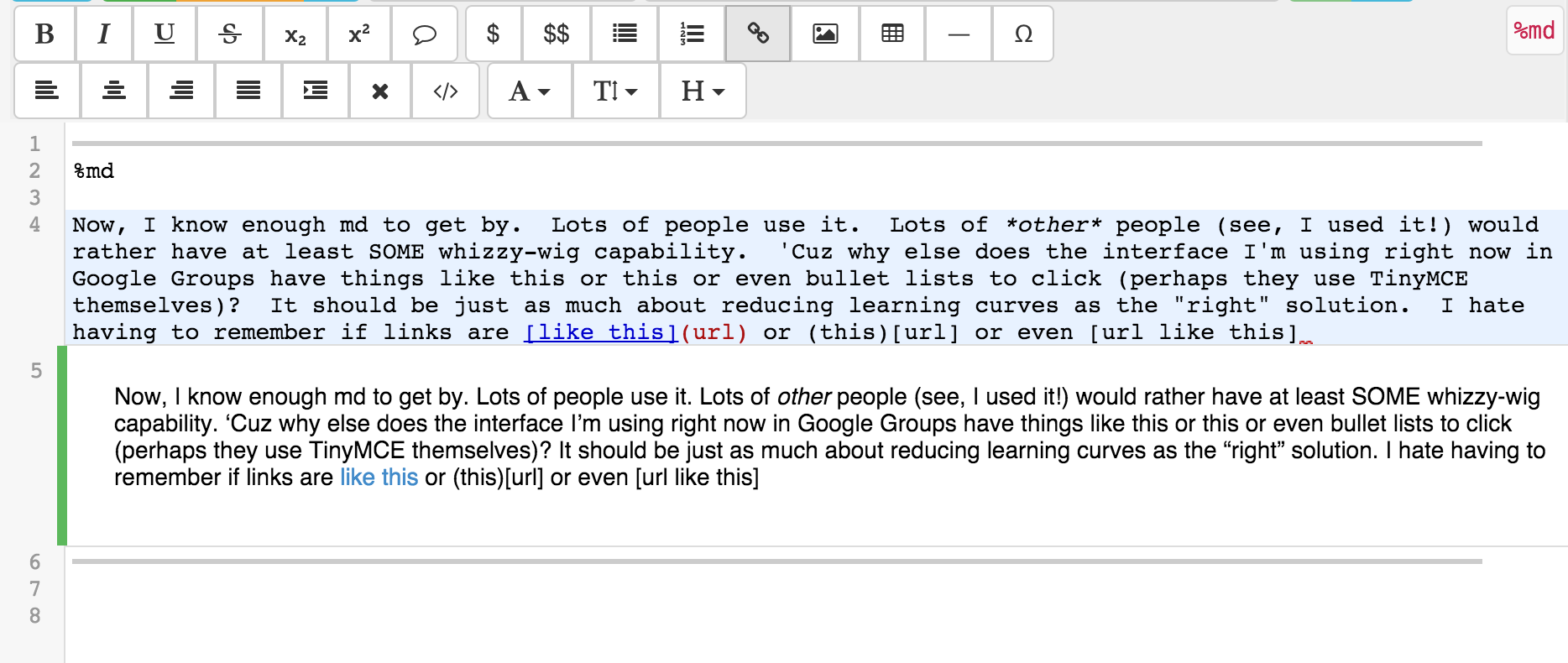{kind=link}
kcrisman
What if we used something like ProseMirror for the markdown editor? http://prosemirror.net/. Would that help? Right now we use Codemirror.
This seems like a step in the right direction. We don't need "flawless" copying of TinyMCE, for instance, but no ability to do wysiwyg in the text cells would definitely be unfortunate for that market segment, as it were.
This? Even finding things between TinyMCE and md is
http://leeoniya.github.io/reMarked.js/
kcrisman
For what it is worth, SageMathCloud has a buttons/lists, etc. for
editing markdown in Sage worksheets, and also a realtime preview
markdown editor for md files. Two screenshots attached. I also fully
implemented a realtime WYSIWYG editor for html and markdown a year
ago, but decided it wasn't up to my standards (getting realtime sync
to fully work well was surprisingly challenging), so I
disabled/removed it.
Oh yeah, I forgot that I get very confused trying to make text cells in SMC too :( presumably for the same reason that I don't want to type %md - but I don't use SMC much (yet). I'm surprised that there isn't more stuff out there trying to do fully-featured wysiwyg md editing, actually, obviously it is completely orthogonal to the math and of very general interest. Huh.
kcrisman
Oh yeah, I forgot that I get very confused trying to make text cells in SMC too :( presumably for the same reason that I don't want to type %md - but I don't use SMC much (yet).
(I.e. this might be awesome after all but I haven't gotten that far!)
William Stein
--
You received this message because you are subscribed to the Google Groups "sage-devel" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sage-devel+...@googlegroups.com.
To post to this group, send email to sage-...@googlegroups.com.
Visit this group at https://groups.google.com/group/sage-devel.
For more options, visit https://groups.google.com/d/optout.
Sent from my massive iPhone 6 plus.
kcrisman
I surprisingly don't remember even one user request for such tinymce style wysiwyg editing for SMC. And our users are constantly asking for the functionality they feel they really need... I'm very surprised by this lack of demand. However maybe they don't know what they want.
kcrisman
Jason Grout
--
Jason Grout
kcrisman
A bit more robust in escaping:
Volker Braun

Jason Grout
--
kcrisman
On Friday, September 9, 2016 at 6:51:00 PM UTC-4, Jason Grout wrote:
Nice! That's even better that it works out-of-the-box!