testing PyFR - 3d cylinder - openmp extremely slow
119 views
Skip to first unread message

Junting Chen
Jun 11, 2019, 6:26:27 PM6/11/19
to PyFR Mailing List
Hello developers,
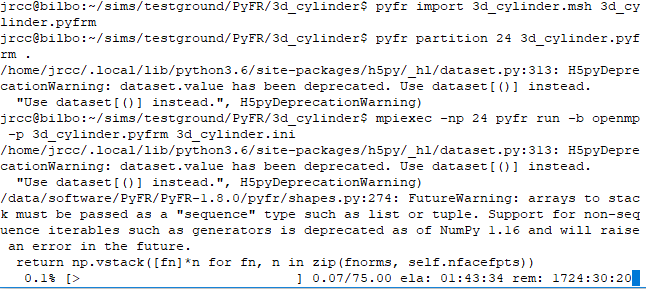
I am on a task of testing several CFD codes with the goal of finding one that suits the best of our needs. I am seeing a lot of potential in PyFR and would like to run a couple of cases on it. The 2d cases that came with the program are nice. Strange thing is that two or more partitions perform slower than one partition. Then I was thinking probably a 2d case might not be big enough, as someone has stated they were designed to run on single core in another post.
So I created this 3d cylinder case (ini and msh file can be found in the attachment). I am trying to run it on the openmp backend at the moment. It is extremely slow. I read that Dr.Vincent said a 3d case setup file was attached to a publication. I could not find it yet. I hope can take a look at it.
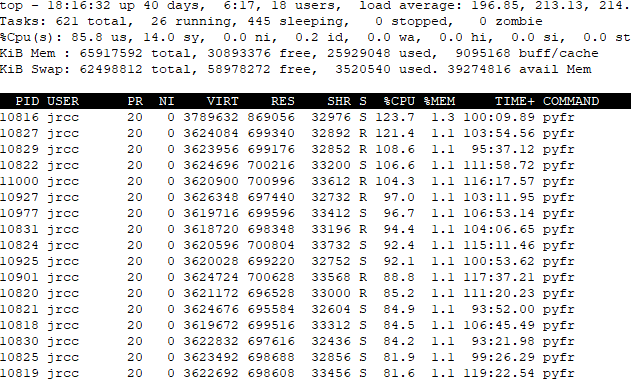
Also I tried to run it on GPU (Tesla k80) on a virtual machine, it would always take one core and shut down the rest at very beginning. I can't provide the error message now. I feel like I need to update the openmpi to 4.0 (current 1.10).
Thanks,
Junting Chen

Vincent, Peter E
Jun 11, 2019, 6:34:12 PM6/11/19
to Junting Chen, PyFR Mailing List
Hi Junting,
Thanks for your interest in PyFR.
I read that Dr.Vincent said a 3d case setup file was attached to a publication. I could not find it yet.
You can find some 3D cases here, for example:
Regards
Peter
Dr Peter Vincent MSci ARCS DIC PhD FRAeS
Reader in Aeronautics and EPSRC Fellow
Department of Aeronautics
Imperial College London
South Kensington
London
SW7 2AZ
UK
Reader in Aeronautics and EPSRC Fellow
Department of Aeronautics
Imperial College London
South Kensington
London
SW7 2AZ
UK
On 12 Jun 2019, at 00:26, Junting Chen <chen...@gmail.com> wrote:
Hello developers,
I am on a task of testing several CFD codes with the goal of finding one that suits the best of our needs. I am seeing a lot of potential in PyFR and would like to run a couple of cases on it. The 2d cases that came with the program are nice. Strange thing is that two or more partitions perform slower than one partition. Then I was thinking probably a 2d case might not be big enough, as someone has stated they were designed to run on single core in another post.
So I created this 3d cylinder case (ini and msh file can be found in the attachment). I am trying to run it on the openmp backend at the moment. It is extremely slow. I read that Dr.Vincent said a 3d case setup file was attached to a publication. I could not find it yet. I hope can take a look at it.
<aasdf.PNG>
Also I tried to run it on GPU (Tesla k80) on a virtual machine, it would always take one core and shut down the rest at very beginning. I can't provide the error message now. I feel like I need to update the openmpi to 4.0 (current 1.10).
Thanks,
Junting Chen
--
You received this message because you are subscribed to the Google Groups "PyFR Mailing List" group.
To unsubscribe from this group and stop receiving emails from it, send an email to pyfrmailingli...@googlegroups.com.
To post to this group, send email to pyfrmai...@googlegroups.com.
Visit this group at https://groups.google.com/group/pyfrmailinglist.
To view this discussion on the web, visit https://groups.google.com/d/msgid/pyfrmailinglist/9790d6c5-767e-4807-89f7-3c1d2c64d235%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.
<3d_cylinder.zip><aasdf.PNG><ffdsa.PNG>
Junting Chen
Jun 12, 2019, 4:57:25 PM6/12/19
to PyFR Mailing List
Hello Dr.Vincent,
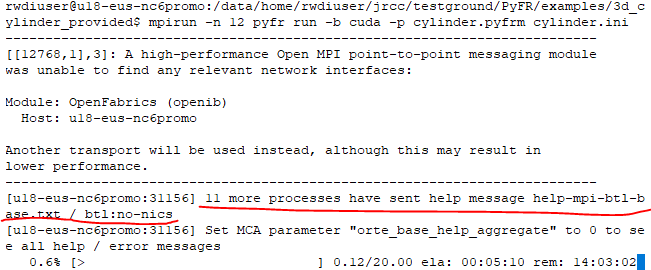

Thanks for the quick reply. I did try to run the case with both openmp and cuda backends.
With CUDA backend (Tesla K80) on a virtual machine, I am constantly seeing this error message:
I found out a way to get rid of the message, but there was no improvement on the performance. (foot note: nvidia-smi tells me 12 cores are used in both cases)
Also, I realized that run speed remains the same regardless how many cores I call (mpirun -n ##). Single core, 12 cores and 20 cores all requiring 14hrs to run 20s of this 3d cylinder case with 360k cell at 4th order. I believe there is still some technical issues in here. I am suspecting the openmpi version is holding me back at the moment. Here it is openmpi 1.10 and latest version is 4.0.
As I am running this case with openmp backend on a local machine, I have encountered similar issue: regardless how many processors I am calling, there was no improvement on performance. The run speed is extremely slow. It is openmpi 2.1 on this local machine.
I am currently rebuilding the latest openmpi on the local machine (there is some difficulties on updating cuda aware openmpi on the virtual machine). Besides the openmpi issue, anything else might go wrong?
Thanks again.
Junting Chen

Freddie Witherden
Jun 13, 2019, 10:11:50 AM6/13/19
to pyfrmai...@googlegroups.com
Hi Junting,
PyFR is a modern code. As such when running with the OpenMP backend you
only want to use one MPI rank per socket. If you are running on a 12
core CPU there should be one MPI rank (the remaining cores will be
saturated by OpenMPI threads). Using more ranks is likely to degrade
performance -- especially if you do not tell OpenMP to use less threads
(as you may end up with 12*12 = 144 threads which is a substantial
amount of over-subscription).
In the case of the CUDA backend all computation is offloaed to the GPU.
Thus there should be one MPI rank per CPU. Here, it is expected that
all but one of the cores will be idle. Running more ranks is just going
to over-subscribe the GPU and degrade performance.
Regards, Freddie.
On 12/06/2019 15:57, Junting Chen wrote:
> Hello Dr.Vincent,
>
> Thanks for the quick reply. I did try to run the case with both openmp
> and cuda backends.
>
> With CUDA backend (Tesla K80) on a virtual machine, I am constantly
> seeing this error message:
>
> 1.png <about:invalid#zClosurez>
> <https://groups.google.com/d/msgid/pyfrmailinglist/101cc570-45fe-454a-8374-9a29d277b46a%40googlegroups.com?utm_medium=email&utm_source=footer>.
PyFR is a modern code. As such when running with the OpenMP backend you
only want to use one MPI rank per socket. If you are running on a 12
core CPU there should be one MPI rank (the remaining cores will be
saturated by OpenMPI threads). Using more ranks is likely to degrade
performance -- especially if you do not tell OpenMP to use less threads
(as you may end up with 12*12 = 144 threads which is a substantial
amount of over-subscription).
In the case of the CUDA backend all computation is offloaed to the GPU.
Thus there should be one MPI rank per CPU. Here, it is expected that
all but one of the cores will be idle. Running more ranks is just going
to over-subscribe the GPU and degrade performance.
Regards, Freddie.
On 12/06/2019 15:57, Junting Chen wrote:
> Hello Dr.Vincent,
>
> Thanks for the quick reply. I did try to run the case with both openmp
> and cuda backends.
>
> With CUDA backend (Tesla K80) on a virtual machine, I am constantly
> seeing this error message:
>
>
>
>
>
>
>
>
>
>
> I found out a way to get rid of the message, but there was no
> improvement on the performance. (foot note: nvidia-smi tells me 12 cores
> are used in both cases)
>
> 2.png <about:invalid#zClosurez>
>
>
>
>
>
>
>
>
> I found out a way to get rid of the message, but there was no
> improvement on the performance. (foot note: nvidia-smi tells me 12 cores
> are used in both cases)
>
>
>
>
> Also, I realized that run speed remains the same regardless how many
> cores I call (mpirun -n ##). Single core, 12 cores and 20 cores all
> requiring 14hrs to run 20s of this 3d cylinder case with 360k cell at
> 4th order. I believe there is still some technical issues in here. I am
> suspecting the openmpi version is holding me back at the moment. Here it
> is openmpi 1.10 and latest version is 4.0.
>
> As I am running this case with openmp backend on a local machine, I have
> encountered similar issue: regardless how many processors I am calling,
> there was no improvement on performance. The run speed is extremely
> slow. It is openmpi 2.1 on this local machine.
>
>
> I am currently rebuilding the latest openmpi on the local machine (there
> is some difficulties on updating cuda aware openmpi on the virtual
> machine). Besides the openmpi issue, anything else might go wrong?
> Thanks again.
>
> Junting Chen
>
>
>
> Also, I realized that run speed remains the same regardless how many
> cores I call (mpirun -n ##). Single core, 12 cores and 20 cores all
> requiring 14hrs to run 20s of this 3d cylinder case with 360k cell at
> 4th order. I believe there is still some technical issues in here. I am
> suspecting the openmpi version is holding me back at the moment. Here it
> is openmpi 1.10 and latest version is 4.0.
>
> As I am running this case with openmp backend on a local machine, I have
> encountered similar issue: regardless how many processors I am calling,
> there was no improvement on performance. The run speed is extremely
> slow. It is openmpi 2.1 on this local machine.
>
>
> I am currently rebuilding the latest openmpi on the local machine (there
> is some difficulties on updating cuda aware openmpi on the virtual
> machine). Besides the openmpi issue, anything else might go wrong?
> Thanks again.
>
> Junting Chen
>
> --
> You received this message because you are subscribed to the Google
> Groups "PyFR Mailing List" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to pyfrmailingli...@googlegroups.com
> <mailto:pyfrmailingli...@googlegroups.com>.
> You received this message because you are subscribed to the Google
> Groups "PyFR Mailing List" group.
> To unsubscribe from this group and stop receiving emails from it, send
> an email to pyfrmailingli...@googlegroups.com
> To post to this group, send email to pyfrmai...@googlegroups.com
> <mailto:pyfrmai...@googlegroups.com>.
> Visit this group at https://groups.google.com/group/pyfrmailinglist.
> To view this discussion on the web, visit
> https://groups.google.com/d/msgid/pyfrmailinglist/101cc570-45fe-454a-8374-9a29d277b46a%40googlegroups.com
> To view this discussion on the web, visit
> <https://groups.google.com/d/msgid/pyfrmailinglist/101cc570-45fe-454a-8374-9a29d277b46a%40googlegroups.com?utm_medium=email&utm_source=footer>.
Junting Chen
Jun 18, 2019, 4:15:37 PM6/18/19
to PyFR Mailing List
Thanks Dr.Witherden, great to hear from you and sorry about the delay. There is still some issue regarding convergence and hope that you can give me some hints.


So first of all I tried to run the simulation Dr.Vincent provided along with the paper - flow past a 3d cylinder. I added a "tend" value and didn't do any other change. It runs ok, take a little too long to see some results. Then I increased the inlet velocity from 0.2 to 3.2, and it no longer converges. All I got is 10E38. Is it because of the increase of Reynolds number from ~3k to ~30k?
Also, I ran a CAARC building case, which is one of our test case. In this case, I am only running 2nd order for now. I have tried both ac-navier-stokes (ac-zeta = 2.5 and 180) and navier-stokes solver. It keeps breaking at certain point. I have attached the msh and ini files if you have time to check. The result before simulation breaks looks like:
The initial condition of the domain was u = 0, and inlet flow velocity is u = 20m/s. The result shown on the left was taken at 173s. The CAARC building is placed at 300m behind the inlet, which means the incoming flow should have passed entire domain multiple times already. As I am checking results from previous time steps, the flow did move forward from the inlet, but not by much. In addition, the simulation breaks as some of the bad nodes diverged very soon after this time step.
In this run, I used navier-stokes.
I did another run with ac-navier-stokes solver, and setting u = 20 in the entire domain. It breaks much early on at around t = 38s. Also, I am expecting to see some turbulence flow above and behind the building.
I am suspecting the boundary condition setup was not done properly. Would you mind to elaborate on the difference between ac-char-riem-inv and ac-in-fv? Is ac-char-riem-inv / char-riem-inv the best option for the outlet?
As I read news on your tweet, Niki has developed an incompressible solver on PyFR. Any chance it will be open sourced?
Best regards,
Junting Chen
Freddie Witherden
Jun 18, 2019, 10:24:27 PM6/18/19
to pyfrmai...@googlegroups.com
Hi Junting,
On 18/06/2019 15:15, Junting Chen wrote:
> So first of all I tried to run the simulation Dr.Vincent provided along
> with the paper - flow past a 3d cylinder. I added a "tend" value and
> didn't do any other change. It runs ok, take a little too long to see
> some results. Then I increased the inlet velocity from 0.2 to 3.2, and
> it no longer converges. All I got is 10E38. Is it because of the
> increase of Reynolds number from ~3k to ~30k?
So increasing the Reynolds number will almost certainly require either
an increase in polynomial order or mesh resolution. However, a bigger
problem is that your inlet velocity is now likely supersonic which will
dramatically change the dynamics of the simulation. Specifically, at a
minimum, you will need to enable the shock capturing functionality in
PyFR in order to stabilize the simulation.
> As I read news on your tweet, Niki has developed an incompressible
> solver on PyFR. Any chance it will be open sourced?
This solver is the ac- prefixed solver (with AC standing for artificial
compressibility which is the technology which underpins the
incompressible solver). As such not only is it open source but it is
also released and available in current versions of PyFR.
Regards, Freddie.
On 18/06/2019 15:15, Junting Chen wrote:
> So first of all I tried to run the simulation Dr.Vincent provided along
> with the paper - flow past a 3d cylinder. I added a "tend" value and
> didn't do any other change. It runs ok, take a little too long to see
> some results. Then I increased the inlet velocity from 0.2 to 3.2, and
> it no longer converges. All I got is 10E38. Is it because of the
> increase of Reynolds number from ~3k to ~30k?
an increase in polynomial order or mesh resolution. However, a bigger
problem is that your inlet velocity is now likely supersonic which will
dramatically change the dynamics of the simulation. Specifically, at a
minimum, you will need to enable the shock capturing functionality in
PyFR in order to stabilize the simulation.
> As I read news on your tweet, Niki has developed an incompressible
> solver on PyFR. Any chance it will be open sourced?
compressibility which is the technology which underpins the
incompressible solver). As such not only is it open source but it is
also released and available in current versions of PyFR.
Regards, Freddie.
Freddie Witherden
Jun 18, 2019, 10:45:20 PM6/18/19
to Junting Chen, pyfrmai...@googlegroups.com
Hi Junting,
On 18/06/2019 21:40, Junting Chen wrote:
> Thanks for the reply. Sorry I am a bit confused by “supersonic inlet”
> you mentioned. I have no intention to introduce compressible flow and
> shock at any point. Those are for sure out of our scope. Is the unit of
> u v and w meter per second? Maybe there is something I missed.
PyFR is dimensionless. However, within the context of the simulation I
suspect that 0.2 is a reference to the Mach number as opposed to the
velocity in m s^-1.
Regards, Freddie.
On 18/06/2019 21:40, Junting Chen wrote:
> Thanks for the reply. Sorry I am a bit confused by “supersonic inlet”
> you mentioned. I have no intention to introduce compressible flow and
> shock at any point. Those are for sure out of our scope. Is the unit of
> u v and w meter per second? Maybe there is something I missed.
PyFR is dimensionless. However, within the context of the simulation I
suspect that 0.2 is a reference to the Mach number as opposed to the
velocity in m s^-1.
Regards, Freddie.
Junting Chen
Jun 18, 2019, 11:06:19 PM6/18/19
to PyFR Mailing List
Thank you for the clarification.
Does the dimension of the computation domain need to be non-dimensionalized somehow?
Junting

Giorgio Giangaspero
Jun 24, 2019, 11:49:59 AM6/24/19
to PyFR Mailing List
Hi Junting
the dimensions of the computational domain should be such that you obtain the desired Reynolds number, given your choice of reference density, velocity, and viscosity. It may be easier though to change these variables to get your target Reynolds number, while keeping fixed your domain (i.e. while keeping fixed your reference length).
Best
Giorgio
Reply all
Reply to author
Forward
0 new messages