Meeting notes 2012/05

Jesse Hallett
Functional programming techniques in protein biochemistry analysis, talk by Gregory Benison
An NMR spectrum is effectively a mapping from frequencies to intensities. Through some magic it is possible to produce two-dimensional spectra in which peaks correspond to pairings of what would be peaks in corresponding one-dimensional spectra.
Through application of transformations on spectra like convolutions, transpositions, and diagonal projections one can eliminate noise to find the frequency of some atom arrangement given a related arrangement with a known frequency.
The problem is that this involves a lot of computations. Lazy evaluation is essential to keep memory use in check. But lazy evaluation might result in repeating a lot of computations.
Perhaps a cache with the correct design could help.
Leif referenced logic-programming as a domain that is specialized for finding solutions in large search spaces.
A typical input spectrum could contain 10^7 double values. The file size could be 50 - 100 MB.
Maglev can handle large volumes of data accessed concurrently using software transactional memory. Could it scale high enough to handle the number-crunching required?
Daniel proposes that this may be a problem for custom hardware. Another example of finding a signal amidst noise is a GPS device: it has to separate out one signal from a plethora of satellites. That is a problem that is handled well by FPGAs.
Special chip support or GPU use could be helpful. GPUs are really good at parallel floating-point operations.
In some situations, memory bandwidth can be a sufficiently problematic that it is efficient to compress data in memory and to take the CPU hit of decompressing it for processing.
Jillian suggests applying wavelet analysis to the input spectra and applying transformations to the result. Wavelet analysis would produce a more compact representation of the input data. There are some papers out there on signal recovery via wavelet analysis.
Can the problem be divided into pieces? Perhaps using mapreduce?
In any case, it is useful to narrow down the problem before putting too much energy into a solution. Hooking up a simple cache and watching the hit/miss ratio might give a hint as to whether any kind of caching solution could work.
Another way to reduce the input size could be to build a K-D tree of local maxima points - as opposed to filtering out all frequencies below a given intensity. Or you could sample the input at reduced resolution.
It is hard to store matrices in a way to make multiplication as efficient as possible. You can choose to store a matrix as a list of rows or as a list of columns - but neither is optimal. You can get better results by using space partitioning to recursively store sub-matrices.
A problem with using multiple threads is that you could end up thrashing memory more than a single thread would, resulting in more cache misses. What might be nice sequential memory access in a single thread could become much messier with interleaved threads.
The final suggestion of the night: what about quantum computing?

Jesse Cooke
Functional programming techniques in protein biochemistry analysis, talk by Gregory Benison
An NMR spectrum is effectively a mapping from frequencies to intensities. Through some magic it is possible to produce two-dimensional spectra in which peaks correspond to pairings of what would be peaks in corresponding one-dimensional spectra.
Through application of transformations on spectra like convolutions, transpositions, and diagonal projections one can eliminate noise to find the frequency of some atom arrangement given a related arrangement with a known frequency.
The problem is that this involves a lot of computations. Lazy evaluation is essential to keep memory use in check. But lazy evaluation might result in repeating a lot of computations.
Perhaps a cache with the correct design could help.
Leif referenced logic-programming as a domain that is specialized for finding solutions in large search spaces.
A typical input spectrum could contain 10^7 double values. The file size could be 50 - 100 MB.
Maglev can handle large volumes of data accessed concurrently using software transactional memory. Could it scale high enough to handle the number-crunching required?
Daniel proposes that this may be a problem for custom hardware. Another example of finding a signal amidst noise is a GPS device: it has to separate out one signal from a plethora of satellites. That is a problem that is handled well by FPGAs.
Special chip support or GPU use could be helpful. GPUs are really good at parallel floating-point operations.
In some situations, memory bandwidth can be a sufficiently problematic that it is efficient to compress data in memory and to take the CPU hit of decompressing it for processing.
Jillian suggests applying wavelet analysis to the input spectra and applying transformations to the result. Wavelet analysis would produce a more compact representation of the input data. There are some papers out there on signal recovery via wavelet analysis.
Can the problem be divided into pieces? Perhaps using mapreduce?
In any case, it is useful to narrow down the problem before putting too much energy into a solution. Hooking up a simple cache and watching the hit/miss ratio might give a hint as to whether any kind of caching solution could work.
Another way to reduce the input size could be to build a K-D tree of local maxima points - as opposed to filtering out all frequencies below a given intensity. Or you could sample the input at reduced resolution.
It is hard to store matrices in a way to make multiplication as efficient as possible. You can choose to store a matrix as a list of rows or as a list of columns - but neither is optimal. You can get better results by using space partitioning to recursively store sub-matrices.
A problem with using multiple threads is that you could end up thrashing memory more than a single thread would, resulting in more cache misses. What might be nice sequential memory access in a single thread could become much messier with interleaved threads.
The final suggestion of the night: what about quantum computing?
--
You received this message because you are subscribed to the Google Groups "pdxfunc" group.
To post to this group, send email to pdx...@googlegroups.com.
To unsubscribe from this group, send email to pdxfunc+u...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/pdxfunc?hl=en.

gregory benison
http://www.scribd.com/doc/93655749
And if anyone wants the actual code, it's here:
https://github.com/gbenison/burrow-owl
If I do find a way to speed up performace - be it caching,
compression, or whatever - I'll be sure to share it!
--
Greg Benison <gben...@gmail.com>
[blog] http://gcbenison.wordpress.com
[twitter] @gcbenison

Jill Burrows
- Basic overview of the transform and a mention of both lossless and lossy compression: http://en.wikipedia.org/wiki/Wavelet_transform
- Overview of a discreet wavelet transform (this is more of what you want since you're working discretely sampled data.) This is similar to the discrete Fourier transform. Code for the Haar wavelet at the end of the article: http://en.wikipedia.org/wiki/Discrete_wavelet_transform
- Fast Wavelet Transform -- similar to the Fast Fourier Transform: http://en.wikipedia.org/wiki/Fast_wavelet_transform
- A C++ implementation of a 2-d wavelet transform for images (just for information): http://nalag.cs.kuleuven.be/research/software/wavelets/
- Slides on optimally matched wavelets: http://www.math.uni-bremen.de/zetem/DFG-Schwerpunkt/rpwaft2006/talks/thielemann.pdf
- MIT's Wavelet user's guide for MATLAB: http://web.mit.edu/1.130/WebDocs/wavelet_ug.pdf
- Signal Recovery and Noise Reduction Using Wavelets: http://gislib.poi.dvo.ru/stud/Goncharova/dsp-wavelets/Wavelets/diss_lu/wvlt_diss26_lu.pdf
- Another overview of wavelets without a lot of context: http://cacs.usc.edu/education/cs653/NRC-c13.10-Wavelets.pdf
- Maybe some useful beginner info: http://www.polyvalens.com/blog/ (I haven't looked at it yet.)
--
You received this message because you are subscribed to the Google Groups "pdxfunc" group.
To post to this group, send email to pdx...@googlegroups.com.
To unsubscribe from this group, send email to pdxfunc+u...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/pdxfunc?hl=en.
Thanks,
Jill Burrows
+1 503 208 5455
ji...@adaburrows.com
http://adaburrows.com
@jburrows (http://twitter.com/jburrows)
Jill Burrows
- This actually looks like a great in depth overview: http://matlab.izmiran.ru/help/toolbox/wavelet/
- GENE SELECTION BY 1-D DISCRETE WAVELET TRANSFORM FOR CLASSIFYING CANCER SAMPLES USING DNA MICROARRAY DATA: http://etd.ohiolink.edu/send-pdf.cgi/Jose%20Adarsh.pdf?akron1240851642
- THE ENGINEER'S ULTIMATE GUIDE TO WAVELET ANALYSIS: http://person.hst.aau.dk/enk/ST8/wavelet_tutotial.pdf

Travis Brooks
I was a pretty green programmer back in those days but I still managed to cobble something together that was pretty fast for those days. IDL is built from the ground up to do this sort of stuff, fast reading and parsing of monstrous files and heavy duty number crunching. The downside is that its a proprietary language and will likely cost more than you'd expect.
-travis
> Subject: Re: [pdxfunc] Meeting notes 2012/05
> From: gben...@gmail.com
> To: pdx...@googlegroups.com
gregory benison
last week's meeting, but I have managed to implement one of them,
which was to instrument the code to get a better idea of access
patterns for the arrays as a way to see if caching would be likely to
improve performance.
(Slides from the meeting here:
http://www.scribd.com/doc/93655749/benison-14may12)
The numbers in this analysis are the result of opening up the viewer
application and twiddling cursors around in a typical way for about a
minute, which generates many spectra and many traversal requests (as
the "parent" spectra are sliced in various ways to provide different
views.) I chose to look at access patterns for one 5-dimensional
spectrum that is an "ancestor" to most of the little spectra being
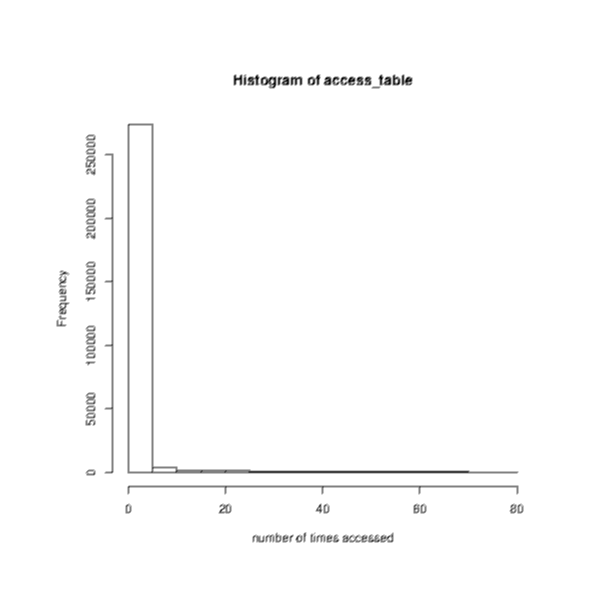
spawned. Some interesting patterns show up. First, looking at a
frequency analysis of indices accessed (see attached image), although
there are some values that were requested repeatedly - up to 70 times
- by far the majority of the values were accessed once or twice. So
perhaps caching is not going to be very helpful, at least not in this
use case. Another interesting thing to look at is the sequential
access pattern (second figure, attached). There are lots of little
clusters of highly localized access separated by huge jumps. So
perhaps re-ordering requests, something like an elevator in a
filesystem does, would be useful. (Although it would require some
care, because requests can't just be reordered arbitrarily; sometimes
an iterator has to wait for two or more values from some ancestor
spectrum before it can proceed; maybe some sort of lookahead caching
would help with that.)
Anyone motivated to look into this further can download the raw data
from which these graphs were generated here (caution: 125MB download)
-
http://dl.dropbox.com/u/46105745/nmr-traversal-data.tar.bz2
{kind=link}
{kind=link}