Standards alignment to standards alignment in LR via data services

Steve Midgley
about a problem that is emerging around standards alignment. Our current
work on data services for finding alignment between resources and
standards is very useful (and seems to be well received by the states
I've talked with). As a result of our work on that problem, we might use
LR to fix this new problem..
The emerging problem is that there are many ways to talk about the same
curricular standard. So there exists for common core a canonical
English-language (non-machine readable) standard defined by the CCSS
consortia. Say this one for ELA:
ASN has the same standard here:
http://asn.jesandco.org/resources/S2364828
Academic Benchmarks has a GUID to describe this same standard, and
Massachusetts has created some internal GUIDs as well. There are
probably others! And there are valid business models and reasons why not
everyone is going to a universal single standard URL, at least not right
away (just recoding the database might be a pain). Of course we all want
them to link to the same resources, but right now it's not even very
easy to figure out which standard is the same as another standard..
Given that in LR it's pretty easy to say stuff like:
This thing is the "verb" of that thing.
Which in this case would be:
This "ASN common core ELA standard URL for rf.2.3" is the "same as"
"CCSS common core ELA standard URL rf.2.3"
With data services it's possible to ask questions of things like:
"Show me all standard URLs that are the same as
http://asn.jesandco.org/resources/S2364828"
And get back MA's GUIDs, AB's GUIDs, CCSS's URLs, etc. Seems like a
useful feature to get working in LR? It's relatively easy to implement I
think.. It seems very, very similar to our standards alignment data
service that connects standards to resources using alignment verbs
("aligned," "teaches," "assesses" etc)?
I wonder if this standard-standard data service should be the second
demo for data services or if ratings data are more useful? Creating a
place where anyone can register a correlation between on standard and
another standard seems very helpful for everyone in figuring stuff out?
All input welcome,
Steve

patrick...@googlemail.com
Steve Midgley
I'm not sure what you mean by topology -- do you mean like network graphs? (I know how to string those words together and pretend that there is math(s) underneath that I understand).
On your second point, we are working on making a data service to go from a curricular standard to one or more pieces of content, and vice versa. But this point is about going from one curricular standard to one or more other equivalent curricular standards.
Already groups like Academic Benchmarks do this for complex standards like connecting California content standards to Texas content standards, etc (two sets of standards which are not that similar). That's too hard for a small OSS operation like LR. But this proposal is just to connect "identical" standards, rather than "similar" standards (as TX and CA are just similar).
For US Common Core standards, there are several sets of identifiers that are being used across the country and it seems handy to be able to simply convert one ID into another that represents the same thing.. In abstract terms if the standards database looks like:
X=Y
X=Z
Z=A
B=C
"Show me all standards equivalent to Z" returns {A,X,Y}
We're still very interested in paradata, but in the early days now to drive adoption, we are focusing narrowly on standards alignment and maybe this new idea of standards-standards conversion. I think California is also sharing "real" paradata in the forms of ratings today..
Steve
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
To post: learning-regis...@googlegroups.com
To unsubscribe:learning-registry-co...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en

Jim Klo
Asking to search for equivalents to any one should include the other two.
Sent from my iPad

Jeffrey Hill
Steve Midgley
--
Marie Bienkowski
One question would be how much there really is equivalence between these different state standards that would warrant a "same as" relationship. EPIC in Oregon was funded by BMGF to compare 5 state standards (including MA and CA) to CCSS where they both linked based on a match on content (which is what Steve initially described) and also considered what can be thought of as degree of difficulty. Some differ also in grain size of the target knowledge.
That's not to say it can't be accomplished, but that users may want a more nuanced vocabulary than "same as" Standards may "match" on content but not on cognitive complexity, for example.
Interesting operations over this data set could be to locate resources that cover areas unique to a state (the CA missions study in 4th grade comes to mind) or that have highly rated OERs to achieve them.
Marie
Steve Midgley
It seems like everyone would have to agree to submit against a specific canonical standard, rather than just a network graph of any standard connecting to any other?
So if canonical were "http://www.corestandards.org/the-standards/english-language-arts-standards/reading-foundational-skills/grade-2/#rf-2-1" (call it "ABC")
Then we'd need submissions like:
http://asn.jesandco.org/resources/S2364828 "same as" ABC
and
http://purl.org/ASN/resources/S2364828 "same as" ABC
But if someone submitted
http://asn.jesandco.org/resources/S2364828 "same as" http://purl.org/ASN/resources/S2364828
This would be harder to return against? Anyway it seems like there will be some customization to make something like this work?
The goals are (I think - input welcome) to be able to ask
"Show me all standard IDs that are same as [[canonical standard ID]]"
"Show me the canonical standard for [[standard ID]]"
It would be a big bonus if you could say
"show me the all standard IDs that are same as [[standard ID]]" (which would walk some kind of graph to figure out which standards are same as which other standards). This seems harder and not worth doing since I think CCSS will produce a set of canonical standard IDs we can use to link to everyone else?
Steve
Steve Midgley
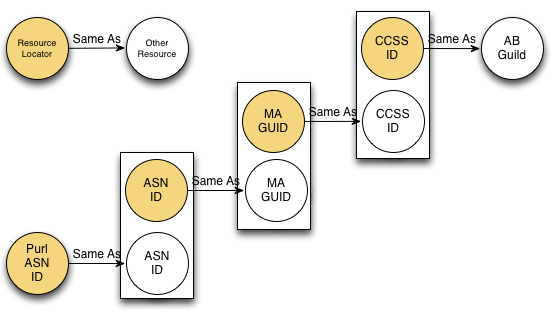
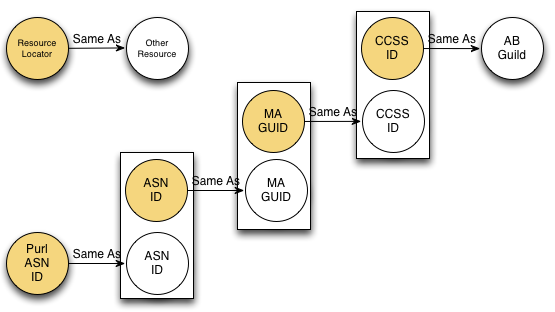
1) CCSS canonical (forthcoming)
2) AB GUIDs (not yet public but may be soon)
3) PURL ASN IDs
4) ASN IDs
5) MA state GUIDs
Possibly others - those are just what I know about..
Steve

Daniel Rehak
- MA GUID same as CCSS id
and I would expect a match to bring back them all. You need to perform the reification across all the statements, and we need same as reification for other things, so no need to drive this one as a special case.
Learning Registry Technical Architect
Email: daniel...@learningregistry.org
daniel.r...@adlnet.gov
Twitter: @danielrehak
Web: learningregistry.org
Google Voice: +1 412 301 3040
Jim Klo
Sent from my iPhone
Jeffrey Hill
Daniel Rehak
- MA GUID same as CCSS id
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
To post: learning-regis...@googlegroups.com
To unsubscribe:learning-registry-co...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
Jim Klo
Daniel Rehak
Jim Klo
I'm suggesting that we could define "match" to require that you walk the entire graph.
Doing the walk/reification seems like a useful capability to have somewhere, otherwise someone will have to layer it on top of obtain or DS. Repeated calls to get single items and external walking of the graph won't be efficient.
On Tue, Mar 20, 2012 at 2:04 PM, Jim Klo <jim...@sri.com> wrote:
I'm not sure "obtain" would do that... since it works by resource_locator or by doc_id, all 6 docs would have to have MA GUID as the resource_locator.
<Untitled.png>

Joshua Marks
Dear Learning Registry folks,
I am cross posting this to the LRMI working group and public group. This relates directly to the issue in LRMI of identify equivalent “Competency Alignments” to multiple “Promulgators” of the same standard. What is described below is rather a mess IMHO. What is needed is a consistent (alpha numerical) identifier for each statement from the publisher of the standard, and agreement amongst all promulgators to include that as a unique linking key. This however, I fear, requires agreement on the part of both the publishers of competency frameworks (standards) and those who provide reference data services (Promulgators).
Attempting to reverse engineer the relationships is not a sustainable solution and will fail at some point. Probably sooner than later.
Joshua Marks
CTO
Curriki: The Global Education and Learning Community
I welcome you to become a member of the Curriki community, to follow us on Twitter and to say hello on our blog, Facebook and LinkedIn communities.
Daniel Rehak
Jim Klo
Daniel Rehak
patrick...@googlemail.com
On Tuesday, 20 March 2012 02:32:02 UTC, Steve Midgley wrote:
Hi Pat,
I'm not sure what you mean by topology -- do you mean like network graphs? (I know how to string those words together and pretend that there is math(s) underneath that I understand)./group/learning-registry-collaborate?hl=en?hl=en
Daniel Rehak
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
To post: learning-regis...@googlegroups.com
To unsubscribe:learning-registry-co...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
Steve Midgley
So Grade 2 English Foundation skills 2.3: "Know and apply grade-level phonics and word analysis skills in decoding words."
So either a state requires this skill to be acquired or they don't. The Venn diagram applies at this level for purposes of matching, not at the level of English as a totality of subject..
Question is at the moment, what is the ID for that skill? ASN has one, MA has one, AB has one, and soon Common Core as an official entity will have one. Probably others..
Helps?
Steve
Steve Midgley
If I have a thousand Khan academy videos (#1 to 1000) that I align to a single state standard called ABC (let's make this an easy example), then I would have a bunch of alignment statements in LR like
#1 "is aligned to" ABC
#2 "is aligned to" ABC
...#1000 "is aligned to "ABC"
Then if someone else figures out that XYZ standard is "same as" ABC, they would put
XYZ "same as" ABC in the system
So if someone comes to the system looking for XYZ resources, at minimum, we could ask them to do this:
Data service #2: "What standards are [same as] XYZ?"
Answer: "ABC"
Data service #1: "Show me all resources aligned to XYZ"; "Show me all resources aligned to ABC"
Answer: #1..1000
You'd only have 1 "same as" statement to relate XYZ to ABC? And then 1000 alignment statements?
How do I have this messed up?
Steve

Doug Gastich
Reply-To: <learning-regis...@googlegroups.com>
Date: Wed, 21 Mar 2012 00:33:54 -0400
To: <learning-regis...@googlegroups.com>
Subject: Re: [Learning Registry: Collaborate] Re: Standards alignment to standards alignment in LR via data services
Daniel Rehak
I'm not sure I agree with this assertion, or maybe I don't understand it.. :)
If I have a thousand Khan academy videos (#1 to 1000) that I align to a single state standard called ABC (let's make this an easy example), then I would have a bunch of alignment statements in LR like
#1 "is aligned to" ABC
#2 "is aligned to" ABC
...#1000 "is aligned to "ABC"
Then if someone else figures out that XYZ standard is "same as" ABC, they would put
XYZ "same as" ABC in the system
So if someone comes to the system looking for XYZ resources, at minimum, we could ask them to do this:
Data service #2: "What standards are [same as] XYZ?"
Answer: "ABC"
Data service #1: "Show me all resources aligned to XYZ"; "Show me all resources aligned to ABC"
Answer: #1..1000
You'd only have 1 "same as" statement to relate XYZ to ABC? And then 1000 alignment statements?
How do I have this messed up?
Steve
On 3/20/2012 3:39 PM, Daniel Rehak wrote:
Hi Pat
Good point.We've been talking about aligning individual standard's statements, the most primitive.So if the standard was described in 1000 statements, then we would need 1000 "same as" alignment statements, one for each part to align it with another standard.
I think you want to align entire aggregates at a time.
Not sure we even have a good model of the aggregates.
- Dan
On Tuesday, 20 March 2012 02:32:02 UTC, Steve Midgley wrote:Hi Pat,
I'm not sure what you mean by topology -- do you mean like network graphs? (I know how to string those words together and pretend that there is math(s) underneath that I understand)./group/learning-registry-collaborate?hl=en?hl=en
Say New York and New Jersey's standards are the same - well their LR nodes talk to each other happily (no issues in sharing)
Say New York and Maryland have the same for English but not science - so they share English materials but not science.
So you do the standards via a node venn diagram?
I may have missed the point entirely.
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
Daniel R. Rehak, Ph.D.
Learning Registry Technical Architect
ADL Technical Advisor
Skype: drrehak
Email: daniel.rehak@learningregistry.org
daniel.r...@adlnet.gov
Twitter: @danielrehak
Web: learningregistry.org
Google Voice: +1 412 301 3040
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en

Jim G
The matching service is valuable, but it is also reasonable to expect
that the resources that LRMI calls promulgators have the publisher/
producer's canonical reference code and GUID in their database /
online reference.
In CEDS terms these identifiers are:
Learning Standard Item Code -- A code designated by the publisher to
identify the statement, e.g. "M.1.N.3", usually not globally unique
and usually has embedded meaning such as a number that represents a
grade/level and letters that represent content strands.
and
Learning Standard Item Identifier -- An unambiguous globally unique
identifier.
(Note: CEDS v2 has URI as URL+GUID, candidate for CEDS v3 change is to
separate out GUID from URI, i.e. Learning Standard Item URL --
reference to the statement using a network-resolvable URI)
- Jim Goodell
On Mar 21, 1:02 am, Doug Gastich <dgast...@learning.com> wrote:
> @Steve: I think the only addition you need to make to reconcile to Pat's email is to add one word to your response (in CAPS):
>
> "If I have a thousand Khan academy videos (#1 to 1000) that I align to a single state standard STATEMENT called ABC…"
>
> Also, consider adding 'EdGate UUID' to your growing list of ID providers for standards statements.
>
> @ Joshua: I think you are correct to fear that agreement is required. Organizations like AB and EdGate (and to some extent, ASN) are in competition to be the de-facto canon. A huge portion of their services value goes out the window the moment an actual official standard is endorsed. It seems to me that Steve's approach here is to find a way to accept this as a condition of the system and work with it. But I agree, it creates a potential for failure at multiple points (the first one that comes to mind is getting somehow out of phase during an update to statement language).
>
> -Doug
>
> Douglas Gastich
>
> Director of Content and Partner Development
> Learning.com
>
> dgast...@learning.com
>
> On Tuesday, 20 March 2012 02:32:02 UTC, Steve Midgley wrote:
>
> Hi Pat,
>
> Say New York and New Jersey's standards are the same - well their LR nodes talk to each other happily (no issues in sharing)
>
> Say New York and Maryland have the same for English but not science - so they share English materials but not science.
>
> So you do the standards via a node venn diagram?
>
> I may have missed the point entirely.
> --
> You received this message because you are subscribed to the Google
> Groups "Learning Registry: Collaborate" group.
>
> To unsubscribe:learning-registry-co...@googlegroups.com<mail to:unsubscribe%3Alearning-registry-collaborate%2Bunsubscribe@googlegroups.c om>
>
> For more options, visit this group athttp://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
> --
> Daniel R. Rehak, Ph.D.
>
> Learning Registry Technical Architect
> ADL Technical Advisor
>
> Skype: drrehak
> daniel.rehak....@adlnet.gov<mailto:daniel.rehak....@adlnet.gov>
> Twitter: @danielrehak
> Web: learningregistry.org<http://learningregistry.org/>
>
> Google Voice:+1 412 301 3040begin_of_the_skype_highlighting +1 412 301 3040
> --
> You received this message because you are subscribed to the Google
> Groups "Learning Registry: Collaborate" group.
>
> To unsubscribe:learning-registry-co...@googlegroups.com<mail to:unsubscribe:learning-registry-co...@googlegroups.com>
>
> For more options, visit this group athttp://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
> --
> You received this message because you are subscribed to the Google
> Groups "Learning Registry: Collaborate" group.
>
> To unsubscribe:learning-registry-co...@googlegroups.com<mail to:learning-registry-co...@googlegroups.com>
>
> For more options, visit this group athttp://groups.google.com/group/learning-registry-collaborate?hl=en?hl=enI'l be

Kelly Peet
@Steve. Regarding your opening example with the Common Core Canonical and ASN URLs, the equivalent AB URL is:
http://www.academicbenchmarks.org/search/?guid=7E402F7C-7440-11DF-93FA-01FD9CFF4B22
And, yes these are public documents in our collection. Per a side discussion with Joe Hobson, who helpfully expressed that we need to make our data easier to discover, we have exposed a standards translation service much like the variety discussed in this thread (e.g. given an ASN ID, what is the AB GUID), which is running here:
http://academicbenchmarks.com/standards-translator
Regardless of where folks prefer a service like this to reside or which protocol is used to access it, there is a critical (and not very sexy) first step of creating the equations between so many fractured organizations attempting to articulate digital copies of standards.
Also, as noted, the tougher problem is finding relevant connections when the relationship between two sets of standards is not an "equals" sign, deemed out of scope for LR at this time. A very prescient point.
@Joshua, Jim. Regarding canonical references and getting promulgators (i.e. SEAs, LEAs, etc) to play nicely according to the rules. I agree it could happen, and generally has not occurred. To that end, Academic Benchmarks is promoting a technically-sound solution directly to SEAs:
http://academicbenchmarks.com/ab-common-core
I completely agree that the separation of the GUID from the URI makes a more flexible model. The Learning Standard Item to which you refer, sounds like the SIF XML (LearningStandardDocument and LearningStandardItem), which many of our clients prefer to receive standards from our collection. It certainly is a valid format, among many, for representing standards in markup language.
Kelly Peet
Founder/CTO
Academic Benchmarks
Joshua Marks
Stuart,
I greatly appreciate bringing more clarity to these terms. I was trying to stay with the conventions you originally suggested, which I interpreted as the “Publishers” produce a standard document, and “Promulgators” convert that to a data representation and distribute that. Perhaps we can be even more exposit and say that a “Producer” creates a standard, a “Publisher” creates a data representation (And there may be multiple publishers for the same standard), and a “Distributor” makes that data available to a “Consumer” (And again there may be multiple distributors for the same standard, and one distributor may have multiple published versions of the same standard).
This one-to-many-to-many structure represents the real world today. Take the case of Curriki where we have the ability to align to most state standards and the common core. In our case, a state or the NGA center Produces the standard document, and AB Publishes it and distributes it to us, and we in turn distribute it to our end users within the Curriki application, so do others.
Now the issue of having a Globally Unique Identifier for each statement in the standard itself does not seem feasible. Only a publisher can insure uniqueness between all statements in all the documents it publishes. But I believe locally unique IDs in the standard is really all that is needed for the matching problem. As long as you know the document (standard) in question, then the locally unique ID is sufficient to identify equivalent statements across multiple publishers or distributors. The Publisher is still responsible for creating a Publisher GUID, and the combination of a publisher unique ID (such as their name or domain) and their statement GUID makes a truly global GUID for any statement in any published version of any standard document. At the same time, two different GUIDs from two different publishers can be matched as representing the same statement in the same document on the basis of the locally unique statement id from the producer of the standard.
So we still need Producers to create locally unique IDs for each statement and Publishers to provide Publisher Unique IDs and maintain the Producer’s local ID and document name in their published data representations. This seems to me to be the most reasonable way to address the issues of matching equivalents statements from multiple sources.
Joshua Marks
CTO
Curriki: The Global Education and Learning Community
US 831-685-3511
I welcome you to become a member of the Curriki community, to follow us on Twitter and to say hello on our blog, Facebook and LinkedIn communities.
From: lrmi...@googlegroups.com [mailto:lrmi...@googlegroups.com] On Behalf Of Stuart Sutton
Sent: Friday, March 23, 2012 10:14 AM
To: lrmi...@googlegroups.com
Cc: learning-regis...@googlegroups.com; LRMI
Subject: Re: [Learning Registry: Collaborate] Re: Standards alignment to standards alignment in LR via data services
Joshua, I'd like to shift the definition you've given to "promulgator" to a slightly more conventional one. There is only _one_ promulgator of a competency and that's the entity that created it. The competencies so promulgated are usually in a narrative form suitable for the audience needing to deal with them in the classroom and elsewhere--not data people but educators and policy people etc.. Because there is a need for a representation of those competencies in a form that can be machine-processable (i.e., as data), "someone" has to do the analysis to represent the original narrative as data. Let's pick up on some advice from Alan Paull and call these folks "producers" (for lack of a better term). You mention a couple of producers--ASN and AB. Now the promulgator _could_ also play the role of producer of a data representation of their narrative. Historically, almost no promulgators have chosen to do so. Frequently, they simply do not see it as their job; and, in the olden days, many promulgators considered doing so antithetical to their goals--a downright violation of their original purpose and even others thought the process of creation and use of such data as now envisioned as degenerate.
You suggest that the mapping problem would be solved if the promulgators assigned a "consistent (alpha numerical) identifier [to] each statement." Perhaps, if such identifiers were _globally unique_ they'd be somewhat useful. In fact, many, many promulgators _do_ assign what they consider _unique identifiers_ to statements--i.e., identifiers that are unique in the domain of their narrative (the only one they care about). I'd note that competent producers of data representations actually _do_ include such promulgator-coined identifiers in their data representations. But, those identifiers are never globally unique and therefore cannot stand as reliable means for mapping in the wild.
Now, if promulgators were willing to do what they have never been willing to do before and produce globally unique identifiers for the semantic components of their competencies in a robust computing and network environment that's up to the task of machine dereferencing of potentially millions of on-the-fly requests, that would be absolutely great. At that point they would be both promulgator and producer of data representations in a context that is curated long term (very long term--we'll be mapping resources of some lasting utility to those data points). Personally, Joshua, I think you are asking a great deal of most promulgators.
Stuart
--
Stuart A. Sutton,
CEO and Managing Director, Dublin Core Metadata Initiative
Associate Professor Emeritus, The Information School
University of Washington
Kelly Peet
Based on my understanding of the definitions, Stuart's explanation is consistent with the first time he explained it, and you have promulgator/producer exactly backwards. Semantics aside, I agree with Stuart in all his eloquence about promulgators. I think the most expedient solution may be to bring to the promulgators a credible, market-tested, and flexible digital version of their own standards in order that they can promulgate with prowess, indirectly by partnering vs directly by building it themselves. This approach is showing some inroads for AB. The distinctions between the various "P" terms may become moot as the lines blur between which entity is playing which role. Honestly, so long as the data representations are accurate, granular enough for the purpose at hand, and interoperable, the standardization of what "just works" seems like it can follow market adoption vs. lead it. In other words, let's do what works, and then call that the standard. I realize this is not the popular opinion of how these things shake out.
kelly

Stuart Sutton
The distinctions between the various "P" terms may become moot as the lines blur between which entity is playing which role. Honestly, so long as the data representations are accurate, granular enough for the purpose at hand, and interoperable, the standardization of what "just works" seems like it can follow market adoption vs. lead it.
+1
Steve Midgley
One question about our data services for this is if we put into registry standard-to-standard alignment data like:
ASN=>CCSS (100 records, say)
MA=>CCSS (100 records)
AB=>CCSS (100 records)
And could that serve to answer questions like "Show me ALL the known standards that are same as this GUID from MA?" (This would imply having some kind of graph? Is this what SPARQL is for (walking graphs of linked data to get answers like this?)
Second, harder case:
ASN=>CCSS (100 records, say)
MA=>ASN (100 records)
AB=>CCSS (100 records)
Can we still answer that question? Seems significantly harder in the MA case, for example to know that AB is related?
I'm not totally positive this is a service we *should* build, to answer these questions, but it helps if we all know how hard it is within the data services system to decide.. But it does seem like many people I've talked with are wondering about how to get from one of these standards to another (and not all the GUIDs/URLs are going to be included in the release of CCSS's official IDs/XML from what I understand).
Steve
--
Daniel R. Rehak, Ph.D.
Learning Registry Technical ArchitectADL Technical Advisor
Skype: drrehak
Email: daniel...@learningregistry.org
daniel.r...@adlnet.gov
Twitter: @danielrehak
Web: learningregistry.org
Google Voice: +1 412 301 3040
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
Steve Midgley
I think we will all be coping with a multiplicity of standard IDs for a long time, even with CCSS official IDs.
I agree that including EdGate UUIDs is a really good point, if they are or become publicly visible (are they now?). I have no contact there. If you do, please email steve....@ed.gov with who I might talk with.
Could you elaborate on the risk factor you identified: "getting somehow out of phase during an update to statement language." I'm not sure I understand that.
On the plus side of all this, at least Learning Registry project isn't proposing to create a whole new set of standard ID's! :)
Steve
On 3/21/2012 1:02 AM, Doug Gastich wrote:
@Steve: I think the only addition you need to make to reconcile to Pat's email is to add one word to your response (in CAPS):
"If I have a thousand Khan academy videos (#1 to 1000) that I align to a single state standard STATEMENT called ABC�"
So if the standard was described in 1000 statements, then we would need 1000 "same as"�alignment�statements, one for each part to align it with another standard.
I think you want to align entire aggregates at a time.
Not sure we even have a good model of the aggregates.
� � - Dan
On Tuesday, 20 March 2012 02:32:02 UTC, Steve Midgley wrote:Hi Pat,
I'm not sure what you mean by topology -- do you mean like network graphs? (I know how to string those words together and pretend that there is math(s) underneath that I understand)./group/learning-registry-collaborate?hl=en?hl=en
Say New York and New Jersey's standards are the same - well their LR nodes talk to each other happily (no issues in sharing)
Say New York and Maryland have the same for English but not science �- so they share English materials but not science.
So you do the standards via a node venn diagram?
I may have missed the point entirely.
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
Daniel R. Rehak, Ph.D.
Learning Registry Technical Architect
ADL Technical Advisor
Skype: drrehak
Email:� daniel...@learningregistry.org
� � � � � � daniel.r...@adlnet.gov
Twitter: @danielrehak
Web:�� learningregistry.org
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
To post: learning-regis...@googlegroups.com
To unsubscribe:learning-registry-co...@googlegroups.com
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�

{kind=link}
{kind=link}
Joseph Chapman
To chime in on SPARQL, I set up some sample graphs in ASN’s Quad Store using Steve’s examples (I think I captured them correctly). Let me preface this post by saying that making “owl:sameAs” relationships casually is not to be taken lightly as things are seldom “the same”. Technically can it be done in SPARQL? I think so, but whether it_should_be_done, is another conversation.
So technically speaking:
Example #1:
If you stored various “sameAs” relationships like this:
ASN=>CCSS
MA=>CCSS
AB=>CCSS
as individual RDF statements in a graph, it may look like this (simplified):
and someone asks: "Show me ALL the known standards that are same as this GUID from MA?" in SPARQL, it could look like this:
SELECT ?matches
WHERE
{
<http://stateStandard.com/1234> owl:sameAs ?o.
OPTIONAL {?matches owl:sameAs ?o.}
FILTER (?matches != <http://stateStandard.com/1234>)
}
Where a user submits a known state identifier (<http://stateStandard.com/1234>) asking, “What is it same as?”, then passing that result back (so now, ?o == CCID) and continue looking for any other RDF subjects (variable - ?matches) that also declare to be sameAs the CCID (?matches == ASN and Corporate GUID).
The ASN SPARQL response in a HTML table:
Example #2:
If you stored various “sameAs” relationships like this:
ASN=>CCSS
MA=>ASN
AB=>CCSS
As individual RDF statements in its own separate graph, it may look like this (simplified):
And you wanted to get from a known state ID, which only expresses alignment to ASN, to any other corporate GUID by walking the graph, you could run SPARQL:
SELECT ?s1 where
{
<http://stateStandard.com/1234> owl:sameAs ?o1.
OPTIONAL {?o1 owl:sameAs ?o2}.
OPTIONAL {?s1 owl:sameAs ?o2}.
FILTER (?s1 != ?o1)
}
Where you search for anything declared as sameAs to the known state ID (<http://stateStandard.com/1234>) (so you’d get ?o1 == ASN) then pass that ASN RDF statement while looking for what it is sameAs (so, ?o2 == CCID) then you look for any unknowns (?s1) that have declared to be the sameAs the CCID stored in ?o2.
The ASN SPARQL response in a HTML table:
I am not a SPARQL connoisseur and this does not take into account any special ontological reasoning setup on the Quad store beforehand, or storing this RDF data more efficiently to simplify the above queries.
I hope this is somewhat helpful?
Joseph
Thanks Doug. I agree that movement to public, official and machine-readable standards from CCSS (endorsed by CCSSO and NGA) does make it hard for any other set of IDs to be considered as "canon" (good word!). I do hope this doesn't harm existing businesses - I think there are lots of areas to create value around common core standards.
I think we will all be coping with a multiplicity of standard IDs for a long time, even with CCSS official IDs.
I agree that including EdGate UUIDs is a really good point, if they are or become publicly visible (are they now?). I have no contact there. If you do, please email steve....@ed.gov with who I might talk with.
Could you elaborate on the risk factor you identified: "getting somehow out of phase during an update to statement language." I'm not sure I understand that.
On the plus side of all this, at least Learning Registry project isn't proposing to create a whole new set of standard ID's! :)
Steve
On 3/21/2012 1:02 AM, Doug Gastich wrote:
@Steve: I think the only addition you need to make to reconcile to Pat's email is to add one word to your response (in CAPS):
"If I have a thousand Khan academy videos (#1 to 1000) that I align to a single state standard STATEMENT called ABC…"
So if the standard was described in 1000 statements, then we would need 1000 "same as" alignment statements, one for each part to align it with another standard.
I think you want to align entire aggregates at a time.
Not sure we even have a good model of the aggregates.
- Dan
On Tuesday, 20 March 2012 02:32:02 UTC, Steve Midgley wrote:Hi Pat,
I'm not sure what you mean by topology -- do you mean like network graphs? (I know how to string those words together and pretend that there is math(s) underneath that I understand)./group/learning-registry-collaborate?hl=en?hl=en
Say New York and New Jersey's standards are the same - well their LR nodes talk to each other happily (no issues in sharing)
Say New York and Maryland have the same for English but not science - so they share English materials but not science.
So you do the standards via a node venn diagram?
I may have missed the point entirely.
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
Daniel R. Rehak, Ph.D.
Learning Registry Technical Architect
ADL Technical Advisor
Skype: drrehak
Web: learningregistry.org
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
To post: learning-regis...@googlegroups.com
To unsubscribe:learning-registry-co...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
Joseph Chapman
Steve Midgley
Thanks for the clarification and it's great to have AB providing these services. Ultimately for any of this to be sustainable, we need business models underneath, so I'm happy to see your company taking this on.
And the value AB and others have created by tying disparate state and other curricular standards together is complex and not something a community project like LR could take on for sure. I'm personally glad if we don't have to take on even just this simple conversion between existing standards for CCSS. Providing an XML or JSON version (machine readable) as a format would be great when you can get to it (it's clear you're heading there with your greyed out pull-down entries). Please email this list (and LRMI) at least, when that's up.
Also, I really like that you're including API docs right in the HTML results set to make it obvious how to use it and how to get alternative formatted results in the future..
http://api.statestandards.com/services/rest/translate?api_key=get_your_api_key&from=ab&value=2AC1FD0A-74F7-11DF-80DD-6B359DFF4B22&to=asn&format=html
Steve
On 3/23/2012 7:38 AM, Kelly Peet wrote:
I find this thread interesting on a number of fronts.� Please excuse any etiquette violations I might be making in my post.
@Steve.� Regarding your opening example with the Common Core Canonical and ASN URLs, the equivalent AB URL is:
http://www.academicbenchmarks.org/search/?guid=7E402F7C-7440-11DF-93FA-01FD9CFF4B22
And, yes these are public documents in our collection.� Per a side discussion with Joe Hobson, who helpfully expressed that we need to make our data easier to discover, we have exposed a standards translation service much like the variety discussed in this thread (e.g. given an ASN ID, what is the AB GUID), which is running here:
http://academicbenchmarks.com/standards-translator
Regardless of where folks prefer a service like this to reside or which protocol is used to access it, there is a critical (and not very sexy) first step of creating the equations between so many fractured organizations attempting to articulate digital copies of standards.
Also, as noted, the tougher problem is finding relevant connections when the relationship between two sets of standards is not an "equals" sign, deemed out of scope for LR at this time.� A very prescient point.
@Joshua, Jim. Regarding canonical references and getting promulgators (i.e. SEAs, LEAs, etc) to play nicely according to the rules.� I agree it could happen, and generally has not occurred.� To that end, Academic Benchmarks is promoting a technically-sound solution directly to SEAs:
http://academicbenchmarks.com/ab-common-core
I completely agree that the separation of the GUID from the URI makes a more flexible model.� The Learning Standard Item to which you refer, sounds like the SIF XML (LearningStandardDocument and LearningStandardItem), which many of our clients prefer to receive standards from our collection.� It certainly is a valid format, among many, for representing standards in markup language.
Kelly Peet
Founder/CTO
Academic Benchmarks
On Wed, Mar 21, 2012 at 3:49 PM, Jim G <james.dona...@gmail.com> wrote:
[shortened version of my post on LRMI to this discussion]
The matching service is valuable, but it is also reasonable to expect
that the resources that LRMI calls promulgators have the publisher/
producer's canonical reference code and GUID in their database /
online reference.
In CEDS terms these identifiers are:
Learning Standard Item Code -- �A code designated by the publisher to
identify the statement, e.g. "M.1.N.3", usually not globally unique
and usually has embedded meaning such as a number that represents a
grade/level and letters that represent content strands.
and
Learning Standard Item Identifier -- An unambiguous globally unique
identifier.
(Note: CEDS v2 has URI as URL+GUID, candidate for CEDS v3 change is to
separate out GUID from URI, i.e. Learning Standard Item URL --
reference to the statement using a network-resolvable URI)
- Jim Goodell
On Mar 21, 1:02�am, Doug Gastich <dgast...@learning.com> wrote:
> @Steve: I think the only addition you need to make to reconcile to Pat's email is to add one word to your response (in CAPS):
>
> "If I have a thousand Khan academy videos (#1 to 1000) that I align to a single state standard STATEMENT called ABC�"
>
> Also, consider adding 'EdGate UUID' to your growing list of ID providers for standards statements.
>
> @ Joshua: I think you are correct to fear that agreement is required. Organizations like AB and EdGate (and to some extent, ASN) are in competition to be the de-facto canon. A huge portion of their services value goes out the window the moment an actual official standard is endorsed. It seems to me that Steve's approach here is to find a way to accept this as a condition of the system and work with it. But I agree, it creates a potential for failure at multiple points (the first one that comes to mind is getting somehow out of phase during an update to statement language).
>
> -Doug
>
> Douglas Gastich
>
> Director of Content and Partner Development
> Learning.com
>
> 503-517-4463begin_of_the_skype_highlighting������������503-517-4463
> � � - Dan
>
> On Tue, Mar 20, 2012 at 3:26 PM, Patrick.Lock...@googlemail.com<mailto:Patrick.Lock...@googlemail.com> <patrick.lock...@googlemail.com<mailto:patrick.lock...@googlemail.com>> wrote:> I'm not sure what you mean by topology -- do you mean like network graphs? (I know how to string those words together and pretend that there is math(s) underneath that I understand)./group/learning-registry-collaborate?hl=en?hl=en<http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en>
>
> On Tuesday, 20 March 2012 02:32:02 UTC, Steve Midgley wrote:
>
> Hi Pat,
>
>
> Say New York and New Jersey's standards are the same - well their LR nodes talk to each other happily (no issues in sharing)
>
> Say New York and Maryland have the same for English but not science �- so they share English materials but not science.
>
> So you do the standards via a node venn diagram?
>
> I may have missed the point entirely.
> --
> You received this message because you are subscribed to the Google
> Groups "Learning Registry: Collaborate" group.
>
> To post: learning-regis...@googlegroups.com<mailto:learning-registry-col labo...@googlegroups.com>
> To unsubscribe:learning-registry-co...@googlegroups.com<mail to:unsubscribe%3Alearning-registry-collaborate%2Bunsubscribe@googlegroups.c om>
>
> For more options, visit this group athttp://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
>
> --
> Daniel R. Rehak, Ph.D.
>
> Learning Registry Technical Architect
> ADL Technical Advisor
>
> Skype: drrehak
> Email: �daniel.re...@learningregistry.org<mailto:daniel.re...@learningregistry.org>
> � � � � � � daniel.rehak....@adlnet.gov<mailto:daniel.rehak....@adlnet.gov>
> Google Voice:+1 412 301 3040begin_of_the_skype_highlighting������������+1 412 301 3040
>> To post: learning-regis...@googlegroups.com<mailto:learning-registry-col labo...@googlegroups.com>
> --
> You received this message because you are subscribed to the Google
> Groups "Learning Registry: Collaborate" group.
>
> To unsubscribe:learning-registry-co...@googlegroups.com<mail to:unsubscribe:learning-registry-co...@googlegroups.com>
>
> For more options, visit this group athttp://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
>> To post: learning-regis...@googlegroups.com<mailto:learning-registry-col labo...@googlegroups.com>
> --
> You received this message because you are subscribed to the Google
> Groups "Learning Registry: Collaborate" group.
>
> To unsubscribe:learning-registry-co...@googlegroups.com<mail to:learning-registry-co...@googlegroups.com>
>
> For more options, visit this group athttp://groups.google.com/group/learning-registry-collaborate?hl=en?hl=enI'l be
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
To post: learning-regis...@googlegroups.com
To unsubscribe:learning-registry-co...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�
Steve Midgley
I don't want to let your email go without mention. Thank you for the really great and detailed inputs on this. It seems like a look up graph in SPARQL ASN could be a very valuable way to share look ups across curricular standard IDs. I do think these standard IDs are "sameAs" in a pretty significant way as they refer to the same semantic element (rare in the world!).
I know that Academic Benchmarks has said they will produce a translation service for anyone to use to convert across these things. I wonder if you can do the same thing with their GUIDs and your URLs? Their GUIDs (I think) are CC-by-nc-sa-nd, which ought to be compliant with your use? YMMV, so look into that before jumping.
Thanks again for a really great and interesting email on this -- if you do pursue let us know so we can share both AB and your service with anyone using LR.
Best regards (and keep in touch on this),
Steve
On 3/24/2012 5:52 PM, Joseph Chapman wrote:
To chime in on SPARQL, I set up some sample graphs in ASN�s Quad Store using Steve�s examples (I think I captured them correctly).� Let me preface this post by saying that making �owl:sameAs� relationships casually is not to be taken lightly as things are seldom �the same�.� Technically can it be done in SPARQL? I think so, but whether it_should_be_done, is another conversation.
So technically speaking:
Example #1:
If you stored various �sameAs� relationships like this:
ASN=>CCSS
MA=>CCSS
AB=>CCSS
as individual RDF statements in a graph, it may look like this (simplified):
and someone asks:� "Show me ALL the known standards that are same as this GUID from MA?" in SPARQL, it could look like this:
SELECT ?matches
WHERE
�{
� <http://stateStandard.com/1234> owl:sameAs ?o.
� OPTIONAL {?matches owl:sameAs ?o.}
� FILTER (?matches != <http://stateStandard.com/1234>)
�}
Where a user submits a known state identifier (<http://stateStandard.com/1234>) asking, �What is it same as?�, then passing that result back (so now, ?o == CCID) and continue looking for any other RDF subjects (variable - ?matches) that also declare to be sameAs the CCID��(?matches == ASN and Corporate GUID).
The ASN SPARQL response in a HTML table:
Example #2:
If you stored various �sameAs� relationships like this:
ASN=>CCSS
MA=>ASN
AB=>CCSS
As individual RDF statements in its own separate graph, it may look like this (simplified):
And you wanted to get from a known state ID, which only expresses alignment to ASN, to any other corporate GUID by walking the graph, you could run SPARQL:
SELECT ?s1 where
{
<http://stateStandard.com/1234> owl:sameAs ?o1.
OPTIONAL {?o1 owl:sameAs ?o2}.
OPTIONAL {?s1 owl:sameAs ?o2}.
FILTER (?s1 != ?o1)
}
Where you search for anything declared as sameAs to the known state ID (<http://stateStandard.com/1234>) (so you�d get ?o1 == ASN) then pass that ASN RDF statement while looking for what it is sameAs (so, ?o2 == CCID) then you look for any unknowns (?s1) that have declared to be the sameAs the CCID stored in ?o2.
The ASN SPARQL response in a HTML table:
I am not a SPARQL connoisseur and this does not take into account any special ontological reasoning setup on the Quad store beforehand, or storing this RDF data more efficiently to simplify the above queries.
I hope this is somewhat helpful?
Joseph
On Fri, Mar 23, 2012 at 5:47 PM, Steve Midgley <steve....@ed.gov> wrote:
Thanks Doug. I agree that movement to public, official and machine-readable standards from CCSS (endorsed by CCSSO and NGA) does make it hard for any other set of IDs to be considered as "canon" (good word!). I do hope this doesn't harm existing businesses - I think there are lots of areas to create value around common core standards.
I think we will all be coping with a multiplicity of standard IDs for a long time, even with CCSS official IDs.
I agree that including EdGate UUIDs is a really good point, if they are or become publicly visible (are they now?). I have no contact there. If you do, please email steve....@ed.gov with who I might talk with.
Could you elaborate on the risk factor you identified: "getting somehow out of phase during an update to statement language." I'm not sure I understand that.
On the plus side of all this, at least Learning Registry project isn't proposing to create a whole new set of standard ID's! :)
Steve
On 3/21/2012 1:02 AM, Doug Gastich wrote:
@Steve: I think the only addition you need to make to reconcile to Pat's email is to add one word to your response (in CAPS):
"If I have a thousand Khan academy videos (#1 to 1000) that I align to a single state standard STATEMENT called ABC�"
So if the standard was described in 1000 statements, then we would need 1000 "same as"�alignment�statements, one for each part to align it with another standard.
I think you want to align entire aggregates at a time.
Not sure we even have a good model of the aggregates.
� � - Dan
On Tuesday, 20 March 2012 02:32:02 UTC, Steve Midgley wrote:Hi Pat,
I'm not sure what you mean by topology -- do you mean like network graphs? (I know how to string those words together and pretend that there is math(s) underneath that I understand)./group/learning-registry-collaborate?hl=en?hl=en
Say New York and New Jersey's standards are the same - well their LR nodes talk to each other happily (no issues in sharing)
Say New York and Maryland have the same for English but not science �- so they share English materials but not science.
So you do the standards via a node venn diagram?
I may have missed the point entirely.
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
Daniel R. Rehak, Ph.D.
Learning Registry Technical Architect
ADL Technical Advisor
Skype: drrehak
Email:� daniel...@learningregistry.org
� � � � � � daniel.r...@adlnet.gov
Twitter: @danielrehak
Web:�� learningregistry.org
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
To post: learning-regis...@googlegroups.com
To unsubscribe:learning-registry-co...@googlegroups.com
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�
For more options, visit this group at
http://groups.google.com/group/learning-registry-collaborate?hl=en?hl=en
--
Joseph Chapman
--
You received this message because you are subscribed to the Google
Groups "Learning Registry: Collaborate" group.
�
�