A TP4 Structure Agnostic Bytecode Specification (The Universal Structure)
462 views
Skip to first unread message

Marko Rodriguez
Apr 25, 2019, 1:46:31 PM4/25/19
to gremli...@googlegroups.com, d...@tinkerpop.apache.org
Hello,
This email proposes a TP4 bytecode specification that is agnostic to the underlying data structure and thus, is both:
1. Turing Complete: the instruction set has process-oriented instructions capable of expressing any algorithm (universal processing).
2. Pointer-Based: the instruction set has data-oriented instructions for moving through referential links in memory (universal structuring).
Turing Completeness has already been demonstrated for TinkerPop using the following sub-instruction set.
union(), repeat(), choose(), etc. // i.e. the standard program flow instructions
We will focus on the universal structuring aspect of this proposed bytecode spec. This work is founded on Josh Shinavier’s Category Theoretic approach to data structures. My contribution has been to reformulate his ideas according to the idioms and requirements of TP4 and then deduce a set of TP4-specific implementation details.
TP4 REQUIREMENTS:
1. The TP4 VM should be able to process any data structure (not just property graphs).
2. The TP4 VM should respect the lexicon of the data structure (not just embed the data structure into a property graph).
3. The TP4 VM should allow query languages to naturally process their respective data structures (standards compliant language compilation).
Here is a set of axioms defining the structures and processes of a universal data structure.
THE UNIVERSAL STRUCTURE:
1. There are 2 data read instructions — select() and project().
2. There are 2 data write instructions — insert() and delete().
3. There are 3 sorts of data — tuples, primitives, and sequences.
- Tuples can be thought of as “key/value maps.”
- Primitives are doubles, floats, integers, booleans, Strings, etc.
- Sequences are contiguous streams of tuples and/or primitives.
4 Tuple data is accessed via keys.
- A key is a primitive used for referencing a value in the tuple. (not just String keys)
- A tuple can not have duplicate keys.
- Tuple values can be tuples, primitives, or sequences.
Popular data structures can be defined as specializations of this universal structure. In other words, the data structures used by relational databases, graphdbs, triplestores, document databases, column stores, key/value stores, etc. all demand a particular set of constraints on the aforementioned axioms.
////////////////////////////////////////////////////////////
/// A Schema-Oriented Multi-Relational Structure (RDBMS) ///
////////////////////////////////////////////////////////////
RDBMS CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
1. There are an arbitrary number of global tuple sequences (tables)
2. All tuple keys are Strings. (column names)
3. All tuple values are primitives. (row values)
4. All tuples in the same sequence have the same keys. (tables have predefined columns)
5. All tuples in the same sequence have the same primitive value type for the same key. (tables have predefined row value types)
Assume the following tables in a relational database.
vertices
id label name age
1 person marko 29
2 person josh 35
edges
id outV label inV
0 1 knows 2
An SQL query is presented and then the respective TP4 bytecode is provided (using fluent notation vs. [op,arg*]*).
// SELECT * FROM vertices WHERE id=1
select(‘vertices’).has(‘id’,1)
=> v[1]
// SELECT name FROM vertices WHERE id=1
select(‘vertices’).has(‘id’,1).project('name’)
=> "marko"
// SELECT * FROM edges WHERE outV=1
select('edges’).has('outV’,1)
=> e[0][v[1]-knows->v[2]]
// SELECT * FROM edges WHERE outV=(SELECT 'id' FROM vertices WHERE name=‘marko')
select('edges’).has(‘outV’,within(select(‘vertices’).has(‘name’,’marko’).project(‘id’)))
=> e[0][v[1]-knows->v[2]]
// SELECT vertices.* FROM edges,vertices WHERE outV=1 AND id=inV
select(‘vertices’).has(‘id’,1).select('edges').by('outV',eq('id')).select('vertices').by('id',eq('inV'))
=> v[2]
VARIATIONS:
1. Relational databases that support JSON-blobs values can have nested “JSON-constrained” tuple values.
2. Relational databases the materialize views create new tuple sequences.
//////////////////////////////////////////////////////////////////
/// A Schema-Less, Recursive, Bi-Relational Structure (GRAPHDB) //
//////////////////////////////////////////////////////////////////
GRAPHDB CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
1. There are two sorts of tuples: vertex and edge tuples.
2. All tuples have an id key and a label key.
- id keys reference primitive values.
- label keys reference String values.
3. All vertices are in a tuple sequence denoted “V”.
4. Vertex tuples have an inE and outE key each containing edge tuples.
5. Edge tuples have an outV and inV key each containing a single vertex tuple.
6. An arbitrary number of additional String-based tuple keys exist for both vertices and edges.
Assume the “classic TinkerPop graph” where marko knows josh and they have names and ages, etc.
A Gremlin query is presented and then the respective TP4 bytecode is provided (using fluent notation vs [op,arg*]*).
// g.V(1)
select(‘V’).has(‘id’,1)
=> v[1]
// g.V(1).label()
select(‘V’).has(‘id’,1).project('label’)
=> “person"
// g.V(1).values(‘name’)
select(‘V’).has(‘id’,1).project(‘name’)
=> “marko”
// g.V(1).outE('knows').inV().values('name')
select(‘V’).has(‘id’,1).project('outE').has('label','knows').project('inV').project('name’)
=> “josh”, “vadas”, “peter”
// g.V(1).out('knows').values('name')
select(‘V’).has(‘id’,1).project('outE').has('label','knows').project('inV').project('name’)
=> “josh”, “vadas”, “peter"
// g.V().has(‘age’,gt(25)).values(‘age’).min()
select(‘V’).has(‘age’,gt(25)).project(‘age’).min()
=> 29
// g.V(1).as(‘a’).out(‘knows’).addE(‘likes’).to(‘a’)
select(‘V’).has(‘id’,1).as(‘a’).
project(‘outE’).has(‘label’,’knows’).
project(‘inV’).
project(‘inE’).insert(identity(),’likes’,path(‘a’))
=> e[7][v[2]-likes->v[1]], ...
VARIATIONS:
1. Schema-based property graphs have the same tuple keys for all vertex (and edge) tuples of the same label.
2. Multi-labeled property graphs have String sequences for vertex labels.
3. Multi-property property graphs have primitive sequences for property keys.
4. Meta-property property graphs have an alternating sequence primitives (values) and tuples (properties).
5. Multi/meta-property property graphs support repeated values in the alternating sequences of the meta-property property graphs.
//////////////////////////////////////////////////////////////////////////
/// A Web-Schema, 3-Tuple Single Relational Structure (RDF TRIPLESTORE) //
//////////////////////////////////////////////////////////////////////////
RDF TRIPLESTORE CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
1. There is only one type of tuple called a triple and it is denoted T.
2. All tuples have a s, p, and o key. (subject, predicate, object)
- s keys reference String values representing URIs or blank nodes.
- p keys reference String values representing URIs.
- o keys reference String values representing URIs, blank nodes, or literals.
A SPARQL query is presented and then the respective TP4 bytecode is provided (using fluent notation vs [op,arg*]*).
- assume ex: is the namespace prefix for http://example.com#
// SELECT ?x WHERE { ex:marko ex:name ?x }
select(’T').by(’s’,is(‘ex:marko')).has(‘p’,’ex:name').project(‘o') -> "marko"^^xsd:string
// SELECT ?y WHERE { ex:marko ex:knows ?x. ?x ex:name ?y }
select(’T').by(’s’, is(‘ex:marko')).has(‘p’,’ex:knows’).
select(’T’).by(’s’,eq(‘o’)).has(‘p’,’ex:name’).
project(‘o’) -> “josh"^^xsd:string
VARIATIONS:
1. Quadstores generalize RDF with a 4-tuple containing a ‘g’ key (called the "named graph").
2. RDF* generalizes RDF by extending T triples with an arbitrary number of String keys (thus, (spo+x*)-tuples)).
///////////////////////////////////////////////////////////////////////
/// A Schema-Less, Type-Nested, 3-Relational Structure (DOCUMENTDB) //
///////////////////////////////////////////////////////////////////////
DOCUMENTDB CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
1. There are sorts of tuples: documents, lists, and maps.
2. Document tuples are in a sequence denoted D.
3. All document tuples have an _id key.
4. All tuple keys are string keys.
5. All tuple values are either primitives, lists, or maps. (JSON-style)
- primitives are either long, double, String, or boolean.
///////////////////////////////////////////////////////////
/// A Schema-Less Multi-Relational Structure (BIGTABLE) ///
///////////////////////////////////////////////////////////
BIGTABLE CONSTRAINTS ON THE UNIVERSAL STRUCTURE: (CASSANDRA)
1. There are an arbitrary number of global tuple sequences. (column families)
2. All tuple keys are Strings. (column key)
3. All tuple values are primitives. (row values)
/////////////////////////////////////////////////////////////////////////
/// A Schema-Less 1-Tuple Single-Relational Structure (KEYVALUESTORE) ///
/////////////////////////////////////////////////////////////////////////
KEYVALUESTORE CONSTRAINTS ON THE UNIVERSAL STRUCTURE:
1. There is one global tuple sequence.
2. Each tuple has a single key/value.
3. All tuple keys must be unique.
————————————————————————————————————————————————————————
————————————————————————————————————————————————————————
————————————————————————————————————————————————————————
WHY SEQUENCES?
In property graphs, V is a tuple sequence.
// g.V()select(‘V’)=> v[1], v[2], v[3],...// g.V(1)select(‘V’).has(‘id’,1)=> v[1]// g.V().has(‘name’,’marko’)select(‘V’).has(‘name’,’marko’)=> v[1]
If V were a tuple of vertex tuples, then V would be indexed by keys. This situation incorporates superfluous “indexing” which contains information auxiliary to the data structure.
// g.V()select(‘V’).values()=> v[1], v[2], v[3], ...// g.V(1)select(‘V’).project(‘1’)=> v[1]// g.V().has(‘name’,’marko’)select(‘V’).values().has(‘name’,’marko’)=> v[1]
In property graphs, outE is a tuple sequence unique to each vertex.
// g.V(1).outE()select(‘V’).has(‘id’,1).project(‘outE’)=> e[0][v[1]-knows->v[2]]...
In all structures, if x is a key and the value is a tuple, then x references a tuple sequence with a single tuple. In particular, for binary property graphs, project(‘inV’) is a single tuple sequence.
// g.V(1).outE(’knows').inV()select(‘V’).has(‘id’,1).project(‘outE’).has(‘label’,’knows’).project(‘inV’)=> e[0][v[1]-knows->v[2]]
————————————————————————————————————————————————————————
JOINS VS. TRAVERSALS
In relational databases, a join is the random-access movement from one tuple to another tuple given some predicate.
// g.V().outE().label()// SELECT edges.label FROM vertices, edges WHERE vertices.id = edges.outVselect(‘vertices’).select(‘edges’).by(id,eq(‘outV’)).project(‘label’)=> knows, knows, created, ...
In a graph database, the structure is assumed to be "pre-joined" and thus, a selection criteria is not needed.
// g.V().outE().label()select(‘vertices’).project(‘outE’).project(‘label’)=> knows, knows, created, …
A latter section will discuss modeling one data structure within another data structure within the universal data structure. In such situations, joins may become traversals given Tuple data caching and function-based tuple values.
————————————————————————————————————————————————————————
THE STRUCTURE PROVIDER OBJECTS OF A TP4 VIRTUAL MACHINE
Data structure providers (i.e. database systems) interact with the TP4 VM via objects that implement:
1. Tuple
- TupleSequence select(String key, Predicate join)
- V project(K key)
2. TupleSequence
- TupleSequence implements Iterator<Tuple>
3. and primitives such as String, long, int, etc.
These interfaces may maintain complex behaviors that take unique advantage of the underlying data system (e.g. index use, function-oriented tuple values, data caching, etc.).
This means that the serializers to/from TP4 need only handle the following object types:
- Bytecode
- Traverser
- Primitives (String, long, int, etc.)
- TupleProxy
- TupleSequenceProxy
This significantly simplifies the binary serialization format relative to TP3.
Tuple’s are never serialized/deserialized as they may be complex, provider-specific objects with runtime functional behavior that interact with the underlying data system over sockets/etc. Thus, every Tuple implementation must have a corresponding TupleProxy which provides an appropriate “toString()” of the object and enough static data to reconnect the TupleProxy to the Tuple within the VM. This latter requirement is necessary for distributed processing infrastructures that migrate traversers between machines.
- TupleProxy
- Tuple attach(Structure provider)
- String toString()
- Tuple
- TupleProxy detach()
Similar methods exist for TupleSequence.
————————————————————————————————————————————————————————
MODELING ONE DATA STRUCTURE WITHIN ANOTHER DATA STRUCTURE WITHIN THE UNIVERSAL DATA STRUCTURE
1. Rewrite the property graph bytecode to respective “property graph encoded” relational bytecode using a compiler strategy. (via a decoration strategy)
2. Develop Tuple objects that maintain functions for values that map the data accordingly.
With respects to 2.
VertexRow implements Tuplev = new VertexRow(1)v.project(‘outE’) // this method (for outE) computes the edge tuple sequence via SELECT * FROM edges WHERE outV=1
=> a bunch of EdgeRowTuples with similar function-based projection and selection operations.
It is possible to model any data structure within any database system, regardless of the native data structure supported by the database. In TP4, databases are understood to be memory systems (like RAM) optimized for particular tuple-structures (e.g. sequential access vs. random access, index-based vs. nested based, cache support, etc.).
————————————————————————————————————————————————————————
CUSTOM DATA STRUCTURE INSTRUCTIONS
In order to make provider bytecode compilation strategies easy to write, DecorationStrategies can exist that translate “universal data structure” read/write instructions to “specific data structure” read/write instructions. For example, a property graph specific read/write instruction set is namespaced as “pg” and the following bytecode
// g.V(1).out(‘knows’).values(‘name’)[[select,V] [has,id,eq(1)] [project,outE] [has,label,eq(knows)] [select,inV] [project,name]]===strategizes to (via PropertyGraphDecorationStrategy)===>[[pg:V,1] [pg:out,knows] [pg:values, name]]
Note that only read/write instructions need to be considered. All other instructions such as repeat(), choose(), count(), union(), is(), where(), match(), etc. are not effected by the underlying data structure.
————————————————————————————————————————————————————————
There is still much more to discuss in terms of how all this relates to query languages and processors. While I haven’t considered all forks in the road, I have yet to hit any contradictions or inconsistencies when looking a few-steps ahead of where this email is now.
Thank you for reading. Your thoughts are more than welcome.
Take care,
Marko.

Joshua Shinavier
Apr 25, 2019, 2:36:58 PM4/25/19
to gremli...@googlegroups.com, d...@tinkerpop.apache.org
+10. Great to see structure and process coming together in this way. I think the algebraic and relational idiom will serve TP4 well. ADTs + constraints are all we need in order to expose a wide variety of structured data models to TinkerPop. Traditional property graphs, hypergraphs, relational DBs, and anything expressed in typical data interchange languages like Protobuf, Thrift, Avro, etc. Graph I/O and graph stream processing becomes easier, because a graph is just a set of tuples. There are fewer barriers to formal analysis of schemas, queries, and mappings, and new forms of optimization become possible. 40+ years of database research is now more immediately applicable, and so is the wide world of category theory. Agreed that there are individual details to nail down, but the broad strokes of this are looking pretty good.
Josh
--
You received this message because you are subscribed to the Google Groups "Gremlin-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/6A0FF63D-8591-41AC-B024-2FF5629B4CD5%40gmail.com.
For more options, visit https://groups.google.com/d/optout.

Ryan Wisnesky
Apr 25, 2019, 3:28:21 PM4/25/19
to gremli...@googlegroups.com, d...@tinkerpop.apache.org
And 40+ years of programming languages research too :-)
> To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/CAPKNUSv2jPxbuuLBLO7F4JQGsU_x6Bp1HXPA2FVD8dWXOwx8Aw%40mail.gmail.com.
Marko Rodriguez
Apr 25, 2019, 4:31:40 PM4/25/19
to gremli...@googlegroups.com, d...@tinkerpop.apache.org
Hello,
After receiving comments from various people and re-reading the proposal over again, I thought it best to provide some fixes and extended notes.
————————————————————————————————————————————————————————
TP4 REQUIREMENTS ERRATA
- Point #2 should read:
The TP4 VM should respect the idiomatic shape of the data structure (not just embed the data structure into a property graph).
————————————————————————————————————————————————————————
SELECT/PROJECT NOTES
select(variable): jump to a sequence referenced by the global variable
by(predicate): ...and generate a sub-sequence based on the predicate.
by(predicate): ...and an arbitrary number of predicates can be added.
project(key...): jump to the value referenced by the key
- if more than one key is provided, then a tuple is generated.
While it may seem that select() should be written select().where(), note that the incoming object to where() is a tuple from the previously selected sequence, not the object doing the selecting (e.g. the left-join tuple). The by() step is a step modulator and thus, it is syntactic sugar extending the previous select() instruction with more arguments.
While it may seem that project() should be written values(), it is possible to generate tuples with project() in an analagous manner to project().by() in TP3.
select('vertices').has('id',1).project('id','age').by().by(incr()) => [1,30]
The names of these fundamental operations are not set in stone as the TP4 instructions have not been fully flushed out. select() was temporarily chosen as TP3 select() will most likely be dropped in TP4 in favor of the more specific path(string...), values(string...), and sideEffect(string...) instructions. Other names for select() could be join(), goto(), sequence(). The problems with these names are:
1. join(): implies that two tuples are being concatenated. (perhaps the best term)
2. goto(): goto().by() doesn't sound right.
3. sequence(): sequence() is a long word.
————————————————————————————————————————————————————————
THIS IS TP4 BYTECODE NOT GREMLIN
Realize that all select()/project() examples are denoting TP4 Bytecode NOT Gremlin. I’m simply using Gremlin-like syntax to make it easier to read instead of writing a bunch of nested [[][][][][][]]]]] op/arg instructions.
As a side, realize that Gremlin is no longer part of the TinkerPop virtual machine. The TP4 VM only understands bytecode. Gremlin is now a (small) separate project that simply generates TP4 bytecode and iterates results.
————————————————————————————————————————————————————————
RDBMS NOTES
Daniel Kuppitz says that SQL Server supports UDTs (user defined types). Thus, an RDBMS VARIATION is one that supports tuple values, where the tuple contains the requisite data for manifesting an instance of the user defined type.
————————————————————————————————————————————————————————
GRAPHDB NOTES
1. The classic Neo4j 1.0 property graph is called "A Schema-Less, Recursive, Bi-Relational Structure"
- The term recursive refers to the fact the vertices contain edges contain vertices contain edges ...
- This is not a "nested" or "tree" structure as children can be parents of their ancestors.
- I couldn’t think of a better word than “recursive." ??
- Bi-Relational refers to the two sorts of tuples: vertices and edges. However, there is only one global tuple sequence denoted "V".
2. There is no global edge tuple sequence "E" because the natural shape of a graph has edges co-located with vertices. Instead
// g.E()select('V').project('outE')
3. In schemaless graphs, realize that tuples of the same sort need not have the same keys.
- vertex tuples can have different properties.
- edge tuples can have different properties.
- In general, at the universal data structure level, tuples in the same sequence need not have the same keys.
————————————————————————————————————————————————————————
RDF TRIPLESTORE NOTES
1. TP4 will not support URI objects. URIs must be represented as Strings.
- It may be worthwhile having "typed Strings" in TP4: https://github.com/Microsoft/BosqueLanguage/blob/master/docs/language/overview.md#0.4-Typed-Strings
2. The examples provided have various bugs (sorry!). A correct and more complex example is provided below.
- "get the name of the people that marko knows who have the same age as marko":
SELECT ?z WHERE {
ex:marko ex:knows ?x.
ex:marko ex:age ?y.?x ex:age ?y.?x ex:name ?z}select('T').has('s','ex:marko').has('p','ex:knows').project('o').as('x').select('T').has('s','ex:marko').has('p','ex:age').project('o').as('y').select('T').by('s',path('x')).by('o',path('y')).has('p','ex:age').select('T').by('s',path('x')).has('p','ex:name').project('o').as('z')
- This can all be made run-time optimized with the match() instruction.
- Again, realize that this is bytecode, not Gremlin. I’m simply writing the bytecode in a Gremlin-like syntax to make it easier to read.
3. Unlike TP3, an RDF graph is not being embedded in a property graph.
- TP4 will support native RDF. (unlike TP3)
- A SPARQL compiler to TP4 bytecode will be W3C compliant. (unlike TP3)
————————————————————————————————————————————————————————
DELETE
I never discussed delete(). It is simple:
1. select(variable).delete()- deletes the entire global sequence.- select('vertices').delete() in an RDBMS is equivalent to DROP TABLE.- select('T').delete() in an triple store deletes all the data.- select('V').delete() in a property graph deletes all the data- select('V').has(id,1).delete('outE')// g.V(1).outE().drop()- select('V').has(id,1).project('outE').has('weight',gt(0.5))// g.V(1).outE().has('weight',gt(0.5)).drop()2. delete(key...)- deletes the key/value entry of a tuple.- select('V').delete('name') in property graphs removes all names from the vertices.
————————————————————————————————————————————————————————
Hope this clears up any confusions.
Joshua Shinavier
Apr 26, 2019, 10:31:27 AM4/26/19
to gremli...@googlegroups.com, Joshua Shinavier, d...@tinkerpop.apache.org
These past few days, I have had some requests for a more detailed write-up of the data model, so here goes. See also my Global Graph Summit presentation.
Algebraic data types
The basic idea of this data model, which I have nicknamed algebraic property graphs, is that an "ordinary" property graph schema is just a special case of a broader class of relational schemas with primary and foreign keys. What are edges if not relations between vertices? What are properties if not relations between elements (edges or vertices) and primitive values? In this model, each edge label and property key identifies a distinct relation in a graph. Vertex types identify unary relations, i.e. sets.
For example, in the schema of the TinkerPop classic graph, below, Person and Project are distinct vertex types, knows and created are distinct edge types, etc. The primitive types are drawn in blue/purple, the vertex types are salmon-colored, the edge types are yellow, and the property types are green. The "o" and "i" ports on the boxes represent the "out" (tail) and "in" (head) component of each edge type or property type.
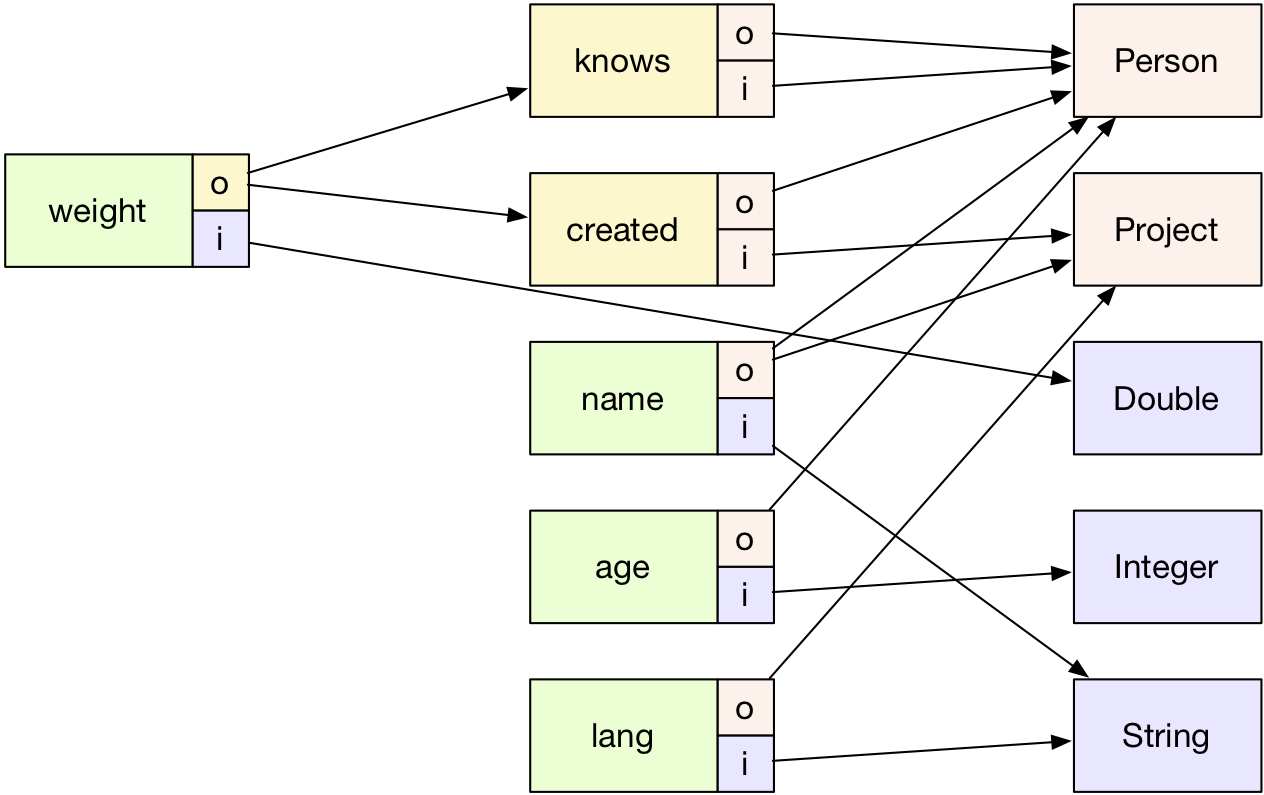
Some details which should stand out visually:
1) In a typical property graph like this one, each type must be placed at one of three levels: primitive or vertex, vertex property or edge, or edge property. Vertex meta-properties would be at the third level as well, if this graph had any. All projections (arrows between types) run from higher levels to lower levels.
2) Primitive types and vertex types have no projections; all other types have two. Element ids (i.e. primary keys) are not depicted.
3) Some ports have more than one outgoing arrow. This represents disjunction, e.g. a weight property can be applied either to a knows edge or a created edge.
Although disjoint unions may not be common in relational schemas (because they introduce complexity), they are necessary for supporting general-purpose algebraic data types, which are fundamental to a broad swath of data models which we support at Uber, and which we would like to support in TinkerPop4.
As we expand beyond vanilla property graphs, we quickly get into greater-than-binary relations such as this hyper-edge type:
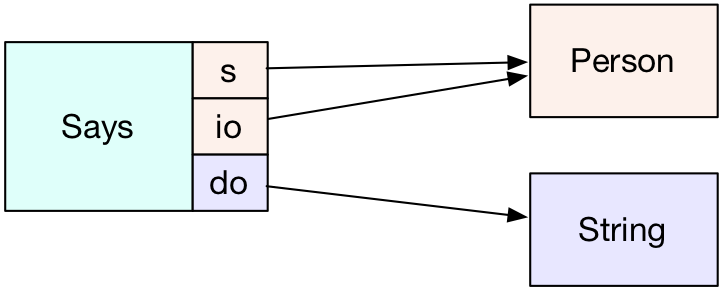
The type is drawn in a different color to indicate that it is neither a vertex type (an element with no projections), a property type (an element with projections to another element and a primitive value) or an edge (an element with projections to two other elements). It is simply an element. The guiding principle here is similar to that of TinkerPop3's Graph.Features: start with a maximally expressive data model, then refine the data model for a particular context by adding constraints. Some examples of schema-level constraints:
*) May a type have more than two projections? I.e. are hyper-edges / n-ary relations supported?
*) Can edge types depend on other edge types? I.e. are meta-edges (sometimes confusingly called hyperedges) supported?
*) Can property types depend on other property types? I.e. are meta-properties supported?
*) Does every relation type of arity >= 2 need to have a primary key? I.e. are compound data types supported (e.g. lat/lon pairs, records like addresses with multiple fields)?
*) Are recursive / self-referential types (e.g. lists or trees of elements or primitives) allowed?
etc.
There are also constraints which apply at the instance level, e.g.
*) May a graph contain two edges which differ only by id? I.e. are non-simple edges supported?
*) May a graph contain two properties which differ only by id? I.e. are multi-properties supported?
*) May a generalized property or edge instance reference itself?
etc.
With the right set of constraints, we obtain a basic property graph data model. Relaxing the constraints, we can define and manipulate datasets which are definitely not basic property graphs, but which are nonetheless graph-like, and for which it makes sense to perform graph traversals. Enter TinkerPop4.
Graph traversal as relational algebra
What are the fundamental operations of labeled graph traversal? In TinkerPop3, the basic element-to-element traversal steps are outE, inV, inE, and outV. These allow you to traverse an edge tail-to-head or head-to-tail, stopping in the middle to look for edge properties, or exotic things like meta-edges (Titan used to have them!) In TP4, however, we want a clear correspondence between graph traversal steps and relations. That means beginning to think about graph elements, such as edges and properties, as tuples like the ones above, and graph operations as operations on tuples. The best-studied procedural language for working with tuples is relational algebra, a fairly simple language having only five basic operations:
- projection: given a relation of arity n, produce a relation of arity k <= n by dropping any columns we don't care about. For example, choose only the in-vertices of knows edges, ignoring the out-vertices.
- selection: given one or more column/value pairs, find the matching subset of a relation. For example, find all knows edges in which the out-vertex is v[1].
- Cartesian product: concatenate each tuple in relation R with each tuple in relation S. For example, the product of a person vertex type with itself gives you all possible knows edges (without ids).
- union: the set union of two relations of the same type. E.g. we might want to find the union of all of the projects Marko created and all of the projects Josh created.
- difference: the set complement of a relation with another relation of the same type. E.g. we might want to find all of the projects Josh created which Marko did not create.
Other operations, such as joins, can be derived from the above.
So, which of these operations are relevant to graph traversal? All of them, but the first two are especially important. All of outE, inV, inE, and outV can be expressed with a combination of select() and project(). So can related operations on properties and on hyper-edges. The right Gremlin or pseudo-Gremlin syntax for selection and projection is a matter of taste; as long as the supported steps map neatly to the relational algebra operations, we are in business.
Graphs as tables
This will get a little involved. Now that element types are relations, they have a straightforward representation as tables in a relational database. However, they actually have more than one straightforward representation, so it is necessary to choose one when storing or transmitting graph data as tables. The two main alternatives here are very different in terms of table structure, but luckily, they are entirely equivalent.
Option #1 is to store all edge relations and all property relations (anything with the same arity and column types) as one big table. Marko illustrated this option above, with:
edges
id outV label inV
0 1 knows 2
Let's expand this to all edges in the TinkerPop classic graph. I will also tweak the order of the columns and rename outV and inV to out and in, just 'cos.
edges
id label out in
7 knows 1 2
8 knows 1 4
9 created 1 3
10 created 4 5
11 created 4 3
12 created 6 3
And that is all of our edges. What about properties? If there are no multi-properties or meta-properties in the graph, then you can inline the properties with the vertices and edges, as Marko did:
vertices
id label name age
1 person marko 29
4 person josh 32
Otherwise, you will need a separate table for properties, which will look much like the edge table. Let's assume vertex and edge ids won't collide, so we can use a single table for vertex properties and edge properties:
properties
id label out in
13 name 1 marko
14 age 1 29
15 name 2 vadas
16 age 2 27
...
I am highlighting the fact that these properties are elements and have ids. Again, in a graph without multi- or meta-properties (or edges incident on properties), there is no need for property ids, so table schemas can be optimized accordingly.
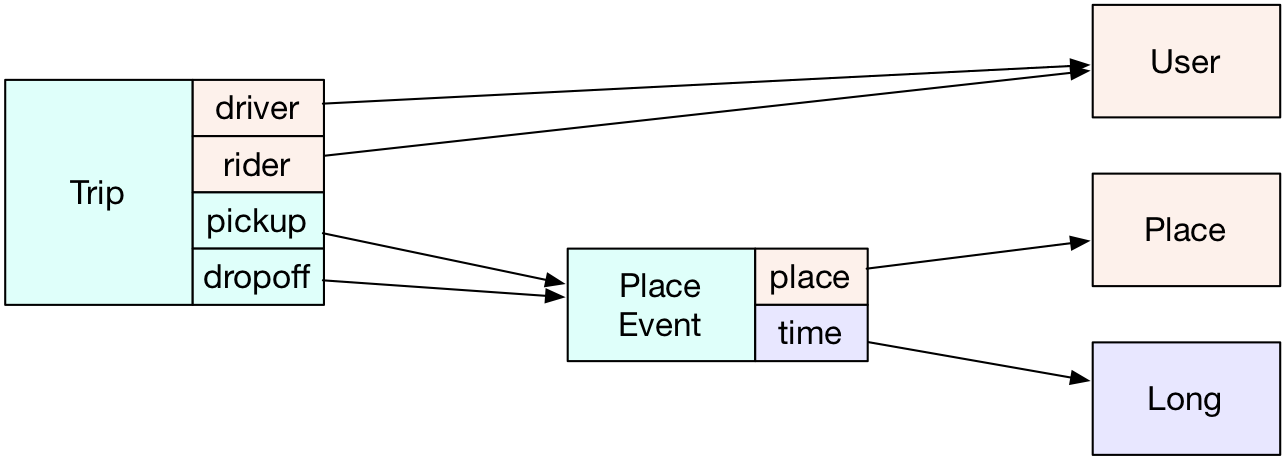
One more element type before we move on: hyper-edges. A hyper-edge type is essentially any relation with a primary key. Let's use the Trip example from above:
hyper4
id label f1 f2 f3 f4
42 Trip 4 1 101 102
43 Trip 4 2 103 104
44 Trip 4 6 105 106
That's me driving Marko, Vadas, and Peter around Santa Fe. If I had another hyper-edge relationship with four fields, e.g. CubicleNeighbors, its elements would belong in the same table. Apart from the fact that the columns of this table do not have informative names, the grouping of a given relation into a particular table is not particularly meaningful, and does not prevent us from having a large number of tables. That brings us to:
Option #2 -- one table per relation. With this approach, we have a separate table for each edge type, and it is no longer necessary to store label as a column:
knows
id out in
7 1 2
8 1 4
created
id out in
9 1 3
10 4 5
11 4 3
12 6 3
Our hyper-edge tables look better, as well:
Trip
id driver rider pickup dropoff
42 4 1 101 102
43 4 2 103 104
44 4 6 105 106
While this is a simple and efficient way to deal with hyper-edges, it is only appropriate for strongly-typed traversals. For example, our tables will work just fine for evaluating the query v.out("knows").out("knows"), but they are terrible for evaluating the query v.out().out(), because we do not know which table to query for either out() step -- forcing us to query all tables, or at least, all tables with a matching field type.
Whether you will be happier with the table-per-schema or table-per-relation style depends on your application. In the Uber knowledge graph, we create tables per relation (multiple tables; one for each supported traversal direction) because it gives us better data isolation. Again, though, the two styles are logically equivalent. The process of moving between them is known as the Grothendieck construction.
One last thing to note is that in the case of sum types like the name property (which can be applied to either a person OR a project) you need to store the tag (label) along with the reference. In the table-per-relation style, the name table should look like this:
name
id out outLabel in
13 1 person marko
15 2 person vadas
17 3 project lop
18 4 person josh
19 5 project ripple
20 6 person peter
Monadic traversals
In functional programming, monads are the go-to trick for building functional pipelines which carry some sort of state along the chain of evaluation. They can be used to deal with branching, optionality, side-effects, and much else besides. The pre-Gremlin language Ripple was monadic, with the exception of some side-effectful primitives. So is Gremlin, more or less. However, as Michael Pollmeier has pointed out, Gremlin does not consistently fulfill the monad laws.
I think it would be very worthwhile to explore a purely functional style of evaluation for the TP4 VM. This could be particularly useful for encapsulating side-effects like element insertion and deletion, and also for a simple and uniform approach to build-as-you-traversal artifacts like paths and subgraphs. Monadic expressions have a well-defined order of evaluation, and in the case of side-effects, have a natural correspondence with transactions, as well.
For example, at the end of a monadic traversal which inserts and/or deletes a number of elements, you would be left not only with path-eval result of the traversal, but also with a reference to the graph as it exists if the inserts and deletions are committed. You can then inspect and throw away that reference, or actually commit it. This gives the TP4 VM some native transaction handling, independent of the vendor database. As the data model is now simpler, in a way, defining monad-friendly traversal steps should also be simpler.
Pattern matching
One of the main advantages of algebraic data types in a functional language is the opportunity to perform functional pattern matching. For example, if we have an edge type destination whose in-type is either an Address or a GeoPoint, we can send our traverser down the appropriate code path using a case statement. For example, using an imaginary case() step:
trip.project("destination").case("Address", [address-specific traversal here]).case("GeoPoint", [point-specific traversal here])
Much more expressivity and elegance are available if traversals are written in a language that natively supports pattern matching, such as Scala.
Think I'm running out of steam. Wrapping up.
Links and kudos
The algebraic property graph concept was developed at Uber for our knowledge graph and data standardization efforts, with an eye toward the future TP4. Since my talk in Austin, I have been in contact with Marko, category theorist Ryan Wisnesky, and also the Property Graph Schema Working Group w.r.t. formalizing the model and tying everything together. Much earlier, Henry Story and I had some interaction around his work on applying category theory to RDF. Ryan in particular has been feeding me a steady stream of background material on category theory and relational database theory. His colleague David Spivak was here at Uber earlier this week, and honored us with a great talk entitled "Categorical Databases". If you are looking for a non-brain-herniating introduction to category theory, I highly recommend David's latest book (with Brendan Fong), Seven Sketches in Compositionality. Bartosz Milewski's blog and videos are a good resource for developers, as well. For an introduction to relational algebra and relation calculus, see Relational Databases, Logic, and Complexity. Finally, for an overview of the property graph standardization effort, check out Juan Sequeda's trip report from the recent W3C workshop.
Josh
--
You received this message because you are subscribed to the Google Groups "Gremlin-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/129F051C-71DB-49F0-B535-4F9C53D80924%40gmail.com.

hid...@gmail.com
Apr 26, 2019, 2:51:49 PM4/26/19
to Gremlin-users
Hello Josh,
I've tried to come up with a formalisation of Algebraic Property Graphs in the style we also use for the Property Graph Schema Working Group. That would make it easier to keep track of the relationship and to see if there is some kind of divergence, which I would like to avoid. Can you take a look and tell me if it is faithful to what you had in mind? I might have overgeneralised it (so no restrictions on the number of levels, for example) but that seemed to me better then the opposite, since being general seemed to me the overarching goal here, plus that tends to keep the formal definition more simple, if perhaps harder to understand.
Kind regards,
-- Jan Hidders
To unsubscribe from this group and stop receiving emails from it, send an email to gremli...@googlegroups.com.
Joshua Shinavier
Apr 29, 2019, 7:46:58 PM4/29/19
to gremli...@googlegroups.com, Joshua Shinavier
Hi Jan,
Thanks very much for this formalization. Glad to be on a path to alignment.
tl; dr of the following is that the APG data model is all about the graph schema, so I have refined your formalization to reflect this. We lean on the category theoretical notion of a functor for the relationship between a graph instance and a graph schema, so I have left this open. Maybe Ryan can think of a formulation which does not involve functors, and does not double/triple the number of slides by defining homomorphisms everywhere, which is what I might try to do.
Here is a set-theoretic formulation of a graph schema, re-using as much as I can of your definitions:
D is a countably infinite set of primitive data types
L is a countably infinite set of element types (labels)
P is a countably infinite set of port/field names. Typical field names in a property graph are"out" and "in".
We also need product and sum types. Let's define
T∧ as the set of product (tuple / record) types, and
T∨ as the set of sum (disjoint/tagged union) types
For convenience, let's also define the set of all types T := L ∪ D ∪ T∧ ∪ T∨. Now,
φ : (L ∪ T∧ ∪ T∨) → 𝒫(P × T) is the mapping of an element type, product type, or sum type to its fields. Only primitive data types have no associated fields, although the set of fields for an element type, product type, or sum type may be empty.
Some examples:
- For any vertex type, the fields are ∅.
- For a knows edge type, the fields are {("out", Person), ("in", Person)}.
- For the name property, the fields are {("out", Person | Project), ("in", String)}, where Person | Project is shorthand for a tagged union with fields like {("person", Person), ("project", Project)}.
- for the Trip example, the fields are {("driver", User), ("rider", User), ("pickup", PlaceEvent), ("dropoff", PlaceEvent)}.
A schema S, then, is simply a set of element types: S ⊆ L.
Likewise a graph G is simply a set E of elements. A graph is not necessarily finite; in the case of graph streams, IMO it is useful to think of an unbounded sequence of elements belonging to an infinite set.
This is where things start to become a little redundant if you don't invoke category theory. You do not really even need to say what graph elements are, so long as you can define a functor F between the graph and the schema. Elements might be database rows, key/value maps, anything that respects the structure of the schema. The functor includes your λ : E → L, which maps every element to its label, but it also maps everything else which we consider to make up the graph to a corresponding thing in the schema, including functions over the graph. For the composition of any two functions h = g ∘ f, we have F(h) = F(g) ∘ F(f). For example, if a graph dataset consists of these JSON objects (note: completely made-up schema and syntax):
[
{
"id": "0042",
"label": "PlaceEvent",
"time": 1556377927395,
"place": "0043"
},
{
"id": "0043",
"label": "Place",
"lat": 37.3986431,
"lon": -122.1387882
}
]
and we have given a certain semantics to the attributes such that "label" indicates an element type, "id" a primary key, and the other attributes correspond to field names for the type, then we are bound by F to pair "place" with "PlaceEvent" only if the Place type has a corresponding field "place". The object with id "0043" can only have the label "Place", etc.
Josh
To unsubscribe from this group and stop receiving emails from it, send an email to gremlin-user...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/gremlin-users/7d70bb2e-3c42-4ccf-b96e-0a9ce3316534%40googlegroups.com.
Reply all
Reply to author
Forward
0 new messages