The scheduler needs a fix and quick.
246 views
Skip to first unread message

de Witte
Sep 1, 2011, 12:51:34 PM9/1/11
to google-a...@googlegroups.com
A majority of the pricing problems are related to the way the scheduler works. If it is that important then put it in the hand of the users. With some simple API calls we can control our scheduler.
The feature request is to handle your own instances via the Scheduler API.
The restriction is that you can never shutdown the last instance.
http://code.google.com/p/googleappengine/issues/detail?id=5755
The feature request is to handle your own instances via the Scheduler API.
- Via the api you can shut down instances and create instances.
- For each instance you can obtain information such as:
- latency data, QPS, Requests, Age, Memory, Availability, Active.
- Obtain total of instance hours.
- Disable or enable the automatic creation of instances.
The restriction is that you can never shutdown the last instance.
http://code.google.com/p/googleappengine/issues/detail?id=5755

Frank
Sep 1, 2011, 10:52:37 PM9/1/11
to google-a...@googlegroups.com
Agreed. The scheduler is not reliable for pricing. And the pricing is based on instances being spawned. This is total non sense.
This is a personal message to the App Engine team: http://www.google.com/events/io/2011/sessions/fireside-chat-with-the-app-engine-team.html
At google there are Product Managers and Software Engineers and Directors. I bet the smart engineer coding the scheduler does not consult with the Product Manager who set the prices when talking to his director whose only goal is to make money.
So the lack of team cohesion is screwing us?
Please PM go talk to the engineer to get a reasonable scheduler out there, one that we developers can get control and rely on.
or
Please engineer, go talk to the PM and tell him that his MBA pricing method does not make any sense. He should go work at Mc Kinsey or Microsoft, but at Google we treat developers differently (at least you used to...)
or
Director, yes director, can you please get your PMs and Engineers to get their act together ?
If you expect us to pay you, you should do a better job as a team.
de Witte
Sep 2, 2011, 3:42:59 AM9/2/11
to google-a...@googlegroups.com
Did some more analyzing this morning after changing the settings last night to:
Max Idle Instances: ( 1 )
Min Pending Latency: ( 15.0s )
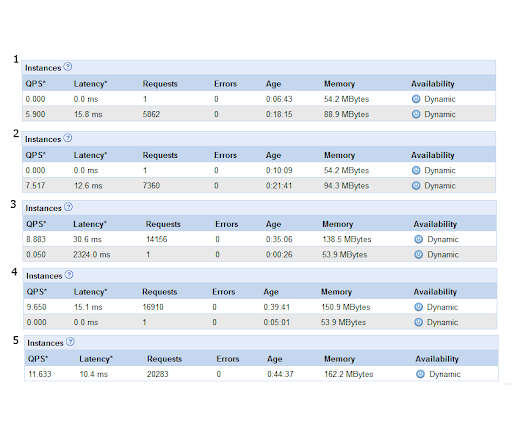
After 1 hours and too many coffee cups, I got the following results.
You can clearly see that the scheduler starts a second active instance for no reasons. It does nothing for 15 minutes, after that it dies but a new one is created soon after, repeating the process.
At point 6, for the third time a second instance has been created. This time the load goes to the second instance and the first one becomes idle.
During 45 minutes I paid for >15 instance minutes doing nothing.
There is second bug, at point 3, the request has to wait 2.4 seconds for the start-up. This request could easily be handled by the first instance. The second instance would be started in the background and the user would have his request back within 20 ms.
Any developer feedback would be welcome.
Max Idle Instances: ( 1 )
Min Pending Latency: ( 15.0s )
After 1 hours and too many coffee cups, I got the following results.
You can clearly see that the scheduler starts a second active instance for no reasons. It does nothing for 15 minutes, after that it dies but a new one is created soon after, repeating the process.
At point 6, for the third time a second instance has been created. This time the load goes to the second instance and the first one becomes idle.
During 45 minutes I paid for >15 instance minutes doing nothing.
There is second bug, at point 3, the request has to wait 2.4 seconds for the start-up. This request could easily be handled by the first instance. The second instance would be started in the background and the user would have his request back within 20 ms.
Any developer feedback would be welcome.

Bay
Sep 2, 2011, 4:21:02 AM9/2/11
to google-a...@googlegroups.com
I completely agree with the above and am experiencing exactly the same issue with the scheduler spawning new instances that do nothing instead of letting the first instance deal with the requests - which is visible in the logs and code that it easily could do.
de Witte
Sep 2, 2011, 4:48:20 AM9/2/11
to google-a...@googlegroups.com


Philip
Sep 2, 2011, 4:54:51 AM9/2/11
to Google App Engine
@de Witte
Do you know there will be also a tighter memory limit you most likely
exceed?
On Sep 2, 10:48 am, de Witte <jcreator.xi...@gmail.com> wrote:
> <https://lh4.googleusercontent.com/-cnnJWBgZNl8/TmCYTtq9XKI/AAAAAAAAAC...>
Do you know there will be also a tighter memory limit you most likely
exceed?
On Sep 2, 10:48 am, de Witte <jcreator.xi...@gmail.com> wrote:
> <https://lh4.googleusercontent.com/-cnnJWBgZNl8/TmCYTtq9XKI/AAAAAAAAAC...>
de Witte
Sep 2, 2011, 5:16:45 AM9/2/11
to google-a...@googlegroups.com
The app itself doesn't need much memory. The memory footprint is high because of the many active threads to handle the requests.
Less memory > means lesser threads > means lesser requests to be handled asynchronously by a single instance.
So hopefully they won't reduce it, where did you read it?
Less memory > means lesser threads > means lesser requests to be handled asynchronously by a single instance.
So hopefully they won't reduce it, where did you read it?

Tom Phillips
Sep 2, 2011, 5:32:38 AM9/2/11
to Google App Engine
Are you using JDO by any chance de Witte?
There is a bad connection leak in DataNucleus (OMFContext) that
results in major leaked memory. If you have non-transactional reads
enabled in jdoconfig.xml (the default)
you have this leak.
Event when the request limit was only 15000, my instances grew their
whole life up (on every read) to about ~130MB by the 15000 requests
(and would have kept growing)
After changing to:
<property name="javax.jdo.option.NontransactionalRead" value="false" /
>
and wrapping all reads (including queries) in transactions, my
instances hang steady at ~80-90MB. I'll keep it his way until the
problem is fixed.
I found the leak when profiling with JProfiler, and then noticed there
was an old issue raised by the datastore guys on it that was since
closed pending an eventual upgrade to Datanucleus 3.0. Can't seem to
find the issue right now though.
/Tom
There is a bad connection leak in DataNucleus (OMFContext) that
results in major leaked memory. If you have non-transactional reads
enabled in jdoconfig.xml (the default)
you have this leak.
Event when the request limit was only 15000, my instances grew their
whole life up (on every read) to about ~130MB by the 15000 requests
(and would have kept growing)
After changing to:
<property name="javax.jdo.option.NontransactionalRead" value="false" /
>
and wrapping all reads (including queries) in transactions, my
instances hang steady at ~80-90MB. I'll keep it his way until the
problem is fixed.
I found the leak when profiling with JProfiler, and then noticed there
was an old issue raised by the datastore guys on it that was since
closed pending an eventual upgrade to Datanucleus 3.0. Can't seem to
find the issue right now though.
/Tom
Bay
Sep 2, 2011, 5:57:37 AM9/2/11
to google-a...@googlegroups.com
This has nothing to do with memory leaks. As I told before I experience the exact same problem and
1) the new limits are not in force yet
2) there are no mentions in the log that a soft memory limit has been reached (which there are, if you have a leak and it closes down instances as a consequence)
3) settings about max. idle instances and latency before new instance is spawned are already set to a configuration that should produce the least amount of instances
I ask you please try not to derail the discussion from the fact that the scheduler is broken and needs
1) a quick fix in the form of a user-setting to allow only 1 instance being run (as the needless and passive instances spawned are costing a lot of money under the new regime for small apps)
2) a long-term fix so that it does not produce new instances that go around doing nothing (this should help larger apps as well)
Philip
Sep 2, 2011, 6:02:33 AM9/2/11
to Google App Engine
I'm sorry I don't find the original source anymore (it was somewhere
in the BIG faq thread) but I've asked for confirmation in the IRC
channel. With the new pricing there will be a 128mb memory limit for
frontend instances.
in the BIG faq thread) but I've asked for confirmation in the IRC
channel. With the new pricing there will be a 128mb memory limit for
frontend instances.
Tom Phillips
Sep 2, 2011, 6:15:07 AM9/2/11
to Google App Engine
The memory issue is indeed tangental to the scheduler issues. A few of
us just happened to notice it from de Witte's instance snapshot and
figured we'd point it out as a separate issue and potential problem
for him once the 128MB limit is enforced.
I believe that that instance would already be killed off prematurely
in the backend with an OutOfMemoryError. And will be in the frontend
as well at some point (soon?).
/Tom
us just happened to notice it from de Witte's instance snapshot and
figured we'd point it out as a separate issue and potential problem
for him once the 128MB limit is enforced.
I believe that that instance would already be killed off prematurely
in the backend with an OutOfMemoryError. And will be in the frontend
as well at some point (soon?).
/Tom

Anders
Sep 2, 2011, 7:03:35 AM9/2/11
to google-a...@googlegroups.com
As I wrote in another thread, I think Google should offer free and unlimited instances. Google will still make a lot of money on the quotas. And the complex and messy configuration of instances and the scheduler would be something Google could work on under the hood so to speak. A cloud service should provide a high abstraction level, not ADD more and more complexity for the customers. Let's not turn back to the old days when only scientists in white lab coats could operate computers. What will the next step be? Thousands of parameters for us customers to adjust for the datastore?
Frank
Sep 2, 2011, 7:30:15 AM9/2/11
to google-a...@googlegroups.com
+1. We are going backwards on this. If we end up having to tweak the scheduler manually we're better off running cheaper instances on other hosting services.
Next step is that we WILL have to know about the datacenters because of the latency between instances which will impact the number of running instances.
We are building business functionality with APIs. App Engine should charge on API calls, not on the electricity it takes to move bits from one data center to the other.
Just raise the cost of API calls if necessary.

Brandon Thomson
Sep 2, 2011, 10:04:34 AM9/2/11
to google-a...@googlegroups.com
Yes, I seem to have the same issue. The scheduler basically keeps an idle instance around all the time even though latency on the first instance is 1.8ms and it is not necessary.
Bay
Sep 2, 2011, 12:05:02 PM9/2/11
to google-a...@googlegroups.com
Here's another example of the broken scheduler.

My app lives on around 64-64MB of RAM. Consistenly (the screendump should testify to that). I've restricted the settings to spawn as few instances as possible. As seen the load is very, very small. Yet, for some reason, the scheduler decided to spawn a new instance (14 minutes old on the screendump) instead of the old one (56 minutes old) that hardly had any load (12 requests) and consumed the same amount of memory. As a result, the old instance now sits (but still runs) without doing anything apart from billing me - and the new one took over.
This picture is reoccouring all day long - with the exception that sometimes there is an idle instance too (that I will also have to pay for).
Can someone please tell me how I am supposed to believe that this is worth 250 USD a year, for a small non-profit app that I finance out of my own pocket?
Being a trusted tester on several API's, trusting in the tagline that it was a perfect platform for small developers that just had a good idea, I now feel sad that I helped Google build this platform - and recomended it to my friends.
In the end, I will have to write a message to the 1000 regular users of my webpage, letting them know the history of this, and pointing their anger to Google. Something I never in my wildest nightmare thought I would have to do.
Bay
Sep 2, 2011, 12:20:27 PM9/2/11
to google-a...@googlegroups.com

Shit I really, really used to like Google...

Francois Masurel
Sep 2, 2011, 4:33:43 PM9/2/11
to google-a...@googlegroups.com
You might want to star this issue :
http://code.google.com/p/googleappengine/issues/detail?id=5414 -> GAE doesn't seem to take "Min Pending Latency" into account
Francois

vlad
Sep 2, 2011, 8:28:46 PM9/2/11
to google-a...@googlegroups.com
Perfect way to shoot yourself in the foot. Be careful what you ask for. Googlers like feature requests like that.
Francois Masurel
Sep 3, 2011, 4:16:11 AM9/3/11
to google-a...@googlegroups.com
| New related issues (5414 has been closed) : "Min Pending Latency" not enforced correctly : http://code.google.com/p/googleappengine/issues/detail?id=5765 |
Francois

Nick Rudnik
Sep 3, 2011, 11:41:05 AM9/3/11
to google-a...@googlegroups.com
This scheduler is quite the conflict of interest in that Google controls the algorithm and profits from any defects that cause us to have unnecessary instances running. Google, please go back to CPU based pricing or some metric that aligns both our interests - we should have incentive to write efficient code while your job should be to efficiently handle how many instances are running.
de Witte
Sep 5, 2011, 7:14:21 PM9/5/11
to google-a...@googlegroups.com
CPU based pricing is a step back. Currently we have to pay 41x less for
instances on the new pricing compared to the CPU time on the old bill.
The high cost is now datastore reads and writes, they are easily to optimize.
The high cost is now datastore reads and writes, they are easily to optimize.
Reply all
Reply to author
Forward
0 new messages