Composition question

Bryan Hunter
Twitter: @bryan_hunter

Garrett Smith
you to use gen_fsm?
If this is just going to run through file sequentially, it seems all
you need is a function.
Scheduling calls to that function is another matter. This could be as
simple as cron (or some other system process) calling an escript with
a call to you function. If scheduling is more complex (e.g. parallel
jobs, etc.) you'd need some OTP goodness, but I don't think it'd
involve gen_fsm or gen_event.
How will these jobs be scheduled/triggered?
Bryan Hunter
Twitter: @bryan_hunter
Garrett Smith
<bryan....@fireflylogic.com> wrote:
> Thanks for the feedback Garrett!
>>> Do you need to handle external notifications/events that would
>>> require you to use gen_fsm?
[snip]
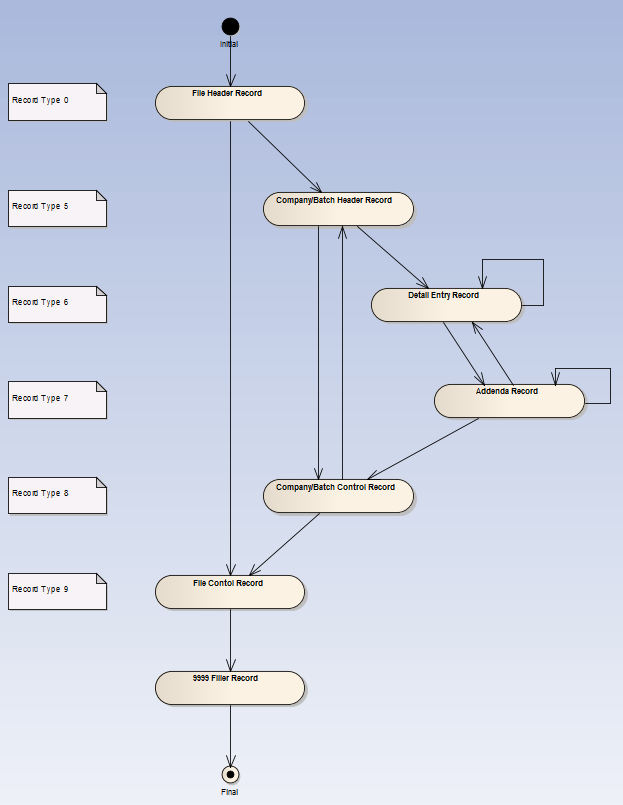
> Back to the import problem...here's a bit more about the data structure. To
> simplify it, let's say there are 6 record types A,B,C,D,E,F that can appear
> in the files. Each record is 20 characters long. Each record type has its
> own set of fixed width fields as shown here:
> A222233344455566777 - File Header
> B222333344566667788 - Group header
> C223333333445556666 - Detail record
> D222333344444445555 - Addenda record
> E222233334444444555 - Group footer
> F222223333333333444 - File footer
> (attached is a state diagram)
When I see something like this, I have Pavlovian reaction to do this:
parse(<<"A222233344455566777", File/binary>>) -> handler_file(File);
parse(<<"B222333344566667788", Group/binary>>) -> handle_group(Group);
...
There's no "state management" here -- there's just parsing logic.
> Each file can contain a few records or hundreds of thousands of records. At
> any given time there may be hundreds of files that need to be processed
> concurrently.
This sounds like a simple_one_for_one supervisor scenario, where you'd
use one Erlang process per file processed.
> In C#, I would have coded each state as a class that would:
> 1) Parse and validate the record that it was instantiated with.
> 2) Do (or delegate) the processing that needed to happen for the current
> state.
> 3) Declare the allowable next states.
> 4) Peek at the next_record and based on the upcoming record type determine
> the next state and instantiate it (passing along the next_record).
> I think you're right. I can simply code my own state machine with functions
> to model each state transition (one for each record type). No one on the
> outside is watching. In the real file the record/field parsing, validation
> and processing for each record type is pretty complex. I could see the each
> of these "state" functions delegating the work of processing the state to
> custom modules.
A state machine may very well be what you want. The trigger for me
would be whether or not the processing stops and has to wait for an
external event (e.g. the classic case of gen_fsm is handling user
dialing where the external event is a human pushing a button on a
phone). If you just need to sequentially run through a series of
parsing and processing steps, you can get by without gen_fsm.
> My original question was about the separation of concerns between file
> chunking and record handling. I could be over-thinking it, but it seems the
> two concerns shouldn't be handled in the same module.
> Assuming a server process is getting "import_file(Filename)" requests what
> would you think the server's next steps should be?
> a) Start up a new file_chunker process and hand the Filename to it. As the
> file_chunker walks the file it would drive the record_handling (state
> machine) module by pushing records at it for sequential, synchronous
> processing.
> b) Start up a new record_handling process and hand the Filename to it. It's
> initial state would be to take the Filename and call a file_chunker module.
> The next state would be the FileHeaderState and it would be seeded with the
> first record from the file_chunker. And so on, and so on...
> c) Something completely different.
As for separation of concerns, there are a few classic ways you can
decouple the handling from the chunking with sequential programming:
1. Return a parsed structure (e.g. a record, a list of records,
whatever) from your chunking function, which is used by your
handler(s)
2. Pass a callback function or module to the chunking function that's
called when content is parsed
3. Use ETS or some other side effect to store the parsed content
If your parsed results are very large (i.e. to the point that memory
would become a concern) option 1 and ETS are probably out. You'd
either want to process the interim chunks in-line (option 2) or store
them out on a disk (e.g. option 3 with DETS, flat file, MySQL, etc).
Option 2 might go like this:
parse(FileName,
[{file_chunk, fun file_chunk:handle/1},
{group_chunk, fun group_chunk:handle/1},
...])
The call back functions could be expressed as {M,F} or {M,F,A} as well.
In this case, you handling logic is divided up into modules. You can
arrange it however you want though (e.g. a module that handles all
chunk types, but in a particular way).
Of course, gen_fsm might help here, but you get a lot of complex state
processing with plain ol' functions.
Garrett

{kind=link}
Chase Allen James
the stream is processed.
webmachine does this too with file uploads:
http://webmachine.basho.com/streambody.html