Solr and Stormcrawler - [WARN] Found data point value of class class java.util.HashMap
38 views
Skip to first unread message

Suman Mallela
Feb 28, 2018, 4:51:41 PM2/28/18
to digita...@googlegroups.com
Hello,
I am trying to integrate solr and stormcrawler and the crawler log just halts at below log:
mer Thread-27 [WARN] Found data point value of class class java.util.HashMap
2018-02-28 16:34:38.899 c.d.c.s.m.MetricsConsumer Thread-27 [WARN] Found data point value of class class java.util.HashMap
Attached is the entire log. Can you please guide me?
Thanks.

DigitalPebble
Mar 1, 2018, 11:36:24 AM3/1/18
to DigitalPebble
It is a warning, not an error. If you had googled the message, you would have found https://github.com/DigitalPebble/storm-crawler/issues/526
--
You received this message because you are subscribed to the Google Groups "DigitalPebble" group.
To unsubscribe from this group and stop receiving emails from it, send an email to digitalpebble+unsubscribe@googlegroups.com.
To post to this group, send email to digita...@googlegroups.com.
Visit this group at https://groups.google.com/group/digitalpebble.
For more options, visit https://groups.google.com/d/optout.
msum...@gmail.com
Mar 8, 2018, 9:55:23 AM3/8/18
to DigitalPebble
Hello Julien,
I understand that WARN is not an error. I have used the same URL that you pasted to correct the MetricsConsumer.java file for External resource Solr code from log.error to log.warn. I have been running the topology for more than 15 hrs and still I don't see any emissions or transfers from Spout. Can you please comment on this?
Here is the screenshot:

Thanks,
Suman
DigitalPebble
Mar 8, 2018, 10:08:16 AM3/8/18
to DigitalPebble
Hi
Have you checked that there are URLs in the status index?
J
--
You received this message because you are subscribed to the Google Groups "DigitalPebble" group.
To unsubscribe from this group and stop receiving emails from it, send an email to digitalpebble+unsubscribe@googlegroups.com.
To post to this group, send email to digita...@googlegroups.com.
Visit this group at https://groups.google.com/group/digitalpebble.
For more options, visit https://groups.google.com/d/optout.
msum...@gmail.com
Mar 8, 2018, 10:20:06 AM3/8/18
to DigitalPebble
Yes, I have checked and it shows the URL that I used in seeds.txt. Here is the screenshot:

On Wednesday, February 28, 2018 at 4:51:41 PM UTC-5, Suman Mallela wrote:
msum...@gmail.com
Mar 9, 2018, 4:44:30 PM3/9/18
to DigitalPebble
Hello Julie,
Do you have any thoughts on no url's are getting indexed ? Do you want to see any of my config files?
Thanks
On Wednesday, February 28, 2018 at 4:51:41 PM UTC-5, Suman Mallela wrote:
DigitalPebble
Mar 10, 2018, 5:18:52 AM3/10/18
to DigitalPebble
Anything in the solr logs?
--
Suman Mallela
Mar 10, 2018, 3:37:22 PM3/10/18
to digita...@googlegroups.com
No errors in solr log. Attached is the solr.log for your reference.
Thanks
--
You received this message because you are subscribed to a topic in the Google Groups "DigitalPebble" group.
To unsubscribe from this topic, visit https://groups.google.com/d/topic/digitalpebble/rP5ikOva6lg/unsubscribe.
To unsubscribe from this group and all its topics, send an email to digitalpebble+unsubscribe@googlegroups.com.
Suman Mallela
Mar 10, 2018, 7:09:37 PM3/10/18
to digita...@googlegroups.com
Only the metrics core is filling up and the indexer bolt is not getting executed at all.
Thanks
DigitalPebble
Mar 11, 2018, 1:34:47 AM3/11/18
to DigitalPebble
That's normal given that the spout is not getting anything from SOLR. Look at the solr logs =>
2018-03-10 20:36:45.468 INFO (qtp205125520-19) [ x:status] o.a.s.c.S.Request [status] webapp=/solr path=/select params={q=*:*&expand=true&expand.rows=100&start=0&fq=nextFetchDate:[*+TO+NOW]&fq={!collapse+field%3Dhost}&rows=100&wt=javabin&version=2} hits=0 status=0 QTime=0
this shows that 1) the communication between the spout and SOLR does happen 2) no docs are returned.
the query looks correct. Try running this query yourself using the SOLR UI and modify elements of it until you are getting documents returned.
Suman Mallela
Mar 12, 2018, 4:18:13 PM3/12/18
to digita...@googlegroups.com
Thanks, Julien.
I had to update the type (from string to tdate) for nextFetchDate in the status (schema.xml) for the query to work in Solr UI.
<field name="nextFetchDate" type="tdate" stored="true" indexed="true"/>
Here is some of the additional logs in the solr.log but still no docs are indexed in the eclkc_solr641 core(solr.indexer.url: "http://localhost:8983/solr/eclkc_solr641")
2018-03-12 20:00:50.032 INFO (qtp205125520-17) [ x:eclkc_solr641] o.a.s.u.p.LogUpdateProcessorFactory [eclkc_solr641] webapp=/solr path=/update params={wt=javabin&version=2}{add=[https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program (1594763352507154432)]} 0 0
But nothing after this for the eclkc_solr641 core. Attached is the full solr.log.
Thanks,
Suman
DigitalPebble
Mar 12, 2018, 4:48:24 PM3/12/18
to DigitalPebble
I am a bit surprised that you had to modify the schema, I used the SOLR module not long ago and it worked without me having to do anything to it.
what do you get when you query the status index for that URL?
anything in the storm logs?
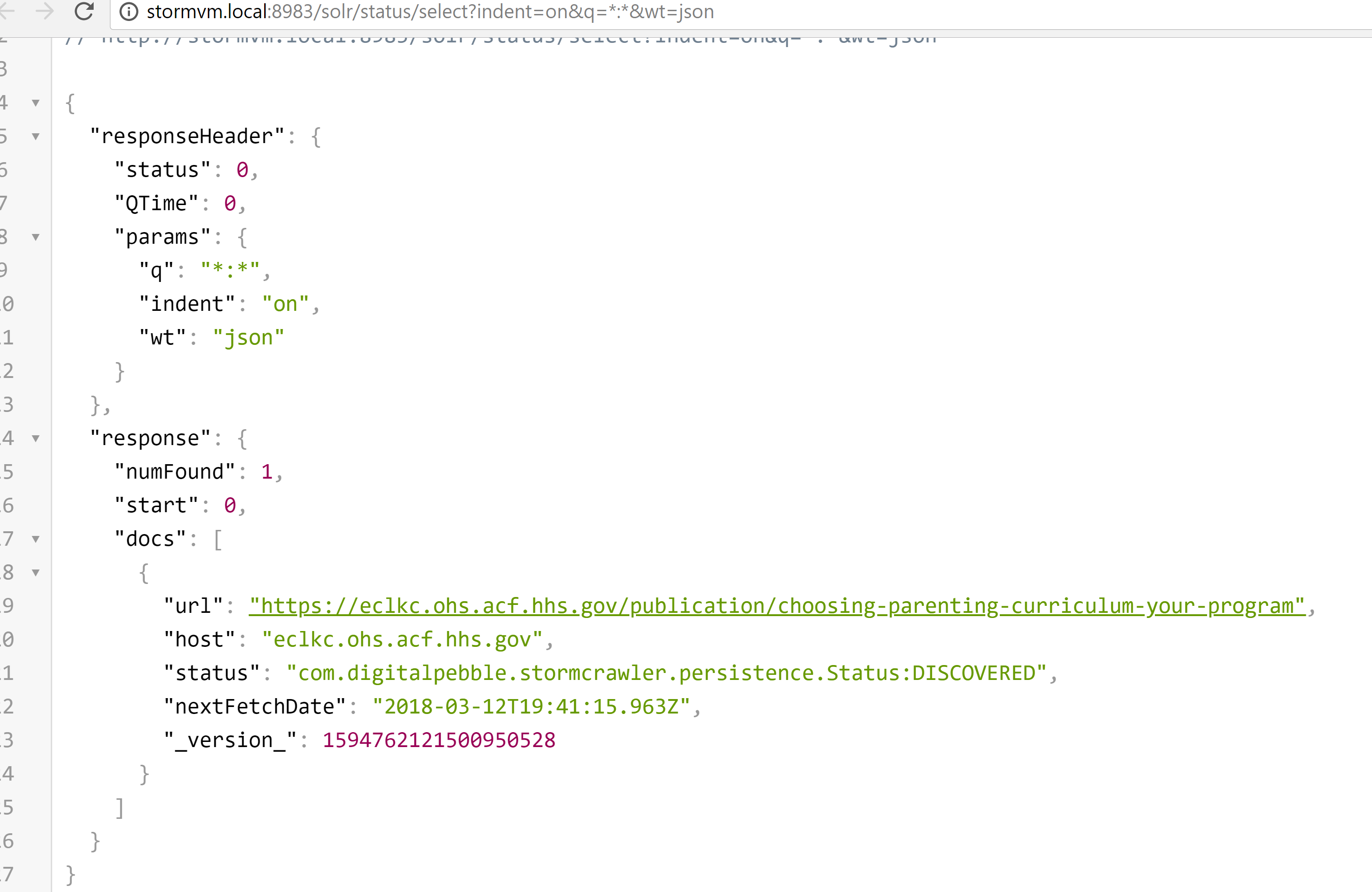
DigitalPebble
Mar 13, 2018, 3:08:50 AM3/13/18
to DigitalPebble
As shown in the screenshot, the status of the URL has not been updated and is still marked as DISCOVERED with a fetch date set in the past. That's why this URL is being fetched over and over. what you need to work out is why the status updater bolt is not successful in updating the URL

Julien Nioche
Mar 13, 2018, 6:46:19 AM3/13/18
to DigitalPebble
I tried with your URL and indeed had to define the date field as you did below. This has been fixed in https://github.com/DigitalPebble/storm-crawler/issues/544, thanks!
There was also an issue with the definition of the docs index -> https://github.com/DigitalPebble/storm-crawler/issues/545
Having said that, I can see the URL status getting updated, new URLs being added etc... so I don't know what the problem is with your setup
DigitalPebble
Mar 13, 2018, 3:16:06 PM3/13/18
to DigitalPebble
I used the example solr config file in the repo.
On 13 Mar 2018 19:04, "Suman Mallela" <msum...@gmail.com> wrote:
Can you look at the settings in the crawler-conf.yaml. Attached is the file. Anything you see configured incorrectly?Can you share you config files to compare?Thanks!
Suman Mallela
Mar 13, 2018, 3:56:12 PM3/13/18
to digita...@googlegroups.com
This is my Streams config within solr-crawler.flux. I suppose the flow is wrong here. I am using flux to inject and crawl. Can you confirm?
streams:
- from: "spout"
to: "partitioner"
grouping:
type: SHUFFLE
- from: "partitioner"
to: "fetcher"
grouping:
type: FIELDS
args: ["key"]
- from: "fetcher"
to: "sitemap"
grouping:
type: LOCAL_OR_SHUFFLE
- from: "sitemap"
to: "parse"
grouping:
type: LOCAL_OR_SHUFFLE
- from: "parse"
to: "index"
grouping:
type: LOCAL_OR_SHUFFLE
- from: "fetcher"
to: "status"
grouping:
type: FIELDS
args: ["url"]
streamId: "status"
- from: "sitemap"
to: "status"
grouping:
type: FIELDS
args: ["url"]
streamId: "status"
- from: "parse"
to: "status"
grouping:
type: FIELDS
args: ["url"]
streamId: "status"
- from: "index"
to: "status"
grouping:
type: FIELDS
args: ["url"]
streamId: "status"
On Tue, Mar 13, 2018 at 3:16 PM, DigitalPebble <jul...@digitalpebble.com> wrote:
I used the example solr config file in the repo.
On 13 Mar 2018 19:04, "Suman Mallela" <msum...@gmail.com> wrote:
Can you look at the settings in the crawler-conf.yaml. Attached is the file. Anything you see configured incorrectly?Can you share you config files to compare?Thanks!
Suman Mallela
Mar 13, 2018, 5:49:28 PM3/13/18
to digita...@googlegroups.com
Hello Julien,
I put in some debug statements in the StatusUpdaterBolt.java file and I see the URL's being discovered but not recursively fetched except for the seed URL. I understand that the DISCOVERED status is not changing for the seed url and so it's getting fetched repeatedly. I am not sure why the status stream is not getting updated. Here is more log that may help you guide me. Attached is the full log, I had to cancel the crawl since it's fetching the same url.
6303 [Thread-24-fetcher-executor[3 3]] INFO c.d.s.b.FetcherBolt - Using queue mode : byHost
6686 [Thread-24-fetcher-executor[3 3]] INFO o.a.s.d.executor - Prepared bolt fetcher:(3)
6736 [Thread-24-fetcher-executor[3 3]] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Threads : 0 queues : 0 in_queues : 0
7472 [FetcherThread #126] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Fetched https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program with status 200 in msec 60
7495 [Thread-34-parse-executor[5 5]] INFO c.d.s.b.JSoupParserBolt - Parsing : starting https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program
8076 [Thread-34-parse-executor[5 5]] INFO c.d.s.b.JSoupParserBolt - Parsed https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program in 539 msec
url execute tuple : https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program
DOC: url https://eclkc.ohs.acf.hhs.gov/job-center - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/human-resources - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/programs/article/head-start-programs - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/data-ongoing-monitoring - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/school-readiness - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/physical-health - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/transportation - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/cas-login - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy/head-start-act - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/family-support-well-being - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/eligibility-ersea - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/program-management - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/designation-renewal-system - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/about-us/article/training-technical-assistance-centers - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy/presenting - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/cross-cutting-approaches - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/children-disabilities - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/curriculum - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/learning-environments - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/federal-administrative-procedures - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/oral-health - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy/pi - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/facilities - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/federal-monitoring - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/about-us/article/mypeers-collaborative-platform-early-care-education-community - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/programs/article/child-care - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy/45-cfr-chap-xiii - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/programs - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/browse/resource-type/publication - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/programs/article/head-start-collaboration-offices - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/topics - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/community-engagement - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/es/publicacion/lista-de-verificacion-para-la-toma-de-decisiones-en-el-curriculo-para-la-crianza - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy/fiscal-regulations - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/about - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/family-community - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/browse/topic/parenting - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/browse/keyword/family-engagement - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/upcoming-events - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/program-planning - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/parenting - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/child-screening-assessment - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/state-systems - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/mental-health - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/family-engagement - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/professional-development - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/subscribe - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/freedom-information-act - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/about-us - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/about-us/article/office-head-start-ohs - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/browse/keyword/parents - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy-regulations - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/education-child-development - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/organizational-leadership - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/download-plug-ins-system-requirements - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/local-early-childhood-partnerships - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/health - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/safety-practices - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy/im - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/ - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/about-us/article/office-child-care-occ - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/disclaimers - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/sites/default/files/pdf/choosing-parenting-curriculum-for-your-program.pdf - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/fiscal-management - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/privacy - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/child-care-policy-regulations - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/culture-language - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/grant-application - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/nutrition - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/policy - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/transitions - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/have-question-or-suggestion - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/health-services-management - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/center-locator - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/browse/keyword/parent-child-relationships - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/teaching-practices - Status DISCOVERED
DOC: url https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program - Status FETCHED
8860 [Thread-24-fetcher-executor[3 3]] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Threads : 0 queues : 0 in_queues : 0
8940 [FetcherThread #175] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Fetched https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program with status 200 in msec 58
8962 [Thread-34-parse-executor[5 5]] INFO c.d.s.b.JSoupParserBolt - Parsing : starting https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program
9024 [Thread-34-parse-executor[5 5]] INFO c.d.s.b.JSoupParserBolt - Parsed https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program in 57 msec
url execute tuple : https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program
DOC: url https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program - Status FETCHED
9119 [Thread-24-fetcher-executor[3 3]] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Threads : 0 queues : 0 in_queues : 0
9188 [FetcherThread #175] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Fetched https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program with status 200 in msec 44
9195 [Thread-34-parse-executor[5 5]] INFO c.d.s.b.JSoupParserBolt - Parsing : starting https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program
9251 [Thread-34-parse-executor[5 5]] INFO c.d.s.b.JSoupParserBolt - Parsed https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program in 50 msec
url execute tuple : https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program
DOC: url https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program - Status FETCHED
9448 [Thread-24-fetcher-executor[3 3]] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Threads : 0 queues : 0 in_queues : 0
9536 [FetcherThread #83] INFO c.d.s.b.FetcherBolt - [Fetcher #3] Fetched
Thanks
Suman Mallela
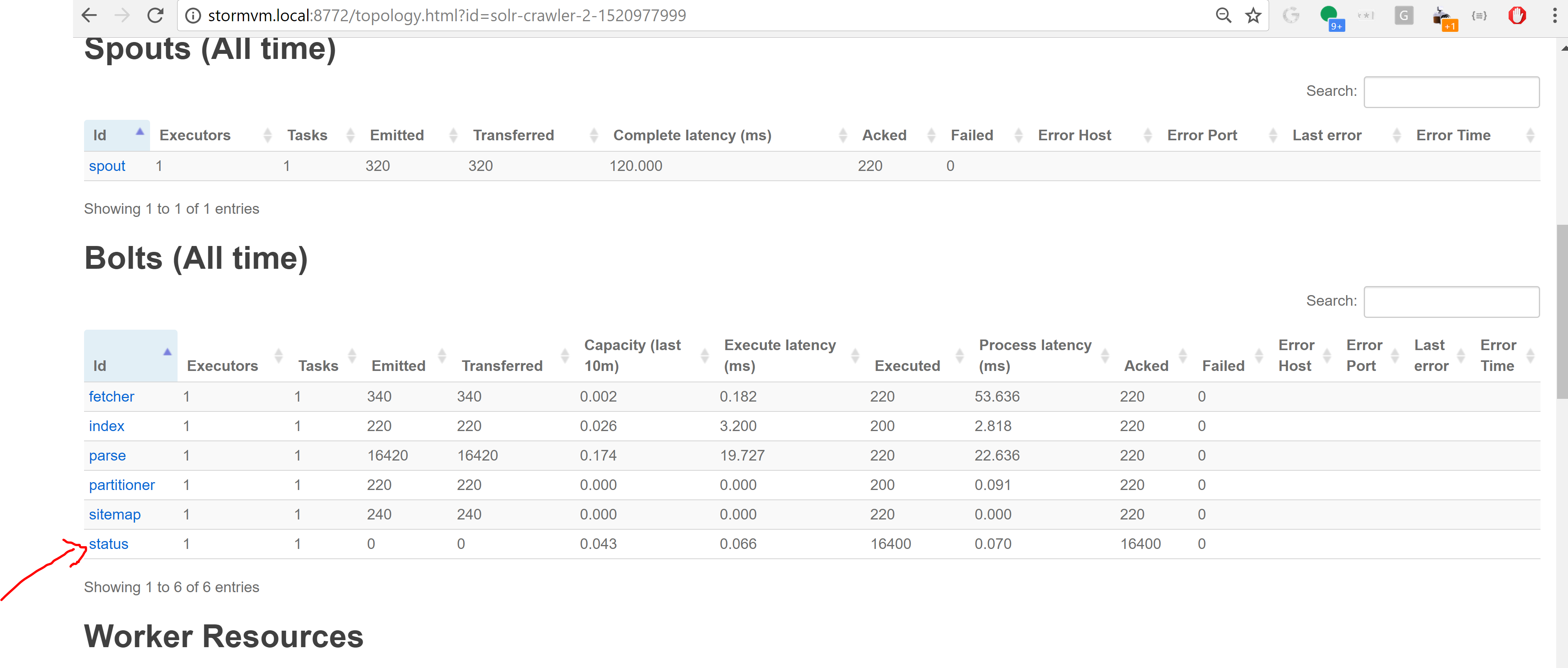
Mar 13, 2018, 6:02:43 PM3/13/18
to digita...@googlegroups.com
And below is the screenshot for storm ui which shows that status is not emitted or transferred (always 0).
DigitalPebble
Mar 14, 2018, 2:45:58 AM3/14/18
to DigitalPebble
I understand that the DISCOVERED status is not changing for the seed url and so it's getting fetched repeatedly.
That's not the case. From your log
DOC: url https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program - Status FETCHED
its status should have been changed to fetched. The other URLs should have been added as well.
https://github.com/DigitalPebble/stormcrawlerfight/tree/solr contains a basic setup with SOLR, check that there are no major differences with your project in the flux and conf
Suman Mallela
Mar 14, 2018, 12:12:26 PM3/14/18
to digita...@googlegroups.com
The setup looks the same for flux and conf.
its status should have been changed to fetched. The other URLs should have been added as well.
Are you suggesting if there might be a problem with solr config not updating the status database (status core write operations issue)?
I ran the crawler overnight and in the morning I saw 1 document indexed (https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program)
in the indexer core (eclkc_solr641) and a lots of documents in metrics core but still the status core didn't show all the discovered URL's nor the status of the URL
(https://eclkc.ohs.acf.hhs.gov/publication/choosing-parenting-curriculum-your-program) didn't change to FETCHED.
I can only think of re-installing solr and create a new brand new StormCrawler-based project based on mvn archetype.
Any thoughts?
DigitalPebble
Mar 14, 2018, 2:11:15 PM3/14/18
to DigitalPebble
Hi Suman
Yes, a fresh setup from the archetype would be a good idea. I'll release 1.8 soon but in the meantime you can download the master from Github.
Make sure you use the configs from the core dir, should be a matter of linking them to the right place in your SOLR setup (can't remember where from top of my head)
Julien
Suman Mallela
Mar 15, 2018, 11:50:30 AM3/15/18
to digita...@googlegroups.com
I did the following steps:
2) mvn clean install
Am not sure what to do after this to build a SOLR setup. Can you send me the steps where to update the pom.xml and config files.
Thanks
Suman Mallela
Mar 15, 2018, 11:59:12 AM3/15/18
to digita...@googlegroups.com
/opt/storm-crawler/archetype/src/main/resources/archetype-resources. Looks like I have to update the files in this location. Can you confirm?
Thanks
DigitalPebble
Mar 15, 2018, 12:03:59 PM3/15/18
to DigitalPebble
Suman
Instead of posting every 10 minutes, why don't you try to work things out by yourself a bit and look at the tutorials, WIKI and videos available?
Thanks
Reply all
Reply to author
Forward
0 new messages