How to make R compute with multiple CPU cores?
9,161 views
Skip to first unread message

Allen
Dec 5, 2012, 6:39:34 PM12/5/12
to davi...@googlegroups.com
Hello, all,
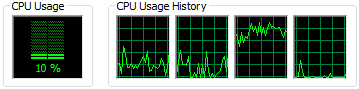
I am doing some really large computation, and it looks the CPU is not working at its full capacity on that (attached is a screenshot from windows task manager while running).
Do you know of ways to make R compute with multiple cores?
Thanks!

Noam Ross
Dec 5, 2012, 7:31:21 PM12/5/12
to Davis R Users Group
Allen,
You need to explicitly set up parallel processing in your code in order to take advantage of multiple cores.
My preferred approach is to use the `foreach` and `plyr` packages. `foreach` provides a parallel version of `for` loops, and `plyr` provides alternatives to `apply` and similar functions with an option for parallel processing. To use these, you need another package which is the "backend" connection between these functions and your multicore machine. The `doParallel` package does this for Windows and OSX/Linux machines.
library(doParallel)
library(foreach)
library(plyr)
cl <- makeCluster(3) # Use 3 cores
registerDoParallel(cl) # register these 3 cores with the "foreach" package
foreach(i=1:3) %dopar% sqrt(i) #run a loop in parallel
aaply(1:3, sqrt, .parallel=TRUE) #apply a function across a vector in parallel
There are other options. `foreach` and `plyr` are some of the highest-level ones (and therefore give you less control). You can also look at at the CRAN task view on parallel computing for more: http://cran.r-project.org/web/views/HighPerformanceComputing.html. I note that a lot of those packages are OS-specific.
Noam
--
Check out our R resources at http://www.noamross.net/davis-r-users-group.html
---
You received this message because you are subscribed to the Google Groups "Davis R Users' Group" group.
To unsubscribe from this group, send email to davis-rug+...@googlegroups.com.
Visit this group at http://groups.google.com/group/davis-rug?hl=en.
李国桢
Dec 12, 2012, 12:42:30 AM12/12/12
to davi...@googlegroups.com
Thank you very mucn, Noam.
I tried to use foreach in this way:
foreach(i=1:9999) %dopar% {
expr;
expr;
expr;
...
}
But R gives me a error message that says:
Error in { : task 1 failed - "could not find function "%dopar%""
I installed and called the packages as you instructed. Was I using foreach in a wrong syntax?
--
李国桢
LI Guozhen
李国桢
LI Guozhen
Noam Ross
Dec 13, 2012, 10:18:42 AM12/13/12
to Davis R Users Group
Hi Allen,
Could you send a working script that generates this error? It will make this much easier to diagnose. A first thought: Do the functions from plyr work?, Such as:
aaply(1:3, 1, sqrt, .parallel=TRUE)
Gregory Burns
Dec 17, 2012, 10:15:23 AM12/17/12
to davi...@googlegroups.com
It sounds like it might be not be the same problem, but you need to call registerDoParallel and pass it the number of cores your wan to use before %dopar% becomes functional. Check out http://cran.r-project.org/web/packages/doParallel/vignettes/gettingstartedParallel.pdf
GRBGregory R. Burns
UC Davis Anthropology (grb...@ucdavis.edu)
Yosemite Archaeology Office (Gregor...@nps.gov)
GRB
UC Davis Anthropology (grb...@ucdavis.edu)
Yosemite Archaeology Office (Gregor...@nps.gov)
李国桢
Dec 18, 2012, 12:31:03 AM12/18/12
to davi...@googlegroups.com
Hi, Noam,
The aapply() function works well on my computer.
Attached are my working scripts, "bike.following.R" defines a function named q(), and "main.r" calls q() in it.
Foreach and %dopar% appear in "bike.following.R".
Thank you very much.
李国桢
Dec 18, 2012, 12:43:46 AM12/18/12
to davi...@googlegroups.com
Thank you very much, Gregory.
I tried on my own computer the "more serious sample" in the pdf link you gave, it turns out %dopar% takes more time (95 sec) than %do% (35 sec).
My computer's CPU is a 4-core Core i5, and I'm running R on Windows 7 Professional 64-bit.
Is it often the case that parallel actually works slower?

Vince S. Buffalo
Dec 18, 2012, 1:07:23 AM12/18/12
to davi...@googlegroups.com
This is because there is overhead in creating threads (or forking processes), setting up and copying over over data into thread stacks, etc. Consider this a high fixed cost that only washes out in the long run of a computationally expensive task. If your task is short, there is no benefit to parallelization. There's even more wall-clock time loss in some cases if you've spent hours parallelizing your code!
HTH,
Vince
Vince Buffalo
Bioinformatics Programmer
Dubcovsky Lab
Plant Sciences, UC Davis

Nick Santos
Dec 18, 2012, 5:18:45 PM12/18/12
to davi...@googlegroups.com
In addition to everything Vince said, a few other notes. I don't have a ton of experience with R, but other programming languages often have similar issues with parallization.
The first thing I'd try if parallelizing is important to you is decreasing the # of cores you want to use to 2 from 3. If you are running a Core i5 that reports 4 cores, it likely only has 2 physical cores and 2 "logical" cores that Intel uses to eek out about 15% more performance from the same cores (but where treating the computer like it has 3 true cores is going to be a heavy load).
The second thing is to make sure your task is actually parallelizable. What I mean by that is that unless you want to enter a whole world of hurt, make sure that each core will be running using its own discrete chunk of data that the other cores will never want to/attempt to access. Once you get into data that needs to be shared between threads, locking of data structures comes into play, which can actually cause threads to wait for each other and have to transfer control, etc. This is on top of all of the initial overhead that Vince mentions. R may have ways of handling some of this for you - I don't have experience with parallelizing R in particular - but generally, it's easier if you hand each processor a distinct chunk of data to churn through so it can just work on it without worrying about what the other cores are doing.
The first thing I'd try if parallelizing is important to you is decreasing the # of cores you want to use to 2 from 3. If you are running a Core i5 that reports 4 cores, it likely only has 2 physical cores and 2 "logical" cores that Intel uses to eek out about 15% more performance from the same cores (but where treating the computer like it has 3 true cores is going to be a heavy load).
The second thing is to make sure your task is actually parallelizable. What I mean by that is that unless you want to enter a whole world of hurt, make sure that each core will be running using its own discrete chunk of data that the other cores will never want to/attempt to access. Once you get into data that needs to be shared between threads, locking of data structures comes into play, which can actually cause threads to wait for each other and have to transfer control, etc. This is on top of all of the initial overhead that Vince mentions. R may have ways of handling some of this for you - I don't have experience with parallelizing R in particular - but generally, it's easier if you hand each processor a distinct chunk of data to churn through so it can just work on it without worrying about what the other cores are doing.
Reply all
Reply to author
Forward
0 new messages