
Philipp at UiT

Philip Durbin
We are having problems with the first row of a csv tabular file being deleted at upload/ingest in Dataverse. We haven't experience this before. Any suggestions on how to avoid this? We are running on version 4.17.Best, Philipp
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
Philipp at UiT
fredag 3. januar 2020 13.19.04 UTC+1 skrev Philip Durbin følgende:
Very strange. Do you get the same behavior on https://demo.dataverse.org ?
On Fri, Jan 3, 2020 at 4:46 AM Philipp at UiT <uit.p...@gmail.com> wrote:
We are having problems with the first row of a csv tabular file being deleted at upload/ingest in Dataverse. We haven't experience this before. Any suggestions on how to avoid this? We are running on version 4.17.--Best, Philipp
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
Philip Durbin
Yes, the same behavior on demo.dataverse.org. Tabulor csv files created with Norwegian locale settings (e.g. in Excel) are usually semicolon-separated, not comma-separated (we use comma as decimal signs). I have replaced the semicolons in the file with commas, and now the first row is not removed anymore! This reminded me of problems we from time to time have with ingesting csv files. Maybe the reason for these problems is that our csv files actually use semicolons and not commas as delimiters? In our deposit guide, we recommend our users to provide tabulor files as tabulator separated plain text files with the extension .txt. However, such files are never ingested properly. Maybe we could have a discussion on what delimiters and extensions ingest should accept?Best, PhilippP.S. Happy New Year to the Dataverse Community!
fredag 3. januar 2020 13.19.04 UTC+1 skrev Philip Durbin følgende:
Very strange. Do you get the same behavior on https://demo.dataverse.org ?
On Fri, Jan 3, 2020 at 4:46 AM Philipp at UiT <uit.p...@gmail.com> wrote:
We are having problems with the first row of a csv tabular file being deleted at upload/ingest in Dataverse. We haven't experience this before. Any suggestions on how to avoid this? We are running on version 4.17.--Best, Philipp
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
Philipp at UiT
fredag 3. januar 2020 22.28.57 UTC+1 skrev Philip Durbin følgende:
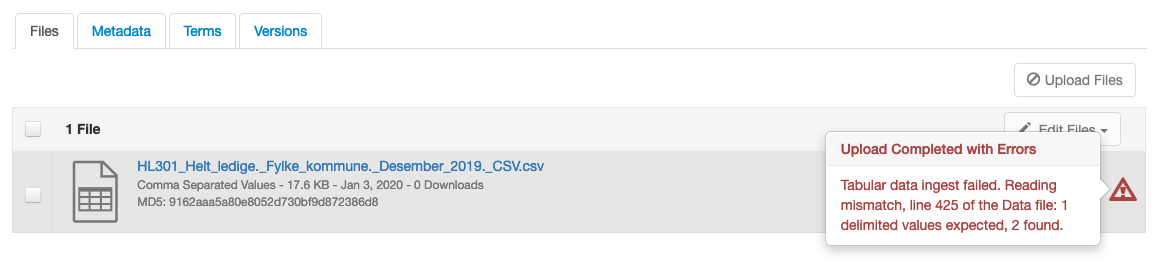
I just downloaded a CSV from https://tovare.com/post/norwegian_unemployment/ and sure enough it had semicolons in it (!) and failed ingest with errors like in the attached screenshot ("Tabular data ingest failed. Reading mismatch, line 425 of the Data file: 1 delimited values expected, 2 found."). A similar error appears in server.log: Ingest failure (IO Exception): Reading mismatch, line 425 of the Data file: 1 delimited values expected, 2 found..I just took a quick look at the code[1] and we use the same "CSVFileReader" for both CSV and TSV files. The only difference is passing a comma (,) vs. a tab (\t). I would think it would be easy enough to pass a semicolon but the harder part is figuring out when. Right now we assume CSV files have, well, commas. :) It would be easy enough to define a global setting to always pass a semicolon to "CSVFileReader" instead of a comma for CSV files but I'm not sure if you'd want that (you may have some of both).Of course, what I'm describing above is "complete failure to ingest" rather than "mostly successful ingest but the first row is missing", which is even stranger. Would you be able to provide a test file for this? It sounds like you're already naming them .txt would should be able to be uploaded to a GitHub issue just fine.As a work around, maybe you could use TSV files. :)Phil
On Fri, Jan 3, 2020 at 3:48 PM Philipp at UiT <uit.p...@gmail.com> wrote:
Yes, the same behavior on demo.dataverse.org. Tabulor csv files created with Norwegian locale settings (e.g. in Excel) are usually semicolon-separated, not comma-separated (we use comma as decimal signs). I have replaced the semicolons in the file with commas, and now the first row is not removed anymore! This reminded me of problems we from time to time have with ingesting csv files. Maybe the reason for these problems is that our csv files actually use semicolons and not commas as delimiters? In our deposit guide, we recommend our users to provide tabulor files as tabulator separated plain text files with the extension .txt. However, such files are never ingested properly. Maybe we could have a discussion on what delimiters and extensions ingest should accept?Best, PhilippP.S. Happy New Year to the Dataverse Community!
fredag 3. januar 2020 13.19.04 UTC+1 skrev Philip Durbin følgende:
Very strange. Do you get the same behavior on https://demo.dataverse.org ?
On Fri, Jan 3, 2020 at 4:46 AM Philipp at UiT <uit.p...@gmail.com> wrote:
We are having problems with the first row of a csv tabular file being deleted at upload/ingest in Dataverse. We haven't experience this before. Any suggestions on how to avoid this? We are running on version 4.17.--Best, Philipp
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
Philip Durbin
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/86ed0cc0-5499-4c13-93cf-7620a7e75c06%40googlegroups.com.

{kind=link}
James Myers
FWIW: One thought w.r.t. a work-around – for QDR I implemented buttons to uningest files (and ingest again if desired). That could be made into a pull request. I think the main QDR use case was to be able to clear errors when ingest fails and to be able to retry after updates (i.e. when we made ingest work on files with more columns) but there may have been cases where the upload set had multiple formats of the same data. I think we talked about making ingest optional to start with for that, but, since QDR is a curated archive, I think we decided that just allowing uningest via the GUI was enough of a solution to drop the priority on going further.
I don’t want this to get in the way of discussion of potentially better solutions (making derived files permanent? making derived files first class objects linked to the originals instead of auxiliary entries?), but wanted to mention it in case it might help in the shorter term.
-- Jim
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
--
Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to
dataverse-commu...@googlegroups.com.
To view this discussion on the web visit
https://groups.google.com/d/msgid/dataverse-community/86ed0cc0-5499-4c13-93cf-7620a7e75c06%40googlegroups.com.
Philipp at UiT
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
Philipp at UiT
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/86ed0cc0-5499-4c13-93cf-7620a7e75c06%40googlegroups.com.
Philip Durbin
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/86ed0cc0-5499-4c13-93cf-7620a7e75c06%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5712c89c-9775-40c8-bb18-7c27f68fd572o%40googlegroups.com.
Philipp at UiT
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/86ed0cc0-5499-4c13-93cf-7620a7e75c06%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-community+unsub...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5712c89c-9775-40c8-bb18-7c27f68fd572o%40googlegroups.com.
Philip Durbin
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/fa161cd9-4fdd-4e6f-b935-f5baf0d32a1c%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/e90b8618-49b0-420b-afd8-6a70246ce000%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/86ed0cc0-5499-4c13-93cf-7620a7e75c06%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/5712c89c-9775-40c8-bb18-7c27f68fd572o%40googlegroups.com.
--Philip Durbin
Software Developer for http://dataverse.org
http://www.iq.harvard.edu/people/philip-durbin
--
You received this message because you are subscribed to the Google Groups "Dataverse Users Community" group.
To unsubscribe from this group and stop receiving emails from it, send an email to dataverse-commu...@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/dataverse-community/ac08f19d-d8cb-4355-b4c4-510ebadb7f72o%40googlegroups.com.