BBR shows lower throughput in 10Gb LAN than Reno

Clark Mi
sudo sysctl -a | grep tcp_congestion_control
net.ipv4.tcp_congestion_control = bbr
iperf3 -c 192.168.200.6 -i 1 -t 10
Connecting to host 192.168.200.6, port 5201
[ 5] local 192.168.200.5 port 60130 connected to 192.168.200.6 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 909 MBytes 7.62 Gbits/sec 104 195 KBytes
[ 5] 1.00-2.00 sec 905 MBytes 7.59 Gbits/sec 3 195 KBytes
[ 5] 2.00-3.00 sec 901 MBytes 7.55 Gbits/sec 16 195 KBytes
[ 5] 3.00-4.00 sec 902 MBytes 7.57 Gbits/sec 0 195 KBytes
[ 5] 4.00-5.00 sec 891 MBytes 7.47 Gbits/sec 12 195 KBytes
[ 5] 5.00-6.00 sec 887 MBytes 7.44 Gbits/sec 0 195 KBytes
[ 5] 6.00-7.00 sec 894 MBytes 7.50 Gbits/sec 1 195 KBytes
[ 5] 7.00-8.00 sec 911 MBytes 7.65 Gbits/sec 10 195 KBytes
[ 5] 8.00-9.00 sec 863 MBytes 7.24 Gbits/sec 0 195 KBytes
[ 5] 9.00-10.00 sec 861 MBytes 7.22 Gbits/sec 0 195 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 8.71 GBytes 7.49 Gbits/sec 146 sender
[ 5] 0.00-10.04 sec 8.71 GBytes 7.46 Gbits/sec receiver
sudo sysctl -a | grep tcp_congestion_control
net.ipv4.tcp_congestion_control = reno
iperf3 -c 192.168.200.6 -i 1 -t 10
Connecting to host 192.168.200.6, port 5201
[ 5] local 192.168.200.5 port 60134 connected to 192.168.200.6 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 1.10 GBytes 9.43 Gbits/sec 43 481 KBytes
[ 5] 1.00-2.00 sec 1.10 GBytes 9.42 Gbits/sec 4 506 KBytes
[ 5] 2.00-3.00 sec 1.10 GBytes 9.42 Gbits/sec 9 505 KBytes
[ 5] 3.00-4.00 sec 1.10 GBytes 9.42 Gbits/sec 0 518 KBytes
[ 5] 4.00-5.00 sec 1.10 GBytes 9.42 Gbits/sec 0 527 KBytes
[ 5] 5.00-6.00 sec 1.10 GBytes 9.41 Gbits/sec 0 539 KBytes
[ 5] 6.00-7.00 sec 1.09 GBytes 9.41 Gbits/sec 0 546 KBytes
[ 5] 7.00-8.00 sec 1.10 GBytes 9.42 Gbits/sec 0 546 KBytes
[ 5] 8.00-9.00 sec 1.10 GBytes 9.42 Gbits/sec 0 547 KBytes
[ 5] 9.00-10.00 sec 1.10 GBytes 9.42 Gbits/sec 5 556 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 11.0 GBytes 9.42 Gbits/sec 61 sender
[ 5] 0.00-10.04 sec 11.0 GBytes 9.38 Gbits/sec receiver

Eric Dumazet
on one BBR flow.
What NIC are you using ? (ethtool -i ethX)
What is the output of "ethtool -c ethX"
> You received this message because you are subscribed to the Google Groups "BBR Development" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to bbr-dev+u...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.

Neal Cardwell
I agree with Eric that this seems like a (receiver-side) driver/LRO/GRO issue.
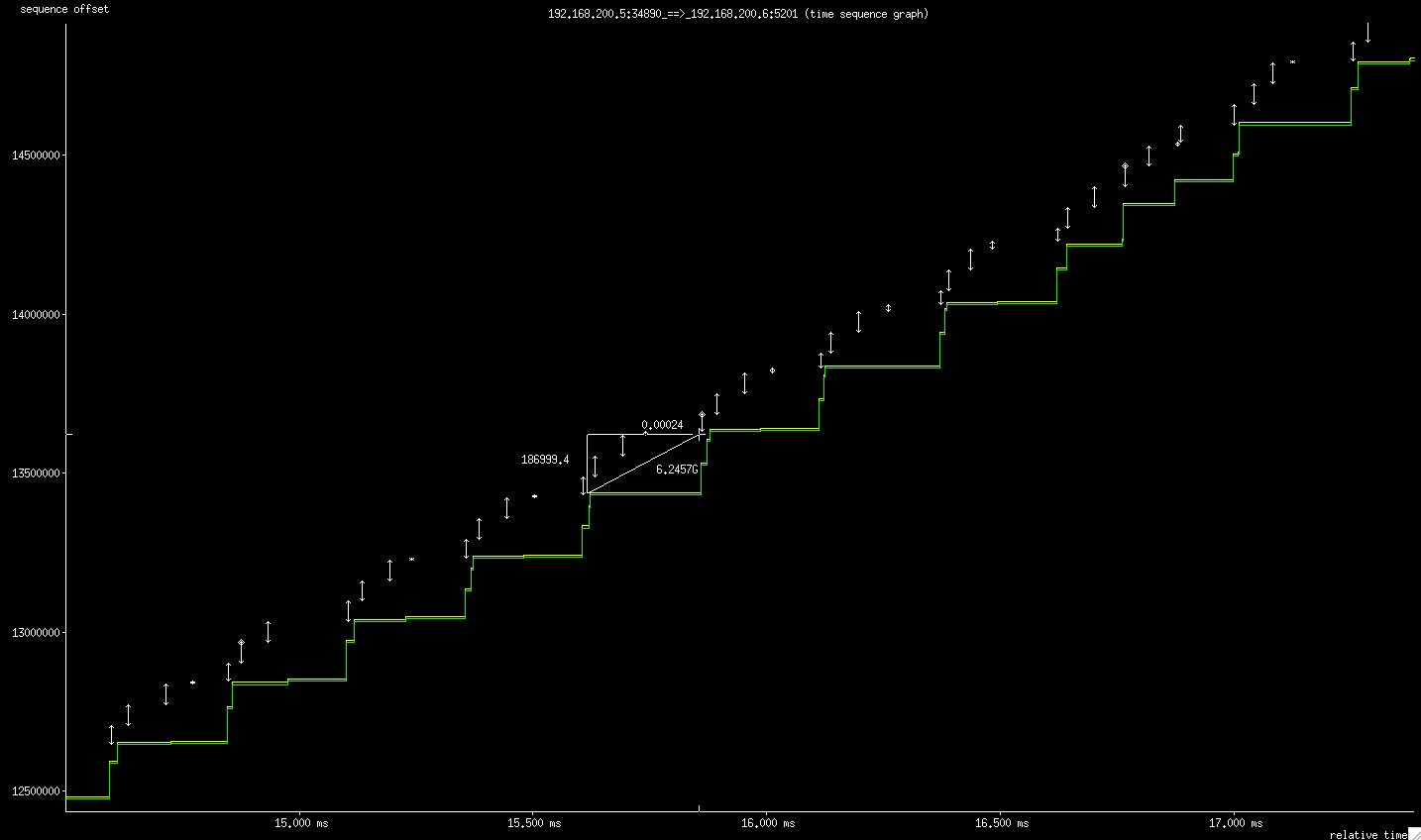
Looking at the trace (attached) we can see high degrees of aggregation
in the ACK stream, with long 240us silences followed by aggregated
ACKs covering more than a single TSO burst. A well-configured receiver
will generally send an ACK for at least every maximally-sized TSO
burst. And this receiver is not doing that. If you can run the
commands Eric listed, we can help see if the receiver's behavior can
be optimized.
That said, if you upgrade the sender by checking out and building the
latest Linux net-next branch then the latest sender-side Linux TCP BBR
should be able to cope with that high degree of aggregation and still
reach pretty good utilization, using the following recent Linux
net-next commit:
78dc70ebaa38 tcp_bbr: adapt cwnd based on ack aggregation estimation
thanks,
neal
{kind=link}
Clark Mi
在 2019年2月20日星期三 UTC+8上午10:51:38,Eric Dumazet写道:
Neal Cardwell
ethtool -k <device_name>
thanks,
neal
Clark Mi
在 2019年2月20日星期三 UTC+8下午12:11:18,Neal Cardwell写道:
Clark Mi
在 2019年2月20日星期三 UTC+8上午11:05:26,Neal Cardwell写道:
Neal Cardwell
BTW, this patch would be extremely important for 11ac WiFi network as 11ac requires much heavy aggregation, A-MSDU and A-MPDU.
Thanks again for your work.
Clark Mi
在 2019年2月20日星期三 UTC+8下午11:24:42,Neal Cardwell写道: