CCS'16 Paper on Improvements of AFL

boehme...@gmail.com
Dear all,
tldr; Checkout AFL on caffeine (= awesome performance improvements) at https://github.com/mboehme/aflfast!
Our paper on improvements of AFL has just been accepted at the 23rd ACM Conference on Computer and Communications Security (CCS'16). You can find the paper here: https://www.comp.nus.edu.sg/~mboehme/paper/CCS16.pdf ("Coverage-based Greybox Fuzzing as Markov Chain"). You can find our modifications here: https://github.com/mboehme/aflfast. The paper makes an attempt to formalise the machinery that drives AFL and discusses of challenges and opportunities (+technical improvements). Kudos to Michal Zalewski for the awesome work on AFL and everybody else who has contributed! Without your work, ours would not be possible.
AFLFast is a fork of AFL that in experiments with Binutils outperformed AFL by an order of magnitude! It helped in the success of Team Codejitsu at the finals of the DARPA Cyber Grand Challenge where their bot Galactica took 2nd place in terms of #POVs proven (see red bar at https://www.cybergrandchallenge.com/event#results; maybe it is even a tie for 1st place). In our experiments, AFLFast exposed several previously unreported CVEs that could not be exposed by AFL in 24 hours and otherwise exposed vulnerabilities significantly faster than AFL while generating orders of magnitude more unique crashes. Our experiments ran on AFL 1.95b but we ported AFLFast to the most recent version AFL 2.30b. Check out AFLFast on Github and evaluate it yourself.
Essentially, we observed that most generated inputs exercise the same few “high-frequency” paths and developed strategies to gravitate towards low-frequency paths, to stress significantly more program behavior in the same amount of time. We devised several search strategies that decide in which order the seeds should be fuzzed and power schedules that smartly regulate the number of inputs generated from a seed (i.e., the time spent fuzzing a seed). We call the number of inputs generated from a seed, the seed's energy.
We find that AFL's exploitation-based constant schedule assigns too much energy to seeds exercising high-frequency paths (e.g., paths that reject invalid inputs) and not enough energy to seeds exercising low-frequency paths (e.g., paths that stress interesting behaviors). Technically, we modified the computation of a seed's performance score (calculate_score), which seed is marked as favourite (update_bitmap_score), and which seed is chosen next from the circular queue (main).
More details on the power schedule in the paper and here: https://github.com/mboehme/aflfast/blob/master/Readme.md
Happy to hear your thoughts!
Best regards,
- Marcel

Michal Zalewski
a bit and report back.
Skimming through the paper, it sounds like your implementation is more
aggressive about skipping deterministic steps:
"Secondly, AFL executes the deterministic stage the first time ti is
fuzzed. Since our power schedules assign significantly less energy for
the first stage, our extension executes the deterministic stage later
when the assigned energy is equal to the energy spent by deterministic
fuzzing."
Have you benchmarked this against afl-fuzz -d? The deterministic
stages are an intentional performance trade off designed to produce
smaller diffs for easily discoverable issues, to simplify debugging at
the expense of discovering paths more slowly - so I wonder if some of
the speedup is attributable to this.
/mz
Marcel Böhme
In the beginning it is easy for explore to make progress. Later, energy is wasted on fuzzing seeds exercising high-frequency paths versus low frequency paths.
Michal Zalewski
incrementally, so here's what my first tests are focusing on:
1) I'm looking specifically at the ability to resolve execution paths
(i.e., the "bitmap density" metric), rather than crash counts. This
makes it easier to experiment with a broader range of targets, and is
how I normally benchmark changes to AFL. In the past, I found this to
be a very good proxy for the overall quality of the mutation & queue
scoring algorithms.
2) In my initial runs, I'm trying to simply compare the traditional -d
mode to -d with your checksum frequency optimization. This is not to
reject the idea of skipping deterministic checks for less interesting
paths - but my reasoning is that this is a simpler (albeit more noisy
and perhaps less effective) comparison - and it takes less time for
the algorithm to reach a plateau, so I don't have to wait several days
to be sure.
3) I'm trying to benchmark against a different range of targets. This
is just out of abundance of caution - in the past, I've often noticed
that optimizations that work for one target often don't work for
others. For example, adding -fno-if-conversions -fno-if-conversions2
to CFLAGS improves coverage in libpng, but actually reduces it in
libjpeg-turbo :-)
Stay tuned!
/mz
Michal Zalewski
> is just out of abundance of caution - in the past, I've often noticed
> that optimizations that work for one target often don't work for
> others. For example, adding -fno-if-conversions -fno-if-conversions2
> to CFLAGS improves coverage in libpng, but actually reduces it in
> libjpeg-turbo :-)
complexity: zlib (minigzip -d), GNU patch, libjpeg-turbo (djpeg, with
dictionary), libpng (readpng, CRC check removed, with dictionary), and
sqlite3 (with dictionary).
/mz

Gustavo Grieco
This paper looks very impressive indeed. I have just one question to
ask. I can't find in the evaluation any measure of unique crashes
according to its backtraces (as it is usual in papers measuring the
real amount of bugs/vulnerabilities found in a fuzzing campaing). I'm
saying this because i'm doing some simple experiments on seed
selection to try to improve AFL and it is easy to see that in most of
the programs i tested you can reduce the number of seeds computed by
afl-cmin to obtain more "afl-unique" crashes in the first 48hs.
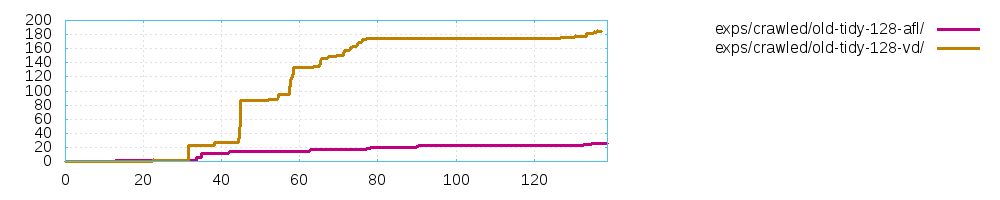
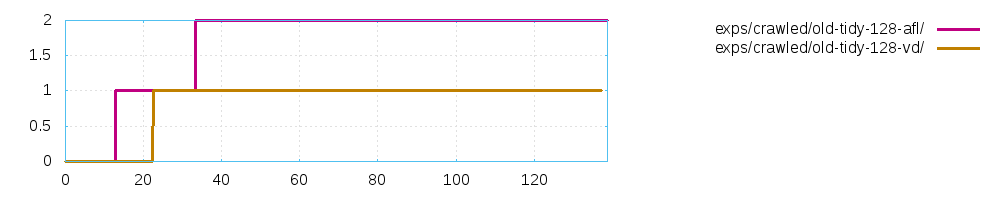
Let me show you an example: I attached an example of an experiment
using approach (labeled "vd") vs AFL seed selection (labeled "afl") to
try to fuzz an old version of tidy with html fragments from the
internet.
Despite our approach can find 10 times more unique crashes, there is
only 2 *real* different crashes and the original AFL is better! The
question is: have you reviewed this type of measure just to be sure
that the results are not telling a completely different story?
Regards,
Gustavo.
> You received this message because you are subscribed to the Google Groups "afl-users" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to afl-users+...@googlegroups.com.
> For more options, visit https://groups.google.com/d/optout.
Marcel Böhme
Michal Zalewski
Okay, so I think your approach works. But based on my preliminary
experiments, there are two potential caveats:
1) The improvements I'm seeing in my (admittedly crude) testing aren't
as dramatic as outlined in the paper. That said, I'm looking at
different targets and using different metrics, so maybe that's not a
very interesting observation.
2) More curiously, I was able to get very close to the results I'm
seeing with AFLFast with a two-line change to stock AFL; as a
consequence, I am not sure if the checksum counting algorithm is truly
responsible for the bulk of the gains you are seeing in your code
(although I have no doubt that it confers some benefits).
Specifically, I sought to replicate two artifacts of your
implementation: the fact that it spends a much greater proportion of
time on non-deterministic fuzzing early on in the game; and that most
of the non-deterministic cycles it carries out end up being very
short, causing the queue to be cycled very rapidly, causing new queue
entries to get air time almost right away. I approximated these by
reducing HAVOC_CYCLES and SPLICE_HAVOC 20-fold (to roughly match the
queue cycling cadence of AFLFast) and then by specifying -d.
I'll refer to this modified setup as FidgetyAFL.
Some rudimentary measurements follow.
== Experiment 1 ==
This involved running AFL against the contrib/libtests/readpng.c
utility from libpng (CRC patch applied). I like this benchmark because
it's fast and predictable, but the target is fairly complex, and it
can take a week or two for AFL to reach a plateau.
I ran this benchmark on FreeBSD, single core, library compiled using
afl-clang. I did two sessions, each 6 hours long. The command line
was:
$ ./afl-fuzz -i testcases/images/png -x dictionaries/png.dict -t 5 -o
out_dir ./readpng
Stock AFL vs AFLFast: stock AFL was consistently but very slightly
(~1%) ahead of AFLFast in terms of the number of tuples seen, with
little variation over time.
FidgetyAFL: this implementation outperformed both "competitors" by
around +10% at the 1h mark, then trailed very slightly by the 6h mark
(-1%).
== Experiment 2 ==
This involved running AFL against the djpeg utility from the latest
libjpeg-turbo. It's another very predictable and easy-going benchmark
with appreciable complexity but no hard puzzles to solve.
I tried this one on Linux, single core, library compiled with afl-gcc.
Two sessions, each six hours long. The command line was:
$ ./afl-fuzz -i testcases/images/jpeg -x dictionaries/jpeg.dict -t 5
-o out_dir ./djpeg
Stock AFL vs AFLFast: AFLFast took a robust lead (+15% tuples seen) by
the 1h mark. It remained in the lead until the end, although its
advantage gradually tapered off to +5%.
FidgetyAFL: robustly outperforms stock AFL and scores slightly below
AFLFast at the 1h mark (+13%). At the 6h mark, the advantage tapered
off to +4%.
== Experiment 3 ==
This involved running AFL against the minigzip [-d] utility from the
latest zlib. It's a simple and graceful target that doesn't take too
long to meaningfully explore, so it's good for shorter-running
benchmarks.
I did three one-hour sessions on Linux, single core, library compiled
with afl-gcc. The command line was:
$ ./afl-fuzz -i testcases/archives/common/gzip -t 5 -o out_dir ./minigzip -d
Stock AFL vs AFLFast: the implementations go toe-to-toe for a while,
but AFLFast tends to take off and secure and keep a +20% lead later
on.
FidgetyAFL: the implementation roughly tied with AFLFast.
== Experiment 4 ==
This involved running AFL against the GNU patch utility. In contrast
to other experiments, it started with a bogus input file, in order to
test for the ability to discover grammar. It's a very graceful target
for that, because it supports several input formats and parses them in
interesting ways.
The test environment was FreeBSD + afl-clang. I did three one-hour
runs. Cmdline:
$ ./afl-fuzz -i testcases/others/text -t 5 -o out_dir ./patch --dry-run
Stock AFL vs AFLFast: AFLFast tends to win *very* decisively,
typically +50% tuples compared to stock AFL. A very clear success
story.
FidgetyAFL: the implementation tied with AFLFast.
/mz
Marcel Böhme
Michal Zalewski
Perhaps we should also time-to-exposure for each vulnerability as a better measure than #unique crashes.
Marcel Böhme
Michal Zalewski
However, using the Markov chain model, we informally argue that our modifications have no detrimental impact on effectiveness. That is, AFL has the *same potential* to generate the unique crashes that AFLFast generated earlier. Because of the circular queue, given the same seeds, there is no reason why AFL should not generate the same unique crashes (at a later point in time) -- on average.

Brian 'geeknik' Carpenter

Kurt Roeckx
> Fuzzing Perl: A Tale of Two American Fuzzy Lops is up at
> http://www.geeknik.net/71nvhf1fp. A very unscientific study performed over
> the last 48 hours. =)
87%, for FidgetyAFL 84%.
You might want to look into getting that higher, it seems to have
had a great effect for me. I got them all higher than 99.5%
currently.
Kurt
Marcel Böhme
Fuzzing Perl: A Tale of Two American Fuzzy Lops is up at http://www.geeknik.net/71nvhf1fp. A very unscientific study performed over the last 48 hours. =)
Brian 'geeknik' Carpenter
--
You received this message because you are subscribed to the Google Groups "afl-users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to afl-users+unsubscribe@googlegroups.com.
Emilien Gaspar
> On Sun, Aug 21, 2016 at 03:34:02AM -0500, Brian 'geeknik' Carpenter wrote:
> > Fuzzing Perl: A Tale of Two American Fuzzy Lops is up at
> > http://www.geeknik.net/71nvhf1fp. A very unscientific study performed over
> > the last 48 hours. =)
>
> So one thing I noticed is that for AFLFast you have a stability of
> 87%, for FidgetyAFL 84%.
>
explain what "stability" is.
Thank you :-).
--
gapz -- https://residus.eu.org
Kurt Roeckx
Kurt
Emilien Gaspar
> > BTW, maybe the section 8 of docs/status_screen.txt should be updated to
> > explain what "stability" is.
>
> It's already explained in that section?

Simon Pinfold
if anyone is following this, your results would be very welcome, too!

{kind=link}
{kind=link}