New entropy coding: faster than Huffman, compression rate like arithmetic

dud...@gmail.com
Hallo, There is a new approach to entropy coding (no patents): Asymmetric Numeral Systems(ANS) - the current implementation has about 50% faster decoding than Huffman (single table use and a few binary operations per symbol from a large alphabet), giving rates like arithmetic: https://github.com/Cyan4973/FiniteStateEntropy The idea is somehow similar to arithmetic coding, but instead of two numbers to define the current state (range), it uses only a single natural number (containing lg(state) bits of information) - thanks of this much smaller space of states, we can put the entire behavior into a small table. Here is a poster explaining the basic concepts and the difference from arithmetic: https://dl.dropboxusercontent.com/u/12405967/poster.pdf I would like to propose a discussion about the possibility of applying it in video compression like VP9 - it should be more than 10 times faster than arithmetic coding, providing similar compression rate. The cost is that we need to store coding tables for a given probability distribution: let say 1-16kB for 256 size alphabet. For different contexts (probability distributions), we can build separate tables and switch between them - the memory cost is "the number of different contexts/distributions" times a few kilobytes. So if the number of different contexts used for given coding parameters is smaller than let say a thousand, ANS can provide huge speedup.

Paul Wilkins
Obviously this is not something that we can retro fit to VP9 at this stage, but it is worth looking at for a future codec and I would encourage you to do some experiments in our experimental branch.
dud...@gmail.com
I am rather a theory person and video compression is something new for me - I just wanted to discuss such eventual applicability.
Indeed the memory need could be an issue, but it is just a few kilobytes per table/context, so for all contexts there would be needed a few hundreds kilobytes - even for hardware implementation, the cost of this amount of memory is a small fraction of a cent.
Especially looking at advantages - large symbol processed in a single table use - here is example of the whole step for symbol processing (including renormalization):
step = decodeTable[state];
symbol = step.symbol;
state = step.newState | (bitStream & mask[step.nbBits]);
bitStream = bitStream >> step.nbBits;
where mask[b]=(1<<b)-1
I imagine that video compression is lots of binary adaptive choices - where we should work bit by bit, but there is also lots of encoding of DCT coefficients as large independent numbers, just a few different ranges/contexts (?) - if so, ANS would be perfect for such static distributions on large alphabets.
However, there are also lots of different ways of use for this new approach (table on page 4 of new version of http://arxiv.org/pdf/1311.2540 ) - for example some of these tables (let say first 32 or 64) could be for quantized probabilities for binary alphabet - we can freely switch between tables symbol by symbol.
In the binary case, tabled or using using formula with single multiplication per symbol, ANS still should have advantage over AC - as you can see, it has much simpler renormalization: instead of branching bit by bit, with issue when the range contains the middle point, in ANS we can just transfer the required number of bits once per symbol.
akiku...@google.com
dud...@gmail.com
I have got two comments regarding memory cost here.
Currently the cost of 1GB SDRAM is about $10, so such a few hundred kB would be a cost below 1 cent, especially that small memories can have smaller addressing, being cheaper and faster. Specialized memory could have less than 16 bit addressing here.
The income of encoding e.g. 256 level quantization DCT coefficient, would be instead of 8 slower (renormalization) AC steps, a single cheap step of ANS – being about 10 times faster, what for hardware implementation means much lower frequencies and energy usage (smartphones…).
The minimal memory cost for 256 size alphabet is 1kB (assuming no symbol above 1/4 probability, 1.25kB general): working about 0.001 from theoretical rate limit for coding tables optimized for given probability distribution (as part of coder) – using a few dozens of quantization types (probability distributions), the memory cost would be only a few dozens of kilobytes.
Thanks of much simpler renormalization than arithmetic coding, replacing it with binary ANS (e.g. qABS) should be also a speedup – this time working about 0.001 from theoretical rate limit would cost below 1kB of tables total.
Thanks, Jarek

Pascal Massimino
A few hundred kilobytes is actually quite a bit of silicon. Our implementation of the entire VP9 hardware decoder for 4k 60 fps resolution needs currently about 240 kB SRAM for all the data it needs to store (including line buffers for motion vectors, pixels for in-loop filtering and intra prediction etc.). It sounds like the ANS solution could more than double that, so in that perspective it is an expensive solution.
Thanks,Aki Kuusela
On Tuesday, January 7, 2014 6:56:50 PM UTC+2, dud...@gmail.com wrote:Hallo, thanks for the reply.
I am rather a theory person and video compression is something new for me - I just wanted to discuss such eventual applicability.
Indeed the memory need could be an issue, but it is just a few kilobytes per table/context, so for all contexts there would be needed a few hundreds kilobytes - even for hardware implementation, the cost of this amount of memory is a small fraction of a cent.
Especially looking at advantages - large symbol processed in a single table use - here is example of the whole step for symbol processing (including renormalization):
step = decodeTable[state];
symbol = step.symbol;
state = step.newState | (bitStream & mask[step.nbBits]);
bitStream = bitStream >> step.nbBits;
where mask[b]=(1<<b)-1
I imagine that video compression is lots of binary adaptive choices - where we should work bit by bit, but there is also lots of encoding of DCT coefficients as large independent numbers, just a few different ranges/contexts (?) - if so, ANS would be perfect for such static distributions on large alphabets.
However, there are also lots of different ways of use for this new approach (table on page 4 of new version of http://arxiv.org/pdf/1311.2540 ) - for example some of these tables (let say first 32 or 64) could be for quantized probabilities for binary alphabet - we can freely switch between tables symbol by symbol.
In the binary case, tabled or using using formula with single multiplication per symbol, ANS still should have advantage over AC - as you can see, it has much simpler renormalization: instead of branching bit by bit, with issue when the range contains the middle point, in ANS we can just transfer the required number of bits once per symbol.
--
You received this message because you are subscribed to the Google Groups "Codec Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to codec-devel...@webmproject.org.
To post to this group, send email to codec...@webmproject.org.
Visit this group at http://groups.google.com/a/webmproject.org/group/codec-devel/.
For more options, visit https://groups.google.com/a/webmproject.org/groups/opt_out.
dud...@gmail.com
First of all, indeed I was told that DeltaH is about 20% larger in experiments.
However, as I write in the paper, I calculate it purely analytically: assume i.i.d. input source, find stationary probability distribution of used states (dominant eigenvector), what allows to find the expected number of used bits per symbol. Then subtract Shannon entropy.
Here is source of Mathematica procedure I was using: https://dl.dropboxusercontent.com/u/12405967/ans.nb
I interpret the difference as mainly caused by imperfect source.
Another issue is spreading the symbols - the better it is done, the smaller deltaH.
The github implementation uses some approximated symbol distributing algorithm - tests in the paper were made for precise initialization (using procedure above).
What symbol distribution are you using?
Tests for precise initialization for 256 size alphabet and probabilities approximated as l_s/512, gave deltaH < 0.01 bits/symbol for 512 states, what requires 512 * (1 byte for symbol + 1 byte for new state) = 1kB table.
Symbol here is almost 8 bits, so this loss means about 0.00125 rate loss.
And for fixed stationary probability distribution, shifting symbol appearances we can "tune" it to be optimal for different probability distribution - such optimal distribution can be a part of coder.
Thanks,
Jarek
akiku...@google.com
dud...@gmail.com
SDRAM in shop costs about $10 per GB, what means 1 cent per MB - still 5 times more would be 5 cents per MB, and probably a fraction of it in production.
And indeed we can download from SDRAM only the currently relevant tables.
If there is nearly no cost of renormalization (and binarization) in hardware implementation, indeed the only advantage of ANS here would be decoding large symbol from static probability distribution (context dependent) in a single cycle.
So the question is how many different static probability distributions (and what alphabet sizes) are used e.g. in VP9?
Like different quantization types for DCT coefficients("level"), or the number of zero coefficients ("run"+"end of block").
Indeed e.g. for given quality level, only some subset of them needs to be loaded to SRAM.
This philosophy of large static alphabets allows to group a few static choices, like "run"+"end of block" into a single choice.
Thanks,
Jarek
ps. ANS also allows to simultaneously encrypt the data, e.g. for video transmission.
Pascal Massimino
Hi skal, all,
First of all, indeed I was told that DeltaH is about 20% larger in experiments.
However, as I write in the paper, I calculate it purely analytically: assume i.i.d. input source, find stationary probability distribution of used states (dominant eigenvector), what allows to find the expected number of used bits per symbol. Then subtract Shannon entropy.
Here is source of Mathematica procedure I was using: https://dl.dropboxusercontent.com/u/12405967/ans.nb
I interpret the difference as mainly caused by imperfect source.
Another issue is spreading the symbols - the better it is done, the smaller deltaH.
The github implementation uses some approximated symbol distributing algorithm - tests in the paper were made for precise initialization (using procedure above).
What symbol distribution are you using?
Tests for precise initialization for 256 size alphabet and probabilities approximated as l_s/512, gave deltaH < 0.01 bits/symbol for 512 states, what requires 512 * (1 byte for symbol + 1 byte for new state) = 1kB table.
Symbol here is almost 8 bits, so this loss means about 0.00125 rate loss.
And for fixed stationary probability distribution, shifting symbol appearances we can "tune" it to be optimal for different probability distribution - such optimal distribution can be a part of coder.
Thanks,
Jarek
dud...@gmail.com
I was asking what symbol distributing algorithm you were using for generating the coding tables - the one from github is probably far from optimal.
My tests were for precise initialization (page 19 and top left fig. 9 of http://arxiv.org/pdf/1311.2540v2.pdf ) - and deltaH dropped with square of table size, what is also expected by theoretical analysis: inaccuracy (epsilon) behaves like 1/l, deltaH generally like epsilon^2 (expanding Kullback-Leibler formula).
Indeed additional issue is approximating the real probabilities by fractions with "number of states" (l) denominator (my tests didn't take into consideration) - still such approximation becomes better while increasing the number of states (again inaccuracy behaves like 1/l).
However, we can "tune" coding table to shift its optimal probability distribution (see fig. 12) - shifting appearances right, reduces probability of given symbol.
Doing it optimally requires further work. Starting precise initialization with real 1/(2p_s) instead of approximated probability may help.
Regarding binary versions, I am not not experienced in low level optimization, but
- in tabled version we can store the number of bits, and transfer all at once, what seems much less costly that AC bit by bit renormalization,
- in arithmetic version, we can use large b, like 256 (or 2^16), and transfer one (or two) bytes at once, once per a few steps.
Maybe you could compare your fast version for binary alphabet with some AC?
Regarding large alphabet formulas, I couldn't find similar to original ABS, but recently I have found something analogous but a bit different (page 8 of last version) - instead of two multiplications in range coding, using single multiplication per symbol ... but rather requires some tables.
> Another non-surprise is that using 256-symbol alphabet (like the github version) compresses significantly better than the binary version of fpaqa/fpaqc.
Anyway, it means that there should be even larger differences comparing to some approximated AC, like CABAC.
Thanks,
Jarek
Pascal Massimino
dud...@gmail.com
Great thanks for the tests!
It is really surprising that all these complex arithmetic coding renormalizations can be made faster than a few fixed binary operations ... but they are just first ANS implementations, so maybe there is still a place for improvement...
The dependence of speed from probability will be larger while using direct ABS formulas and large b to gather accumulated byte or two at once, like in Matt Mahoney fpaqc.
The large alphabet version is perfect for large stationary probability distributions, like DCT coefficients.
However, we can also use its huge speed advantage for binary case when probabilities change from bit to bit - by grouping symbols of the same quantized probability.
Let say we use 64 different quantizations of probability of the least probable symbol (1/128 precision) - so we can use 64 of 8bit buffers, add binary choices bit by bit to corresponding buffers, and one of 64 ANS coding tables for 256 size alphabet every time a buffer accumulates to 8 binary symbols.
All these 64 tables can work on the same state - decoder knows symbols of which probability run out.
About the required table size, I see you have indeed used the github version - I have just tested it and it gives a few to hundreds times larger deltaH (found analytically) than precise initialization, and generally is very capricious.
It was made to be fast, but better symbol spread would need a few times smaller coding tables.
Here is a sketch of fast approximated precise symbol spread (I am not good at C) by bucketing the search for the most appropriate symbol (can be improved by increasing the number of buckets) - it should need much smaller tables for the same accuracy:
int first[nbStates]; // first symbol in given bucket
int next[nbSymbols]; // next symbol in the same stack
float pos[nbSymbols]; // expected symbol position, can be U16 instead
for(i=0; i < nbStates; i++) first[i]=-1; //empty buckets
for(s=0; s < nbSymbols; s++)
{pos[s]=ip[s]/2; //ip[s]=1/probability[s];
t = round(ip[s]/2); //which bucket
next[s]=first[t]; first[t]=s;} //push to stack t
cp=0; //position in decoding table
for(i=0; i < nbStates; i++)
while((s=first[i]) > = 0)
{first[i]=next[s]; // remove from stack
t = round(pos[s]+=ip[s]); // new expected position
next[s]=first[t]; first[t]=s; // insert in new position
tableDecode[cp++].symbol=s}
Thanks,
Jarek
Pascal Massimino
Hi skal, all,
Great thanks for the tests!
It is really surprising that all these complex arithmetic coding renormalizations can be made faster than a few fixed binary operations ... but they are just first ANS implementations, so maybe there is still a place for improvement...
The dependence of speed from probability will be larger while using direct ABS formulas and large b to gather accumulated byte or two at once, like in Matt Mahoney fpaqc.
The large alphabet version is perfect for large stationary probability distributions, like DCT coefficients.
However, we can also use its huge speed advantage for binary case when probabilities change from bit to bit - by grouping symbols of the same quantized probability.
Let say we use 64 different quantizations of probability of the least probable symbol (1/128 precision) - so we can use 64 of 8bit buffers, add binary choices bit by bit to corresponding buffers, and one of 64 ANS coding tables for 256 size alphabet every time a buffer accumulates to 8 binary symbols.
All these 64 tables can work on the same state - decoder knows symbols of which probability run out.
About the required table size, I see you have indeed used the github version - I have just tested it and it gives a few to hundreds times larger deltaH (found analytically) than precise initialization, and generally is very capricious.
It was made to be fast, but better symbol spread would need a few times smaller coding tables.
Here is a sketch of fast approximated precise symbol spread (I am not good at C) by bucketing the search for the most appropriate symbol (can be improved by increasing the number of buckets) - it should need much smaller tables for the same accuracy:
int first[nbStates]; // first symbol in given bucket
int next[nbSymbols]; // next symbol in the same stack
float pos[nbSymbols]; // expected symbol position, can be U16 instead
for(i=0; i < nbStates; i++) first[i]=-1; //empty buckets
for(s=0; s < nbSymbols; s++)
{pos[s]=ip[s]/2; //ip[s]=1/probability[s];
t = round(ip[s]/2); //which bucket
next[s]=first[t]; first[t]=s;} //push to stack t
cp=0; //position in decoding table
for(i=0; i < nbStates; i++)
while((s=first[i]) > = 0)
{first[i]=next[s]; // remove from stack
t = round(pos[s]+=ip[s]); // new expected position
next[s]=first[t]; first[t]=s; // insert in new positiontableDecode[cp++].symbol=s}
dud...@gmail.com
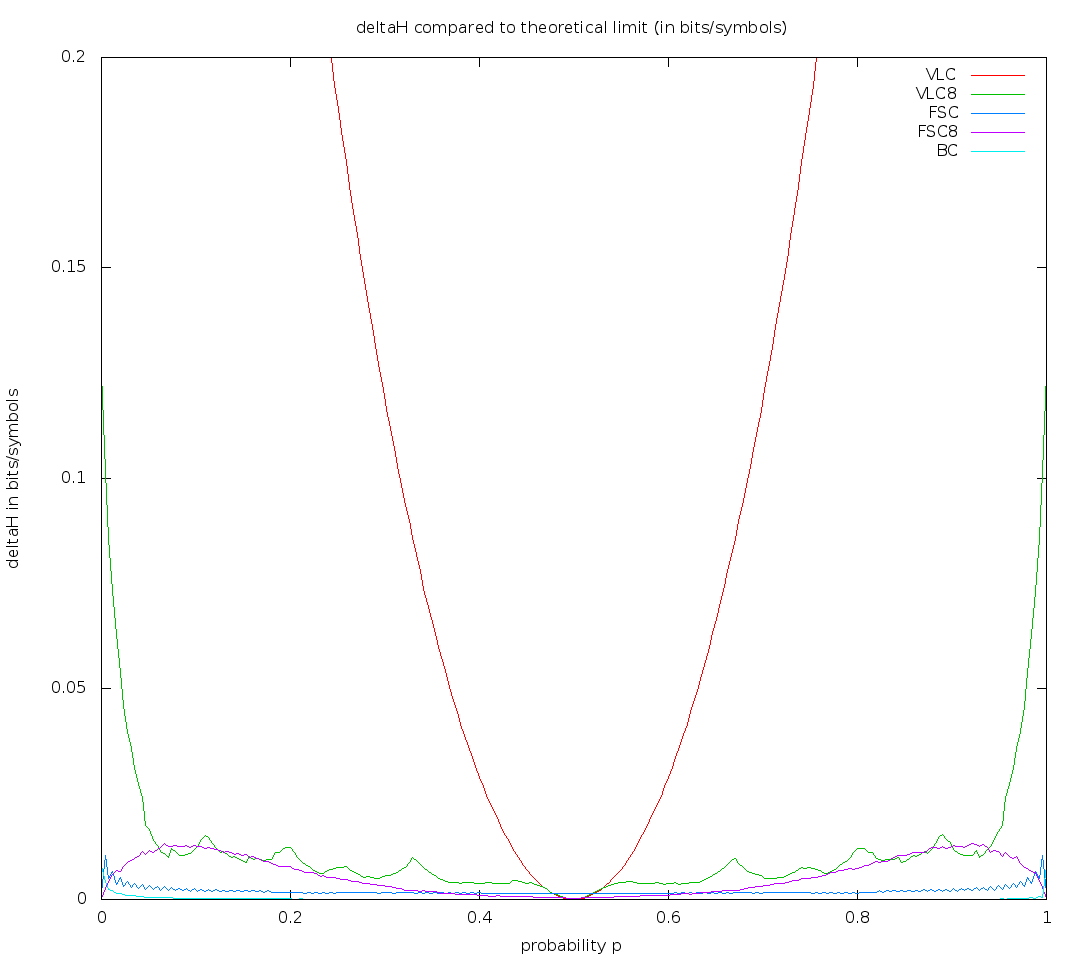
Thank you for the tests. It looks really really bad, so I have just checked precise initialization for the worse case in your graph: p=0.1.
This time, instead of finding stationary probability like before, I just applied the encoder for 10^6 symbol random sequences: https://dl.dropboxusercontent.com/u/12405967/ans1.nb
So for 2^12 states, ANS needs ~1.01 of what Shanon says (sum lg(1/p) over symbols), as h~3.752 bits/symbol for this binomial distribution, it means deltaH~0.04 bits/symbol.
For 2^13 states, it needs ~1.004 of what Shannon says, what means deltaH ~ 0.015 bits/symbol.
For 2^14 states, it needs ~1.00165 of what Shannon says, deltaH ~ 0.0062 bits/symbol
The last value is about twice smaller than in your graph for p=0.1 - so you could improve it about twice by not approximating precise initialization (my approximation is a bit better, as it doesn't round expected positions).
Also the question is how to approximate probabilities with "number of states" denominator fractions.
Probably we could improve it further by tuning - for example by shifting extremely low probable symbols to the end.
Still these values are much worse than in the paper - mainly because, as I have emphasized, I didn't consider the approximating of probabilities with "number of states" denominator, what is the real problem here - lots of symbols having much smaller probability.
Thanks,
Jarek
Pascal Massimino
Hi skal, all,
Thank you for the tests. It looks really really bad, so I have just checked precise initialization for the worse case in your graph: p=0.1.
This time, instead of finding stationary probability like before, I just applied the encoder for 10^6 symbol random sequences: https://dl.dropboxusercontent.com/u/12405967/ans1.nb
So for 2^12 states, ANS needs ~1.01 of what Shanon says (sum lg(1/p) over symbols), as h~3.752 bits/symbol for this binomial distribution, it means deltaH~0.04 bits/symbol.
For 2^13 states, it needs ~1.004 of what Shannon says, what means deltaH ~ 0.015 bits/symbol.
For 2^14 states, it needs ~1.00165 of what Shannon says, deltaH ~ 0.0062 bits/symbol
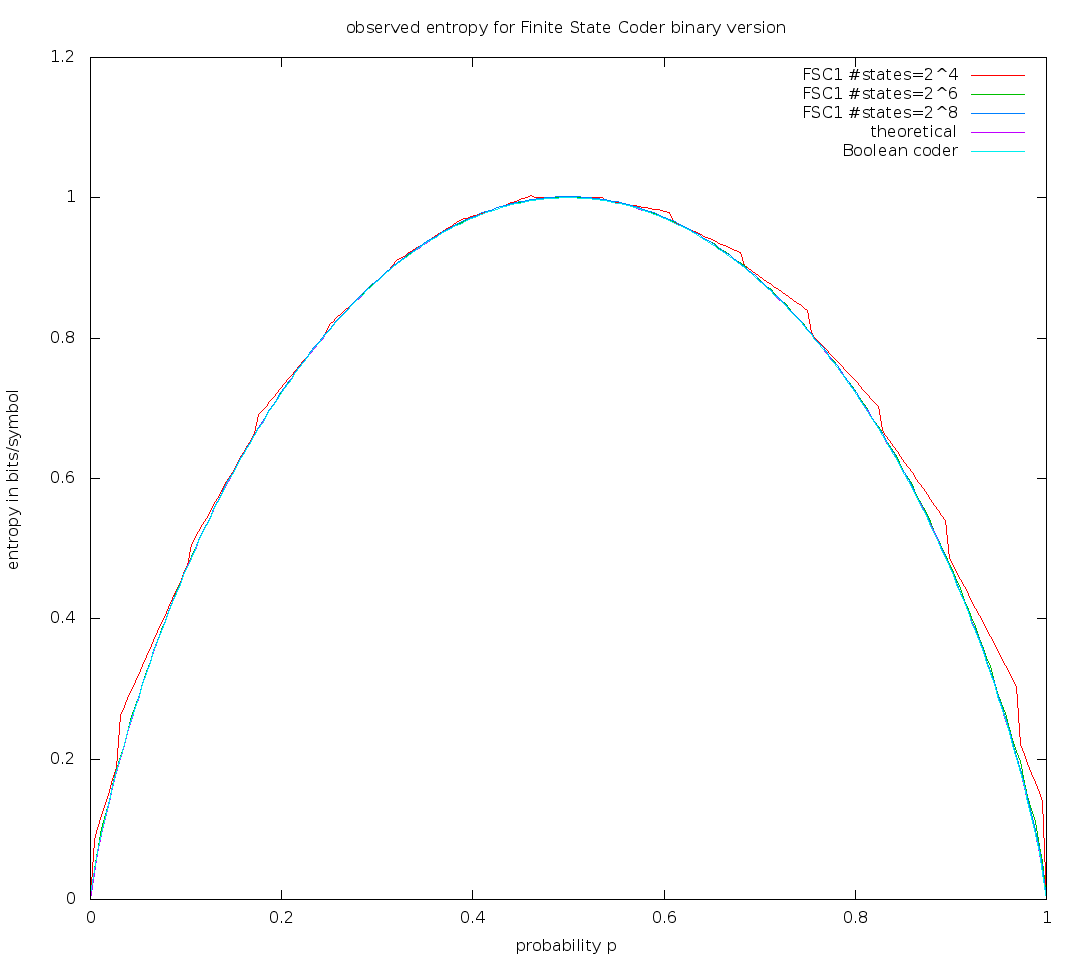
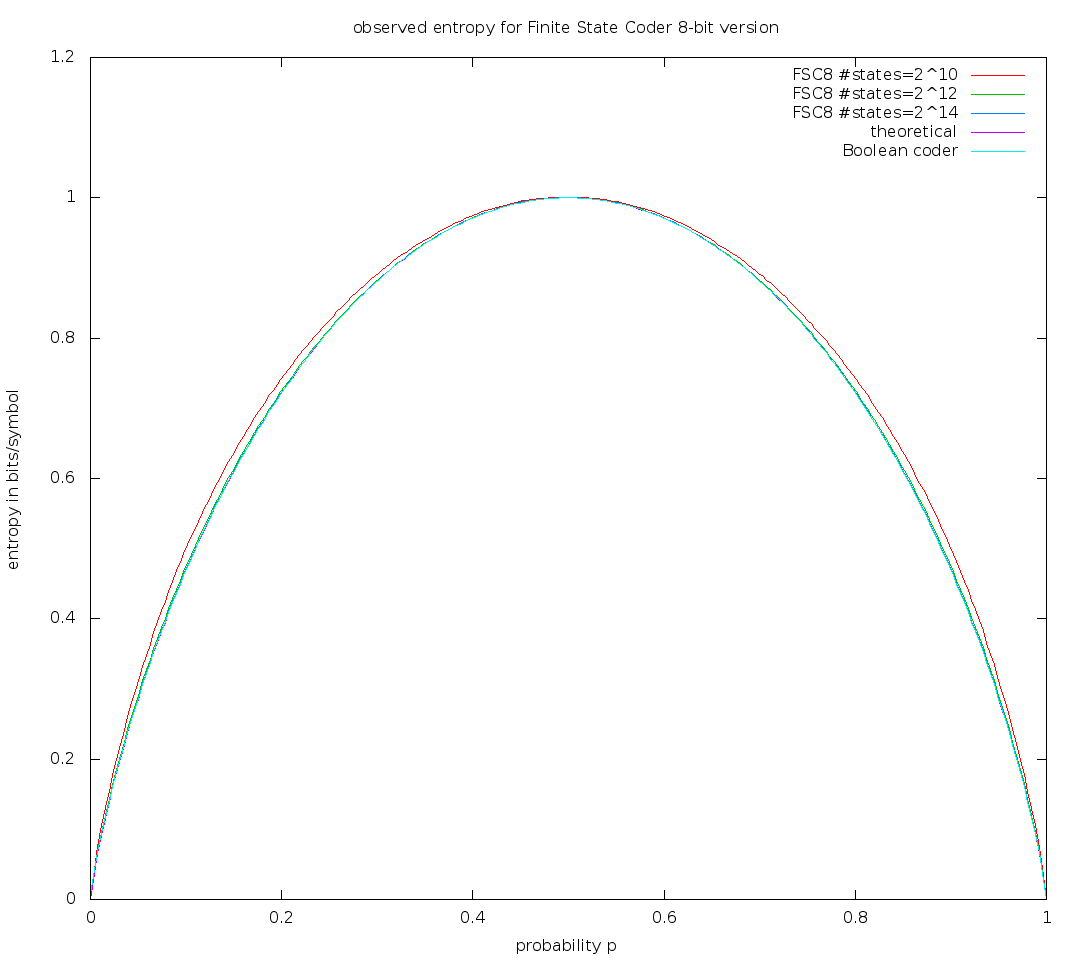
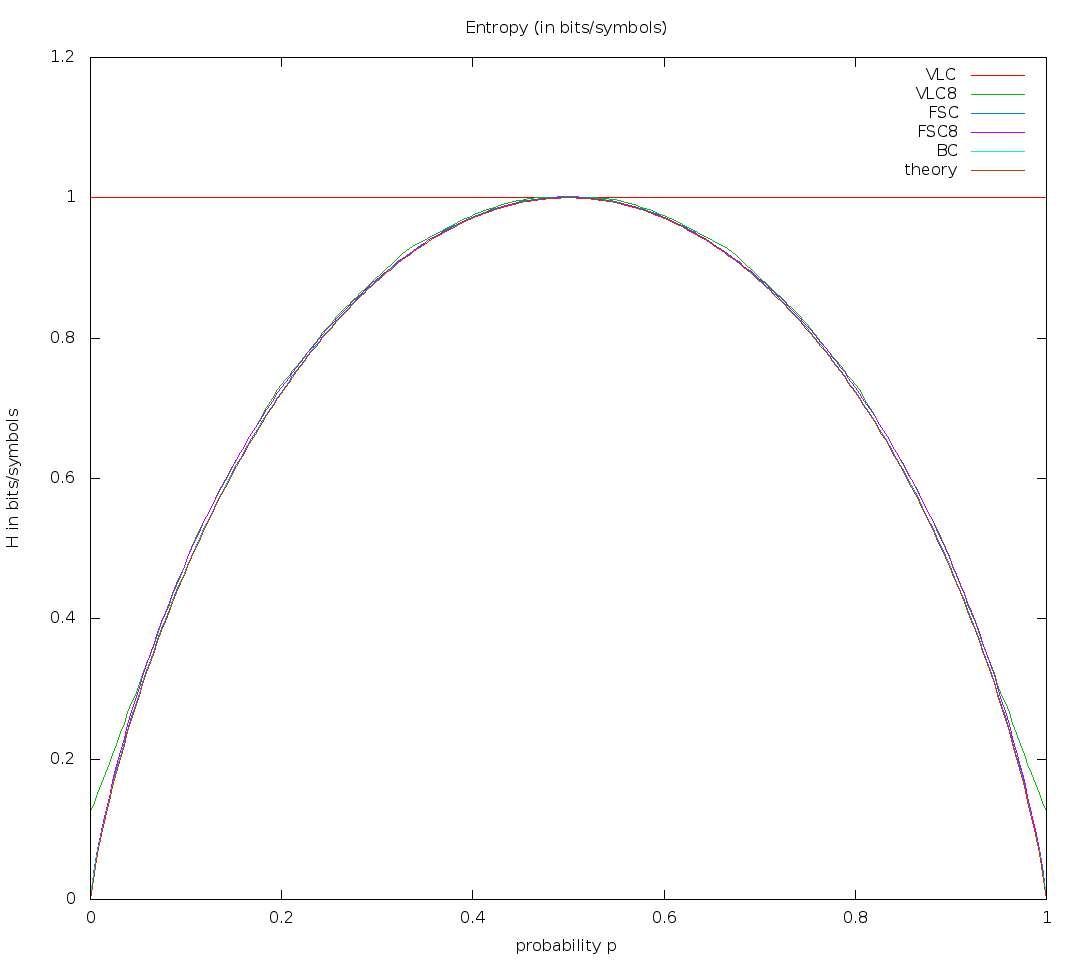
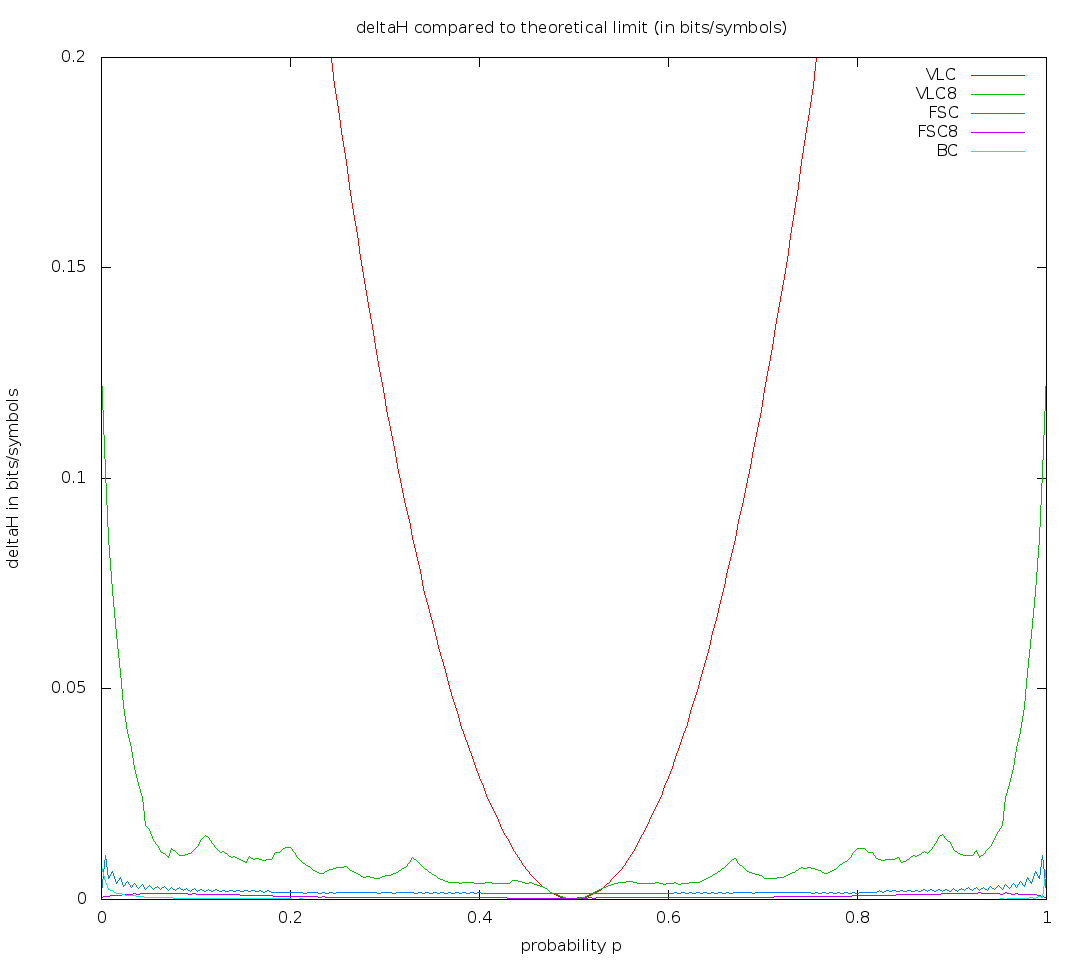
p Proba| h FSC | h FSC8 | h BC | h theory
0.1019608 0.4767120 0.4760080 0.4750568 0.4747218
which is deltaH ~= .002
The last value is about twice smaller than in your graph for p=0.1 - so you could improve it about twice by not approximating precise initialization (my approximation is a bit better, as it doesn't round expected positions).
Also the question is how to approximate probabilities with "number of states" denominator fractions.
Probably we could improve it further by tuning - for example by shifting extremely low probable symbols to the end.
Still these values are much worse than in the paper - mainly because, as I have emphasized, I didn't consider the approximating of probabilities with "number of states" denominator, what is the real problem here - lots of symbols having much smaller probability.
dud...@gmail.com
Thank you, it looked really bad - now it's much better.
And speed should be indeed similar to Huffman with tabled the whole behavior, like in Yann's comparison: http://fastcompression.blogspot.fr/2014/01/huffman-comparison-with-fse.html
Maybe this 50% speed optimization also improves the previous comparison for binary alphabet?
I have just checked the cost of approximating with "number of state" denominator fraction for above case: p[s] approximated as lt[s]/l.
Using perfect encoder for lt[s]/l distribution to encode p[s] distribution, we would use
sum_s p[s] lg( l / lt[s] ) bits per symbol
instead of h = sum_s p[s] lg( 1 / p[s] )
dividing them for lt[s] from attached ans1.nb we get:
1.01084 for 2^12 states
1.00419 for 2^13 states
1.00166 for 2^14 states
what is nearly the same what ANS gets - so practically the whole inaccuracy here comes from this p[s] ~ lt[s]/l approximation ... so the fast decaying probability distribution tail like here or Gaussian will be probably always an issue for small table size.
It can be improved by dividing into two choices, for example by grouping some number of the least probable symbols into a single symbol for the first choice - so still one step per symbol will be sufficient in most of cases.
Also probably we could improve a bit by a better choice of lt[s] and tuning symbol distribution - I will have to work on that...
Thanks,
Jarek
dud...@gmail.com
1.00729 for 2^12 states
1.00302 for 2^13 states
1.00112 for 2^14 states
Unfortunately it is probably close to the end of possibilities of ANS (?).
Best,
Jarek
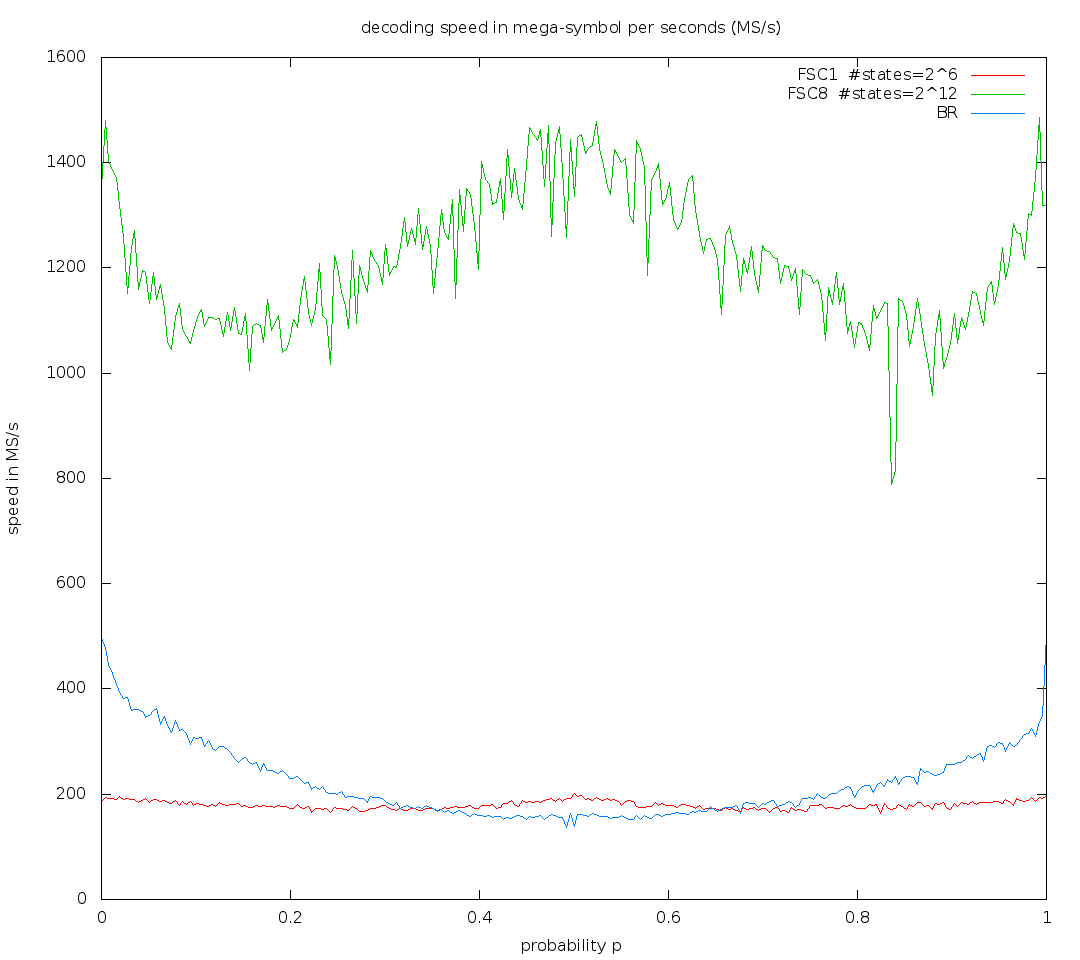
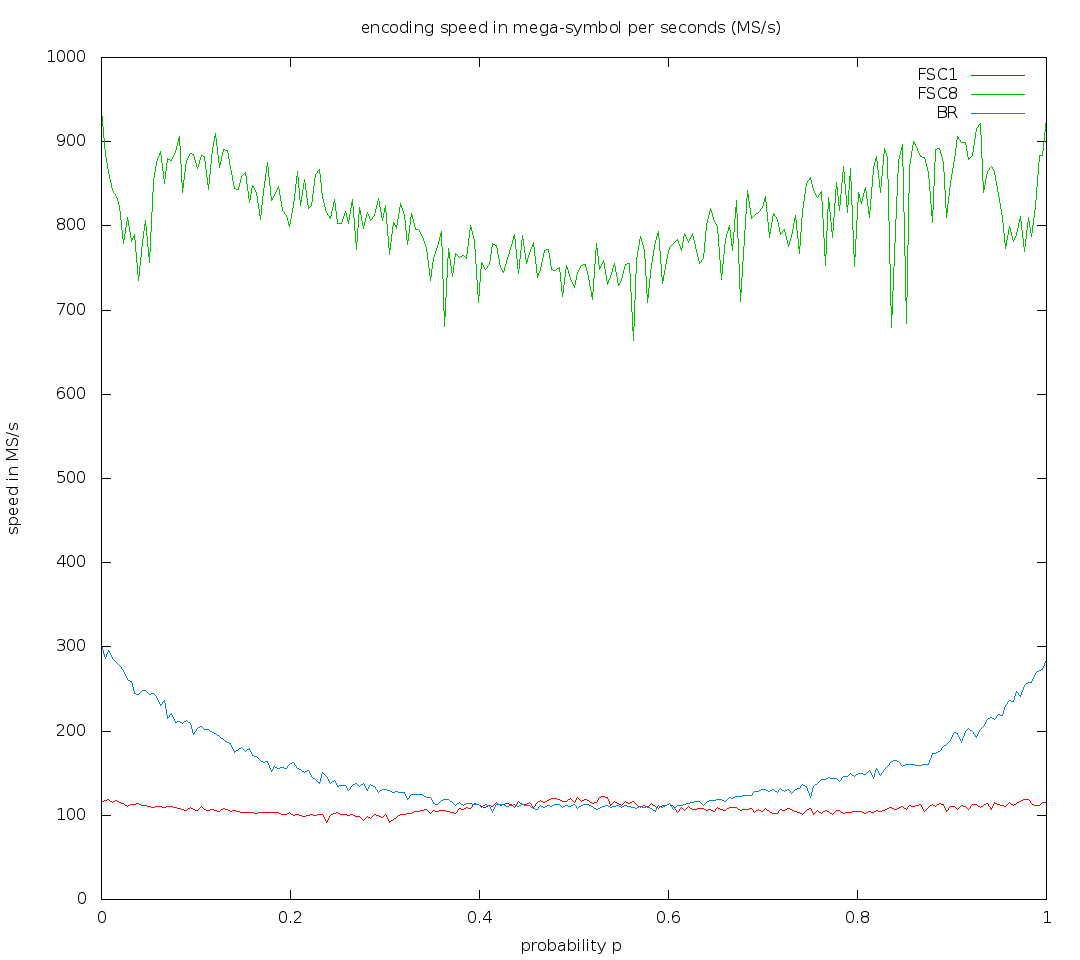
ps. skal, there is missing binary FSE in the decoding speed graph after your recent speedup - is it now faster than arithmetic coding for most of probabilities?
dud...@gmail.com
https://font-compression-reference.googlecode.com/issues/attachment?aid=10002000&name=ANSforBrotli.pdf&token=Ql25CIskoTXGfJ_MykmOxeGY8T0%3A1391043805587
It shows that 1024 states, even using Yann's old fast symbol distribution (step=5/8L+1), is often sufficient to work near 0.15% loss range (3rd and 1st):
Huffman ANS 1024 ANS 2048 ANS 4096 Entropy
Literal data 22’487’335 22’029’598 22’003’260 21’999’180 21’996’501
Cmd data 19’214’724 19’096’518 18’884’079 18’836’315 18’823’580
Dist data 17’966’376 17’807’524 17’792’696 17’787’763 17’782’613
However, they use huge headers and small blocks - making that both speed and total size is worse than for Huffman.
It is a lesson that we should be more careful while directly replacing Huffman with ANS - with choosing sizes of blocks and eventual headers (how to represent/approximate probabilities).
Generally, storing frequencies with better precision than the number of appearances in the table (lt[s]) makes no sense - and still these values can be compressed (lt[s]=1 can be very often).
Larger representation which makes sense is storing the entire optimized symbol distribution (included tuning) - uncompressed it's 1kB for 1024 states and 256 size alphabet.
dud...@gmail.com
Here is implementation of the "range variant of ANS" (rANS) of Fabian "ryg" Giesen: https://github.com/rygorous/ryg_rans
Accordingly to discussion on Charles Bloom blog ( http://cbloomrants.blogspot.com/ ), it is the most interesting version of ANS (?) - faster replacement of range coding: simpler and using single multiplication per decoded symbol (8th page of http://arxiv.org/pdf/1311.2540 ):
For natural f[s] (quantization of probabilities):
freq[s] = f[s] / 2^n
cumul[s] = sum_{i<s} f[s]
mask = 2^n - 1
symbol[x=0 ... n-1] = min_s : cumul[s]>x - which symbol is in x-th position in (0..01..1...) length 2^n range: having f[s] appearances of symbol s
encoding of symbol s requires 1 division modulo f[s]:
C(s,x) = (floor(x/f[s]) << n) + mod(x , f[s]) + cumul[s]
decoding from x has one multiplication and needs symbol[] table or function deciding in which subrange we are:
s = symbol [ x & mask ]
x = f[s] * (x >> n) + (x & mask) - cumul[s]
Best,
Jarek
dud...@gmail.com
For example the simplicity of renormalization allows to use SIMD to get, as he says, more that 2x speedup:
SIMD decoder with byte-wise normalization
1: // Decoder state
2: Vec4_U32 x;
3: uint8 * read_ptr;
4:
5: Vec4_U32 Decode ()
6: {
7: Vec4_U32 s;
8:
9: // Decoding function (uABS , rANS etc.).
10: s, x = D(x);
11:
12: // Renormalization
13: // L = normalization interval lower bound .
14: // NOTE: not quite equivalent to scalar version!
15: // More details in the text.
16: for (;;) {
17: Vec4_U32 new_bytes;
18: Vec4_bool too_small = lessThan(x, L);
19: if (! any( too_small))
20: break ;
21:
22: new_bytes = packed_load_U8( read_ptr , too_small);
23: x = select (x, (x << 8) | new_bytes , too_small);
24: read_ptr += count_true( too_small);
25: }
26:
27: return s;
28: }
Pascal Massimino
There has just appeared Fabian Giesen paper with practical remarks for ANS implementation (especially formula variants): http://arxiv.org/abs/1402.3392
--
dud...@gmail.com
Thanks for the implementation.
Regarding Fabian, I think very interesting is also his rANS with alias method: http://fgiesen.wordpress.com/2014/02/18/rans-with-static-probability-distributions/
For size m alphabet we split the range into m equal subranges ("buckets") and in each of them place the corresponding symbol and eventually part of probability distribution of one other symbol ("alias").
It is a bit slower, but allows to work on much larger alphabets with great accuracy.
I think it is also perfect variant for dynamical updating in more adaptive compressors - in opposite to Huffman, it is accurate and cheap to modify: simple modification is just shifting a single divider (and updating starts of further appearances of symbol and alias).
Regarding speed, also Yann's implementation got nearly 2x speedup back then - here are some more current benchmarks (however, "TurboANS" seems unconfirmed) : http://encode.ru/threads/1890-Benchmarking-Entropy-Coders
Fabian's vectorization due to single number state is indeed another interesting feature, which can provide additional speedup. Binary version could use even 16 x 8bit uABS ...
There can be dependence between symbols while encoding, however, while decoding, symbols read in such single step have to be independent - what is a big inconvenience for binary case ...
Cheers,
Jarek
ps. Here is Charles Bloom post about ANS applications: http://cbloomrants.blogspot.com/2014/02/02-25-14-ans-applications.html
Basically, replacing Huffman and Range coding ... however, I think tABS (set of tables for different probabilities) should be also faster than AC, as it is just table use and BitOr per symbol (e.g. CABAC is muuuch more complicated).
dud...@gmail.com
http://encode.ru/threads/1920-In-memory-open-source-benchmark-of-entropy-coders
ps. Fresh slides about ANS: https://www.dropbox.com/s/qthswiguq5ncafm/ANSsem.pdf
dud...@gmail.com
I have recently found fast "tuned" symbol spread for tANS while working on toolkit to test various quantization and spread methods ( https://github.com/JarekDuda/AsymmetricNumeralSystemsToolkit ): which does not only use q[s] ~ L*p[s] quantization of probability distribution (number of appearances), but also exact values of probabilities p[s].
For example for 4 symbol and L=16 states:
p: 0.04 0.16 0.16 0.64
q/L: 0.0625 0.1875 0.125 0.625
this quantization itself has dH/H ~ 0.011 rate penalty
spread_fast() gives 0233233133133133 and dH/H ~ 0.020
spread_prec() gives 3313233103332133 and dH/H ~ 0.015 - generally it is close to quantization dH/H
while spread_tuned(): 3233321333313310 and dH/H ~ 0.0046 - better than quantization dH/H due to using also p
Tuning shifts symbols right when q[s]/L > p[s] and left otherwise, getting better agreement and so compression rate.
The found rule is: preferred position for i \in [q[s], 2q[s]-1) appearance of symbol s is x = 1/(p[s] * ln(1+1/i)).
Returning to video compression, I have a problem finding VP9 documentation, but here ( http://forum.doom9.org/showthread.php?t=168947 ) I have found: "Probabilities are one byte each, and there are 1783 of them for keyframes, 1902 for inter frames (by my count)".
So you are probably using 256 size alphabet range coder for a lot of fixed probabilities - rANS is its many times faster direct alternative ( https://github.com/rygorous/ryg_rans ):
- it uses single multiplication per decoding step instead of 2 for range coding,
- its state is a single natural number, making it perfect for SIMD parallelization,
- it uses simpler representation of probability distribution, for example allowing for alias method to reduce memory need ( http://fgiesen.wordpress.com/2014/02/18/rans-with-static-probability-distributions/ ).
tANS is often even faster (FSE has ~50% faster decoding than zlib Huffman). Thanks to tuning, I believe L=1024 states should be sufficient for most situations (eventually grouping low probable symbols: below 0.7/L, into an exit symbol decoded in succeeding step) - you need 1kB to store such symbol spread and can nearly instantly generate a 3-4kB decoding table for a given one.
dud...@gmail.com
Let us choose M=L, b=2 degenerate rANS case. Equivalently, take tANS, b=2. Use quantization to L denominator:
p[s] ~ q[s]/L
Now spread tANS symbols in ranges: symbol s in {B[s],...B[s+1]-1} positions
where B[s] = L + q[0] + ... + q[s-1]
x is in I = {L , ... , 2L-1} range, symbol s encodes from {q[s], ..., 2q[s] - 1} range
now decoding step is:
s = s(x); // like for rANS, different approaches possible
x = q[s] + x - B[s]; // the proper decoding step
while (x<L) x = x<<1 + "bit from stream"; // renormalization
encoding s:
while (x >= 2q[s]) {produce(x&1); x >>=1;} // renormalization
x = B[s] + x - q[s]; // the proper coding step
Unfortunately its rate penalty does not longer drop to 0 while growing L - it is usually better than Huffman (can be tested by last version of toolkit), but there are exceptions (I think they could be improved by modifying quantizer - I could work on that if there would be an interest).
Discussion and information: http://encode.ru/threads/2035-tANS-rANS-fusion-further-simplification-at-cost-of-accuracy
ps. Another compressor has recently replaced Huffman with tANS (lzturbo) - it is now ~2 times faster than tor for similar compression rates: http://encode.ru/threads/2017-LzTurbo-The-fastest-now-more-faster?p=39815&viewfull=1#post39815
Pascal Massimino
Hi skal, all,
I have recently found fast "tuned" symbol spread for tANS while working on toolkit to test various quantization and spread methods ( https://github.com/JarekDuda/AsymmetricNumeralSystemsToolkit ): which does not only use q[s] ~ L*p[s] quantization of probability distribution (number of appearances), but also exact values of probabilities p[s].
For example for 4 symbol and L=16 states:
p: 0.04 0.16 0.16 0.64
q/L: 0.0625 0.1875 0.125 0.625
this quantization itself has dH/H ~ 0.011 rate penalty
spread_fast() gives 0233233133133133 and dH/H ~ 0.020
spread_prec() gives 3313233103332133 and dH/H ~ 0.015 - generally it is close to quantization dH/H
while spread_tuned(): 3233321333313310 and dH/H ~ 0.0046 - better than quantization dH/H due to using also p
Tuning shifts symbols right when q[s]/L > p[s] and left otherwise, getting better agreement and so compression rate.
The found rule is: preferred position for i \in [q[s], 2q[s]-1) appearance of symbol s is x = 1/(p[s] * ln(1+1/i)).
Returning to video compression, I have a problem finding VP9 documentation, but here ( http://forum.doom9.org/showthread.php?t=168947 ) I have found: "Probabilities are one byte each, and there are 1783 of them for keyframes, 1902 for inter frames (by my count)".
So you are probably using 256 size alphabet range coder for a lot of fixed probabilities - rANS is its many times faster direct alternative ( https://github.com/rygorous/ryg_rans ):
- it uses single multiplication per decoding step instead of 2 for range coding,
- its state is a single natural number, making it perfect for SIMD parallelization,
- it uses simpler representation of probability distribution, for example allowing for alias method to reduce memory need ( http://fgiesen.wordpress.com/2014/02/18/rans-with-static-probability-distributions/ ).
Enc time: 0.134 sec [149.41 MS/s] (15901586 bytes out, 20000000 in).
Entropy: 0.7951 vs expected 0.7930 (off by 0.00211 bit/symbol [0.266%])
Dec time: 0.155 sec [129.09 MS/s].
With alias method:
Enc time: 0.215 sec [92.92 MS/s] (15894578 bytes out, 20000000 in).
Entropy: 0.7947 vs expected 0.7930 (off by 0.00176 bit/symbol [0.222%])
Dec time: 0.174 sec [114.85 MS/s].
tANS is often even faster (FSE has ~50% faster decoding than zlib Huffman). Thanks to tuning, I believe L=1024 states should be sufficient for most situations (eventually grouping low probable symbols: below 0.7/L, into an exit symbol decoded in succeeding step) - you need 1kB to store such symbol spread and can nearly instantly generate a 3-4kB decoding table for a given one.
--
You received this message because you are subscribed to the Google Groups "Codec Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to codec-devel...@webmproject.org.
To post to this group, send email to codec...@webmproject.org.
Visit this group at http://groups.google.com/a/webmproject.org/group/codec-devel/.
For more options, visit https://groups.google.com/a/webmproject.org/d/optout.
dud...@gmail.com
- discussed above Pascal's implementation (recently got speedup thanks to interleaving): https://github.com/skal65535/fsc
- discussion about binary cases, where ANS turns out also providing speedup: http://encode.ru/threads/1821-Asymetric-Numeral-System/page8
Here are decoding step from Pascal's listing for 32bit x, 16bit renormalization, 16bit probability precision: p0=prob*2^16 \in {1, ..., 2^16 - 1} for two variants.
rABS variant:
uint16_t xfrac = x & 0xffff;
uint32_t x_new = p0 * (x >> 16);
if (xfrac < p0) { x = x_new + xfrac; out[i] = 0;
} else { x -= x_new + p0; out[i] = 1; }
uABS variant (very similar to Matt Mahoney fpaqc):
uint64_t xp = (uint64_t)x * p0 - 1;
out[i] = ((xp & 0xffff) + p0) >> 16; // <= frac(xp) < p0
xp = (xp >> 16) + 1;
x = out[i] ? xp : x - xp;
plus renormalization (much simpler than in arithmetic coding):
if (x < (1 << 16)) { x = (x << 16) | *ptr++; }
- list of available implementations of ANS: http://encode.ru/threads/2078-List-of-Asymmetric-Numeral-Systems-implementations
- another compressor has switched to ANS: LZA, moving to the top of this benchmark: http://heartofcomp.altervista.org/MOC/MOCADE.htm (zhuff = LZ4 + tANS is at the top for decoding speed there).
Pascal Massimino
This thread needs some updates:
- discussed above Pascal's implementation (recently got speedup thanks to interleaving): https://github.com/skal65535/fsc
- discussion about binary cases, where ANS turns out also providing speedup: http://encode.ru/threads/1821-Asymetric-Numeral-System/page8
Here are decoding step from Pascal's listing for 32bit x, 16bit renormalization, 16bit probability precision: p0=prob*2^16 \in {1, ..., 2^16 - 1} for two variants.
rABS variant:
uint16_t xfrac = x & 0xffff;
uint32_t x_new = p0 * (x >> 16);
if (xfrac < p0) { x = x_new + xfrac; out[i] = 0;
} else { x -= x_new + p0; out[i] = 1; }
uABS variant (very similar to Matt Mahoney fpaqc):
uint64_t xp = (uint64_t)x * p0 - 1;
out[i] = ((xp & 0xffff) + p0) >> 16; // <= frac(xp) < p0
xp = (xp >> 16) + 1;
x = out[i] ? xp : x - xp;
uint64_t xp = (uint64_t)x * q0;
out[i] = ((xp & (K - 1)) >= p0);
xp >>= L_pb;
x = out[i] ? xp : x - xp;
plus renormalization (much simpler than in arithmetic coding):
if (x < (1 << 16)) { x = (x << 16) | *ptr++; }
- list of available implementations of ANS: http://encode.ru/threads/2078-List-of-Asymmetric-Numeral-Systems-implementations
- another compressor has switched to ANS: LZA, moving to the top of this benchmark: http://heartofcomp.altervista.org/MOC/MOCADE.htm (zhuff = LZ4 + tANS is at the top for decoding speed there).
--
dud...@gmail.com
"System and method for compressing data using asymmetric numeral systems with probability distributions"
https://www.ipo.gov.uk/p-ipsum/Case/ApplicationNumber/GB1502286.6
I wanted to make us cover all possibilities to prevent patenting, I cannot even find its text.
As it could complicate the use of ANS, I thought that it would be also of Google interest to prevent that ...
ps. Very interesting Yann Collet ANS-based compressor: https://github.com/Cyan4973/zstd , https://www.reddit.com/r/programming/comments/2tibrh/zstd_a_new_compression_algorithm/
ps2. ANS will be presented at PCS 2015 in two weeks - paper (nothing new but understood by reviewers): https://dl.dropboxusercontent.com/u/12405967/pcs2015.pdf
dud...@gmail.com
Here is a nice Fabian's post about its adaptive modification of large alphabet probability distribution: https://fgiesen.wordpress.com/2015/05/26/models-for-adaptive-arithmetic-coding/
ps. list of ANS implementations: http://encode.ru/threads/2078-List-of-Asymmetric-Numeral-Systems-implementations
Pascal Massimino
It has just turned out that somebody is trying to patent something looking very general about ANS:
"System and method for compressing data using asymmetric numeral systems with probability distributions"
https://www.ipo.gov.uk/p-ipsum/Case/ApplicationNumber/GB1502286.6
I wanted to make us cover all possibilities to prevent patenting, I cannot even find its text.
As it could complicate the use of ANS, I thought that it would be also of Google interest to prevent that ...
ps. Very interesting Yann Collet ANS-based compressor: https://github.com/Cyan4973/zstd , https://www.reddit.com/r/programming/comments/2tibrh/zstd_a_new_compression_algorithm/
ps2. ANS will be presented at PCS 2015 in two weeks - paper (nothing new but understood by reviewers): https://dl.dropboxusercontent.com/u/12405967/pcs2015.pdf
dud...@gmail.com
Thanks, I cannot afford going to Australia and it's only a poster presentation, but maybe the peer-reviewed paper will finally make ANS no longer invisible to Huffman-worshiping academics.
For example cheap tANS compression+encryption would be perfect for battery powered: Internet of Things, smarwatches, implants, sensors, RFIDs ... but it requires a serious cryptographic research.
I'm a bit worried about the patent, hopefully it will be rejected.
Best,
Jarek
ps. Maybe you are thinking about watermarking for VPs? If so, I have just finished a paper about enhancement of Fountain Codes concept - where the sender not only don't have to care about which subset of packets will be received, but also about their damage levels. So e.g. such watermarking could be extracted from some number of badly captured frames: http://arxiv.org/abs/1505.07056
dud...@gmail.com
http://encode.ru/threads/2221-LZFSE-New-Apple-Data-Compression
better compression than zlib and 3x faster ...
dud...@gmail.com
https://chromium-review.googlesource.com/#/c/318743
there is implementation of uABS, rABS and rANS - indeed rANS+uABS seem a perfect combination for video compression: switching between large alphabets (DCT coefficients, prediction modes etc.) and binary choices (e.g. if exception happens).
They can operate on the same state x (64 or 32 bit with 32 or 16 bit renormalization).
There is nice recent Fabian's post about efficient switching: https://fgiesen.wordpress.com/2015/12/21/rans-in-practice/
Efficient application of adaptive large alphabet entropy coder in video compression seems a good topic for a discussion here ...
For example it might be worth grouping a few DCT coefficients into a single symbol - this way entropy coder also takes correlations between them into considerations.
Alias rANS might be worth considering for adaptive purposes - modifications of probabilities can be made by just shifting the divider there ( https://fgiesen.wordpress.com/2014/02/18/rans-with-static-probability-distributions/ ).
ps. Yann Collet's open-source ZSTD (tANS) got high compression mode and generally is quickly developing: https://github.com/Cyan4973/zstd
ps2. order 1 rANS is used in CRAM 3.0 data (practically default) compressor of genetic data (European Bioinformatics Institute): http://www.htslib.org/benchmarks/CRAM.html
Aℓex Converse
--
You received this message because you are subscribed to the Google Groups "Codec Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to codec-devel...@webmproject.org.
To post to this group, send email to codec...@webmproject.org.
Visit this group at https://groups.google.com/a/webmproject.org/group/codec-devel/.
dud...@gmail.com
Hi Alex,
I wanted to take a closer look at VP9/10 to think about optimizations, but I cannot find documentation. The best sources I could find are:
http://files.meetup.com/9842252/Overview-VP9.pdf
http://forum.doom9.org/showthread.php?t=168947
Are there some better available? Could you summarize made/planned changes for VP10?
The main advantage of ANS is accurate handling of large alphabet – there are many places including compressed header, prediction modes, motion vectors, etc. … however, the most significant are DCT coefficients – it is indeed a natural first step, but finally it might be beneficial to complete change into switching between ANS and ABS (probably rANS and uABS, but can be also realized with tabled variants – without multiplications).
From the decoder point of view, which is the main priority in YouTube-like applications, such change means improvement of performance (including uABS vs AC), and simplification (no binarizing) – I don’t see any additional issues with parallelization here?
From the encoder point of view, there would be needed additional buffer for probabilities if adaptively modifying probabilities. However, at least in VP9, probability model seems to be fixed within a frame (still true in VP10?) – eventual adaptation is made for successive frame. In such case we have just context-base modelling (like in Markov) – no additional buffer is needed: encoder goes backward, but uses context from the perspective of later forward decoding. In current (software) implementations of ANS-based compressors, entropy coding is usually split from modelling phase to use boost from interleaving. In any case, I don’t see additional issues regarding parallelization?
See Fabian’s post about dynamical switching between various streams: https://fgiesen.wordpress.com/2015/12/21/rans-in-practice/
Let’s look at the DCT/ADST, if I properly understand, you use symmetric Pareto probability distribution:
cdf(x) = 0.5 + 0.5 * sgn(x) * [1 - {alpha/(alpha + |x|)} ^ beta
for beta=8 and alpha determined by context – one of 576 combinations of: {Y or UV, block size, position in block, above/left coefficient}, using 8 bit probabilities – originally for branches of a binary tree.
Using large alphabet entropy coder, you can have prepared coding tables for quantized alpha, and choose one accordingly to the context – it seem this is what you are doing (?), also rANS is perfect here.
However, it seems you have remained 8 bit probabilities – large alphabet might need a better resolution here, and there is no problem with it while using rANS. I see you use 32 bit state, and 8 bit renormalization – there is no problem with using even 16 bit probabilities in this setting.
There are probably possible optimizations here, tough questions like:
- What family of probability distributions to choose (I thought it is usually used two-sided exponential: rho(x) ~ exp(-alpha|x|)), and context dependencies …
- The context of neighboring coefficients seems extremely important and hard to use effectively – maybe it should depend e.g on (weighted) average of all previous coefficients …
- If high frequencies take only e.g. {-1,0,1} values, you can group a few of them into a larger alphabet,
- The EOB token seems a burden – wouldn’t it better to just encode the number of nonzero coefficients? …
dud...@gmail.com
http://encode.ru/threads/1870-Range-ANS-%28rANS%29-faster-direct-replacement-for-range-coding?p=47976&viewfull=1#post47976
https://github.com/jkbonfield/rans_static
"Q8 test file, order 0:
arith_static 239.1 MB/s enc, 145.4 MB/s dec 73124567 bytes -> 16854053 bytes
rANS_static4c 291.7 MB/s enc, 349.5 MB/s dec 73124567 bytes -> 16847633 bytes
rANS_static4j 290.5 MB/s enc, 354.2 MB/s dec 73124567 bytes -> 16847597 bytes
rANS_static4k 287.5 MB/s enc, 666.2 MB/s dec 73124567 bytes -> 16847597 bytes
rANS_static4_16i 371.0 MB/s enc, 453.6 MB/s dec 73124567 bytes -> 16847528 bytes
rANS_static64c 351.0 MB/s enc, 549.4 MB/s dec 73124567 bytes -> 16848348 bytes"
"Q8 test file, order 1:
arith_static 189.2 MB/s enc, 130.4 MB/s dec 73124567 bytes -> 15860154 bytes
rANS_static4c 208.6 MB/s enc, 269.2 MB/s dec 73124567 bytes -> 15849814 bytes
rANS_static4j 210.5 MB/s enc, 305.1 MB/s dec 73124567 bytes -> 15849814 bytes
rANS_static4k 212.2 MB/s enc, 403.8 MB/s dec 73124567 bytes -> 15849814 bytes
rANS_static4_16i 240.4 MB/s enc, 345.4 MB/s dec 73124567 bytes -> 15869029 bytes
rANS_static64c 239.2 MB/s enc, 397.6 MB/s dec 73124567 bytes -> 15850522 bytes"dud...@gmail.com
https://github.com/powzix/kraken/blob/master/lzna.cpp
It has rANS with very nice symbol-by-symbol adaptation for 8 (3 bit) or 16 (4 bit) size alphabet - with both search of a symbol and adaptation as a few SIMD instructions.
Pascal Massimino
--
You received this message because you are subscribed to the Google Groups "Codec Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to codec-devel+unsubscribe@webmproject.org.
dud...@gmail.com
So the used mechanisms are described in Fabian's article: https://fgiesen.wordpress.com/2015/12/21/rans-in-practice/
Here is discussion about these "open-source" decoders: http://encode.ru/threads/2577-Open-source-Kraken-Mermaid-Selkie-LZNA-decompression
I believe AV1 could really benefit a help from Charles Bloom and Fabian Giesen - maybe AOM could ask RAD Game Tools to join?
dud...@gmail.com
https://code.facebook.com/posts/1658392934479273/smaller-and-faster-data-compression-with-zstandard/

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Alexey Eromenko
Are there any Zstandard tools for Windows ? (preferably GUI, but CLI also good)
To me it would be great if it get's integrated into 7-zip, the
Open-Source Software compress/decompress for Windows.
--
-Alexey Eromenko "Technologov"
dud...@gmail.com
Here is for various languages: http://facebook.github.io/zstd/#other-languages
dud...@gmail.com
http://encode.ru/threads/2607-AVX-512-and-interleaved-rANS
For example Fabian writes that 4x interleaving with 8x SIMD vectors allows for ~1GB/s decoding ... but it would require 32 independent streams.
In 2013 state-of-art for accurate entropy decoding was far below 100 MB/s ...
Hamid has recently updated his entropy coder benchmarks and added ARM: https://sites.google.com/site/powturbo/entropy-coder
Currently James rANS has ~20% ~faster decoding than Yann's FSE/tANS on i7 (600 vs 500 MB/s), but surprisingly it's the opposite on ARM (100 vs 120 MB/s).
rANS relies on fast multiplication, but if tANS + Huffman (tANS decoder can also decode Huffman) would get hardware support from processor manufacturers, it cheaply could be a few times faster, like 1 symbol/cycle.
dud...@gmail.com
Method: VP9 Daala rANS
Encoding: 107 192 367
Decoding: 113 145 182
In contrast, state-of-art static rANS ( http://encode.ru/threads/2607-AVX-512-and-interleaved-rANS ) has currently >400 MB/s encoding, 1300MB/s decoding.
Using 16 size alphabet, it mulitiplies by 4 bits/symbol: to ~1600 Mbps encoding and ~5200 Mbps decoding.
So static rANS decoding can be like 30x faster than reported in Daala paper ...
Also, it states that you cannot do adaptive rANS: "However, unlike rANS, it is possible to modify the implementation to encode with estimated probabilities rather than optimal probabilities." - what is just not true, see e.g. LZNA or BitKnit compressors ...
https://fgiesen.wordpress.com/2015/12/21/rans-in-practice/
Timothy B. Terriberry
> Also, it states that you cannot do adaptive rANS: "However, unlike rANS,
> it is possible to modify the implementation to encode with estimated
> probabilities rather than optimal probabilities." - what is just not
_even_ _if_ you are using static probabilities over a whole frame, you
can avoid buffering the symbols for the entire frame by substituting in
sub-optimal probabilities (based solely on past statistics). Whereas you
cannot avoid the buffering needed to reverse the symbol order in rANS
(to my understanding).
It was not an attempt to make a statement about adaptive symbol
probabilities.
dud...@gmail.com
Regarding throughputs, the biggest surprise was that rANS decoder was slower than encoder (which is still slower even than for non-approximated RC: https://github.com/jkbonfield/rans_static ) - usually it is the opposite.
The main reason is that decoder still uses linear loop to determine the symbol:
for (i = 0; rem >= (top_prob = cdf[i]); ++i) {cum_prob = top_prob;}
from https://aomedia.googlesource.com/aom/+/master/aom_dsp/ansreader.h
Most of implementations use table to determine the symbol, but it's too memory costly here.
Here is fresh Fabian's response how they get fast implementation without the table: http://encode.ru/threads/2607-AVX-512-and-interleaved-rANS/page2
1) SIMD on PC - lines 234-243 for 4bit alphabet here: https://github.com/powzix/kraken/blob/master/lzna.cpp (analogously for hardware implementation)
t0 = _mm_loadu_si128((const __m128i *)&model->prob[0]);
t1 = _mm_loadu_si128((const __m128i *)&model->prob[8]);
t = _mm_cvtsi32_si128((int16)x);
t = _mm_and_si128(_mm_shuffle_epi32(_mm_unpacklo_epi16(t, t), 0), _mm_set1_epi16(0x7FFF));
c0 = _mm_cmpgt_epi16(t0, t);
c1 = _mm_cmpgt_epi16(t1, t);
_BitScanForward(&bitindex, _mm_movemask_epi8(_mm_packs_epi16(c0, c1)) | 0x10000);
2) branchless quaternary search on ARM:
val = (cumfreq[ 4] > x) ? 0 : 4;
val += (cumfreq[ 8] > x) ? 0 : 4;
val += (cumfreq[12] > x) ? 0 : 4;
const U16 *cffine = cumfreq + val;
val += (cffine[ 1] > x) ? 0 : 1;
val += (cffine[ 2] > x) ? 0 : 1;
val += (cffine[ 3] > x) ? 0 : 1;
Another option is alias rANS ( https://fgiesen.wordpress.com/2014/02/18/rans-with-static-probability-distributions/ ) - a single branch per decoded symbol, but it's more costly from encoder side.
Aℓex Converse
--
dud...@gmail.com
https://www.ipo.gov.uk/p-ipsum/Case/ApplicationNumber/GB1502286.6
https://www.ipo.gov.uk/p-ipsum/Document/ApplicationNumber/GB1502286.6/9534f916-094d-4b23-925f-b0f5b95145e4/GB2538218-20161116-Publication%20document.pdf
Here is a timeline for UK Patent application: http://www.withersrogers.com/wp-content/uploads/2015/03/uk_patent_application_time_line.pdf
It seems extremely general, combination among others of my and Fabian's paper ( https://arxiv.org/abs/1402.3392 ) - it cites only https://arxiv.org/abs/1311.2540
Title: "System and method for compressing data using asymmetric numeral systems with probability distributions"
Abstract: "A data compression method using the range variant of Asymmetric Numeral Systems, rANS, to encode a data stream, where the probability distribution table(s) used is constructed using a Markov model. A plurality of probability distribution tables may be used each constructed from a subset of the data stream and each used to encode another subset of the data stream. The probability distribution table may compromise a special code (or 'escape code') which marks a temporary switch to second probability distribution table. The probability distribution table itself may be stored in a compressed format. The data stream may be information containing gene sequences or related information."
Maybe Google could help fighting with it?
ps. Very interesting rANS-based "GST: GPU-decodable Supercompressed Textures": http://gamma.cs.unc.edu/GST/
Format JPEG PNG DXT1 Crunch GST Time (ms) 848.6 1190.2 85.8 242.3 93.4 Disk size (MB) 6.46 58.7 16.8 8.50 8.91 CPU size (MB) 100 100 16.8 16.8 8.91
dud...@gmail.com
discussion: http://encode.ru/threads/2648-Published-rANS-patent-by-Storeleap
dud...@gmail.com
The only non-rejected claims concern basic techniques of PPM compression, so I hope the situation is safe (?)
I was thinking about Moffat/Daala approximation of range coding to remove the need for multiplication (up to 3% ratio loss for binary alphabet).
So there is unpublished ANS variant kind of between rANS and tANS - which directly operates on CDF like rANS, but doesn't use multiplication nor large tables - at cost of being approximated (still handling skewed distributions).
http://encode.ru/threads/2035-tANS-rANS-fusion-further-simplification-at-cost-of-accuracy
Like in rANS, denote symbol[x] = s: CDF[s] <= x < CDF[s+1] ...
... but just use it as symbol spread for tANS - getting simple direct math formulas.
decoding step becomes just subtraction ( xs[s] = L + 2*CDF[s] - CDF[s+1] ):
s = symbol(x);
x = x - xs[s]; // proper ANS decoding step
while (x<L) x = x<<1 + "bit from stream"; // renormalization
Where normalization can be done directly by just looking at the number of leading zeros - especially for hardware implementation.
coding step ( q[s] = CDF[s+1] - CDF[s] ):
while(x >= 2 q[s]) {produce(x&1); x >>=1;} // renormalizationx = x + xs[s]
It is tANS with trivial symbol spread - allowing to use simple formula instead of table, but at cost of some small inaccuracies. In contrast to Huffman, it doesn't operate on power-of-2-probabilites: doesn't have problem with skewed distributions (Pr ~ 1).
If you want, I can compare it with much more complex Moffat/Daala approximation or you can just test it using spread_range in https://github.com/JarekDuda/AsymmetricNumeralSystemsToolkit
dud...@gmail.com
This trivial variant is degenerated rANS:
- minimal_state = quantization_denominator,
- bit-by-bit renormalization: it is more accurate, the number of bits for decoding can be obtained by counting leading zeros.
Another option is minimal_state = 2 * quantization_denominator, it gets ~0.7% average ratio loss, and multiplication in rANS is by 0 or 1, what can be realized by single branch.
For minimal_state = 4 * quantization_denominator, it gets ~0.3% average ratio loss, multiplication is by {0,1,2,3}, what can be realized by two branches.
Ratio loss for these 4 cases and binary alphabet (horizontal axis is probability, simulations: https://dl.dropboxusercontent.com/u/12405967/Moffat.pdf ):

So it can be much better than Moffat without multiplication, still directly operating on CDF.
And generally I could help with the "Google ANS vs Daala Moffat" discussion if I would know the details ...
dud...@gmail.com
I have just spotted a week old Daala slides ( https://people.xiph.org/~tterribe/pubs/lca2017/aom.pdf ) and couldn’t resist commenting its summary on AV1 entropy coding (slide 22):
“
– daala_ec : the current default
– ans : faster in software, complications for hardware/realtime (must encode in reverse order)
“
1) 1) Surprisingly, it has forgotten to mention the real problem with Daala EC – that it is INACCURATE.
Moffat’s inaccuracy gives on average 2.5% ratio loss, I understand it is reduced a bit by using the tendency of the first symbol to be the most probable one.
However, we could use this tendency in a controlled way instead: e.g. in the initial probability distribution, which optimally should be chosen individually for each context or group of contexts (and e.g. fixed in the standard).
Then after making the best of controlled prediction, there should be used an accurate entropy coder – you could easily get >1% ratio improvement here (I got a few percent improvement when testing a year ago: http://lists.xiph.org/pipermail/daala/2016-April/000138.html ).
And no,
adaptiveness is an obstruction for using rANS ( https://fgiesen.wordpress.com/2015/05/26/models-for-adaptive-arithmetic-coding/ ).
2) 2). Regarding cost, my guess is that
internet traffic is dominated by video streaming like YouTube and Netflix, so
savings there should be the main priority: where you encode once and decode thousands-millions
of times - decoding cost is muuuch more important.
And honestly, the additional cost of rANS backward encoding seems completely negligible here
(?): it requires just a few kilobyte buffer for encoder (can be shared) to
get < < 0.1% ratio loss due to data blocks fitting the buffer. The required tables of probability distributions for hundreds of contexts are already many times larger, and video encoder seems to generally require megabytes of memory for all
the analysis and processing (?).
As you plan billions of users for AV1, it is a matter of time when people will start asking why while we have now modern fast and accurate entropy coding, widely used e.g. by Apple and Facebook, the Google et. al. team has decided to use an old slow and inaccurate one instead?
Leading to comments like "Although brotli uses a less efficient entropy encoder than Zstandard, it is already implemented (...)" from the Guardian ( https://www.theguardian.com/info/developer-blog/2016/dec/01/discover-new-compression-iinovations-brotli-and-zstandard ).
Maybe let’s spare the embarrassment and start this inevitable discussion now – is there a real objective reason for using the slow inaccurate Moffat’s approximation for AV1?
Jean-Marc
On Wednesday, January 25, 2017 at 7:25:14 AM UTC-5, dud...@gmail.com wrote:
1) 1) Surprisingly, it has forgotten to mention the real problem with Daala EC – that it is INACCURATE.Moffat’s inaccuracy gives on average 2.5% ratio loss, I understand it is reduced a bit by using the tendency of the first symbol to be the most probable one.
However, we could use this tendency in a controlled way instead: e.g. in the initial probability distribution, which optimally should be chosen individually for each context or group of contexts (and e.g. fixed in the standard).
I understand your confusion here. The actual version of the Daala EC we merged in AV1 does not actually have the inaccuracy. The original inaccuracy was due to our use of non-power-of-two total for the CDF and our desire to avoid a division. We later added a version of the EC that assumes power of two for the total frequency (something rANS already assumes), which makes it possible to use shifts rather than divisions and leads to <<0.1% overhead instead of the 1-2% overhead we otherwise had. Since in AV1, we only merged the power-of-two EC, the EC now has negligible overhead. Given that, the (new) Daala EC and rANS are actually nearly interchangeable in AV1. The only difference is that rANS is (IIRC) slightly faster on the decoder side, at the cost of having to do the buffering on the encoder side.
Jean-Marc
dud...@gmail.com
I understand you now use standard range coder: 353-395 from https://aomedia.googlesource.com/aom/+/master/aom_dsp/entdec.c : “ Decodes a symbol given a cumulative distribution function (CDF) table that sums to a power of two.”
So now instead of single multiplication of rANS decoder, you have a loop with up to 16 multiplications (lines 387-390):
do {
u = v;
v = cdf[++ret] * (uint32_t)r >> ftb;
} while (v <= c);
This seems extremely expensive and its variability seems deadly for synchronization and frequency of hardware decoder (?) Ok, you would probably just always perform 16 multiplications in parallel, but this is muuuuch more expensive than just single rANS multiplication – also for hardware.
For software decoders, the general experience of the society is that rANS is even 30x faster than range decoder (1500 vs 50 MB/s: https://sites.google.com/site/powturbo/entropy-coder ): less multiplications, much simpler renormalization and range coder is hard to vectorize as its state are two numbers instead of one.
Could you maybe explain how this cost paid by billions of YouTube and Netflix users (decoders) is compensated by avoiding a few kilobytes of buffer for rANS encoder?
dud...@gmail.com
It can reduced practically to zero due to compensating it by storing some information in the initial state of encoder: instead of starting with e.g. 2^16 (L_BASE), start with 2^16 + "some relevant 16 bits" initial state. These bits are just read at the end of decoding process.
Here are some possibilities:
1) the initial state can for example directly contain last four symbols. However, it requires (e.g. 4 symbol) earlier information about the incoming flush for decoder, what I understand is a technical difficulty,
2) the initial state can contain some completely separate information, like about post-processing of a frame, global transformations, checksum, etc. ... or even a part of audio information,
3) finally, the state can be directly used as a built in checksum: start encoding e.g. with L_BASE, but if there was a damage, decoder will most likely end in a different state (like 2^-23 false positive probability).
So just put "if((stat & mask) != 0) checksum_error()" at the end of decoder to turn the overhead into checksum (no need for additional hashing), which I believe is generally required: indicates not to use this damaged frame for prediction.
Exploiting the possibility of storing some information in the initial state, the overhead problem vanishes - allowing to use relatively short fixed length blocks, making sufficient a few kilobyte buffer at encoder.
dud...@gmail.com
https://www.ipo.gov.uk/p-ipsum/Case/ApplicationNumber/GB1502286.6
https://register.epo.org/ipfwretrieve?apn=US.201615041228.A&lng=en
I thought it is safe and nearly forgot about it, but accidentally checked today and in seems there is a huge problem on the US side: after non-final rejection, from this March there are new claims - mainly just rANS for Markov sources, and then "Notice of allowance" for these claims.
I have mentioned handling Markov sources at least in earlier last arxiv (1311.2540v2 checked), there are also James Bonfield earlier implementations - and his remarks, but only on the UK site ( https://www.ipo.gov.uk/p-ipsum/Document/ApplicationNumber/GB1502286.6/30e7bdd1-48d5-4b86-85c7-0f60092e7a2f/GB2538218-20170126-Third%20party%20observations.pdf ).
The US reviewer related only to other patents.
I wanted ANS to be free, patent-free, especially after the nightmare for arithmetic coding ( https://en.wikipedia.org/wiki/Arithmetic_coding#US_patents ).
I haven't got a dime from ANS, I cannot afford a patent lawyer.
I hope it is in the best interest of companies actually earning and planning to earn from it like Google to fight with such patenting attempts.
dud...@gmail.com
I hope it has essentially reduced the overhead – is its size still seen as an issue?
For any case, here are some my remarks (I could gladly discuss or elaborate on).
I see L_BASE is currently 2^17, IO_BASE is 2^8 (8 bit renormalization), what makes state in [2^17, 2^25 - 1].
However, I see that especially for storing 4 symbols, it uses shifts up to 30 bits (artifact of 16 bit state + 16 bit renormalization?).
In fact there is no problem with storing four of 4-bit symbols in the current setting (L_BASE=2^17). The initial state here can be chosen as:
“0 0000 001x xxxx xxxx xxxx xxxx”
The above initial zeros can be generally changed to 1, but it would come with a price in the actual entropy coding (state contains ~lg(state) bits of information) – so it is probably better to leave them as zeros. Hence, we can directly store 17 bits here (“x” positions).
To fit four 4-bit symbols here, one bit should indicate this case: e.g. first bit set to 1 means four symbols, fitting in the remaining 16 bits.
Else, e.g. the next two bits indicate the number of stored symbols (0-3).
This way in the < 4 symbol case, there remain unused bits (up to 14 for 0 stored symbols here).
It seems a waste not to exploit them – especially that for free they can be used as checksum: just set them to zero in encoder, and test if they are still zeros in decoder – otherwise e.g. mark this part to be somehow avoided in inter-prediction (replace it with some other prediction).
I wonder how error protection is currently handled in AV1?
This just exploiting the unused bits of the state could complement or maybe completely replace the current checksum system (n such bits give ~ 2^-n probability of false positive).
Of course there are also other ways to include information in the initial state up to reduction of overhead to practically zero – for example instead of starting encoding with state L_BASE, start with state 1. Then decoder just disables the renormalization at the end: decodes until state is 1.
And all the unused information can be always exploited as free checksum – which I believe is required in video codec for some robustness (like avoiding the nasty green artifacts from h.264).
Anyway, let me know if rANS overhead is still seen as an issue.
Ps. Additionally, as I have mentioned a few post ago, the hardware cost can be essentially reduced by going to much smaller multiplication (e.g. 4 x 16 bit) – I can also help with that (summer break).
dud...@gmail.com
While it is unknown if it will be in AV1, you want to make sure it won't be in h.266 and many other places ...
I have explicitly mentioned mixing ABS/ANS in the 2014 arxiv you cite there (page 23): "While maintaining the state space (I), we can freely change between different probability distributions, alphabets or even ABS/ANS variants. "
I have and can further help to make the best from it, but not in building patent minefield like for AC: https://en.wikipedia.org/wiki/Arithmetic_coding#US_patents
dud...@gmail.com
- "equation-free" basic description of ANS, the possibility of its use in image/video compression (discussed much earlier in maaany places, e.g. mentioned in my arxiv, my initial post of this thread, many places in encode.ru),
- general techniques with flags controlling symbol types, bitstream - exactly like in other video compressors, e.g. VP8, VP9, h.264, h.265, but without the binarization,
- the title suggests that the main innovation is switching between binary and size 16 alphabet and its control - switching between ABS/ANS variants is explicitly mentioned in my arxiv, e.g. boolean values for bitstream control is a completely standard approach used for decades.
... and there is at least one compressor (2015 Oodle LZNA: https://github.com/powzix/kraken/blob/master/lzna.cpp ) which switches between even more: 3 separately optimized ANS variants - binary, size 8 and size 16 alphabet, using most of techniques described in these claims.
Is there anything really new in these claims?
This patent application and general situation is completely ridiculous ...
Therefore, I would like to propose not wasting more time with it - please just remove specifying ANS in this patent, and let us forget about this situation - I can further help you with making the best of ANS, and in case of a formal collaboration I am still open for (which e.g. would allow me to build a team or e.g. just through working remotely and summer breaks for Google), in future bring you many new ideas indeed worth patenting.
dud...@gmail.com
https://register.epo.org/ipfwretrieve?apn=US.201615041228.A&lng=en
… approaching a lawyer’s paradise, where everybody has ANS patent, and nobody can safely use ANS.
It is not that I am completely against software patents, only the pathological obvious ones - with the only purpose to fight competition, create a legal minefield – usually from both sides.
Instead of further inflaming this pathological situation, please let us try to end this madness of ridiculous patents, make basic application of ANS legally unrestricted. Peace.
dud...@gmail.com
compressed size , compression ratio, compression speed, decompression speed
621704996 62.2 74.89 100.77 TurboANXN (nibble) o0 *NEW*
622002650 62.2 17.94 14.34 AOMedia AV1 nibble o0 *NEW*
+BWT:
194954146 19.5 88.84 100.37 TurboANXN (nibble) o0 *NEW*
196471059 19.6 22.57 18.58 AOMedia AV1 nibble o0 *NEW*
Where TurboANXN probably refers to LZNA-like symbol-wise adaptive rANS suggested here earlier.