is it normal that denseflipout produce a different uncertainty estimation compared to concrete dropout?

P.
.png?part=0.1&view=1)
Denseflipout instead gives me this result
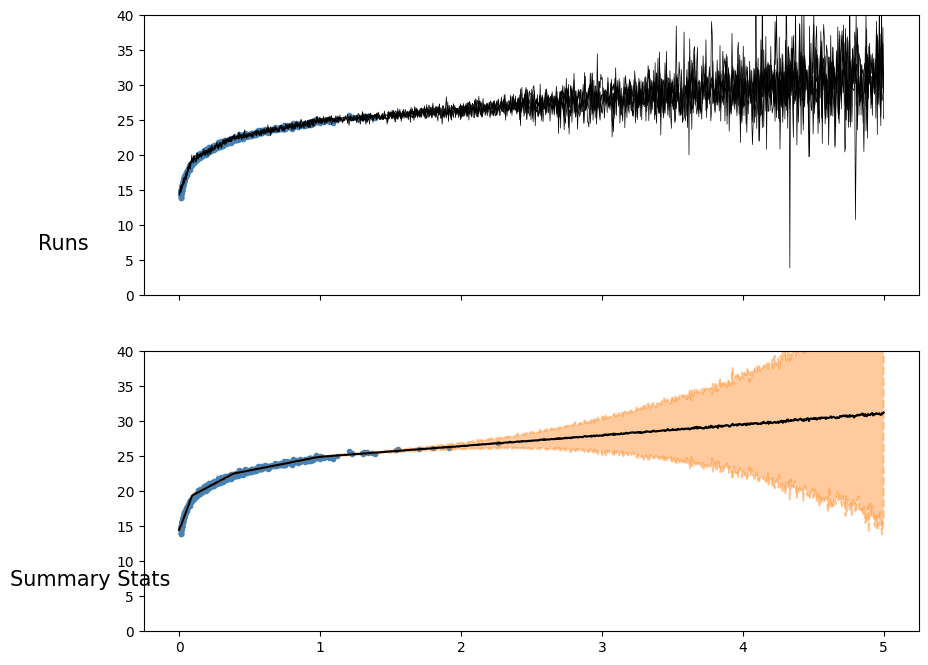
2)I have also noticed that bnns needs to be trained longer then traditional nns, like 40000 epochs, even after if the nll has dropped at 6000. is this normal?

Matias Valdenegro
Yes it should be different as Dropout and Flipout work in a completely different way, there is no requirement to have the same uncertainty, and even there is no true or correct uncertainty at all.
P.
Matias Valdenegro
Well this is directly the concept of epistemic uncertainty, also known as model uncertainty, the model structure, assumptions, training data, all contribute to the output uncertainty, this is completely expected. The uncertainty quantification method also contributes to this, I have some papers that shows these differences and comparisons:
https://arxiv.org/abs/2111.09808
https://arxiv.org/abs/2204.09308
Also do not forget that all current uncertainty quantification methods are approximations, MC-Dropout and Flipout produce a approximation to the posterior predictive distribution (which is intractable to compute), and different methods produce different approximations, I do not think there is something inherently better than other method, it all depends on the application.
Also there are ways to separate/disentangle data and model uncertainty, see the second paper I linked.

Josh Dillon
all the selected examples."
--
You received this message because you are subscribed to the Google Groups "TensorFlow Probability" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tfprobabilit...@tensorflow.org.
To view this discussion on the web visit https://groups.google.com/a/tensorflow.org/d/msgid/tfprobability/3224306.Sgy9Pd6rRy%40vsd-grey-wolf.