how to reduce spikes in training loss when using DenseFlipout layers
85 views
Skip to first unread message

P.
Dec 13, 2022, 12:23:18 AM12/13/22
to TensorFlow Probability
Hi everyone, I was trying to train a fully connected neural network through the method of variational inference with DenseFlipout layers but when the neural network seems to have reached convergence huge spikes appear in the training loss plot. On stackoverflow I was suggested to use gradient clipping ( i added
clipnorm=1.0 among the parameters of the SGD optimizer) but it doesn't seem to work.
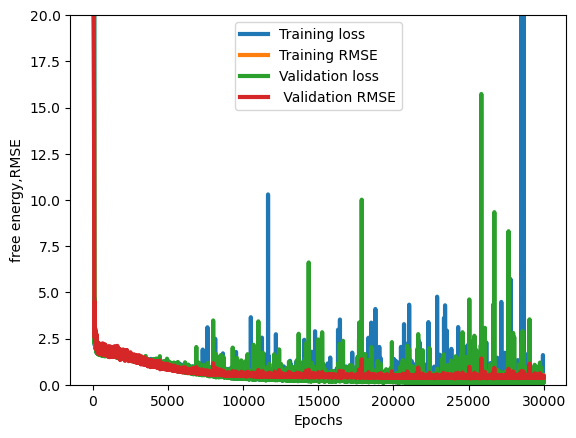
my model is quite simple altough slightly overparameterized. I tried lowering the number of neurons per layer but if i do it the neural network doesn't fit the data very well
def create_flipout_bnn_model(train_size):
def normal_sp(params):
return tfd.Normal(loc=params[:,0:1], scale=1e-3 + tf.math.softplus(0.05 * params[:,1:2]))
kernel_divergence_fn=lambda q, p, _: tfp.distributions.kl_divergence(q, p) / (train_size)
bias_divergence_fn=lambda q, p, _: tfp.distributions.kl_divergence(q, p) / (train_size)
inputs = Input(shape=(1,),name="input layer")
hidden = tfp.layers.DenseFlipout(20,
kernel_divergence_fn=kernel_divergence_fn,
activation="relu",name="DenseFlipout_layer_1")(inputs)
hidden = tfp.layers.DenseFlipout(20,
kernel_divergence_fn=kernel_divergence_fn,
activation="relu",name="DenseFlipout_layer_2")(hidden)
hidden = tfp.layers.DenseFlipout(20,
kernel_divergence_fn=kernel_divergence_fn,
activation="relu",name="DenseFlipout_layer_3")(hidden)
params = tfp.layers.DenseFlipout(2,
kernel_divergence_fn=kernel_divergence_fn,
name="DenseFlipout_layer_5")(hidden)
dist = tfp.layers.DistributionLambda(normal_sp,name = 'normal_sp')(params)
model = Model(inputs=inputs, outputs=dist)
return model
def normal_sp(params):
return tfd.Normal(loc=params[:,0:1], scale=1e-3 + tf.math.softplus(0.05 * params[:,1:2]))
kernel_divergence_fn=lambda q, p, _: tfp.distributions.kl_divergence(q, p) / (train_size)
bias_divergence_fn=lambda q, p, _: tfp.distributions.kl_divergence(q, p) / (train_size)
inputs = Input(shape=(1,),name="input layer")
hidden = tfp.layers.DenseFlipout(20,
kernel_divergence_fn=kernel_divergence_fn,
activation="relu",name="DenseFlipout_layer_1")(inputs)
hidden = tfp.layers.DenseFlipout(20,
kernel_divergence_fn=kernel_divergence_fn,
activation="relu",name="DenseFlipout_layer_2")(hidden)
hidden = tfp.layers.DenseFlipout(20,
kernel_divergence_fn=kernel_divergence_fn,
activation="relu",name="DenseFlipout_layer_3")(hidden)
params = tfp.layers.DenseFlipout(2,
kernel_divergence_fn=kernel_divergence_fn,
name="DenseFlipout_layer_5")(hidden)
dist = tfp.layers.DistributionLambda(normal_sp,name = 'normal_sp')(params)
model = Model(inputs=inputs, outputs=dist)
return model
have you guys faced a similar problem? what can i do to solve it? thanks

Guilherme Namen Pimenta
Dec 13, 2022, 6:47:28 AM12/13/22
to TensorFlow Probability, p.cate...@gmail.com
Use DenseVariational with a prior trainable distribution with a small deviation. But I spikes is not bad, it indicate that the model is not over-fitting as time goes. The problem is the "size".
Another problem is that your network is too deep, in this case you are given a random variable to a random distributions, this will increase the variation. In my models I tend to use only one variational
layer in the end.
Another problem is the activation function relu that do not have an upper bound, even using softplus for scale parameter it can increase a lot.
In the end you need understand your data. Is the mean positive or negative? Is the sd too high? Almost every data is not normal. Remember, you are using probabilities ideas in neural network model, not the inverse.
Reply all
Reply to author
Forward
0 new messages