16x8 quantization for RNNs
134 views
Skip to first unread message

Blaine Rister
Feb 27, 2023, 6:42:16 PM2/27/23
to TensorFlow Lite
Hi all,
I'm sitting on the MLPerf Tiny benchmark committee, which uses TFLite to develop benchmarks for various embedded ML accelerators. We are trying to develop a speech enhancement benchmark using LSTMs, and no one has been able to achieve satisfactory results using 8-bit quantized activations. (In fact, audio playback is usually 16 bits / sample, so it is going to be tough to get anything reasonable if the model's output is 8-bit.) TFLite supports 16x8 quantization experimentally, but we have never been able to get it to work for LSTMs, or any other kind of RNN for that matter. We made a Github ticket for this a few weeks back. https://github.com/tensorflow/tensorflow/issues/59626
I know 16x8 quantization is marked as experimental, but it is really essential for a number of audio applications, especially those involving RNNs, which are more sensitive to numerical precision than other kinds of models. Is expanded 16x8 support on the roadmap for TFLite? If not, is it something that would be feasible for community contributors? I think a number of startups would be interested in contributing to this if possible.
Regards,
Blaine Rister
I'm sitting on the MLPerf Tiny benchmark committee, which uses TFLite to develop benchmarks for various embedded ML accelerators. We are trying to develop a speech enhancement benchmark using LSTMs, and no one has been able to achieve satisfactory results using 8-bit quantized activations. (In fact, audio playback is usually 16 bits / sample, so it is going to be tough to get anything reasonable if the model's output is 8-bit.) TFLite supports 16x8 quantization experimentally, but we have never been able to get it to work for LSTMs, or any other kind of RNN for that matter. We made a Github ticket for this a few weeks back. https://github.com/tensorflow/tensorflow/issues/59626
I know 16x8 quantization is marked as experimental, but it is really essential for a number of audio applications, especially those involving RNNs, which are more sensitive to numerical precision than other kinds of models. Is expanded 16x8 support on the roadmap for TFLite? If not, is it something that would be feasible for community contributors? I think a number of startups would be interested in contributing to this if possible.
Regards,
Blaine Rister

Advait Jain
Feb 28, 2023, 1:31:44 AM2/28/23
to Blaine Rister, TensorFlow Lite
A speech enhancement benchmark in mlperf tiny sounds very good to me.
We have some support for inference LSTM months with 16x8 quantization in the TFLM repository: https://github.com/tensorflow/tflite-micro/tree/main/tensorflow/lite/micro/examples/mnist_lstm
This is early stage and somewhat experimental with no current plans to port to TfLite.
Please feel free to join the monthly SIG-micro meeting where the group has been discussing such topics and more.
I have mentioned to the community previously that we're open to collaborating on an LSTM-based audio example for the TFLM repo.
Regards,
Advait
--
You received this message because you are subscribed to the Google Groups "TensorFlow Lite" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tflite+un...@tensorflow.org.
To view this discussion on the web visit https://groups.google.com/a/tensorflow.org/d/msgid/tflite/950f2f1b-02d5-4071-8617-557a28b64b37n%40tensorflow.org.

Doyoung Gwak
Feb 28, 2023, 3:12:37 AM2/28/23
to TensorFlow Lite, Advait Jain, TensorFlow Lite, blaine...@femtosense.ai, YoungSeok Yoon
Hi all,
Thank you for raising the issue.
Although we don't currently have any concrete support plans, we've recently added an experimental 16x8 quantization feature for LSTM, and here's how you could try using it.
[What's Done and Known Limitations]
We had worked with LSTM for int16x8 quantization recently. It uses the MLIR quantizer at C++ level. And we made several unit tests and e2e test for the LSTM int16x8 MLIR quantization. 16x8 MLIR quantizer currently supports unidirectional_sequence_lstm, fully_connected, softmax Ops for 16x8, but because of the MLIR itself, we only support 32-bit bias (not 64-bit).
[How to try it at python level]
There is no python level interface to use the 16x8 MLIR quantizer. You can still try using it by changing your lite.py and run the converter by referring to this PR.
As Advait said above, we'd be open to collaborating on 16x8 quantization support and getting community contributions.
Thank you for raising the issue.
Although we don't currently have any concrete support plans, we've recently added an experimental 16x8 quantization feature for LSTM, and here's how you could try using it.
[What's Done and Known Limitations]
We had worked with LSTM for int16x8 quantization recently. It uses the MLIR quantizer at C++ level. And we made several unit tests and e2e test for the LSTM int16x8 MLIR quantization. 16x8 MLIR quantizer currently supports unidirectional_sequence_lstm, fully_connected, softmax Ops for 16x8, but because of the MLIR itself, we only support 32-bit bias (not 64-bit).
[How to try it at python level]
There is no python level interface to use the 16x8 MLIR quantizer. You can still try using it by changing your lite.py and run the converter by referring to this PR.
As Advait said above, we'd be open to collaborating on 16x8 quantization support and getting community contributions.
Best,
Doyoung
Blaine Rister
Feb 28, 2023, 6:13:43 PM2/28/23
to TensorFlow Lite, doyou...@google.com, advai...@google.com, TensorFlow Lite, Blaine Rister, youngs...@google.com
Hi Advait and Doyoung,
Thank you for the thorough responses! I am really excited to hear that 16x8 LSTMs are actively being developed. Looking through the code samples, is it correct to say that TFLM has a tool to convert an 8x8 flatbuffer to 16x8 mode? And that is how you can currently get 16x8 LSTMs? I found that Adavait's code was using this module: https://github.com/tensorflow/tflite-micro/blob/main/tensorflow/lite/micro/tools/requantize_flatbuffer.py
We would be very interested in contributing to this feature. Also, I would be happy to join the SIG-micro meetings. It seems like there is a lot of overlap with what we are trying to do in MLCommons, so it only makes sense to share.
Regards,
Blaine
Thank you for the thorough responses! I am really excited to hear that 16x8 LSTMs are actively being developed. Looking through the code samples, is it correct to say that TFLM has a tool to convert an 8x8 flatbuffer to 16x8 mode? And that is how you can currently get 16x8 LSTMs? I found that Adavait's code was using this module: https://github.com/tensorflow/tflite-micro/blob/main/tensorflow/lite/micro/tools/requantize_flatbuffer.py
We would be very interested in contributing to this feature. Also, I would be happy to join the SIG-micro meetings. It seems like there is a lot of overlap with what we are trying to do in MLCommons, so it only makes sense to share.
Regards,
Blaine
Blaine Rister
Mar 28, 2023, 8:35:31 PM3/28/23
to TensorFlow Lite, Blaine Rister, doyou...@google.com, advai...@google.com, TensorFlow Lite, youngs...@google.com
Hi all,
I am very happy to report that I was able to compile 16x8 LSTMs using Doyoung's PR, provided that I set `unroll=True` in Keras. I also verified the accuracy of the resulting model on my own IMDB test program.
This is a really important feature for a number of people in the embedded audio community. Is there any hope of enabling the 16x8 MLIR quantizer in mainstream TF? Even if it was just an experimental flag, that would be a very useful thing to give customers and benchmark submitters. We would be happy to help contribute to the feature if at all possible.
Regards,
Blaine
I am very happy to report that I was able to compile 16x8 LSTMs using Doyoung's PR, provided that I set `unroll=True` in Keras. I also verified the accuracy of the resulting model on my own IMDB test program.
This is a really important feature for a number of people in the embedded audio community. Is there any hope of enabling the 16x8 MLIR quantizer in mainstream TF? Even if it was just an experimental flag, that would be a very useful thing to give customers and benchmark submitters. We would be happy to help contribute to the feature if at all possible.
Regards,
Blaine
Blaine Rister
Apr 7, 2023, 7:42:22 PM4/7/23
to TensorFlow Lite, Blaine Rister, doyou...@google.com, advai...@google.com, TensorFlow Lite, youngs...@google.com, Debayan Ghosh
Hi all,
I just wanted to share some experiments from our team using the above PR.
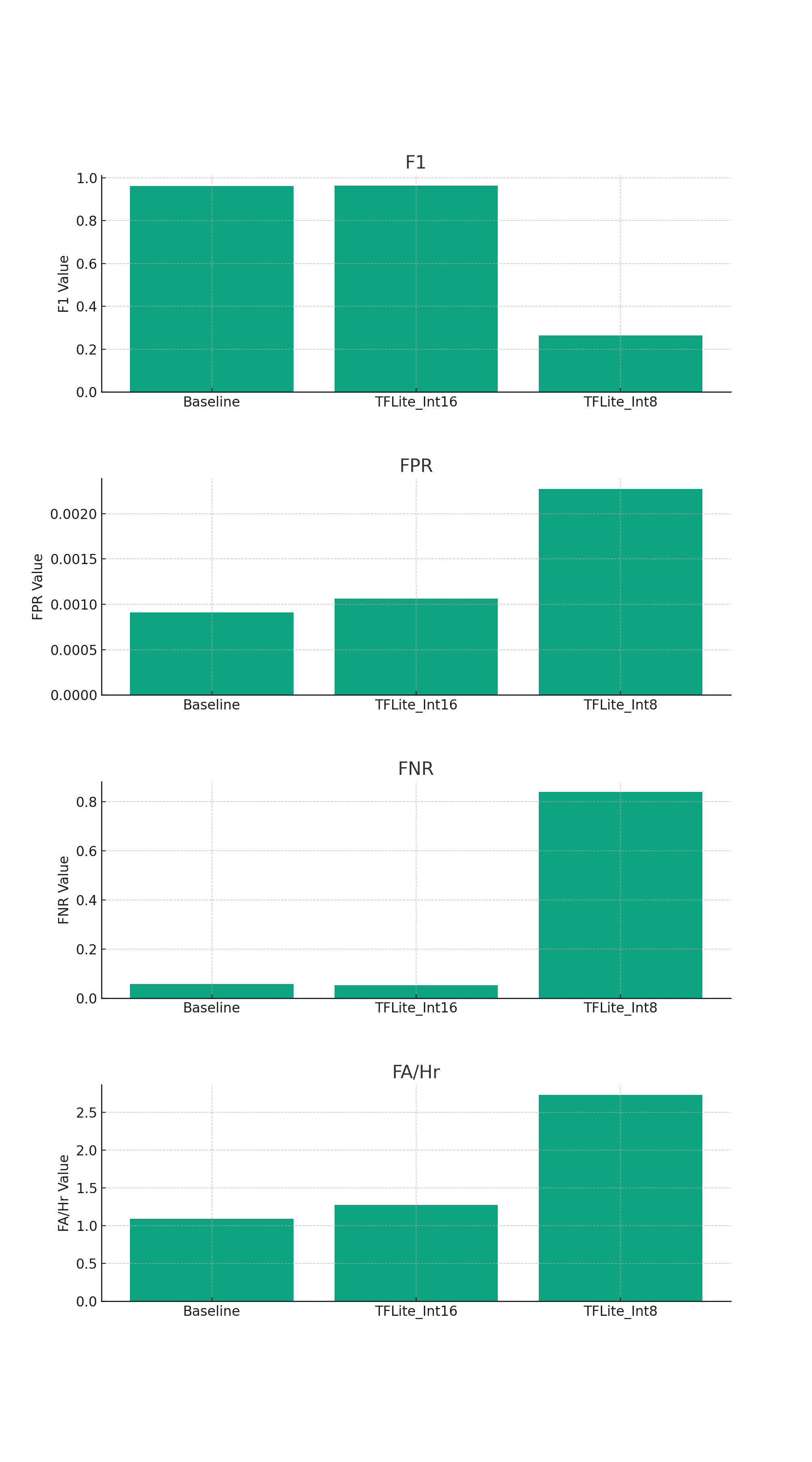
This is for a keyword spotting model based on LSTMs. The "baseline" is the original Keras model, compared to TFLite integer-quantized models with 8x8 and 16x8 quantization. Both TFLite models used `unroll=True` in keras.layers.RNN, which decomposes the LSTM into primitive ops rather than relying on the built-in TFLite LSTM ops. For this task, decomposed LSTMs can recover almost all the performance of the original floating point model, provided that we use 16x8 quantization. On the other hand, 8x8 quantization results in a significant accuracy degradation. In my mind, this is very strong evidence for the usefulness of 16x8 mode.
Terminology: F1 is the usual classification accuracy metric. FPR = "false positive rate", FNR = "false negative rate", FA/hr = "false acceptance / hour", a metric used for keyword spotting.
Regards,
Blaine
I just wanted to share some experiments from our team using the above PR.
This is for a keyword spotting model based on LSTMs. The "baseline" is the original Keras model, compared to TFLite integer-quantized models with 8x8 and 16x8 quantization. Both TFLite models used `unroll=True` in keras.layers.RNN, which decomposes the LSTM into primitive ops rather than relying on the built-in TFLite LSTM ops. For this task, decomposed LSTMs can recover almost all the performance of the original floating point model, provided that we use 16x8 quantization. On the other hand, 8x8 quantization results in a significant accuracy degradation. In my mind, this is very strong evidence for the usefulness of 16x8 mode.
Terminology: F1 is the usual classification accuracy metric. FPR = "false positive rate", FNR = "false negative rate", FA/hr = "false acceptance / hour", a metric used for keyword spotting.
Regards,
Blaine
{kind=link}
Reply all
Reply to author
Forward
0 new messages