[RFC] Fully support of Dynamic Shape in XLA with MLIR

Kai Zhu
As we all know, XLA works in a "static shape" approach, with a XlaCompilationCache to squeeze the optimizaton potentials. This brings problems in some scenarios:
(1) when the shapes do varies within a huge range. One typical example is when there are many "Unique" alike ops in the users' computation graph. Another example is the Transformer inference workload in which the (encoder length)/(decoder steps)/(batch size) are all changing.
(2) This dynamic shape problem sometimes can easily be solved via manual padding or manual clustering(move those dynamic shape operations out of the cluster to be compiled), but usually users are not familiar with XLA and don't know how to deal with it;
An existing solution is the "Dynamic Padder" [https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/xla/service/dynamic_padder.h], which can partially solve the problems, however in a restricted way.
The basic idea we are going to discuss in this RFC is to provide a "Dynamic Shape Mode" in the XLA flow to provide fully dynamic shape support for the complete compilation flow(including TF2HLO, HLO passes, codegen and kernels execution) when the ranges of the shapes vary a lot and the cost of JIT re-compilation is not affordable. Both CPU and GPU backend is taken into consideration.
For sure this "Dynamic Shape Mode" will lose some of the optimization potentials, while it at least keep the profit of op fusion codegen (including kLoop/kInput in XLA), i.e. the reduction of kernel launch /memory access /operation launch overhead. Also the "Dynamic Shape Mode" is only a supplement of the current static shape mode as a last resort rather than a replacement.
The "Dynamic Shape Mode" requires changes in many aspects regarding to current XLA design & implementation. And MLIR provides an opportunity to make things easier. However, mlir_compiler in XLA code repo currently is not complete enough even for the legacy static shape work flow. So, in order to support "Dynamic Shape Mode" we also need some other features/works to be supported which in our understanding should be in the roadmap of MLIR but may not be directly related with "Dynamic Shape" at all. All the works needed will be briefly listed here for an overall discussion. We may open separate RFCs for such features when necessary.
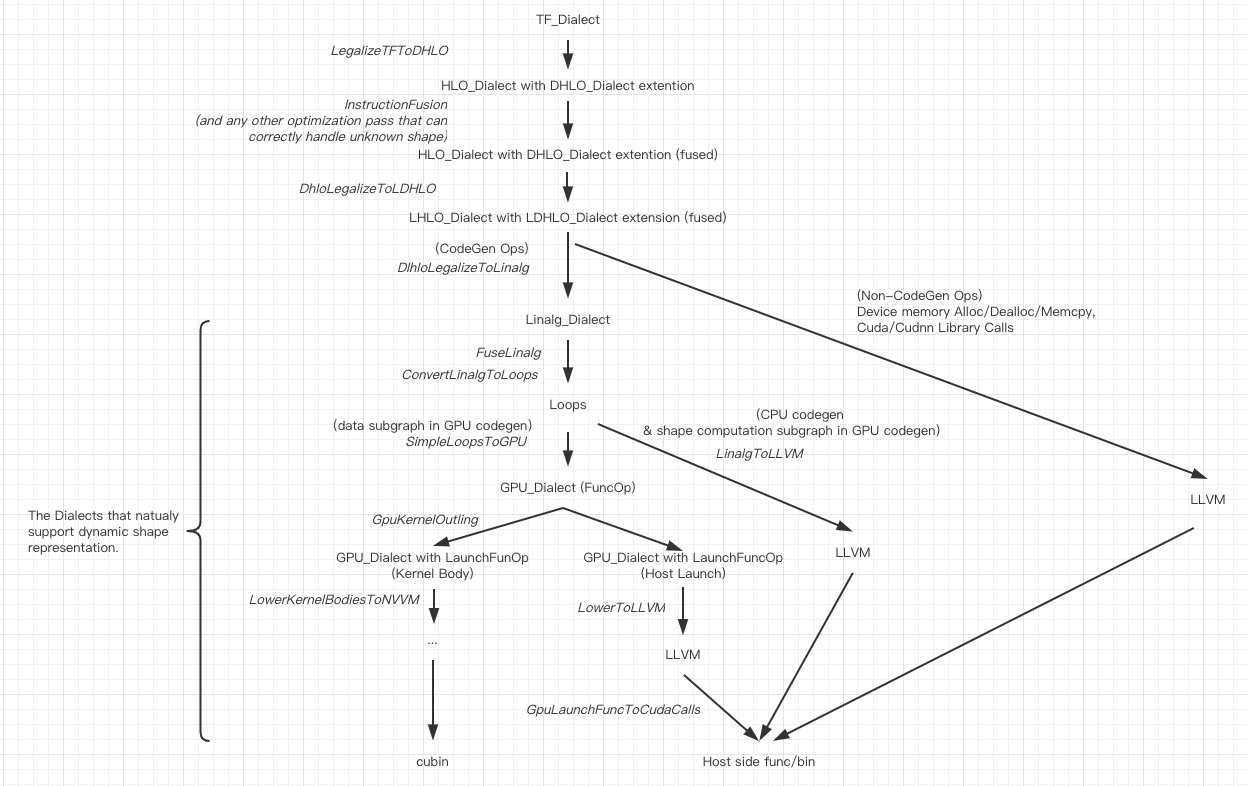
Briefly, the Ops that face the "dynamic shape issue" can be seperated into two categories:
- The output shape can be easily infered from the value of input tensors, and the calculation of the output shape is light enough. There are lots of such examples, like Reshape, Slice, Transpose.
- The output shape can only be known after the "real" calculation. One of the most common seen examples is the "Unique" Op. And just for this reason, XLA has not supported Unique like Ops yet.
Category 1 on CPU/GPU device and Category 2 on CPU device are commonly seen in deep learning workloads. The requirement Category 2 on GPU device is very rare while the solution is slightly more complicated. We still take this into consideration but the priority will be lower. The discussion on such case will be on Chapter 9.
1, An extension of HLO/LHLO_Dialect
An extension of HLO_Dialect/LHLO_Dialect, named DHLO_Dialect/LDHLO_Dialect here (D means dynamic here), is needed to fully support dynamic shape representation. There is a separate thread [https://groups.google.com/a/tensorflow.org/forum/#!msg/mlir/pbWk9a-t3Xc/kMeA-ijSBAAJ] discussing why current HLO/LHLO_Dialect can not fully support dynamic shape representation. A minimal typical pattern is provided here to help explain, taking SliceOp as an example:
func @main(%arg0: tensor<4x8xf32>, %arg1: tensor<2xi64>, %arg2: tensor<?x?xf32>, %arg3: tensor<?x?xf32>) -> tensor<?x?xi32> { %starts = "tf.Const"() {value = dense<[0, 0]> : tensor<2xi64>} : () -> (tensor<2xi64>) // "shape" calculation, the "size" input of the slice may come from some subgraph %0 = "tf.Add"(%arg1, %arg1) : (tensor<2xi64>, tensor<2xi64>) -> (tensor<2xi64) // "data" calculation %1 = "tf.Slice"(%arg0, %starts, %0) : (tensor<2x4xf32>, tensor<2xi64>, tensor<2xi64>) -> tensor<?x?xf32> %2 = "tf.Add"(%1, %arg2) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) %3 = "tf.MatMul(%2, %arg3) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) return %3 : tensor<?x?xi32> }
In static shape mode, the subgraph that calculating %0 must be constant folded, and %arg1 is required to be compile time constant after BackwardConstAnalysis.
To fully support dynamic shape representation, we have to reserve the subgraph that calculating shapes in HLO layer. So we need a DHLO_SliceOp as an extension, since HLO_SliceOp/HLO_DynamicSliceOp must have "size" as attributes which are compile time constant, while in DHLO_SliceOp "size" is defined as the output tensor of a subgraph. Note that DHLO_Dialect is only an extension and not to replace HLO_Dialect even in Dynamic Shape Mode, since for many Ops like elementwise Add/Mul etc. their definition in HLO_Dialect is representable enough to support dynamic shape and we should leave them as they are. The DHLO extention is only needed for TF Ops that require some input as compile time constant, like Reshape/Pad/Slice etc.
The lowered HLO/DHLO_Dialect is something like this:
func @main(%arg0: tensor<4x8xf32>, %arg1: tensor<2xi64>, %arg2: tensor<?x?xf32>, %arg3: tensor<?x?xf32>) -> tensor<?x?xi32> { %starts = "xla_hlo.const"() {value = dense<[0, 0]> : tensor<2xi64>} : () -> (tensor<2xi64>) // "shape" calculation, the "size" input of the slice may come from some subgraph %0 = "xla_hlo.add"(%arg1, %arg1) : (tensor<2xi64>, tensor<2xi64>) -> (tensor<2xi64) // "data" calculation %1 = "xla_dhlo.slice"(%arg0, %starts, /*size*/%0) : (tensor<2x4xf32>, tensor<2xi64>, tensor<2xi64>) -> tensor<?x?xf32> %2 = "xla_hlo.add"(%1, %arg2) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) %3 = "xla_hlo.matmul(%2, %arg3) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) return %3 : tensor<?x?xi32> }
Two major differences:
1, the subgraph calculating shapes will be kept, rather than being constant folded during compile time.
2, some xla_dhlo Ops (xla_dhlo.slice in this example) is needed to fully represent dynamic shape.
Note that here we choose to add a new dialect to extend HLO/LHLO. Another possible solution is to add some new ops to the original dialect or use an unified representation for both static shape mode and dynamic shape mode. These options can be further discussed. One reason we prefer the former one is that XLA_HLO/XLA_LHLO dialect is served as a bridge between MLIR and XLA, thus it would be better if their ops definition can be as close as possible to simplify the translation between them.
2, InstructionFusion Pass
An InstructionFusion Pass is needed for kLoop/kInput fusion. Its functionaility is the same as in current XLA, but just turns out to be a MLIR pass. In addition, it has to support xla_dhlo Ops together with xla_hlo Ops, which can be fused in a same Fusion Op.
Pls let us know if there are any ongoing work similar to this pass, or if you have any other plans in the roadmap. For example in our understanding, the fusion pass in Linalg layer is not to replace the fusion pass in HLO layer. Please point out if our understanding is not correct.
3, LegalizeDHLOtoLDHLO Pass
In the current static shape XLA flow, a BufferAssignment pass will analyze the liveness according to the known shape/buffer sizes and then put each optimized temporary buffer into one piece of TempBuffer. In dynamic shape flow, we prefer to abondon the static buffer optimization. Instead, to allocate/deallocate right before/after each kernel execution is more likely to make sense. This is similar as the executor behavior in TensorFlow.
It is worth noting that the shape inference now should be done in the runtime instead of the compile-time. To support this, we should emit(codegen) shape inference code as well. Similar to TF, we assume that each op has a registered shape inference function. For the fusion op, we also fuse the shape inference function of each fused op to generate a fused shape inference function.
The representation in LHLO layer is perfect to handle this, althought there are some more work to do to finish the LegalizeDHLOtoLDHLO Pass. After the Pass, the above pattern should be something like this:
func @main(%arg0: memref<4x8xf32>, %arg1: memref<2xi64>, %arg2: memref<?x?xf32>, %arg3: memref<?x?xf32>) -> memref<?x?xi32> { %starts = "xla_hlo.const"() {value = dense<[0, 0]> : memref<2xi64>} : () -> (memref<2xi64>) // "shape" calculation, the "size" input of the slice may come from some subgraph %0 = alloc() {temp = true,custom_allocator = bfc_cpu} : memref<2xf32> "xla_lhlo.add"(%arg1, %arg1, %0) : (memref<2xi64>, memref<2xi64>, memref<2xi64) -> () // "data" calculation %4 = dim %arg2, 0 : memref<?x?xf32> %5 = dim %arg2, 1 : memref<?x?xf32> %2 = alloc(%4, %5) {temp = true, custom_allocator = bfc_gpu} : memref<?x?xf32> "xla_lhlo.fusion"(%arg0, %starts, /*size*/%0, %arg2, %2) ( { "xla_ldhlo.slice"(%arg0, %starts, /*size*/%0, %1) : (tensor<2x4xf32>, tensor<2xi64>, tensor<2xi64>, tensor<?x?xf32>) -> () "xla_lhlo.add"(%1, %arg2, %2) : (tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32) -> () } ) : (memref<2x4xf32>, memref<2xi64>, memref<2xi64>, memref<?x?xf32>, memref<?x?xf32>) -> () dealloc %0 : memref<2xf32> "xla_lhlo.matmul(%2, %arg3, %3) : (memref<?x?xf32>, memref<?x?xf32>, memref<?x?xf32) -> () dealloc %2 : memref<?x?xf32> return %3 : memref<?x?xi32> }
4, Custom alloc/dealloc lowering
Lowering of Alloc/Dealloc Ops with custom buffer allocator is to be supported. In order to work with TensorFlow and to minimize the overhead of alloc/dealloc, BFC host/device allocator should be supported.
We noticed that some discussion on this is ongoing months ago:
https://groups.google.com/a/tensorflow.org/forum/?nomobile=true#!topic/mlir/MO0CNmMOa0M
We would like to know the current status.
5, Device representation in HLO/LHLO Dialect
HLO/LHLO Dialect, (together with their extension DHLO/LDHLO) should be able to represent device placement information.
In the current static shaped XLA,there's no such issue since the placement of XlaLaunch Op onto the same device is good enough. However, considering the Dynamic Shape CodeGen for GPU device, for performance purpose the subgraph calculating shapes should be lowered to host codes, while the subgraph manipulating tensors should be lowered to GPU. This rule has been verified in TensorFlow executor and planned to be used here. By this way, we would need the IR in HLO/LHLO layer to be able to represent the device placement semantics.
Any ongoing discussion on this?
6, custom MemRefType lowering on accelerator (e.g. GPU)
After the LegalizeDHLOtoLDHLO pass,all ops are assumed to operate on MemRefType instead of TensorType. MemRefType is an type in standard dialect which is used to model memory assess and is adopted by many existing dialects (e.g. linalg, affine and loops). In the current lowering pipeline, MemRefType is eventually lowered to the MemRefDescriptor structure when we lower std dialect to llvm dialect.
Following is a simple example where we have a function with two arguments of MemRefType.
func @test(%arg0 : memref<?x?xf32>, %arg1: memref<?x?xf32>) { // do something here return }
The lowered version of the above function is shown as below:
llvm.func @test(%arg0: !llvm<"{ float*, float*, i64, [2 x i64], [2 x i64] }*">, %arg1: !llvm<"{ float*, float*, i64, [2 x i64], [2 x i64] }*">) { %0 = llvm.load %arg0 : !llvm<"{ float*, float*, i64, [2 x i64], [2 x i64] }*"> %1 = llvm.load %arg1 : !llvm<"{ float*, float*, i64, [2 x i64], [2 x i64] }*"> // do something here llvm.return }
Note that the type of the argument of the function is changed to MemRefDescriptor pointer type. This is because current MLIR implementation promotes the LLVM struct representation of all MemRef descriptors to stack and uses pointers to struct to avoid the complexity of the platform-specific C/C++ ABI lowering related to struct argument passing (as shown here https://github.com/llvm/llvm-project/blob/master/mlir/include/mlir/Conversion/StandardToLLVM/ConvertStandardToLLVM.h#L68).
Under this assumption, it is the responsibility of the caller to allocate and fill MemRefDescriptor and then pass the pointer to the callee. The above design choice is ok on the host platform while it may degrade the performance on accelerartor (e.g. GPU) since additional memcpy of the MemRefDescriptor struct from host to device is required (e.g. in the above example, copy structs that %arg0 and %arg1 point to) before we can launch the kernel func on the device.
To eliminate the additional memcpy, we should have a change to customize the codegen of the prototype of kernel function and update the caller side accordingly (e.g. flatten each fields of MemRefDescriptor struct and passes them by scalar value). Note that scalar argument of kernel func does not need explicitly copy since they can be collapsed into the kernel launch itself.
llvm.func @test(%arg0: !llvm<"float*">, %arg1: !llvm<"float*">, %arg2: llvm.i64, %arg3: llvm.i64, %arg4: llvm.i64, %arg5: llvm.i64, %arg6: !llvm<"float*">, %arg7: !llvm<"float*">, %arg8: llvm.i64, %arg9: llvm.i64, %arg10: llvm.i64, %arg11: llvm.i64) { // reconstruct the structs // do something here llvm.return }
Please also be aware that, this change doesn't relate with "Dynamic Shape". In our understanding it is a problem that needs our attention for all the accelerator codegen (e.g. GPU kernel).
7, extension on GPU_Dialect to support intrinsics like Atomic instructions
It would be very helpful to have atomic support in gpu dialect especially when we codegen for a general (fused) reduce op. To the best of our knowledge, we are still in lack of such functionality currently, thus we would like to contribute this or other simliar feature if necessary.
Again, if somebody is already doing this, please let us know.
8, Support of LHLO lowering to library calls
The current XLA GPU backend only does codegen for the Kernels. "GpuExecutable" together with a number of "Thunks" manages to launch these kernels and third party library calls in a planned way, which is more like a mini-executor inside the XlaRunOp. In order to support Dynamic Shape in the current XLA codes, we would need a new executor, with the support of dynamic BufferAssignment and the ability to deal with the runtime shape inference and "subgraphs that calculating shapes" on host codegen. This will be quite different with the executor in the current XLA. Considering that in MLIR, with the work of GpuKernelOutlining pass/GpuLaunchFuncToCudaCalls pass, we believe that to CodeGen an executor (including host launch codes, library calls, buffer allocation/deallocation, cuda memcpy etc) should be more promising than to develop a new executor with Thunks.
In order to do this, besides the topics in 4/5, the support of lowering LHLO Ops directly to library calls such as cuBlas/cuDNN/MKL would be necessary.
The lowering should be some simple pattern matching, like this:
But the main effort may exist in building a wrapper on cuBlas/cuDNN that can handle different library versions. StreamExecutor of TensorFlow might be a good candidate but some more study is still necessary.
"xla_lhlo.matmul"(%2, %arg3, %3) : (memref<?x?xf32>, memref<?x?xf32>, memref<?x?xf32) -> ()
lowered to:
call %cuBLASGEMM(%2, %arg3, %3) : (memref<?x?xf32>, memref<?x?xf32>, memref<?x?xf32) -> ()
We have noticed that this should be considered on the roadmap, but is not aware of any existing work or ongoing discussion yet. Please let us know if someone is already working on this.
9, "Unique" like Ops on GPU device
As discussed in chapter 6, for a MemRef on the GPU device, we prefer the data contents on device memory and the shape dimension sizes on host memory. This brings a problem that, for "Unique" like Ops (e.g. https://www.tensorflow.org/api_docs/python/tf/unique), the output shape can only be get with the GPU kernel (supposing we do have a reason and a scenario to calculate such Ops on GPU). Thus we will need some mechanism to add the output shape dimension sizes into the list of the kernel's parameters. We may also need a preallocated temp buffer since the size of the output buffer is unknown before the kernel launch.
"xla_ldhlo.unique"(%0, %1, %2) : (/*input*/memref<?xf32>, /*output*/memref<?xf32>, /*ids*/memref<?xf32) -> ()
will be lowered to:
%0 = dim %input_data, 0 : memref<?x?xf32> %output_idx = alloc(%0) {temp = true, custom_allocator = bfc_gpu} : memref<?xf32> %temp_buffer = alloc(%0) {temp = true, custom_allocator = bfc_gpu} : memref<?xf32> %output_data_shape = alloc() {temp = true, custom_allocator = bfc_gpu} : memref<1xi64> "gpu.launch_func"(%cst, %cst, %cst, // Grid sizes. %cst, %cst, %cst, // Block sizes. %input_data, %output_idx, %temp_buffer, %output_data_shape) { kernel_module = @kernels, // Module containing the kernel. kernel = "unique_impl_kernel" } // Kernel function. : (index, index, index, index, index, index, memref<?xf32>, memref<?xf32>, memref<?xf32>, memref<1xi64>) -> () %output_data_shape = alloc() {temp = true, custom_allocator = bfc_cpu} : memref<1xi64> call %mcuMemcpyDeviceToHost(%output_data_shape, %output_data_shape_host) %output_data_dim0 = load %output_data_shape_host[0] : memref<1xf32> %output_data = alloc(output_data_dim0) {temp = true, custom_allocator = bfc_gpu} : memref<?xf32> "gpu.launch_func"(%cst, %cst, %cst, // Grid sizes. %cst, %cst, %cst, // Block sizes. %temp_buffer, %output_data) { kernel_module = @kernels, // Module containing the kernel. kernel = "unique_memcpy_kernel" } // copy from temp_buffer to output_data // a kernel is be more general than mcuMemcpy() // when stride has to be considered for multidim shapes : (index, index, index, index, index, index, memref<?xf32>, memref<?xf32>) -> ()

Jun Yang
--
You received this message because you are subscribed to the Google Groups "MLIR" group.
To unsubscribe from this group and stop receiving emails from it, send an email to mlir+uns...@tensorflow.org.
To view this discussion on the web visit https://groups.google.com/a/tensorflow.org/d/msgid/mlir/15ece19e-8c22-4eee-861a-51e829542d77%40tensorflow.org.

Mehdi AMINI
As we all know, XLA works in a "static shape" approach, with a XlaCompilationCache to squeeze the optimizaton potentials. This brings problems in some scenarios:
(1) when the shapes do varies within a huge range. One typical example is when there are many "Unique" alike ops in the users' computation graph. Another example is the Transformer inference workload in which the (encoder length)/(decoder steps)/(batch size) are all changing.
(2) This dynamic shape problem sometimes can easily be solved via manual padding or manual clustering(move those dynamic shape operations out of the cluster to be compiled), but usually users are not familiar with XLA and don't know how to deal with it;
An existing solution is the "Dynamic Padder" [https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/xla/service/dynamic_padder.h], which can partially solve the problems, however in a restricted way.
The basic idea we are going to discuss in this RFC is to provide a "Dynamic Shape Mode" in the XLA flow to provide fully dynamic shape support for the complete compilation flow(including TF2HLO, HLO passes, codegen and kernels execution) when the ranges of the shapes vary a lot and the cost of JIT re-compilation is not affordable. Both CPU and GPU backend is taken into consideration.
For sure this "Dynamic Shape Mode" will lose some of the optimization potentials, while it at least keep the profit of op fusion codegen (including kLoop/kInput in XLA), i.e. the reduction of kernel launch /memory access /operation launch overhead. Also the "Dynamic Shape Mode" is only a supplement of the current static shape mode as a last resort rather than a replacement.
The "Dynamic Shape Mode" requires changes in many aspects regarding to current XLA design & implementation. And MLIR provides an opportunity to make things easier. However, mlir_compiler in XLA code repo currently is not complete enough even for the legacy static shape work flow. So, in order to support "Dynamic Shape Mode" we also need some other features/works to be supported which in our understanding should be in the roadmap of MLIR but may not be directly related with "Dynamic Shape" at all. All the works needed will be briefly listed here for an overall discussion. We may open separate RFCs for such features when necessary.
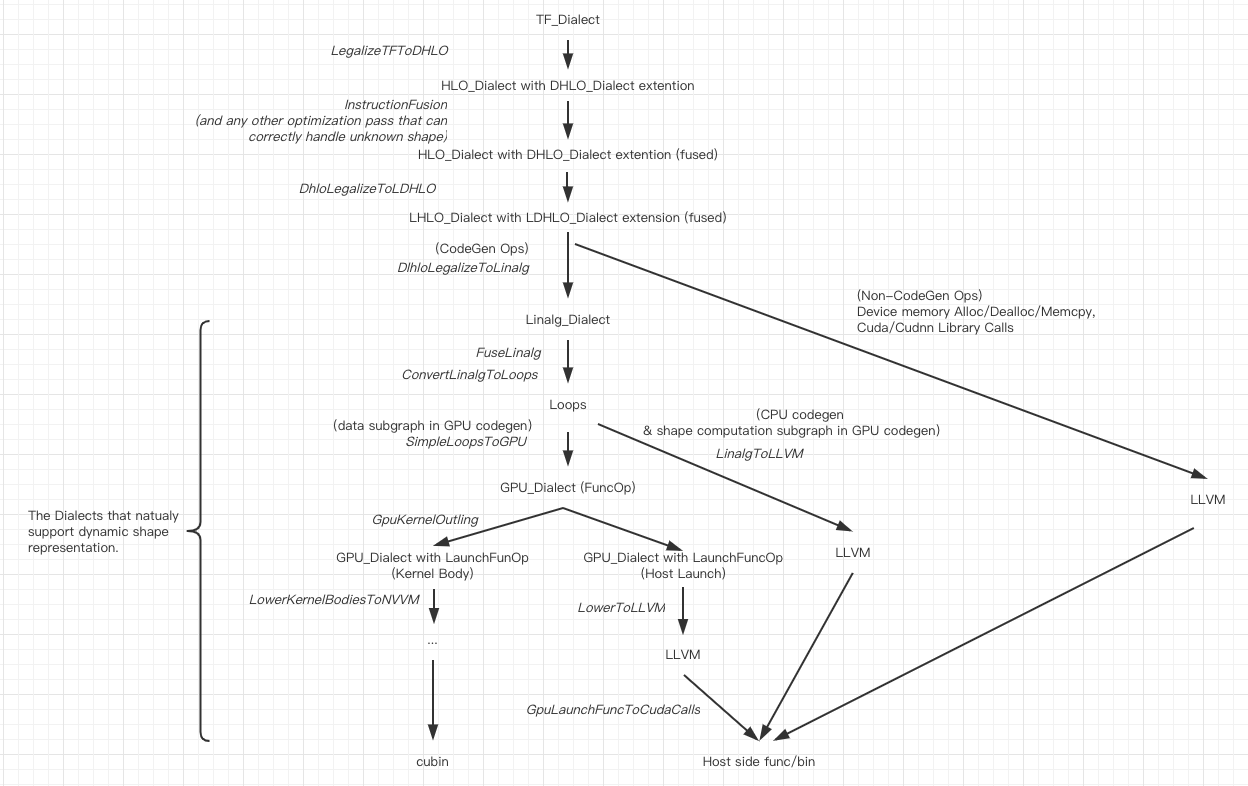
Briefly, the Ops that face the "dynamic shape issue" can be seperated into two categories:
- The output shape can be easily infered from the value of input tensors, and the calculation of the output shape is light enough. There are lots of such examples, like Reshape, Slice, Transpose.
- The output shape can only be known after the "real" calculation. One of the most common seen examples is the "Unique" Op. And just for this reason, XLA has not supported Unique like Ops yet.
Category 1 on CPU/GPU device and Category 2 on CPU device are commonly seen in deep learning workloads. The requirement Category 2 on GPU device is very rare while the solution is slightly more complicated. We still take this into consideration but the priority will be lower. The discussion on such case will be on Chapter 9.
1, An extension of HLO/LHLO_Dialect
An extension of HLO_Dialect/LHLO_Dialect, named DHLO_Dialect/LDHLO_Dialect here (D means dynamic here), is needed to fully support dynamic shape representation. There is a separate thread [https://groups.google.com/a/tensorflow.org/forum/#!msg/mlir/pbWk9a-t3Xc/kMeA-ijSBAAJ] discussing why current HLO/LHLO_Dialect can not fully support dynamic shape representation. A minimal typical pattern is provided here to help explain, taking SliceOp as an example:
func @main(%arg0: tensor<4x8xf32>, %arg1: tensor<2xi64>, %arg2: tensor<?x?xf32>, %arg3: tensor<?x?xf32>) -> tensor<?x?xi32> { %starts = "tf.Const"() {value = dense<[0, 0]> : tensor<2xi64>} : () -> (tensor<2xi64>) // "shape" calculation, the "size" input of the slice may come from some subgraph %0 = "tf.Add"(%arg1, %arg1) : (tensor<2xi64>, tensor<2xi64>) -> (tensor<2xi64) // "data" calculation %1 = "tf.Slice"(%arg0, %starts, %0) : (tensor<2x4xf32>, tensor<2xi64>, tensor<2xi64>) -> tensor<?x?xf32> %2 = "tf.Add"(%1, %arg2) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) %3 = "tf.MatMul(%2, %arg3) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) return %3 : tensor<?x?xi32> }
In static shape mode, the subgraph that calculating %0 must be constant folded, and %arg1 is required to be compile time constant after BackwardConstAnalysis.
To fully support dynamic shape representation, we have to reserve the subgraph that calculating shapes in HLO layer. So we need a DHLO_SliceOp as an extension, since HLO_SliceOp/HLO_DynamicSliceOp must have "size" as attributes which are compile time constant, while in DHLO_SliceOp "size" is defined as the output tensor of a subgraph. Note that DHLO_Dialect is only an extension and not to replace HLO_Dialect even in Dynamic Shape Mode, since for many Ops like elementwise Add/Mul etc. their definition in HLO_Dialect is representable enough to support dynamic shape and we should leave them as they are. The DHLO extention is only needed for TF Ops that require some input as compile time constant, like Reshape/Pad/Slice etc.
The lowered HLO/DHLO_Dialect is something like this:
func @main(%arg0: tensor<4x8xf32>, %arg1: tensor<2xi64>, %arg2: tensor<?x?xf32>, %arg3: tensor<?x?xf32>) -> tensor<?x?xi32> { %starts = "xla_hlo.const"() {value = dense<[0, 0]> : tensor<2xi64>} : () -> (tensor<2xi64>) // "shape" calculation, the "size" input of the slice may come from some subgraph %0 = "xla_hlo.add"(%arg1, %arg1) : (tensor<2xi64>, tensor<2xi64>) -> (tensor<2xi64) // "data" calculation %1 = "xla_dhlo.slice"(%arg0, %starts, /*size*/%0) : (tensor<2x4xf32>, tensor<2xi64>, tensor<2xi64>) -> tensor<?x?xf32> %2 = "xla_hlo.add"(%1, %arg2) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) %3 = "xla_hlo.matmul(%2, %arg3) : (tensor<?x?xf32>, tensor<?x?xf32>) -> (tensor<?x?xf32) return %3 : tensor<?x?xi32> }
Two major differences:
1, the subgraph calculating shapes will be kept, rather than being constant folded during compile time.
2, some xla_dhlo Ops (xla_dhlo.slice in this example) is needed to fully represent dynamic shape.
Note that here we choose to add a new dialect to extend HLO/LHLO. Another possible solution is to add some new ops to the original dialect or use an unified representation for both static shape mode and dynamic shape mode. These options can be further discussed. One reason we prefer the former one is that XLA_HLO/XLA_LHLO dialect is served as a bridge between MLIR and XLA, thus it would be better if their ops definition can be as close as possible to simplify the translation between them.
2, InstructionFusion Pass
An InstructionFusion Pass is needed for kLoop/kInput fusion. Its functionaility is the same as in current XLA, but just turns out to be a MLIR pass. In addition, it has to support xla_dhlo Ops together with xla_hlo Ops, which can be fused in a same Fusion Op.
Pls let us know if there are any ongoing work similar to this pass, or if you have any other plans in the roadmap.
For example in our understanding, the fusion pass in Linalg layer is not to replace the fusion pass in HLO layer. Please point out if our understanding is not correct.
3, LegalizeDHLOtoLDHLO Pass
In the current static shape XLA flow, a BufferAssignment pass will analyze the liveness according to the known shape/buffer sizes and then put each optimized temporary buffer into one piece of TempBuffer. In dynamic shape flow, we prefer to abondon the static buffer optimization. Instead, to allocate/deallocate right before/after each kernel execution is more likely to make sense. This is similar as the executor behavior in TensorFlow.
It is worth noting that the shape inference now should be done in the runtime instead of the compile-time. To support this, we should emit(codegen) shape inference code as well. Similar to TF, we assume that each op has a registered shape inference function. For the fusion op, we also fuse the shape inference function of each fused op to generate a fused shape inference function.
The representation in LHLO layer is perfect to handle this, althought there are some more work to do to finish the LegalizeDHLOtoLDHLO Pass. After the Pass, the above pattern should be something like this:
func @main(%arg0: memref<4x8xf32>, %arg1: memref<2xi64>, %arg2: memref<?x?xf32>, %arg3: memref<?x?xf32>) -> memref<?x?xi32> { %starts = "xla_hlo.const"() {value = dense<[0, 0]> : memref<2xi64>} : () -> (memref<2xi64>) // "shape" calculation, the "size" input of the slice may come from some subgraph %0 = alloc() {temp = true,custom_allocator = bfc_cpu} : memref<2xf32> "xla_lhlo.add"(%arg1, %arg1, %0) : (memref<2xi64>, memref<2xi64>, memref<2xi64) -> () // "data" calculation %4 = dim %arg2, 0 : memref<?x?xf32> %5 = dim %arg2, 1 : memref<?x?xf32> %2 = alloc(%4, %5) {temp = true, custom_allocator = bfc_gpu} : memref<?x?xf32> "xla_lhlo.fusion"(%arg0, %starts, /*size*/%0, %arg2, %2) ( { "xla_ldhlo.slice"(%arg0, %starts, /*size*/%0, %1) : (tensor<2x4xf32>, tensor<2xi64>, tensor<2xi64>, tensor<?x?xf32>) -> () "xla_lhlo.add"(%1, %arg2, %2) : (tensor<?x?xf32>, tensor<?x?xf32>, tensor<?x?xf32) -> () } ) : (memref<2x4xf32>, memref<2xi64>, memref<2xi64>, memref<?x?xf32>, memref<?x?xf32>) -> () dealloc %0 : memref<2xf32> "xla_lhlo.matmul(%2, %arg3, %3) : (memref<?x?xf32>, memref<?x?xf32>, memref<?x?xf32) -> () dealloc %2 : memref<?x?xf32> return %3 : memref<?x?xi32> }
4, Custom alloc/dealloc lowering
Lowering of Alloc/Dealloc Ops with custom buffer allocator is to be supported. In order to work with TensorFlow and to minimize the overhead of alloc/dealloc, BFC host/device allocator should be supported.
We noticed that some discussion on this is ongoing months ago:
https://groups.google.com/a/tensorflow.org/forum/?nomobile=true#!topic/mlir/MO0CNmMOa0MWe would like to know the current status.
5, Device representation in HLO/LHLO Dialect
HLO/LHLO Dialect, (together with their extension DHLO/LDHLO) should be able to represent device placement information.
In the current static shaped XLA,there's no such issue since the placement of XlaLaunch Op onto the same device is good enough. However, considering the Dynamic Shape CodeGen for GPU device, for performance purpose the subgraph calculating shapes should be lowered to host codes, while the subgraph manipulating tensors should be lowered to GPU. This rule has been verified in TensorFlow executor and planned to be used here. By this way, we would need the IR in HLO/LHLO layer to be able to represent the device placement semantics.
Any ongoing discussion on this?
8, Support of LHLO lowering to library calls
The current XLA GPU backend only does codegen for the Kernels. "GpuExecutable" together with a number of "Thunks" manages to launch these kernels and third party library calls in a planned way, which is more like a mini-executor inside the XlaRunOp. In order to support Dynamic Shape in the current XLA codes, we would need a new executor, with the support of dynamic BufferAssignment and the ability to deal with the runtime shape inference and "subgraphs that calculating shapes" on host codegen. This will be quite different with the executor in the current XLA. Considering that in MLIR, with the work of GpuKernelOutlining pass/GpuLaunchFuncToCudaCalls pass, we believe that to CodeGen an executor (including host launch codes, library calls, buffer allocation/deallocation, cuda memcpy etc) should be more promising than to develop a new executor with Thunks.
Kai Zhu
To unsubscribe from this group and stop receiving emails from it, send an email to ml...@tensorflow.org.