OpenXLA overall architecture & components

Mehdi AMINI
Hi all,
I was looking for some public info on the overall architecture of the OpenXLA project, trying to define “what are we trying to build?” and how to start articulating all this. I couldn’t find much unfortunately, and it may be time to get some alignment here to avoid a chaotic iterative and ad-hoc merge of the components.
When we started OpenXLA (I wrote the first doc circa 11/2021!), the goal was to create a community-driven project around the XLA compiler, which was under-going already a transition to incorporate gradually more of MLIR internally. Beyond that, we worked on modularizing the project: finding within XLA the abstract components and the extension point. While the XLA codebase may come across as a bit monolithic, the overall architecture is actually pretty decoupled: you can theoretically slot your own compiler at various points of the stack! That led to the goal of OpenXLA being “an ecosystem of reusable ML infrastructure components”: while XLA presents a consistent assembly of such components, they should be designed and built to be reused separately. One of the first examples was how StableHLO was extracted and built into a separate repository decoupled from XLA.
The overlap between this evolution of XLA in the context of OpenXLA, and IREE led to a merge of IREE into OpenXLA, and an acknowledgement to adopt the IREE execution environment into OpenXLA as the replacement of the current execution environment for XLA (other than the runtime specificities, both project were adopting the same MLIR-based codegen already).
There hasn’t been much high-level public discussions on the future of OpenXLA since then, and I find it incredibly hard to discuss RFCs without a top-level view: I see some changes into individual components or between the interface between components but I can’t evaluate them without positioning them in a big picture.
"IREE" is mentioned multiple times in isolation of anything else, and I’ve been trying to find some reference on “What is IREE?” and more importantly “What is IREE within the context of OpenXLA?” because I would expect that joining the OpenXLA project, the definition of "IREE" evolves to mesh within OpenXLA.
Looking back, it was announced in December that IREE is joining the OpenXLA project without more details, and the last slide from the 1/24 community meeting just mentioned “more details to come”. Stella mentioned in the OpenXLA summit a couple of weeks ago that we should see a transition over the next 18 months towards the “OpenXLA compiler” which is “combining both IREE and XLA”. I'm interested in looking into what this combination means.
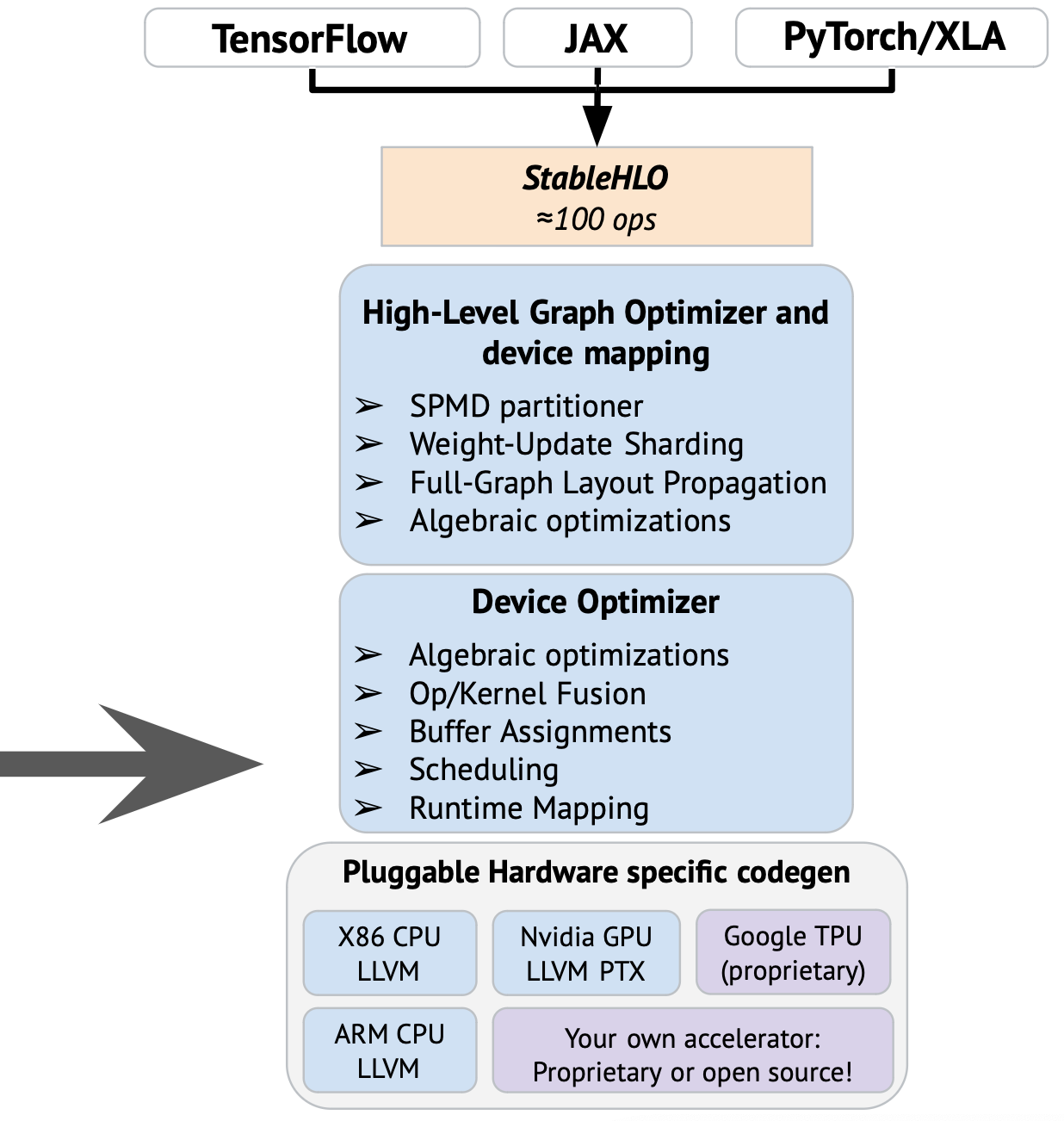
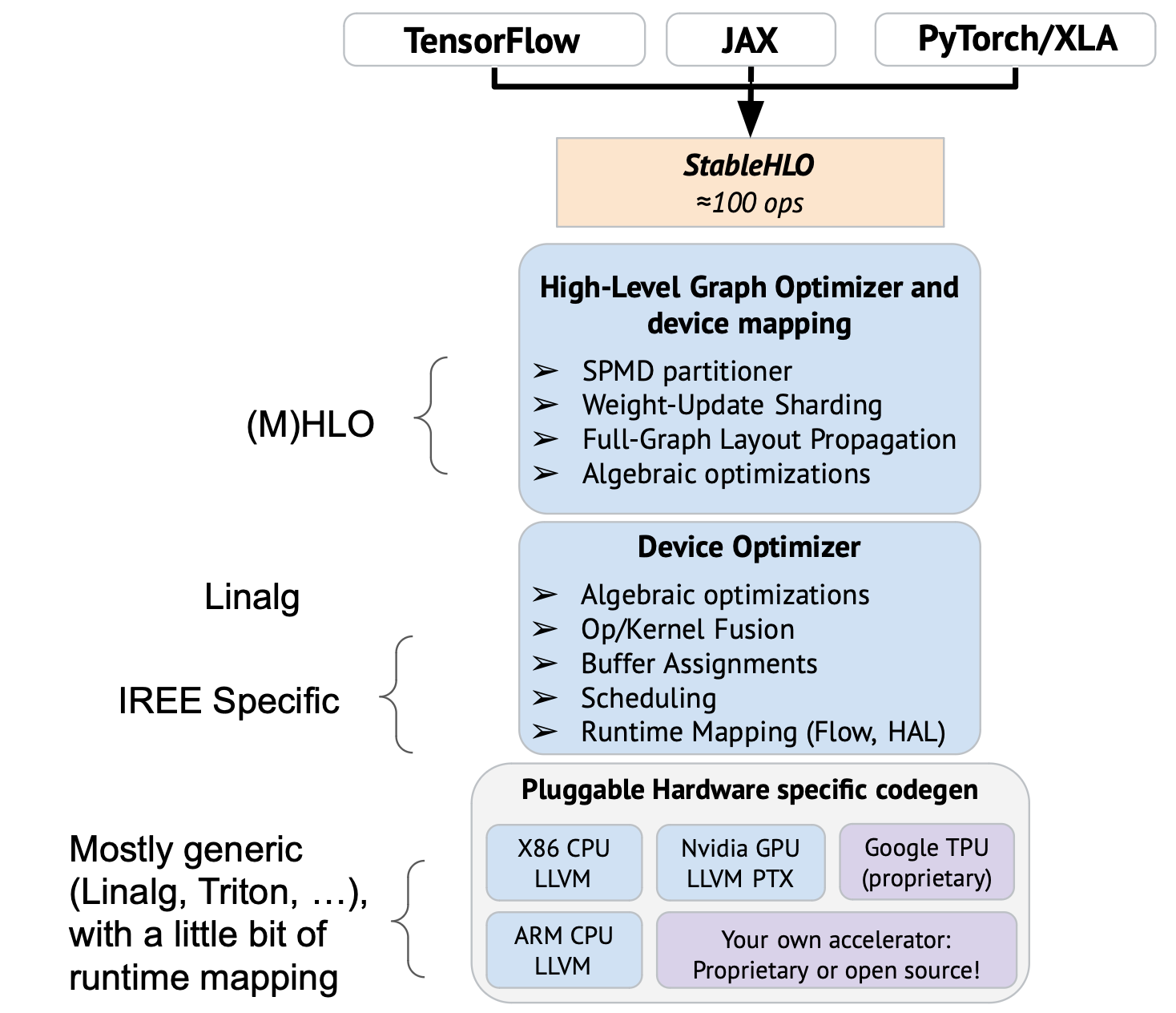
I wrote many times slides about the OpenXLA stack over the last year, the most recent time was a couple of months ago, when Jacques and myself presented OpenXLA privately to some company. In our presentation, IREE was introduced that way in the broader OpenXLA stack on the following slide (where the arrow is):
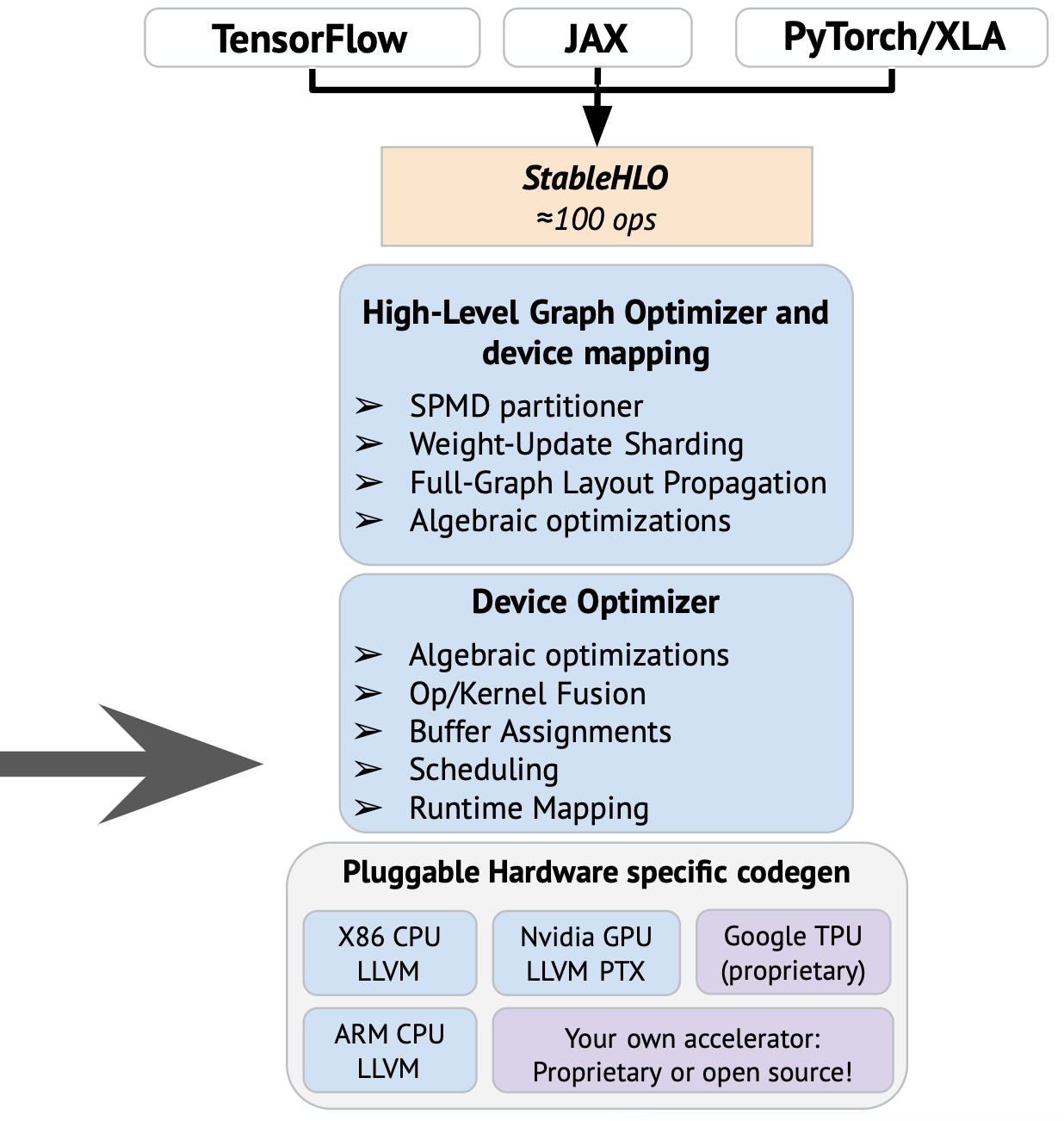
To elaborate a bit more on how I see the components in this picture, it should be roughly the following:
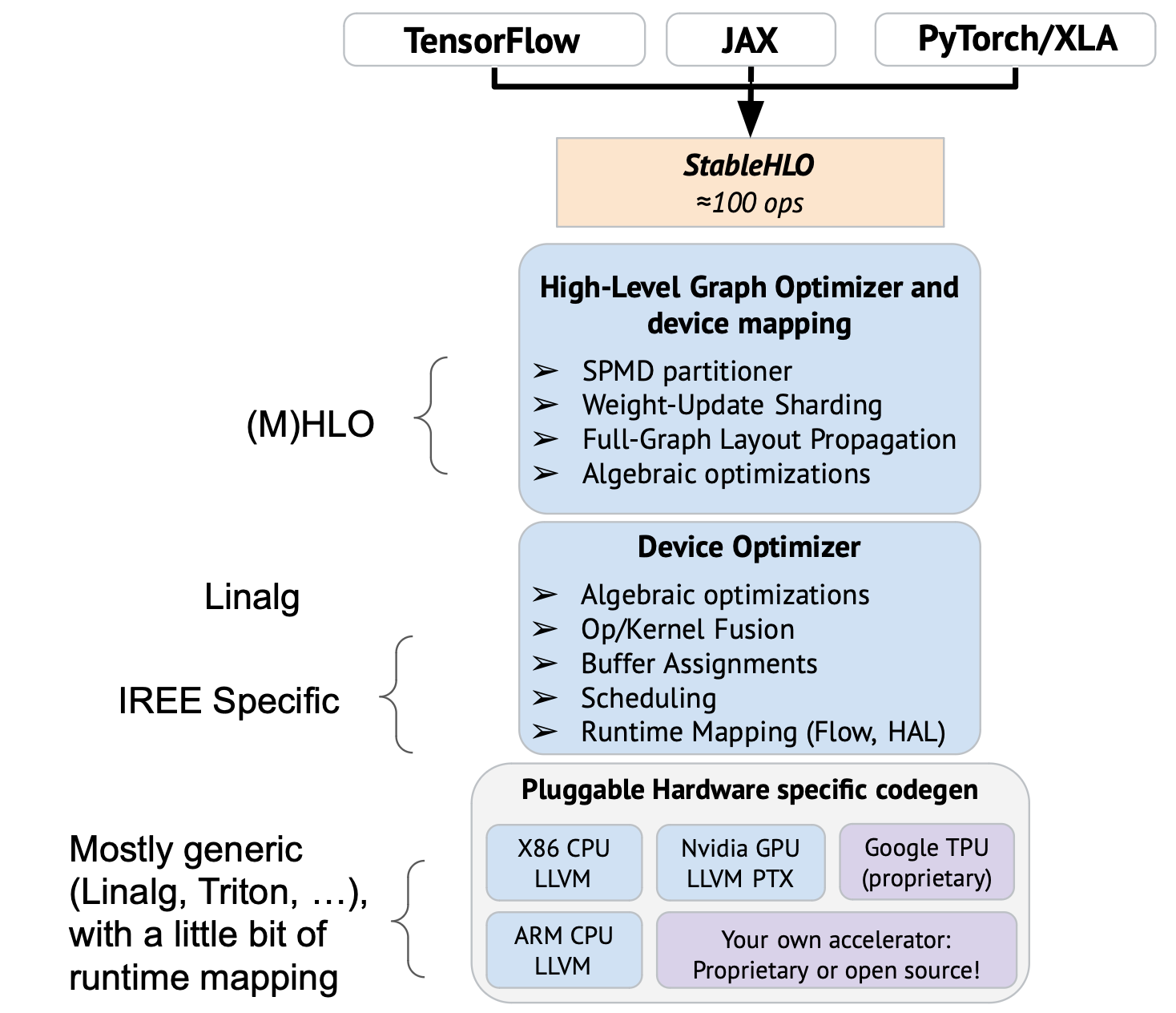
This does not give a detailed and complete picture of IREE, but as far as I understand, this integrates the specificity of IREE into the general stack provided by OpenXLA: IREE brings to OpenXLA mostly a modern execution engine, with new low-level abstraction capabilities and a set of compiler abstractions and transformations to map a sequence of operations to an efficient dynamic schedule.
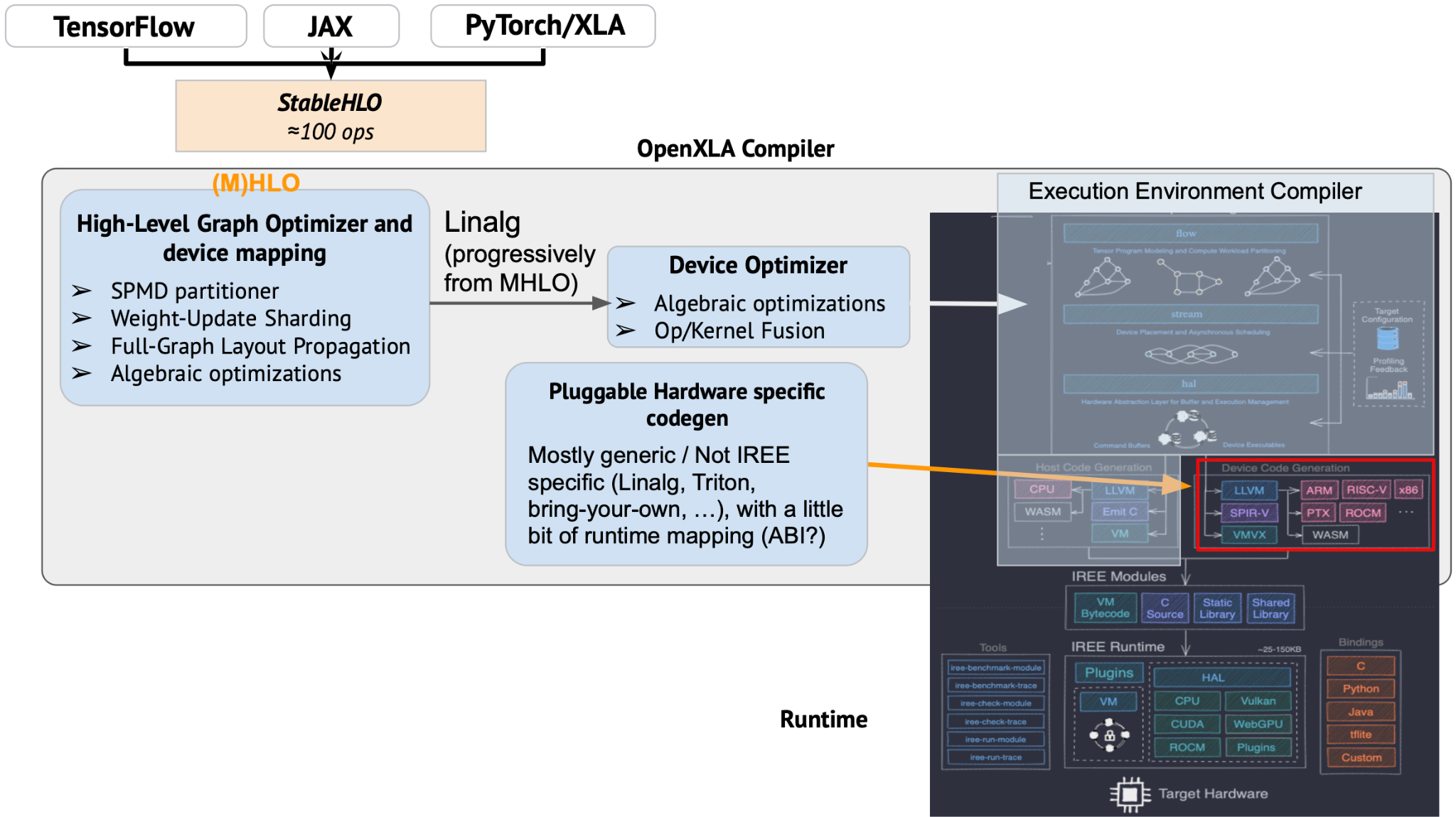
If we zoom in and really want to see what IREE provides, it seems like the following will make it more explicit and accurate:
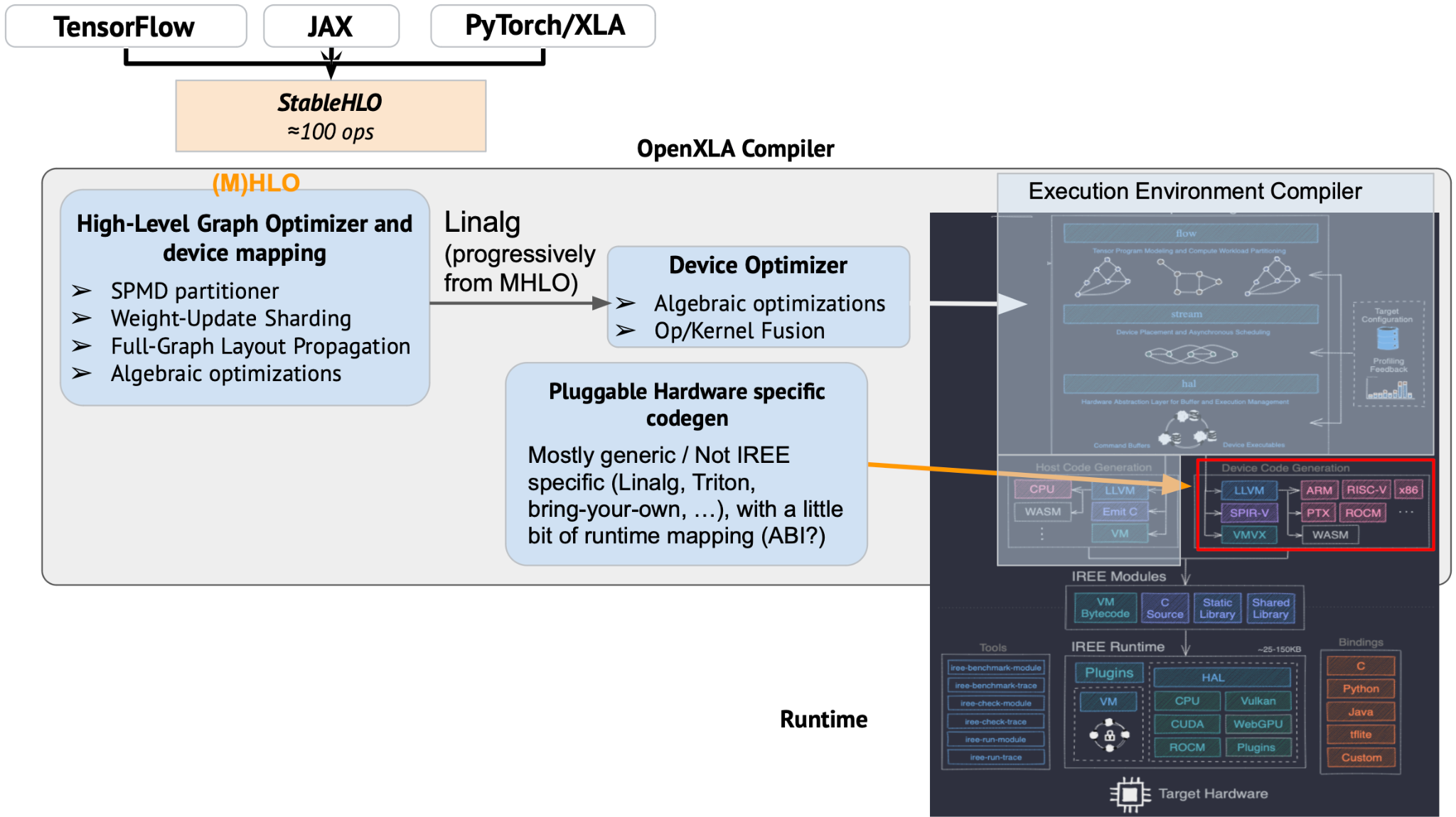
I’m trying to build some shared vocabulary and understanding here, and get to an overall architecture diagram, a description of the modular components in OpenXLA and their role and interactions. I defined some on the diagram above, here is a first attempt to describe these:
OpenXLA: the whole project, I would describe it as “an ecosystem of ML Infrastructure modular components that can be assembled to form an e2e stacks targeting CPU/GPU with extension points enabling xPU targets”
StableHLO: “a portability layer between ML frameworks and ML compilers, is an operation set for high-level operations (HLO) that supports dynamism, quantization, and sparsity. Furthermore, it can be serialized into MLIR bytecode to provide compatibility guarantees.” It is a stable format that is intentionally decoupled for MHLO, which in turn is positioned as a compiler IR (no stability and different ergonomic goals).
OpenXLA compiler: it is the component that takes StableHLO as input and generates an output for an execution environment. The out-of-the-box OpenXLA compiler execution environment is IREE and the IREE compiler uses extension points from the OpenXLA compiler to plug in as the execution environment. Other execution environments should be possible to plug-in for platforms which haven’t adopted IREE.
High-level optimization and device mapping: it is the component in the OpenXLA that operates at the full-graph level and performs transformations accordingly. It also considers the topology of the target (for multi-devices environments) and performs all sharding/partitioning necessary, and optimizes the cross-device communication scheduling to overlap computations. It is parameterized and customized for a given execution environment (platform/runtime/…).
Device Optimizer: it is a point where the partitioning is complete and the code has a “single device” view of the program and optimizes accordingly. This is a level where some linalg fusions may happen for example (In cases where linalg is being used). This is composed of generic and reusable transformations, but this is likely invoked and customized by a particular “execution environment compiler” (like the IREE compiler) since there is a dance that starts to take place with lowering towards a particular environment (and possibly a particular platform).
Pluggable HW specific codegen: this is a point where a single “fusion” or “dispatch” is handed over to the vendor plugin to generate the executable for a given fusion (e.g. to generate ptx/cubin), we can plug the Triton compiler as a codegen for specific kind of “fusions” here.
Execution Environment Compiler: in OpenXLA this is the “IREE Compiler”, it takes as input the output of the “High-level optimization and device mapping” and sets up the “Device Optimizer” according to its need (to lower as needed and transform it accordingly). Other environments are possible (a “no-runtime” embedded CPU environment compiler for example), which could reuse the “device Optimizer” but not map to the same kind of runtime abstractions as IREE.
Runtime: isn’t directly part of the compiler, it is the sets of components that are available on the target platform to allow execution of the resulting program. It is extensible in similar ways to the compiler, with different goals and constraints. There is a strong coupling between the execution environment compiler and the runtime.
MLIR: this is an infrastructure providing tools for building compilers, with reusable dialects and codegen components. OpenXLA is built using MLIR, reusing the codegen components provided as much as possible, and contributing back any improvements or new components (including tools) developed for the need of OpenXLA.
And for simplicity, the diagrams above side-step PJRT, which abstracts from the frameworks the instantiation of the platform and the compiler.
There are likely other ways to slice and dice the overall architecture, and I’d be interested to discuss this further and come up with some diagrams, terminology, and components descriptions we could put online as documentation of OpenXLA.

Stella Laurenzo
----Mehdi
You received this message because you are subscribed to the Google Groups "OpenXLA Discuss" group.
To unsubscribe from this group and stop receiving emails from it, send an email to openxla-discu...@openxla.org.
To view this discussion on the web visit https://groups.google.com/a/openxla.org/d/msgid/openxla-discuss/CANF-O%3DbopQtt%2B5uks87_nViSqKk4ZpV3u64yFJ1%3DZDVq9eJRWw%40mail.gmail.com.
For more options, visit https://groups.google.com/a/openxla.org/d/optout.

Vinod Grover US
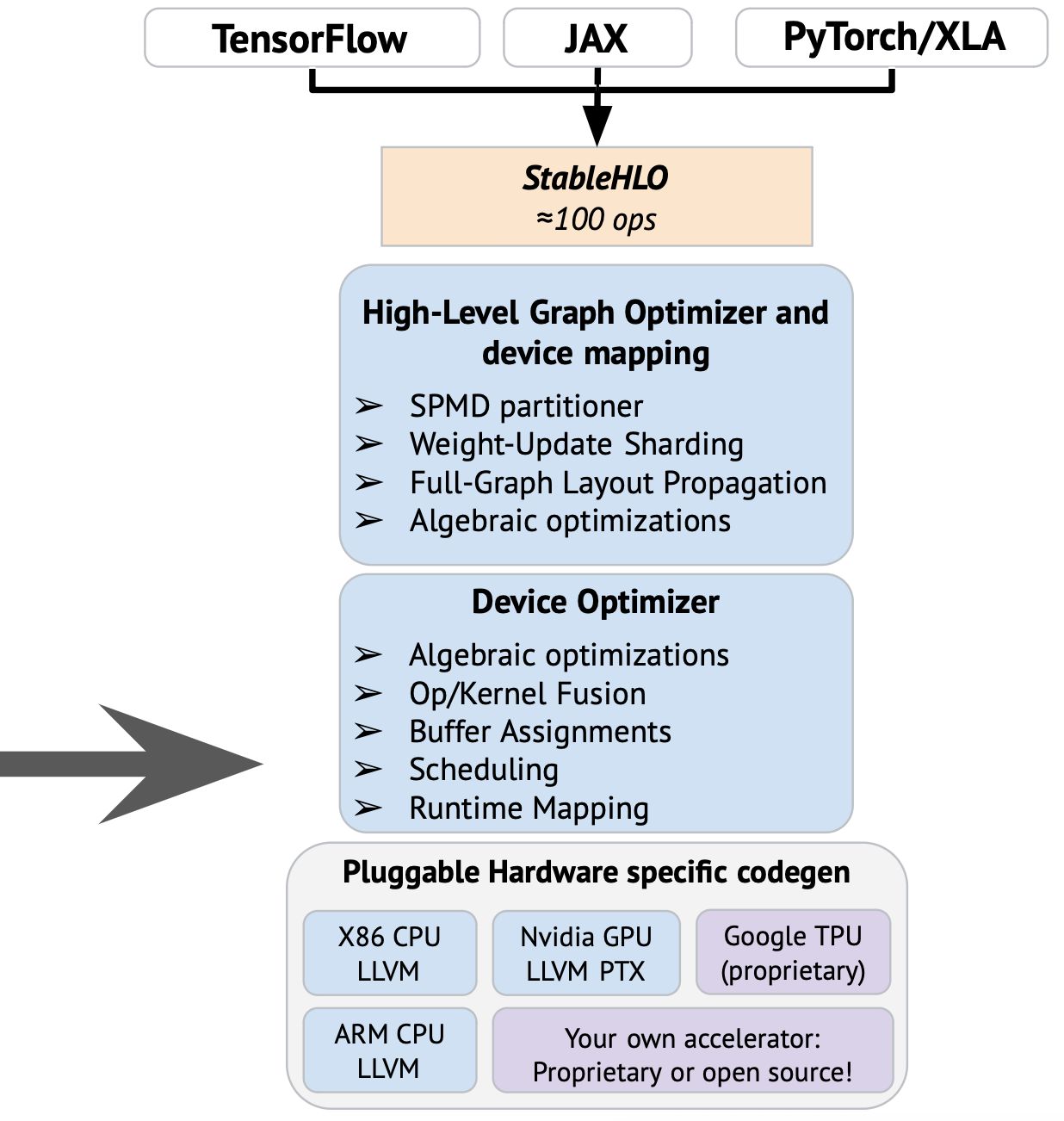
My understanding was that both HLO and device optimizer should, both, accept StableHLO. in Mehdi's new picture device optimizer only recognizes linalg.

Julian Jones

Eugene Zhulenev
Hi all,
I was looking for some public info on the overall architecture of the OpenXLA project, trying to define “what are we trying to build?” and how to start articulating all this. I couldn’t find much unfortunately, and it may be time to get some alignment here to avoid a chaotic iterative and ad-hoc merge of the components.
When we started OpenXLA (I wrote the first doc circa 11/2021!), the goal was to create a community-driven project around the XLA compiler, which was under-going already a transition to incorporate gradually more of MLIR internally. Beyond that, we worked on modularizing the project: finding within XLA the abstract components and the extension point. While the XLA codebase may come across as a bit monolithic, the overall architecture is actually pretty decoupled: you can theoretically slot your own compiler at various points of the stack! That led to the goal of OpenXLA being “an ecosystem of reusable ML infrastructure components”: while XLA presents a consistent assembly of such components, they should be designed and built to be reused separately. One of the first examples was how StableHLO was extracted and built into a separate repository decoupled from XLA.
The overlap between this evolution of XLA in the context of OpenXLA, and IREE led to a merge of IREE into OpenXLA, and an acknowledgement to adopt the IREE execution environment into OpenXLA as the replacement of the current execution environment for XLA (other than the runtime specificities, both project were adopting the same MLIR-based codegen already).
There hasn’t been much high-level public discussions on the future of OpenXLA since then, and I find it incredibly hard to discuss RFCs without a top-level view: I see some changes into individual components or between the interface between components but I can’t evaluate them without positioning them in a big picture.
"IREE" is mentioned multiple times in isolation of anything else, and I’ve been trying to find some reference on “What is IREE?” and more importantly “What is IREE within the context of OpenXLA?” because I would expect that joining the OpenXLA project, the definition of "IREE" evolves to mesh within OpenXLA.
Looking back, it was announced in December that IREE is joining the OpenXLA project without more details, and the last slide from the 1/24 community meeting just mentioned “more details to come”. Stella mentioned in the OpenXLA summit a couple of weeks ago that we should see a transition over the next 18 months towards the “OpenXLA compiler” which is “combining both IREE and XLA”. I'm interested in looking into what this combination means.
I wrote many times slides about the OpenXLA stack over the last year, the most recent time was a couple of months ago, when Jacques and myself presented OpenXLA privately to some company. In our presentation, IREE was introduced that way in the broader OpenXLA stack on the following slide (where the arrow is):
To elaborate a bit more on how I see the components in this picture, it should be roughly the following:
This does not give a detailed and complete picture of IREE, but as far as I understand, this integrates the specificity of IREE into the general stack provided by OpenXLA: IREE brings to OpenXLA mostly a modern execution engine, with new low-level abstraction capabilities and a set of compiler abstractions and transformations to map a sequence of operations to an efficient dynamic schedule.
If we zoom in and really want to see what IREE provides, it seems like the following will make it more explicit and accurate:
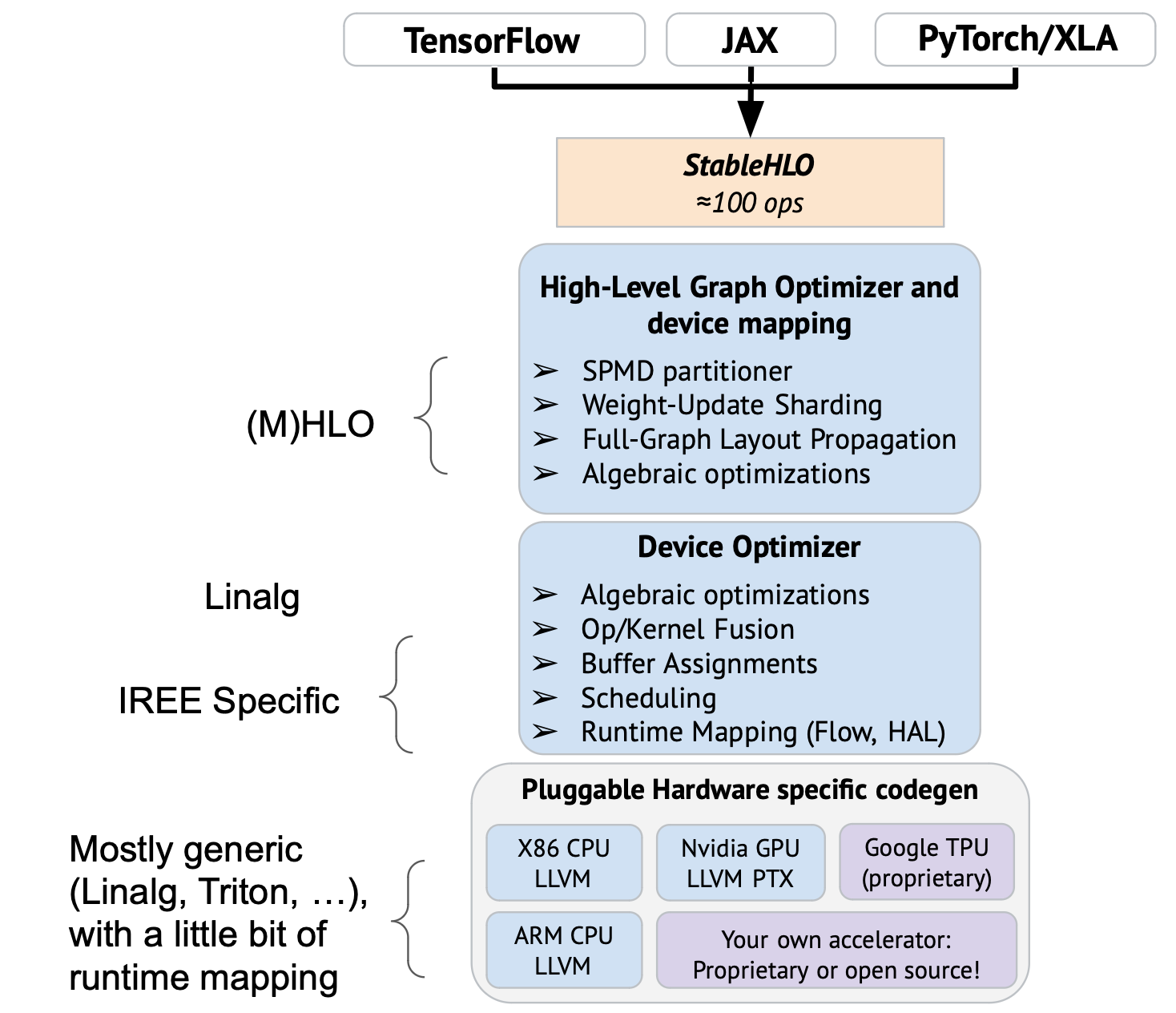
I’m trying to build some shared vocabulary and understanding here, and get to an overall architecture diagram, a description of the modular components in OpenXLA and their role and interactions. I defined some on the diagram above, here is a first attempt to describe these:
OpenXLA: the whole project, I would describe it as “an ecosystem of ML Infrastructure modular components that can be assembled to form an e2e stacks targeting CPU/GPU with extension points enabling xPU targets”
StableHLO: “a portability layer between ML frameworks and ML compilers, is an operation set for high-level operations (HLO) that supports dynamism, quantization, and sparsity. Furthermore, it can be serialized into MLIR bytecode to provide compatibility guarantees.” It is a stable format that is intentionally decoupled for MHLO, which in turn is positioned as a compiler IR (no stability and different ergonomic goals).
OpenXLA compiler: it is the component that takes StableHLO as input and generates an output for an execution environment. The out-of-the-box OpenXLA compiler execution environment is IREE and the IREE compiler uses extension points from the OpenXLA compiler to plug in as the execution environment. Other execution environments should be possible to plug-in for platforms which haven’t adopted IREE.
High-level optimization and device mapping: it is the component in the OpenXLA that operates at the full-graph level and performs transformations accordingly. It also considers the topology of the target (for multi-devices environments) and performs all sharding/partitioning necessary, and optimizes the cross-device communication scheduling to overlap computations. It is parameterized and customized for a given execution environment (platform/runtime/…).
Device Optimizer: it is a point where the partitioning is complete and the code has a “single device” view of the program and optimizes accordingly. This is a level where some linalg fusions may happen for example (In cases where linalg is being used). This is composed of generic and reusable transformations, but this is likely invoked and customized by a particular “execution environment compiler” (like the IREE compiler) since there is a dance that starts to take place with lowering towards a particular environment (and possibly a particular platform).
Pluggable HW specific codegen: this is a point where a single “fusion” or “dispatch” is handed over to the vendor plugin to generate the executable for a given fusion (e.g. to generate ptx/cubin), we can plug the Triton compiler as a codegen for specific kind of “fusions” here.
Execution Environment Compiler: in OpenXLA this is the “IREE Compiler”, it takes as input the output of the “High-level optimization and device mapping” and sets up the “Device Optimizer” according to its need (to lower as needed and transform it accordingly). Other environments are possible (a “no-runtime” embedded CPU environment compiler for example), which could reuse the “device Optimizer” but not map to the same kind of runtime abstractions as IREE.
Runtime: isn’t directly part of the compiler, it is the sets of components that are available on the target platform to allow execution of the resulting program. It is extensible in similar ways to the compiler, with different goals and constraints. There is a strong coupling between the execution environment compiler and the runtime.
MLIR: this is an infrastructure providing tools for building compilers, with reusable dialects and codegen components. OpenXLA is built using MLIR, reusing the codegen components provided as much as possible, and contributing back any improvements or new components (including tools) developed for the need of OpenXLA.
And for simplicity, the diagrams above side-step PJRT, which abstracts from the frameworks the instantiation of the platform and the compiler.
There are likely other ways to slice and dice the overall architecture, and I’d be interested to discuss this further and come up with some diagrams, terminology, and components descriptions we could put online as documentation of OpenXLA.
--Mehdi

Oscar Hernandez
You received this message because you are subscribed to a topic in the Google Groups "OpenXLA Discuss" group.
To unsubscribe from this topic, visit https://groups.google.com/a/openxla.org/d/topic/openxla-discuss/DnPUmpyk4y0/unsubscribe.
To unsubscribe from this group and all its topics, send an email to openxla-discu...@openxla.org.
To view this discussion on the web visit https://groups.google.com/a/openxla.org/d/msgid/openxla-discuss/b1915ec8-18ce-4269-80c7-78da10fe48e0n%40openxla.org.
Geoffrey Martin-Noble
Another term to define is "Classic" OpenXLA. I heard of it today for the first time ;-). Oscar
To view this discussion on the web visit https://groups.google.com/a/openxla.org/d/msgid/openxla-discuss/CAO8OWu7ENJUS%3DK8zuRnSbWJLNLr%2BiNb9FA9HGEZYj4aqJRyLHQ%40mail.gmail.com.
Stella Laurenzo
Stella Laurenzo
My understanding was that both HLO and device optimizer should, both, accept StableHLO. in Mehdi's new picture device optimizer only recognizes linalg.
Stella Laurenzo
On Mon, May 15, 2023 at 5:13 PM Mehdi AMINI <joke...@gmail.com> wrote:Hi all,
I was looking for some public info on the overall architecture of the OpenXLA project, trying to define “what are we trying to build?” and how to start articulating all this. I couldn’t find much unfortunately, and it may be time to get some alignment here to avoid a chaotic iterative and ad-hoc merge of the components.
When we started OpenXLA (I wrote the first doc circa 11/2021!), the goal was to create a community-driven project around the XLA compiler, which was under-going already a transition to incorporate gradually more of MLIR internally. Beyond that, we worked on modularizing the project: finding within XLA the abstract components and the extension point. While the XLA codebase may come across as a bit monolithic, the overall architecture is actually pretty decoupled: you can theoretically slot your own compiler at various points of the stack! That led to the goal of OpenXLA being “an ecosystem of reusable ML infrastructure components”: while XLA presents a consistent assembly of such components, they should be designed and built to be reused separately. One of the first examples was how StableHLO was extracted and built into a separate repository decoupled from XLA.
The overlap between this evolution of XLA in the context of OpenXLA, and IREE led to a merge of IREE into OpenXLA, and an acknowledgement to adopt the IREE execution environment into OpenXLA as the replacement of the current execution environment for XLA (other than the runtime specificities, both project were adopting the same MLIR-based codegen already).
There hasn’t been much high-level public discussions on the future of OpenXLA since then, and I find it incredibly hard to discuss RFCs without a top-level view: I see some changes into individual components or between the interface between components but I can’t evaluate them without positioning them in a big picture.
"IREE" is mentioned multiple times in isolation of anything else, and I’ve been trying to find some reference on “What is IREE?” and more importantly “What is IREE within the context of OpenXLA?” because I would expect that joining the OpenXLA project, the definition of "IREE" evolves to mesh within OpenXLA.
Looking back, it was announced in December that IREE is joining the OpenXLA project without more details, and the last slide from the 1/24 community meeting just mentioned “more details to come”. Stella mentioned in the OpenXLA summit a couple of weeks ago that we should see a transition over the next 18 months towards the “OpenXLA compiler” which is “combining both IREE and XLA”. I'm interested in looking into what this combination means.
I wrote many times slides about the OpenXLA stack over the last year, the most recent time was a couple of months ago, when Jacques and myself presented OpenXLA privately to some company. In our presentation, IREE was introduced that way in the broader OpenXLA stack on the following slide (where the arrow is):
To elaborate a bit more on how I see the components in this picture, it should be roughly the following:
This does not give a detailed and complete picture of IREE, but as far as I understand, this integrates the specificity of IREE into the general stack provided by OpenXLA: IREE brings to OpenXLA mostly a modern execution engine, with new low-level abstraction capabilities and a set of compiler abstractions and transformations to map a sequence of operations to an efficient dynamic schedule.
If we zoom in and really want to see what IREE provides, it seems like the following will make it more explicit and accurate:
I’m trying to build some shared vocabulary and understanding here, and get to an overall architecture diagram, a description of the modular components in OpenXLA and their role and interactions. I defined some on the diagram above, here is a first attempt to describe these:This is very close to how I think of OpenXLA.
OpenXLA: the whole project, I would describe it as “an ecosystem of ML Infrastructure modular components that can be assembled to form an e2e stacks targeting CPU/GPU with extension points enabling xPU targets”
StableHLO: “a portability layer between ML frameworks and ML compilers, is an operation set for high-level operations (HLO) that supports dynamism, quantization, and sparsity. Furthermore, it can be serialized into MLIR bytecode to provide compatibility guarantees.” It is a stable format that is intentionally decoupled for MHLO, which in turn is positioned as a compiler IR (no stability and different ergonomic goals).
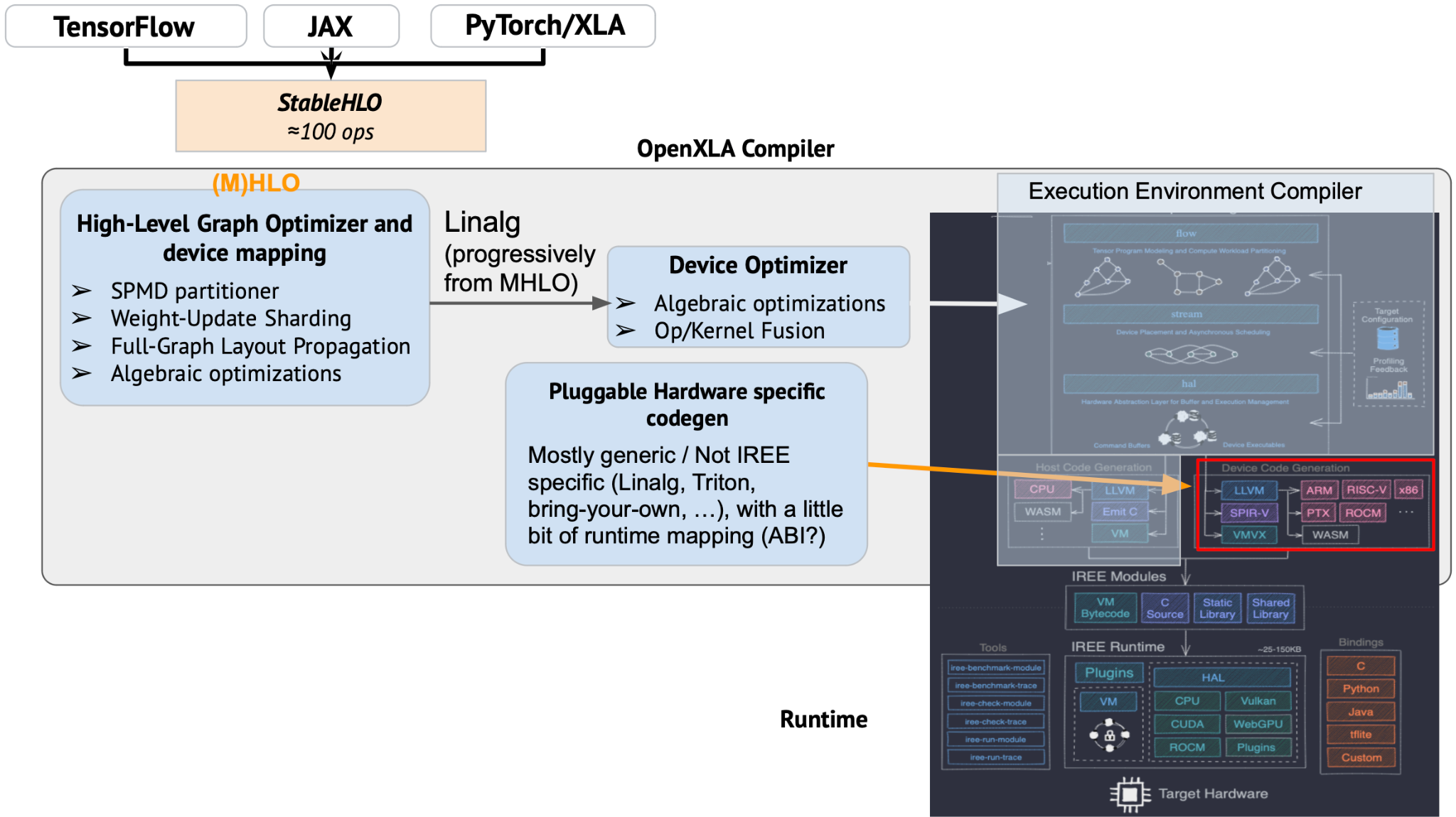
OpenXLA compiler: it is the component that takes StableHLO as input and generates an output for an execution environment. The out-of-the-box OpenXLA compiler execution environment is IREE and the IREE compiler uses extension points from the OpenXLA compiler to plug in as the execution environment. Other execution environments should be possible to plug-in for platforms which haven’t adopted IREE.
I think that PjRt will be another integration point for users that don't want to take any dependencies on IREE compiler, and want to build everything from scratch (although IREE VM / non-hal-runtime still can be reused for running host executables).
High-level optimization and device mapping: it is the component in the OpenXLA that operates at the full-graph level and performs transformations accordingly. It also considers the topology of the target (for multi-devices environments) and performs all sharding/partitioning necessary, and optimizes the cross-device communication scheduling to overlap computations. It is parameterized and customized for a given execution environment (platform/runtime/…).
With mhlo going away I'm not sure at what level this will happen. For example in openxla-nvgpu we had to write custom stablehlo transpose folding (https://github.com/openxla/openxla-nvgpu/commit/52e88c15f7c660badf7119210420f8920ddd048b), because previously it was in mhlo and we relied on it.