Cassandra joinWithCassandraTable is not working in cassandra cluster but working in Standalone

Amol Khanolkar
I have 2 cassandra instances ( local standalone single instance), and 3 node cluster.
I have created table as below
CREATE TABLE dev.test ( a text, b int, c text, PRIMARY KEY ((a, b), c)) WITH CLUSTERING ORDER BY (c ASC)
I have entered data
a | b | cI am connecting to spark shell using below command. For cluster its i/p of one of machine in cluster. then below are individual commands
./spark-shell --conf spark.cassandra.connection.host=127.0.0.1 --packages com.datastax.spark:spark-cassandra-connector_2.12:3.0.0-betaNow I see difference at this step **On My local **
scala> repartitioned.partitionsSame steps when performed connecting to cluster (one of contact point)
scala> repartitioned.partitionsBecause of this when I do joinwithCassandraTable on cluster it dosent return any records
Do I need to do any other configuration on my cluster for this to work ?
I am having lot of partition keys which i want to fetch and do in memory computations using below architecture. If I understnd correctly ReplicaPartition should partition keys as per their location in cluster
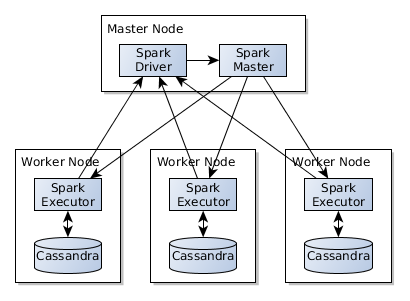
Regards
Amol

Russell Spitzer
--
To unsubscribe from this group and stop receiving emails from it, send an email to spark-connector-...@lists.datastax.com.
