The failures of iostreams

Jason McKesson
This kind of thing is indicative of a real problem in iostreams. In order to eventually solve that problem, we must first identify exactly what the problems are. This discussion should be focused on exactly that: identifying the problems with the library. Once we know what the real problems are, we can be certain that any new system that is proposed addresses them.
Note that this is about problems within iostreams. This is not about a list of things you wish it could do. This is about what iostreams actually tries to do but fails at in some way. So stuff like async file IO doesn’t go here, since iostreams doesn’t try to provide that.
Feel free to add to this list other flaws you see in iostreams. Or if you think that some of them are not real flaws, feel free to explain why.
Performance
This is the big one, generally the #1 reason why people suggest using C-standard file IO rather than iostreams.Oftentimes, when people defend iostreams performance, they will say something to the effect of, “iostreams does far more than C-standard file IO.” And that’s true. With iostreams, you have an extensible mechanism for writing any type directly to a stream. You can “easily” write new streambuf’s that will allow you to (via runtime polymorphism) be able to work with existing code, thus allowing you to leverage your file IO for other forms of IO. You could even use a network pipe as an input or output stream.
There’s one real problem with this logic, and it is exactly why people suggest C-standard file IO. Iostreams violates a fundamental precept of C++: pay only for what you use.
Consider this suite of benchmarks. This code doesn’t do file IO; it writes directly to a string. All it’s doing is measuring the time it takes to append 4-characters to a string. A lot. It uses a `char[]` as a useful control. It also tests the use of `vector<char>` (presumably `basic_string` would have similar results). Therefore, this is a solid test for the efficiency of the iostreams codebase itself.
Obviously there will be some efficiency loss. But consider the numbers in the results.
The ostringstream is more than full order of magnitude slower than the control. It’s almost 100x in some cases. Note that it’s not using << to write to the stream; it’s using `ostream::write()`.
Note that the vector<char> implementations are fairly comparable to the control, usually being around 1x-4x the speed. So clearly this is something in ostringstream.
Now, you might say that one could use the stringbuf directly. And that was done. While it does improve performance over the ostringstream case substantially (generally half to a quarter the performance), it’s still over 10x slower than the control or most vector<char> implementations.
Why? The stringbuf operations ought to be a thin wrapper over std::string. After all, that’s what was asked for.
Where does this inefficiency come from? I haven’t done any extensive profiling analysis, but my educated guesses are from two places: virtual function overhead and an interface that does too much.
ostringstream is supposed to be able to be used as an ostream for runtime-polymorphism. But here’s where the C++ maxim comes into play. Runtime-polymorphism is not being used here. Every function call should be able to be statically dispatched. And it is, but all of the virtual machinery comes from within ostringstream.
This problem seems to come mostly from the fact that basic_ostream, which does most of the leg-work for ostringstream, has no specific knowledge of its stream type. Therefore it's always a virtual call. And it may be doing many such virtual calls.
You can achieve the same runtime polymorphism (being able to overload operator<< for any stream) by using a static set of stream classes, tightly coupled to their specific streambufs, and a single “anystream” type that those streams can be converted into. It would use std::function-style type erasure to remember the original type and feed function calls to it. It would use a single function call to initiate each write operation, rather than what appears to be many virtual calls within each write.
Then, there’s the fact that streambuf itself is overdesigned. stringbuf ought to be a simple interface wrapper around a std::string, but it’s not. It’s a complex thing. It has locale support of all things. Why? Isn’t that something that should be handled at the stream level?
This API has no way to get a low-level interface to a file/string/whatever. There’s no way to just open a filebuf and blast the file into some memory, or to shove some memory out of a filebuf. It will always employ the locale machinery even if you didn’t ask for it. It will always make these internal virtual calls, even if they are completely statically dispatched.
With iostreams, you are paying for a lot of stuff that you don’t frequently use. At the stream level, it makes sense that you’re paying for certain machinery (though again, some way to say that you’re not using some of it would be nice). At the buffer level, it does not, since that is the lowest level you’re allowed to use.
Utility
While performance is the big issue, it’s not the only one.The biggest selling point for iostreams is the ability to extend its formatted writing functionality. You can overload operator<< for various types and simply use them. You can’t do that with fprintf. And thanks to ADL, it will work just fine for classes in namespaces. You can create new streambuf types and even streams if you like. All relatively easily.
Here’s the problem, and it is admittedly one that is subjective: printf is really nice syntax.
It’s very compact, for one. Once you understand the basic syntax of it, it’s very easy to see what’s going on. Especially for complex formatting. Just consider the physical size difference between these two:
snprintf(..., “0x%08x”, integer);
stream << "0x" << std::right << std::hex << std::setw(8) << iVal << std::endl;
It may take a bit longer to become used to the printf version, but this is something you can easily look up in a reference.
Plus, it makes it much easier to do translations on formatted strings. You can look the pattern string up in a table that changes from language to language. This is rather more difficult in iostreams, though not impossible. Granted, pattern changes may not be enough, as some languages have different subject/verb/object grammars that would require reshuffling patterns around. However, there are printf-style systems that do allow for reshuffling, whereas no such mechanism exists for iostream-style.
C++ used the << method because the alternatives were less flexible. Boost.Format and other systems show that C++03 did not really have to use this mechanism to achieve the extensibility features that iostreams provide.
What do you think? Are there other issues in iostreams that need to be mentioned?

Nevin Liber
C++ used the << method because the alternatives were less flexible. Boost.Format and other systems show that C++03 did not really have to use this mechanism to achieve the extensibility features that iostreams provide.
What do you think? Are there other issues in iostreams that need to be mentioned?
Nevin ":-)" Liber <mailto:ne...@eviloverlord.com> (847) 691-1404

Loïc Joly
> legitimate C++ professional, who like C++ and use modern C++ idioms,
> telling people to not use iostreams. This is not due to differing
> ideas on C++ or C-in-classes-style development, but the simple
> practical realities of the situation.
>
- Performance: I performances really matter, granted, I will not use
iostream, but I will not use C I/O facilities either. I will use
platform specific API that can deliver maximum performance.
- Usability: I find printf format really hard to use (and very error
prone). It's another language, and an obscure one. I genuinely have no
idea what 0x%08x meant in your message. I was not even sure if it
expected one argument or several. But this is not my main point. My main
point is that your comparison is unfair: Most of the time, when doing
I/O, I don't care about format (when I care, then I use a UI library
such as Qt, or I generate HTML, or LaTeX, or whatever, but I don't use
iostream). And in this case, iostream are not more verbose:
os << "Line " << line << ": Error(" << code << "): " << msg;
printf("Line %??: Error(%??): %??", line, code, msg);
The difference is not that big, even when using only basic types (and,
as you said, the difference is in the other direction when dealing with
user defined types).
For me, the biggest issue I have with iostream is localisation, and the
possibility to have a whole sentence in one block, and to be able to
swap arguments. And boost format really helps here.
--
Lo�c
Nicol Bolas
On Saturday, November 17, 2012 12:03:52 PM UTC-8, Nevin ":-)" Liber wrote:
On 17 November 2012 13:36, Jason McKesson <jmck...@gmail.com> wrote:C++ used the << method because the alternatives were less flexible. Boost.Format and other systems show that C++03 did not really have to use this mechanism to achieve the extensibility features that iostreams provide.Boost.Format came out in 2002. C++03 (which is basically C++98) was standardized in the 90s. Short of building a time machine, I fail to see how Boost.Format showed C++03 anything.
My point being that Boost.Format was possible, so it could have been done. That is, we didn't need variadic templates or other C++11 features to be able to have this functionality.
What do you think? Are there other issues in iostreams that need to be mentioned?Not really, no. Ragging on iostreams is easy, and has been done plenty of times already. Coming up with a proposal to replace it is hard and time consuming. I don't see any proposal here. Are you looking to write one?
Did you read the intro section of the post, where I state that writing a proposal first requires collecting the problems? You're kinda missing the point here. You have to figure out what went wrong before you can fix it. Otherwise, you're likely to create more problems by missing something important.
Nicol Bolas
On Saturday, November 17, 2012 12:08:20 PM UTC-8, Loïc Joly wrote:
Le 17/11/2012 20:36, Jason McKesson a �crit :
> The Iostreams library in C++ has a problem. We have real, reasonable,
> legitimate C++ professional, who like C++ and use modern C++ idioms,
> telling people to not use iostreams. This is not due to differing
> ideas on C++ or C-in-classes-style development, but the simple
> practical realities of the situation.
>
There are mostly two points where I disagree with your analysis:
- Performance: I performances really matter, granted, I will not use
iostream, but I will not use C I/O facilities either. I will use
platform specific API that can deliver maximum performance.
I would consider this something of a non-sequitor. Yes, one can always run to the OS facilities if one wants maximum performance. That is not an excuse for iostream's performance however (and the fact that you do so is indicative of the exact problem I state).
There's a big difference between "maximum performance", "reasonable performance", and "iostreams performance". The difference between vector<char> and writing to a char[] is "reasonable performance." It's an abstraction, but it's a tight one that can work out well if your compiler is good. The difference between iostreams (especially stringbuf) and vector<char> is utterly inexcusable. There is no reason for such a massive performance difference to exist between those cases.
I again remind you of the C++ maxim: pay only for what you use. You shouldn't have to leave performance on the table unless you're doing something that requires that loss of performance. C-standard file IO offers reasonable performance relative to the OS facilities; why shouldn't iostreams? Isn't that what one should expect from standard library facilities, to offer a wrapper around the OS that is reasonably thin?
You don't see people ditching operator new just to get reasonable allocation performance. Even if they want to write their own allocation system based on the OS specifics, they'll still hook it into operator new.
However, you rarely see people write a file IO system built on OS specifics and then build a streambuf-derived class to use it with iostreams. There's a reason for that.
Iostreams should be someone that people should want to use for platform-neutral development. That's my point, and it's performance makes people want to use other things.
- Usability: I find printf format really hard to use (and very error
prone). It's another language, and an obscure one. I genuinely have no
idea what 0x%08x meant in your message. I was not even sure if it
expected one argument or several. But this is not my main point. My main
point is that your comparison is unfair: Most of the time, when doing
I/O, I don't care about format
That's nice that you don't have to. Some people do, a lot. Their use cases should not be ignored.
My comparison came from actual use. There are plenty of times when I have needed to look at a 32-bit integer output as a hexadecimal number. And iostreams makes that incredibly difficult, while printf makes it incredibly easy.
(when I care, then I use a UI library
such as Qt, or I generate HTML, or LaTeX, or whatever, but I don't use
iostream)
Isn't that indicative of a failure in iostreams? That if you need to write hexadecimal numbers, you bring in Qt/HTML/LaTeX (I really don't know what LaTeX is doing there), rather than using standard library features. Remember: we're not talking about visual formatting; this is pure text stuff. This is "I want the integer to be hexadecimal" or "I want the float to only have 2 decimal digits."
You shouldn't have to run screaming to Qt whenever you want to do that in a reasonable way.
. And in this case, iostream are not more verbose:
os << "Line " << line << ": Error(" << code << "): " << msg;
printf("Line %??: Error(%??): %??", line, code, msg);
The difference is not that big, even when using only basic types (and,
as you said, the difference is in the other direction when dealing with
user defined types).
For me, the biggest issue I have with iostream is localisation, and the
possibility to have a whole sentence in one block, and to be able to
swap arguments. And boost format really helps here.
--
Lo�c
Loïc Joly
>
> (when I care, then I use a UI library
> such as Qt, or I generate HTML, or LaTeX, or whatever, but I don't
> use
> iostream)
>
>
> Isn't that indicative of a failure in iostreams? That if you need to
> write hexadecimal numbers, you bring in Qt/HTML/LaTeX (I really don't
> know what LaTeX is doing there), rather than using standard library
> features. Remember: we're not talking about visual formatting; this is
> pure text stuff. This is "I want the integer to be hexadecimal" or "I
> want the float to only have 2 decimal digits."
>
visual formatting, I will anyway use other libraries than iostream. And
if I don't want visual formatting, but pure text, then I usually don't
care if floats have 2, 6 or 12 decimal digits.
There is another point where I believe iostreams are weak, it's
encoding. There is the codecvt facet that can be used, but I find it not
really easy to use. Moreover, I'd like to open a file and let the system
automatically detect its format (using BOM, or maybe other heuristics)
and allow me to directly read from it into my internal format.
--
Lo�c

Václav Zeman
The Iostreams library in C++ has a problem. We have real, reasonable, legitimate C++ professional, who like C++ and use modern C++ idioms, telling people to not use iostreams. This is not due to differing ideas on C++ or C-in-classes-style development, but the simple practical realities of the situation.
This kind of thing is indicative of a real problem in iostreams. In order to eventually solve that problem, we must first identify exactly what the problems are. This discussion should be focused on exactly that: identifying the problems with the library. Once we know what the real problems are, we can be certain that any new system that is proposed addresses them.
Note that this is about problems within iostreams. This is not about a list of things you wish it could do. This is about what iostreams actually tries to do but fails at in some way. So stuff like async file IO doesn’t go here, since iostreams doesn’t try to provide that.
Feel free to add to this list other flaws you see in iostreams. Or if you think that some of them are not real flaws, feel free to explain why.
What do you think? Are there other issues in iostreams that need to be mentioned?
Performance
I have never needed that much performance that I would have to not use C++ IO streams to get the performance. Thus, I do not consider performance an issue with the current IO streams except for std::stringstream et al. I think that it is a failure in design that getting the string out of the stringstream is by value. Second, that the only way to reset the stream easily is to call 'stream.str("")' or 'stream.str(std::string())'. There should be some sort of 'clear()' like member function.
Problematic cases
Here are some use cases and experiences where I think the current C++ IO streams are lacking or failing.
Recently, I have decided that I wanted to read (on Windows with MSVC) UTF-16 or UTF-32 text files using wchar_t variants of file IO streams. Now, to get that with C++11 I have to imbue the streams with one of codecvt_utf{16,32} facets. So far that's ok and understandable. What I consider a failure in design is that to actually get it working, I have to open files in binary mode. Opening the file in binary mode means that the stream will stop translating DOS/*NIX EOLs. Clearly, IMHO, the EOLs and encoding are two separate issues, or should be. Maybe locale should also have some sort of EOL facet to do this?
Second problem I consider important is that writing own streambufs is exceptionally hard. This seems to be because both the semantics and names of streambuf's member functions are bizarre.
Possible solution?
On few occasions, I have used Boost.IOStreams. Their abstractions and categories of streams are richer than what standard C++ IO streams offer and they have worked for me well enough, certainly better than raw streams, in some situations. Especially the 'stream' and 'stream_buffer' class templates are extremely useful. Implementing own stream and stream_buf on to of Device concept using these two templates is rather easy. Filtering stream with chain of filters is another very useful concept.
If Boost.IOStreams are not directly usable to be adopted as a standard library, then at least they can server as an example of successful library, IMHO, from which anybody who would like to improve existing C++ IO streams should learn.
If nothing else could be accepted from the library, just the stream and the stream_buffer classes alone (with the necessary support classes/code) would be a huge improvement to standard C++ IO streams.
HTH,
--
VZ

Beman Dawes
> ...
one problem.
> What do you think? Are there other issues in iostreams that need to be
> mentioned?
iostreams. IIRC, there are eight or ten issues on his list, and he
believes a C++11 version of Boost.Format, or something similar, would
solve a lot of them. But best to ask him directly.
This mailing list is a good place to float an idea about your library,
as mentioned in http://isocpp.org/std/submit-a-proposal
But the assumption was that you had an existing library you wanted to
float for possible standardization, not just a wish-list and some
ideas about a possible future library.
As has been noted many times by many LWG members, the problem with
libraries that don't exist yet is that they are inevitably presented
as far superior to existing libraries for the problem domain. And if
someone raises an issue with the not-yet-existing library, the
response is often that the issue will be easy to fix. So of course
everyone would love to have this wondrous library for the standard!
But only If it ever gets implemented, documented, used, refined, and
matures into something useful, and someone writes an actual proposal
document.
--Beman

Martinho Fernandes
On 11/17/2012 08:36 PM, Jason McKesson wrote:I think that it is a failure in design that getting the string out of the stringstream is by value.
I think getting the string by value is the correct design. What I think is missing is to make str() have lvalue and rvalue ref-qualified overloads so you can get it out of a temporary stringstream with a move, or even write std::move(some_stringstream).str() and "move a string out", but stealing the buffer from the underlying stringbuf.
Martinho
Nicol Bolas
The main purpose of this thread is to collect a list of legitimate grievances towards iostreams. That way, when someone writes or submits a proposal, we can check it against the list and know how well it's doing. Even better, if I (or anyone reading this) were inclined to write such a library and a proposal, it would help guide my interface to know what the major issues that need resolving are.

Tony V E

VinceRev
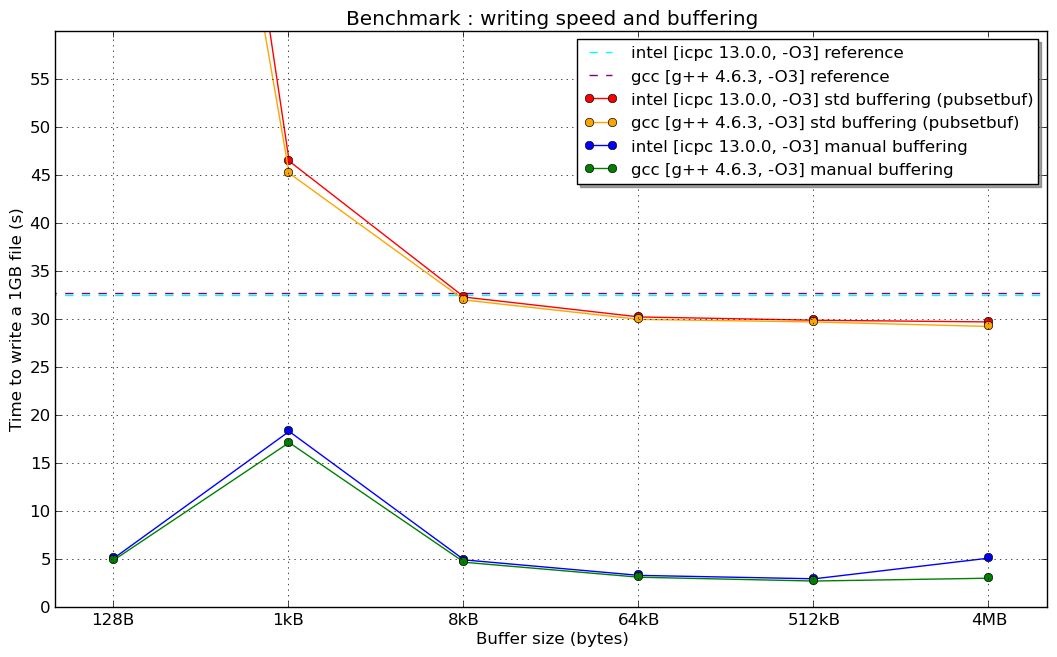
- the standard solution using a loop of write()/read() and varying the size of the internal buffer with pubsetbuf
- another one, where I put "manually" the data in a large memory buffer, and when the buffer is full, I call the write()/read() function passing this buffer as parameter
... and the second technique is in general 10x faster than the first one (see the attached plot).
I don't have any elegant solution to provide, but the fact is that the write() and read() functions have a substantial overhead....

Julien Nitard

Bjorn Reese
> What do you think? Are there other issues in iostreams that need to be
> mentioned?
cannot use them for debug printing from the destructors of global
objects.
Having said that, I also think that we should consider the virtues of
iostream-style. How would to create something like Boost.Serialization
using a printf-style?

Arthur Tchaikovsky
It’s very compact, for one. Once you understand the basic syntax of it, it’s very easy to see what’s going on. Especially for complex formatting. Just consider the physical size difference between these two:
snprintf(..., “0x%08x”, integer);
stream << "0x" << std::right << std::hex << std::setw(8) << iVal << std::endl;
It may take a bit longer to become used to the printf version, but this is something you can easily look up in a reference.
Arthur Tchaikovsky
It’s very compact, for one. Once you understand the basic syntax of it, it’s very easy to see what’s going on. Especially for complex formatting. Just consider the physical size difference between these two:
snprintf(..., “0x%08x”, integer);
stream << "0x" << std::right << std::hex << std::setw(8) << iVal << std::endl;
It may take a bit longer to become used to the printf version, but this is something you can easily look up in a reference.
Martinho Fernandes
It’s very compact, for one. Once you understand the basic syntax of it, it’s very easy to see what’s going on. Especially for complex formatting. Just consider the physical size difference between these two:
snprintf(..., “0x%08x”, integer);stream << "0x" << std::right << std::hex << std::setw(8) << iVal << std::endl;It may take a bit longer to become used to the printf version, but this is something you can easily look up in a reference.Again, logic of a person for whom recursion is as easy to understand and use as iteration.
Your most recent replies have been getting somewhat inflamatory. I think you should take a break.
Martinho

J. Daniel Garcia
--
Nicol Bolas
On Sunday, November 18, 2012 5:20:13 AM UTC-8, Arthur Tchaikovsky wrote:
It’s very compact, for one. Once you understand the basic syntax of it, it’s very easy to see what’s going on. Especially for complex formatting. Just consider the physical size difference between these two:snprintf(..., “0x%08x”, integer);stream << "0x" << std::right << std::hex << std::setw(8) << iVal << std::endl;It may take a bit longer to become used to the printf version, but this is something you can easily look up in a reference.a) every heard of "type safety"?
Yes. Which Boost.Format provides quite nicely while still using printf-style syntax.

Jens Maurer
> Perhaps peripheral, but std::cout (and std::cerr) are objects, so you
> cannot use them for debug printing from the destructors of global
> objects.
"The objects are not destroyed during program execution."
plus footnote:
"294) Constructors and destructors for static objects can access these
objects to read input from stdin or write output to stdout or stderr."
Jens

Brendon Costa
--
Bjorn Reese
then. I just checked C++98, and it also contains the passages you quote.

Olaf van der Spek
What do you think? Are there other issues in iostreams that need to be mentioned?
Arthur Tchaikovsky
Your most recent replies have been getting somewhat inflamatory. I think you should take a break.
Nicol Bolas
On Tuesday, November 20, 2012 2:23:26 AM UTC-8, Arthur Tchaikovsky wrote:
Your most recent replies have been getting somewhat inflamatory. I think you should take a break.Fair enough, but interestingly, you didn't say anything to the guy who claimed that my suggestion is idiotic. I believe that either apply rules (of correct manners etc) to everyone and I am more than happy for it, or don't apply them at all. Saying just to one guy (me) to ease off and don't say anything to another guy why I believe presented far worse behavior than I (calling someone's suggestion "idiotic") is simply not fair. I would like you to note that I wasn't the first guy who posted "somewhat" inflammatory posts. Some people here are passive aggressive and this bad too yet you don't mind them doing so. And also, please note that I didn't use any offensive words, like commenting on someone's suggestion as "idiotic", for example.
"idiotic" is not an offensive word. More importantly, he called your suggestion idiotic, which is very different from calling you idiotic. Attacks against your suggestion are going to happen; that's what this discussion forum is about. Attacking you as a person is what we wouldn't allow; attacking a suggestion is perfectly reasonable.
Plus, the "idiotic" comment came after an extended period of discussion where you continued to use the same reasoning over and over, without showing the slightest sense that you understood the opposing argument. Nor did you display any recognition or understanding of the simple fact that the standard doesn't cover what you were talking about. Given the substance of the discussion, I think it was a perfectly reasonable assessment of your suggestion.

DeadMG

ma...@lysator.liu.se
If you remove the locale support then everything can be nicely inlined into nothingness and run in circles around printf. Remember that printf do parse the format string every time it runs so there is a pretty big wiggle room if that is what you wish to beat.
> There’s one real problem with this logic, and it is exactly why people
> suggest C-standard file IO. Iostreams violates a fundamental precept of
> C++: pay only for what you use.
Yes. See above.
> Consider this suite of benchmarks. This code doesn’t do file IO; it writes
> directly to a string. All it’s doing is measuring the time it takes to append
> 4-characters to a string. A lot. It uses a `char[]` as a useful control. It also
> tests the use of `vector<char>` (presumably `basic_string` would have
> similar results). Therefore, this is a solid test for the efficiency of the
> iostreams codebase itself.
>
> Obviously there will be some efficiency loss. But consider the numbers in
> the results.
My g++ is g++-4.7.2 on linux.
All tests run in about the same time save for 'putting binary data into a
vector<char> using back_inserter' which took about 6x the times of the rest and, contradicting your analysis, 'putting binary data directly into stringbuf' which took about half the time of the rest.If I were to remove the -O2 flag, telling the compiler to not optimize the code, then my test results show some similarity to yours (Worst case 15x) but who compiles benchmarks without optimization?
/MF
Nicol Bolas
On Thursday, November 22, 2012 11:11:43 PM UTC-8, ma...@lysator.liu.se wrote:
The performance problem of iostreams is the locale support.
If you remove the locale support then everything can be nicely inlined into nothingness and run in circles around printf.
Remember that printf do parse the format string every time it runs so there is a pretty big wiggle room if that is what you wish to beat.
> There’s one real problem with this logic, and it is exactly why people
> suggest C-standard file IO. Iostreams violates a fundamental precept of
> C++: pay only for what you use.
Yes. See above.
> Consider this suite of benchmarks. This code doesn’t do file IO; it writes
> directly to a string. All it’s doing is measuring the time it takes to append
> 4-characters to a string. A lot. It uses a `char[]` as a useful control. It also
> tests the use of `vector<char>` (presumably `basic_string` would have
> similar results). Therefore, this is a solid test for the efficiency of the
> iostreams codebase itself.
>
> Obviously there will be some efficiency loss. But consider the numbers in
> the results.
I did download the tests and ran them using g++ -O2 <filename>.cpp
My g++ is g++-4.7.2 on linux.
All tests run in about the same time save for 'putting binary data into avector<char>usingback_inserter' which took about 6x the times of the rest and, contradicting your analysis, 'putting binary data directly intostringbuf' which took about half the time of the rest.
If I were to remove the -O2 flag, telling the compiler to not optimize the code, then my test results show some similarity to yours (Worst case 15x) but who compiles benchmarks without optimization?
As stated in the page, the benchmarks were compiled with O3 on g++ 4.3.4. Thus, this is more likely due to more aggressive optimizations and/or better standard library implementations. Also, were you compiling as C++11 or as C++03?
/MF
Olaf van der Spek
The performance problem of iostreams is the locale support.
If you remove the locale support then everything can be nicely inlined into nothingness and run in circles around printf. Remember that printf do parse the format string every time it runs so there is a pretty big wiggle room if that is what you wish to beat.
Arthur Tchaikovsky
"idiotic" is not an offensive word
Arthur Tchaikovsky
On Tuesday, 20 November 2012 17:01:16 UTC, Nicol Bolas wrote:

Xeo

Ville Voutilainen
> After all, iteration is more natural to C++ than recursion
> (Alexandrescu,Modern C++ Design Generic Programming and Design Patterns
> Applied, chapter 3.5)
> One more prove that your logic is flawed (oopss, not flawed, idiotic as you
> don't find this word offending), that you're rude, that you're not
> interested in listening in others opinions etc. etc.
Or with std-proposals? Well, actually, please *don't* explain that, I
don't think
we want to hear.
Nicol Bolas
I think locales would be important for things like formatting currency, dates, times, etc. It could have its place in the formatting part of the API. The reason locales aren't often used is because... they're terrible. And unreliable. If we had Boost.Locale-style locales, then there'd be a better chance of them seeing use.
The problem with iostreams is that locales are part of the streambuf, not merely the formatting stream. The streambuf should be about basic "byte" input/output to/from a stream, not locale-specific constructs.
Arthur Tchaikovsky
"idiotic" is not an offensive word. More importantly, he called your suggestion idiotic, which is very different from calling you idiotic. Attacks against your suggestion are going to happen; that's what this discussion forum is about. Attacking you as a person is what we wouldn't allow; attacking a suggestion is perfectly reasonable.
Plus, the "idiotic" comment came after an extended period of discussion where you continued to use the same reasoning over and over, without showing the slightest sense that you understood the opposing argument. Nor did you display any recognition or understanding of the simple fact that the standard doesn't cover what you were talking about. Given the substance of the discussion, I think it was a perfectly reasonable assessment of your suggestion.
Please do explain what this response has to do with "the failures of iostreams"?

ri...@longbowgames.com
On Friday, November 23, 2012 12:49:38 PM UTC-5, Nicol Bolas wrote:
The problem with iostreams is that locales are part of the streambuf, not merely the formatting stream. The streambuf should be about basic "byte" input/output to/from a stream, not locale-specific constructs.
There's an argument to be made that locale formatting shouldn't be done in a stream at all, but rather be a collection of string operations.
DeadMG
Olaf van der Spek
--
Olaf
ri...@longbowgames.com
Where should newline translation be done?
I would argue that newline translation is a serialization issue, not a localization issue, and so is within the realm of I/O. Same goes with BOMs and byte order if we're dealing with Unicode streams. Number formats and padding, on the other hand, are harder to justify.
DeadMG
Olaf van der Spek
> Nowhere- or at least, if the user wants to do it, he should do it himself. I
> can see a potential argument for having a newline constant for different
> plats but when dealing with input, the various kinds of newline are really
> the user's problem. It's not like "Ignore \r and use \n" is a complex thing
> to do.
--
Olaf
DeadMG
ri...@longbowgames.com
However, even before Unicode, back when the only thing you had to worry about when reading/writing text files was how newlines were encoded, the standard library was already doing a pretty bad job, since it's fairly difficult to choose exactly which kind of newline you want to output.
It appears to me that there's three things we're dealing with here: raw I/O, I/O file format, and natural language localization. Locales currently couple the last two, and IOStreams currently couple all three.
My personal feeling is that we should have classes for reading/writing raw I/O, classes built on top of that for reading/writing text files (rather than the existing ios_base::bin solution), and the natural language localization should be string operations rather than I/O operations.
DeadMG
ri...@longbowgames.com
The primary problem with that is that "Text file" isn't actually a well-defined platform-independent concept because of the newlines.
Let's make it well defined :)
Ideally, an "oTextStream" would let you set the newline sequence, which encoding to use (minimally UTF-8, UTF-16LE, UTF-16BE, UTF32-LE, or UTF32BE), and whether or not to include a BOM. The newline sequence should *not* be decided by the platform, since it's not uncommon to want to write Unix-style text files in a Windows app, for instance.
An "iTextStream" should attempt to determine the encoding based on the BOM, or default to UTF-8 if no BOM is present. The user should also be able to explicitly say which encoding to use and whether or not to parse BOMs.
Lets talk more about the IOStream library as a whole. It would be really nice if it chained, like Boost.Iostreams. This would make the library flexible enough to support things like sockets, compression, and encryption.
I would be tempted to stay with an inheritance design so that to chain all you need to do is inherit from an iStream or oStream and hold a unique_ptr to the next iStream or oStream. In the case of something like iTextStream, this would give you enough flexibility to be constructed from a unique_ptr or just a filename. The filename version would really just be for convenience, but it would make it easier to teach new users how to read text files.
Some people in this thread are worried about the cost of virtual calls, so another option is to base the chaining on templates instead of inheritance. That would complicate the interface, and it would require that you either template-ize anything that deals with streams or to wrap your streams in some sort of stream_ref class, but it would probably be faster and more flexible.
The third option is to do it just like Boost.Iostreams, where you use inheritance but you only store a reference to your chained streams instead of taking ownership of them. This has the advantage of making it easier to adjust a filter after it's bound, but it means the user is responsible for the lifetime of each stream in the chain, which gets really annoying when you want to give a stream to an object, since it means you have to manually make sure the streams don't die before the object that's using them does. It would also preclude things like a text stream accepting a file path, since that would require the text stream to be able to optionally create its own source/sink.
Nicol Bolas
This is getting kind of off-topic (this is about finding out where iostreams went wrong, not how to fix it), but the way I invisioned text files was that they were filters that would be used on top of binary files as sources/sinks. You wouldn't need a separate sink for them. They scan text for a character; if they find '\n', they convert it into the platform-specific equivalent. BOMs would work more or less the same way, except that they only do the insertion once: the first time someone tries to write something. After that, they're inert.
DeadMG
set the newline sequence,
stay with an inheritance design
You wouldn't need a separate sink for them.
convert it into the platform-specific equivalent

Jean-Marc Bourguet
The primary problem with that is that "Text file" isn't actually a well-defined platform-independent concept because of the newlines.
All platforms have a notion of text file. One needs to have a C++ notion which is abstract enough that it can be used with the platform notion, not a C++ notion which is specified in such a way that there are platforms which may not implement C++ text files using their notion of text file.
Historically, OS have used notions of files which are far more than just a stream of byte. They may have stream oriented files, sequence of record files, key accessed record files,... lines in text file were numbered in some OS.
I'm not sure if that variety is still relevant but C and C++ IO were designed to handle them (for instance, spaces before end of line may disappear when rereading a text file, NUL characters may appear at end of file for binary files). Before designing a replacement which is unable to handle them, I'd suggest to be sure that they are no more relevant (start by looking at z/OS) and to bring people aware of the IO models of the OS you want to support early enough that you don't have to restart your design as not portable enough.
Yours,
--
Jean-Marc Bourguet
Nicol Bolas
Why do we have to support those?
I know it sounds silly to say, but iostream will continue to exist. Just as fopen does. If you're working in such a system and need those specific kinds of translations, I would suggest that the new system simply be able to use an iostreambuf as a sink/source.
Yours,
--
Jean-Marc Bourguet
ri...@longbowgames.com
We have iterators for that. Hell, you can do that right now.
Let's say I have a compressed log file that I want to read one line at a time. With chaining streams, you could do this:
ITextStream stream(make_unique<ICompressedStream>(make_unique<IFileStream>("log.gz")));
while(s = getline(stream))
// Do something
Try doing that with iterators. The only way you could do it is by loading the entire file into memory, or by using those 'silly' input iterators.
set the newline sequence,And if I want to support multiple? Does that mean I have to be precognitive?
You'll notice I only suggested setting the newline sequence for output streams. For input streams, a sane default would be to swallow \r characters, unless the user is expecting a certain sequence.
So we can continue to feel the pain of multiple inheritance?
std::iostream is the only part of the existing library that uses multiple inheritance, and with a filter design I'm not 100% convinced that multiple inheritance is necessary. Even so, I've never experience any pain using std::iostream; not that I use it often.
On Saturday, November 24, 2012 2:07:08 PM UTC-5, Jean-Marc Bourguet wrote:
I'm not sure if that variety is still relevant but C and C++ IO were designed to handle them (for instance, spaces before end of line may disappear when rereading a text file, NUL characters may appear at end of file for binary files). Before designing a replacement which is unable to handle them, I'd suggest to be sure that they are no more relevant (start by looking at z/OS) and to bring people aware of the IO models of the OS you want to support early enough that you don't have to restart your design as not portable enough.
On Saturday, November 24, 2012 12:51:26 PM UTC-5, Nicol Bolas wrote:
this is about finding out where iostreams went wrong, not how to fix it
Okay, I'll 'answer in the form of a question', as it were. Here's my list:
* Not designed with filters in mind.
* Newline format is defined by the platform rather than the programmer.
* No support for UTF.
* Because binary mode is set with ios_base::bin instead of with a different type, passing streams as parameters is unsafe.
* Locales conflate encoding with localization.
* You have no idea what you get with a locale, and defining your own is not trivial.
* Since localization and formatting is tied to streams, you can't localize or format a value to a string without going through a stream.
And a new one:
* Not designed with non-blocking streams in mind. This is necessary for network sockets, but would also be nice to have for stdio.
Jean-Marc Bourguet
On Saturday, November 24, 2012 11:07:08 AM UTC-8, Jean-Marc Bourguet wrote:I'm not sure if that variety is still relevant but C and C++ IO were designed to handle them (for instance, spaces before end of line may disappear when rereading a text file, NUL characters may appear at end of file for binary files). Before designing a replacement which is unable to handle them, I'd suggest to be sure that they are no more relevant (start by looking at z/OS) and to bring people aware of the IO models of the OS you want to support early enough that you don't have to restart your design as not portable enough.
Why do we have to support those?
Personally, I don't care. I consider the platforms I'm sure would have had problems as no more relevant if they ever were. The more relevant platform I know which could have problems is z/OS, but I don't know enough about it to be sure.
But if this end up in a formal proposal and if my understanding of the committee dynamic is right, it'll be confronted to people who are thinking in the other direction and will ask why we should make a standard only partially implementable on these platforms which were supported. Especially if the platforms are still relevant, but possibly even if they aren't. See what happened with the proposition to remove trigraphs. Its better to have a design which doesn't have foreseeable objections, or at least to be prepared to answer them.
Yours,
--
Jean-Marc Bourguet
DeadMG
Try doing that with iterators. The only way you could do it is by loading the entire file into memory, or by using those 'silly' input iterators.
You'll notice I only suggested setting the newline sequence for output streams. For input streams, a sane default would be to swallow \r characters, unless the user is expecting a certain sequence.
ri...@longbowgames.com
I agree that input iterators are really just functions in disguise, but they do work and not badly either. There is no reason why an input-iterator based solution could not work just fine. More relevantly, an input-iterator based solution would actually be remotely generic- I could decompress a file I had already loaded into memory, for example.
Ah, input iterators aren't so silly now, are they?
You can always adapt an input iterator to a stream of vice versa, but iterators are awkward in this case for three reasons:
1) The end of an input_iterator is a wasteful hack.
2) You can't differentiate between 'no data' and 'end of data'.
3) Iterators don't take ownership, so you have additional lifetime management.
Here's what the code would look like with iterators:
ifstream fin("log.gz");
istream_iterator it1Start(fin), it1End();
ICompressorIterator it2Start(it1Start), it2End(it1End);
IPlaintextIterator it3Start(it2Start), it3End(it2End);
while(s = getline(it3Start, it3End))
// Do something
And because iterators don't take ownership of the thing they're iterating (at least not idiomatically), you can't give it3Start/End to an object without ensuring that fin, it1Start/End, and it2StartEnd all outlive the object in question.
It's much easier to go the other way:
Like many things, the situation gets a lot better if you use ranges instead of iterators. Why? It's not because streams are only useful for 'reading and writing to external sources'. It's because one-directional ranges and streams are effectively the same thing.
Now, completely abolishing streams and using input/output ranges is an interesting idea. It's mostly just a naming issue, but assuming the standard library adopted range-based algorithms, it would make things more consistent and interoperable. It would look like this:
auto range = make_iplaintext_range(make_icompressedrange_range(make_ifile_range("log.gz")));
while(s = getline(range))
// Do something
Not bad. Unfortunately, a function expecting a range like that would look like this:
void foo(IPlaintextRange<ICompressedRange<IFileRange>> range);
So you would either have to templatize anything that uses file streams, or make wrapper objects for ranges. Not the end of the world.
You'll notice I only suggested setting the newline sequence for output streams. For input streams, a sane default would be to swallow \r characters, unless the user is expecting a certain sequence.You have no idea what the user is expecting. Only they know that.
Oh for heaven's sake, are you seriously taking me to task for suggesting that users who use line endings other than \n, \n\r, or \r\n, would have to stoop so low as to override a default option?
DeadMG
Oh for heaven's sake, are you seriously taking me to task for suggesting that users who use line endings other than \n, \n\r, or \r\n, would have to stoop so low as to override a default option?
1) The end of an input_iterator is a wasteful hack.
2) You can't differentiate between 'no data' and 'end of data'.
3) Iterators don't take ownership, so you have additional lifetime management.
It's because one-directional ranges and streams are effectively the same thing.
ri...@longbowgames.com
First, a couple things I do want to respond to:
On Sunday, November 25, 2012 10:23:59 AM UTC-5, DeadMG wrote:
Well, yes. I'm saying that the stream should not eat data unless explicitly asked for.
By using a plaintext stream you're already asking for translation. If you want all the carriage returns, you probably want a binary stream. If you want a stream that handles UTF translation and doesn't handle newline translation, then you're certainly in the minority, and overriding a default isn't the end of the world.
2) You can't differentiate between 'no data' and 'end of data'.I don't see the difference. In either case, there is no more data to be had.
Think about non-blocking streams, like network sockets. There's a difference between reaching the end of the stream and the rest of the stream not being ready. This is one of the things that ranges typically don't deal with.
If we're talking about replacing streams with file ranges, I think it would be worth consideration that we give a ready() function to all input ranges, and a flush() option to all output ranges. This can even be important for something like compressing and decompressing a file, since you might have to read/write a large amount of data before the next block is ready.
DeadMG
Okay, you misunderstood some of the stuff I was saying about iterators, but I'm pretty sure it's moot. We both agree that ranges are a superior solution to iterators, and, while our confidence levels differ, we both think ranges have the potential for making good streams, so we can stop talking about iterators now, right?

robertmac...@gmail.com
a) The std::binary flag was necessary to avoid the i/o stream from munching characters. Unfortunatly, there is no way to inquire (e.g. i/ostream.is_binary() ) to determine how a stream has been opened so that certain user errors can be detected.
b) the << and >> interfaces turned out to be performance killers. But the functionality provided by these operators was totally unused. So later versions of the library just used the streambuf interface directly. The constructor for a binary archive can take as an argument either a streambuf or a stream. If passed a stream, the associated streambuf is used directly. This results in a huge performance boost # 1.
c) unfortunately, the streambuf implements the codecvt interface. A performance hit and not a good match for binary i/o. So I made a custom codecvt facet which does nothing. Another performance improvement.
So.....
if you want close to raw I/O speed without the stream features - do these things. If you want to make it convenient to use, derive your own variant from stream and/or streambuf and implement these features in your own variant. This would give you today most of what you need - close to max performance with simple interface AND portable code. Less functionality though - of course.
It would be very interesting in this discussion if someone were to do this and re-run the bench marks. (also increase the default buffer size).
Robert Ramey
DeadMG
Beman Dawes
> a) The std::binary flag was necessary to avoid the i/o stream from munching
> characters. Unfortunatly, there is no way to inquire (e.g.
> i/ostream.is_binary() ) to determine how a stream has been opened so that
> certain user errors can be detected.
streams to improve error detection.
If you write up an issue with the motivation for
i/ostream.is_binary(), and the suggested P/R, I'll champion it with
the LWG.
--Beman
robertmac...@gmail.com
On Sunday, November 25, 2012 8:45:25 AM UTC-8, DeadMG wrote:
The binary and text streams would likely comprise separate classes, so there'd be no need for a flag. As for operator<< and codecvt_facet, they are almost certain to be removed.
I'm not sure if this is a reply to my post (Am I the only one who finds he operation of the forum a little ... funky?).
Assuming it is.
I'm only suggesting that many of the issues raised in this thread can be addressed by modest (and one time) adjustments to usage of the current library. Phrasing it a different way - the current library provides means to work around or diminish the complaints listed here. It's clear to me that the current library was designed to permit exactly this usage. So if someone want's to make a simple library for boost "raw_i/ostream" which would set things up, I'm sure it would be looked at. I would be very curious to see how speed compares with the other examples here.
In short, I think that before starting design of some alternative library, one should be sure that all other alternatives should be explored first - and I don't think they have been.
Robert Ramey
robertmac...@gmail.com
what's a P/R? and where would one "write up" such an issue?
Robert Ramey
--Beman
DeadMG
Jean-Marc Bourguet
I' ve read through this thread and would like to mention a few points. This information is fruit of my experience in implementing the boost serialization library. For "binary" archives performance was he supreme consideration. At the same time I wanted/needed it to be built on top of the standard library constructs.
a) The std::binary flag was necessary to avoid the i/o stream from munching characters. Unfortunatly, there is no way to inquire (e.g. i/ostream.is_binary() ) to determine how a stream has been opened so that certain user errors can be detected.
Never though about that, but I'd have been in situations where I'd have used one if it had been available.
b) the << and >> interfaces turned out to be performance killers. But the functionality provided by these operators was totally unused. So later versions of the library just used the streambuf interface directly. The constructor for a binary archive can take as an argument either a streambuf or a stream. If passed a stream, the associated streambuf is used directly. This results in a huge performance boost # 1.
<< and >> are about providing a formatting interface. There is an unformated API to stream, but like you I usually resort to streambuf as I find it more convenient (but I usually use only streams in my public interface and use its error reporting interface). One aspect I don't like about streambuf from a performance POV is that sgetn and sputn directly call xsgetn and xsputn which are virtual functions even if there is room in the corresponding area, and that prevent them to be inlined when used with small length.
c) unfortunately, the streambuf implements the codecvt interface. A performance hit and not a good match for binary i/o. So I made a custom codecvt facet which does nothing. Another performance improvement.
Wouldn't imbuing locale::classic() enough? That's what I do on my binary stream but I've never though about measuring if there was a win in imbuing a custom codecvt.
Yours,
--
Jean-Marc Bourguet
robertmac...@gmail.com
On Sunday, November 25, 2012 10:09:21 AM UTC-8, Jean-Marc Bourguet wrote:
Le dimanche 25 novembre 2012 17:26:15 UTC+1, robertmac...@gmail.com a écrit :I' ve read through this thread and would like to mention a few points. This information is fruit of my experience in implementing the boost serialization library. For "binary" archives performance was he supreme consideration. At the same time I wanted/needed it to be built on top of the standard library constructs.
a) The std::binary flag was necessary to avoid the i/o stream from munching characters. Unfortunatly, there is no way to inquire (e.g. i/ostream.is_binary() ) to determine how a stream has been opened so that certain user errors can be detected.
Never though about that, but I'd have been in situations where I'd have used one if it had been available.
b) the << and >> interfaces turned out to be performance killers. But the functionality provided by these operators was totally unused. So later versions of the library just used the streambuf interface directly. The constructor for a binary archive can take as an argument either a streambuf or a stream. If passed a stream, the associated streambuf is used directly. This results in a huge performance boost # 1.
<< and >> are about providing a formatting interface. There is an unformated API to stream, but like you I usually resort to streambuf as I find it more convenient (but I usually use only streams in my public interface and use its error reporting interface). One aspect I don't like about streambuf from a performance POV is that sgetn and sputn directly call xsgetn and xsputn which are virtual functions even if there is room in the corresponding area, and that prevent them to be inlined when used with small length.
note that one is permitted to make his own streambuf implemenation as well. Another path that should be exhausted before starting to think about a whole new library. I don't think that in my code I actually use these put/get functions - but I could be wrong, I forget.
I was responding to the suggestion that in many cases they aren't convenient to use and any other alternative could dispense with these. My view is that you don't have to use them and if you want to make your own "raw_ostream" it doesn't have to support them if you feel this way. My real point is that it's premature to think about a new library when the possibilities of the current one haven't been exhausted. It's also possible that attempts to make a "raw_i/ostream" class might work just fine except for some small thing that could be addressed with a small tweak to the current library - implementation of is_binary() is would be an example.
c) unfortunately, the streambuf implements the codecvt interface. A performance hit and not a good match for binary i/o. So I made a custom codecvt facet which does nothing. Another performance improvement.
Wouldn't imbuing locale::classic() enough? That's what I do on my binary stream but I've never though about measuring if there was a win in imbuing a custom codecvt.
lol - truth is I don't know the answer to this. I did this because I thought it would make a difference. I likely concluded this by tracing into library code. It was an easy fix so I implemented and forgot about it.
Too re-iterate my point,
a) the main concern of the original post was that streams have performance issues and that a new library might be needed to address this.
b) Another (secondary concern) was the interface.
c) My view is that these ideas should be "Tested" by making some derivations/ehancements to the current libraries to address these concerns. Now that we have things like variadic templates, there is much opportunity in this area. Boost is the perfect place to post any such enhancements and or derivations.
d) So it's premature to start the haggling over a stream replacement.
Robert Ramey
Nicol Bolas
On Sunday, November 25, 2012 12:26:32 PM UTC-8, robertmac...@gmail.com wrote:
On Sunday, November 25, 2012 10:09:21 AM UTC-8, Jean-Marc Bourguet wrote:Le dimanche 25 novembre 2012 17:26:15 UTC+1, robertmac...@gmail.com a écrit :I' ve read through this thread and would like to mention a few points. This information is fruit of my experience in implementing the boost serialization library. For "binary" archives performance was he supreme consideration. At the same time I wanted/needed it to be built on top of the standard library constructs.
a) The std::binary flag was necessary to avoid the i/o stream from munching characters. Unfortunatly, there is no way to inquire (e.g. i/ostream.is_binary() ) to determine how a stream has been opened so that certain user errors can be detected.
Never though about that, but I'd have been in situations where I'd have used one if it had been available.
b) the << and >> interfaces turned out to be performance killers. But the functionality provided by these operators was totally unused. So later versions of the library just used the streambuf interface directly. The constructor for a binary archive can take as an argument either a streambuf or a stream. If passed a stream, the associated streambuf is used directly. This results in a huge performance boost # 1.
<< and >> are about providing a formatting interface. There is an unformated API to stream, but like you I usually resort to streambuf as I find it more convenient (but I usually use only streams in my public interface and use its error reporting interface). One aspect I don't like about streambuf from a performance POV is that sgetn and sputn directly call xsgetn and xsputn which are virtual functions even if there is room in the corresponding area, and that prevent them to be inlined when used with small length.
note that one is permitted to make his own streambuf implemenation as well. Another path that should be exhausted before starting to think about a whole new library. I don't think that in my code I actually use these put/get functions - but I could be wrong, I forget.
I was responding to the suggestion that in many cases they aren't convenient to use and any other alternative could dispense with these. My view is that you don't have to use them and if you want to make your own "raw_ostream" it doesn't have to support them if you feel this way. My real point is that it's premature to think about a new library when the possibilities of the current one haven't been exhausted. It's also possible that attempts to make a "raw_i/ostream" class might work just fine except for some small thing that could be addressed with a small tweak to the current library - implementation of is_binary() is would be an example.
The performance tests were designed to see what the cost of the interface is, not the underlying implementation. The streambuf interface is sufficiently esoteric to me that I don't really understand how to implement one, but if a basic_stringbuf implementation (which should be nothing more than a wrapper around basic_string) is an order of magnitude less efficient than just doing basic_string::push_back, then that's not a problem that's going to be solved with a "small tweak."
The problem isn't basic_stringbuf; the problem is basic_streambuf itself. It's the virtual interface with how characters are written to the buffer that's causing the performance issue. You can't fix that with a different version of basic_stringbuf.
c) unfortunately, the streambuf implements the codecvt interface. A performance hit and not a good match for binary i/o. So I made a custom codecvt facet which does nothing. Another performance improvement.
Wouldn't imbuing locale::classic() enough? That's what I do on my binary stream but I've never though about measuring if there was a win in imbuing a custom codecvt.
lol - truth is I don't know the answer to this. I did this because I thought it would make a difference. I likely concluded this by tracing into library code. It was an easy fix so I implemented and forgot about it.
Too re-iterate my point,
a) the main concern of the original post was that streams have performance issues and that a new library might be needed to address this.
b) Another (secondary concern) was the interface.
c) My view is that these ideas should be "Tested" by making some derivations/ehancements to the current libraries to address these concerns.
From the given performance tests, it would appear that "derivations/ehancements(sic)" will be insufficient to resolve this problem. It's an interface problem, and you can't solve an interface problem by continuing to use the same interface.

Rob Meijer
The Iostreams library in C++ has a problem. We have real, reasonable, legitimate C++ professional, who like C++ and use modern C++ idioms, telling people to not use iostreams. This is not due to differing ideas on C++ or C-in-classes-style development, but the simple practical realities of the situation.--
This kind of thing is indicative of a real problem in iostreams. In order to eventually solve that problem, we must first identify exactly what the problems are. This discussion should be focused on exactly that: identifying the problems with the library. Once we know what the real problems are, we can be certain that any new system that is proposed addresses them.
Note that this is about problems within iostreams. This is not about a list of things you wish it could do. This is about what iostreams actually tries to do but fails at in some way. So stuff like async file IO doesn’t go here, since iostreams doesn’t try to provide that.
Feel free to add to this list other flaws you see in iostreams. Or if you think that some of them are not real flaws, feel free to explain why.
Performance
This is the big one, generally the #1 reason why people suggest using C-standard file IO rather than iostreams.
Oftentimes, when people defend iostreams performance, they will say something to the effect of, “iostreams does far more than C-standard file IO.” And that’s true. With iostreams, you have an extensible mechanism for writing any type directly to a stream. You can “easily” write new streambuf’s that will allow you to (via runtime polymorphism) be able to work with existing code, thus allowing you to leverage your file IO for other forms of IO. You could even use a network pipe as an input or output stream.
There’s one real problem with this logic, and it is exactly why people suggest C-standard file IO. Iostreams violates a fundamental precept of C++: pay only for what you use.
Consider this suite of benchmarks. This code doesn’t do file IO; it writes directly to a string. All it’s doing is measuring the time it takes to append 4-characters to a string. A lot. It uses a `char[]` as a useful control. It also tests the use of `vector<char>` (presumably `basic_string` would have similar results). Therefore, this is a solid test for the efficiency of the iostreams codebase itself.
Obviously there will be some efficiency loss. But consider the numbers in the results.
The ostringstream is more than full order of magnitude slower than the control. It’s almost 100x in some cases. Note that it’s not using << to write to the stream; it’s using `ostream::write()`.
Note that the vector<char> implementations are fairly comparable to the control, usually being around 1x-4x the speed. So clearly this is something in ostringstream.
Now, you might say that one could use the stringbuf directly. And that was done. While it does improve performance over the ostringstream case substantially (generally half to a quarter the performance), it’s still over 10x slower than the control or most vector<char> implementations.
Why? The stringbuf operations ought to be a thin wrapper over std::string. After all, that’s what was asked for.
Where does this inefficiency come from? I haven’t done any extensive profiling analysis, but my educated guesses are from two places: virtual function overhead and an interface that does too much.
ostringstream is supposed to be able to be used as an ostream for runtime-polymorphism. But here’s where the C++ maxim comes into play. Runtime-polymorphism is not being used here. Every function call should be able to be statically dispatched. And it is, but all of the virtual machinery comes from within ostringstream.
This problem seems to come mostly from the fact that basic_ostream, which does most of the leg-work for ostringstream, has no specific knowledge of its stream type. Therefore it's always a virtual call. And it may be doing many such virtual calls.
You can achieve the same runtime polymorphism (being able to overload operator<< for any stream) by using a static set of stream classes, tightly coupled to their specific streambufs, and a single “anystream” type that those streams can be converted into. It would use std::function-style type erasure to remember the original type and feed function calls to it. It would use a single function call to initiate each write operation, rather than what appears to be many virtual calls within each write.
Then, there’s the fact that streambuf itself is overdesigned. stringbuf ought to be a simple interface wrapper around a std::string, but it’s not. It’s a complex thing. It has locale support of all things. Why? Isn’t that something that should be handled at the stream level?
This API has no way to get a low-level interface to a file/string/whatever. There’s no way to just open a filebuf and blast the file into some memory, or to shove some memory out of a filebuf. It will always employ the locale machinery even if you didn’t ask for it. It will always make these internal virtual calls, even if they are completely statically dispatched.
With iostreams, you are paying for a lot of stuff that you don’t frequently use. At the stream level, it makes sense that you’re paying for certain machinery (though again, some way to say that you’re not using some of it would be nice). At the buffer level, it does not, since that is the lowest level you’re allowed to use.
Utility
While performance is the big issue, it’s not the only one.
The biggest selling point for iostreams is the ability to extend its formatted writing functionality. You can overload operator<< for various types and simply use them. You can’t do that with fprintf. And thanks to ADL, it will work just fine for classes in namespaces. You can create new streambuf types and even streams if you like. All relatively easily.
Here’s the problem, and it is admittedly one that is subjective: printf is really nice syntax.
It’s very compact, for one. Once you understand the basic syntax of it, it’s very easy to see what’s going on. Especially for complex formatting. Just consider the physical size difference between these two:
snprintf(..., “0x%08x”, integer);stream << "0x" << std::right << std::hex << std::setw(8) << iVal << std::endl;It may take a bit longer to become used to the printf version, but this is something you can easily look up in a reference.
Plus, it makes it much easier to do translations on formatted strings. You can look the pattern string up in a table that changes from language to language. This is rather more difficult in iostreams, though not impossible. Granted, pattern changes may not be enough, as some languages have different subject/verb/object grammars that would require reshuffling patterns around. However, there are printf-style systems that do allow for reshuffling, whereas no such mechanism exists for iostream-style.
C++ used the << method because the alternatives were less flexible. Boost.Format and other systems show that C++03 did not really have to use this mechanism to achieve the extensibility features that iostreams provide.
What do you think? Are there other issues in iostreams that need to be mentioned?
robertmac...@gmail.com
On Sunday, November 25, 2012 12:52:45 PM UTC-8, Nicol Bolas wrote:
From the given performance tests, it would appear that "derivations/ehancements(sic)" will be insufficient to resolve this problem.
I don't think the tests show that.
It's an interface problem, and you can't solve an interface problem by continuing to use the same interface.
I guess that's where we disagree. Of course without an alternative interface to test it's really hard to know.
Robert Ramey
Nicol Bolas
On Sunday, November 25, 2012 2:16:48 PM UTC-8, robertmac...@gmail.com wrote:
On Sunday, November 25, 2012 12:52:45 PM UTC-8, Nicol Bolas wrote:
From the given performance tests, it would appear that "derivations/ehancements(sic)" will be insufficient to resolve this problem.
I don't think the tests show that.
Well, how else can you explain it? vector::push_back is over 10x faster than doing the equivalent task with basic_stringbuf directly when they are doing the exact same thing. There are only two possible conclusions one could draw from this:
1) two separate `basic_stringbuf` implementations were written by complete morons.
2) the basic_stringbuf interface creates substantial inefficiencies.
#1 seems highly unlikely, since the same "complete morons" who wrote `basic_stringbuf` also wrote `vector`. And again, it wasn't an isolated incident: the two most popular implementations of the C++ standard library (VC's library and GCC's libstdc++) have the exact same performance problem. If there were a competitive implementation, odds are good that one of them would have found it.
So how do you explain it?
It's an interface problem, and you can't solve an interface problem by continuing to use the same interface.
I guess that's where we disagree. Of course without an alternative interface to test it's really hard to know.
It was tested against an alternate interface: `std::vector`. And `char[]`, for that matter. It lost against both of them. Badly.
robertmac...@gmail.com
On Sunday, November 25, 2012 3:57:03 PM UTC-8, Nicol Bolas wrote:
On Sunday, November 25, 2012 2:16:48 PM UTC-8, robertmac...@gmail.com wrote:
On Sunday, November 25, 2012 12:52:45 PM UTC-8, Nicol Bolas wrote:
From the given performance tests, it would appear that "derivations/ehancements(sic)" will be insufficient to resolve this problem.
I don't think the tests show that.
Well, how else can you explain it? vector::push_back is over 10x faster than doing the equivalent task with basic_stringbuf directly when they are doing the exact same thing.
The stream implementation considers codeconvert, /r/n translation etc, etc. Even though this functionality isn't used. string keeps track of the length even though that functionality isn't used in the test. char [] doesn't have to keep track of anything. The tests show that the implementation of stream is much slower for simple functionality than char []. This suggests that it might be worth spending some effort in the implementation of streams when the extended functionality isn't needed. That's what I was suggesting.
I haven't seen any proposals for alternative interface so I can't comment on them.
Robert Ramey
Beman Dawes
big enough problem to merit its own paper, so a library issue is all
that is required. See http://isocpp.org/std/submit-a-library-issue for
how to submit one.
Also see http://cplusplus.github.com/LWG/lwg-active.html for sample issues.
--Beman
Nicol Bolas
On Sunday, November 25, 2012 5:40:58 PM UTC-8, robertmac...@gmail.com wrote:
On Sunday, November 25, 2012 3:57:03 PM UTC-8, Nicol Bolas wrote:
On Sunday, November 25, 2012 2:16:48 PM UTC-8, robertmac...@gmail.com wrote:
On Sunday, November 25, 2012 12:52:45 PM UTC-8, Nicol Bolas wrote:
From the given performance tests, it would appear that "derivations/ehancements(sic)" will be insufficient to resolve this problem.
I don't think the tests show that.
Well, how else can you explain it? vector::push_back is over 10x faster than doing the equivalent task with basic_stringbuf directly when they are doing the exact same thing.
The stream implementation considers codeconvert, /r/n translation etc, etc.
Does it? He used basic_stringbuf directly. While locale support is in streambuf, any end-line translation is not.
Furthermore, that's part of the point. You can't just rip that stuff out, because the system requires it. To remove it would be a non-backwards-compatible change to a system that's been more or less stable for over 14 years now. streambuf does locale and codecvt stuff; it can't not do that without breaking people's code.
Breaking changes are allowed, but you generally need to show a serious need for them, as well as a reason why it can't be done in a non-breaking way. As well as doing a study of how widespread the breakage would be.
You're much more likely to get a proposal actually accepted if it doesn't break things.

0xcdc...@gmx.at
The Iostreams library in C++ has a problem. We have real, reasonable, legitimate C++ professional, who like C++ and use modern C++ idioms, telling people to not use iostreams. ...
(Somehow I think this whole thread shopuld be moved to [ISO C++ Standard - Discussion ] but while we're here ...)
I assume that many have felt the pain of IOstreams at some point, and I have recently found a nice question on SO:
What serious alternatives exist for the IOStream library? (besides cstdio) -
http://stackoverflow.com/q/6171360/321013There's really two points I want to highlight from there:
1) quoting the OP: "[iostreams is] ... [e]ntirely too complicated to a client. If you use only what comes with the standard library it's great, but attempting to extend things is next to impossible. I read the entire "Standard C++ IOStreams and Locales" book -- the only book seemingly available on the topic -- twice -- and I still don't know what's going on."
2) The mentioned FastFormat library - While the FastFormat library has it's quirks, and I never used it in production, it's at least one serious attempt to implement something.

nae...@gmail.com
See what happened with the proposition to remove trigraphs.
What proposal? (And what was done wrong?) I've been thinking of trying to propose that they at least be (optionally) disabled by default. (Perhaps with an interim period in which they just be deprecated by default, though it seems rather as though they effectively are already. There would probably have to be a special "#pragma" to enable them, with an alternate "??=pragma" spelling despite trigraphs being disabled.)

eulo...@live.com
For example, how could I read std::time_t correctly? Use what? "%d"? "%u"? "%llu"? "%lld"? "%"PRIu32?
eulo...@live.com
在 2012年11月18日星期日UTC+8上午3时36分37秒,Nicol Bolas写道:
Jean-Marc Bourguet

{kind=link}
fritzpoll
That said, it is all very well to complain and compile a list of grievances, but we need a) some solutions and b) a sample implementation of the same. I think the answer in a new library would be to take the functionality of iostreams and split it up, so that you have something like:
- streams classes that are sources and/or sinks - these conceptually simply stream byte data from one place to another. So a file stream would simply take in the data provided and write out the data into the file, a string stream would do the same but store it in a string, etc. As now, you'd have separate classes relating to different source/sink types. These would all inherit from a single base class, largely to account for the use case where one may wish to store pointers to multiple streams of different types in a container to loop over during processing.
- More string formatting functions. C++11 extended the <string> header to include conversions from most primitives into a string/wstring, but further formatting functions could be included by default - these would need to be written for unicode types as well, I suspect. I'm not sure exactly how to start with the list of functionality required to replicate what one can achieve with iostreams, but perhaps other can offer guidance.
Other aspects such as Unicode/Localisation should be dealt with by other libraries - it doesn't seem like it should be the purpose of a stream to do this, and not every user of the streaming library should have to pay the cost by default, as at present. It seems perverse at the moment that one can improve the performance of iostreams only by introducing more complex code - the inverse of the more typical equation where more code => more functionality.
If we can pin down/agree a more suitable interface, I'm certainly happy to help provide a sample implementation for testing and improvement. My ideas above can be discarded if they are not appropriate - I'm not wedded to them, but I thought they might provide a hook for criticism!