Clusters instead of std::list and std::map!

sven...@web.de


Gašper Ažman
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/cf119955-9bde-46f6-84bd-01aabf5b4a6d%40isocpp.org.

Bengt Gustafsson

Martin Moene
I hope my solution will make it into the standard-library!
Best regards
Martin

Sven Bieg
Hello Mr. Gustafsson,
in fact my algorithm doesn’t build a binary tree, it builds a pyramid, 50 times more steep than the real ones! Have You had a look at my homepage? There is a short overview how it works. I’m from Germany, please excuse my bad english!
Best regards,
Sven Bieg

Magnus Fromreide
> Hello Mr. Gustafsson,
>
> in fact my algorithm doesn’t build a binary tree, it builds a pyramid, 50 times more steep than the real ones! Have You had a look at my homepage? There is a short overview how it works. I’m from Germany, please excuse my bad english!
See e.g. wikipedia: https://en.wikipedia.org/wiki/B-tree
/MF
> Best regards,
>
> Sven Bieg
>
> --
> You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
> To post to this group, send email to std-pr...@isocpp.org.
Sven Bieg
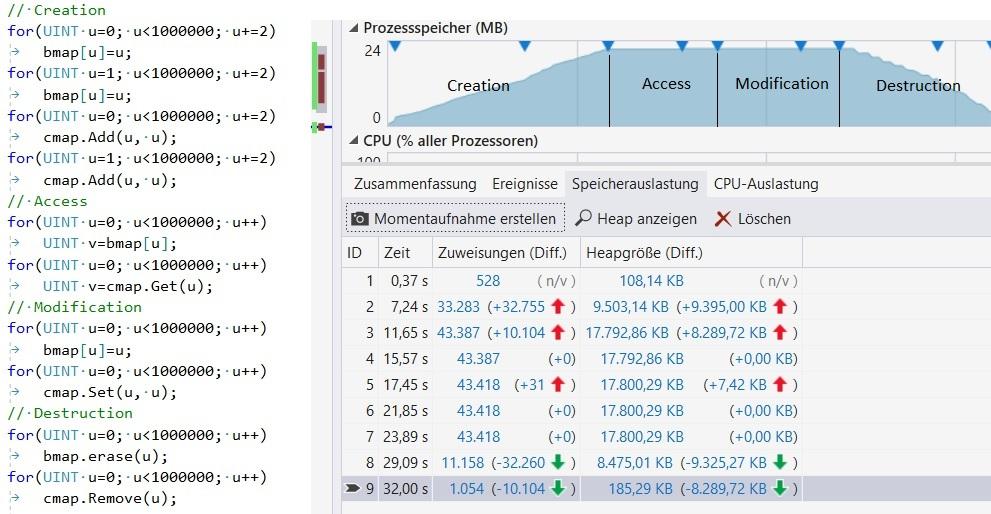
I've done a comparison to std::list and std::map. You can find some diagrams at
http://svenbieg.azurewebsites.net/Clusters/List
and
http://svenbieg.azurewebsites.net/Clusters/Index
I don't know if Microsoft has it's own Implementation, but i get much better results using Clusters!
sven...@web.de
Gašper Ažman
1) The iterator stores the position for each level. Because the cluster starts with only one level and the number can grow, it is allocated.I'm not sure what You mean with iterator-stability, iteration ain't critical.
If the position on one level reaches the end, it is reset to zero and theposition of the parent is increased. The most critical process is the insertion. With a group-size of 100 items i have to move at most 10.000 itemson the first level. If new groups have to be allocated, the maximum number is the number of levels, while the number of items grows exponential.The groups are half-full at least, because an empty group is created only when all groups on a level are full,and the groups are combined with their neighbors when possible.
2) You need to use new and delete, wich can be overloaded. The entries are moved in the structure without calling their con-/destructors.
3) Every time an entry is removed, the parent checks, if the group can be combined with the neighbor-groups. The groups are half-full at minimum.
4) My algorithm works a little bit different. I have item-groups on the lowest level, and parent-groups on higher levels.The parent-group fails to insert an item, it splits the child-group when possible. If the root is full and can not be split,a new root is created.
5) In the index, the items are in ascending order. It references the first and the last entry. I think, this is what You mean.
6) An exception can be thrown, every time memory needs to be allocated. I'm not using exceptions, only assertion for debugging.
I'm using Visual Studio and the Windows Runtime environment. I'm not using the standard-library directly.
Maybe You can help me to write a standard-implementation?
Best regards,Sven
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/09f8e2a6-871c-4474-b887-1cfec7d3a7d0%40isocpp.org.
sven...@web.de
Bengt Gustafsson
Den söndag 14 oktober 2018 kl. 05:58:03 UTC+2 skrev sven...@web.de:
Hello Gasper,like You said, i created a new list-class today wich is more standard-conform. In fact i only put things together and renamed everything, i did no changes to the code itself.To the questions again:1) I now understand what You mean with iterator-stability. The iterators have to stay valid, when another iterator changes the list.I didn't implement this, but it is possible. The list would have to keep track of all iterators for this, maybe a limited number ofsimultaneous iterators.
2) The allocator is easy to integrate, i think. I will leave this away, because i have integrated a custom allocator already.A number of 100 items is allocated uninitialized in each item-group.
sven...@web.de
sven...@web.de

Bryce Adelstein Lelbach aka wash
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/3c8fb242-bdde-1ee8-878f-94bfb3ae084c%40eld.physics.LeidenUniv.nl.
sven...@web.de
Bryce Adelstein Lelbach aka wash
I don't think so, sorry!
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/5888e4a7-3ed3-4759-969e-30211027e7b0%40isocpp.org.
sven...@web.de
Gašper Ažman
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/CAP3wax_V-42h6fBD3LvEFWfGGAcBF1nf0NPmMbAKN%2B3QzKg1eA%40mail.gmail.com.
Gašper Ažman
sven...@web.de
Bryce Adelstein Lelbach aka wash
--
You received this message because you are subscribed to the Google Groups "ISO C++ Standard - Future Proposals" group.
To unsubscribe from this group and stop receiving emails from it, send an email to std-proposal...@isocpp.org.
To post to this group, send email to std-pr...@isocpp.org.
To view this discussion on the web visit https://groups.google.com/a/isocpp.org/d/msgid/std-proposals/8cd19c2f-3a6d-4943-b18e-625b6cc6ee95%40isocpp.org.

holme...@gmail.com
sven...@web.de
nice to meet You! I'm looking forward to Your issues on GitHub. I've seen a chart of the stadard-comittee today, where SG14 is part of. There is another team SG21, working with databases. They should know about Clusters, too! I actually was writing a database, when the algorithm began becoming intersting for memory-management. There is a lot of work to do, but not today. Today is party-time!
Mit freundlichen Grüßen,
Sven

Jens Maurer
> Hey Odin,
>
> nice to meet You! I'm looking forward to Your issues on GitHub. I've seen a chart of the stadard-comittee today, where SG14 is part of. There is another team SG21, working with databases. They should know about Clusters, too! I actually was writing a database, when the algorithm began becoming intersting for memory-management. There is a lot of work to do, but not today. Today is party-time!
writing a database implementation (where b-trees are useful),
but standardizing the interface to relational databases such
as Oracle or MySQL (roughly, ODBC for C++).
Jens
sven...@web.de
sven...@web.de

pa...@lib.hu
pa...@lib.hu
sven...@web.de
You are right, my tests are not scientific. I don't even know how the map works internally, but i know about clusters.
In a cluster, the worst case is push_front(), then the maximum number of items has to be moved. I'm going to add this test as worst case scenario to the specification.
The groups in a cluster are half-full at minimum, except there is only one group.
With a minimal item-size of 1 byte, there is an overhead of about 104% on the lowest level at maximum.
The overhead for parent-groups is about 100 pointers per 2.500 items, with half-full parent-groups and half-full item-groups, this is about 16%.
Parent-groups on higher levels are below 2 percent.
The maximum overhead is 118% then.
With an item-size less the size of 3 pointers, the cluster would save memory, having more than 50 items. Of course, having many clusters with only a few items could increase memory usage, but with a benefit in speed.
Best regards,
Sven
Magnus Fromreide
> Hello Mr. Pasa,
>
> You are right, my tests are not scientific. I don't even know how the map works internally, but i know about clusters.
> In a cluster, the worst case is push_front(), then the maximum number of items has to be moved. I'm going to add this test as worst case scenario to the specification.
>
> The groups in a cluster are half-full at minimum, except there is only one group.
> With a minimal item-size of 1 byte, there is an overhead of about 104% on the lowest level at maximum.
> The overhead for parent-groups is about 100 pointers per 2.500 items, with half-full parent-groups and half-full item-groups, this is about 16%.
> Parent-groups on higher levels are below 2 percent.
> The maximum overhead is 118% then.
element - would not that get considerably worse overhead than 118%? From the
description I'd guess that cluster would have a memory overhead in the
vicinity of 10000%.
/MF
sven...@web.de
the point is that one item is not a list. There may be an overhead of 10000%,
but this is only 100 times the item-size. With pointers as items, this would be only 400 bytes. The custom allocators are not mentioned here, wich cause an additional overhead, too. Think of an index-cluster in memory-management, sorting free space by size!
Best regards,
Sven
sven...@web.de
First i wanted to use strings like in a dictionary, but there were not enough characters to fill one block on the hard-disk. So i built a group of ids that could fill one block, and thought of this group as a single character. The parent-group was then the previous character in the string. To minimize the overhead from the disk-drive, the blocks had to be as full as possible. And because the drive was slow, the strings had to be as short as possible. I've now chosen c++ as language, and i'm not going to complete the original filesystem-driver.
The Clusters-algorithm is done and it seems to be the most powerful sorting algorithm in the world! Even the btree-algorithm from Google needs double the time and 10% more memory. This is why i write this specification, to bring Clusters into the standard-library.
Memory-allocations take a lot of time and the Clusters-algorithm in memory-management can bring a big benefit to the general public.
When i was writing the algorithm i found, that the algorithm could also be used for serialization only, without sorting. This can drastically reduce memory allocations, but only if the data may be fragmented. A double success!
Best regards,
Sven Bieg
