Proposal: Alternative RV128 (Upgrade path for Legacy 64b systems, skipping RV64 entirely)
87 views
Skip to first unread message

Xan Phung
Feb 5, 2023, 12:11:37 AM2/5/23
to RISC-V ISA Dev
This proposal is a business case & feasibility review for an Alternative RV128 design, and outlines a couple of design choices for which I would welcome input from Forum members.
My proposal assumes the first high volume market to adopt 128b computing will be data centres/cloud services & 128b Personal Computer CPUs. In both these markets, x86_64 has overwhelmingly the largest installed base, with trillions in sunk costs by 2030 (AWS, Azure, GCP alone > $500bil).
Example here & now demands for 128b compute:
* Fixed length 128b word size strings are roomy enough (16 chars) to be viable replacements for many byte array string use cases.
* Int128 data type language support is increasing (eg. Rust & Zig) & also packed bitfield structs up to 128b of total size in C.
* LISP (& related languages) using 128 bit cons cells (ie: a pair of 64 bit car/cdr's)
* Faster portable null terminated string processing (eg. musl strlen), where portable = same C code can be compiled for 32b to 128b architectures
* Software can be easily modified to use a 128b datapath for the above here & now, it is just waiting for hardware to catch up!!
* In all the above, 128b can be introduced piecemeal, most pointers are 64b, and there won't be a "big bang" replacement of entire software stacks.
* Even for full 128b user mode address sizes, the kernel may remain 64b (for device driver compat), eg. first 64b Mac OS X had 32b & 64b user mode with a 32b kernel
* Moreover, the silicon wafer cost of a 128 bit datapath is trivial compared to the enormous cost of changing entire installed systems & software.
RV64 can be skipped entirely & RV128 should *not* be a 100% extrapolation from RV64:
* My vision for RV128 sees it as a "feature add-on" to legacy 64b systems (and there is no benefit in an RV64 intermediate transition). However, "pure" or greenfield implementations of my RV128 are also possible - the important point is not to pre-maturely foreclose on either choice.
* See attached PDF file for further details (register model, instruction set & encodings) of my Alternative RV128 ISA
* In it, I also outline ISA strategies for:
1. Greater energy efficiency (128b registers > more energy hungry than 64b registers).
2. Design choices for ABI interop between (legacy) 64b code and (new) 128b code. I believe the link register needs to be dropped from the RV128 ABI so that legacy 64b code can call new 64/128b code, and vice versa. (But I fully retain the fused branch-compare instructions, 32 registers/5b register fields, non destructive destination reg).
3. I also outline scenarios of a "pure" 128b only ISA, vs a "mixed" ISA where my RV128 ISA is embedded in a host ISA using a REX-like prefix (or using almost deprecated x86 opcodes like x87 FPU instructions).
I believe we need to start thinking about 128b systems from today, as the barrier is not silicon/transistor budget cost, nor is it waiting for 128b memory addressing. All it will take is that we change our own historical mindset (that 128b is far off into the future), and think of practical/incremental ways to build & use 128b datapaths right now.

MitchAlsup
Feb 5, 2023, 4:58:05 PM2/5/23
to RISC-V ISA Dev, Xan Phung
One can easily agree that we are on the cusp of some sort of migration to 128-bit systems.
But what you outline does not address some fundamental issues::
1) What does code look like when you call a function over a 64-bit boundary ??
2) What does array access look like when you access an array over a 64-bit boundary ??
3) and indirectly:: What does GOT access look like when GOT is bigger than 2^24 bytes ??
RISC-V is already saddled with an untasty 64-bit versions of these:
1.v) You would access memory for a 64-bit absolute address of function, and then JMPI
2.v) You would access memory for a 64-bit absolute address of array and then index it.
Since the 12-bit ±offset becomes relatively smaller as addresses get larger, there is
additional overhead in accessing these indirect tables (not illustrated herein).
How will RISC-V compare against other ISAs that provide direct access to 64-bit
<Virtual> Address Spaces without the level of indirection RISC-V currently needs.
That is, those systems that do not use instructions (or consume registers) to obtain large
constants.
On Saturday, February 4, 2023 at 11:11:37 PM UTC-6 Xan Phung wrote:
This proposal is a business case & feasibility review for an Alternative RV128 design, and outlines a couple of design choices for which I would welcome input from Forum members.
My proposal assumes the first high volume market to adopt 128b computing will be data centres/cloud services & 128b Personal Computer CPUs. In both these markets, x86_64 has overwhelmingly the largest installed base, with trillions in sunk costs by 2030 (AWS, Azure, GCP alone > $500bil).
Example here & now demands for 128b compute:
I see these are nickle-and-dime uses of 128-bit items::
* Fixed length 128b word size strings are roomy enough (16 chars) to be viable replacements for many byte array string use cases.
* Int128 data type language support is increasing (eg. Rust & Zig) & also packed bitfield structs up to 128b of total size in C.
* LISP (& related languages) using 128 bit cons cells (ie: a pair of 64 bit car/cdr's)
* Faster portable null terminated string processing (eg. musl strlen), where portable = same C code can be compiled for 32b to 128b architectures
The betwixt represent maybe 1% of instructions being processed ?!? and you are going to target a new architecture to make these better/more efficient ?!?!?
* Software can be easily modified to use a 128b datapath for the above here & now, it is just waiting for hardware to catch up!!
The world is replete with SW that cannot deal with integers not being 32-bits, too. Some SW
breaks is integers are not at least this big, others break when integers are bigger !?!?! And we
20 years after x86-64...........
* In all the above, 128b can be introduced piecemeal, most pointers are 64b, and there won't be a "big bang" replacement of entire software stacks.
Yes, this is exactly how the 16-bit architectures attempted to migrate to 32-bit architectures, and
how most 32-bit architectures intended to migrate to 64-bit architectures. None of the 16-bitters
survived the transition. Almost none of the 32-bitters did either.....not exactly the track record to pursue.
* Even for full 128b user mode address sizes, the kernel may remain 64b (for device driver compat), eg. first 64b Mac OS X had 32b & 64b user mode with a 32b kernel
* Moreover, the silicon wafer cost of a 128 bit datapath is trivial compared to the enormous cost of changing entire installed systems & software.
Here, we agree, the silicon design cost is "trivial" to "not very hard" the only units getting out of
hand would be the multiplier(s) and the Alignment multiplexers associated with LDs and STs. Almost everything else is just "poof; all this logic gets doubled".
RV64 can be skipped entirely & RV128 should *not* be a 100% extrapolation from RV64:
* My vision for RV128 sees it as a "feature add-on" to legacy 64b systems (and there is no benefit in an RV64 intermediate transition). However, "pure" or greenfield implementations of my RV128 are also possible - the important point is not to pre-maturely foreclose on either choice.
* See attached PDF file for further details (register model, instruction set & encodings) of my Alternative RV128 ISA
* In it, I also outline ISA strategies for:
1. Greater energy efficiency (128b registers > more energy hungry than 64b registers).
2. Design choices for ABI interop between (legacy) 64b code and (new) 128b code. I believe the link register needs to be dropped from the RV128 ABI so that legacy 64b code can call new 64/128b code, and vice versa. (But I fully retain the fused branch-compare instructions, 32 registers/5b register fields, non destructive destination reg).
3. I also outline scenarios of a "pure" 128b only ISA, vs a "mixed" ISA where my RV128 ISA is embedded in a host ISA using a REX-like prefix (or using almost deprecated x86 opcodes like x87 FPU instructions).
So, we find ourselves at a point in time where we still have 20-odd years before we run out of
the 64-bit address space, but entering the realm where more and more SW wants efficient
access to "a few" multi-precision calculations. For the most part, whether:: uint128_t i = j + k
takes 1 cycle or 5 is not visible. This SW realm has been growing since the transition from
32-to-64-bits (and even earlier). And every time we make the machines 2× as wide, we set
back the need for efficiency because a large portion of multi-precision need was for the size
2× bigger that what is natural for the architecture.
I believe we need to start thinking about 128b systems from today, as the barrier is not silicon/transistor budget cost, nor is it waiting for 128b memory addressing. All it will take is that we change our own historical mindset (that 128b is far off into the future), and think of practical/incremental ways to build & use 128b datapaths right now.
When do you think it will be practicable to place 2^65 bytes of DRAM DIMM addressable in a
single coherent system ??

John Leidel
Feb 5, 2023, 5:57:25 PM2/5/23
to MitchAlsup, RISC-V ISA Dev, Xan Phung
Xan, as a potential middle group, I would suggest reviewing some of
the work we've done with xBGAS. It provides extended addressing
semantics without trouncing on the base addressing schema (as opposed
to flat 128bit addressing). It does not, however, provide support for
128bit arithmetic (but could likely be modified to do so). We've
published several papers on the efforts hardware and software efforts,
but the seminal work was published at IPDPS:
https://ieeexplore.ieee.org/abstract/document/9460481
best
john
> --
> You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
> To view this discussion on the web visit https://groups.google.com/a/groups.riscv.org/d/msgid/isa-dev/7f7cba37-a02e-4cda-b582-166053db6216n%40groups.riscv.org.
the work we've done with xBGAS. It provides extended addressing
semantics without trouncing on the base addressing schema (as opposed
to flat 128bit addressing). It does not, however, provide support for
128bit arithmetic (but could likely be modified to do so). We've
published several papers on the efforts hardware and software efforts,
but the seminal work was published at IPDPS:
https://ieeexplore.ieee.org/abstract/document/9460481
best
john
> You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
> To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
> To view this discussion on the web visit https://groups.google.com/a/groups.riscv.org/d/msgid/isa-dev/7f7cba37-a02e-4cda-b582-166053db6216n%40groups.riscv.org.
Xan Phung
Feb 5, 2023, 11:55:23 PM2/5/23
to RISC-V ISA Dev, MitchAlsup, Xan Phung
Hi Mitch, thanks for your comments and first I will address your "big picture" questions about the cost/benefit of 128b systems upgrade.
(I address your specific other questions, about synthesizing constants in my embedded response within the quoting of your email below).
1. 128b data, not 128b addresses (yet):
In relation to your last question about 2^65 sized DRAM systems, my guess is that's likely to be 20+ years away (if not longer - there seems to be a slow down in memory density increase from 2003 onwards). The historical numbers are as follows:
8080 in 1974 = 16b
8086 in 1978 = 20b = +1b per year
80286 in 1982 = 24b address size = +1b per year
80386 in 1985 = 32b address sizes = +2b per year
AMD64 Opteron in 2003 = 48b virtual address space = +1b per year
current systems = approx 57 bits virtual address space = +0.5b per year
For this reason, I don't see the need for 128b memory addresses for at least a decade. I agree my examples (128b data, but retaining 64b pointers in an X64ABI) are not as technically revolutionary as going to 128b addresses, but I think 128b data is the use case the "market" will adopt fastest. I should emphasise moving from X64ABI to the full blown 128ABI is a software migration issue (not hardware), and my aim is first to get 128b capable hardware installed first using X64 ABI - then take time to migrate software to 128ABI.
I agree from a technology viewpoint, the 8086->80286->80386->amd64 transition was a dog's breakfast. But commercially they were all successful due to the incumbent power of the x86 installed base, and that's why I think RV128 should provide an upgrade path from x86_64 (and RV64 should be bypassed).
2. Yes, much software will be stuck on 4 byte int - this is the whole business case for Alternative RV128 (vs "Original" RV128):
I also 100% agree with your comments about "world is replete with SW that cannot deal with integers not being 32-bits" - that's why Alternative RV128 has 16 registers which remain only 64b in size, as we simply don't need *all* 32 registers to be 128b. My Alternative RV128 assumes the data size model as int = 32b for the foreseeable future, pointers = 64b for next 10 yrs then 128b thereafter, and long long or long long long = 128b immediately "here & now".
[I will provide a more detailed look at the Alternative RV128b 16x64b + 16x128b register file in another forum posting very soon].
3. Marketing power of 128b is important, not just technical merit
(Silicon cost of 128b is trivial/not hard, but marketing power of 128b upgrade path is potentially huge):
I disagree though with your estimate that only 1% of processing will use the 128b datapath. Even if it is, I wouldn't underestimate the marketing power of 128b nonetheless - remember, I am looking at this from a business case & market adoption point of view, not purely technical merit.
Is marketing power an illegitimate consideration? I would say *no*. Users care about future proofing. Even if they only need 128b capability for 1% initially, they want the optionality/reassurance that their system won't go obsolete in 3-5 yrs if their need for 128b has increased. The silicon cost of this optionality/reassurance is trivial/not hard, so why not provide it?
But even on the issue of technical merit, the 128b techniques I outlined are under-used, as current software can't assume the presence of 128b hardware. So it's a chicken & egg dilemma (which is why I think establishing business cases is more important than technical merit).
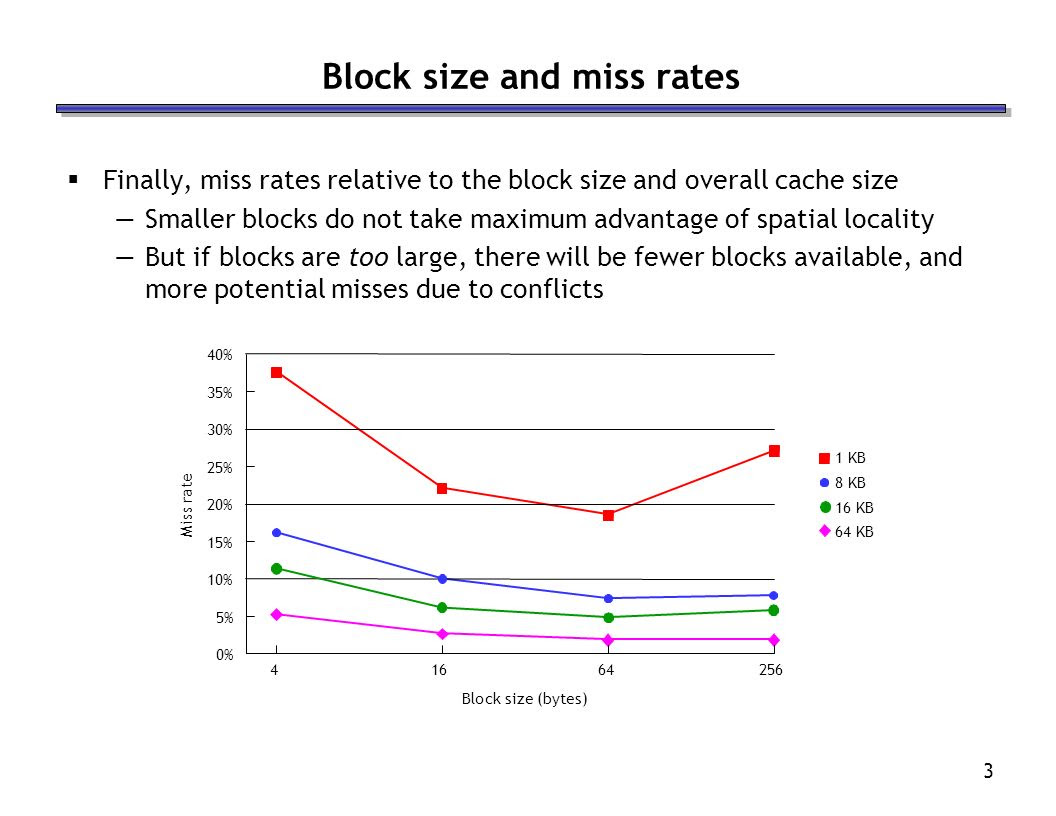
But converting small C structures into bitfields packed into one (or more) 128b words alone would be on the order of 5%+ of workloads, given how common small structures are. What data do I have to show most structures are small & <128b? The best proxy data I can think of is cache miss rates with increasing cache block sizes (which analyses the effect of spatial locality, ie: multiple accesses within a given sized block) - as shown below, the spatial locality effect is most pronounced for memory access within 16 byte blocks and any bigger than this the effect levels off. I admit this data is an imperfect proxy (it would also include array & scalar accesses, not just structs) but anyone with better data is welcome to contribute! Nonetheless, in the structs example, the comparison isn't whether 128b ADD is 1 cycle or 5, the comparison is the speed of register based struct manipulation vs memory based struct manipulation.
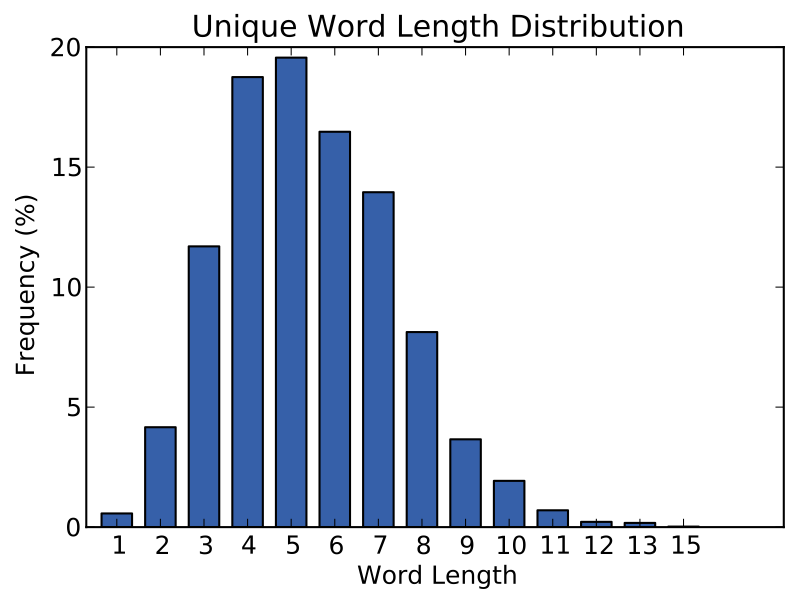
In relation to my fixed size strings (up to 16 chars) example replacing byte array strings, the comparison again isn't speed of a 128b ADD, it is a single load/store/SLT/MOV/CTZ of 128b vs multiple load/stores/compare/strdup/strlen of individual bytes. The former is purely 128b register based manipulation of the string, whereas the latter requires memory access & string library API function calls. How many strings are 16 chars or less? Again, I don't have good data but using English word length as a proxy, the nearly the entire English dictionary can fit inside 16 chars!:
On Monday, 6 February 2023 at 8:58:05 am UTC+11 MitchAlsup wrote:
One can easily agree that we are on the cusp of some sort of migration to 128-bit systems.But what you outline does not address some fundamental issues::
1) What does code look like when you call a function over a 64-bit boundary ??
2) What does array access look like when you access an array over a 64-bit boundary ??
3) and indirectly:: What does GOT access look like when GOT is bigger than 2^24 bytes ??
RISC-V is already saddled with an untasty 64-bit versions of these:
1.v) You would access memory for a 64-bit absolute address of function, and then JMPI
2.v) You would access memory for a 64-bit absolute address of array and then index it.
Since the 12-bit ±offset becomes relatively smaller as addresses get larger, there is
additional overhead in accessing these indirect tables (not illustrated herein).
How will RISC-V compare against other ISAs that provide direct access to 64-bit
<Virtual> Address Spaces without the level of indirection RISC-V currently needs.
If I understand your list below correctly, your concerns are the RISC V approach to synthesizing arbitrary 64b+ constants, or calling/accessing 64b+ absolute addresses/arrays/functions.
My alternative RV128 proposal doesn't (substantially) change RISC V approaches to these problems, but can help (slightly) in the following ways:
(a) You mention limitations of 12b offsets. My Alternative RV128 (for data >=32b word size) would use 4 byte multiples, so in effect 12b offsets have a range of 2^14 bytes.
(b) For synthesising constants, by only using 6% of opcode space in the base RV128, I leave available the opcodes for the equivalent of x86_64's MOVABSQ instruction, ie: something like the following:
49 bc ca cc cc cc cc cc cc 0c movabsq $0xcccccccccccccca,%r12
The above is a 10 byte long instruction (which is why I hesitate to endorse it, as so far everything in Alternative RV128 is a fixed 4 byte instruction length). It could be an extension of Alternative RV128. Of course, the RISC V approach would instead be to encourage instruction fusion of a sequence of LUI/ADDI to synthesize the 64b+ constant. I have also included the PACK instruction (in the base Alternative RV128 spec, not as a Bitmanip add-on) to help further with this approach.
(c) I should also emphasise a key initial use of Alternative RV128 is with the "X64" ABI, which uses 128b for data, but for memory uses 64b pointers, so at least Alternative RV128 won't make the above problems worse than it currently is in RV64.
I hope that answers your questions but if I have misunderstood you, apologies & could you please explain/discuss further?
Best regards
Xan
MitchAlsup
Feb 6, 2023, 2:55:41 PM2/6/23
to RISC-V ISA Dev, Xan Phung, MitchAlsup
On Sunday, February 5, 2023 at 10:55:23 PM UTC-6 Xan Phung wrote:
Hi Mitch, thanks for your comments and first I will address your "big picture" questions about the cost/benefit of 128b systems upgrade.
(I address your specific other questions, about synthesizing constants in my embedded response within the quoting of your email below).
1. 128b data, not 128b addresses (yet):
In relation to your last question about 2^65 sized DRAM systems, my guess is that's likely to be 20+ years away (if not longer - there seems to be a slow down in memory density increase from 2003 onwards). The historical numbers are as follows:
8080 in 1974 = 16b
8086 in 1978 = 20b = +1b per year
80286 in 1982 = 24b address size = +1b per year
80386 in 1985 = 32b address sizes = +2b per year
AMD64 Opteron in 2003 = 48b virtual address space = +1b per year
current systems = approx 57 bits virtual address space = +0.5b per year
For this reason, I don't see the need for 128b memory addresses for at least a decade. I agree my examples (128b data, but retaining 64b pointers in an X64ABI) are not as technically revolutionary as going to 128b addresses, but I think 128b data is the use case the "market" will adopt fastest. I should emphasise moving from X64ABI to the full blown 128ABI is a software migration issue (not hardware), and my aim is first to get 128b capable hardware installed first using X64 ABI - then take time to migrate software to 128ABI.
I agree from a technology viewpoint, the 8086->80286->80386->amd64 transition was a dog's breakfast. But commercially they were all successful due to the incumbent power of the x86 installed base, and that's why I think RV128 should provide an upgrade path from x86_64 (and RV64 should be bypassed).
2. Yes, much software will be stuck on 4 byte int - this is the whole business case for Alternative RV128 (vs "Original" RV128):
I also 100% agree with your comments about "world is replete with SW that cannot deal with integers not being 32-bits" - that's why Alternative RV128 has 16 registers which remain only 64b in size, as we simply don't need *all* 32 registers to be 128b. My Alternative RV128 assumes the data size model as int = 32b for the foreseeable future, pointers = 64b for next 10 yrs then 128b thereafter, and long long or long long long = 128b immediately "here & now".
[I will provide a more detailed look at the Alternative RV128b 16x64b + 16x128b register file in another forum posting very soon].
3. Marketing power of 128b is important, not just technical merit
(Silicon cost of 128b is trivial/not hard, but marketing power of 128b upgrade path is potentially huge):
I disagree though with your estimate that only 1% of processing will use the 128b datapath.
Note:: not what I said. I said that current processors are spending less than 1% of executed
instructions doing 128-bit (or larger) calculations/stuff. Things like encryption/decryption
are migrating to special function units and should not be considered 128-bitted. Other large
value calculations are often hidden in multi-precision arithmetic sequences.
Even if it is, I wouldn't underestimate the marketing power of 128b nonetheless - remember, I am looking at this from a business case & market adoption point of view, not purely technical merit.
Is marketing power an illegitimate consideration? I would say *no*. Users care about future proofing. Even if they only need 128b capability for 1% initially, they want the optionality/reassurance that their system won't go obsolete in 3-5 yrs if their need for 128b has increased. The silicon cost of this optionality/reassurance is trivial/not hard, so why not provide it?
Marketing power is not illegitimated, but consider a new car exactly the same make and body of
another car, one has 400 HP and one 800 HP. Your application is driving interstates at 65 MPH.
Which one represents the best value to you ?
But even on the issue of technical merit, the 128b techniques I outlined are under-used, as current software can't assume the presence of 128b hardware. So it's a chicken & egg dilemma (which is why I think establishing business cases is more important than technical merit).
One of my earlier points was that multi-precision arithmetic sequences are providing this
feature/functionality today without any 128-bit HW or instructions specifying 128-bit operands.
Any, yes, I see it as chicken and egg, and I am wondering if the egg needs a bit more time before
it is time to be born.
But converting small C structures into bitfields packed into one (or more) 128b words alone would be on the order of 5%+ of workloads, given how common small structures are.
Where did I mention packing at bit levels ??
What data do I have to show most structures are small & <128b? The best proxy data I can think of is cache miss rates with increasing cache block sizes (which analyses the effect of spatial locality, ie: multiple accesses within a given sized block) - as shown below, the spatial locality effect is most pronounced for memory access within 16 byte blocks and any bigger than this the effect levels off. I admit this data is an imperfect proxy (it would also include array & scalar accesses, not just structs) but anyone with better data is welcome to contribute! Nonetheless, in the structs example, the comparison isn't whether 128b ADD is 1 cycle or 5, the comparison is the speed of register based struct manipulation vs memory based struct manipulation.
I would say the data provided shows 64-byte lines are better. Also note: internal busses in GPUs
are 1023 bits going in and 1024 bits coming out per shader core. If GPUs can find this many wires,
so can core design--that is looking forward, you might want to consider transmitting whole cache
lines in a single beat over the interconnect. Interconnects like this will alter the above graph.
In relation to my fixed size strings (up to 16 chars) example replacing byte array strings, the comparison again isn't speed of a 128b ADD, it is a single load/store/SLT/MOV/CTZ of 128b vs multiple load/stores/compare/strdup/strlen of individual bytes. The former is purely 128b register based manipulation of the string, whereas the latter requires memory access & string library API function calls. How many strings are 16 chars or less? Again, I don't have good data but using English word length as a proxy, the nearly the entire English dictionary can fit inside 16 chars!:
I will grant, freely, that many even most strings are "not that long". But the average parts of
a program handling strings does not one part that handles monolithic strings and another
handling arbitrary length strings. We settled on arbitrary length a long time ago.
On Monday, 6 February 2023 at 8:58:05 am UTC+11 MitchAlsup wrote:
One can easily agree that we are on the cusp of some sort of migration to 128-bit systems.But what you outline does not address some fundamental issues::
1) What does code look like when you call a function over a 64-bit boundary ??
2) What does array access look like when you access an array over a 64-bit boundary ??
3) and indirectly:: What does GOT access look like when GOT is bigger than 2^24 bytes ??
RISC-V is already saddled with an untasty 64-bit versions of these:
1.v) You would access memory for a 64-bit absolute address of function, and then JMPI
2.v) You would access memory for a 64-bit absolute address of array and then index it.
Since the 12-bit ±offset becomes relatively smaller as addresses get larger, there is
additional overhead in accessing these indirect tables (not illustrated herein).
How will RISC-V compare against other ISAs that provide direct access to 64-bit
<Virtual> Address Spaces without the level of indirection RISC-V currently needs.
If I understand your list below correctly, your concerns are the RISC V approach to synthesizing arbitrary 64b+ constants, or calling/accessing 64b+ absolute addresses/arrays/functions.
My alternative RV128 proposal doesn't (substantially) change RISC V approaches to these problems, but can help (slightly) in the following ways:
(a) You mention limitations of 12b offsets. My Alternative RV128 (for data >=32b word size) would use 4 byte multiples, so in effect 12b offsets have a range of 2^14 bytes.
Trifling of help.
(b) For synthesising constants, by only using 6% of opcode space in the base RV128, I leave available the opcodes for the equivalent of x86_64's MOVABSQ instruction, ie: something like the following:
49 bc ca cc cc cc cc cc cc 0c movabsq $0xcccccccccccccca,%r12
You are still wasting a register.
Now try for::
STD #0x123456789ABCDEF,[sp+16]
as 1 instruction.
The above is a 10 byte long instruction (which is why I hesitate to endorse it, as so far everything in Alternative RV128 is a fixed 4 byte instruction length).
Some consider this a fatal flaw in RISC-V and I am merely stating that you have this
opportunity to solve the problem (flaw) once and for all. You should devote more of your
effort in making the architecture "better" and less towards making it wider--wider being
much easier to accomplish. Go spend a month reading RISC-V assembly out of the compiler
and reason about those sequences the compiler has to (currently) produce and figure out
how to make those sequences take fewer instructions to encode and fewer cycles to
execute.
RISC-V 32-bit mode has fixed length instructions, RISC-Vc ha 16-bit variable length instructions.
So, you are already dealing with variable length; bake it in and use it as a lever to make RISC-V
128 better than RISC-V 64.
It could be an extension of Alternative RV128. Of course, the RISC V approach would instead be to encourage instruction fusion of a sequence of LUI/ADDI to synthesize the 64b+ constant. I have also included the PACK instruction (in the base Alternative RV128 spec, not as a Bitmanip add-on) to help further with this approach.
(c) I should also emphasise a key initial use of Alternative RV128 is with the "X64" ABI, which uses 128b for data, but for memory uses 64b pointers, so at least Alternative RV128 won't make the above problems worse than it currently is in RV64.
I hope that answers your questions but if I have misunderstood you, apologies & could you please explain/discuss further?
Best regards
Xan
Thank you for you well considered response.
Reply all
Reply to author
Forward
0 new messages