Proposal: RV16E

Cesar Eduardo Barros
variant, for small microcontrolers, a 64-bit variant, for servers and
workstations, and a future-proof 128-bit variant. For even smaller
microcontrollers, there is a reduced 32-bit variant (RV32E) which omits
half of the register set. But what if you have a need for an even
smaller microcontroller?
I present here a proposal for a RISC-V variant that's even smaller than
RV32E, yet still usable. I call it RV16E, and going in the oposite
direction of RV128I, it extends RISC-V downwards, with sixteen 16-bit
integer registers.
That is, XLEN=16, and like RV32E, only x0-x15 are available. Immediates
are also 16-bit only: for instructions like LUI, AUIPC or jumps, the
immediate must be sign-extended before being encoded into the
instruction, otherwise it's an invalid instruction.
Going in the order the instructions are described in the manual:
- Registers x16-x31 are not available;
- For SLLI/SRLI/SRAI, the shamt field is reduced to 4 bits, the leftover
bit being always zero;
- For LUI/AUIPC, bits [31:16] of the immediate must be a copy of bit 15
of the immediate;
- For SLL/SRL/SRA, the shift amount is in the lower 4 bits of the register;
- For JAL, bits [20:16] of the offset must be a copy of bit 15 of the
offset;
- For LOAD/STORE, the available widths are only LB/SB, LH/SH, and LBU;
- Like with RV32E, counter instructions are optional, and floating point
not allowed.
Using compressed instructions with RV16E is clearly desirable, since for
instance C.LUI can replace nearly all uses of LUI. The RVC extension for
RV16E is based on RV32C, with the following modifications:
- C.LHSP replaces C.LWSP, and scales by 2 (imm is offset[5] and
offset[4:1|6])
- C.SHSP replaces C.SWSP, and scales by 2 (imm is offset[5:1|6])
- C.LH replaces C.LW, and scales by 2 (imm is offset[5:3] and offset[2:1])
- C.SH replaces C.SW, and scales by 2 (imm is offset[5:3] and offset[2:1])
- C.J, C.JAL, C.JR, C.JALR, C.BEQZ, C.BNEZ, C.LI stay the same
- C.LUI must have bits 17 and 16 of nzuimm idential to bit 15
- C.ADDI stays the same
- C.ADDI16SP is replaced by C.ADDI4SP (TODO: immediate encoding)
- C.ADDI4SPN is replaced by C.ADDI2SPN (TODO: immediate encoding)
- C.SLLI, C.SRLI, C.SRAI must have shamt[5] zero
- C.ANDI, integer register-register, illegal, C.NOP, C.EBREAK stay the same
The stack is aligned to 4 bytes, instead of 16 bytes. (TODO: check
immediate encodings)
The obvious disadvantage of RV16E is being able to address only 65536
bytes of memory, which has to be shared between the large 4-byte
instructions, data, and memory-mapped I/O. The traditional solution for
this is banking. I propose, therefore, a set of four BANKn CSRs, each
having up to 16 bits. The top two bits of the memory address would
select which CSR contains the bank number, while the lower 14 bits would
be the offset within the bank.
--
Cesar Eduardo Barros
ces...@cesarb.eti.br

Luke Kenneth Casson Leighton
<ces...@cesarb.eti.br> wrote:
> The obvious disadvantage of RV16E is being able to address only 65536 bytes
> of memory, which has to be shared between the large 4-byte instructions,
> data, and memory-mapped I/O. The traditional solution for this is banking. I
> propose, therefore, a set of four BANKn CSRs, each having up to 16 bits. The
> top two bits of the memory address would select which CSR contains the bank
> number, while the lower 14 bits would be the offset within the bank.
of RV32* as i was considering investigating adding NUMA RV32* cores to
operate along-side SMP RV64GC cores, for multimedia video and 3D
graphics processing).
what you propose with BANKn CSRs reminds me of the Z80. that had
memory banks that could (shock, gasp) address up to 1MB of RAM (!).
from what i remember of the Z80 it was a pain: half the 64k memory was
bank-addressable and the other half not, and i don't believe you could
address multiple banks at once. this in turn meant that if you wished
to operate on two sets of bank-addressed memory you simply couldn't:
you had to *copy* one bank into the bottom 32k and then change the
bank address to refer to the other, do the operations and then copy
the results *back* to the first bank.
total pain.
i note however that you are proposing 4 BANK addresses. 2^14=..
16384. so the addressable memory range would be 16384. and with 2
bits in the top selecting which CSR you could... yes! simultaneously
address 4 separate different areas in memory. smart. i like it.
however.... presumably the BANKn CSR would need to be 18 bits not 16
in order to address the full 2^32 memory range? otherwise the memory
range is limited to 2^30 = 1GB of memory, not 4GB. it might not make
sense in a traditional micro-controller environment however i am used
to some really weird architectures: 2D grids of 4-bit ALUs (a company
in bristol, UK), 1D strings of 1-bit and later 2-bit ALUs (Aspex
Microelectronic Array-String Processor: massively wide SIMD: one
processor with 4096 ALUs with 256 bits of content-addressable RAM *per
ALU*). also, eperantotech (*waves to Allen*) have 4096 RV32 cores,
they might well have considered 8192 or 16384 RV16 cores, perhaps
fitting into the same die area if they are really that much smaller,
who knows.
so with that in mind, Cesar, had you considered BANK0 applying to the
first memory-address (a read) and BANK1 applying to the stores, and so
on? i don't know if it's possible to issue 2 reads (or two writes) in
a single RISC-V instruction.
or, having the BANKn CSRs be 32-bit (would require 2 16-bit
instructions to set each, i realise) and be *added* to the load/store,
turning all instructions into *relative* addresses, what about that?
developers could then choose to set the lower 14 bits to zero and
choose not to issue the 2nd of the bank-setting instructions, thus
effectively being functionally-identical to the idea that you propose,
and save on one instruction... but the advantage is, relative
addressing would allow inter-bank boundaries to be crossed without
needing to mess about with extra manual memory copying [and detection
of when such boundaries occur. yuck!]
oooor.... is there 2 bits spare somewhere in the BANKn CSR setting
instruction which would allow the top 2 bits (17 and 18) to be written
to at the time that the other 16 bits were being loaded? bit of a
hack that... :)
really like the idea of tiny cores, cesar. love to see the BANKn idea
added to RV32 as well in some fashion.
l.
Cesar Eduardo Barros
> On Sun, Apr 1, 2018 at 1:23 PM, Cesar Eduardo Barros
> <ces...@cesarb.eti.br> wrote:
>
>> The obvious disadvantage of RV16E is being able to address only 65536 bytes
>> of memory, which has to be shared between the large 4-byte instructions,
>> data, and memory-mapped I/O. The traditional solution for this is banking. I
>> propose, therefore, a set of four BANKn CSRs, each having up to 16 bits. The
>> top two bits of the memory address would select which CSR contains the bank
>> number, while the lower 14 bits would be the offset within the bank.
>
> ha, very cool: i was just going to ask about this (but in the context
> of RV32* as i was considering investigating adding NUMA RV32* cores to
> operate along-side SMP RV64GC cores, for multimedia video and 3D
> graphics processing).
(adding more levels to the page table) would be a better idea. Or, since
they are auxiliary cores, somethine like an IOMMU managed by the RV64
side, using the RV64 page table formats.
> what you propose with BANKn CSRs reminds me of the Z80. that had
> memory banks that could (shock, gasp) address up to 1MB of RAM (!).
> from what i remember of the Z80 it was a pain: half the 64k memory was
> bank-addressable and the other half not, and i don't believe you could
> address multiple banks at once. this in turn meant that if you wished
> to operate on two sets of bank-addressed memory you simply couldn't:
> you had to *copy* one bank into the bottom 32k and then change the
> bank address to refer to the other, do the operations and then copy
> the results *back* to the first bank.
>
> total pain.
> i note however that you are proposing 4 BANK addresses. 2^14=..
> 16384. so the addressable memory range would be 16384. and with 2
> bits in the top selecting which CSR you could... yes! simultaneously
> address 4 separate different areas in memory. smart. i like it.
with the convenience of having multiple mappable ranges. Two would be
the minimum, I chose 4 to be more flexible.
> however.... presumably the BANKn CSR would need to be 18 bits not 16
> in order to address the full 2^32 memory range? otherwise the memory
> range is limited to 2^30 = 1GB of memory, not 4GB. it might not make
> sense in a traditional micro-controller environment however i am used
> to some really weird architectures: 2D grids of 4-bit ALUs (a company
> in bristol, UK), 1D strings of 1-bit and later 2-bit ALUs (Aspex
> Microelectronic Array-String Processor: massively wide SIMD: one
> processor with 4096 ALUs with 256 bits of content-addressable RAM *per
> ALU*). also, eperantotech (*waves to Allen*) have 4096 RV32 cores,
> they might well have considered 8192 or 16384 RV16 cores, perhaps
> fitting into the same die area if they are really that much smaller,
> who knows.
of memory ought to be enough for anybody ;-)
> so with that in mind, Cesar, had you considered BANK0 applying to the
> first memory-address (a read) and BANK1 applying to the stores, and so
> on? i don't know if it's possible to issue 2 reads (or two writes) in
> a single RISC-V instruction.
>
> or, having the BANKn CSRs be 32-bit (would require 2 16-bit
> instructions to set each, i realise) and be *added* to the load/store,
> turning all instructions into *relative* addresses, what about that?
> developers could then choose to set the lower 14 bits to zero and
> choose not to issue the 2nd of the bank-setting instructions, thus
> effectively being functionally-identical to the idea that you propose,
> and save on one instruction... but the advantage is, relative
> addressing would allow inter-bank boundaries to be crossed without
> needing to mess about with extra manual memory copying [and detection
> of when such boundaries occur. yuck!]
>
> oooor.... is there 2 bits spare somewhere in the BANKn CSR setting
> instruction which would allow the top 2 bits (17 and 18) to be written
> to at the time that the other 16 bits were being loaded? bit of a
> hack that... :)
A more serious proposal could use a separate BANK_TOP CSR to hold the
top bits of the BANKn registers. That would give 20-bit bank numbers,
which should be way beyond plenty.
> really like the idea of tiny cores, cesar. love to see the BANKn idea
> added to RV32 as well in some fashion.
proposal, I do believe the idea of "extending down" RISC-V into the
16-bit land might have some merit.

Christopher Celio
--
You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
To post to this group, send email to isa...@groups.riscv.org.
Visit this group at https://groups.google.com/a/groups.riscv.org/group/isa-dev/.
To view this discussion on the web visit https://groups.google.com/a/groups.riscv.org/d/msgid/isa-dev/0b7c0d18-a5e4-0696-fe0b-e3a25c07f8c7%40cesarb.eti.br.

Liviu Ionescu
> Even though it's just an April 1st joke
> proposal,
> I do believe the idea of "extending down" RISC-V into
> the
> 16-bit land might have some merit.
from a software point of view, the ideal embedded core would be a
64-bits one (if you don't believe this, take a look at the recommended
method to access 64-bits timer registers on a 32-bits core). not to
mention multiply/divide instructions, more consistent with double
floating point, etc.
hopefully the 16-bit land will be a thing of the past, and remain so.
regards,
Liviu
Luke Kenneth Casson Leighton
<ces...@cesarb.eti.br> wrote:
> If you want to make RV32 access more memory, something like x86's PAE
> (adding more levels to the page table) would be a better idea.
> Or, since
> they are auxiliary cores, somethine like an IOMMU managed by the RV64 side,
> using the RV64 page table formats.
code synchronisation would not be needed.
> Yes, it was directly inspired by the Z80.
> If XLEN is 16, each CSR can hold up to 16 bits. No exceptions. And 1GB of
> memory ought to be enough for anybody ;-)
>> oooor.... is there 2 bits spare somewhere in the BANKn CSR setting
>> instruction which would allow the top 2 bits (17 and 18) to be written
>> to at the time that the other 16 bits were being loaded? bit of a
>> hack that... :)
>
>
> That would be too much complexity for a joke proposal (check the date).
> A
> more serious proposal could use a separate BANK_TOP CSR to hold the top bits
> of the BANKn registers. That would give 20-bit bank numbers, which should be
> way beyond plenty.
per bank, i just expressed it badly enough for you not to be able to
recognise it as such.
>> really like the idea of tiny cores, cesar. love to see the BANKn idea
>> added to RV32 as well in some fashion.
>
>
> I'm glad someone liked it ;-) Even though it's just an April 1st joke
> proposal, I do believe the idea of "extending down" RISC-V into the 16-bit
> land might have some merit.
for washing machine processors, SIM cards, and sub-micro-amp power
scenarios, hell yes. the STM8S003 for example is a 20-pin TSSOP, it's
$0.24 in quantity *ONE* even from digikey (so imagine what the volume
price is in Shenzhen), it has 256 bytes of RAM and i believe 1k of
NAND and it's *awesome*. gets used in microwaves, washing machines,
fridges, the works. how many of _those_ are sold world-wide? just
because RV32 and above are sexy and modern doesn't mean that RiSC-V as
a concept has to stop there. hell, 10 years ago i heard of a company
doing extremely well with an 8-bit fully-functioning processor that
only had *140 gates*.
also (liviu), as Aspex Microelectronics showed, when the processor
core is small enough such that it can be efficiently embedded as part
of a massively-replicable array that also has a small
Content-Addressable RAM in each element of the array, very very
interesting things start to become possible. certain applications
become literally a hundred times faster: pattern recognition, network
routing, video processing, neural networks and so on. unfortunately
they're also a couple orders of magnitude more of a bitch to program
but hey you can't have everything.
l.
Liviu Ionescu
> > also (liviu), as Aspex Microelectronics showed, when the processor
> core is small enough such that it can be efficiently embedded
> as part
> of a massively-replicable array that also has a small
> Content-Addressable RAM in each element of the array, very very
> but hey you can't have everything.
however, personally I'm more interested in improving the quality of
life for the today software guys, in order to become more productive.
thus my proposal for a C/C++ friendly RISC-V microcontroller
architecture, where I accept to trade some transistors for ease of
use.
regards,
Liviu
Luke Kenneth Casson Leighton
> I have nothing against experimentation and research.
>
> however, personally I'm more interested in improving the quality of
> life for the today software guys, in order to become more productive.
> thus my proposal for a C/C++ friendly RISC-V microcontroller
> architecture, where I accept to trade some transistors for ease of
> use.
which are absolutely enormous volumes (literally billions of units)
and the programs extremely small and often written in assembler or are
targets of sdcc or avr-utils (specialist subset c compilers) and the
general-purpose worlds (MIPS32/MIPS64, x86_64, ARM) are completely...
alien to each other. there's almost nothing in common.
l.

Tommy Murphy

Ray Van De Walker
For any newcomers, here is a link to an earlier set of RV16 proposals:
https://groups.google.com/a/groups.riscv.org/forum/#!searchin/isa-dev/16-bit/isa-dev/iK3enKGb5bw/cuVAq0J8EAAJ
You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
To post to this group, send email to isa...@groups.riscv.org.
Visit this group at https://groups.google.com/a/groups.riscv.org/group/isa-dev/.

Rogier Brussee
notation by example:
4rsd = registers x0-x15 used as rd and rs1
4rs2* = registers x1-x15 used as rs2
3rs1 = registers x8-x15 used as rs1 encoded as in the C extension
5imm = 5bit immediate.
7imm* = 7bit nonzero immediate
# = comment
#instruction = instruction that does not currently exist in RVIMA but might become one in B or small integer extension
lx = lh for rv16 lw for rv32, ld for rv64 lq for rv 128 (or maps to a hypothetical lx instruction with an immediate in units of XLEN/8 byte). Also x is used to indicate shift over log2(XLEN/8)
@auipc zero imm: break 5imm = sneak in the break instruction by reusing the li opcode with rsd = zero
li 4rd* 5imm addi rd zero sext(imm)
li_7 4rd* 5imm addi rd zero sext(imm<<7)
lui 4rd* 5imm lui rd sext(imm) #aka li_12
auipc 4rd* 5imm auipc rd sext(imm) #aka ai_12pc
addi 4rsd* 7imm* addi rsd rsd sext(imm, XLEN)
ai_xsp 4rd* 7imm* add rd sp sext(imm<<7) #for stack adjustment and pointers into stack. Assume stack is 2*XLEN/8 aligned. Alternatively define addi16sp imm add sp sp imm<<4 (aka addi_4sp) for rd = sp
addwi 4rsd* 5imm addwi rsd rsd sext(imm<<7) #replace with addhi for 16/32 portability
addi_7 4rsd* 5imm* addi rsd rsd sext(5imm << 7)
addi_x 4rsd* 5imm* addi rsd rsd sext(5imm << log2(XLEN/8)
addi_5x 4rsd* 5imm* addi rsd rsd sext(5imm << (log2(XLEN/8)+5))
beqz 4rs1* 7imm* beq rs1 zero imm
bnez 4rs1* 7imm* bne rs1 zero imm
jalri 4rsd 7imm jalr rsd rsd sext(imm) #mainly useful for milicode: use li_7 t0 MILICODE_BASE jalr t0 imm to call imm for a milicode call en li_7 t1 MILICODE_BASE jalr t1 imm for a tailcall
lxsp 4rd* 7imm l[h/w] rd sext(imm<<log2(XLEN/8))(sp)
lx 3rd 3rs1 5imm l[h/w] rd zext(imm<<log2(XLEN/8))(rs1)
lw 3rd 3rs1 5imm lh rd zext(imm<<1)(rs1) #replace with lh 3rd 3rs1 5imm for 16/32 portability
lbu 3rd 3rs1 3imm lbu rd zext(imm)(rs1) # replace all with lbu, 3rd 3rs1 5imm for 16/32 portability
lh 3rd 3rs1 3imm lh rd zext(imm<<1)(rs1) # replace with ld for 64/128 portability
flw 3rd 3rs1 3imm flw rd zext(imm<<2)(rs1)
fld 3rd 3rs1 3imm fld rd zext(imm<<3)(rs1)
sxsp 4rs1* 7imm s[h/w] rs1 sext(imm <<log2(XLEN/8))(sp)
sx 3rd 3rs1 5imm s[h/w] rs1zext(imm<<log2(XLEN/8))(sp)
sw 3rd 3s1 5imm sh rs1 zext(imm<<1)(sp) #replace with sh 3rs1 3rs2 5imm for 16/32 portability
sb 3rs1 3rs2 3imm lbu rd zext(imm)(rs1) # replace with sb, 3rd 3rs1 5imm for 16/32 portability
lh 3rs1 3rs1 3imm lh rd zext(imm<<1)(rs1)
fsw 3rs1 3rs2 3imm flw rd zext(imm<<2)(rs1)
fsd 3rd 3rs1 3imm fld rd zext(imm<<3)(rs1)
auipc_ra 11imm auipc ra sext(imm) for 32/64
jalr_rara 11imm jalr ra ra imm<<1 #use in combination with auipc_ra. Fusable to effectively jal ra 22imm
j 11imm* jal zero sext(imm)
jal 11imm* jal ra sext(imm)
andi 4rsd* 5imm andi rsd rsd sext(imm) #imm == 0 and imm == -1 are both useless.
slli 4rsd* 5imm slli rsd rsd sext(imm) #imm ==0 encodes 32 for 32/64
srli 4rsd* 5imm srli rsd rsd sext(imm) #likewise
srai 4rsd* 5imm srai rsd rsd sext(imm) #likewise
add 4rsd* 4rs2* add rsd rsd rs2
sub 4rsd* 4rs2* sub rsd rsd rs2
addw 4rsd* 4rs2* addw rsd rsd rs2 #replace with addh for 16/32, to follow the letter of the RV spec simply map to add instead of addw in RV32
subw 4rsd* 4rs2* subw rsd rsd rs2 #replace with addh for 16/32, to follow the letter of the RV spec simply map to add instead of addw in RV32
slt 4rsd* 4rs2 slt rsd rsd rs2
sltu 4rsd* 4rs2 sltu rsd rsd rs2
mv 4rd* 4rs1* add rd rs1 zero
jalr 4rd 4rs1* jalr rd rs1 0
and 3rsd 3rs2 and rsd rsd rs2
or 3rsd 3rs2 or rsd rsd rs2
xor 3rsd 3rs2 xor rsd rsd rs2
#addh 3rsd 3rs2 #superfluous for 16/32
sll 3rsd 3rs2 sll rsd rsd rs2
srl 3rsd 3rs2 srl rsd rsd rs2
sra 3rsd 3rs2 sra rsd rsd rsd
#rll 3rsd 3rs2 #rs2 is taken mod log2(XLEN), therefore negative values rotate right.
mul 3rsd 3rs2 mul rsd rsd rs2
mulh 3rsd 3rs2 mulh rsd rsd rs2
mulhsu 3rsd 3rs2 mulhsu rsd rsd rs2
mulhu 3rsd 3rs2 mulhu rsd rsd rs2
div 3rsd 3rs2 div rsd rsd rs2
divu 3rsd 3rs2 div rsd rsd rs2
rem 3rsd 3rs2 rem rsd rsd rs2
remu 3rsd 3rs2 rem rsd rsd rs2
not 3rd 3s1 xori rd rs1 -1
sllx 3rd 3rs1 slli rd rs1 x
#sextb 3rd 3rs1
#sexth 3rd 3rs1
#sextw 3rd 3rs1
#zextb 3rd 3rs1
#zexth 3rd 3rs1
#zextw 3rd 3rs1
#popc 3rd 3rs1
#clz 3rd 3rs1
#bswap 3rd 3rs1
lr rd rs1 lr rd rs1
sc rsd rs1 sc rsd rs1 rsd
lrw rd rs1 lrw rsd rs1 rsd #for 16/32 portability just drop
scw rsd rs2 scw rsd rs1 rsd #for 16/32 portability just drop
amoadd 3rsd 3rs1 amoadd.aqrl rsd rs1 rsd
amoaddw 3rsd 3rs1 amoaddw.aqrl rsd rs1 rsd #for 16/32 portability just drop
amoswap 3rsd 3rs1 amoswap.aqrl rsd rs1 rsd
amoand 3rsd 3rs1 amoand.aqrl rsd rs1 rsd
amoor 3rsd 3rs1 amoor.aqrl rsd rs1 rsd
amoxor 3rsd 3rs1 amoxor.aqrl rsd rs1 rsd
memadd 3rsd 3rs1 amoadd. rsd rs1 rsd #no ordering, but indivisible
memaddw 3rsd 3rs1 amoaddw. rsd rs1 rsd #no ordering, but indivisible; for 16/32 portability just drop
memswap 3rsd 3rs1 amoswap. rsd rs1 rsd #no ordering, but indivisible
memand 3rsd 3rs1 amoand. rsd rs1 rsd #no ordering, but indivisible
memor 3rsd 3rs1 amoor. rsd rs1 rsd #no ordering, but indivisible
memxor 3rsd 3rs1 amoxor. rsd rs1 rsd #no ordering, but indivisible
csrrw 3rsd imm7 csrrw rsd rsd map(imm7) #mapping TBD
csrrs 3rsd imm7 csrrs rsd rsd map(imm7)
csrrc 3rsd imm7 csrrc rsd rsd map(imm7)
csrr 3rd imm7 csrrc rd zero map(imm7)
@li zero 0 : designated illegal
@li zero 1 : ecall
@li zero 1imm[3:0] : break 4imm #different breaks are useful for hosted environments
@li_7 zero 0imm[3:0] : mfence 4imm fence.imm0000
@ll_7 zero 1imm[3:0] : iofence 4imm fence 0000imm
@lui zero 0 : ifence
@beq zero 0 : wfi
Op maandag 2 april 2018 21:37:15 UTC+2 schreef ray.vandewalker:
Luke Kenneth Casson Leighton
> (CC'ing Liviu Ionescu and Jacob Bachmeyer as something like this might be
> useful for the microcontroller spec, John Hauser because he proposed
> modifications for RV32E and RV32EC to better use halfword and bytesize
> data, Kelly Dean because he proposed ideas on binary portability between
> RV32 and RV64, Michael Clark because of RV8 JIT, and Xan Phung in
> recognition of his ideas on Xcondensed).
>
> Thanks for linking to the Xcondensed proposal. My proposal was not so much a
> proposal for RV16 as for an alternative for the C extension using 16bit wide
> instructions with a comparable code compression characteristics as the
> standard C extension when used in combination with the full 32bit wide
> instructions with the following properties:
been on these lists for only a couple of months so have been catching
up, and i've seen quite a fair share of proposals and questions about
support for 8 and 16-bit integer operations, as well as some 16-bit FP
justifications.
such operations appear to be misaligned (haha) sorry *ma*ligned,
perplexingly with the justificattion "the world is going 64-bit, we
tolerate 32-bit, why on earth would you want 16 and 8 bit arithmetic"
and as a result there is load and store with zero and sign-extend into
the *full* extent of the 32/64-bit registers.
where such operations (8 and 16 bit) make sense is when you perform
multiples of those in parallel (Vector/SIMD), or you need to be
bit-level manipulation. so let's take a look...
* B Extension: place-holder
* V-Extension: i love it for its power and potential: sadly it's so
complex and comprehensive and all-or-nothing that there only one
implementation, and that's not been published.
at this point we can quietly say to ourselves a single word:
"...oops".
to address the problem of V-Extension being too complex and
comprehsnsive, i raised the following topic / question a couple of
days ago:
https://groups.google.com/a/groups.riscv.org/forum/#!topic/isa-dev/GuukrSjgBH8
borrowing from the V-Extension, the proposal basically boils down to a
single instruction: "please implicitly tag register N as being a
vector of length M, such that operations on register N implicitly
actually are carried out simultaneously across registers N through
N+M-1".
the basic assumption of this proposal was that it would be possible to
use the RV32 instructions to say "i'd like to do 32-bit vector
operations", and the RV64 instructions to say "i'd like to do 64-bit
vector operations", and i hadn't quite thought through how to do 8 and
16-bit operations completely.
i guess i kinda assumed that 16-bit operations were possible... but
was then shocked to find that they weren't *anywhere* in the spec: you
*have* to use the load/store with zero/sign-extend operations, and, in
a vector/SIMD world that's not going to fly as it wastes huge amounts
of space (and cycles).
with apologies at not quite being able to remember who it was (was it
richard herveille? i think it was you, wasn't it?), someone previously
raised the puzzling lack of symmetry in the instruction set: there is
an "impllcit-sized" add, a 32-bit add and a 64-bit add.
the implicit-sized operations *might* be the saving grace by which
it's possible to extricate from this hole, by borrowing (again) from
the V-Extension, by being able to say "please implicitly tag register
N as being of width M" where M is 8, 16, "original size" or
"future-reserved" (2 bits to store that). this would over-rule the
default "implicit-sized" operations to be of size M, indefinitely.
so in this way, rogier, there are a couple of possibilities:
(A) rather than add RV16 (and even RV8!) to the existing instruction
set, registers are "tagged" into a CSR with a size (exactly as is
proposed in V-Extension, right now). by setting the Vector length
equal to one, you have the means to use the "implicit-sized"
operations.
(B) you *still* add RV16 (and possibly even RV8) *not* so much because
someone might want to implement stand-alone 16-bit or 8-bit processors
(they might) but because those instructions would become *part of
RV32/64/128*.
so in the case that you describe, rogier, of condensed instructions in
the proposed RV16, they might not actually matter as much. to make
that clear: the counter-arguments against RV16 *did not take into
account* the fact that RV16 (or RV8) operations would be accessible to
RV32/64/128, and as such could reduce the burden of implementing a B
extension proposal, and also a simplified V extension proposal.
if Bit-wise operations are *forced* to be carried out on the full
(default) bit-width, how on earth do you do 16-bit rotate when it's
needed? or 8-bit rotate? it has to be *explicitly* coded into the
actual Bit-wise instruction, doesn't it?
and in some cases you *really cannot* do full (default, 32/64/128
bit-wise operations). for example here:
https://groups.google.com/a/groups.riscv.org/d/msg/isa-dev/zi_7B15kj6s/w9y_KHM0AwAJ
clifford points out that the proposed BGS (bit gatherer and shuffler)
instruction is limited deliberately to only 16 bits, because the
amount of control/bit-manipulation information required to arbitrarily
swap greater than 16 bits is simply too large.
.... but if there was an instruction which explicitly allowed the
operand size to be reduced to 16 or 8 bits, that problem is solved, is
it not?
anyway apologies to you, rogier, i'm not ignoring what you described :)
l.
Liviu Ionescu
> CC'ing Liviu Ionescu ... as something like
> with a comparable code compression characteristics as the standard
> C extension
As far as the microcontroller proposal is targetted, I already
mentioned that it does not focus on changes to the instruction set,
but to making the architecture more C/C++ friendly.
So, any instruction sets and encodings that will be agreed for the
privileged profile will probably be ok for the microcontroller profile
too, except the ABI, which needs a redesign to reduce the number of
registers saved by the caller and possibly be consistent with the
RV32E reduced number of registers.
In my oppinion, in a well designed architecture, the actual user
should have nothing to do with the instruction set at all, the
toolchain must deal with these details, not the end user.
This does not mean that the instruction set is not important, it
obviously it, but it is not the corner stone of the microcontroller
profile.
In addition, although I agree that there may be use cases that I did
not think about, I would not go below 32-bits registers and memory
space.
Regards,
Liviu
lk...@lkcl.net
On Wednesday, April 4, 2018 at 3:27:43 PM UTC+1, Rogier Brussee wrote:
(CC'ing Liviu Ionescu and Jacob Bachmeyer as something like this might be useful for the microcontroller spec,
John Hauser because he proposed modifications for RV32E and RV32EC to better use halfword and bytesize data,
Kelly Dean because he proposed ideas on binary portability between RV32 and RV64,
Michael Clark because of RV8 JIT,
and Xan Phung in recognition of his ideas on Xcondensed).
Ray Van De Walker
But, 32 registers are too many for most register allocators to use well, so I have always thought
this wasted some bits, and was a real opportunity for improvement.
If R-format instructions were recast for 16 registers, 3 bits are freed for an orthogonal size field.
Other formats could extend the immediate fields.
Five of the sizes are obvious: 8, 16, 32, 64, 128. The three unused sizes could handle the misty future.
The float set's R-mode instructions can then encode the D and Q R-format instructions.
Another way to handle sizes and types would have load instructions tag registers.
The tags then become part of the instruction decoding. That's a very different ISA, however.
You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
To post to this group, send email to isa...@groups.riscv.org.
Visit this group at https://groups.google.com/a/groups.riscv.org/group/isa-dev/.
Luke Kenneth Casson Leighton
<ray.van...@silergy.com> wrote:
> The user-mode I set is frozen, (and honestly, quite well-designed) so it's too late for a size field to be added to the ISA.
17.5. it's termed "element width". sizes are 8 16 32 64 128 and
"disabled". oh... i hadn't noticed before, there's... don't quite
understand the latter paragraphs (table 17.6)
17.12 then goes on to describe the vector instruction format(s),
17.14 describes the polymorphism feature (impllicit type-casting from
int to float including automatic zero sign-extension).
so there are two divergent aspects:
(1) what i proposed does not need a size field to be added to the
ISA. it *implicitly* marks registers as containing 8-bit (or 16-bit)
values, where the top bits would (implicitly) be left unaltered.
(2) i was asking if RV16 (and RV8?) were practical to add, with their
own complete ISA, such that there becomes now a separate add, separate
div, separate mul and so on, each carrying out 16-bit (or 8-bit)
operations respectively, *such that*, when added to the ISA, they
*augment* the RV32 and RV64 ISAs in an *identical* way to that which
the RV32 ISA augments the RV64 ISA.
> If R-format instructions were recast for 16 registers, 3 bits are freed for an orthogonal size field.
frozen) be a hypothetical but alternative way to gain 8-bit and 16-bit
operations, and that (1) or (2) above (as separate and distinct from
th hypothetical R-format recast) would still be feasible and/or worth
exploring?
l.

Richard Herveille
Sent from my iPhone
> On 4 Apr 2018, at 18:40, Ray Van De Walker <ray.van...@silergy.com> wrote:
>
> The user-mode I set is frozen, (and honestly, quite well-designed) so it's too late for a size field to be added to the ISA.
Adding a register size control register would not break the ISA and be fully backward compatible.
Richard

lkcl .
<richard....@roalogic.com> wrote:
>> On 4 Apr 2018, at 18:40, Ray Van De Walker <ray.van...@silergy.com> wrote:
>>
>> The user-mode I set is frozen, (and honestly, quite well-designed) so it's too late for a size field to be added to the ISA.
>
> The ISA is frozen. Any changes must ensure backward compatibility.
> Adding a register size control register would not break the ISA and be fully backward compatible.
l.
Rogier Brussee
(A) rather than add RV16 (and even RV8!) to the existing instruction
set, registers are "tagged" into a CSR with a size (exactly as is
proposed in V-Extension, right now). by setting the Vector length
equal to one, you have the means to use the "implicit-sized"
operations.
(B) you *still* add RV16 (and possibly even RV8) *not* so much because
someone might want to implement stand-alone 16-bit or 8-bit processors
(they might) but because those instructions would become *part of
RV32/64/128*.
so in the case that you describe, rogier, of condensed instructions in
the proposed RV16, they might not actually matter as much. to make
that clear: the counter-arguments against RV16 *did not take into
account* the fact that RV16 (or RV8) operations would be accessible to
RV32/64/128, and as such could reduce the burden of implementing a B
extension proposal, and also a simplified V extension proposal.
if Bit-wise operations are *forced* to be carried out on the full
(default) bit-width, how on earth do you do 16-bit rotate when it's
needed? or 8-bit rotate? it has to be *explicitly* coded into the
actual Bit-wise instruction, doesn't it?
and in some cases you *really cannot* do full (default, 32/64/128
bit-wise operations). for example here:
https://groups.google.com/a/groups.riscv.org/d/msg/isa-dev/zi_7B15kj6s/w9y_KHM0AwAJ
clifford points out that the proposed BGS (bit gatherer and shuffler)
instruction is limited deliberately to only 16 bits, because the
amount of control/bit-manipulation information required to arbitrarily
swap greater than 16 bits is simply too large.
.... but if there was an instruction which explicitly allowed the
operand size to be reduced to 16 or 8 bits, that problem is solved, is
it not?
anyway apologies to you, rogier, i'm not ignoring what you described :)
l.
Rogier Brussee
Op woensdag 4 april 2018 17:22:58 UTC+2 schreef Liviu Ionescu:
On 4 April 2018 at 17:27:44, Rogier Brussee (rogier....@gmail.com) wrote:
> CC'ing Liviu Ionescu ... as something like
> this might be useful for the microcontroller spec
...
> an alternative for the C extension using 16bit wide instructions
> with a comparable code compression characteristics as the standard
> C extension
Thank you, Rogier.
As far as the microcontroller proposal is targetted, I already
mentioned that it does not focus on changes to the instruction set,
but to making the architecture more C/C++ friendly.
So, any instruction sets and encodings that will be agreed for the
privileged profile will probably be ok for the microcontroller profile
too, except the ABI, which needs a redesign to reduce the number of
registers saved by the caller and possibly be consistent with the
RV32E reduced number of registers.
In my oppinion, in a well designed architecture, the actual user
should have nothing to do with the instruction set at all, the
toolchain must deal with these details, not the end user.
This does not mean that the instruction set is not important, it
obviously it, but it is not the corner stone of the microcontroller
profile.
In addition, although I agree that there may be use cases that I did
not think about, I would not go below 32-bits registers and memory
space.
Regards,
Liviu

Michael Chapman
Our proprietary 32 bit CPUs are often used to replace 8 and 16 bit cores and usually run code which originates from a code base which was created for an 8 or 16 bit cpu.
We have only 32 bit operations, but we do have [s|z]ext[b|h] instructions. However, we find that these are actually rarely required and are required even less in well written code.
The biggest use for the extend instructions is when a loop counter has been declared as something like uint8_t or uint16_t instead of just int and there is a possibility that the value could wrap around. In many cases it is possible for the compiler to avoid generating the extend instructions as it is easy enough to ascertain that the value will not ever wrap around.
My opinion is that you should fix the compiler rather than adding half word or byte signed and unsigned add instructions to the ISA. There are very few occasions where there they will be useful - even on code written for 8 or 16 bit cores.
We do have an option to support unaligned accesses on all our cores. On our smallest cores, customers very rarely use this option - even when their code is coming from an 8 or 16 bit processor.
I think unaligned accesses should be prohibited and dropped from the specification. At the moment the spec says that an unaligned access could be very slow. In which code will avoid ever using it. And then there is no point in having it in the spec at all.
A bit field insert instruction is often useful for deeply embedded code. I.e. an instruction which can take the n least significant bits from a register and insert them at an arbitrary position in another register without upsetting the other bits. This can be used for coding rotates as well.
16 registers is plenty for most applications we see. For RV32E I would still allow the possibility to have single precision floating point, but would not encode them into 16 bit instructions. I would also not have a separate floating point register file but use the same registers as for integer instructions. This reduces the context size required for each task in a small embedded RTOS and again, in practice for most code we see - even with floating point, 16 registers is enough.
Even in floating point intensive applications, there is little point in using up 16 bit instruction space with the floating point instructions. Leave them all as 32 bits.
--
You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
To post to this group, send email to isa...@groups.riscv.org.
Visit this group at https://groups.google.com/a/groups.riscv.org/group/isa-dev/.
To view this discussion on the web visit https://groups.google.com/a/groups.riscv.org/d/msgid/isa-dev/e3113485-a024-40e7-b931-cd4f316e366e%40groups.riscv.org.
Liviu Ionescu
> > As far as the microcontroller proposal is targetted, I already
> > mentioned that it does not focus on changes to the instruction
> set,
> > but to making the architecture more C/C++ friendly.
>
> Which seems eminently sensible.
Regards,
Liviu
Rogier Brussee
oof, whoops rogier, the cc list was borked! :) also i tracked down some cross-references to the various discussions you mention, for the benefit of people who may not have seen them (or wish to re-read and refresh their memories).
On Wednesday, April 4, 2018 at 3:27:43 PM UTC+1, Rogier Brussee wrote:(CC'ing Liviu Ionescu and Jacob Bachmeyer as something like this might be useful for the microcontroller spec,John Hauser because he proposed modifications for RV32E and RV32EC to better use halfword and bytesize data,
Kelly Dean because he proposed ideas on binary portability between RV32 and RV64,i *think* it's this link (kelly, rogier, can you confirm?)
ok whoops that's important to note that it's "rv8 as in like google v8" *NOT* repeat *NOT* "RV8" as in "RV8, RV16, RV32, RV64, RV128...."
and Xan Phung in recognition of his ideas on Xcondensed).i believe you may be referring to this, rogier?
Rogier Brussee
Op woensdag 4 april 2018 18:40:18 UTC+2 schreef ray.vandewalker:
The user-mode I set is frozen, (and honestly, quite well-designed) so it's too late for a size field to be added to the ISA.
But, 32 registers are too many for most register allocators to use well, so I have always thought
this wasted some bits, and was a real opportunity for improvement.
If R-format instructions were recast for 16 registers, 3 bits are freed for an orthogonal size field.
Other formats could extend the immediate fields.
Five of the sizes are obvious: 8, 16, 32, 64, 128. The three unused sizes could handle the misty future.
Rogier Brussee
Op donderdag 5 april 2018 12:53:41 UTC+2 schreef Liviu Ionescu:
Regards,
Liviu
Liviu Ionescu
> ... people are more expensive and important than transistors.
nicely said. probably it should be the motto of the microcontroller profile.
> ... an easy to understand,
> be a deciding factor.
unfortunately I am not aware of any formal efforts to advance the
RISC-V microcontroller profile proposal :-(
regards,
Liviu
Luke Kenneth Casson Leighton
My opinion is that you should fix the compiler rather than adding half word or byte signed and unsigned add instructions to the ISA. There are very few occasions where there they will be useful - even on code written for 8 or 16 bit cores.
We do have an option to support unaligned accesses on all our cores. On our smallest cores, customers very rarely use this option - even when their code is coming from an 8 or 16 bit processor.
I think unaligned accesses should be prohibited and dropped from the specification. At the moment the spec says that an unaligned access could be very slow. In which code will avoid ever using it. And then there is no point in having it in the spec at all.
A bit field insert instruction is often useful for deeply embedded code. I.e. an instruction which can take the n least significant bits from a register and insert them at an arbitrary position in another register without upsetting the other bits. This can be used for coding rotates as well.
16 registers is plenty for most applications we see. For RV32E I would still allow the possibility to have single precision floating point, but would not encode them into 16 bit instructions. I would also not have a separate floating point register file but use the same registers as for integer instructions.
Luke Kenneth Casson Leighton
> On 5 April 2018 at 15:04:27, Rogier Brussee (rogier....@gmail.com) wrote:
>
>> ... people are more expensive and important than transistors.
>
> nicely said. probably it should be the motto of the microcontroller profile.
>> ... an easy to understand,
>> reliable, and easy to debug programming model for low level features will
>> be a deciding factor.
>
> I hope it will.
>
> unfortunately I am not aware of any formal efforts to advance the
> RISC-V microcontroller profile proposal :-(
external contributors) *and* V-Extension is stalled (i learned that
Hwacha was terminated in 2017, it's listed as a "former project" here:
http://people.eecs.berkeley.edu/~krste/)
whaaat's gooing ooon?
l.
Richard Herveille
http://people.eecs.berkeley.edu/~krste/)
The V-extensions are not stalled.
Hwacha is an implementation of a vector processor, but it is not compatible with the proposed V-extensions.
See Esperanto Technology’s presentations.
Richard
whaaat's gooing ooon?
l.
--
You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
To post to this group, send email to isa...@groups.riscv.org.
Visit this group at https://groups.google.com/a/groups.riscv.org/group/isa-dev/.
To view this discussion on the web visit https://groups.google.com/a/groups.riscv.org/d/msgid/isa-dev/CAPweEDzc8Mg9R9W7Unt-09%3De4RD6RjKjk%3DKsZvbD2_Y9B3Jabw%40mail.gmail.com.
Liviu Ionescu
> ... whaaat's gooing ooon?
well, on the Linux front, lots of things.
outside the Linux world... nothing. :-(
and don't expect any change soon, Krste clearly stated that the
official position is to maintain compatibility with the privileged
specs. which will probably discourage any use of RISC-V in
microcontrollers.
regards,
Liviu
On 17 March 2018 at 02:16:23, kr...@berkeley.edu (kr...@berkeley.edu) wrote:
> ... The
> new task group is looking at extending interrupt behavior, but
> with a
> view to maintaining backwards compatibility and to support
> dual-use
> cores that run either real-time or virtual-memory code.
Richard Herveille
microcontrollers.
There’s nothing from stopping us from writing a microcontroller spec which does not comply to the privilege spec, but still comply to the user spec and the other extensions.
Richard
regards,
Liviu
On 17 March 2018 at 02:16:23, kr...@berkeley.edu (kr...@berkeley.edu) wrote:
... The
new task group is looking at extending interrupt behavior, but
with a
view to maintaining backwards compatibility and to support
dual-use
cores that run either real-time or virtual-memory code.
--
You received this message because you are subscribed to the Google Groups "RISC-V ISA Dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to isa-dev+u...@groups.riscv.org.
To post to this group, send email to isa...@groups.riscv.org.
Visit this group at https://groups.google.com/a/groups.riscv.org/group/isa-dev/.
To view this discussion on the web visit https://groups.google.com/a/groups.riscv.org/d/msgid/isa-dev/CAG7hfcLUJt9DXDLJvA8-4Apyu7Zk-pQS7Uonng9RfrjEh6sjkA%40mail.gmail.com.
Luke Kenneth Casson Leighton
> On 5 April 2018 at 16:18:01, Luke Kenneth Casson Leighton (lk...@lkcl.net) wrote:
>
>> ... whaaat's gooing ooon?
>
> well, on the Linux front, lots of things.
>
> outside the Linux world... nothing. :-(
>
> and don't expect any change soon, Krste clearly stated that the
> official position is to maintain compatibility with the privileged
> specs.
Liviu Ionescu
> There’s nothing from stopping us from writing a microcontroller
> spec which does not comply to the privilege spec, but still comply
> to the user spec and the other extensions.
those who took the time to read it generally had positive feedback.
Krste also acknowledged that 'we also need a standard "rich"
microcontroller profile and that this should support C ISRs and
preemption/nesting efficiently'.
but apart from this... there were no further contributions. :-(
regards,
Liviu
Liviu Ionescu
> > official position is to maintain compatibility with the privileged
> > specs.
>
> why?
I already analysed this concern, and did not find it realistic:
https://github.com/emb-riscv/specs-markdown/blob/develop/improvements-upon-privileged.md#fragmentation-would-break-upward-compatibility
regards,
Liviu
Luke Kenneth Casson Leighton
single-sided double-layer PCBs that cost $50 to prototype and come
back in 24-48 hours from shenzhen factories (and about 7-10 days from
Eurocircuits for about the same price).
you're absolutely right about the embedded NAND and RAM (but didn't
mention the PMIC issue). *nobody* replaces a $0.32 STM32F030 or
$1.50 STM32F072, which can be powered from discrete components costing
$0.15 where the PCB costs $0.40 and assembly even less, where
prototypes can be made all-in for under $200 with a $4+ 400-pin
processor that takes up 8x the PCB space, needs a PMIC with *four*
inductors surrounding it, external DRAM, external NAND and a 4-layer
to 8-layer PCB that costs two THOUSAND dollars to get 10 samples made
up.
any company that tried that would quickly go out of business.
plus, the software that fits on embedded cores (1k, 8k, 16k, gosh you
have how much... you have 128k RAM on that micro-controller? wow
that's amazing!) is so tiny and so tied to the actual hardware that
you just... you _just_ don't port it, you rewrite it. the libraries
(libopencm3) are so hard-core specialist (libopencm3 is an exception
in that it provides abstracted APIs common to many many different ECUs
but is still so far from POSIX you might as well be talking Klatchian)
that a total rewrite to a linux-based OS - even if the SoC supported
all the same peripherals - would be about your only option.
so yeah i'd agree you pretty much nailed it.
the rest... i feel... yeah, the people in the RISC-V Foundation who
were controlling the specification for micro-controllers really were
out of their depth, with not enough knowledge and expertise on how
MCUs are deployed in commercial real-world applications.... and their
response was... to shut down the development of that part of the
specification.
i'm seeing a pattern, here.
l.
Michael Chapman
On Thu, Apr 5, 2018 at 11:46 AM, Michael Chapman <michael.c...@gmail.com> wrote:
My opinion is that you should fix the compiler rather than adding half word or byte signed and unsigned add instructions to the ISA. There are very few occasions where there they will be useful - even on code written for 8 or 16 bit cores.
if the only use-case was general-purpose computing i would absolutely agree with you. however would it not be reasonable to want to use RISC-V for 3D Graphics, Video Processing, Cryptographic algorithms, Audio processing, and many many more applications which normally you would easily spend $500k on for 3D, $200k for video, $100k for a cryptographics co-processor and $50k-$100k for an audio DSP and so on? these are not uncommon use-case scenarios [understatement: Xtensa were proud to announce their *billionth* license of their Audio DSP hard mcro, about ten years ago!]
We have other deeply embedded devices with similar costs (including one where the number of IOs and IO pad size determines the choice of process node and foundry rather than what is actually inside the chip - basically an IO pad costs more in smaller geometries).
that's an awful lot of money to be spending when you _could_ .... if RISC-V supported it... use a B-Extended SIMD/Simple-Vector extended 8/16-bit-capable RISC-V processor instead [hell, the cost of licensing the above hard macros *alone* justifies putting a team together to make that happen!].
looking at jeff bush's nyuzi 3D GPU analysis [1], he points out that the reason why software-defined GPUs have failed is because it's not the amount of processing that's so much the issue, it's the amount of power needed for the SRAM / L1 cache. once you've got the data into the ALU, it's *really* important to do as much work as possible before writing it back out of the registers.
if we want RISC-V to be successful in really rather high-profile mass-volume uses (cryptography, DSP work, Video, 3D, Tensors for AI), we *really* need to think beyond just the "general-purpose" scenario.
We do have an option to support unaligned accesses on all our cores. On our smallest cores, customers very rarely use this option - even when their code is coming from an 8 or 16 bit processor.
I think unaligned accesses should be prohibited and dropped from the specification. At the moment the spec says that an unaligned access could be very slow. In which code will avoid ever using it. And then there is no point in having it in the spec at all.
i also considered suggesting the same thing (to prohibit unaligned memory access). however... how would you then do audio processing of data that comes in from a DMA buffer, in 8, 16, 24 or 32-bit configurations (back-to-back samples with no word-alignment)? someone buys an off-the-shelf AC97 hard macro... they pay $50k to $100k for it and they *can't read the data*??? or they have to jump through insane hoops to get at it, by doing a multiply (shift by 8 or 16), then & to mask out unwanted bits, then divide (shift by 16 or 24) to get the lower bits? and do that on almost every single or every other audio sample?
so maybe the data rate of audio one might imagine that doing that would be fine... but for video processing (1080p60 which is nearly 500 mbytes per second of bandwidth for 32-bit pixels), you might think that going to 24-bit or 16-bit would save on bandwidth but on CPU cycles the above hoops to jump through would... you get the idea.
You are already far too late to market for HD!
A bit field insert instruction is often useful for deeply embedded code. I.e. an instruction which can take the n least significant bits from a register and insert them at an arbitrary position in another register without upsetting the other bits. This can be used for coding rotates as well.
clifford kindly elaborated on this very recently:
16 registers is plenty for most applications we see. For RV32E I would still allow the possibility to have single precision floating point, but would not encode them into 16 bit instructions. I would also not have a separate floating point register file but use the same registers as for integer instructions.
yes: i was quite surprised to see that FP has a separate register file. it makes sense from a perspective of an optimised implementation where the FPU runs separately from an ALU
(and those FENCE instructions are used to keep stuff in order). or.... no actually it doesn't make sense at all :)
On https://github.com/emb-riscv/specs-markdown/blob/develop/improvements-upon-privileged.md
It is true that by far the most common cause of crashes in a multi-threaded device is stack overflow. However, it is very easy for the compiler to add code to check for stack overflow and the overhead is really not great. There is no need for a HW register.The hardware stack limit register is expensive
"The stack limit register needs to be read and compared on every store via the stack register so it should have dedicated read circuit and comparator.
Yes, it is a small price to pay, but by far the most common cause of crashes in a multi-threaded device is stack overflow, so detecting this exception should be worth the extra price.
The RTOS has to context switch the stack limit register/global variable in any case.
Luke Kenneth Casson Leighton
I am talking about low cost micro-controllers
for deeply embedded devices such as SIM cards, Java cards etc, where the complete SOC (with NVM. peripherals and accelerators) sells for 10c including profit margin. One of our clients has made billions of those.
We have other deeply embedded devices with similar costs (including one where the number of IOs and IO pad size determines the choice of process node and foundry rather than what is actually inside the chip - basically an IO pad costs more in smaller geometries).
This is SIMD/Vector processing. Nothing to do with supporting wrap around 16 bit arithmetic for low cost microcontrollers running old code.
Any C compiler will generate the proper code to access unaligned data out of a packed structure without doing an unaligned load or store.
And that code is not that inane either. However, thought should be given to fixing the peripheral (or putting a wrapper around it) to present the data in a sensible format.
Fix the peripheral. If you are designing anything for video today, you should be doing it for 8K.
You are already far too late to market for HD!
Indeed - it is a shame that one implementation seems to have forced the ISA definition on this point.
> Microcontrollers should not be on networks
wtf??? try telling that to the people who sell ethernet, WIFI and BT Shields for Arduino-compatible devices!! 3D printer controller developers (dc42 and the developers of the smoothieboard) are going to be *pissed*! and ST Micro, "sorry, you know the high-end STM32* Cortex M-series devices - all 90 of them [1] - that you sell with MII ethernet PHY support, i'm sorry, you're going to have to stop selling those because microcontrollers should not be on networks" ???> "Generally, microcontrollers should probably not be on networks, except
> possibly for multi-core versions that can handle real-time tasks on
> one core and network latency on the other."
sorry for getting a bit sarcastic / low-grade humour there but i'm really quite taken aback at what i'm learning.
Rogier Brussee
Op donderdag 5 april 2018 14:50:33 UTC+2 schreef Liviu Ionescu:
regards,
Liviu
Liviu Ionescu
> You seem to be doing a good job. I like your proposals.
If you have any proposals on how to improve them, please let me know.
At a certain point, when RISC-V QEMU will be more usable outside
Linux, I'll try to emulate a device based on this proposal, so we'll
have a platform to test the microcontroller software.
Liviu

Xan Phung
and Xan Phung in recognition of his ideas on Xcondensed).
i believe you may be referring to this, rogier?
No this (unfortunately Xan seems to have removed his image)
Table 1: my 16 opcode version of RV Compressed
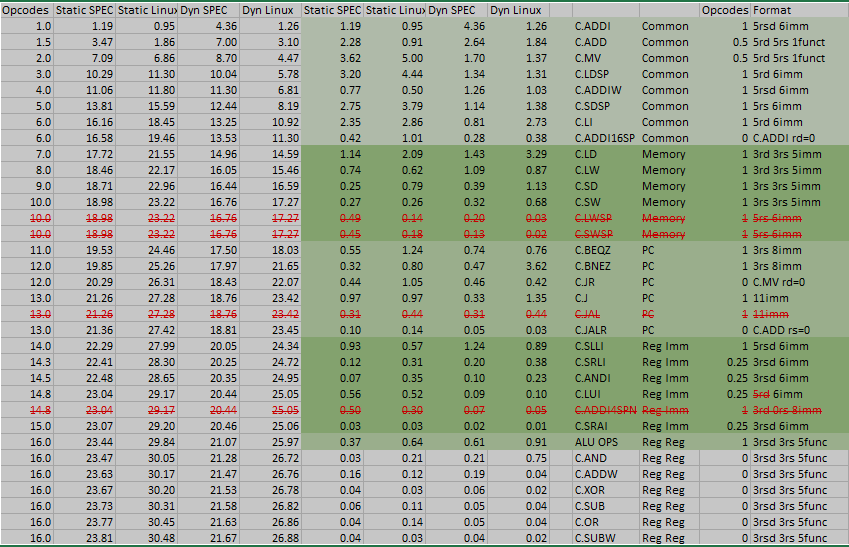


Alex Bradbury
>
> There’s nothing from stopping us from writing a microcontroller spec which
> does not comply to the privilege spec, but still comply to the user spec and
> the other extensions.
intended to make them cleanly separable, it's not clear to me that it
will be possible to jettison the privilege spec, implement a
non-standard alternative, and still have a core that can use the
'RISC-V' name. I do strongly hope this is possible, as it only seems
consistent with the flexibility available for the standard extensions.
Either way, it would be good to have clarity.
There was some discussion on this issue here
https://github.com/riscv/riscv-isa-manual/commit/a439dada57fe6c1ed426351742a5ba7dd2cace37#commitcomment-27447508
Best,
Alex
Richard Herveille
On 06/04/2018, 11:28, "Alex Bradbury" <a...@asbradbury.org> wrote:
<richard....@roalogic.com> wrote:
There’s nothing from stopping us from writing a microcontroller spec which
does not comply to the privilege spec, but still comply to the user spec and
the other extensions.
Although the separation between privileged and unprivileged is
intended to make them cleanly separable, it's not clear to me that it
will be possible to jettison the privilege spec, implement a
non-standard alternative, and still have a core that can use the
'RISC-V' name.
Note that I specifically omitted that claim. Given previous replies/emails I am afraid it won’t be recognized as RISC-V anymore.
We could call it R5M, but that leads to fragmentation, which should be avoided if possible.
I do strongly hope this is possible, as it only seems
consistent with the flexibility available for the standard extensions.
Either way, it would be good to have clarity.
Agreed. I hope the foundation shows some flexibility and leeway here.
Richard
Liviu Ionescu
hope is good, action is better.
https://github.com/riscv/riscv-isa-manual/blob/a9d7704765360679c1a5e3fa06e0b0e41d6c5f26/src/intro.tex#L57-L63
as long as these lines will not be changed, the privileged specs
remain part of the mandatory requirements.
and the first manual should cover only the instruction set (The RISC-V
Architecture: Instruction Set), without any mention to 'unprivileged',
or 'user' or anything that reminds the 'privileged' specs.
regards,
Liviu
Luke Kenneth Casson Leighton
crowd-funded eco-conscious hardware: https://www.crowdsupply.com/eoma68
On Fri, Apr 6, 2018 at 12:36 PM, Richard Herveille
<richard....@roalogic.com> wrote:
>
>
> On 06/04/2018, 11:28, "Alex Bradbury" <a...@asbradbury.org> wrote:
> Note that I specifically omitted that claim. Given previous replies/emails I
> am afraid it won’t be recognized as RISC-V anymore.
>
> We could call it R5M, but that leads to fragmentation, which should be
> avoided if possible.
>
>
> I do strongly hope this is possible, as it only seems
>
> consistent with the flexibility available for the standard extensions.
>
> Either way, it would be good to have clarity.
>
>
>
> Agreed. I hope the foundation shows some flexibility and leeway here.
the Director of the RISC-V Foundation for that purpose.
Rick: there appears to be a general consensus and disenfranchisement
with the unintentional exclusion of libre and open hardware
contributors (shutting down of WGs without warning being one of many
examples), who for various reasons (financial and ethical) cannot or
will not join the RISC-V Foundation, and yet would have an
extraordinary amount to contribute to the development of RISC-V *if*
they were actually empowered and enabled to do so.
That they have not been able to do so is resulting in them wishing to
take matters into their own hands and to go ahead with their own
initiative, effectively forking the RiSC-V ISA.
If we do not hear from you with a proposal that allows libre and open
hardware contributors to take a more active role in RISC-V's
development and steering, in a way that is both financially and
ethically respectful of our independent sovereign status as separate
from Corporate interests that primarily make up the members of the
RISC-V Foundation, we will ASSUME that it is perfectly acceptable to
proceed, without the RISC-V Foundation taking any action, to
effectively fork the development of RISC-V under a different name.
If that is not clear please do not hesitate to *publicly* discuss
this in an open fashion on the RISC-V mailing lists. We look forward
to hearing from you but if we do not, we will ASSUME that our proposed
direction is perfectly acceptable and compatible with the RISC-V
Foundation and that no action can or will be taken which prevents and
prohibits us from exploring the options that the RISC-V Foundation has
closed to us without wider consultation and consideration.
thanks.
l.
lkcl
<lk...@lkcl.net> wrote:
> If that is not clear please do not hesitate to *publicly* discuss
> this in an open fashion on the RISC-V mailing lists. We look forward
> to hearing from you but if we do not, we will ASSUME that our proposed
> direction is perfectly acceptable and compatible with the RISC-V
> Foundation and that no action can or will be taken which prevents and
> prohibits us from exploring the options that the RISC-V Foundation has
> closed to us without wider consultation and consideration.
otherwise, it will be perfectly acceptable to discuss AND MANUFACTURE
AND SELL commercial implementations of the same, without license,
restriction or impediment, any fork or enhancement / extension to
RISC-V, under a different name (yet to be decided), as long as the
RISC-V Trademark is not utilised in any such commercially-sold
libre-licensed implementations.
l.

Samuel Falvo II
<richard....@roalogic.com> wrote:
> Although the separation between privileged and unprivileged is
>
> intended to make them cleanly separable, it's not clear to me that it
>
> will be possible to jettison the privilege spec, implement a
>
> non-standard alternative, and still have a core that can use the
>
> 'RISC-V' name.
>
>
>
> Note that I specifically omitted that claim. Given previous replies/emails I
> am afraid it won’t be recognized as RISC-V anymore.
There are a plurality of ARM variants (some very small, some large
enough to run server workloads), not all of which are binary
compatible with each other. Yet they are all still recognized as
being ARM variants, and I seem quite well insulated from any
vociferous concerns over whether or not a variant is Linux-compatible,
etc. In fact, my ONLY exposure to concerns about how fragmented Linux
support for ARM devices is has come from this very mailing list.
I think the industry is smarter than you give it credit for.
Once upon a time, if memory serves me right, support for the
privileged specification was denoted as RV64S or RV32S. Then, it was
changed so that U and S denoted support for user-mode and
supervisor-mode. I think, then, all one needs to do is just allocate
an additional letter to denote the final privilege specification:
machine-mode. For example, I'm always very careful to state that my
KCP53000 processor supports the RV64I instruction set <<and version
1.9 of the M-mode only privileged subset>>, but I have no convenient
way of denoting the bracketed part of that phrase. I'd love to be
able to label my ISA support level as RV64I_0.9 (where _ is some
officially sanctioned letter indicating machine-mode per the draft
specs).
Looking at the current, online version of the draft privilege
specifications, the misa register documentation reserves no bit nor
provides any indication of a letter to indicate machine mode is
supported. I'm thinking the framers thought it superfluous, as if
you're reading misa, you must obviously support the rest of M-mode
too. But, this need not be true; CSR instructions are not M-mode
specific; they're actually defined in user ISA now, although excepting
for fcsr, no specific CSRs have been defined.
Perhaps it's time to isolate misa from M-mode, and allocate a bit for
the draft proposed machine-mode, as has been done for S and U?
Given that, this issue becomes moot, an exercise in labeling the
correct compliance level (e.g., RV64IMXmyCustomMachineMode vs
RV32IM_SU).
--
Samuel A. Falvo II
lkcl
> On Fri, Apr 6, 2018 at 4:36 AM, Richard Herveille
> enough to run server workloads), not all of which are binary
> compatible with each other. Yet they are all still recognized as
> being ARM variants, and I seem quite well insulated from any
> vociferous concerns over whether or not a variant is Linux-compatible,
> etc. In fact, my ONLY exposure to concerns about how fragmented Linux
> support for ARM devices is has come from this very mailing list.
ridiculous the ARM situation is, and have been writing - publicly -
for the past TWELVE YEARS - about it, many many times.... not that
anybody cared what the hell i said because, hey, My Name's Not Linus
Or {insert N.E.Other well-known prominent free software guru}. Ten
years ago i heard that there were *OVER SEVEN HUNDRED* separate
licensees of some ARM design. Since then with Cortex M and many more
designs that number will have gone through the roof.
Efforts by ARM to standardise on AXI-Bus internal identifiers (similar
to USB IDs), that would have made hard macro interfaces much much
easier to identify in a dynamic fashion, went COMPLETELY IGNORED by
implementors licensing ARM's processors, who decided in their infinite
wisdom to set that AXI-Bus ID field to *ZERO*.
Now... do you think that ARM would tolerate having people discuss the
*disadvantages* of their eco-system on forums under their own control
(hint: ARM *actively* censors discussions on their forums, in case you
were ever wondering), such that you would find it easy to *find* such
disadvantages in an easily documented and clear fashion?
So the fact that you've only just heard - on here - that ARM's
eco-system is a huge gelatinous mess is probably because it's
attracted people who are willing and feel comfortable discussing such
limitations... and then wish to learn from them.
Whether that actually happens (the "Learning") remains to be seen.
I'm seeing evidence which tends to suggest that despite having a clear
goal and clear foundational guiding principles, which have resulted in
an absolutely amazing and astoundingly well assembled ISA so far,
there is clear cognitive dissonnance in how the RISC-V Foundation is
run, a feedback mechnism that is either non-existent, extremely
restrictive or completely broken for *both* how the RISC-V Foundation
itself is run *and* how it makes technical decisions, that is going to
have consequences and affect whether the RISC-V Foundation can achieve
its clearly-stated and extremely laudble mission if those issues are
not addressed.
l.
Liviu Ionescu
> Perhaps it's time to isolate misa from M-mode,
M-mode/S-mode/U-mode, should be decoupled from the instruction set,
and moved from Volume I to Volume II.
The microcontroller profile proposal has no benefits from keeping any
compatibility with the current M-mode; the few CSRs kept were
reorganised, mainly to make context switching easier.
Maybe I'm wrong, but if we take a look at the current Linux context
switch routine, there are 5 CSRs saved:
https://github.com/torvalds/linux/blob/38c23685b273cfb4ccf31a199feccce3bdcb5d83/arch/riscv/kernel/entry.S#L90-L100
The microcontroller profile uses only one word for the hart status.
---
The point is that the modes, as defined now, are probably fine for the
privileged profile, but a different profile (like the microcontroller
profile) can be designed to make a better use of them.
Regards,
Liviu
Samuel Falvo II
On 6 April 2018 at 19:43:19, Samuel Falvo II (sam....@gmail.com) wrote:
> Perhaps it's time to isolate misa from M-mode,
I think that the idea of 'modes', as they are known now,