The hardware implementation of Atomic instruction in RISCV and performance differences compared to HTM
657 views
Skip to first unread message

jagten leo
May 24, 2023, 9:45:13 AM5/24/23
to RISC-V ISA Dev
1. I'm confused with "registers a reservation set" in the sentence "LR.W loads a word from the address in rs1, places the sign-extended value in rd, and registers a reservation set—a set of bytes that subsumes the bytes in the addressed word" from page 48 Volume I: RISC-V Unprivileged ISA V20191213.
I want to know if the reservation set is registered in the cache during the load request from load reaserve instruction, Because the CPU cannot be sure if it will store conditional successfully when executing store conditional, only the L1 Cache first knows if an ST has occurred after LR, and the CPU's store conditional cannot be retained in the store buffer and Should be sent to the cache. If store conditional carries rl attribute, does it mean that the entries in front of store buffer need to be sent to the cache in order before the entry of store conditional can be sent to the cache? And the cache needs special handling when receiving the store conditional request. If any probe of a store matching the address is received during lr/sc, it should fail, and give a feedback signal to the CPU to set rd register of store conditional instruction non-zero, flush the instruction beginning with lr.
Is there something wrong with my understanding?
2. I'm also confused with "set of bytes that subsumes the bytes in the addressed word" in the sentence above!
From what I just understood, if the reservation set is on the cache side, then the granularity of the cache detection conflict is a cacheline and whether it is necessary to record as byte granularity?
3. I'm confused with "livelock" in the sentence "The main disadvantage of LR/SC over CAS is livelock, which we avoid, under certain circumstances, with an architected guarantee of eventual forward progress as described below.
As I know, The interconnect will sequence the store to the same cacheline, And always the core that executes sc first succeds, and the other core that executes SC later fails! So I can't imagine any scenario that could lead to a live lock. I saw a post saying that load will also cause sc failure, but this is not consistent with the stipulations in spec "An SC may succeed only if no store from another hart to
the reservation set can be observed to have occurred between the LR and the SC, and if there is no other SC between the LR and itself in program order."4. Can someone tell me how real riscv hardware implements stomicadd isntruction from a cpu and interconnection collaboration perspective.
All I can think of is the implementation of macro instructions, such as when cpu load the value then lock the bus, and release the bus only when wirte has completed to insure the atomic semantics of read-modify-write! Or As described in the spec, implement AMOs at memory controllers.

5. Does anyone know about the possible performance differences between HTM and atomic instructions,just As spec said that "More generally, a multi-word atomic primitive is desirable, but there is still considerable debate about what form this should take, and guaranteeing forward progress adds complexity to a system. Our current thoughts are to include a small limited-capacity transactional memory buffer along the lines of the original transactional memory proposals as an optional standard extension “T”"

Any help will be appreciated!

MitchAlsup
May 24, 2023, 6:49:21 PM5/24/23
to RISC-V ISA Dev, jagten leo
On Wednesday, May 24, 2023 at 8:45:13 AM UTC-5 jagten leo wrote:
1. I'm confused with "registers a reservation set" in the sentence "LR.W loads a word from the address in rs1, places the sign-extended value in rd, and registers a reservation set—a set of bytes that subsumes the bytes in the addressed word" from page 48 Volume I: RISC-V Unprivileged ISA V20191213.I want to know if the reservation set is registered in the cache during the load request from load reaserve instruction, Because the CPU cannot be sure if it will store conditional successfully when executing store conditional, only the L1 Cache first knows if an ST has occurred after LR, and the CPU's store conditional cannot be retained in the store buffer and Should be sent to the cache. If store conditional carries rl attribute, does it mean that the entries in front of store buffer need to be sent to the cache in order before the entry of store conditional can be sent to the cache? And the cache needs special handling when receiving the store conditional request. If any probe of a store matching the address is received during lr/sc, it should fail, and give a feedback signal to the CPU to set rd register of store conditional instruction non-zero, flush the instruction beginning with lr.Is there something wrong with my understanding?
The above is an Architectural statement that holds across implementations, all cache line sizes, all cache hierarchies, all TLB-page sizes,.....
What you are asking is where in µArchitecture is the reservation applied ?? {The word register means "to establish" in this context}
It could be put in the cache tag.
It could be put in the miss buffers.
It could be put between L1 cache and L2 Cache.
And several other places.
What you can be assured of is that some circuit (a monitor perhaps) in the µArchitecture holds that address and at least a bit mask of the accessed bytes, AND if an attempt to read-with-intent-to-modify or Coherent Invalidate (or any other access command that delivers write permission to the requestor) those bytes, THEN your SC will fail. We call this interference.
2. I'm also confused with "set of bytes that subsumes the bytes in the addressed word" in the sentence above!From what I just understood, if the reservation set is on the cache side, then the granularity of the cache detection conflict is a cacheline and whether it is necessary to record as byte granularity?
This is also an Architectural statement.
You are, in effect, asking about what happens when LL is misaligned and may cross a cache line boundary.....
3. I'm confused with "livelock" in the sentence "The main disadvantage of LR/SC over CAS is livelock, which we avoid, under certain circumstances, with an architected guarantee of eventual forward progress as described below.
LL/SC has a soft guarantee to software that forward progress can be made (albeit slowly under massive interference)--and the guarantee comes from the separation between LL and SC AND having some circuit monitor that address between LL and SC.
CAS implementations can reach a point where the system interconnect is saturated and no CAS can ever succeed (also only under massive contention). The failure is that the LD that eventually arrives at the CAS did not setup a monitor because it is NOT marked as participating in a ATOMIC event, and there is no monitor on the address, merely bit comparison on the data AT that address.
As I know, The interconnect will sequence the store to the same cacheline, And always the core that executes sc first succeds, and the other core that executes SC later fails! So I can't imagine any scenario that could lead to a live lock. I saw a post saying that load will also cause sc failure, but this is not consistent with the stipulations in spec "An SC may succeed only if no store from another hart tothe reservation set can be observed to have occurred between the LR and the SC, and if there is no other SC between the LR and itself in program order."4. Can someone tell me how real riscv hardware implements stomicadd isntruction from a cpu and interconnection collaboration perspective.
The general scheme is to bundle up the command, size, the address, and data into a single message and sent message through the memory hierarchy until it runs into the data, perform the work there, then return result to requestor. Since the data is read-modified-and-written before any other request can access that same unit of data, it appears ATOMIC even though it takes place over multiple cycles.
All I can think of is the implementation of macro instructions, such as when cpu load the value then lock the bus, and release the bus only when wirte has completed to insure the atomic semantics of read-modify-write! Or As described in the spec, implement AMOs at memory controllers.5. Does anyone know about the possible performance differences between HTM and atomic instructions,

Is there a successful implementation of HTM ? yet ?
just As spec said that "More generally, a multi-word atomic primitive is desirable, but there is still considerable debate about what form this should take, and guaranteeing forward progress adds complexity to a system. Our current thoughts are to include a small limited-capacity transactional memory buffer along the lines of the original transactional memory proposals as an optional standard extension “T”"Any help will be appreciated!

My ISA (which is not RISC-V) has what could be known of as pipeline LL and SC where as many as 8 cache lines can participate
in a single ATOMIC event. If you would like to understand it, you can find me on e-mail and strike up a conversation. My scheme
is not HTM but can be used to help software build a more efficient HTM.
Message has been deleted
jagten leo
May 24, 2023, 11:40:35 PM5/24/23
to RISC-V ISA Dev, MitchAlsup, jagten leo
On Wednesday, May 24, 2023 at 8:45:13 AM UTC-5 jagten leo wrote:1. I'm confused with "registers a reservation set" in the sentence "LR.W loads a word from the address in rs1, places the sign-extended value in rd, and registers a reservation set—a set of bytes that subsumes the bytes in the addressed word" from page 48 Volume I: RISC-V Unprivileged ISA V20191213.I want to know if the reservation set is registered in the cache during the load request from load reaserve instruction, Because the CPU cannot be sure if it will store conditional successfully when executing store conditional, only the L1 Cache first knows if an ST has occurred after LR, and the CPU's store conditional cannot be retained in the store buffer and Should be sent to the cache. If store conditional carries rl attribute, does it mean that the entries in front of store buffer need to be sent to the cache in order before the entry of store conditional can be sent to the cache? And the cache needs special handling when receiving the store conditional request. If any probe of a store matching the address is received during lr/sc, it should fail, and give a feedback signal to the CPU to set rd register of store conditional instruction non-zero, flush the instruction beginning with lr.Is there something wrong with my understanding?The above is an Architectural statement that holds across implementations, all cache line sizes, all cache hierarchies, all TLB-page sizes,.....What you are asking is where in µArchitecture is the reservation applied ?? {The word register means "to establish" in this context}It could be put in the cache tag.It could be put in the miss buffers.It could be put between L1 cache and L2 Cache.And several other places.
What you can be assured of is that some circuit (a monitor perhaps) in the µArchitecture holds that address and at least a bit mask of the accessed bytes, AND if an attempt to read-with-intent-to-modify or Coherent Invalidate (or any other access command that delivers write permission to the requestor) those bytes, THEN your SC will fail. We call this interference.
Thanks a lot, I got it! I want to clarify some of the details here in order to better compare the possible performance differences between HTM and atomic instructions
2. I'm also confused with "set of bytes that subsumes the bytes in the addressed word" in the sentence above!From what I just understood, if the reservation set is on the cache side, then the granularity of the cache detection conflict is a cacheline and whether it is necessary to record as byte granularity?This is also an Architectural statement.You are, in effect, asking about what happens when LL is misaligned and may cross a cache line boundary.....
I'm sorry. what I'm confused is that, when L1 recieves probe request from other harts or interconnet, the requests usually does not carry mask information just as AC channel in the AMBA ACE protocol, that is to say, L1 can only know that another hart may write to this cache line but does not know which byte to write to!
maybe the monitor circuit as you said can get information from the interconnect only which knows which bytes will be written by other hart!
3. I'm confused with "livelock" in the sentence "The main disadvantage of LR/SC over CAS is livelock, which we avoid, under certain circumstances, with an architected guarantee of eventual forward progress as described below.
LL/SC has a soft guarantee to software that forward progress can be made (albeit slowly under massive interference)--and the guarantee comes from the separation between LL and SC AND having some circuit monitor that address between LL and SC.
CAS implementations can reach a point where the system interconnect is saturated and no CAS can ever succeed (also only under massive contention). The failure is that the LD that eventually arrives at the CAS did not setup a monitor because it is NOT marked as participating in a ATOMIC event, and there is no monitor on the address, merely bit comparison on the data AT that address.
1. what I think of as a livelook is that hart A terminates hart B, then hart B re-executes ll/sc loop and terminates hart A!
Each ll/sc sequence may cause other ll/ SCS to fail only when sc is issued to the interconnection at the end of the sequence unless a normal write to that address is issued in the middle of the ll/sc!
So What I can think of is that there one of the two sides will succeed and the other side will fail and may cause one side hunger but no livelock!
just as the figure below that hartA may fail many times and become hunger but hart B is over with success and there is no chance that hart A will stop it
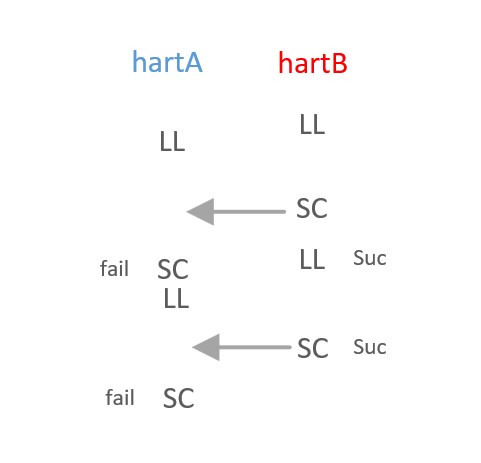
CAS implementations can reach a point where the system interconnect is saturated and no CAS can ever succeed (also only under massive contention). The failure is that the LD that eventually arrives at the CAS did not setup a monitor because it is NOT marked as participating in a ATOMIC event, and there is no monitor on the address, merely bit comparison on the data AT that address.
I only know the semantic of cas from the internet and I notice that RISC-V ISA-spec adds CAS instructions not long ago!


And I can't imagine what you're saything why all CAS will fail! Can you talk more about the implementation of CAS From the perspective of the difference between CAS and ll/sc! (Let's not worry about ABA for a moment)
5. Does anyone know about the possible performance differences between HTM and atomic instructions,
Is there a successful implementation of HTM ? yet ?
just As spec said that "More generally, a multi-word atomic primitive is desirable, but there is still considerable debate about what form this should take, and guaranteeing forward progress adds complexity to a system. Our current thoughts are to include a small limited-capacity transactional memory buffer along the lines of the original transactional memory proposals as an optional standard extension “T”"
Any help will be appreciated!
My ISA (which is not RISC-V) has what could be known of as pipeline LL and SC where as many as 8 cache lines can participate
in a single ATOMIC event. If you would like to understand it, you can find me on e-mail and strike up a conversation. My scheme
is not HTM but can be used to help software build a more efficient HTM.
Here is what I know about HTM is that entering HTM there is no need to use atomic instructions and Just use normal load and store instructions But There is some overhead to entering HTM and rollback when abort
Thanks a lot! I am very interested in your scheme and I would like to contact you later
MitchAlsup
May 25, 2023, 3:07:03 PM5/25/23
to RISC-V ISA Dev, jagten leo, MitchAlsup
On Wednesday, May 24, 2023 at 10:40:35 PM UTC-5 jagten leo wrote:
On Wednesday, May 24, 2023 at 8:45:13 AM UTC-5 jagten leo wrote:1. I'm confused with "registers a reservation set" in the sentence "LR.W loads a word from the address in rs1, places the sign-extended value in rd, and registers a reservation set—a set of bytes that subsumes the bytes in the addressed word" from page 48 Volume I: RISC-V Unprivileged ISA V20191213.I want to know if the reservation set is registered in the cache during the load request from load reaserve instruction, Because the CPU cannot be sure if it will store conditional successfully when executing store conditional, only the L1 Cache first knows if an ST has occurred after LR, and the CPU's store conditional cannot be retained in the store buffer and Should be sent to the cache. If store conditional carries rl attribute, does it mean that the entries in front of store buffer need to be sent to the cache in order before the entry of store conditional can be sent to the cache? And the cache needs special handling when receiving the store conditional request. If any probe of a store matching the address is received during lr/sc, it should fail, and give a feedback signal to the CPU to set rd register of store conditional instruction non-zero, flush the instruction beginning with lr.Is there something wrong with my understanding?The above is an Architectural statement that holds across implementations, all cache line sizes, all cache hierarchies, all TLB-page sizes,.....What you are asking is where in µArchitecture is the reservation applied ?? {The word register means "to establish" in this context}It could be put in the cache tag.It could be put in the miss buffers.It could be put between L1 cache and L2 Cache.And several other places.What you can be assured of is that some circuit (a monitor perhaps) in the µArchitecture holds that address and at least a bit mask of the accessed bytes, AND if an attempt to read-with-intent-to-modify or Coherent Invalidate (or any other access command that delivers write permission to the requestor) those bytes, THEN your SC will fail. We call this interference.Thanks a lot, I got it! I want to clarify some of the details here in order to better compare the possible performance differences between HTM and atomic instructions
2. I'm also confused with "set of bytes that subsumes the bytes in the addressed word" in the sentence above!From what I just understood, if the reservation set is on the cache side, then the granularity of the cache detection conflict is a cacheline and whether it is necessary to record as byte granularity?This is also an Architectural statement.You are, in effect, asking about what happens when LL is misaligned and may cross a cache line boundary.....I'm sorry. what I'm confused is that, when L1 recieves probe request from other harts or interconnet, the requests usually does not carry mask information just as AC channel in the AMBA ACE protocol, that is to say, L1 can only know that another hart may write to this cache line but does not know which byte to write to!
The incoming request either has a size (non-cacheable) or is line-size (cacheable). From this information, the monitor can decide it interference has transpired.
maybe the monitor circuit as you said can get information from the interconnect only which knows which bytes will be written by other hart!3. I'm confused with "livelock" in the sentence "The main disadvantage of LR/SC over CAS is livelock, which we avoid, under certain circumstances, with an architected guarantee of eventual forward progress as described below.LL/SC has a soft guarantee to software that forward progress can be made (albeit slowly under massive interference)--and the guarantee comes from the separation between LL and SC AND having some circuit monitor that address between LL and SC.
CAS implementations can reach a point where the system interconnect is saturated and no CAS can ever succeed (also only under massive contention). The failure is that the LD that eventually arrives at the CAS did not setup a monitor because it is NOT marked as participating in a ATOMIC event, and there is no monitor on the address, merely bit comparison on the data AT that address.1. what I think of as a livelook is that hart A terminates hart B, then hart B re-executes ll/sc loop and terminates hart A!
Many times one needs more parties to establish livelock. But yes, this is the general scheme; some kind of loop is setup where A causes B to fail, B causes C to fail, c.....causes A to fail; and nobody is making forward progress.
Each ll/sc sequence may cause other ll/ SCS to fail only when sc is issued to the interconnection at the end of the sequence unless a normal write to that address is issued in the middle of the ll/sc!So What I can think of is that there one of the two sides will succeed and the other side will fail and may cause one side hunger but no livelock!just as the figure below that hartA may fail many times and become hunger but hart B is over with success and there is no chance that hart A will stop itCAS implementations can reach a point where the system interconnect is saturated and no CAS can ever succeed (also only under massive contention). The failure is that the LD that eventually arrives at the CAS did not setup a monitor because it is NOT marked as participating in a ATOMIC event, and there is no monitor on the address, merely bit comparison on the data AT that address.I only know the semantic of cas from the internet and I notice that RISC-V ISA-spec adds CAS instructions not long ago!How does the cpu ensure that no other hart will modify the value at the rs1 address between loading the value of rs1 and writing the value of rs2?
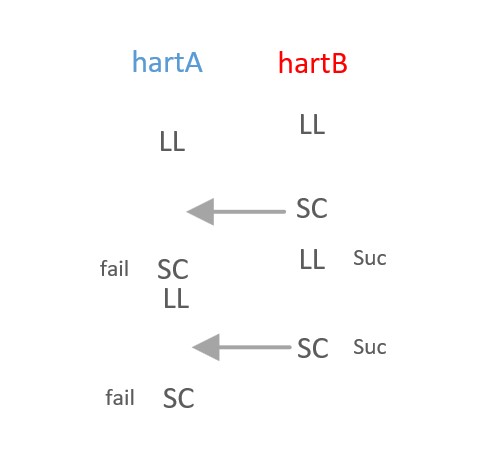

This is the advantage of LL/SC--an address monitor can be setup to watch accesses to *[rs1] between LL and SC. If interference is detected, SC fails.
(Whether it is possible to lock the bus, and I noticed Support for locking the bus has been dropped from AXI4【IHI0022G_amba_axi_protocol_spec】, Do you know any other ways?)
Yes, but not relevant to RISC-V.
And I can't imagine what you're saything why all CAS will fail! Can you talk more about the implementation of CAS From the perspective of the difference between CAS and ll/sc! (Let's not worry about ABA for a moment)

I am not saying all CAS implementations will always fail, but CAS is a data-based atomic operation and is even subject to the A-B-A synchronization problem. {This actually happened:: an OS task started a CAS atomic event, an interrupt transpired, and the task was put to sleep for a whole week! when the task woke up it attempted the CAS primitive and found the data matched, the CAS was performed; and then the system went down. You see the data values were the same, but the data at those locations had nothing to do with the thread trying to complete its ATOMIC event and also nothing to dow .}
5. Does anyone know about the possible performance differences between HTM and atomic instructions,
Is there a successful implementation of HTM ? yet ?
just As spec said that "More generally, a multi-word atomic primitive is desirable, but there is still considerable debate about what form this should take, and guaranteeing forward progress adds complexity to a system. Our current thoughts are to include a small limited-capacity transactional memory buffer along the lines of the original transactional memory proposals as an optional standard extension “T”"Any help will be appreciated!
My ISA (which is not RISC-V) has what could be known of as pipeline LL and SC where as many as 8 cache lines can participate
in a single ATOMIC event. If you would like to understand it, you can find me on e-mail and strike up a conversation. My scheme
is not HTM but can be used to help software build a more efficient HTM.
The commercial HTM I know of is intel and IBM power and ARM has added TME (transactional memory) to armv9!
Intel is having "problems" with its HTM--with several known attack vectors.
Here is what I know about HTM is that entering HTM there is no need to use atomic instructions and Just use normal load and store instructions But There is some overhead to entering HTM and rollback when abort
Yes, I have seen a SW HTM where a single atomic "configuration" value is used. As the transaction steps are performed, a new container for each unit of data is allocated and updated and linked back to single value. If the transaction finishes and everything went all right, then the single value is changed 0->1, and then everybody walking that part of the data-structure sees the transaction as having been complete, if they see that their value has changed they know their transaction will fail. This has extra overhead, but requires zero support at the HW level above that of single data locking. {And I can't remember the name of the process right now.}
jagten leo
May 25, 2023, 8:25:25 PM5/25/23
to MitchAlsup, RISC-V ISA Dev
Thanks a lot!
'MitchAlsup' via RISC-V ISA Dev <isa...@groups.riscv.org> 于2023年5月26日周五 03:07写道:
--
You received this message because you are subscribed to a topic in the Google Groups "RISC-V ISA Dev" group.
To unsubscribe from this topic, visit https://groups.google.com/a/groups.riscv.org/d/topic/isa-dev/Bau3QqQlpTU/unsubscribe.
To unsubscribe from this group and all its topics, send an email to isa-dev+u...@groups.riscv.org.
To view this discussion on the web visit https://groups.google.com/a/groups.riscv.org/d/msgid/isa-dev/4f93b298-f245-4f8e-919d-c5977e0a4446n%40groups.riscv.org.
Reply all
Reply to author
Forward
0 new messages