[Web facing change PSA] Heads-up: Faster assets with the HTTP caching extension "stale-while-revalidate"

Kenji Baheux
Blinkeuses, Blinkeurs
Chromeuses, Chromeurs
Baring any unexpected events, we’ll start the implementation work for one of the HTTP caching extensions proposed by Mark Nottingham. Specifically, the “stale-while-revalidate” extension to the cache-control header.
This extension gives webmasters the ability to let the cache serve slightly stale content, as long as it refreshes things in the background.
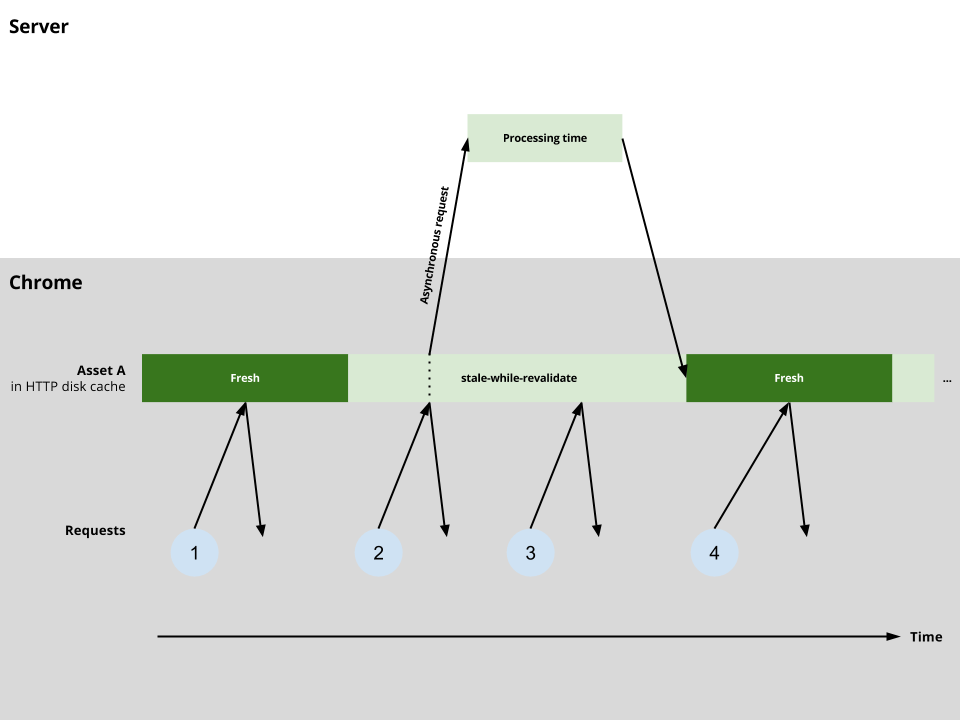
This should results in faster page loads for regularly visited websites and sites that use popular third party web services (e.g. analytics, ads, social, web fonts...).
Improvements
With a reasonably sized stale-while-revalidate window(*), the following improvements would be achieved:
1. Less blocking requests
The re-validations of blocking assets (e.g. some of the css/js assets, web fonts) would not block the page anymore given that re-validation requests would happen asynchronously after the page is loaded.
2. Improved network usage efficiency
Asynchronous re-validations will improve opportunity costs. In other words, there will be more bandwidth and simultaneous connections available for other requests.
Example
With an HTTP response containing the following header:
Cache-Control: max-age=86400, stale-while-revalidate=604800
max-age indicates that the asset is fresh for 1 day,
-
and stale-while-revaldiate indicates that the asset may continue to be served stale for up to an additional 7 days while an asynchronous re-validation is attempted.
References
- RFC 5861.
- crbug.com/348877: Feel free to star it to show your support or to simply follow along.
- Support for HTTP cache control extensions can be found in proxy like Squid.

Yoav Weiss
To unsubscribe from this group and stop receiving emails from it, send an email to blink-dev+...@chromium.org.
Kenji Baheux
Note for Yoav: Thanks for the feedback! I posted a reply but it either got lost or it's not showing up yet; I'll wait a day or so and re-post if needed.
follow up, part 1:
How to choose a good value for stale-while-revalidate
I've spent some time thinking this through but it's quite possible that I missed something. Don't hesitate to point any oversights or better solutions :)
In order to maximize the benefits of this header, one should pick a value that minimize the number of synchronous requests for as many access patterns as one can afford (e.g. daily access, weekly access).
Part 1: assets that are served by-and-for the visited website
Perhaps a slightly contrived example but lets consider a website that is accessed every morning but mainly on weekdays. Let’s also assume an original max-age of 43200 seconds (12 hours).
A bad choice would be:
Cache-Control: max-age=43200, stale-while-revalidate=43200
This gives a maximal lifetime of 1 day and incorrectly assume that your website (and its ssets) is accessed precisely every 24 hours. If your user slightly deviates from that expectation, he will suffer some extra re-validations. Also, the Monday commute is guaranteed to be comparatively bad.
A decent choice would be:
Cache-Control: max-age=43200, stale-while-revalidate=172800
This gives a maximal lifetime of 2 days and 12 hours. This will work for users who access the site religiously every weekday as well as the users who access almost every weekday. The only downside: the Monday commute will still be comparatively bad (Friday morning to Monday morning > 60 hours).
A better choice would then be:
Cache-Control: max-age=43200, stale-while-revalidate=259200
This gives a maximal lifetime of 3 days and 12 hours. This would then solve the poor user experience on the Monday commute.
Comments welcomed!

William Chan (陈智昌)
Kenji Baheux
Kenji Baheux
Do you know if other browsers have plans to support these extensions?
Also - I noticed that the proposal draft has long expired. Is there a current draft of these proposals? If not, can we revive the old draft?
- originally, Mark had 2 drafts for stale-while-revalidate and stale-if-error
- he merged them into http://tools.ietf.org/html/draft-nottingham-http-stale-controls-00
- which eventually became RFC 5861
Kenji Baheux
follow up, part 2:
Continuation of How to choose a good value for stale-while-revalidate
Part 2: the asset is served for other websites (e.g. analytics, ads, social, web fonts...)
Determine your “window of comfort”:
Determine how long you are willing to have stale assets used in the wild (e.g. backward compatibility burden). When you only had max-age at your disposal, things were straightforward but with the introduction of stale-while-revalidate it’s a little bit more involved.
- Unless you do something fancy on the server side(1), you will need to think about assets created 2 x (max-age + stale-while-revalidate) seconds ago.
- The 2x factor might seem surprising but it's actually there in the max-age only case.
(1): In Part 3, I will share extra thoguhts about this topic and explain the 2x factor.
Generic goals:
maximize stale-while-revalidate to minimize synchronous re-validation requests
maximize max-age to minimize any kind of traffic
minimize max-age to minimize time to deliver updates
-
minimize (max-age + stale-while-revalidate) in order to meet your “window of comfort” requirement
Concrete example:
With a service that other websites use via the inclusion of a JS asset, let’s assume the following conditions:
original max-age of 1 day
-
an effectiveness of 90% is desired from the stale-while-revalidate header
with a day-time timeframe of 3 hours, the probability that any given user would visit a website using the asset consistently crosses the 90% target(2)
a night-time timeframe of 6 hours should be excluded in order to guarantee point 3.
-
the service can cope with obsolete-by-a-week versions of the asset
(2): true for any days of the week or any time of the year.
A bad choice would be:
Cache-Control: max-age=86400, stale-while-revalidate=10800
This gives a maximal lifetime of 1 day and 3 hours. It’s highly unlikely that the stale-while-revalidate window would be large enough for a significant number of users. For instance, if the asset enters its stale-while-revalidate period near the beginning of the night, we would end up with a truly stale asset on the next morning.
A reasonable choice would be:
Cache-Control: max-age=86400, stale-while-revalidate=32400
This gives a maximal lifetime of 1 day and 9 hours (3+6). Which is enough to go over the night and get a 90% hit from a 3 hour window on the next morning.
Now let’s assume that:
- the service is developing new features and wants the ability to push updates about twice as fast in case something goes wrong.
- the service can handle twice as much re-validation traffic
A good choice would then be:
Cache-Control: max-age=43200, stale-while-revalidate=82800
The maximal lifetime is unchanged (1 day and 11 hours) but max-age has been cut in half for the benefit of the stale-while-revalidate window.
Closing remark on fine-tuning needs
Kenji Baheux
Follow-up, Part 3:
Preface
stale-while-revalidate doesn’t introduce any new problems. If you are familiar with the implications of max-age, there isn’t anything new per say. For instance, when it comes to solving the “instant update” problem, the same technique of revving the resource name via a fingerprint or version number would be used. The problem outlined from the next section is specific to the few resources that must maintain the same URL.
If you are still a bit confused, head over Mark’s blog: he recently published a great post about the stale-while-revalidate header in the context of web browsers.
Deep dive on the “window of comfort”
In the second follow-up installment, I introduced the “window of comfort” as an initial consideration before thinking about the value of stale-while-revalidate and max-age (note the errata*):
Determine your “window of comfort”:
Determine how long you are willing to have stale assets used in the wild (e.g. backward compatibility burden). When you only had max-age at your disposal, things were straightforward but with the introduction of stale-while-revalidate it’s a little bit more involved.
-
Unless you do something fancy on the server side(1), you will need to think about all the assets that were actively served max-age + stale-while-revalidate seconds ago.
In a max-age (= X) only setup, consider the following scenario:
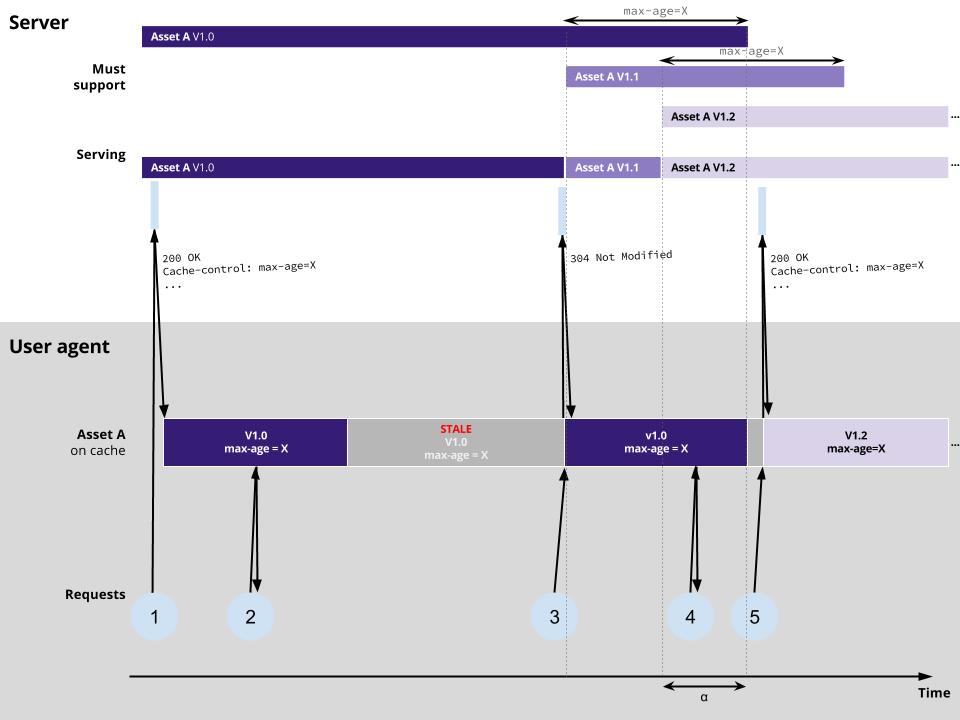
As you can see, there is a period of time, marked α, during which the service is expected to work with all 3 versions of Asset A (1.0, 1.1, 1.2).
And similarly, with a max-age=M, stale-while-revalidate=S setup:
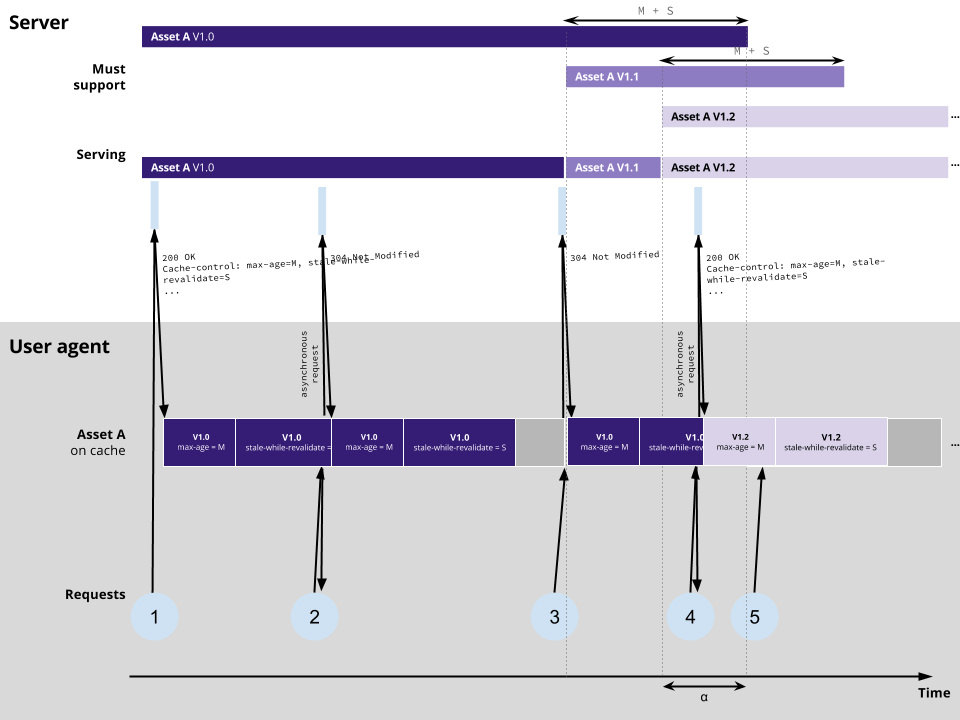
How to minimize the burdern of supporting older versions of an asset
While the issue isn’t specific to stale-while-revalidate (a max-age only setup has the same issues), addressing it can help further maximize the stale-while-revalidate window.
Maybe this is a widely known method but just in case, here is how one could theoretically only support the latest version of a given asset at any given time:
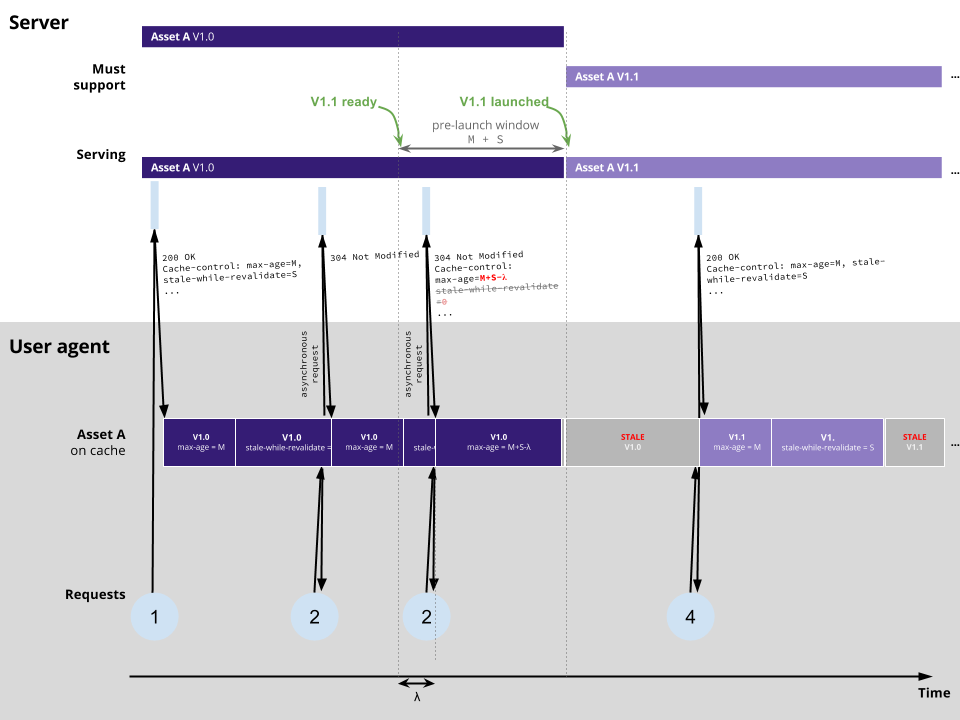
As soon as you have a new version of your asset (e.g. V1.1), you can setup a pre-launch window whose length is equal to max-age+stale-while-revalidate. During that window, your server should use a dynamically computed cache-control header for its 200s and 304s responses regarding asset A:
Cache-control: max-age=M+S-λ
Where λ represents how many seconds have passed since the beginning of the pre-launch window.
Theoretically, this will guarantee that any V1.0 in the wild will be stale by the time you launch V1.1. In practice, you might want to keep support for V1.0 around for a little while in order to deal with the usual shenanigans.
*: about the errata: the 2x factor came from a scenario that assumed that the lifetime of an asset was always equal to max-age.
Kenji Baheux
- opportunity assessment
- scenarios/use cases (RFC compliant implementation, custom HTTP header for monitoring/fine tuning the values, integration with devtools, integration with Resource Timing API)
- launch plan. In particular our intent is to experiment/iterate before deciding to stick with the feature.

Chris Bentzel
Kenji Baheux
Looks cool, thanks for pushing on this.
I am interested in when you are planning on doing the revalidation step. For example - if the main html resource for a page has stale-while-revalidate but there is no network connection at present do you queue up revalidations when that happens? Also - do you try to queue up revalidations so that these don't wake up the radio if all resources for a navigation are in cache?
Initial versions could just do revalidation at the time the staled cache entry is returned and we aren't any worse off than the current state of affairs (and better since the user is saved the latency), but just wondering if there are plans beyond that.
- scheduling as much as possible when plugged-in and/or on WiFi
- avoiding taking risky bets (e.g. issue a HEAD request for infrequently used resources, abandon if you get a 200 OK for a large resource given that it's not used all that much)
Chris Bentzel

Christian Biesinger
Hey,I'm curious, how do you guys see this interacting with voluntary revalidates -- eg when the user explicitly refreshes the page?I've been studying the behavior of Facebook's CDN recently. Most of our resources are served with a long term TTL and are invalidated by changing the name of the resource. On Chrome, even for resources that are maintained this way, we see roughly 60% of requests to our CDN result in a 304 not modified. This is largely because Chrome has a peculiar behavior on pages that are redirected to after a POST request (https://code.google.com/p/chromium/issues/detail?id=294030). Even on other browsers without this behavior, we see roughly 15-20% of requests to our CDN result in a 304 not modified.Our static resource system NEVER changes a resource after it is created. We'd really like to make it so that a user who refreshes Facebook's home page (likely wanting to see an updated feed) doesn't send redundant requests to our CDN -- or at the very least doesn't block the page rendering.If we sent a stale-while-revalidate on our static resources, would Chrome respect this header on an explicit refresh?-b

Ricardo Vargas
Hey,I totally agree that the expectation of the user is that when they refresh all resources are up to date with the latest version from the server.However, it's common for applications to know that URLs are truly static. For example, Facebook's static resource system generates urls like: https://static.xx.fbcdn.net/rsrc.php/v2/yV/r/l_C8JMZfIdK.js. There is no circumstance which would ever cause the content of this URL to change. If we want to change the content of this file, our system will generate a new URL and change any references.If a website like Facebook knows that a given URL will never change, it should be able to communicate that to chrome. When the user refreshes the page, they will still see up to date versions of every resource since the server is telling the client that those URLs are never going to change.In https://code.google.com/p/chromium/issues/detail?id=294030 we measured the impact of working around Chrome's behavior of sending conditional responses for static resources on pages that get a redirect from a POST. We saw a substantial increase in a number of our engagement metrics. Therefore, we'd really like to get the number of conditional requests down to zero for any resource that uses unique URLs.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/net-dev/CABgOVaLyQ441HAcFty%2BEUN_oHKwHOHBJH5_D8LEHzyg7HJuPUA%40mail.gmail.com.--
You received this message because you are subscribed to the Google Groups "net-dev" group.
To unsubscribe from this group and stop receiving emails from it, send an email to net-dev+u...@chromium.org.
To post to this group, send email to net...@chromium.org.

Ben Maurer

Darin Fisher
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/net-dev/CABgOVa%2B%2BRdjFra-3Z6OBfe54Exeue9GWr95jF%3D2xdG_3E7S0-A%40mail.gmail.com.
Ben Maurer
That said, we'd also love to get these requests off our CDN -- even though 304s use minimal bandwidth, it's a non-trivial usage of CPU resources.
On Mon, Jun 16, 2014 at 11:19 AM, Ben Maurer <ben.m...@gmail.com> wrote:
15-20% is a substantial chunk of our CDN usage. Eliminating this would likely have a noticeable impact on our performance and engagement metrics.
I'm guessing engagement implies "faster page load --> more user activity"? In which case, stale-while-revalidate should still deliver that because the browser wouldn't block the page render on the revalidation request -- right? It wouldn't reduce the load on the CDN, but that's a separate concern.ig
Ben Maurer
Darin Fisher
Yep, some other folks from the Chrome team pointed that out to me -- it's a very interesting spec. That said, if one of the goals of reloading is trying to help the user fix an issue on the page (as Ricardo pointed out), the more site specific logic we add to the reload event the higher the risk of us having bugs that cause the reload not to work. I suspect only developers know about shift+reload.
Serving a static resource with a long TTL is an explicit best practice (eg https://developers.google.com/speed/articles/caching suggests "If your resources change more often than that, you can change the names of the resources. A common way to do that is to embed a version number into the URLs. The main HTML page can then refer to the new versions as needed."). It'd be great if Chrome could increase the performance of reloads for people who follow this advice without requiring the use of Service Worker.
Ben Maurer
Kenji Baheux
Do you have thoughts on how we could evaluate a change to the behavior of reloading static resources? Three potential options for doing this that I mentioned in this thread are (1) using stale-while-revalidate
I'm guessing engagement implies "faster page load --> more user activity"? In which case, stale-while-revalidate should still deliver that because the browser wouldn't block the page render on the revalidation request -- right? It wouldn't reduce the load on the CDN, but that's a separate concern.
- first time would kick sync and async revalidations
- second time would use the new resources obtained via the async revalidations and kick another round of sync and async revalidations.
- some network connectivity issues (taking too long, lost connection)
- issues with some of the resources
- want to see the latest updates
- #1: reload happened while Chrome was still busy with network requests
- #2: one of the revalidation for the immutable/fresh assets got a 2XX response
- #3: all the rest?
- RegularReload is used on the order of 35 times per 10k page loads.
- IgnoreCacheReload is used about once every 20K page loads.
(2) Using a new cache control header stating that the resource is immutable (3) not revalidating far-in-the-future TTLs. What are the risks you are worried about and how might they be mitigated for these options.
- Expires, max-age, stale-while-revalidate values
- (now - last-modified)
- history of past responses
- # of successive reload in a short timeframe as a proxy for user frustration
- ...
This suggests that perhaps any measure that caused the browser not to revalidate a resource on reload should only apply to subresources, not the root document. As long as we always revalidate the root document, the developer can always fix their server to return a 200 response and then rename any subresources on the page.
Ben Maurer
3. Motivations for hitting reloadI'm wondering what are the main motivations for hitting reload:
- some network connectivity issues (taking too long, lost connection)
- issues with some of the resources
- want to see the latest updates
If we could measure each of these, we would be able to make an informed decision about these async revalidations. Strawman:
- #1: reload happened while Chrome was still busy with network requests
- #2: one of the revalidation for the immutable/fresh assets got a 2XX response
- #3: all the rest?
- RegularReload is used on the order of 35 times per 10k page loads.
- IgnoreCacheReload is used about once every 20K page loads.
This suggests that perhaps any measure that caused the browser not to revalidate a resource on reload should only apply to subresources, not the root document. As long as we always revalidate the root document, the developer can always fix their server to return a 200 response and then rename any subresources on the page.
I think that this would not work for the third party services integrated on a page. Say, your favorite analytics solution served a wonky response with a max-age=1year. It would be painful for them to get all of their customers to fix their integration. With the ideas above, we should be able to come up with a failsafe solution.
Kenji Baheux
On Mon, Jun 16, 2014 at 6:19 PM, Kenji Baheux <kenji...@chromium.org> wrote:
3. Motivations for hitting reloadI'm wondering what are the main motivations for hitting reload:
- some network connectivity issues (taking too long, lost connection)
- issues with some of the resources
- want to see the latest updates
If we could measure each of these, we would be able to make an informed decision about these async revalidations. Strawman:
- #1: reload happened while Chrome was still busy with network requests
- #2: one of the revalidation for the immutable/fresh assets got a 2XX response
- #3: all the rest?
One other metric to look at here might be reload time - original view time. If this is long it suggests #3.
It'd be really interesting to get more stats on this.
- RegularReload is used on the order of 35 times per 10k page loads.
- IgnoreCacheReload is used about once every 20K page loads.
That seems kind of low given the % of our responses that are 304s. Do you have any metrics on the overall rate of 304s chrome gets? Or maybe metrics from Google's CDN?
This suggests that perhaps any measure that caused the browser not to revalidate a resource on reload should only apply to subresources, not the root document. As long as we always revalidate the root document, the developer can always fix their server to return a 200 response and then rename any subresources on the page.
I think that this would not work for the third party services integrated on a page. Say, your favorite analytics solution served a wonky response with a max-age=1year. It would be painful for them to get all of their customers to fix their integration. With the ideas above, we should be able to come up with a failsafe solution.Can we maybe assume here that anybody smart enough to be a huge 3rd party analytics service is also smart enough to not serve their JS with a crazy TTL. Chances are if the 3rd party analytics script was served with a long TTL it wouldn't actually break the page, and users wouldn't know to refresh.Imagine that Google Analytics or the Facebook Like Button accidentally served a version of our JS with a 1 year TTL. Even with the rules browsers use today, we'd be pretty screwed.
- let's imagine that Google Analytics or the Facebook Like Button accidentally served a wonky version of their JS with a not too crazy max-age (e.g. couple of hours, a day).
- If the regular Reload doesn't trigger any revalidation, the user would have to
- Shift+Reload or nuke the cache to get the fixed version.
- wait max-age seconds at most and access the site.
Ben Maurer
If we can prove that Reloads are the main cause of the remaining 15-20% (as seen on other browsers which are not affected by crbug.com/294030) then it seems worth considering improving Reload's behavior.
The other cause I can think of is that max-age seconds have passed and we issue a revalidation. But I expect this to explain a relatively small fraction of the requests.