disabling flaky tests

Evan Martin
marked as “flaky” as instead “disabled”.
This will cause such tests to stop running on the build bots. If
you’re currently tracking down why a test is flaky, or intend to do so
in the future, read on for how and why.
Currently tests that are marked with a “FLAKY_” prefix still run on
the bots, but whether they pass or fail is ignored by the bots. For a
recent run on the bots 1% of all tests we ran, more than a thousand,
were marked FLAKY.
We currently have a web of interdependent problems around flaky tests
and it’s difficult to find which thread to first pull. When a test
begins to unreliably fail it’s difficult to determine the cause,
because the bots take a long time to cycle (providing fewer runs worth
of data and larger blamelists per change), but the bots take a long
time to cycle in part due to flaky tests taking time.
I intend to start pulling. Concretely, I plan to:
1) Use a sed script to rename every FLAKY_foo test to DISABLED_foo.
2) Institute a zero-tolerance policy for flaky tests. If a test ever
fails for reasons other than a bad change causing it to regress we
disable it.
Q1. Won't we lose test coverage?
A. We're already ignoring the success/fail of flaky tests. When they
fail, the bot stays green.
Q2. Shouldn't we instead fix those tests?
A. Yes, I agree 100%. But realistically that hasn't happened. We can
talk a lot about blame or what ought to be done but nobody has stepped
up. I am stepping up.
Q3. Shouldn’t we instead do [insert complicated engineering solution here]?
A. I have lots of ideas like this too, but unless you’re volunteering
to do such work then your idea isn’t very useful.
Q4. How will people diagnose a test that they think is flaky?
A. Once I’ve done this sweeping change, you can mark a test as FLAKY_
again and collect data for it. I just want to reset all tests that
aren't currently being worked on. (When I looked into which flaky
tests were slowest I found the slowest one has had a bug open on it
for nearly a year, no action taken.) I would like to follow up this
change with some policy (either verbal or in code) like "if a test is
marked flaky for more than a few days it goes back to disabled unless
someone says they're working on it".
Q5. Why not leave the tests marked flaky, and just only run the tests
marked flaky on a different bot?
A. When a test is flaky it's often flaky on just a specific
configuration or specific machine. To get full configuration coverage
for a separate flaky set of tests we'd need a second copy of every bot
in existence, from Mac 10.5 debug to Linux ChromeOS Aura Clang. It's
better to allow people who want to analyze a test to have them run on
exactly the same bots that normal tests would run on, via the above
FLAKY_ mechanism.
Q6. Often a test is marked flaky but it’s due to some unrelated
problem, like the browser crashing on startup. It’s not fair to
disable the test!
A. Regardless of who is at fault, an unreliable test has a cost across
the team that outweighs its utility. (In fact, people who didn’t
author the test are perhaps even more impacted by it, as they
redundantly attempt to track down whether they’re at fault for
regressing it.)
Q7. How can I prevent my test from getting disabled?
A. The more isolated a test is from the rest of Chrome, the more
reliable it becomes and the faster it runs. (For example, each
individual browser_test takes around ten seconds to run on XP debug.)
Converting your tests to unit tests (as distinct from the integration
tests we usually do, see
http://en.wikipedia.org/wiki/Software_testing#Unit_testing ) will
help.
Q8. What is the performance impact of this?
A. I grabbed the output for a single cycle across all the bots earlier
this week.
Not running all flaky tests would reduce the total wall time spent in
tests by 9%, saving just under an hour. But because we run bots in
parallel the actual cycle time impact varies per bot. The maximally
impacted test suite by percentage impact shaves off 96% of its
runtime, and the maximally impacted bot by time shaves off 6 minutes
(10%).

James Hawkins
--
Chromium Developers mailing list: chromi...@chromium.org
View archives, change email options, or unsubscribe:
http://groups.google.com/a/chromium.org/group/chromium-dev

Stuart Morgan
memory smasher in another test in the same binary, or some sort of
random bot issue, instead of ignoring that one-off failure and moving
on the process will be:
1) Someone disables it
2) They file a bug
3) Someone (hopefully) takes the bug
4) That person re-enables it FLAKY to get data
5) They monitor it for several days to see that it's always green
6) They remove the FLAKY marker
This seems like huge amount of overhead, especially for something that
is supposed to be reducing the drain on the team. Can you explain what
the compelling advantage of "zero tolerance" over "much lower than
current, but non-zero tolerance" is that is worth this cost? We
already have the dashboards that let us distinguish between one-off
failures and tests that are actually flaky.
-Stuart
Evan Martin
Could you contrast the above procedure against the alternative you're
proposing? I'm not sure I follow.
Stuart Morgan
> Could you contrast the above procedure against the alternative you're
> proposing? I'm not sure I follow.
The alternative procedure is to check the flakiness dashboard when a
test flakes, and if there's no indication that the test has any
history of flake, skip all the other steps and save a lot of
unnecessary work for one-off failures. If it really is flaky, it'll
fail a second time and get disabled then.
The cost of waiting for a second failure seems a lot lower than the
cost of dealing with a lot of false-positive disabling.
-Stuart
Evan Martin
I guess you're talking about which action should be taken when a test
fails. I think I was premature in bringing that up, as it's not a
direct conclusion of what I'm doing right now but rather where I
intend to head.
There are different options with different tradeoffs, but no option
seems very satisfactory to me. Yours seems to optimize forging ahead
at the cost of making every person who makes a change a Chrome needing
to be able to reason through whether any given test fails. Mine has
collateral test suite damage but simpler reasoning.
Let me walk you through an example of where my reasoning comes from.
I don't know about you, but my experience with the commit queue is
that the majority of my changes take multiple (automated) tries to get
through. E.g. looking through my recent history my second-most-recent
was https://chromium-status.appspot.com/cq/evan%40chromium.org/9316110/4002
. It took three tries on Mac, the second of which involved a
45-second timeout.
Prompted by this email, I looked into the problem. Its adjacent test
that uses the same signalling mechanism is already marked flaky, and
this test also frequently times out on the commit queue:
http://code.google.com/p/chromium/issues/detail?id=95058 ). My point
is not to pick on this test or Macs in particular, but rather to note
that I don't have the time to track down why my Linux-only (literally:
this change adjusted Linux compiler flags) failed on a Mac bot. And
apparently nor does anyone else; from that bug's log, it appears this
test (not the one already marked flaky, but the one that delayed my
commit by nearly thirty minutes) has timed out many times, causing
many different people's jobs to be delayed and retried.
We'd all have been better off with this test turned off a long time
ago. That isn't to say that the test isn't useful, or that its
failure isn't a real problem, but rather that given that it's not
fixing itself, we're better off without it than with it. I don't see
a better way to amortize the cost of fixing this kind of problem other
than by making it everyone's problem. I would have personally
disabled the test if I had felt I had the authority to.
PS: At some level if you have a random memory smasher in your test
suite, no amount of disabling will save you (unless you manage to
accidentally disable the memory smasher). But at the same time, a
test suite with a random memory smasher is not very useful.

James Cook
appreciate changes that reduce the time I spend looking at test
failures in code I didn't affect.
I've been hacking on Chrome for about a year now and my first few
months were filled with terror whenever I got email from the build
system -- I had no idea what the failing tests were supposed to do,
and I was 95% sure I didn't affect them, but with hundreds of people
tracking ToT was I *sure* I didn't break something?
Disabling all our current flaky tests has my support. It's like the
step in "Inbox Zero" that says "delete your inbox." It's painful, and
might lose something, but it can help you get to a better place.
James

Dirk Pranke
> <stuart...@chromium.org> wrote:
>> Le 13 février 2012 22:56, Evan Martin <ev...@chromium.org> a écrit :
>>> Could you contrast the above procedure against the alternative you're
>>> proposing? I'm not sure I follow.
>>
>> The alternative procedure is to check the flakiness dashboard when a
>> test flakes, and if there's no indication that the test has any
>> history of flake, skip all the other steps and save a lot of
>> unnecessary work for one-off failures. If it really is flaky, it'll
>> fail a second time and get disabled then.
>>
>> The cost of waiting for a second failure seems a lot lower than the
>> cost of dealing with a lot of false-positive disabling.
>
> I guess you're talking about which action should be taken when a test
> fails. I think I was premature in bringing that up, as it's not a
> direct conclusion of what I'm doing right now but rather where I
> intend to head.
>
> There are different options with different tradeoffs, but no option
> seems very satisfactory to me. Yours seems to optimize forging ahead
> at the cost of making every person who makes a change a Chrome needing
> to be able to reason through whether any given test fails. Mine has
> collateral test suite damage but simpler reasoning.
>
I think perhaps the question is how long a grace period a flaky test
should have. Clearly, we shouldn't disable a test immediately after it
fails once - you wouldn't be able to distinguish a flake from a
regression. Arguably a test that was passing fine now failing every
other time probably indicates a regression (and not just a flaky test)
as well. However, if a test fails 1 out 10 times, or 1/100, or 1/1000,
and you don't have a good past history of passing to draw on ... I'm
not sure where the best place to draw the line is
(We have this problem in spades in the layout tests right now ...
fortunately marking tests as flaky or not just involves tweaking
test_expectations.txt, not changing code, making this more amenable to
automation).
-- Dirk

Shawn Singh

Peter Kasting
I thought the idea was to skip FLAKY tests, not re-categorize them to DISABLED.

Fred Akalin
--

Mihai Parparita
Perhaps adding "-*FLAKY*" to --gtest_filters for the command lines of our build/trybots?
Peter Kasting
Perhaps adding "-*FLAKY*" to --gtest_filters for the command lines of our build/trybots?
Shawn Singh
Fred Akalin

Mark Larson (Google)
Summary: This week I’m going to mass-mark every test we’ve currently
marked as “flaky” as instead “disabled”.
This will cause such tests to stop running on the build bots. If
you’re currently tracking down why a test is flaky, or intend to do so
in the future, read on for how and why.
Currently tests that are marked with a “FLAKY_” prefix still run on
the bots, but whether they pass or fail is ignored by the bots. For a
recent run on the bots 1% of all tests we ran, more than a thousand,
were marked FLAKY.
We currently have a web of interdependent problems around flaky tests
and it’s difficult to find which thread to first pull. When a test
begins to unreliably fail it’s difficult to determine the cause,
because the bots take a long time to cycle (providing fewer runs worth
of data and larger blamelists per change), but the bots take a long
time to cycle in part due to flaky tests taking time.
I intend to start pulling. Concretely, I plan to:
1) Use a sed script to rename every FLAKY_foo test to DISABLED_foo.
2) Institute a zero-tolerance policy for flaky tests. If a test ever
fails for reasons other than a bad change causing it to regress we
disable it.
Q1. Won't we lose test coverage?
A. We're already ignoring the success/fail of flaky tests. When they
fail, the bot stays green.
Q2. Shouldn't we instead fix those tests?
A. Yes, I agree 100%. But realistically that hasn't happened. We can
talk a lot about blame or what ought to be done but nobody has stepped
up. I am stepping up.
Q3. Shouldn’t we instead do [insert complicated engineering solution here]?
A. I have lots of ideas like this too, but unless you’re volunteering
to do such work then your idea isn’t very useful.
Q4. How will people diagnose a test that they think is flaky?
A. Once I’ve done this sweeping change, you can mark a test as FLAKY_
again and collect data for it. I just want to reset all tests that
aren't currently being worked on. (When I looked into which flaky
tests were slowest I found the slowest one has had a bug open on it
for nearly a year, no action taken.) I would like to follow up this
change with some policy (either verbal or in code) like "if a test is
marked flaky for more than a few days it goes back to disabled unless
someone says they're working on it".
Sreeram Ramachandran
> As for losing the flaky bit when mass-renaming to disabled, I think the fact
> that that info is still in svn/git is good enough.
Better still might be to rename the test to DISABLED_FLAKY_Test, so
that it's clear when looking at the code what happened to the test (or
if that's too confusing, perhaps DISABLED_WasFlaky_Test or such).

Rachel Blum
Better still might be to rename the test to DISABLED_FLAKY_Test, so
that it's clear when looking at the code what happened to the test (or
if that's too confusing, perhaps DISABLED_WasFlaky_Test or such).
Szymon Jakubczak
DISABLED tests are a graveyard (once a test enters, it never comes
back to life)? If so, shouldn't we actually cut them out of the source
to speed up build times?

James Cook
> months were filled with terror whenever I got email from the build
> system -- I had no idea what the failing tests were supposed to do,
> and I was 95% sure I didn't affect them, but with hundreds of people
> tracking ToT was I *sure* I didn't break something?
I realized last night that my comment has nothing to do with Evan's
work. His plan cuts cycle times. It neither increases nor decreases
the chance a particular build run will hit a not-known-to-be-flaky
test.
However, shorter cycle times mean narrower lists of revision ranges to
examine when investigating a failure, and less anxious waiting time
for test results. Full steam ahead!
James

Scott Hess
>> I've been hacking on Chrome for about a year now and my first few
>> months were filled with terror whenever I got email from the build
>> system -- I had no idea what the failing tests were supposed to do,
>> and I was 95% sure I didn't affect them, but with hundreds of people
>> tracking ToT was I *sure* I didn't break something?
>
> I realized last night that my comment has nothing to do with Evan's
> work. His plan cuts cycle times. It neither increases nor decreases
> the chance a particular build run will hit a not-known-to-be-flaky
> test.
It decreases the chances, because what you know FOR CERTAIN about
flaky tests is that something is wrong. In some cases, the test is
flaky because it tickles something latent, this won't improve those.
In other cases the test really is messing things up, and skipping
those will improve the environment for later tests.
-scott

Paweł Hajdan, Jr.
If recategorizing FLAKY to DISABLED is a loss, does this mean the
DISABLED tests are a graveyard (once a test enters, it never comes
back to life)? If so, shouldn't we actually cut them out of the source
to speed up build times?
In other cases the test really is messing things up, and skippingthose will improve the environment for later tests.

Scott Byer

Ricardo Vargas

Albert Bodenhamer
Albert Bodenhamer | Software Engineer | abodenha@chromium.org
Evan Martin
<abod...@chromium.org> wrote:
> Perhaps a good second step to this would be to automatically generate a high
> priority bug on any code without good test coverage? Perhaps some
> consequences for people who leave untested code laying around?
>
> That way we can call out uncovered code as a risk and provide solid
> incentives to fix it.
See question #3 in the initial email. ;)
In seriousness, test coverage is a really weak point of our process.
Even being able to identify which code is covered by tests is
something that nobody is currently working on, as far as I know.
Albert Bodenhamer
On Tue, Feb 14, 2012 at 12:01 PM, Albert BodenhamerSee question #3 in the initial email. ;)
<abod...@chromium.org> wrote:
> Perhaps a good second step to this would be to automatically generate a high
> priority bug on any code without good test coverage? Perhaps some
> consequences for people who leave untested code laying around?
>
> That way we can call out uncovered code as a risk and provide solid
> incentives to fix it.
In seriousness, test coverage is a really weak point of our process.
Even being able to identify which code is covered by tests is
something that nobody is currently working on, as far as I know.

Chris Bentzel
Randy Smith
> <abod...@chromium.org> wrote:
>> Perhaps a good second step to this would be to automatically generate a high
>> priority bug on any code without good test coverage? Perhaps some
>> consequences for people who leave untested code laying around?
>>
>> That way we can call out uncovered code as a risk and provide solid
>> incentives to fix it.
It's a bit of a thread hijack, but I'd like to +1 this. We're
spending a lot of time talking about flaky and failing tests (and for
good reasons, as Evan points out--what he's doing is just step one,
but I'm excited about it). But when we talk about feedback loops
(Developers shouldn't have flaky tests! They should be forced to fix
them!) I think we miss the point. Code shouldn't be in the tree
without good tests. Someone who checks in code with minimal testing
is in the same position as someone who checks in code with flaky tests
that provided good coverage before they were disabled. The feedback
loops we should put in place for getting people to write/fix tests
should have to do with code coverage (*), not with flaky or disabled
tests.
-- Randy
P.S. (*) I know that code coverage is an imperfect metric for quality
of testing. I just think it's better one than a lack of test flake
:-J.
>
> See question #3 in the initial email. ;)
>
> In seriousness, test coverage is a really weak point of our process.
> Even being able to identify which code is covered by tests is
> something that nobody is currently working on, as far as I know.
I've done some work to make it easier to get coverage run for a test
subset which I need to write up and put o nthe wiki.
Scott Hess
> requiring any new feature and significant behavior changing CL to have
> relevant tests. Deleting tests without removing the code that the test is
> supposed to verify is basically the same as allowing new code that is not
> tested. I don't think that the fact that the code "works" in the stable
> channel is an indicator of the usefulness of unit tests, and the number of
> bug reports is not exactly going down.
Very old flaky (and disabled) tests are like three-digit bug numbers -
the easy ones don't get to that point. When you go to look, you find
out that it's going to be a 12-week yak-shave to fix it.
In many cases, the problem may not be that the test needs to be fixed
so much as the code needs to be refactored to be more testable, or, in
many cases, more portable (there are tons of "MAYBE" cases in that
bin). I am quite sure that we have fair amount of code which only
exists because a disabled test somewhere refers to it.
-scott
Evan Martin
> Summary: This week I’m going to mass-mark every test we’ve currently
> marked as “flaky” as instead “disabled”.
> This will cause such tests to stop running on the build bots. If
> you’re currently tracking down why a test is flaky, or intend to do so
> in the future, read on for how and why.
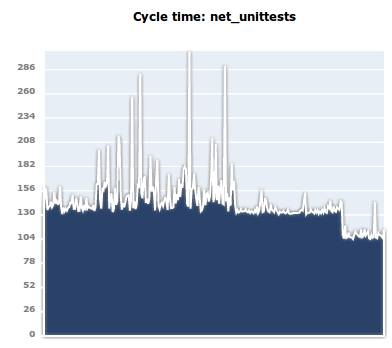
This is now more or less complete. The attached image shows the sort
of impact it had on a random bot. It appears in many cases the bot
cycle time variance has gone down a lot. (Caveat: I am not certain
this was all due to my change. The buildbot UI makes it difficult to
be certain.)
Here are some random ideas I've had for places to take this in the future:
- remove all FAILS_ tests that always time out
- eliminate the XP debug bot, instead using Release+DCHECKs
- construct a new test framework for testing browser UI that doesn't
involve rebooting Chrome for each test
- construct a new test framework for testing browser UI that builds
Chrome without webkit (less code = faster boots / faster links)
- more tooling to monitor and auto-report on problematic tests
However, I found taking even this small step incredibly frustrating
and not worth the pain, so it implementing these sorts of ideas will
unfortunately have to fall on someone else.

Ilya Sherman
On Mon, Feb 13, 2012 at 10:18 AM, Evan Martin <ev...@chromium.org> wrote:
> Summary: This week I’m going to mass-mark every test we’ve currentlyThis is now more or less complete. The attached image shows the sort
> marked as “flaky” as instead “disabled”.
> This will cause such tests to stop running on the build bots. If
> you’re currently tracking down why a test is flaky, or intend to do so
> in the future, read on for how and why.
of impact it had on a random bot. It appears in many cases the bot
cycle time variance has gone down a lot. (Caveat: I am not certain
this was all due to my change. The buildbot UI makes it difficult to
be certain.)
Here are some random ideas I've had for places to take this in the future:
- remove all FAILS_ tests that always time out
- eliminate the XP debug bot, instead using Release+DCHECKs
- construct a new test framework for testing browser UI that doesn't
involve rebooting Chrome for each test
- construct a new test framework for testing browser UI that builds
Chrome without webkit (less code = faster boots / faster links)
- more tooling to monitor and auto-report on problematic tests
However, I found taking even this small step incredibly frustrating
and not worth the pain, so it implementing these sorts of ideas will
unfortunately have to fall on someone else.
Reid Kleckner
- construct a new test framework for testing browser UI that doesn't
involve rebooting Chrome for each test
Paweł Hajdan, Jr.

{kind=link}
Vincent Scheib
Corrections welcome if I got it wrong.