Windows builds now use clang by default, reloaded
256 views
Skip to first unread message

Nico Weber
Oct 30, 2017, 2:45:12 PM10/30/17
to Chromium-dev, Hans Wennborg
Hi,
we tried to flip on clang-by-default back in m62, but had to revert that due to some debug info and minidump quality issues. We think we fixed those, and we reenabled clang-by-default-on-Windows one week ago. We're hoping to ship this in m64.
Other than s/m62/m64/, the notes from last time still apply ("most things should just work"): https://groups.google.com/a/chromium.org/forum/#!msg/chromium-dev/Y3OEIKkdlu0/TCcT1SvwAwAJ
Nico

Leonard Mosescu
Oct 30, 2017, 9:52:48 PM10/30/17
to Nico Weber, Chromium-dev, Hans Wennborg
Nice. Do we have a list of the debug info and minidump bugs that were found (and fixed)?
--
--
Chromium Developers mailing list: chromi...@chromium.org
View archives, change email options, or unsubscribe:
http://groups.google.com/a/chromium.org/group/chromium-dev
---
You received this message because you are subscribed to the Google Groups "Chromium-dev" group.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chromium-dev/CAMGbLiExAxYaE558qJqgGd_Z2HahM5wSWpiv4jGOa7boitsQSg%40mail.gmail.com.
Nico Weber
Oct 31, 2017, 1:09:51 AM10/31/17
to Leonard Mosescu, Chromium-dev, Hans Wennborg
The fixed blockers of https://bugs.chromium.org/p/chromium/issues/detail?id=636111 and https://bugs.chromium.org/p/chromium/issues/detail?id=755611 are probably the most interesting ones.
Nico Weber
Oct 31, 2017, 1:09:51 AM10/31/17
to Leonard Mosescu, Chromium-dev, Hans Wennborg
The fixed blockers of https://bugs.chromium.org/p/chromium/issues/detail?id=636111 and https://bugs.chromium.org/p/chromium/issues/detail?id=755611 are probably the most interesting ones.
On Oct 30, 2017 9:51 PM, "Leonard Mosescu" <mos...@chromium.org> wrote:

Lei Zhang
Jan 11, 2018, 3:04:16 PM1/11/18
to Hans Wennborg, Chromium-dev, Nico Weber
Are we on track to ship with Clang by default for M64?
Nico Weber
Jan 11, 2018, 4:03:16 PM1/11/18
to Lei Zhang, Hans Wennborg, Chromium-dev
So far it looks like it.

bruce...@chromium.org
Jan 11, 2018, 8:12:33 PM1/11/18
to Chromium-dev, the...@chromium.org, ha...@chromium.org
I am unaware of any blockers.
There are some outstanding issues related to clang, but none are significant - they are of the same level of importance as the outstanding bugs we would have if we reverted back to VC++.

Vadim Petrov
Jan 12, 2018, 8:45:22 AM1/12/18
to Chromium-dev, the...@chromium.org, ha...@chromium.org
Hello!
What about PGO in clang?
Do you plan to use it?
Nico Weber
Jan 12, 2018, 9:33:23 AM1/12/18
to lo...@yandex-team.ru, Chromium-dev, Lei Zhang, Hans Wennborg
We don't currently use it. We found that a regular non-pgo non-ltcg clang build is competitive with pgo ltcg msvc as long as we use order files (else startup perf is worse). See https://cs.chromium.org/chromium/src/docs/win_order_files.md?q=orderfile&sq=package:chromium&dr=C&l=3 for notes on the order files.
We'll look into LTO and PGO in the future to improve perf even more (lto bug: https://crbug.com/598772; can't find one for PGO), but it looks like it's not needed for the initial switch.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chromium-dev/8592abc9-1daf-4ea1-8307-17a7eef37ed3%40chromium.org.
Vadim Petrov
Jan 16, 2018, 8:32:40 AM1/16/18
to Chromium-dev, lo...@yandex-team.ru, the...@chromium.org, ha...@chromium.org
Thank you!
We found that in yandex browser msvc + pgo is better than clang in many ways.
Especially in memory consumption, see attach.
Especially in memory consumption, see attach.
Do you have open source PGO-profiles for chromium?
Then we can compare chromium + pgo vs chromium + clang.
Nico Weber
Jan 16, 2018, 8:41:00 AM1/16/18
to Vadim Petrov, Chromium-dev, Lei Zhang, Hans Wennborg, Sébastien Marchand
As far as I know our PGO bots were internal-only. (Seb, is that true? Or do we have public profiles somewhere?)
We didn't see any difference in memory use in our telemetry data. I'm pretty surprised you're seeing this -- since the two compilers are ABI-compatible (i.e. same struct layout etc), can you think of reasons why memory use should be different? I would expect memory use to be identical (and that's what we saw in our data). What are your population sizes? Have you tried comparing two identical PGO builds in an A/B test to make sure that those do report the same memory use in your telemetry?
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chromium-dev/3b3d1c10-1e3f-41d1-a55a-15b42d91ad17%40chromium.org.

Daniel Bratell
Jan 16, 2018, 9:32:32 AM1/16/18
to Vadim Petrov, Nico Weber, Chromium-dev, Lei Zhang, Hans Wennborg, Sébastien Marchand
I don't think we (Opera) noticed any differences in memory use. I can imagine two possible reasons though.
Maybe with PGO you get certain actions serially because each step is fast enough to end, while with slower they might end up in parallel, driving up memory usage. *If* that is the case, it might be a testing artifact, because of running things quickly.
Or maybe the binary is larger without PGO (PGO does sometimes shrink binaries in a nice way), driving up RAM needed to execute code. That is a one time cost though, so what looks like a large percentage in an empty browser, will be a small percentage once you have a few hundred tabs (I can't be the only one!).
/Daniel
To unsubscribe from this group and stop receiving emails from it, send an email to chromium-dev...@chromium.org.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chromium-dev/CAMGbLiHvtgdBJ3FNCV%3DS4gyn22uUrMySXTtTA7KxumV2WhuUpA%40mail.gmail.com.
--
/* Opera Software, Linköping, Sweden: CET (UTC+1) */
Nico Weber
Jan 16, 2018, 9:39:42 AM1/16/18
to Daniel Bratell, Vadim Petrov, Chromium-dev, Lei Zhang, Hans Wennborg, Sébastien Marchand
On Tue, Jan 16, 2018 at 9:30 AM, Daniel Bratell <bra...@opera.com> wrote:
I don't think we (Opera) noticed any differences in memory use.
That sounds comforting :-) Just to confirm, did you do PGO builds with MSVC?
To unsubscribe from this group and stop receiving emails from it, send an email to chromium-dev+unsubscribe@chromium.org.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chromium-dev/CAMGbLiHvtgdBJ3FNCV%3DS4gyn22uUrMySXTtTA7KxumV2WhuUpA%40mail.gmail.com.
Vadim Petrov
Jan 16, 2018, 9:48:09 AM1/16/18
to Chromium-dev, lo...@yandex-team.ru, tha...@chromium.org, the...@chromium.org, ha...@chromium.org, sebma...@chromium.org
Thanks to all.
I think we need to investigate it more in yandex.browser.
Daniel Bratell
Jan 16, 2018, 11:24:36 AM1/16/18
to Nico Weber, Vadim Petrov, Chromium-dev, Lei Zhang, Hans Wennborg, Sébastien Marchand
Yes, Opera on Windows has been built with VS+PGO since late 2016, up to and including the release last week. The next major release (Chromium 64 based) will be built either with VS+PGO or with Clang depending on the outcome of performance testing. I'm guessing clang if order files work well.
/Daniel
To unsubscribe from this group and stop receiving emails from it, send an email to chromium-dev...@chromium.org.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chromium-dev/CAMGbLiHvtgdBJ3FNCV%3DS4gyn22uUrMySXTtTA7KxumV2WhuUpA%40mail.gmail.com.
--/* Opera Software, Linköping, Sweden: CET (UTC+1) */

Andrey Malets
Jan 17, 2018, 8:40:16 AM1/17/18
to Chromium-dev, lo...@yandex-team.ru, the...@chromium.org, ha...@chromium.org, sebma...@chromium.org
On Tuesday, January 16, 2018 at 6:41:00 PM UTC+5, Nico Weber wrote:
> As far as I know our PGO bots were internal-only. (Seb, is that true? Or do we have public profiles somewhere?)
> We didn't see any difference in memory use in our telemetry data. I'm pretty surprised you're seeing this -- since the two compilers are ABI-compatible (i.e. same struct layout etc), can you think of reasons why memory use should be different? I would expect memory use to be identical (and that's what we saw in our data). What are your population sizes? Have you tried comparing two identical PGO builds in an A/B test to make sure that those do report the same memory use in your telemetry?
> As far as I know our PGO bots were internal-only. (Seb, is that true? Or do we have public profiles somewhere?)
> We didn't see any difference in memory use in our telemetry data. I'm pretty surprised you're seeing this -- since the two compilers are ABI-compatible (i.e. same struct layout etc), can you think of reasons why memory use should be different? I would expect memory use to be identical (and that's what we saw in our data). What are your population sizes? Have you tried comparing two identical PGO builds in an A/B test to make sure that those do report the same memory use in your telemetry?
Well, ABI compatibility does not mean at all that compilers generate the same code :) So at least code size and layout differences may influence memory consumption and, of course, various timings. I see differences of 7-9% just in binary sizes (our version of chrome.dll is 41M in msvs build versus 47M in clang, chrome_child.dll is 55M vs 64M in clang), the only difference in the builds is a change of condition in BUILDCONFIG.gn to enable/disable clang compiler (1).
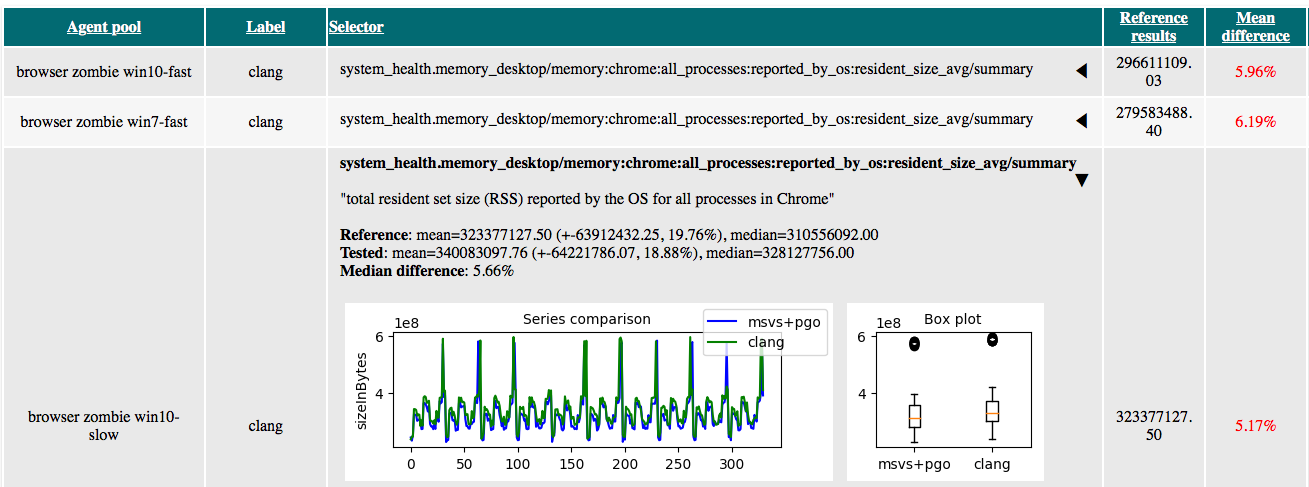
The picture Vadim posted was from a comparison that was done using 10 different machines of the same software and hardware configuration, each one reporting 33 samples of summary data in case of system_health.memory_desktop test. The picture you see includes all of the data combined into one graph, total of 330 samples for each configuration.
(1) https://chromium.googlesource.com/chromium/src.git/+/master/build/config/BUILDCONFIG.gn#141
The picture Vadim posted was from a comparison that was done using 10 different machines of the same software and hardware configuration, each one reporting 33 samples of summary data in case of system_health.memory_desktop test. The picture you see includes all of the data combined into one graph, total of 330 samples for each configuration.
My confidence in this comparison is very high because of
a) the final p-value obtained from statistical tests on this data: we use Mann-Whitney U-test to compare individual sample pairs generated on one machine (we never compare results obtained from different machines directly), and then combine p-values with Stouffer's Z-score method. p-value for the data shown in this picture is less than 5e-5, unfortunately, I made a screenshot which does not include this value in the rightmost column :) Furthermore, we drop results which yield different comparison decisions on different machines (imagine 5% decrease in median on two of ten machines and 7% increase on all the other, all this data would have been filtered as inappropriate)
a) the great stability of system_health.memory_desktop results across different machines (from the same pool and from different pools) and stories;
c) results on individual stories, all of them show quite the same difference in memory consumption
d) results from other perftests checking memory consumption (for example, we still use page_cycler which used to measure memory in Chrome couple of years ago before system_health entered the game), the differences in those perftests metrics tend to be quite the same
Talking about A/B testing and false positives: yes, we did a lot of work trying to lower false positive rate, and I triggered such a comparison using two identical MSVS PGO builds we used earlier to confirm this: the results showed 3 random metrics with p-values sitting around confidence level of 0.05 with absolutely noisy graphs (nothing even closer to what we see in msvs-clang comparison), rendering them as clear false positives.
(1) https://chromium.googlesource.com/chromium/src.git/+/master/build/config/BUILDCONFIG.gn#141
Nico Weber
Jan 17, 2018, 8:45:24 AM1/17/18
to andrey...@gmail.com, Chromium-dev, Vadim Petrov, Lei Zhang, Hans Wennborg, Sébastien Marchand
On Wed, Jan 17, 2018 at 8:40 AM, Andrey Malets <andrey...@gmail.com> wrote:
On Tuesday, January 16, 2018 at 6:41:00 PM UTC+5, Nico Weber wrote:
> As far as I know our PGO bots were internal-only. (Seb, is that true? Or do we have public profiles somewhere?)
> We didn't see any difference in memory use in our telemetry data. I'm pretty surprised you're seeing this -- since the two compilers are ABI-compatible (i.e. same struct layout etc), can you think of reasons why memory use should be different? I would expect memory use to be identical (and that's what we saw in our data). What are your population sizes? Have you tried comparing two identical PGO builds in an A/B test to make sure that those do report the same memory use in your telemetry?
Well, ABI compatibility does not mean at all that compilers generate the same code :) So at least code size and layout differences may influence memory consumption and, of course, various timings. I see differences of 7-9% just in binary sizes (our version of chrome.dll is 41M in msvs build versus 47M in clang, chrome_child.dll is 55M vs 64M in clang), the only difference in the builds is a change of condition in BUILDCONFIG.gn to enable/disable clang compiler (1).
Oh sure, many metrics move. Our speed metrics moved around a bit and size is definitely different (for us, 32-bit binaries got larger while 64-bit binaries got smaller; crbug.com/457078 has many details on size investigations and improvements). But memory use?
The picture Vadim posted was from a comparison that was done using 10 different machines of the same software and hardware configuration, each one reporting 33 samples of summary data in case of system_health.memory_desktop test. The picture you see includes all of the data combined into one graph, total of 330 samples for each configuration.My confidence in this comparison is very high because ofa) the final p-value obtained from statistical tests on this data: we use Mann-Whitney U-test to compare individual sample pairs generated on one machine (we never compare results obtained from different machines directly), and then combine p-values with Stouffer's Z-score method. p-value for the data shown in this picture is less than 5e-5, unfortunately, I made a screenshot which does not include this value in the rightmost column :) Furthermore, we drop results which yield different comparison decisions on different machines (imagine 5% decrease in median on two of ten machines and 7% increase on all the other, all this data would have been filtered as inappropriate)a) the great stability of system_health.memory_desktop results across different machines (from the same pool and from different pools) and stories;c) results on individual stories, all of them show quite the same difference in memory consumptiond) results from other perftests checking memory consumption (for example, we still use page_cycler which used to measure memory in Chrome couple of years ago before system_health entered the game), the differences in those perftests metrics tend to be quite the sameTalking about A/B testing and false positives: yes, we did a lot of work trying to lower false positive rate, and I triggered such a comparison using two identical MSVS PGO builds we used earlier to confirm this: the results showed 3 random metrics with p-values sitting around confidence level of 0.05 with absolutely noisy graphs (nothing even closer to what we see in msvs-clang comparison), rendering them as clear false positives.
(1) https://chromium.googlesource.com/chromium/src.git/+/master/build/config/BUILDCONFIG.gn#141
--
--
Chromium Developers mailing list: chromi...@chromium.org
View archives, change email options, or unsubscribe:
http://groups.google.com/a/chromium.org/group/chromium-dev
---
You received this message because you are subscribed to the Google Groups "Chromium-dev" group.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chromium-dev/46dec7d7-fb33-4ebb-aee5-ad13eefbfc1f%40chromium.org.

{kind=link}
Sébastien Marchand
Jan 17, 2018, 11:25:25 AM1/17/18
to Nico Weber, andrey...@gmail.com, Chromium-dev, Vadim Petrov, Lei Zhang, Hans Wennborg
We do have some Chromium PGO profiles archived via CIPD but it's not trivial to retrieve them, here's how to do it:
- In a Chromium repo, fetch the branch that contains the 'git notes' with the hashes of the profile databases (e.g. "git fetch -f https://chromium.googlesource.com/chromium/src.git refs/notes/pgo/profile_database/windows-386:refs/notes/pgo/profile_database/windows-386" to get the x86 profile databases hashes, s/386/amd64/ for the x64 ones).
- Now if you do a "git log --notes=refs/notes/pgo/profile_database/windows-386" you'll see that some notes appears for some commits, e.g. for [8bdfe6b1a372ee0238ff31e7b2b8cc667e55d69a] you can see "Notes (pgo/profile_database/windows-386): c47e3533806cb3712b295f19dfabb7504e79126c"
- This gives you the CIPD hash of the profile database generated for this particular version of the codebase, to fetch it just go to a temp directory and do a 'cipd init' followed by 'cipd install chromium/pgo/profiles/profile_database/windows-386 c47e3533806cb3712b295f19dfabb7504e79126c'.
The goal with this was to generate the PGO database on some continuous builders and to have a (relatively) easy way to retrieve the most recent profile database for any Chrome commit. Currently the instrumentation, profiling and the optimization step all happen on the same bot, this'd have allowed us to easily split this (with one bot generating the databases and one consuming them).
This work kinda stopped after we managed to archive the databases (with CIPD and 'git notes'), we never really used this data (in fact we don't even support the /USEPROFILE linker flag yet in Chrome, but this should be pretty easy to add this).
The databases are generated by our 2 continuous PGO builders (see the "archive profile database.*" step in the logs):
- https://ci.chromium.org/buildbot/chromium.fyi/Chromium%20Win%20PGO%20Builder/
- https://ci.chromium.org/buildbot/chromium.fyi/Chromium%20Win%20x64%20PGO%20Builder/
And the code that do this is here: https://cs.chromium.org/chromium/build/scripts/slave/recipe_modules/pgo/api.py?l=135&rcl=38d03bc58620804a21899ea93e1f5f47b63df96c
--
Reply all
Reply to author
Forward
0 new messages