Query all global data efficiently with the new experimental table
74 views
Skip to first unread message

Rick Viscomi
Mar 10, 2020, 6:31:21 PM3/10/20
to chrome-ux-report
Hey everyone,
SELECT
SUM(lcp.density) AS fast_lcp
FROM
`chrome-ux-report.experimental.global`,
UNNEST(largest_contentful_paint.histogram.bin) AS lcp
WHERE
yyyymm = 202002 AND
origin = 'https://example.com' AND
form_factor.name = 'phone' AND
effective_connection_type.name = '4G' AND
lcp.start < 2500
Please give the experimental data a try and let me know what you think. If it proves useful it may become the default way to extract CrUX data on BigQuery.
I've been working on a more efficient way to query CrUX data. Every release in the `all` dataset has been collated into a single table named chrome-ux-report.experimental.global. Each release has its own "partition" with "clustering", which are BigQuery terms for more efficiently storing the data to reduce query costs.
For example, this query computes the % of fast LCP experiences for a given origin:
SELECT
SUM(lcp.density) AS fast_lcp
FROM
`chrome-ux-report.all.202002`,
UNNEST(largest_contentful_paint.histogram.bin) AS lcp
WHERE
origin = 'https://example.com' AND
form_factor.name = 'phone' AND
effective_connection_type.name = '4G' AND
lcp.start < 2500
SUM(lcp.density) AS fast_lcp
FROM
`chrome-ux-report.all.202002`,
UNNEST(largest_contentful_paint.histogram.bin) AS lcp
WHERE
origin = 'https://example.com' AND
form_factor.name = 'phone' AND
effective_connection_type.name = '4G' AND
lcp.start < 2500
Query complete (0.8 sec elapsed, 97.8 GB processed)
Now compare that with a query over the experimental dataset:
SUM(lcp.density) AS fast_lcp
FROM
`chrome-ux-report.experimental.global`,
UNNEST(largest_contentful_paint.histogram.bin) AS lcp
WHERE
yyyymm = 202002 AND
origin = 'https://example.com' AND
form_factor.name = 'phone' AND
effective_connection_type.name = '4G' AND
lcp.start < 2500
Query complete (1.5 sec elapsed, 39.4 MB processed)
It's a bit slower but processes 0.04% as much data, which is crucial for BigQuery users on the free tier.
Note that the second query has a WHERE clause of `yyyymm = 202002`. All queries over the experimental.global table require a condition like this to prevent accidentally incurring the full cost of the dataset. If you forget to include it, you'll get an error like this:
Cannot query over table 'chrome-ux-report.experimental.global' without a filter over column(s) 'yyyymm' that can be used for partition elimination
If you want to intentionally query all data, you can silence the error by adding ` WHERE yyyymm > 0`, which includes all monthly releases. For example:
SELECT
yyyymm,
SUM(fid.density) AS fast_fid
FROM
`chrome-ux-report.experimental.global`,
UNNEST(first_input.delay.histogram.bin) AS fid
WHERE
yyyymm > 0 AND
origin = 'https://example.com' AND
form_factor.name = 'phone' AND
effective_connection_type.name = '4G' AND
fid.start < 100
GROUP BY
yyyymm
ORDER BY
yyyymm
yyyymm,
SUM(fid.density) AS fast_fid
FROM
`chrome-ux-report.experimental.global`,
UNNEST(first_input.delay.histogram.bin) AS fid
WHERE
yyyymm > 0 AND
origin = 'https://example.com' AND
form_factor.name = 'phone' AND
effective_connection_type.name = '4G' AND
fid.start < 100
GROUP BY
yyyymm
ORDER BY
yyyymm
Query complete (6.5 sec elapsed, 321.5 MB processed)
This query calculates the % of fast FID experiences for a given origin over time. This kind of query was difficult if not impossible using the existing `chrome-ux-report.all` dataset because the FID metric has been graduated out of the experimental dataset, causing naming inconsistencies across releases. Using the partitioned dataset and its consistent metric naming schema, it can find an answer using less than a third of a gigabyte of data.
Known limitations:
- Not available for country datasets yet, but you can imagine similarly having a single `chrome-ux-report.experimental.country` table with a `country` field including all country data.
- Metrics that used to be in the `experimental` namespace are now collated under their latest name. For example `experimental.first_input_delay` can now be found under `first_input.delay`. This naming scheme may obscure when data was considered experimental and liable to change.
Rick

Manuel
Mar 11, 2020, 3:18:11 AM3/11/20
to chrome-ux-report
Hi Rick,
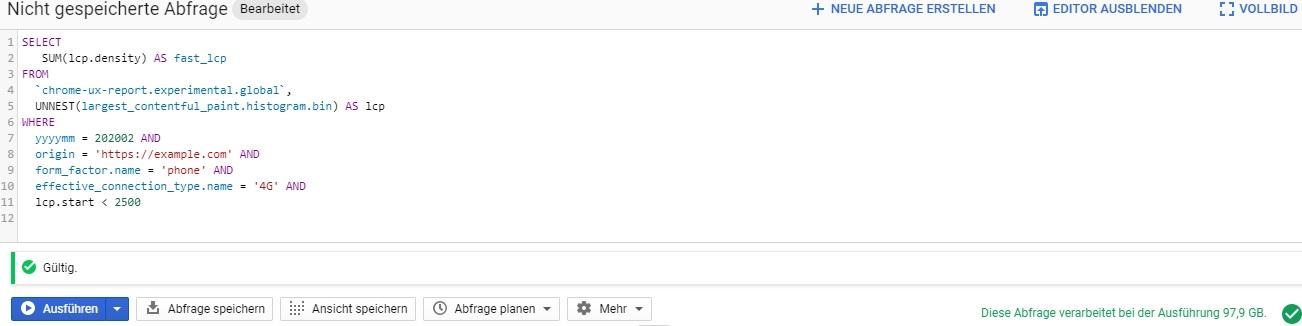
thanks a lot for this approach i think wait a little longer, but process less Data is the right approach.
However if i try your Query it says it sill still process ~98 GB of Data. Any Idea why?
Rick Viscomi
Mar 11, 2020, 2:50:17 PM3/11/20
to Manuel, chrome-ux-report
Hi Manual, thanks for the question. It gets at the differences between partitions and clusters in BigQuery.
Because the query restricts yyyymm to only 202002, BigQuery knows it can ignore all other monthly partitions. The 202002 partition is ~98 GB, which is the same size as the standalone all.202002 table.
The experimental table also clusters by origin. Clusters of origins are stored in different logical locations so that once example.com is found, the query can stop early. The BigQuery validator doesn't know how many clusters it will need to search before finding example.com, so it estimates 98 GB as an upper limit. When the query executes, it will usually incur much smaller costs if the correct cluster is found early. The exact cost of the query will vary depending on the origin(s) in the query.
So what you're seeing is just an estimated upper limit and the actual amount of billable bytes will almost certainly be orders of magnitude cheaper when querying a single origin. Querying multiple origins may span multiple clusters, increasing the cost, but still cheaper than necessarily querying the entire monthly release without clusters. Do give it a try!
--
You received this message because you are subscribed to the Google Groups "chrome-ux-report" group.
To unsubscribe from this group and stop receiving emails from it, send an email to chrome-ux-repo...@chromium.org.
To view this discussion on the web visit https://groups.google.com/a/chromium.org/d/msgid/chrome-ux-report/bfddc3d4-a758-4c42-91b7-95927dbb8b29%40chromium.org.
Reply all
Reply to author
Forward
0 new messages