Suggestion: make a faster more compatible SPI class with a faster Transfer function.

Kurt Eckhardt
Sorry, I know this is probably not the first time this has come up on this email list. Also sorry if I am at times a little too long winded.
Background:
But over the last few years I have been playing around with several different boards and have experimented with several SPI devices, lately mostly with Teensy boards.
Currently I have a new version of the SPI library for the Teensy boards, which hopefully over time I will be able to integrate into the main version.
All SPI objects have common class (or base class):
One of my primary reasons for this new version, is to make all of the SPI objects to of the class SPIObject, instead of the current version where each of the SPI objects have their own class. This change will make the objects more compatible with some of the other implementations, such as the Arduino SAM and SAMD implementations. With this I am hoping over time we can update many of the different libraries that use SPI to allow us to select which SPI buss to use.
Currently if someone has a Teensy 3.6 and wishes to use SPI2 for some device. The typical way to handle this is to edit the library and do a global search and replace for “ SPI.” To “ .SPI2.”… Which is not optimal especially if in other cases you still wish to use that device on SPI.
I believe I have this all working in my version.
Transfer functions:
But the other main thing that I believe SPI needs is some faster standardized way to do transfers of data. Today the only standardized API to transfer data is:
X = SPI.transfer(y)
And this API complete completely handicaps the SPI buss on the majority of boards as you can not make use of any hardware features such as FIFO queues or at a minimum double buffering and as such, there are gaps of time between each byte output, which significantly reduces the throughput.
Currently several libraries also support:
X = SPI.transfer16(y)
Which helps a little in some cases
Currently in the Arduino and Teensy libraries, there is also a multibyte version :
SPI.transfer(buf, cnt)
This API can improve the performance, as different implementations can make use of specific features of the processor. For example on the Teensy 3.x processors, we can make use of the FIFO queue, we can choose to pack the outputs into 16 bit value and we can tell SPI hints like more data is coming so don’t add delays. Or on the Teensy LC, we can make use of the double buffering to speed things up.
Unfortunately many of the implementations (Teensy was this way until latest release). This is implemented simply as:
void SPIClass::transfer(void *buf, size_t count)
{
uint8_t *buffer = reinterpret_cast<uint8_t *>(buf);
for (size_t i=0; i<count; i++) {
*buffer = transfer(*buffer);
buffer++;
}
}
Which gains you nothing performance wise. And in many cases can make the program slower.
For example the Sparkfun_TeensyView display (SSD1306), you use a memory buffer (512 bytes), you do your graphics into and when you are ready to update the display, you call the display function, which outputs a 4 byte header (DC Asserted), followed by the first 128 bytes of the buffer (DC not asserted) and repeat 4 times to output the display… So calling the SPI.transfer(&screenbuffer[0], 128), will overwrite your screen buffer. So to use this API, you typically need to first copy the region of the screen buffer into a temporary buffer and then call this api. On fast machines with lots of memory this may not be too bad, but on slower machines with limited memory, this can be a problem.
So what do many developers do? If you are using a Teensy 3.x, you may choose to write code that is very specific to the Teensy. For example you may make use of the FIFO queues and understand that you can encode additional information such as which chip select pins to assert, or you might make use of DMA, which again is very processor specific. But this has several downfalls, including it will only work with those processors and it is not easy for novice users to understand.
Suggestion:
Make a standard API or a set of APIs that allows you to do multibyte transfers which do not overwrite the main buffer passed in. Also we should have the option to do write only and/or read only operations.
Note: several of the different platforms already have added functions to do help with this
Examples:
Intel Edison/Galileo have added the API
void transferBuffer(const uint8_t *, uint8_t *, uint32_t);
Where I believe you have the option to pass in NULL for the first parameter (will send all zeros), or NULL for 2nd parameter and no read data will be returned.
ESP32: has a couple of different methods.
void transferBytes(uint8_t * data, uint8_t * out, uint32_t size);
void transferBits(uint32_t data, uint32_t * out, uint8_t bits);
I believe there are some others as well. And some of them also have wrapper functions like read and write And I believe in some case you may be able to set what character to send in a read operation…
What I have tried so far is, like the Edison version, except the method name is still just transfer. I also added a define to the library, such that a program could check to see if a library supports it and use it else do something different.
That is I have:
#define SPI_HAS_TRANSFER_BUF 1
void transfer(const void * buf, void * retbuf, uint32_t count);
I then implemented versions of it for Teensy 3.x, Teensy LC, Arduino AVR, plus I experimented with a version for Arduino SAMD (Sparkfun version).
My current stuff for Teensy (and the avr part of it) is up in my fork/branch of SPI on github:
https://github.com/KurtE/SPI/tree/SPI-Multi-one-class
I then setup a test app, bases off of the Teensyview Screen update code, I mentioned above. I have four versions of this function.
One that does it the uses transfer(x), another that uses transfer(buf, cnt), another that use my updated code transfer(buf, NULL, cnt) and a fourth that is specific to Teensy 3.x which uses the fifo queue and I used a baseline for what is at least possible.
I ran most of these tests with default board parameters.
Times are in us
One byte Transfer(buf, cnt) Transfer(buf, NULL, cnt), PUSHR/POPR
Teensy 3.2: 677 562 554 539
Teensy LC 1205 942 844
Arduino UNO 1404 1052 888
Sparkfun SAMD 1169 1331 612-800+?
I am not an expert on Atmel SAMD code but the docs, I believe implied that you could try to keep the output going by checking the DRE bit and when set you could output the next data. It appears like it can mostly work, but at times I was getting hang, so put a quick and dirty countdown counter to bail out. So that is why there is differences in speed in this case. Not sure of best fix. Probably best left to someone who uses these processors more than I do.
void SERCOM::transferDataSPI(const uint8_t *buf, uint8_t *rxbuf, uint32_t count)
{
if ( count == 0 )
return;
const uint8_t *p = buf;
uint8_t *pret = rxbuf;
uint8_t in;
// Probably don't need here .
sercom->SPI.DATA.bit.DATA = p ? *p++ : 0; // Writing data into Data register
while (--count > 0) {
while( sercom->SPI.INTFLAG.bit.DRE == 0 )
{
// Waiting for TX Buffer empty
}
sercom->SPI.DATA.bit.DATA = p ? *p++ : 0; // Writing data into Data register
while( sercom->SPI.INTFLAG.bit.RXC == 0 )
{
// Waiting Complete Reception
}
in = sercom->SPI.DATA.bit.DATA;
if (pret)*pret++ = in;
}
uint16_t timeout_countdown = 0x1ff; // should not be needed.
while( (sercom->SPI.INTFLAG.bit.RXC == 0 ) && timeout_countdown--)
{
// Waiting Complete Reception
}
in = sercom->SPI.DATA.bit.DATA;
if (pret)*pret++ = in;
}
Main question:
Are there others who are interested in adding a new method or methods to the SPI interface and if so suggestions on which one(s)?
Thanks
Kurt

Mikael Patel
https://github.com/mikaelpatel/Cosa/blob/master/cores/cosa/Cosa/SPI.hh
https://github.com/mikaelpatel/Cosa/blob/master/cores/cosa/Cosa/SPI.cpp
https://github.com/mikaelpatel/Cosa/blob/master/libraries/SD/SD.cpp#L183
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.

Sanyaade Adekoya

Paul Stoffregen
The different names and parameters they've chosen show the fragmentation of the Arduino community that's occurring. My hope is Arduino can standardize the API, and at least publish a non-optimized implementation quickly. No matter what's written on this mail list, even if the words come directly from Massimo & Cristian, the API needs to be published in SPI.h for the AVR platform to "stick". Code can be optimized later, but APIs need to be decided up front.
If Arduino doesn't decide, or decides but doesn't update SPI.h, then I need to choose what I'll do on Teensy. ChipKit and the various STM32 platforms will have choices to make. Personally, I like your proposal much more than I like the different names ESP and Intel chose, but if I go with one of those, at least Teensy would be API compatible with one other platform.
Of course my hope is Arduino will decisively define & publish this API in their SPI.h and we can all work towards API compatibility for everyone in the Arduino community. As you know, I've been putting this off for Teensy for a while, in hopes Arduino will define the API.
I also agree, definitive guidance on multiple SPI & Wire instances is greatly needed. In the interest of keeping this reply shorter, I'd prefer to chime in later on that matter.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.

Thomas Roell
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.

Paul Carpenter
First of all for both I suggest staying away from ANY definition of a bus as they can mean many different things in many different applications. It is possible to do SS decodes in many ways even external decode giving many ways of referring to slave devices.
In I2C it can get even more complicated with actual I2C slave devices that are bus switches switching in or out different segments to a master or multi-master common bus. Similarly people do weird things on their SPI side.
What you need is three classes of objects
Controller and its methods of transfer, config
Slave Devices and their configuration methods or getters/setters or public variables.
(SPI controller as slave could have the same object)
Callback functions uusally for slave device, if necessary called after 'n' command
bytes received to determine what to do.
Whenever you are dealing with a slave device certain things are FIXED
- Which SPI controller
- Which SS to send (any other port pins for external decode not responsible here)
- What clock speed (yes you may want to change speed for different devices)
- What bit size (yes you may want to size for different devices)
- What bit order
- What byte order for multi-byte devices
- Type of Read transfer overlapped or not
- Do you ignore n bits or bytes when reading
- Where to read data from
- Where to write data to
- Bits/Bytes to send
- Bits/Bytes to read
Personally get away from multiple parameter passing move to defining the slave device object and pass that by reference. If necessary these can then be queued giving smaller queue size.
Passing the class and knowing what the last transfer type was or even if SAME object can mean bypassing setting up for transaction and many other calls to
change between devices. This can also reduce programme complexity for beginners with more than one external slave device.
Then there are three modes of transfer single or multi-byte at slave DEVICE, as several devices have one or more bytes to be sent then to them, then read one byte.
- Simple Write
- Simple Read (data is still efectively clocked out usually as fixed '0' or '1')
- Complex Write then Read (like I2C with restart)
Then there is bit/byte delay when doing a complex Write then Read (EEPROM, multi-channel ADC, MEMs and similar devices) you have to send one or more bytes to command WHAT to read in the SAME transfer. In some cases I see that nothing is valid until all bits have been written in other cases I have seen the data is valid n bits later, on some ADCs the data is valid immediately from last conversion.
Examples
4 bits delayed on read old BurrBrown (now TI) ADC ADC082S021
Invalid data during write (EEPROM like Ramtron FM25040A
or ST Microelectroonics LPS331AP)
Personally EACH slave device should have the ABILITY to have its own buffers, then you can use the same buffers for all slave devices when space limited or not time constrained. Then you can have a 256 byte buffer for EEPROM, display or similar device. The ability to have separate buffers means for display devices the handling of multiple buffers (one to send one to change) can be handled by the application. Also on large or often sampled data sets the buffers can be handled
while different buffers are used for another SPI transaction.
Please do NOT get constrained with this must ONLY work on UNO, if necessary define a new version for Mega and anything else bigger than UNO. I even work on other 6/8 pin micros for simple functions with more memory than an UNO.
Kurt Eckhardt
Thanks Paul(s),
I can understand the desire to completely rework the SPI interface, into a complete new interface, which could be a good thing. Yes – there are times when you need to set the bit size and the user has to do something processor specific. You can already set different speeds, bit order and mode using the transaction support.
And I agree that it would be great if we had more control over reads and writes, …
However what I am hoping to be able to do, is not such a set of radical changes, but simply slightly extend the current the current library, as to help users and library developers to be able to get higher throughput over the SPI buss in a compatible way.
My main goal is to hopefully come up with simple update to the library which allows for their code use the SPI, in a way to increase throughput, in a way that can be done without having to resort to directly mucking with the hardware…. As I mentioned in the first message, many of the current platforms have already defined methods to do this. What I am suggesting is to define a standard one. Yes there already is the transfer(buf, cnt), which can get most of the performance I mention, but in many cases you do not want the buffer you pass in to be overwritten, so often have to copy to temporary buffer than call this version of transfer, which in many cases is a waste of CPU and memory.
Since my first posting on this, I have tried making versions of the code for a few more platforms to try out. Some cases I updated my test case to run. Examples:
I tried running my code (with mods) on ESP-WROOM-32 board. Using single byte transfers took 677us which was pretty good, using their transfer buffer 555
I tried on Arduino DUE: Single byte transfers 1334us with transfer buffer 792 or with current with memcpy (800)
Again the best I have seen with test is with Teensy 3.2, one byte 677, transfer buffer 554, custom code using hardware pushr/popr/ : 539
I might get slightly better results with T3.6, but again we are mostly hampered by SPI utilization not CPU speed.
Along the same line, wondering if some of the additions that were added to Arduino DUE make sense to adopt? In particular all of their Transfer functions map to new ones with two more parameters, that is:
SPI.transfer(data) maps to SPI.transfer(BOARD_SPI_DEFAULT_SS, data, SPI_LAST)
So my assumption this allows you to specify which pin to use for CS and either pass Continue or last, which I assume will select that pin (assuming appropriate SPI CS pin) as part of the hardware instruction. Which could be a good thing, but as each of these calls, is a start the transfer and wait for the result, again not sure how much performance it would add? Again if this could be subtly enhanced for example on Teensy to be a CS Mask (up to 5 pins can be chosen to be controlled).
That is in my test case which logically does:
SPI.transfer(CS+DC, channel 0 header, NULL, count, CONTINUE)
SPI.transfer(CS, Channel 0 data, NULL, count, CONTINUE)
…
SPI.transfer(CS+DC, channel 3 header, NULL, count, CONTINUE)
SPI.transfer(CS, Channel 3 data, NULL, count, LAST)
Would I gain anything performance wise if each one has to complete, including not returning any data (in this case). If each of these calls wait until they complete before returning, probably very little performance gained, versus us doing the CS and DC support our self. However if we can special case support to say IF we are not interested in the results (NULL), and doing CONTINUE, then don’t necessarily wait until complete. Depending on your hardware, example Teensy, you will have to wait until the last WORD of your output is queued, before returning. I would probably also assume that the LAST flag that you would wait until it completes.
With the above special conditions, my guess is we could get pretty close to the performance of hardware specific output code, but the question is do we want the added complexity here?
Again thanks for the feedback.
Paul Carpenter
other things most of those figures mean little to me. I do assume you are
setting same SPI speed on all platforms.
Yes you can change things continuously making all sorts of calls with
multiple parameters, with all its overheads, but I thought you wanted
to improve performance (speed, time used to create and then perform a
transaction).
If SPI transfer time is holding things up it is the blocking nature
again.
Kurt Eckhardt
Yes I am outputting at the same speed and the like. What I am trying to do is to more fully utilize the SPI bandwidth. For example a few years ago was working with Edison. Again I don't remember the exact numbers, but for example they said could go up to maybe 8mbs, but with the overhead of each call, especially go through using spidev at best you could maybe get 2mbs...
Now more specific. As right now I have Teensy LC hooked up. If I did the code I mentioned, if you look at the output using a Logic analyzer or Scope you will see something like:
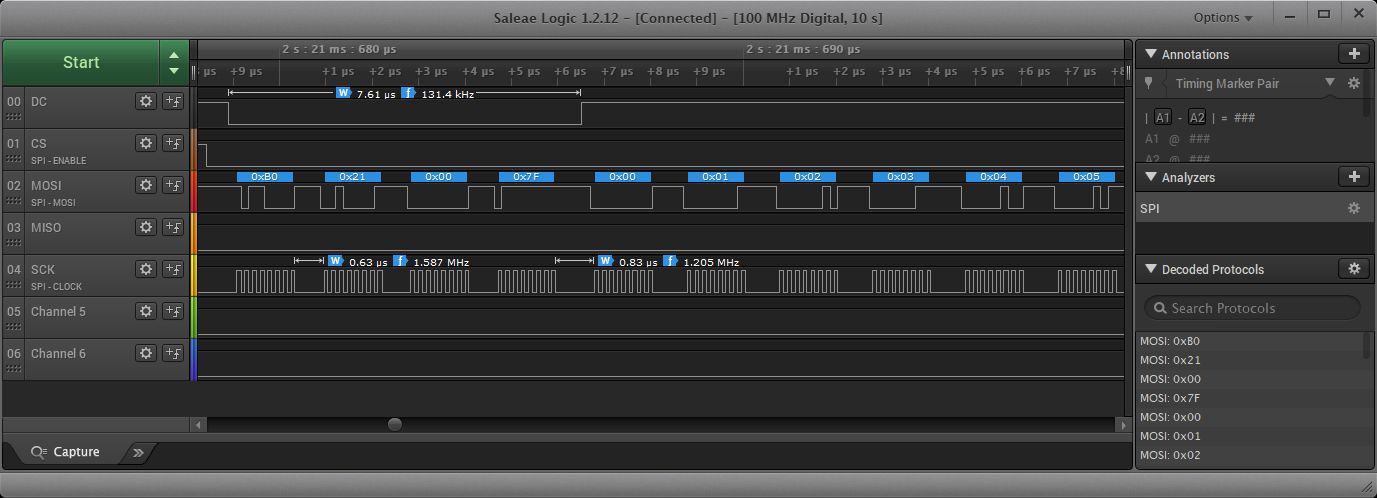
Here is outputting one byte at a time, and you see a delay between bytes of about .63us. Here the gap between changing the DC pin is about .83us.. So these times the SPI buss is not transferring anything.
With my current transfer Buffer code on the LC the output looks more like:
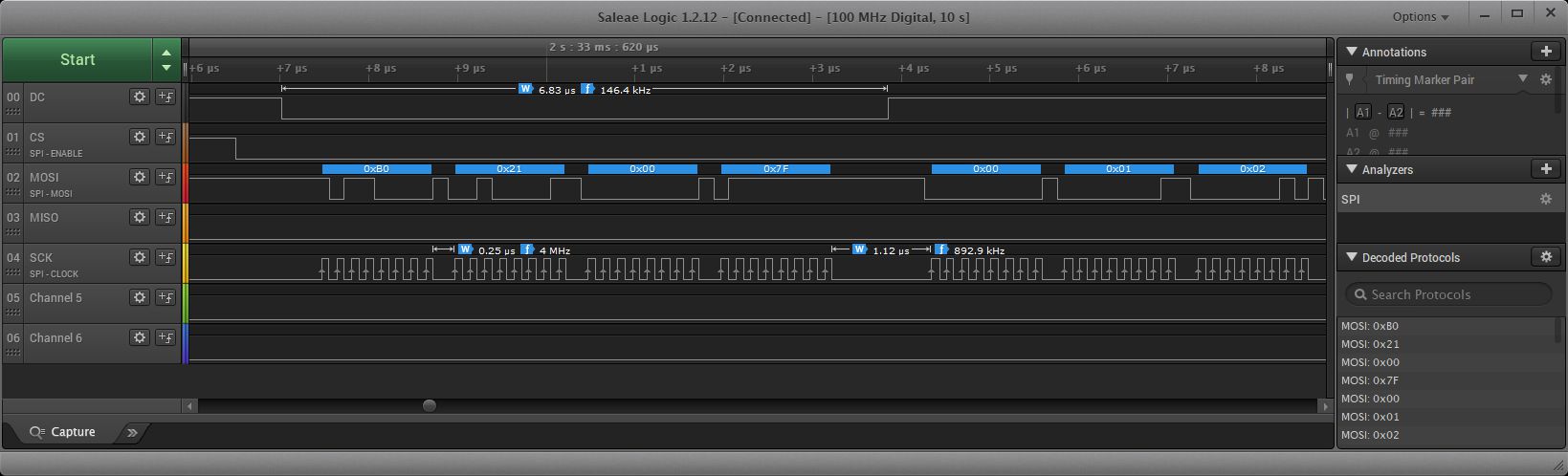
In this cas you see the main gap of about .25us which is getting better. For some reason in this test the gap between changing DC line increased, probably a bug in my code. Also currently using digitalWrite, where I normally would be using toggle of a bit to update.
Now if you look at the T3.6 using the hardware registers you see data more like:
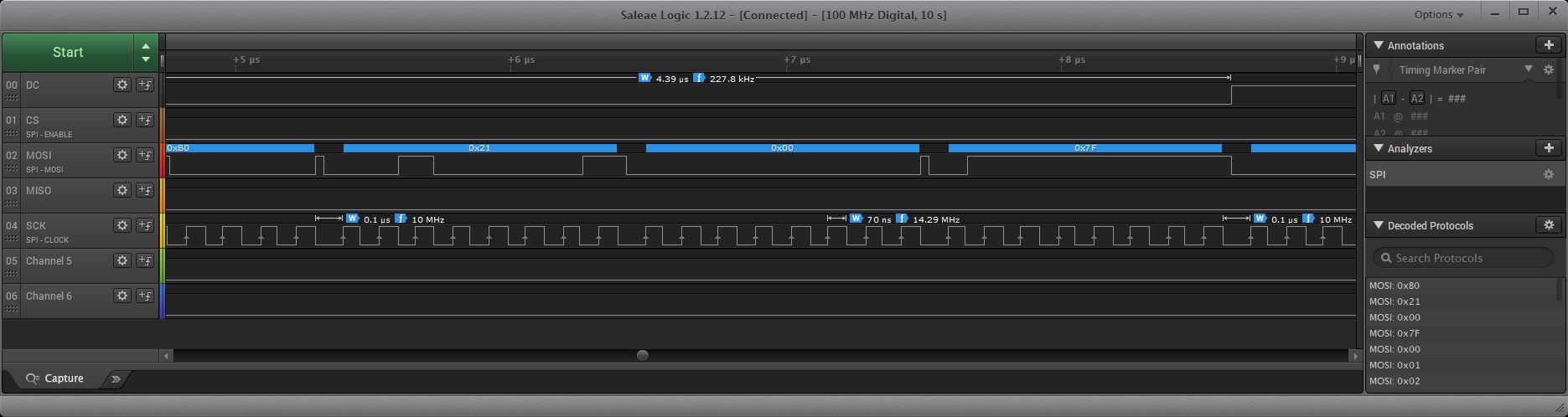
In here you see almost no gaps. The normal pulse is about 70ns but the pause is about .1us between bytes, this also includes the gap between changing of DC as this was encoded into the information pushed onto the queue with the T3.x system.
Again this less to do with the actual buss speed you ask for and more to do with how much time is lost between each byte/word transferred.
Hope that makes more sense. And sorry for the larger posting with pictures.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
Paul Carpenter
overhead gap between each byte. The type of reduction you are looking
for CANNOT be done by tweaking block mode software alone, or repeated
software calls, especially when you get up to the SPI speeds I am used
to of 10 to 20MHz, without gaps. You must use the HARDWARE functions
available to assist it.
Right this is NOT API level issue, this is board specific implementation of
an API whether byte, word, or block transfer. How it is implemented to talk
to registers will ALWAYS be board specific.
Cursory glance at processors for
Teensy LC
Due R3
BOTH have FIFO's for SPI (not on all channels), so should be used over
software calls.
BOTH have DMA capability for SPI RX and TX separately on EACH controller, so
if you really want to improve the speed of transfer even at the around 1 to
2 MHz you seem to be doing, to do anything over 4 bytes USE DMA. I doubt
much else is using DMA on those boards.
If you REALLY want to design for speed you WILL have to use DMA and specify
buffers which goes back to my suggestions on buffers.
Using DMA WILL increase the bandwidth especially for large block transfers.
Actually using DMA and completion/error interrupts, actually gives you the
ability to create NON-BLOCKING transactions.
This also applies to Wire/I2C as well as the only sensible block
implementation to get NON-blocking.
I have used DMA on many, many systems from PDP-11's to micros, in one case
16 years ago a 20Mhz 16 bit controller to do memory to memory transfers to
configure external memory mapped peripherals with about 500kB of data at
start up, then update 128kB portions at random times.
As to getting Arduino to speed things up, I doubt it, I created a MAJOR LCD
speed up February last year still waiting to get into milestones/project. As
in reducing time to write 20 characters to LCD down to 30% of normal time.
See https://github.com/arduino/Arduino/pull/4550
So don't hold your breath for acceptance into mainstream Arduino.
Personally creating an API for Mega and above for new API is medium term
a better approach. Allow each platform to use its FULL hardware capabilities
not a much restricted subset.
Kurt Eckhardt wrote:
>
>
> Yes I am outputting at the same speed and the like. What I am trying to
> do is to more fully utilize the SPI bandwidth. For example a few years
> ago was working with Edison. Again I don't remember the exact numbers,
> but for example they said could go up to maybe 8mbs, but with the
> overhead of each call, especially go through using spidev at best you
> could maybe get 2mbs...
>
>
>
> Now more specific. As right now I have Teensy LC hooked up. If I did
> the code I mentioned, if you look at the output using a Logic analyzer
> or Scope you will see something like:
>
>
>
> of about .63us. Here the gap between changing the DC pin is about
> .83us.. So these times the SPI buss is not transferring anything.
>
>
>
> With my current transfer Buffer code on the LC the output looks more like:
>
> better. For some reason in this test the gap between changing DC line
> increased, probably a bug in my code. Also currently using
> digitalWrite, where I normally would be using toggle of a bit to update.
>
>
>
> Now if you look at the T3.6 using the hardware registers you see data
> more like:
>
>
>
>
> --
> You received this message because you are subscribed to a topic in the
> Google Groups "Developers" group.
> To unsubscribe from this topic, visit
> https://groups.google.com/a/bcmi-labs.cc/d/topic/developers/Q12I7sB_Elk/unsubscribe.
> To unsubscribe from this group and all its topics, send an email to
> developers+...@bcmi-labs.cc
> <mailto:developers+...@bcmi-labs.cc>.
--
Paul Carpenter | pa...@pcserviceselectronics.co.uk
<http://www.pcserviceselectronics.co.uk/> PC Services
<http://www.pcserviceselectronics.co.uk/LogicCell/> Logic Gates Education
<http://www.pcserviceselectronics.co.uk/pi/> Raspberry Pi Add-ons
<http://www.pcserviceselectronics.co.uk/fonts/> Timing Diagram Font
<http://www.badweb.org.uk/> For those web sites you hate

Andrew Kroll
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc <mailto:developers+unsubscribe@bcmi-labs.cc>.
--
You received this message because you are subscribed to a topic in the Google Groups "Developers" group.
To unsubscribe from this topic, visit https://groups.google.com/a/bcmi-labs.cc/d/topic/developers/Q12I7sB_Elk/unsubscribe.
To unsubscribe from this group and all its topics, send an email to developers+unsubscribe@bcmi-labs.cc <mailto:developers+unsubscribe@bcmi-labs.cc>.
--
Paul Carpenter | pa...@pcserviceselectronics.co.uk
<http://www.pcserviceselectronics.co.uk/> PC Services
<http://www.pcserviceselectronics.co.uk/LogicCell/> Logic Gates Education
<http://www.pcserviceselectronics.co.uk/pi/> Raspberry Pi Add-ons
<http://www.pcserviceselectronics.co.uk/fonts/> Timing Diagram Font
<http://www.badweb.org.uk/> For those web sites you hate
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.

William Westfield
> you are claiming that you get too long a software overhead gap between each byte. The type of reduction you are looking for CANNOT be done by tweaking block mode software alone, or repeated software calls, especially when you get up to the SPI speeds I am usedto of 10 to 20MHz, without gaps. You must use the HARDWARE functions available to assist it.
Alas, the AVR (at least) has no hardware assist. Not even a one-byte holding register for transmit. Various very clever people have tried using the AVR SPI interface to generate video (for example), and were unable to get back-to-back transfers. (They did get it to about 1 bit-time of idle in between bytes, which is a lot better than the current code.) They have had better luck with “UART in SPI mode” (which DOES have an extra byte of transmit buffer.)
Due is suppose to have a extra Transmit Data Register (one byte fifo), but there was some recent discussion ( https://forum.arduino.cc/index.php?topic=437243.0 ) where I never was able to get back-to-back transmission, either (using programmed IO.) Due (and most or all of the other ARM chips) also has DMA, of course…
> In lieu of hardware fifo you can always do a software fifo on an interrupt to emulate it on platforms that lack a hardware fifo.
BillW/WestfW
Paul Carpenter
> On Apr 16, 2017, at 5:13 PM, Paul Carpenter <pa...@pcserviceselectronics.co.uk> wrote:
>
>> you are claiming that you get too long a software overhead gap between each byte. The type of reduction you are looking for CANNOT be done by tweaking block mode software alone, or repeated software calls, especially when you get up to the SPI speeds I am usedto of 10 to 20MHz, without gaps. You must use the HARDWARE functions available to assist it.
>
> Alas, the AVR (at least) has no hardware assist. Not even a one-byte holding register for transmit. Various very clever people have tried using the AVR SPI interface to generate video (for example), and were unable to get back-to-back transfers. (They did get it to about 1 bit-time of idle in between bytes, which is a lot better than the current code.) They have had better luck with “UART in SPI mode” (which DOES have an extra byte of transmit buffer.)
performance and better block mode transfers create a new API for Mega and
above at least on Mega you can use the USART SPI and have more RAM to play
with. Without adding external RAM interface.
I have seen some hardware that could NOT drive SS properly if you wanted to
do more than one byte so you had to create your own GPIO driven SS and put
up with long gaps due to hardware.
> Due is suppose to have a extra Transmit Data Register (one byte fifo), but there was some recent discussion ( https://forum.arduino.cc/index.php?topic=437243.0 ) where I never was able to get back-to-back transmission, either (using programmed IO.) Due (and most or all of the other ARM chips) also has DMA, of course…
own DMA FIFO as well, you need to use DMA to do it right.
Andrew Kroll
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
Paul Carpenter
SPI @ 1 MHz requires a new byte every 8 us
Teensy LC clock speed 48 MHz
If it was always one clock cycle per instruction that means it can perform
SIX instructions between bytes, which WILL NOT be enough to
Accept interrupt (end of current instruction or disabled interrupts)
Do context switch (save known registers)
Enter interrupt routine
Save registers we know we must save here
Check any status/errors
Fetch next byte to send
CALL the library function to actually send it
(with all its stack frame overhead)
etc etc
Start running SPI at 10MHz and it gets hairier, let alone running on AVR at
16 MHz. I wish people understood how the ABI of a compiler worked along with
context switching, interrupt latency.
Also remember the VERY limiting design restriction set for this speed up
use existing spidev (manufacturer supplied library commonly known in
industry as Board Support Package - BSP). So any inefficiencies there are
still limiting us. Including probably excessive parameter passing.
BSP are of VERY variable quality and performance, often written by junior
devs or interns who think they can do things the same as on their
multi-GHz desktop. The fact that the SPI clocks at 1Mhz is enough the inter
byte gap is USUALLY NOT part of the design requirements. The package is
designed as a quick way to get to market for them and their evaluation
boards and lazy customers who do not need performance.
Anyway by the time they work out the problems there will be a new device
to upsell them with faster clock and more RAM.
Generally use BSP is a good STARTING point, but you really need to realise
that at least the peripheral functions WILL have to be rewritten, you can
often stay with startup code, bootloader, power management and one off used
code, other sections need to be rewritten over time.
Even if things like SPI are supported it probably was not tested on anything
more than simple devices that only do Read or only do Write, inter byte
gaps do not matter. If it has code that has been tested with DMA that would
be unusual.
Having had to rewrite sections of code to get round counter division
calculations rounding the WRONG way amongst other things.
Andrew Kroll wrote:
> Well, yes, of course. That wasn't my point!
>
> AVR can interrupt on tx empty, kind-of like serial.
> Point is on avr you won't bet back to back transfers, however it can
> pretend to have a fifo, allowing for a uniform api.
>
> On Apr 17, 2017 12:54 AM, "William Westfield" <wes...@mac.com
>
> On Apr 16, 2017, at 5:13 PM, Paul Carpenter
> <paul@pcserviceselectronics. co.uk
Andrew Kroll
Paul Carpenter
similar, which have more capabilities than AVR.
Bloody Stupid AVR limiting API is the PROBLEM, the current code will
be better than your suggestion for AVR.
There are more processors than AVR even in the current line up, so will
people stop this we must be consistent with the damn limiting AVR.
Andrew Kroll wrote:
> I have well over 35 years under my belt as far as writing code.
> Back then, we counted cycles, etc. I know how they work, and at one
> point wrote my own libc and libm. Don't assume I'm not understanding.
> My point, again, wasn't speed for AVR.
>
> General rule is this: If an MCU isn't fitting your needs, then obviously
> you need to select one that does. E.g. Would you expect to be able to
> have an AVR navigate an automobile? Of course not!
>
>
>
>
>
> On Apr 17, 2017 1:33 AM, "Paul Carpenter"
> <pa...@pcserviceselectronics.co.uk
> <paul@pcserviceselectronics. co.uk <http://co.uk>
> <mailto:paul@pcserviceselectro nics.co.uk
Andrew Kroll
Paul Carpenter
Windows 10, Linux and Mac as 64 bit OS
2/ Teensy is too small for a lot of my applications so I doubt it
A vast majority of the AVR style limitations is great for blinking lights
and VERY slow apps, mainly linear code for students who in my experience
cannot grasp why moving between float and int all over the place is a
problem.
One application is going to have to use the Mega external memory interface
as acquiring 425 bytes in parallel in 10 us needs a memory mapped FPGA and
some re-writing of core functions as the core cannot support certain things.
Only using Mega as customer blindly wants Arduino style for wrong reasons.
Andrew Kroll wrote:
> Exactly why I suggested a work-alike solution for AVR.
> I write tons of ARM code, and not just on an MCU.
> I also write MIPS as well.
> Don't assume I'm not following the conversation.
> Ever used my SPI lib for teemsy 3? Chances are you could have.
>
> On Apr 17, 2017 2:17 AM, "Paul Carpenter"
> <pa...@pcserviceselectronics.co.uk
>
> Read back majority of the discussion has been about Teensy Due and
> similar, which have more capabilities than AVR.
>
> Bloody Stupid AVR limiting API is the PROBLEM, the current code will
> be better than your suggestion for AVR.
>
> There are more processors than AVR even in the current line up, so will
> people stop this we must be consistent with the damn limiting AVR.
>
>
> Andrew Kroll wrote:
>
> I have well over 35 years under my belt as far as writing code.
> Back then, we counted cycles, etc. I know how they work, and at
> one point wrote my own libc and libm. Don't assume I'm not
> understanding.
> My point, again, wasn't speed for AVR.
> *Point is API*. Sometimes slow is acceptable. It depends on what
> your code is doing.
>
> General rule is this: If an MCU isn't fitting your needs, then
> obviously you need to select one that does. E.g. Would you
> expect to be able to have an AVR navigate an automobile? Of
> course not!
>
>
>
>
>
> On Apr 17, 2017 1:33 AM, "Paul Carpenter"
> <pa...@pcserviceselectronics.co .uk
> <mailto:paul@pcserviceselectro nics.co.uk
>
> On Apr 16, 2017, at 5:13 PM, Paul Carpenter
> <paul@pcserviceselectronics. co.uk <http://co.uk>
> <mailto:paul@pcserviceselectro
> <mailto:paul@pcserviceselectro> nics.co.uk <http://nics.co.uk>
> <mailto:paul@pcserviceselectro nics.co.uk
Andrew Kroll
1/ I consider the must be consistent with AVR akin to support CPM/86 on
Windows 10, Linux and Mac as 64 bit OS
2/ Teensy is too small for a lot of my applications so I doubt it
A vast majority of the AVR style limitations is great for blinking lights
and VERY slow apps, mainly linear code for students who in my experience
cannot grasp why moving between float and int all over the place is a
problem.
One application is going to have to use the Mega external memory interface
as acquiring 425 bytes in parallel in 10 us needs a memory mapped FPGA and
some re-writing of core functions as the core cannot support certain things.
Only using Mega as customer blindly wants Arduino style for wrong reasons.
Andrew Kroll wrote:
Exactly why I suggested a work-alike solution for AVR.
I write tons of ARM code, and not just on an MCU.
I also write MIPS as well.
Don't assume I'm not following the conversation.
Ever used my SPI lib for teemsy 3? Chances are you could have.
On Apr 17, 2017 2:17 AM, "Paul Carpenter" <pa...@pcserviceselectronics.co.uk <mailto:paul@pcserviceselectronics.co.uk>> wrote:
Read back majority of the discussion has been about Teensy Due and
similar, which have more capabilities than AVR.
Bloody Stupid AVR limiting API is the PROBLEM, the current code will
be better than your suggestion for AVR.
There are more processors than AVR even in the current line up, so will
people stop this we must be consistent with the damn limiting AVR.
Andrew Kroll wrote:
I have well over 35 years under my belt as far as writing code.
Back then, we counted cycles, etc. I know how they work, and at
one point wrote my own libc and libm. Don't assume I'm not
understanding.
My point, again, wasn't speed for AVR.
*Point is API*. Sometimes slow is acceptable. It depends on what
your code is doing.
General rule is this: If an MCU isn't fitting your needs, then
obviously you need to select one that does. E.g. Would you
expect to be able to have an AVR navigate an automobile? Of
course not!
On Apr 17, 2017 1:33 AM, "Paul Carpenter"
<pa...@pcserviceselectronics.co .uk
<mailto:paul@pcserviceselectronics.co.uk>
<mailto:paul@pcserviceselectro nics.co.uk
Paul Carpenter
> Need an ip stack too? Got one of those for avr using slip ;-)
> CP/M86 would be too new, try CP/M 2/3+, MPM, and even early 8051 stuffs.
> Yes i agree, there is a need for using faster hardware when available,
> but that isn't Arduino's main audience. So... emulate what's 'missing'.
>
a) Copy and paste = programming (in UK govt eyes that is coding)
Even to extent of copy/paste two sections of code with different
variable names and wonder why it does work by magic
b) Magic happens
c) Please do my homework.
Don't bother using faster hardware the software is just as slow on that

Mike
Kurt Eckhardt
Thanks for the input.
As I mentioned in previous message. I think it would be great if someone tried to come up with a more advanced set of APIs. As mentioned, you will probably always get a more optimal solution when it is tightly wired to the underlying hardware. And yes some of the AVR stuff can be constricting.
And not that it matters, I also have been programming for several decades as well and have played around with a variety of processors.
Personally I would love to see Arduino start to add some more advanced features like some simple RTOS and more interrupt and DMA support to their platforms.
But I also understand their desire to make it easy for people to get started.
As such I still think it is worthwhile if one can implement a simple solution that gets you 80-90% there, that ordinary Arduino developers can understand and use.
Other approaches:
Interrupts:
I may be wrong, but in the majority of cases I don’t think using interrupts will help in maximizing the output on the SPI bus. That is currently the code typically spins waiting for the appropriate status bit to be set and then directly reads or writes the data to the SPI register. Versus have the system detect this same status bit is set and the interrupt enable is set and then call off to an interrupt handler. And many of these interrupt handlers you then have to read the status again to figure out why it was called and then do the read or write.
However I could understand the use of Interrupts if you tried to model the SPI, maybe something like a UART, where you can write to a queue and read from a queue and you had the transfers happen in the background. Might not be hard to implement a version like this. Don’t know how much control one would add on Writes to say should each byte I read imply something is put on the Read queue… As I mentioned this may be good to allow you to do other things instead of looping, waiting for a transfer to complete. And maybe could help throughput some, as people could do single byte writes and hopefully add the next one before previous one completes, but I am unsure here…
And I am unsure how well this would work, with things like controlling CS pins and on several displays and probably other devices a secondary pin DC which needs to be synchronized with when bytes are actually transferred.
DMA:
I have only used DMA on Teeny 3.x boards and have experimented a little on the LC (read that test out DmaSPI library on the LC for both buses). And with at least the Teensy 3.x I did not see it make any better use of the SPI buss than simply using the FIFO queues. This may be true for most of the advanced processors who at least support at a minimum double buffering
Don’t get me wrong, SPI DMA access is great for things, in that it then allows you to use the processor for something else other than spinning on reading the status flags.
For example, for the Teensy 3.6 which has enough memory to do a do a frame buffer for an ILI9341 display, I have updated my ili9341_t3n library to optionally do this. The code now has the option to use DMA to update the screen, either as a one shot or continuous. So this is great, I can do all of my screen updates quickly to memory, tell it update now and then continue on other tasks, and then when I am ready to update the display again, I can see if the update has completed or not… Note: for this display we output as fast as we can usually something like 20-30mbs depending on your CPU speed.
But this code is very specific to the Teensy! You have to know about how large each DMA transfer can be, and how to chain them and know when you can update the chain. Have interrupts to handle… I don’t know how easy this would be to translate into something generic. Do most DMA setups allow for chains? Have possible interrupts at end of an item or midpoint…
Proposed Simple Update
Again this proposed update will not get you all of the performance that you can get using some other more advanced CPU specific features, however in many case I believe it can get you a reasonable improvement.
I suggest adding another #define to let users know you have this feature, maybe something like:
#define SPI_HAS_TRANSFER_BUF 1
I then suggest adding a new transfer buffer function with separate pointer to output buffer and receive buffer, which either one can be NULL. Like:
void transfer(const void * buf, void * retbuf, uint32_t count) {
How does this help?
For processors who have no additional hardware support like double buffering. At minimal it does not hurt. That is its timing is no worse than you doing the for loop.
For processors like Teensy LC which has double buffering, I have this implemented by starting the first byte, then wait until I can set the 2nd byte and then wait for first byte to complete, read it, and then repeat until last byte has been received. A version of this is in the current release for the transfer(buf, count) and it sped up the output a reasonable amount. Again nice thing here is if it turns out using the FIFO on the LC can improve things, we can simply update its implementation…
For processors like the Teensy 3.x which has Fifo queues, you can do similar, except enhanced it to fill the fifo queue. Also found that smaller gaps between bytes on 16 byte transfers, so it packs the bytes into words… Again keeps the queue full and SPI buss going at full speed.
Again I have not tried it, but if on some other processor, DMA is faster and easy to setup, then maybe it would make sense to have an implementation that has a DMA setup, where you can point to the users buffers and do the task and then return when the DMA completes. Again don’t know how well that would work, but?
So again hopefully we can come up with an API or set of APIs that can help to write reasonably efficient code that is still easy to move to another processor. Example here is a version of the Teensyview display driver code to update a screen. Using it:
void display_transfer_buf(void)
{
uint8_t set_page_column_address[] =
{
0xb0, 0x21, 0, 0x7f
}; // set to page 0 column 0
uint8_t i;
uint8_t * pscreen_data = screenmemory;
uint8_t count_pages = (_height / 8);
SPI.beginTransaction(SPISettings(clockRateSetting, MSBFIRST, SPI_MODE0));
ASSERT_CS();
for (i = 0; i < count_pages; i++)
{
// Output the header
ASSERT_DC(); // assert DC
set_page_column_address[0] = 0xb0 + i;
SPI.transfer(set_page_column_address, NULL, sizeof(set_page_column_address));
// Now go into data mode
RELEASE_DC();
SPI.transfer(pscreen_data, NULL, LCDWIDTH);
pscreen_data += LCDWIDTH;
}
RELEASE_CS();
SPI.endTransaction();
}
Again this does not get me the same speed as doing Teensy 3.x specific code using PUSHR/POPR, but it is not that far from it. There are minor gaps in time when we ASSERT_DC and RELESE_DC (these are defined as either digitalWrite, or in some cases we have register pointer/mask that we use.
The other question I have here is does it make sense to add some of the Arduino DUE changes to the API? I believe they encode some CS support into the API, like choosing which CS and to continue or not continue? If so might make sense to maybe abstract this some as to either be a pin or maybe it is some hardware specific MASK (like CS channel(s)).
Again I think it would be great to define a higher level more advanced API, but until then it would be nice to try to get the current one to work well.
Thanks again
Kurt
Thomas Roell
--
Paul Carpenter
> Couple of generic comments (been there done that ;-))
> A good example of what not to do is the "sam" core with the embedded
> "CS" line handling. Not every application will need it (actually most
> will not), but you pay the additional software overhead per dinky little
> SPI.transfer(8-bit-data) call. That translates to lower performance for
> the 95% of the applications for no good reasons. So one has to be
> careful what to add and what not to add.
bit GPIO has quite a bit of overhead.
> IMHO a CPU driven SPI.transfer(source, destination, count) type API can
> saturate a SPI bus easily. One of the holdups is sometimes a bad choice
> of polarities (SPI_MODE), that cause some SPI peripherals to insert an
> extra clock between data transfers. Or simply a suboptimal
> implementation in software.
software time, the scope shots earlier showed bus busy (SS low) but doing
nothing between bytes. Which to me is not bus saturated but software driver
saturated.
> DMA normally does not help the throughput, but allows you to background
> the transfer, and have the CPU to attend to other tasks. If that is
> required, a interrupt based scheme might be usable for lower clocks SPI
> buses as well (1MHz SPI on a STM32L4 with 80MHz took less the 5% of the
> total processor cycles). N.b. DMA is in general SLOWER than letting the
> CPU drive the bus, because there is overhead involved setting up the DMA
> operation.
for LARGE block size (eg 256 bytes from EEPROM), but the backgrounding gives
you more processor time, less spin locking. the overhead in setting up is
once the overhead of repeated calls and buffer manipulation becomes 'O'n
complexity, in the amount of processing time lost. Also if buffers have to
be copied adds overhead.
This is true of using DMA for anything.
You don't know what else any application is doing so always minimise your
blocking time.
Where you set the boundary to start using DMA at be it 4, 8, 16, 32, 64
bytes is more a matter of performance of software and system. If all your
application is doing is waiting for the device before doing anything else
then either method may well do. NOT all applications do this, even for
beginners.
I said at outset of mentioning DMA this would best be done for at least
4 byte blocks.
There was a debate in 386 days about what is faster for disk drives to use
programmed I/O or DMA because the processor was 'fast enough' (33MHz) with
512 byte blocks, that became clusters or even tracks, since then it has
always been DMA on PCs, but even back then there was an option for parallel
printer port to use DMA.
Thomas Roell
IMHO a CPU driven SPI.transfer(source, destination, count) type API can saturate a SPI bus easily. One of the holdups is sometimes a bad choice of polarities (SPI_MODE), that cause some SPI peripherals to insert an extra clock between data transfers. Or simply a suboptimal implementation in software.
It depends what you mean by saturate, if you mean saturate the calls in
software time, the scope shots earlier showed bus busy (SS low) but doing
nothing between bytes. Which to me is not bus saturated but software driver
saturated.
DMA normally does not help the throughput, but allows you to background the transfer, and have the CPU to attend to other tasks. If that is required, a interrupt based scheme might be usable for lower clocks SPI buses as well (1MHz SPI on a STM32L4 with 80MHz took less the 5% of the total processor cycles). N.b. DMA is in general SLOWER than letting the CPU drive the bus, because there is overhead involved setting up the DMA operation.
DMA will ALWAYS be slower for SMALL block sizes, but will always be FASTER
for LARGE block size (eg 256 bytes from EEPROM), but the backgrounding gives
you more processor time, less spin locking. the overhead in setting up is
once the overhead of repeated calls and buffer manipulation becomes 'O'n
complexity, in the amount of processing time lost. Also if buffers have to
be copied adds overhead.
Paul Carpenter
> Comments embedded.
>
> - Thomas
>
> On Mon, Apr 17, 2017 at 9:52 AM, Paul Carpenter
> <pa...@pcserviceselectronics.co.uk
...
> DMA normally does not help the throughput, but allows you to
> background the transfer, and have the CPU to attend to other
> tasks. If that is required, a interrupt based scheme might be
> usable for lower clocks SPI buses as well (1MHz SPI on a STM32L4
> with 80MHz took less the 5% of the total processor cycles). N.b.
> DMA is in general SLOWER than letting the CPU drive the bus,
> because there is overhead involved setting up the DMA operation.
>
>
> DMA will ALWAYS be slower for SMALL block sizes, but will always be
> FASTER
> for LARGE block size (eg 256 bytes from EEPROM), but the
> backgrounding gives
> you more processor time, less spin locking. the overhead in setting
> up is
> once the overhead of repeated calls and buffer manipulation becomes 'O'n
> complexity, in the amount of processing time lost. Also if buffers
> have to
> be copied adds overhead.
>
>
> Incorrect. For a CPU to SPI ratio like outline above, a DMA cannot be
> faster, as the limiter is really the SPI bandwidth.
me. 10 to 20 MHz is my norm, but on Due I limited to 5 MHz.
>DMA will be almost
> always be slower due to the added setup overhead. DMA is even worse,
> because you also have to either have a callback when DMA is done, or
> poll a DMA-done status bit. Over larger block sizes this relative
> overhead goes down.
peripheral combination that does not have an end of DMA interrupt.
Interrupt routine (NOT a callback) sets up either more transfers or sets
flags. Up to task to check if done then return to doing other things.
What is it with arduino folks who like to sit polling things all the time
or everything must have a callback.
If all you ever do is
Process A
Delay or poll
Process B
......
No wonder the general libraries are so slow and many other things.
Thomas Roell
Thomas Roell wrote:
Comments embedded.
- Thomas
On Mon, Apr 17, 2017 at 9:52 AM, Paul Carpenter <pa...@pcserviceselectronics.co.uk <mailto:paul@pcserviceselectronics.co.uk>> wrote:
...
DMA normally does not help the throughput, but allows you to
background the transfer, and have the CPU to attend to other
tasks. If that is required, a interrupt based scheme might be
usable for lower clocks SPI buses as well (1MHz SPI on a STM32L4
with 80MHz took less the 5% of the total processor cycles). N.b.
DMA is in general SLOWER than letting the CPU drive the bus,
because there is overhead involved setting up the DMA operation.
DMA will ALWAYS be slower for SMALL block sizes, but will always be
FASTER
for LARGE block size (eg 256 bytes from EEPROM), but the
backgrounding gives
you more processor time, less spin locking. the overhead in setting
up is
once the overhead of repeated calls and buffer manipulation becomes 'O'n
complexity, in the amount of processing time lost. Also if buffers
have to
be copied adds overhead.
Incorrect. For a CPU to SPI ratio like outline above, a DMA cannot be faster, as the limiter is really the SPI bandwidth.
Assumption by most folks is slow SPI around 1MHz, yes 1MHz SPI is slow for
me. 10 to 20 MHz is my norm, but on Due I limited to 5 MHz.
DMA will be almost always be slower due to the added setup overhead. DMA is even worse, because you also have to either have a callback when DMA is done, or poll a DMA-done status bit. Over larger block sizes this relative overhead goes down.
WHAT I have never yet come across a DMA controller or DMA controller and
peripheral combination that does not have an end of DMA interrupt.
Interrupt routine (NOT a callback) sets up either more transfers or sets
flags. Up to task to check if done then return to doing other things.
What is it with arduino folks who like to sit polling things all the time
or everything must have a callback.
If all you ever do is
Process A
Delay or poll
Process B
......
No wonder the general libraries are so slow and many other things.
Paul Stoffregen
> What is it with arduino folks who like to sit polling things all the time
> or everything must have a callback.
unproductive arguments with a particularly unsavory aspect of
participants asserting their superiority, such a number of years
experience programming, insinuating others are inferior, not to mention
a whole lot of negativity about Arduino in general. Or in short, to
everyone else bothering to keep reading, a "pissing contest".
But yeah, what is it with Arduino folks?
Thomas Roell
Andrew Kroll
Andrew Kroll
Thomas Roell
Paul Stoffregen
> Why not just design something and present it and see how well it gains
> acceptance?
when he started this thread.
Kurt Eckhardt
Thanks,
This makes sense to me.
Which up through the callback stuff is what I have suggested. With difference of if txBuffer is NULL I suggested 0x00 be sent and you did 0xff
Could potentially add a member to set what character to be sent… Or I have seen cases where people do things like if the buffer pointer is in the range of 0x00—0xff, then use that value as your TX value.
With the Async stuff would probably want to set up rules on what happens if you have one transfer active and try to issue a 2nd transfer. Does it wait for the previous one to complete or is there some form of queue of requests…
Again this feels like a simple enhancement to current stuff, plus retains compatibility.
What is not discusses and maybe should be left separate is does it make sense to add in the stuff like the Arduino Due to have the SPI interface have some control over hardware chip select pin(s)?
Thanks
From: Thomas Roell [mailto:grumpyo...@gmail.com]
Sent: Monday, April 17, 2017 10:33 AM
To: devel...@bcmi-labs.cc
Subject: Re: [Developers] Re: Suggestion: make a faster more compatible SPI class with a faster Transfer function.
Andrew,
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
Thomas Roell
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
Thomas Roell
Sorry, I know this is probably not the first time this has come up on this email list. Also sorry if I am at times a little too long winded.
Background:
But over the last few years I have been playing around with several different boards and have experimented with several SPI devices, lately mostly with Teensy boards.
Currently I have a new version of the SPI library for the Teensy boards, which hopefully over time I will be able to integrate into the main version.
All SPI objects have common class (or base class):
One of my primary reasons for this new version, is to make all of the SPI objects to of the class SPIObject, instead of the current version where each of the SPI objects have their own class. This change will make the objects more compatible with some of the other implementations, such as the Arduino SAM and SAMD implementations. With this I am hoping over time we can update many of the different libraries that use SPI to allow us to select which SPI buss to use.
Currently if someone has a Teensy 3.6 and wishes to use SPI2 for some device. The typical way to handle this is to edit the library and do a global search and replace for “ SPI.” To “ .SPI2.”… Which is not optimal especially if in other cases you still wish to use that device on SPI.
I believe I have this all working in my version.
Transfer functions:
But the other main thing that I believe SPI needs is some faster standardized way to do transfers of data. Today the only standardized API to transfer data is:
X = SPI.transfer(y)
And this API complete completely handicaps the SPI buss on the majority of boards as you can not make use of any hardware features such as FIFO queues or at a minimum double buffering and as such, there are gaps of time between each byte output, which significantly reduces the throughput.
Currently several libraries also support:
X = SPI.transfer16(y)
Which helps a little in some cases
Currently in the Arduino and Teensy libraries, there is also a multibyte version :
SPI.transfer(buf, cnt)
This API can improve the performance, as different implementations can make use of specific features of the processor. For example on the Teensy 3.x processors, we can make use of the FIFO queue, we can choose to pack the outputs into 16 bit value and we can tell SPI hints like more data is coming so don’t add delays. Or on the Teensy LC, we can make use of the double buffering to speed things up.
Unfortunately many of the implementations (Teensy was this way until latest release). This is implemented simply as:
void SPIClass::transfer(void *buf, size_t count)
{
uint8_t *buffer = reinterpret_cast<uint8_t *>(buf);
for (size_t i=0; i<count; i++) {
*buffer = transfer(*buffer);
buffer++;
}
}
Which gains you nothing performance wise. And in many cases can make the program slower.
For example the Sparkfun_TeensyView display (SSD1306), you use a memory buffer (512 bytes), you do your graphics into and when you are ready to update the display, you call the display function, which outputs a 4 byte header (DC Asserted), followed by the first 128 bytes of the buffer (DC not asserted) and repeat 4 times to output the display… So calling the SPI.transfer(&screenbuffer[0], 128), will overwrite your screen buffer. So to use this API, you typically need to first copy the region of the screen buffer into a temporary buffer and then call this api. On fast machines with lots of memory this may not be too bad, but on slower machines with limited memory, this can be a problem.
So what do many developers do? If you are using a Teensy 3.x, you may choose to write code that is very specific to the Teensy. For example you may make use of the FIFO queues and understand that you can encode additional information such as which chip select pins to assert, or you might make use of DMA, which again is very processor specific. But this has several downfalls, including it will only work with those processors and it is not easy for novice users to understand.
Suggestion:
Make a standard API or a set of APIs that allows you to do multibyte transfers which do not overwrite the main buffer passed in. Also we should have the option to do write only and/or read only operations.
Note: several of the different platforms already have added functions to do help with this
Examples:
Intel Edison/Galileo have added the API
void transferBuffer(const uint8_t *, uint8_t *, uint32_t);
Where I believe you have the option to pass in NULL for the first parameter (will send all zeros), or NULL for 2nd parameter and no read data will be returned.
ESP32: has a couple of different methods.
void transferBytes(uint8_t * data, uint8_t * out, uint32_t size);
void transferBits(uint32_t data, uint32_t * out, uint8_t bits);
I believe there are some others as well. And some of them also have wrapper functions like read and write And I believe in some case you may be able to set what character to send in a read operation…
What I have tried so far is, like the Edison version, except the method name is still just transfer. I also added a define to the library, such that a program could check to see if a library supports it and use it else do something different.
That is I have:
#define SPI_HAS_TRANSFER_BUF 1
void transfer(const void * buf, void * retbuf, uint32_t count);
I then implemented versions of it for Teensy 3.x, Teensy LC, Arduino AVR, plus I experimented with a version for Arduino SAMD (Sparkfun version).
My current stuff for Teensy (and the avr part of it) is up in my fork/branch of SPI on github:
https://github.com/KurtE/SPI/tree/SPI-Multi-one-class
I then setup a test app, bases off of the Teensyview Screen update code, I mentioned above. I have four versions of this function.
One that does it the uses transfer(x), another that uses transfer(buf, cnt), another that use my updated code transfer(buf, NULL, cnt) and a fourth that is specific to Teensy 3.x which uses the fifo queue and I used a baseline for what is at least possible.
I ran most of these tests with default board parameters.
Times are in us
One byte Transfer(buf, cnt) Transfer(buf, NULL, cnt), PUSHR/POPR
Teensy 3.2: 677 562 554 539
Teensy LC 1205 942 844
Arduino UNO 1404 1052 888
Sparkfun SAMD 1169 1331 612-800+?
I am not an expert on Atmel SAMD code but the docs, I believe implied that you could try to keep the output going by checking the DRE bit and when set you could output the next data. It appears like it can mostly work, but at times I was getting hang, so put a quick and dirty countdown counter to bail out. So that is why there is differences in speed in this case. Not sure of best fix. Probably best left to someone who uses these processors more than I do.
void SERCOM::transferDataSPI(const uint8_t *buf, uint8_t *rxbuf, uint32_t count)
{
if ( count == 0 )
return;
const uint8_t *p = buf;
uint8_t *pret = rxbuf;
uint8_t in;
// Probably don't need here .
sercom->SPI.DATA.bit.DATA = p ? *p++ : 0; // Writing data into Data register
while (--count > 0) {
while( sercom->SPI.INTFLAG.bit.DRE == 0 )
{
// Waiting for TX Buffer empty
}
sercom->SPI.DATA.bit.DATA = p ? *p++ : 0; // Writing data into Data register
while( sercom->SPI.INTFLAG.bit.RXC == 0 )
{
// Waiting Complete Reception
}
in = sercom->SPI.DATA.bit.DATA;
if (pret)*pret++ = in;
}
uint16_t timeout_countdown = 0x1ff; // should not be needed.
while( (sercom->SPI.INTFLAG.bit.RXC == 0 ) && timeout_countdown--)
{
// Waiting Complete Reception
}
in = sercom->SPI.DATA.bit.DATA;
if (pret)*pret++ = in;
}
Main question:
Are there others who are interested in adding a new method or methods to the SPI interface and if so suggestions on which one(s)?
Thanks
Kurt
Kurt Eckhardt
Thanks,
I am not sure of any specific dummy bytes. I know with several display drivers many pass 0 to them. But with the ili9341 display I have had better luck using 0x3c (not sure which document semi implied this value)…
With the arduino CS DUE stuff, I probably agree, although as I mentioned in the case of a Teensy 3.x, it could come in handy. That is if you could do something like:
transfer(CS+DC, command_bytes, NULL, count_command_bytes, CONTINUE)
transfer(CS, data_bytes, NULL, count_data_bytes, (maybe last or maybe CONTINUE)
I understand your rational for erroring out Asnyc calls if another one is already busy.
It will be interesting to see how one would do Async on some of the platforms. Example Intel Edison. All of the transfer calls are simply IOCTL calls to SPIDEV. Not sure how many other platforms may be similar to this.
In theory you might be able to use this allow the Teensy to encode the CS/DC pin select data into the underlying PUSHR/POPR usage, such that you don’t have to wait until all bytes have been fully transferred and have the command complete before switching the state of the DC pin start the transfer of data bytes.
But I agree with you that this may not be needed or helpful in general.
From: Thomas Roell [mailto:grumpyo...@gmail.com]
Sent: Monday, April 17, 2017 11:48 AM
To: devel...@bcmi-labs.cc
Subject: Re: [Developers] Re: Suggestion: make a faster more compatible SPI class with a faster Transfer function.
Kurt,
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
William Westfield
On Apr 16, 2017, at 10:34 PM, Paul Carpenter <pa...@pcserviceselectronics.co.uk> wrote:
> SPI @ 1 MHz requires a new byte every 8 us
>
> Teensy LC clock speed 48 MHz
>
> If it was always one clock cycle per instruction that means it can perform
> SIX instructions between bytes, which WILL NOT be enough
> Stupid AVR limiting API is the PROBLEM
> If "rxBuffer" is NULL, then no data is returned, if "txBuffer" is NULL, 0xff bytes are send. The classic multibyte transfer becomes a simple inline with "txBuffer = rxBuffer = buffer".
BillW/WestfW
Thomas Roell
Thanks,
I am not sure of any specific dummy bytes. I know with several display drivers many pass 0 to them. But with the ili9341 display I have had better luck using 0x3c (not sure which document semi implied this value)…
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
Thomas Roell
Kurt Eckhardt
Sorry I missed this one. I will give it a try.
For some reason my email provider put about half of the messages of this thread into the SPAM folder. I only realized that when I was seeing responses to messages that I had not received.
I believe the main difference you did here was to separate out the transfer code into three sections: Write only, Read only, and transfer. It will be curious to see if there is any noticeable differences in doing it this way. That is for example having separate section for Read only. The main difference in the loop is along the line of one if statement, something in the nature of: if (txbuf) txChar = *txbuf++;
So in the read only case you save the if test as earlier you already setup txChar or the like to appropriate value.
Actually with the LC, I thought my next test would be to instead of using the double buffering turn on the 64 bit fifo queue and see if that speeds things up or not and also potentially pack two bytes into a word, as at least on the T3.x version, the hardware gives a smaller space between bytes of a word than it does between bytes/words of the queue.
Again thanks for your suggestions.
Also it still would be great if some of the main people of Arduino would comment on what level of changes (if any) that they would accept.
Also Paul (PJRC), Should I also try adding in the Async version to my fork?
Thanks everyone.
From: Thomas Roell [mailto:grumpyo...@gmail.com]
Sent: Monday, April 17, 2017 12:38 PM
To: devel...@bcmi-labs.cc
--
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
Thomas Roell
--
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
William Westfield
> With SPI the bidirectional transfer is the normal case, not the special case. That is what SPI is on a hardware level.
OTOH, I’m a little worried that there might be devices that do “send the 64 data bytes followed by a dummy byte, and the response to the dummy byte will contain the status of the transaction (but the preceding bytes can be ignored.) None of the APIs suggested would handle that very well…
> having explicit read()/write() functions might reduce the code size, as unneeded functions would not be linked in.
BillW
Kurt Eckhardt
Update: I have been working along these lines for the Teensy SPI implementation.
It took me awhile to get all of the Async version with a callback on all of the Teensy 3.x and LC boards using mostly DMA.
I won’t go into all of the details, but took a while as all of the boards handled DMA subtly differently. Things like what happens if the last Transfer you did before your Async request was a 16 bit write, or If you are doing a write only transfer to make sure it does not do the Callback until the write fully completes…
But one thing I am wondering about, is the use of Call backs. That is, is there a semi-standard for if an API is going to use a Callback, that the call back would be of the type: void MyCallback(void)?
Yes it is the simplest for most people to understand and maybe the easiest to use in simple cases. However they can be pretty limiting when you are using them for multiple objects, example inside of a class.
That is suppose I wish to update the Sparkfun Teensyview (simple 128x32 pixel display) code to add an Async update display function and I can have multiple of these displays on my machine, how do I use this simple callback? What I am hacking up as a test, is to create several static call back methods, and each object registers with one of them and then it calls back to a method that is part of the object…
But if instead of this real simple callback you defined it to be like: void MyCallback(void* data)
You can then have your Async version of Transfer be called like: transfer(mybuf, null, count, MyCallback, this)
And then your one simple static callback can then call through to the instance…
But not sure, it this would be considered too complex for the Arduino users?
But again all of this may not matter if none of these SPI enhancements are accepted.
Thoughts?
From: Thomas Roell [mailto:grumpyo...@gmail.com]
Sent: Monday, April 17, 2017 10:33 AM
To: devel...@bcmi-labs.cc
Subject: Re: [Developers] Re: Suggestion: make a faster more compatible SPI class with a faster Transfer function.

Bruce Boyes
Thomas Roell
--

Todd Krein
Many of the original libraries did a pretty good C++ job of hiding complexities for people that didn’t need them, while allowing calls for the “power” user.
What if you made the default call hide the async by providing a default call back, and either block on the call (which makes it synchronous and understandable to the beginner) or provide a mailbox variable that can be checked in the main loop. If someone really does need special handling on the async, they can provide their own call back.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.

Tilo Nitzsche
Kurt,there is a simple technical reason not to include a "data" item in the callback, at least for the STM32L4 core. There all callbacks are routed throu a "PendSV" queue so that the higher priority interrupts get not blocked by user level code. Minimally you need there a routine pointer to you class-event handler, and a "this" pointer to the class itself. So adding an extra "data" means that your queue needs 3 entries instead of 2.
You need 2. A function pointer and one 'void*' parameter is enough. The function (which could be a simple lambda) can use the 'void*' to dispatch to an object/method. (If you look at Kurts post, he suggested a C-style function pointer, with a single 'void*' parameter.) This is good enough for classes to support multiple instances with a unique callback for each. (If an object member call with parameters is required, the context could be a pointer to a struct containing the necessary stuff.)
class S {
public:
void callback();
};
void registerCallback(void (*callback_fn)(void*), void* context) {
// ...
}
void test(S* s) {
// ...
registerCallback([](void* ctx){ ((S*) ctx)->callback(); }, s);
}
Glancing at the STM32L4 core, the PendSV dispatching supports a 'void*' parameter for callbacks.
What am I missing?
Also there is precedence in the Wire & I2S library, the attachInterrupt() code, where no arguments are passed back to the callback that would be per-callback privates.
That is a bad precedent, requiring nasty workarounds. E.g. look at what Encoder does to emulate a context parameter:
https://github.com/PaulStoffregen/Encoder/blob/master/Encoder.h
Kurt Eckhardt
Thanks Tilo and Thomas (and others),
As you probably can tell, I personally like the idea of having the ability to pass something like a void* parameter for the reasons mentioned here and earlier. As Tilo mentioned, yes there are work arounds one can do, like Encoder but they can get messy.
But I would also like to hopefully be able to be reach a consensus and hopefully advance SPI on several of the platforms.
Over this last week or two I implemented a DMA version for the Teensy 3.x and LC platforms using DMA. Took a while to debug as all of the platforms behaved subtly different. I am also hacking on an SSD1306 (Teensyview) driver to have it run on all of the SPI buses of the boards and be able to do Async (DMA) updates of their display…
So again I am hoping that we can all(most) merge to a more common SPI interface.
Thanks again for all of the good feedback and suggestions.
Kurt
From: Tilo Nitzsche [mailto:tni.a...@gmail.com]
Sent: Friday, May 05, 2017 2:07 PM
To: Developers <devel...@bcmi-labs.cc>
Subject: Re: [Developers] Re: Suggestion: make a faster more compatible SPI class with a faster Transfer function.
On Tuesday, May 2, 2017 at 5:37:17 PM UTC+2, Thomas Roell wrote:
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
Kurt Eckhardt
Thanks Bruce,
I can understand the hair pulling. Been there… Actually this week trying to debug how the different DMA implementations of the 3 different T3.x boards was subtly different and some things would work on one and not on one of the others. So I went through maybe three different implementations until I think I have all three working…
As for Error codes and Recovery, I believe that is a much more general and probably a huge can of worms.
That is I know that there are multiple approaches to this.
For example suppose that your ethernet case, where you have some high level call into Ethernet , which probably goes through a few sets of calls there, to where it then calls into some Driver, which may go a few calls deep and then it calls into SPI, which lets say now uses the ASYNC code, and currently my ASYNC code only supports up to 32767 byte transfers… AND you passed in 65536… Now what to do?
Option 1: the SPI call fails maybe return false, maybe add Error code capability… You then have to have the caller check this, and error out to its caller, who has to check this, and error out to its caller… And hopefully the calling code has a way to handle this. If the sub-systems support error codes – then you may also have to have each level translate the code into their level. Also does each subsystem roll their own Error system/calls, or do you have some system level error system, where maybe each error code is 32 or 64 bits and maybe part of it is some sub-system number… Sounds familiar…
Option 2: Some of 1, like maybe System error manager… But instead of trying to return error codes that hopefully the caller checks for, you instead throw an exception and then different levels can use something like:
Try… Catch… Finally… Or something similar.
Option 3 or 4 or: ?
Over the many years on several platforms I have seen/read lots of discussions and arguments on the merits and pitfalls of different Error strategies. Both camps arguing the other causes speed or memory size issues… I think this would be a great topic on its own.
As this issue is far bigger than hopefully the step wise improvements to SPI.
From: Bruce Boyes [mailto:bbo...@gmail.com]
Sent: Tuesday, May 02, 2017 8:36 AM
To: devel...@bcmi-labs.cc
Subject: Re: [Developers] Re: Suggestion: make a faster more compatible SPI class with a faster Transfer function.
Well, this is an interesting thread. It relates to some hair-pulling I am doing over Ethernet, using WIZnet W5500 with SPI comms.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+...@bcmi-labs.cc.
Andrew Kroll
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--
You received this message because you are subscribed to the Google Groups "Developers" group.
To unsubscribe from this group and stop receiving emails from it, send an email to developers+unsubscribe@bcmi-labs.cc.
--