GC memory leak with java.lang.ref.Finalizer / BaseAnnouncementService

Austin
Austin

Sam Ottenhoff
Any instances of classes that implement the finalize() method are often called finalizable objects. They will not be immediately reclaimed by the Java garbage collector when they are no longer referenced. Instead, the Java garbage collector appends the objects to a special queue for the finalization process. Usually it's performed by a special thread called a "Reference Handler" on some Java Virtual Machines. During this finalization process, the "Finalizer" thread will execute each finalize() method of the objects. Only after successful completion of the finalize() method will an object be handed over for Java garbage collection to get its space reclaimed by "future" garbage collection. I did not say "current," which means at least two garbage collection cycles are required to reclaim the finalizable object. Sounds like it has some overhead? You got it. We need several shots to get the space recycled.
Finalizer threads are not given maximum priorities on systems. If a "Finalizer" thread cannot keep up with the rate at which higher priority threads cause finalizable objects to be queued, the finalizer queue will keep growing and cause the Java heap to fill up. Eventually the Java heap will get exhausted and a java.lang.OutOfMemoryError will be thrown.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.

Hendrik Steller
Subject: Re: [sakai-dev] GC memory leak with java.lang.ref.Finalizer
BaseAnnouncementService
Date: Donnerstag, 8. Februar 2018, 00:51:06 CET
On Mittwoch, 7. Februar 2018 21:15:09 CET Austin wrote:
> Has anyone seen anything like this? Is it a memory leak in the
> Announcement tool? Or do we need to tune our Memory settings to improve
> the GC?
If a class overrides this (AFAIK empty by default) method, it makes garbage
collection more tricky. Those objects can't be destroyed immediately when the
JVM thinks that they're ready to be garbage collected, because their
finalize()-method has to be called first.
To that end, they're stuffed into a queue and a rather low-priority
"finalizer"-thread walks by and pops elements off that queue and calls their
finalize-method.
Potential Problem 1:
Objects can be queued faster than the low-priority thread removes them.
Potential Problem 2:
People can do stupid sh*t inside their finalize() method which might delay or
block the finalizer thread; think deadlocks, infinite loops, hanging
connections [1], ..
So there seem to be a couple of basic rules regarding overriding "finalize":
1. Don't do it
2. If you do it anyway, the implementation should return quickly and naturally
not hang, so it's probably a good idea to avoid expensive stuff, stuff that
needs locking or stuff that might have to wait for network connections or
other system.
.so I did a quick grep over the Sakai 11.4 source for "void finalize" [2]
and found that Sakai seems to do all of that:
Several classes override finalize and some seem to do stuff which looks rather
dangerous for doing it in a finalize.
For example, I still had the AssignmentService open in eclipse and tried
following the calls in the finalize-implementations of one of the inner edit-
classes. This took me to
org.sakaiproject.util.BaseDbSingleStorage#cancelResource(Edit)
Without trying to really understand it or thinking it through, there seem to
be at least three things happening which would make me hesitate to call them
from an overridden finalize():
* using synchronization (accessing a hashtable in this case)
* making database calls, likely across a network in many cases
* doing something with locks; I didn't actually look if those edit locks being
released there are just some flags sakai sets in one of its own tables or if
there are "actual" db locks involved (like explicitly doing "lock table"s etc)
In case the problem occurs again, it might be worth a try to deploy a button
which calls System.runFinalization() (or just copy a "secret" JSP with a
scriplet into an existing webapp or the ROOT context and call that JSP) .
Because should the JVM start a separate finalizer thread for that call and
should the problem be that the original finalizer thread is blocked by a
single object e.g. waiting for a hanging connection and not some general
problem, then a potential second finalizer thread might be able to empty the
queue.
Regards,
Hendrik
[1]
"Fun" possibly relataed fact which I learned the hard way once:
by default, java.net.URLConnection uses an "infinite" read timeout, i.e. if
you don't take special care, your program can end up waiting forever for a
ressource which isn't available anymore.
[2]
If there's more than one match in one class file, it's likely because there
are inner classes overriding finalize() - for example, in case of the
AssignmentService, there seem to be several inner "AssignmentEdit"-classes
$> grep -r "void\s*finalize\s*(" | grep .java | grep -iv test
kernel/kernel-impl/src/main/java/org/sakaiproject/user/impl/
BasePreferencesService.java:
protected void finalize()
kernel/kernel-impl/src/main/java/org/sakaiproject/user/impl/
BaseUserDirectoryService.java: protected void finalize()
kernel/kernel-impl/src/main/java/org/sakaiproject/alias/impl/
BaseAliasService.java:
protected void finalize()
kernel/kernel-impl/src/main/java/org/sakaiproject/db/impl/
BasicSqlService.java:
protected void finalize() {
kernel/kernel-impl/src/main/java/org/sakaiproject/event/impl/
BaseNotificationService.java:
protected void finalize()
kernel/kernel-impl/src/main/java/org/sakaiproject/content/impl/
BaseContentService.java:
protected void finalize()
kernel/kernel-impl/src/main/java/org/sakaiproject/content/impl/
BaseContentService.java:
protected void finalize()
kernel/kernel-impl/src/main/java/org/sakaiproject/email/impl/
BaseDigestService.java:
protected void finalize()
message/message-util/util/src/java/org/sakaiproject/message/util/
BaseMessage.java:
protected void finalize()
message/message-util/util/src/java/org/sakaiproject/message/util/
BaseMessage.java:
protected void finalize()
assignment/assignment-impl/impl/src/java/org/sakaiproject/assignment/impl/
BaseAssignmentService.java: protected void finalize()
assignment/assignment-impl/impl/src/java/org/sakaiproject/assignment/impl/
BaseAssignmentService.java: protected void finalize()
assignment/assignment-impl/impl/src/java/org/sakaiproject/assignment/impl/
BaseAssignmentService.java: protected void finalize()
chat/chat-tool/tool/src/java/org/sakaiproject/chat2/tool/
PresenceObserverHelper.java:
protected void finalize()
providers/jldap/src/java/edu/amc/sakai/user/PooledLDAPConnection.java:
protected void
finalize() throws LDAPException {
common/archive-api/src/main/java/org/sakaiproject/importer/api/
ResetOnCloseInputStream.java: public void finalize() throws IOException{
Austin
Sam Ottenhoff
Austin

Ashley Willis
The reason this sounds really suspicious to me is that we saw something similar with a tool a year or 2 ago, I think it was Melete. The tool had a method to sanitize Strings by removing tags etc. One professor was using the tool for class photos. I don't remember all the details but it was essentially trying to process the images as Strings and running out of heap. I wonder if something similar is going on here.
We are on
Sakai 11.2
java 1.8.0_144
Tomcat 8.0.32
I don't have the GC settings handy but I can get them if needed.
Ashley
Hendrik Steller
> Creating a "secret JSP" that runs System.runFinalization() sounds
> interesting, but I might need a little help getting started with that.
ending in ".jsp" (e.g. "thats_totally_secure.jsp")
2. Copy that file into the root folder of a webapp of your choice (e.g.
tomcat/webapps/foobar)
Now you (well, and everyone else..) can call the JSP directly by opening the
URL http://server/foobar/thats_totally_secure.jsp
Or, if you copy the file into tomcat/webapps/ROOT, you can call it via
http://server/thats_totally_secure.jsp
(3.)
Delete the file again / move it out of the webapp's folder once you don't need
it anymore.
Hendrik
Code (also attached):
<%@page import="java.util.Date"%>
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%!
private static Date lastFinalize;
private static Date lastGC;
%>
<%
if ("post".equalsIgnoreCase(request.getMethod())) {
final String action = request.getParameter("whatdo");
if ("finalize".equals(action)) {
lastFinalize = new Date();
System.runFinalization();
}
else if ("gc".equals(action)) {
lastGC = new Date();
System.gc();
}
}
%>
<html>
<head><title>Top secret JSP</title></head>
<body>
<div>
<form action="" method="POST">
<span>Last manual finalize run: <%=lastFinalize != null ?
lastFinalize : "never"%></span> <input type="submit"
value="Run finalize"> <input type="hidden" name="whatdo"
value="finalize">
</form>
</div>
<div>
<form action="" method="POST">
<span>Last manual garbage collection: <%=lastGC != null ? lastGC :
"never"%></span> <input type="submit" value="Force GC">
<input type="hidden" name="whatdo" value="gc">
</form>
</div>
</body>
</html>
Austin
Austin

Matthew Buckett
Does anyone know which comes first (or how I can find out) ...if the heap fills up with Finalizer objects, then the [CMS-concurrent-reset-start] is unable to process them causing it to keep looping?Or...does the [CMS-concurrent-reset-start] fail first (for some other reason), making the heap fill up with Finalizer objects?
On Wed, Feb 7, 2018 at 4:15 PM, Austin <aust...@hawaii.edu> wrote:
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
Systems and Applications, Technology Enhanced Learning
IT Services, University of Oxford
13 Banbury Road, OX2 6NN
Tel: 01865 283349
Austin
Matthew Jones
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--Matthew Buckett, Senior VLE Developer
Systems and Applications, Technology Enhanced Learning
IT Services, University of Oxford
13 Banbury Road, OX2 6NN
Tel: 01865 283349
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
Austin
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--Matthew Buckett, Senior VLE Developer
Systems and Applications, Technology Enhanced Learning
IT Services, University of Oxford
13 Banbury Road, OX2 6NN
Tel: 01865 283349
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
Austin
Austin
Hendrik Steller
On Freitag, 9. Februar 2018 20:28:04 CET Austin wrote:
> Another thing I was wondering is if Announcements get loaded into memory
> whenever a user is added into memory? The reason I ask is because, we have
> a site that has 30,000 users, which includes a ton of "old" users. (which
> I've also been suspicious of in the past causing problems) And since some
> of the Announcements I inspected were also 'old'... this is kind of a leap,
> but is there any chance that even though these old users are not actually
> logging in, but they are somehow getting loaded into memory (suspect that
> if one person logs in and views that 30K site, every user from that site
> will also be loaded into mem.), are announcements they would have been
> seeing also getting loaded into memory?
I don't think so; sounds rather unlikely.
Also, I just had a look by enabling the mysql general query log for my local development sakai instance and then:
started the server,
logged in with an admin account,
clicked a bit around the announcements tool in my Home site,
went to a course site,
looked at the announcements,
edited one until "preview,
canceled the preview,
logged out of sakai without canceling the edit and
shut down the server again.
Only a few queries were made which included "%announcement%" and nothing of that looked like what you were suspecting (see queries below) ; then again, your setup, tools, customizations etc are going to be different.
I also didn't find what I was suspecting (or not really suspecting because I hadn't found any evidence of it happening in the code) and actually looking for:
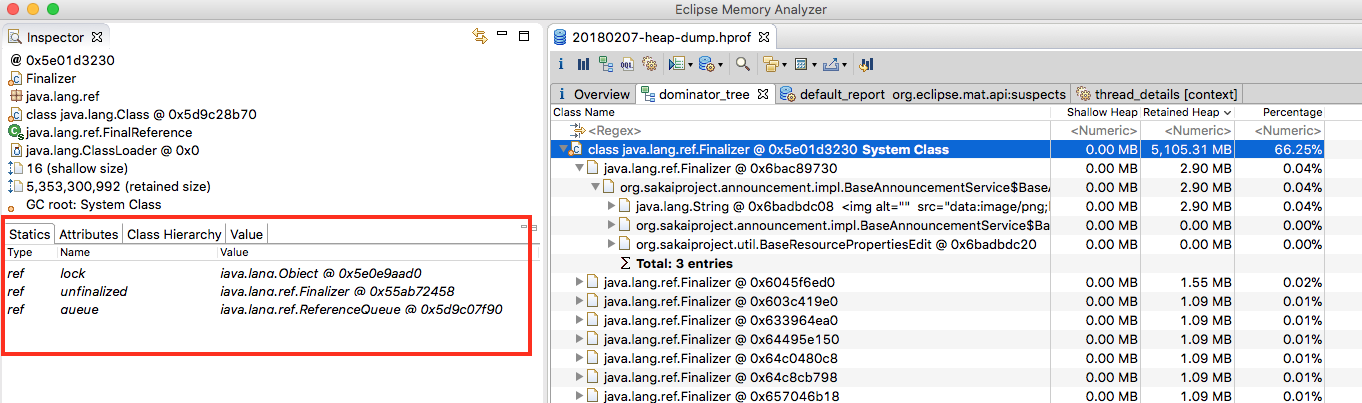
In your screenshots, those were "edit"-objects which were waiting for finalization. That seems like there's more happening than e.g. a user or a search engine's crawler opening and reading an old announcement.
I found ~160 four abandoned records which never got cleaned up in my sakai_locks table with the oldest ones from February 2014.
That made me wonder if something could be loading all entries from that locks table and create "ancient" edit objects for those records that way, e.g. for prefilling a local cache or something cleanup-related.
But according to the query log, this doesn't happen; at least not on my one-tomcat-no-distributed-caching notebook without any quartz jobs.
If I were really interested in where those old announcement edits are originating from, I would go into the announcement service where those edit objects for announcements are being created and then add something like
if (switchToEnableThis && "thatOldAnnouncementsId".equals(announcementId)) {
dumpRequestAndSessionInfo();
throwAndCatchSomeDummyExceptionAndLogItsStacktrace();
notifyMe();
}
Regards
Hendrik
-------
Query log:
MariaDB [sakai11]> select argument from mysql.general_log where argument like '%announcement%' and argument not like '%mysql.general_log%' and command_type!= 'Prepare';
| CREATE TABLE ANNOUNCEMENT_CHANNEL ( CHANNEL_ID VARCHAR (255) NOT NULL, NEXT_ID INT, XML LONGTEXT ) |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/!site/motd' ) |
| select XML from ANNOUNCEMENT_MESSAGE where (CHANNEL_ID = '/announcement/channel/!site/motd' and DRAFT = '0') order by MESSAGE_DATE desc |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/~hsteller/main' ) |
| select XML from ANNOUNCEMENT_MESSAGE where (CHANNEL_ID = '/announcement/channel/~hsteller/main' )order by MESSAGE_DATE asc |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' )
| select XML from ANNOUNCEMENT_MESSAGE where (CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' )order by MESSAGE_DATE asc
| select SAKAI_ALIAS.ALIAS_ID,SAKAI_ALIAS.TARGET,SAKAI_ALIAS.CREATEDBY,SAKAI_ALIAS.MODIFIEDBY,SAKAI_ALIAS.CREATEDON,SAKAI_ALIAS.MODIFIEDON from SAKAI_ALIAS where TARGET = '/announcement/ann
ouncement/30f49e34-5224-49aa-9099-9f11fa490654' order by SAKAI_ALIAS.ALIAS_ID |
| select SAKAI_ALIAS.ALIAS_ID,SAKAI_ALIAS.TARGET,SAKAI_ALIAS.CREATEDBY,SAKAI_ALIAS.MODIFIEDBY,SAKAI_ALIAS.CREATEDON,SAKAI_ALIAS.MODIFIEDON from SAKAI_ALIAS where TARGET = '/announcement/ann
ouncement/30f49e34-5224-49aa-9099-9f11fa490654' order by SAKAI_ALIAS.ALIAS_ID |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' )
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) |
| select XML from ANNOUNCEMENT_MESSAGE where (CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' )order by MESSAGE_DATE asc |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) |
| select XML from ANNOUNCEMENT_MESSAGE where (CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' )order by MESSAGE_DATE asc |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) |
| select XML from ANNOUNCEMENT_MESSAGE where (CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) and ( MESSAGE_ID = 'f419dcea-72ef-4e8b-8f63-3a98b969628a' )
|
| select XML from ANNOUNCEMENT_MESSAGE where (CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) and ( MESSAGE_ID = 'f419dcea-72ef-4e8b-8f63-3a98b969628a' )
|
| insert into SAKAI_LOCKS (TABLE_NAME,RECORD_ID,LOCK_TIME,USAGE_SESSION_ID) values ('ANNOUNCEMENT_MESSAGE', '1275768022 - /announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main/f41
9dcea-72ef-4e8b-8f63-3a98b969628a', TIMESTAMP'2018-02-09 21:29:56.459000', 'd78979c3-f937-48a9-8edc-bcad916955f6') |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) |
| select count(1) from SAKAI_REALM_RL_FN,SAKAI_REALM force index (AK_SAKAI_REALM_ID) where SAKAI_REALM_RL_FN.REALM_KEY = SAKAI_REALM.REALM_KEY and SAKAI_REALM.REALM_ID IN ('/announcement/c
hannel/30f49e34-5224-49aa-9099-9f11fa490654/main','/site/30f49e34-5224-49aa-9099-9f11fa490654','!site.helper') and FUNCTION_KEY in (select FUNCTION_KEY from SAKAI_REALM_FUNCTION where FUNCT
ION_NAME = 'annc.read') and (ROLE_KEY in (select ROLE_KEY from SAKAI_REALM_RL_GR where ACTIVE = '1' and USER_ID = NULL and REALM_KEY in (select REALM_KEY from SAKAI_REALM where SAKAI_REA
LM.REALM_ID IN ('/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main','/site/30f49e34-5224-49aa-9099-9f11fa490654','!site.helper'))) or ROLE_KEY in (1) ) |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) |
| select XML from ANNOUNCEMENT_CHANNEL where ( CHANNEL_ID = '/announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main' ) |
| delete from SAKAI_LOCKS where TABLE_NAME = 'ANNOUNCEMENT_MESSAGE' and RECORD_ID = '1275768022 - /announcement/channel/30f49e34-5224-49aa-9099-9f11fa490654/main/f419dcea-72ef-4e8b-8f63-3a9
8b969628a'
Matthew Jones
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--Matthew Buckett, Senior VLE Developer
Systems and Applications, Technology Enhanced Learning
IT Services, University of Oxford
13 Banbury Road, OX2 6NN
Tel: 01865 283349
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
Austin
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--Matthew Buckett, Senior VLE Developer
Systems and Applications, Technology Enhanced Learning
IT Services, University of Oxford
13 Banbury Road, OX2 6NN
Tel: 01865 283349
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
Austin
Austin
Hendrik Steller
Hi Austin,
after glancing over
I would take a closer look at those;
On Mittwoch, 28. Februar 2018 03:47:54 CET Austin wrote:
> | 5,780 | 0 | com.novell.ldap.LDAPConnection
Because:
a)
zero-versus-anything
Doesn't have to mean anything, but being the only one, it it looks a bit suspicious
b)
It does something over the network, i.e. there's a chance of something hanging
c)
To add to b) by looking at the source linked above:
unless explicitly told otherwise, that class use "0" as the default timeout for the sockets it opens
d)
Among other fun things - like potentially making the finalizer-Thread waiting to join() another thread[1] - it also does this in its finalize() method [2]:
while( true ) {
try {
extending_vector_ie_heavily_synchronized.remove(0);
}
catch( ArrayIndexOutOfBoundsException ex) {
break;
}
}
It might be worth to add some debug message at the begin and end of that class's finalize method and see if/when it doesn't leave.
Or maybe change the default socket timeout from 0ms to something like 5 minutes and see what happens.
Hendrik
[1]
[2]

Mark Triggs
Hi Austin,
Have you been able to get a thread dump out of Tomcat when it has run out of memory? I think that might be the missing piece here (I read back through the archives and didn't see one, but apologies if I missed it).
When an object with a finalize() method is to be garbage collected, a java.lang.ref.Finalizer object is created for it and added to a queue. That queue is processed by a "Finalizer" background thread, which takes care of running the appropriate finalize() method for each of those objects.
All it takes is for one object to have a badly implemented finalize() method for the whole thing to come crashing down. As a perverse example, creating an object with a method like:
class UhOh {
protected void finalize() throws Throwable {
while (true) {}
}
}is going to permanently lock up that Finalizer thread. At that point you're leaking memory and it's only a matter of time until you get an OOM error (which may take a while to manifest if you're running with a large heap).
The important thing here is that the counts of objects waiting to be finalized don't necessarily tell you the root cause—there may just be millions of ready-to-be-collect object stuck behind a single bad object, so you've got to find the needle in the haystack. My above example is a bit contrived, but I've seen this happen with single LDAP connections deadlocking, for instance.
If you can get a thread dump from the JVM, that will let you see what the Finalizer thread is actually doing, and hopefully give a hint as to what's blocking the queue. While the JVM is running, you can do:
kill -3 <java pid>and it will log a thread dump to your catalina.out file. Look for an entry called "Finalizer"--something like this:
"Finalizer" #3 daemon prio=8 os_prio=0 tid=0x00007faac04d9000 nid=0x347a in Object.wait() [0x00007faaadf15000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.$$YJP$$wait(Native Method)
at java.lang.Object.wait(Object.java)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)
- locked <0x00000000800466d0> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)Mine's currently doing nothing, which in a healthy system is probably a good thing. If yours looks different, try running multiple thread dumps a few seconds apart and see how they change. That should give more an idea of where that thread is spending its time.
Cheers,
Mark
Austin <aust...@hawaii.edu> writes:
Hello All,
Sorry to keep bugging you all with this problem. But here's some additional info from our heap dumps.
After comparing the java.lang.ref.Finalizer object between a bad and a normal heap dump (e.g. when the system is running normally), the number objects retained in Finalizer is inflated by the thousands (note these are just a handful of objects, I haven't listed them all). However, that makes sense because Sam Ottenhoff said,
*"If a "Finalizer" thread cannot keep up with the rate at which higher priority threads cause finalizable objects to be queued, the finalizer queue will keep growing and cause the Java heap to fill up. Eventually the Java heap will get exhausted and a java.lang.OutOfMemoryError will be thrown"*
However, we don't have an OutOfMemoryError when this happens, the GC just keeps looping over and over, but you can see below how many more objects are in the Finalizer when the problem happens.
+-----------+----------+------------------------------------ ----------------------------------------------------+ | BAD GC | GOOD GC | | #objects | #objects | Class +-----------+----------+------------------------------------ ----------------------------------------------------+ | 245,941 | 18,875 | org.sakaiproject.announcement.impl.BaseAnnouncementService$BaseAnnouncementMessageEdit | 2,171,252 | 6,289 | org.sakaiproject.content.impl.BaseContentService$BaseCollectionEdit | 444,086 | 2,443 | org.sakaiproject.content.impl.BaseContentService$BaseResourceEdit | 248,318 | 200 | java.util.zip.ZipFile\$ZipFileInputStream | 246,652 | 1,715 | java.util.zip.Inflater | 248,030 | 200 | java.util.zip.ZipFile\$ZipFileInflaterInputStream | 242,115 | 207 | sun.net.www.protocol.jar.URLJarFile | 39,572 | 18 | com.sun.crypto.provider.PBEKey | 341,342 | 3,236 | java.util.jar.JarFile | 103,226 | 57,231 | org.sakaiproject.user.impl.BaseUserDirectoryService$BaseUserEdit | 92,685 | 49 | java.io.FileInputStream | 5,780 | 0 | com.novell.ldap.LDAPConnection | 67,453 | 11 | org.apache.commons.fileupload.disk.DiskFileItem +-----------+----------+------------------------------------ ------------------------------------------------------+
The 2 million org.sakaiproject.content.impl.BaseContentService$BaseCollectionEdit objects above seemed suspicious, so looking into *that* object, there were 400K+ instances each of Content Collection objects that referenced "/" and "/group/". And normal site references seemed to have 1000s of references more than usual. (see screenshots). However, I wouldn't know if these increased number of "/" and "/group/" objects is *CAUSING* the Finalizer to keep growing, or if it's a *SYMPTOM* of it growing.
We also tried adding these to our JAVA config, but the problem still happened (I didn't get a chance to take a heap dump when the prob. happened with these settings)
-XX:CMSMaxAbortablePrecleanTime=10000
-XX:+CMSScavengeBeforeRemarkThanks,
Austin
-- Mark Triggs <ma...@dishevelled.net>
Mark Triggs
Hi Hendrik,
I see our last messages crossed in the post :) Just to note: NYU had issues with exactly this code, where LDAP connections would deadlock in their finalize method waiting on another thread.
NYU is now running Sam's Unboundid LDAP implementation from here:
https://github.com/sakaiproject/sakai/pull/1924
with the modifications described further down in that PR thread.
Mark
Hendrik Steller <sa...@stellers.net> writes:
Hi Austin,
after glancing over
http://grepcode.com/file/repo1.maven.org/maven2/com.novell.ldap/jldap/4.3/com/ novell/ldap/LDAPConnection.java
I would take a closer look at those;
-- Mark Triggs <ma...@dishevelled.net>
Hendrik Steller
> Hi Hendrik,
>
> I see our last messages crossed in the post :)
:)
>> Just to note: NYU had
> issues with exactly this code, where LDAP connections would deadlock in
> their finalize method waiting on another thread.
seems to wait for forever via join() without at timeout..
.happens to be the one waiting for responses from the LDAP server on that
socket without a timeout by default.
So changing the default timeout or adding one to the join()-call at
http://grepcode.com/file/repo1.maven.org/maven2/com.novell.ldap/jldap/4.3/com/
novell/ldap/Connection.java#986
might improve things, too.
Hendrik
Austin

Earle Nietzel
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
Austin
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
Earle Nietzel
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
Austin
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.

Alex Balleste
Hi, everyone. We've been experimenting those memory leak. We discovered using YourKit that the problem is the same Austin described in the previous emails. We have a lot of objects org.sakaiproject.announcement.impl.BaseAnnouncementService$BaseAnnouncementMessageEdit . They are pending to finalize. I've been seeing the content of those announcements, and they are really old. That, made me think those messages are loaded when somebody access to the Workspace announcements tool and loads all the messages (we had multiple sites that are available for l all students and had announcements since 2008).
There are some announcement specially big, (they use base64
images embeded) and java retains arround 2MB for each object. That
makes that we rapidly gather 4GB of memory just for announcements
when a lot of users access to the announcements tool.
I was wondering if anyone found the solution for this problem
Thanks in advance.
Àlex
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
-- Alexandre Ballesté Crevillén alexandre.balleste at udl.cat ==================== Universitat de Lleida Àrea de sistemes d'Informació i Comunicacions Analista/Programador University of Lleida Information and Communication Systems Service Tlf: +34 973 702148 Fax: +34 973 702130 ===================== Avís legal / Aviso legal / Avertiment legal / Legal notice <http://www.imatge.udl.cat/avis_legal_lopd.html>

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Stephen Marquard
With Longsight’s help, we recently resolved (we think) an issue with GC related to Finalizers by switching from the default JLDAP provider to the new unboundid LDAP provider.
https://jira.sakaiproject.org/browse/SAK-23630
Before that, we would see one or two app servers run out of memory and into excessive, repeated Full GCs every week. Since that change, it hasn’t happened again.
Regards
Stephen
---
Stephen Marquard, Learning Technologies Co-ordinator,
Centre for Innovation in Learning and Teaching (CILT)
University of Cape Town
http://www.cilt.uct.ac.za
stephen....@uct.ac.za
Phone: +27-21-650-5037 Cell: +27-83-500-5290
From: saka...@apereo.org <saka...@apereo.org>
On Behalf Of Alex Balleste
Sent: 19 September 2018 02:30 PM
To: Sakai Development <saka...@apereo.org>; aust...@hawaii.edu; sa...@stellers.net
Subject: Re: [sakai-dev] GC memory leak with java.lang.ref.Finalizer / BaseAnnouncementService
Hi, everyone. We've been experimenting those memory leak. We discovered using YourKit that the problem is the same Austin described in the previous emails. We have a lot of objects org.sakaiproject.announcement.impl.BaseAnnouncementService$BaseAnnouncementMessageEdit . They are pending to finalize. I've been seeing the content of those announcements, and they are really old. That, made me think those messages are loaded when somebody access to the Workspace announcements tool and loads all the messages (we had multiple sites that are available for l all students and had announcements since 2008).
There are some announcement specially big, (they use base64 images embeded) and java retains arround 2MB for each object. That makes that we rapidly gather 4GB of memory just for announcements when a lot of users access to the announcements tool.
I was wondering if anyone found the solution for this problem
Thanks in advance.
Àlex
Alex Balleste
Do you think both problems are related, LDAP and Announcements?. Is LDAP preventing in some way to finalize those BaseAnnouncementEdit Objects? I would try it because we are using LDAP provider too.
Thanks.
Àlex
Disclaimer - University of Cape Town This email is subject to UCT policies and email disclaimer published on our website at http://www.uct.ac.za/main/email-disclaimer or obtainable from +27 21 650 9111. If this email is not related to the business of UCT, it is sent by the sender in an individual capacity. Please report security incidents or abuse via https://csirt.uct.ac.za/page/report-an-incident.php. --
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
Stephen Marquard
Hi Àlex,
The analysis of heap dumps and thread dumps taken when the server was in extreme low-memory conditions suggested that the finalizer queue was being blocked by JLDAP objects, so the GC was never able to run the finalizers and thus free up the BaseAnnouncementEdit objects.
Sam Ottenhof from Longsight may be able to explain that better.
Hendrik Steller
if I recall the problem and the LDAP code I looked at correctly, the problem
is that there's by default only one finalizer-thread for all objects in the
JVM.
So due to Sakai#s inner workings, there might be a ton of announcements queued
up and waiting to have their finalize()-method called, but the object
actually blocking the finalizer thread from doing its work might be something
completely unrelated to all those announcements.
I vaguely remember seeing some rather suspicious code in the finalize()-
methods of the LDAP libraries being used - it might have been something along
the lines of opening a connection to the LDAP server with Java's default URL
connection settings, i.e. with the connection timeouts set to "unlimited",
which means that. this code and thus the finalizer thread will hang forever if
it can't reach the LDAP server for whatever reason in that exact moment.
Hendrik
On Wednesday, 19 September 2018 14:57:42 CEST Alex Balleste wrote:
> Do you think both problems are related, LDAP and Announcements?. Is LDAP
> preventing in some way to finalize those BaseAnnouncementEdit Objects? I
> Thanks.
>
> Àlex
>
> El 19/09/18 a les 14:34, Stephen Marquard ha escrit:
> > With Longsight’s help, we recently resolved (we think) an issue with
> > GC related to Finalizers by switching from the default JLDAP provider
> > to the new unboundid LDAP provider.
> >
> > https://jira.sakaiproject.org/browse/SAK-23630
> >
> > Before that, we would see one or two app servers run out of memory and
> > into excessive, repeated Full GCs every week. Since that change, it
> > hasn’t happened again.
> >
> > Regards
> >
> > Stephen
> >
> > ---
> > Stephen Marquard, Learning Technologies Co-ordinator,
> > Centre for Innovation in Learning and Teaching (CILT)
> > University of Cape Town
> > stephen....@uct.ac.za <mailto:stephen....@uct.ac.za>
> > Phone: +27-21-650-5037 Cell: +27-83-500-5290
> >
> > *From:*saka...@apereo.org <saka...@apereo.org> *On Behalf Of *Alex
> > Balleste
> > *Sent:* 19 September 2018 02:30 PM
> > *To:* Sakai Development <saka...@apereo.org>; aust...@hawaii.edu;
> > sa...@stellers.net
> > *Subject:* Re: [sakai-dev] GC memory leak with java.lang.ref.Finalizer
Alexandre Ballesté
blocked. Thanks for the infomation.
Àlex.
El 19/9/18 a les 15:24, Hendrik Steller ha escrit:
Earle Nietzel
private int writeSemaphoreOwner = 0;
...
synchronized( writeSemaphore) {
if( id == 0) {
ephemeralId = ((ephemeralId == Integer.MIN_VALUE)
? (ephemeralId = -1) : --ephemeralId);
id = ephemeralId;
}
while( true) {
if( writeSemaphoreOwner == 0) {
// we have acquired the semahpore
writeSemaphoreOwner = id;
break;
} else {
if( writeSemaphoreOwner == id) {
// we already own the semahpore
break;
}
try {
// Keep trying for the lock
writeSemaphore.wait();
continue;
} catch( InterruptedException ex) {
// Keep trying for the lock
continue;
}
}
}
writeSemaphoreCount++;
}
private volatile int writeSemaphoreOwner = 0;
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Austin
> > stephen....@uct.ac.za <mailto:stephen.marquard@uct.ac.za>
> > an email to sakai-dev+unsubscribe@apereo.org
> > <mailto:sakai-dev+unsubscribe@apereo.org>.
> > To post to this group, send email to saka...@apereo.org
> > <mailto:saka...@apereo.org>.
> > Visit this group at
> > https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
Alex Balleste
Hi, thanks for all that information. I'll definitively go to the
new unboundid LDAP provider. It's true that in the logs I can see
problems about semaphores related with LDAP.
Thanks again.
Àlex.
Earle Nietzel
> > stephen....@uct.ac.za <mailto:stephen....@uct.ac.za>
> > an email to sakai-dev+...@apereo.org
> > <mailto:sakai-dev+...@apereo.org>.
> > To post to this group, send email to saka...@apereo.org
> > <mailto:saka...@apereo.org>.
> > Visit this group at
> > https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+...@apereo.org.
Alex Balleste
Well, we've applied the LDAP provider implementation as you
suggested and it really improved the system behavior. It has been
running for a week and the number of GC alerts decreased
drastically.
Àlex.
PS. It would be nice to have the new provider in the next 12 release too.
Austin
> > stephen....@uct.ac.za <mailto:stephen.marquard@uct.ac.za>
> > an email to sakai-dev+unsubscribe@apereo.org
> > <mailto:sakai-dev+unsubscribe@apereo.org>.
> > To post to this group, send email to saka...@apereo.org
> > <mailto:saka...@apereo.org>.
> > Visit this group at
> > https://groups.google.com/a/apereo.org/group/sakai-dev/.
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
-- Alexandre Ballesté Crevillén alexandre.balleste at udl.cat ==================== Universitat de Lleida Àrea de sistemes d'Informació i Comunicacions Analista/Programador University of Lleida Information and Communication Systems Service Tlf: +34 973 702148 Fax: +34 973 702130 ===================== Avís legal / Aviso legal / Avertiment legal / Legal notice <http://www.imatge.udl.cat/avis_legal_lopd.html>--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
To post to this group, send email to saka...@apereo.org.
Visit this group at https://groups.google.com/a/apereo.org/group/sakai-dev/.
-- Alexandre Ballesté Crevillén alexandre.balleste at udl.cat ==================== Universitat de Lleida Àrea de sistemes d'Informació i Comunicacions Analista/Programador University of Lleida Information and Communication Systems Service Tlf: +34 973 702148 Fax: +34 973 702130 ===================== Avís legal / Aviso legal / Avertiment legal / Legal notice <http://www.imatge.udl.cat/avis_legal_lopd.html>
--
You received this message because you are subscribed to the Google Groups "Sakai Development" group.
To unsubscribe from this group and stop receiving emails from it, send an email to sakai-dev+unsubscribe@apereo.org.
{kind=link}
{kind=link}