posting photo(s)

S. Douglass
yet another thread about this. I've tried to scour all the existing
threads and examples but things are still not entirely clear to me. I
was hoping that folks could settle a couple points of confusion for
me. It'd be great to have these details made plain, and not in example
code, so that anybody can look at it without having to know
programming language X or Y or Z.
1. Content-type - is it application/x-www-form-urlencoded or multipart/
form-data ???
2. How is the OAuth signature generated? The same as for every other
API call? Or differently? The Twitter documentation for their upload
API call (which looks to be using multipart/form-data) indicates that
the OAuth signature is generated differently in that case:
https://dev.twitter.com/discussions/1059
3. The binary data is supposed to be turned into a string then
encoded. Is it Base64 encoded? URL query parameter encoded? Both?
4. The parameter names, are they supposed to be named "data[0]",
"data[1]", "data[2]", etc? If I'm sending just one file do I use
"data" or "data[0]"?
I have looked at both the example gists on GitHub mentioned in
elsewhere here but it isn't clear to me from the comments if they
actually work, and also I'm not familiar with Python, so I'm not
really sure I'm interpreting the code 100% correctly. So I'm just
hoping for some non-code details about how it works. Thanks!

Steven Pears
concise post - so I suggest we keep all photo/photoset posting to here
from now.
So far my requests have been url-encoded form requests, and the
parameter names have been in the data[0] format. Because these aren't
multi-part requests they're signature'd in the same way as the other
requests.
The one issue I've had so far is that even if these points are
followed, I then get an "error saving photo" message - indicating that
it's point 3 I'm getting wrong; I'm encoding the photo incorrectly.
Hope this moves us forward a little.
Steven
Steven Pears

Federico Carlos Erostarbe Candamil
I'm going mad in Objective-C and haven't managed to nailed it yet.

mohacs
hello everyone,
photo is not only the problem...
when i upload a mp3 file it returns
{"meta":{"status":201,"msg":"Created"},"response":{"id":12967144041}}
Also the post appear on my blog however when i play it no audio.
it is same for video as well..
when i upload a video file it returns.
{"meta":{"status":201,"msg":"Created"},"response":{"id":12967187657}}
but video didn't even appear on my blog,
i was creating iPhoto / Finder plug-ins and universal IOS application but until they came back with reasonable documentation i will give up because this became pain.
many thanks.

John Bunting
mohacs
John Bunting
mohacs
mohacs
S. Douglass
anyone looking at this thread in the future, you're saying:
1. The Content-type should be application/x-www-form-urlencoded
2. The OAuth signature is generated the same way as for the other API
calls
3. ???
4. The parameter names should be "data[0]", "data[1]", etc. even if
there is just one photo (so with one photo, you would use "data[0]")
So the remaining issue is, how are the binary data encoded? Or maybe
rather, how are the binary data turned into characters in a string?
(It seems like if the data are passed as request parameters in an
application/x-form-urlencoded POST they should be URL encoded. But URL
encoding raw bytes doesn't seem to make sense to me, so I assume the
problem we're really having is figuring out how to turn the bytes into
a string?)
I really appreciate your response Steve. I also appreciate that lots
of people are having issues with this. It might be better for people
referring to this thread in the future though if we really tried to
stay focused on this one topic and resolving these specific details.
Most likely once we figure out how to get this to work for one binary
type we can reuse the approach for video, audio, etc.
Steven Pears
I get an error in the request, when these are set up that way I end up
just with a tumblr response, the meta containing the error about
unable to save the photo.
This is why I keep referring to the test image I've been using - I'm
sure if we could get a sample of a correctly encoded, small, image -
from another dev or from Tumblr - we could just keep looking at our
own languages until it matched and finally tick that last box.
But no matter what I try I just can't get it right.
S. Douglass
the Tumblr folks and the raw post made by my (Java) code here:
Two things are different that I see. The binary data in the request is
encoded differently (it starts with "%FF%D8%FF" in the Python version
and "%EF%BF%BD" in my version). Probably more significant is that the
oauth_signature value has an "=" in the Python version but it's been
escaped to "%3D" in the oauth_signature value in my version. Perhaps
that's the root of the problem with my posts...?
Steven Pears
post - this should be the bit that really turns it!
I've got real life stuff getting in the way a little bit this morning,
but I'll get on replicating this in C# soon as I've got chance.
Just to confirm - is this with the same test image?
S. Douglass
earlier:
http://www.convr.co.uk/test.jpg
Steven Pears
I see the problem I've been having - this is a raw dump, a byte at a
time - all the Base64/URL encoding systems I've been using have
assumed the text would be handled in a double-byte format like UTF-8.
This shouldn't be difficult to sort out at all!
Right, real-life beckons.
Steven Pears
data at a time, then convert that number to hex and place "%" +
hexConversion into the string.
It looks like there's a special case where if it's a space character
it's getting replaced by the + sign, but I'm still working on that.
I can get the string, the issue now is that because it's url-encoded
data, my OAuth library is (quite correctly in my opinion) trying to
encode the string I've just generated. So this causes problems.
I've contacted the author to ask if there's an encoding option we can
add, but in the mean time I'm looking at working backwards to where I
need to be.
This is a lot of messing around compared to a multi-part request or
base64 encoding, it really is, but I feel like it's progress at least.
Steven Pears
but on a single-byte at a time read of the file.
This is a bit of a problem. If you're using a library (I guess most
people aren't implementing their own OAuth code) then most of that
code is going to be assuming double-byte encoding, probably UTF-8.
If you change the encoding of the request, then you're limiting the
characters that can be entered into the text-based fields - and
therefore the language you can say you support. Normally it's UTF-8 so
it handles pretty much anything you can throw at it.
I would be interested in the other languages, because for me this may
end up being a show stopper. UTF-8 is so standard across the web that
Silverlight/Windows Phone 7 doesn't implement a single-bye encoding. I
may have to try and implement codepage 1252 (the most likely encoding
candidate) myself so that my OAuth library can handle it.
Does anyone have any idea why UTF-8 is accceptable on every other call
in this API, but not on the binary URL encoding? No wonder we've been
having trouble.
Steven

wyvern
http://groups.google.com/group/tumblr-api/browse_thread/thread/16f1131f825a8d81
>If sending parameters in the application/www-form-urlencoded in the
>body of request. One big problem come arise when posting photo(binary
>values?),
>Those parameters has to be included in the process of generating
>signature base string of OAuth.
>The problem is most OAuth client libarary expects to takes parameters
>as *string* or treats them as *string* internally. so when signing
>request,
>those binary paramaters are handled incorrectly(that is, UTF8 encoding
>are applied to those binary parameters incorrectly).
most OAuth library expects to takes parameters as string(that is input
parameters is declared as string type).
so binary parameters can't passed directly :(
of course, if u url-encoded binary parameters to string, pass it as
input parameters, this causes wrong result.
Steven Pears
Guess this is the bigger question to put forward to the Tumblr team
then:
How can we post a photo into API V2 while still using UTF-8 encoding?
This is one I would really like the Tumblr guys to get back to us on!
Steven Pears
wyvern
Although I don't know which OAuth library u are using, When passsing
parameters to your OAuth library, u always need to pass them as
string(in case of C#, string type(UTF16-Unicode)) right??
There's no overloaded method to pass them as Byte array or Stream
class?
if theres no such methods, ur oauth library can't handle binary
values(photo data) correctly.
This is what i mean by "most OAuth library expects to takes parameters
as string".
In this case, If convert binary value(photo) to string using
urlencoding by force and passing it as string to your oauth library,
this result in wrong singature.
because converted data is ***again*** encoded using UTF8 internally in
OAuth library u using.
Look at section 3.6. Percent Encoding in RFC5849 http://tools.ietf.org/html/rfc5849.
It says 1. Text values are first encoded as UTF-8 octets per
[RFC3629] if
they are not already. This does not include binary values that
are not intended for human consumption.
Your OAuth library handle all parameters as Text values and can't
distinguish which Text values and Binary values.
umm. can't explain well.
Steven Pears
I see what you mean - my library assumes files will be sent via multi-
part form data, so yes - you're spot on.
Steven
S. Douglass
default encoding is for Python on my system it says "ascii". Even if I
tell my Java code to read in the file data and convert it to a string
using ASCII, that string will then be converted to UTF-8 by the
library I'm using before being percent encoded, as per Section 3.6. So
I guess I am out of luck.
I suppose I could try to bypass the library I'm using and try to
figure out how to make sure the binary data never gets UTF-8 encoded?
It would be really great if the Tumblr API supported multipart POSTs
like Twitter's API.
Steven Pears
Tumblr team: is there any chance binary API calls, or right now this one call, could be changed to accept either multi-part or UTF-8 requests?
From: S. Douglass
Sent: 21/11/2011 06:23
To: Tumblr API Discussion
Subject: Re: posting photo(s)
wyvern
so OAuth library itself needs to distinguish between Text and Binary
values, that is,
for example, It needs to hold binary values as Byte array for Binary
values internally in addition to String for Text values.
This is what i mean by "most OAuth client libarary expects to
treats(handle) them as *string* internally".
My own OAuth implemetation also was one of such libraries.
But Adapting it to support binary values is not so hard job.
Steven Pears
problem. The library I use DOES handle binary data, it handles it the
way the internet has accepted you handle binary data by default, by
creating a multi-part form request!
This way it's able to handle the binary data in a way which is
specifically built to do so in a common, easy to read and pretty
efficient format.
By asking for the data to be submitted through a url-encoded request,
you are asking the system to assume the data is a string. In that case
the most accepted practice is that you fallback to what other systems
do for such a decision and Base64 encode the data. Suddenly you're ok
for web services and emails and other text-based systems that need to
handle binary. I'd have no problems whatsoever with this decision.
Instead the system is relying on a single-byte encoding of the binary
data, a very arbitary approach, and I don't believe it's acceptable to
punch a hole into each OAuth provider for this when most OAuth
libraries and developers do have to work with multiple social
networks, and this is the only one that asks it's devs to do so.
S. Douglass
about how you adapted your OAuth library to support binary data? The
binary data has to be encoded somehow, to be used in the OAuth
signature base string, and to go into the request body. It's still not
clear to me what the encoding schemes are for those cases for binary
data. If I know what the encoding schemes are I can try to hack them
in to my OAuth library.
Mohac Bilecen
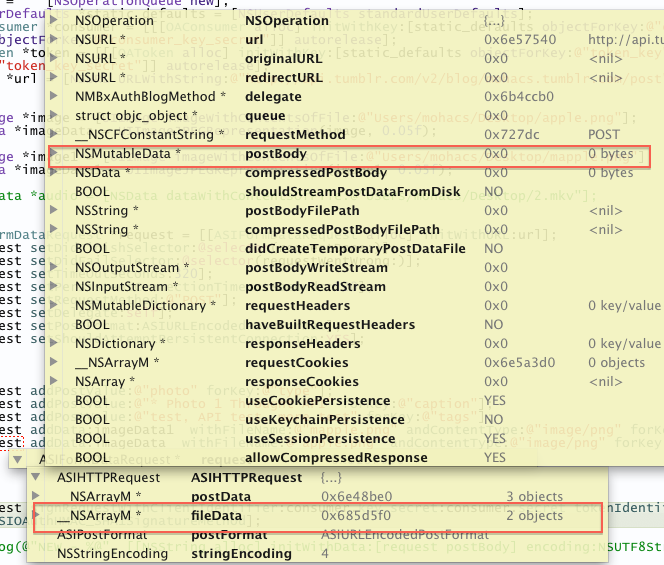
- (void)appendPostDataFromFile:(NSString *)file
{
[self setupPostBody];
NSInputStream *stream = [[[NSInputStream alloc] initWithFileAtPath:file] autorelease];
[stream open];
NSUInteger bytesRead;
while ([stream hasBytesAvailable]) {
unsigned char buffer[1024*256];
bytesRead = [stream read:buffer maxLength:sizeof(buffer)];
if (bytesRead == 0) {
break;
}
if ([self shouldStreamPostDataFromDisk]) {
[[self postBodyWriteStream] write:buffer maxLength:bytesRead];
} else {
[[self postBody] appendData:[NSData dataWithBytes:buffer length:bytesRead]];
}
}
[stream close];
}
Mohac BILECEN
S. Douglass
encoded.
http://stackoverflow.com/questions/7405655/how-to-urlencode-an-actionscript-bytearray
If I turn the test file's bytes into a string using Latin 1, then use
Latin 1 when URL encoding, I wind up with the same string
representation of the file ("%FF%D8%FF...") as the Python code. So I
guess for any request involving binary data I have to kludge things to
use Latin 1 encoding all the way through, instead of UTF-8/ASCII...?
Steven Pears
The fact you're using data[1] makes it look like it's not a 0-based array, that would have caused me trouble!
Will attempt implementing this tonight, thank you!!
Sent from my Windows Phone
From: Mohac Bilecen
Sent: 21/11/2011 16:53
To: tumbl...@googlegroups.com
Subject: Re: posting photo(s)
- (void)appendPostDataFromFile:(NSString *)file
{
[self setupPostBody];
NSInputStream *stream = [[[NSInputStream alloc] initWithFileAtPath:file] autorelease];
[stream open];
NSUInteger bytesRead;
while ([stream hasBytesAvailable]) {
unsigned char buffer[1024*256];
bytesRead = [stream read:buffer maxLength:sizeof(buffer)];
if (bytesRead == 0) {
break;
}
if ([self shouldStreamPostDataFromDisk]) {
[[self postBodyWriteStream] write:buffer maxLength:bytesRead];
} else {
[[self postBody] appendData:[NSData dataWithBytes:buffer length:bytesRead]];
}
}
[stream close];
}
Wyvern, thanks for the information. Do you have any specific details
about how you adapted your OAuth library to support binary data? The
binary data has to be encoded somehow, to be used in the OAuth
signature base string, and to go into the request body. It's still not
clear to me what the encoding schemes are for those cases for binary
data. If I know what the encoding schemes are I can try to hack them
in to my OAuth library.
On Nov 21, 5:37 am, wyvern <wyvern1...@gmail.com> wrote:
> OAuth 1.0 spec itself support binary values.
>
> so OAuth library itself needs to distinguish between Text and Binary
> values, that is,
> for example, It needs to hold binary values as Byte array for Binary
> values internally in addition to String for Text values.
>
> This is what i mean by "most OAuth client libarary expects to
> treats(handle) them as *string* internally".
>
> My own OAuth implemetation also was one of such libraries.
>
> But Adapting it to support binary values is not so hard job.
Mohac BILECEN
Mohac Bilecen
Mohac BILECEN
S. Douglass
he uses multipart. Does that actually work? I thought folks had
already established the content type was supposed to be form encoded,
like in the Python example from the Tumblr team?
On Nov 21, 9:51 am, Mohac Bilecen <moh...@gmail.com> wrote:
> Steven,
> data, data[0], data[1] or data[hello] doesn't matter always get 1st
> attached one. but i am sure this ASIhttpRequest does right encoding because
> i can upload audio and video with it no problem.
> i'll share if i can find further.
> best,
> -mohac.
>
> On Mon, Nov 21, 2011 at 7:18 PM, Steven Pears <steven.pe...@live.co.uk>wrote:
>
>
>
>
>
>
>
>
>
> > Thank you mohac!
>
> > The fact you're using data[1] makes it look like it's not a 0-based array,
> > that would have caused me trouble!
>
> > Will attempt implementing this tonight, thank you!!
>
> > Sent from my Windows Phone
> > ------------------------------
Mohac Bilecen
Mohac BILECEN
wyvern
binary values and
Instead, sending it with multipart type is used commonly but it's not
required. Internet related spec is really confusion and messy.
But Tumblr API seems only accept application/x-www-form-urlencoded so
all we can do is
to ask Tumblr team to accept multipart type or to ask your OAuth
library implmentater to adapt it for supporting binary values.
According to OAuth spec,
only if sending parameters with application/x-www-form-urlencoded,
those parameters has to be included for generating singnature.
It just seems Your OAuth library ignores binary values for application/
x-www-form-urlencoded.
Steven Pears
The issue I have is that Tumblr is using a single-byte encoding for their data (clarified in another post to be Latin-1). Single-byte encoding is not supported by WP7 or Silveright, so the implementation is not only non-standard, but completely cuts out microsoft web technology and, thanks to Nokia moving to WP7 rather than Symbian for future phones, an upcoming web operating system.
Now it seems there may be a multi-part option available, but that it's not fully implemented - so currently I'm looking into that, but I'm not holding out much hope.
As a developer for one of the few dedicated Tumblr apps in the WP7 marketplace right now, this is a problem for me.
S. Douglass
expecting Latin 1 when they should be expecting UTF-8. I have a
working Java version of the Python Gist that Derek from Tumblr shared
that I'm going to try to clean up and make available somewhere to show
exactly what I had to do to get it to work. In Java I have to specify
the character set for every conversion between bytes and characters,
so it should illustrate exactly how the data is being handled.
Steven Pears
I've tried to get my request to look as close to yours as possible
with my little test image and all I get is "not authorized" errors
POST http://api.tumblr.com/v2/blog/justaddmuse.tumblr.com/post HTTP/
1.1
Accept: */*
Referer: file:///Applications/Install/F200CA02-F63B-46DC-AC29-27AA1AD47030/Install/
Content-Length: 765
Accept-Encoding: gzip
Authorization: OAuth
oauth_consumer_key="xxxxx",oauth_nonce="nri1vh4m4cuylc32",oauth_signature="xxxx",oauth_signature_method="HMAC-
SHA1",oauth_timestamp="1321908715",oauth_token="xxx",oauth_version="1.0"
Content-Type: multipart/form-data; charset=utf-8;
boundary=5cee46f6-6d50-42c3-81de-3f811a541e83
User-Agent: DashBuddy
Host: api.tumblr.com
Connection: Keep-Alive
Pragma: no-cache
--5cee46f6-6d50-42c3-81de-3f811a541e83
Content-Disposition: form-data; name="type"
photo
--5cee46f6-6d50-42c3-81de-3f811a541e83
Content-Disposition: form-data; name="data"; filename="photo.jpg"
Content-Type: image/jpg
����� JFIF� �H�H�����C�
���C
��� � � � ��� � ��������������� ��� ������������������� ������������������� �������������������
� �?�T���
--5cee46f6-6d50-42c3-81de-3f811a541e83
Content-Disposition: form-data; name="state"
draft
--5cee46f6-6d50-42c3-81de-3f811a541e83
Content-Disposition: form-data; name="caption"
DashBuddy Test Photo Post
--5cee46f6-6d50-42c3-81de-3f811a541e83--
Mohac Bilecen
POST&http://api.tumblr.com/v2/blog/mohacs.tumblr.com/post&caption=* Photo 1 Throught API&oauth_consumer_key=xxxxxxxxxxx&oauth_nonce=fRHRCYyVTLZEHowL&oauth_signature_method=HMAC-SHA1&oauth_timestamp=1321910962&oauth_token=xxxxxxxxxxxx&oauth_version=1.0&tags=test, API test, more test&type=photo
POST&http%3A%2F%2Fapi.tumblr.com%2Fv2%2Fblog%2Fmohacs.tumblr.com%2Fpost&caption%3D%252A%2520Photo%25201%2520Throught%2520API%26oauth_consumer_key%3Dxxxxxxxxxxxxxxxxxxxxx%26oauth_nonce%3DfRHRCYyVTLZEHowL%26oauth_signature_method%3DHMAC-SHA1%26oauth_timestamp%3D1321910962%26oauth_token%xxxxxxxxxxxx%26oauth_version%3D1.0%26tags%3Dtest%252C%2520API%2520test%252C%2520more%2520test%26type%3Dphoto
Mohac BILECEN
wyvern
bytes(I'm not sure it completely produces same results).
Naturally, Handling binary values as string type involves wrong,
unnecessary char <-> bytes conversion, which results in data loss.
Reliable approach is handing binary values as Byte array or Stream
class and so on.
for example, take a example of .NET HttpUtility class. This class has
methods for urlencoding.
If all parameters to be passed is text, Only using
HttpUtility.UrlEncode(string, [encoding Encoding]) is enough.
But if some of them are binary, overloaded version
HttpUtility.UrlEncode(byte Bytes[]) has to be used together.
Why this Byte array overloaded version exists? Its primarily for
binary parameters. no encoding parameter!!
You are just going to convert binary values to Latin 1 *in force* and
handle it, which might produces same results as raw bytes but
mentioned eariler, it really dangerous approach.
anyway, it seems better wait for Tumblr team anwser.
>Steven Pears
View profile
> More options Nov 22, 5:23 am
>No - again, my OAuth provider is accepting them, I don't know how to make it any clearer - it's not my OAuth provider!
Which library u using, can u give me a link? then i can check.
Thx.
anyway,
Alayna Fox
Mohac Bilecen
Steven Pears
You're left looking at manual encoding because these functions are for textual streams, such as querystring parameters, not megabytes of binary!
Steven
Sent from my Windows Phone
From: wyvern
Sent: 21/11/2011 22:40
To: Tumblr API Discussion
Subject: Re: posting photo(s)
Steven Pears
As I've said several times now, silverlight/WP7 has no single-byte encoding, so again - manual is all you're left with.
I hope this puts to rest the idea I've just missed something in Silverlight/WP7 that will work easily, there are good reasons for asking for supported UTF-8, Base64 or multi-part requests and I promise you it wasn't due to lack of trying.
If I've misunderstood the API calls, that's a different matter entirely, and am thankful to the other devs for helping me in that regard.
Goodnight from the UK
S. Douglass
multiple photos.
There are two problems with Tumblr's API that I had to work around.
1. The Tumblr API does not appear to expect the use of the UTF-8
character set for all byte/character conversions. I had to make sure
to use Latin 1 (ISO 8859-1) when:
- initially reading in the binary file's bytes and converting them to
characters
- URL encoding those characters to put the file into the POST contents
- percent encoding "data" parameter names and values for OAuth (see
http://tools.ietf.org/html/rfc5849#section-3.6 )
2. The Tumblr API appears to expect "data" parameter names used in the
OAuth base signature string to be singly percent encoded, but they
should be doubly percent encoded. For example, with a parameter name
of "data[0]", what should be in the OAuth base signature string is
"%255B0%255D", but what the Tumblr API expects is "data%5B0%5D".
- The first percent encoding happens to parameter names and values
during "Parameters Normalization" (see http://tools.ietf.org/html/rfc5849#section-3.4.1.3.2
)
-- "1. First, the name and value of each parameter are encoded"
- The second percent encoding happens to the normalized parameter
string as part of "String Construction" (see http://tools.ietf.org/html/rfc5849#section-3.4.1.1
)
-- "5. ... after being encoded",
If Tumblr could resolve these two issues, then I imagine more OAuth
libraries would work "out of the box" with their API.
It'd be great too if they could add support for multipart POSTs too,
which as has been stated here already would make it much more
straightforward to send binary data to the API.
Thanks for all your help everybody on this thread. Is there somewhere
I can file a bug with Tumblr about these issues...? I've seen they
have use getsatisfaction.com ( http://getsatisfaction.com/tumblr ) so
maybe I'll try to post something there about this stuff.
S. Douglass
http://getsatisfaction.com/tumblr/topics/tumblr_v2_api_issues_when_posting_binary_data_e_g_photos
On Nov 21, 6:08 pm, "S. Douglass" <sdouglass...@gmail.com> wrote:
> So, I have things working now for posting photos, including sending
> multiple photos.
>
> There are two problems with Tumblr's API that I had to work around.
>
> 1. The Tumblr API does not appear to expect the use of the UTF-8
> character set for all byte/character conversions. I had to make sure
> to use Latin 1 (ISO 8859-1) when:
> - initially reading in the binary file's bytes and converting them to
> characters
> - URL encoding those characters to put the file into the POST contents
> - percent encoding "data" parameter names and values for OAuth (seehttp://tools.ietf.org/html/rfc5849#section-3.6)
>
> 2. The Tumblr API appears to expect "data" parameter names used in the
> OAuth base signature string to be singly percent encoded, but they
> should be doubly percent encoded. For example, with a parameter name
> of "data[0]", what should be in the OAuth base signature string is
> "%255B0%255D", but what the Tumblr API expects is "data%5B0%5D".
> - The first percent encoding happens to parameter names and values
> during "Parameters Normalization" (seehttp://tools.ietf.org/html/rfc5849#section-3.4.1.3.2
> )
> -- "1. First, the name and value of each parameter are encoded"
> - The second percent encoding happens to the normalized parameter
> string as part of "String Construction" (seehttp://tools.ietf.org/html/rfc5849#section-3.4.1.1
> )
> -- "5. ... after being encoded",
>
> If Tumblr could resolve these two issues, then I imagine more OAuth
> libraries would work "out of the box" with their API.
>
> It'd be great too if they could add support for multipart POSTs too,
> which as has been stated here already would make it much more
> straightforward to send binary data to the API.
>
> Thanks for all your help everybody on this thread. Is there somewhere
> I can file a bug with Tumblr about these issues...? I've seen they
> have use getsatisfaction.com (http://getsatisfaction.com/tumblr) so
wyvern
>2. The Tumblr API appears to expect "data" parameter names used in the
>OAuth base signature string to be singly percent encoded, but they
>should be doubly percent encoded. For example, with a parameter name
>of "data[0]", what should be in the OAuth base signature string is
>"%255B0%255D", but what the Tumblr API expects is "data%5B0%5D".
When collecting parameters, it must be decoded...
Look at section 3.4.1.3.1
3.4.1.3.1. Parameter Sources
The parameters from the following sources are collected into a
single
list of name/value pairs:
o The query component of the HTTP request URI as defined by
[RFC3986], Section 3.4. The query component is parsed into a
list
of name/value pairs by treating it as an
"application/x-www-form-urlencoded" string, separating the names
and values and decoding them as defined by
[W3C.REC-html40-19980424], Section 17.13.4.
o The OAuth HTTP "Authorization" header field (Section 3.5.1) if
present. The header's content is parsed into a list of name/
value
pairs excluding the "realm" parameter if present. The parameter
values are decoded as defined by Section 3.5.1.
o The HTTP request entity-body, but only if all of the following
conditions are met:
* The entity-body is single-part.
* The entity-body follows the encoding requirements of the
"application/x-www-form-urlencoded" content-type as defined
by
[W3C.REC-html40-19980424].
* The HTTP request entity-header includes the "Content-Type"
header field set to "application/x-www-form-urlencoded".
The entity-body is parsed into a list of decoded name/value
pairs
as described in [W3C.REC-html40-19980424], Section 17.13.4.
The "oauth_signature" parameter MUST be excluded from the signature
base string if present. Parameters not explicitly included in the
request MUST be excluded from the signature base string (e.g., the
"oauth_version" parameter when omitted).
It says The entity-body is parsed into a list of decoded name/value
pairs
as described in [W3C.REC-html40-19980424], Section 17.13.4.
So "data%5B0%5D" is correct..
S. Douglass
entity-body but not for the OAuth signature base string. "data%5B0%5D"
would initially be decoded, as per the spec that you quoted, using
[W3C.REC-html40-19980424], Section 17.13.4, back to "data[0]". But I
think that during the construction of the signature base string, it
would be percent encoded -twice- first during "Parameters
Normalization" then again during "String Construction", as per the
spec sections that I mentioned. So I think it should be "data
%255B0%255D" in the signature base string. That's why my OAuth library
(Spring Social http://www.springsource.org/spring-social ) tries to
use and I'm pretty sure that it's written according to the OAuth
spec.
wyvern
English.
>what should be in the OAuth base signature string is
>"%255B0%255D", but what the Tumblr API expects is "data%5B0%5D"?
How do u know/check Tumblr API expects is "data%5B0%5D"?
wyvern
In my own implementation, data%255B0%255D is produced for singature
base string
S. Douglass
https://raw.github.com/gist/1198576/0a04d2400582adb72bc8de33c3cc6989202766d6/gistfile1.py
I added a line to print out the signature base string, right before
"base64.encodestring(hmac.new(...))". I see "data[0]=" get turned into
"data%5B0%5D%3D" in the signature base string and the post works. If I
change the code so that it encodes the "data[0]" another time (which I
think it should, based on the OAuth spec), I see it get turned into
"data%255B0%255D" in the signature base string and the post fails. My
Java code was always turning the parameter name to "data%255B0%255D"
and always failed. Part of how I got my code to work was by putting in
a special check for parameter names starting with "data" to avoid
double encoding them, to match the Python code.
jola...@aol.co.uk
Sent from my BlackBerry® wireless device
-----Original Message-----
From: "S. Douglass" <sdougl...@gmail.com>
Sender: tumbl...@googlegroups.com
Date: Mon, 21 Nov 2011 21:19:00
To: Tumblr API Discussion<tumbl...@googlegroups.com>
Reply-To: tumbl...@googlegroups.com
Subject: Re: posting photo(s)

funfu...@gmail.com
Sent via my BlackBerry from Vodacom - let your email find you!
mohacs
S. Douglass
to get your base signature string to look something like this:
POST&http%3A%2F%2Fapi.tumblr.com%3A65029%2Fv2%2Fblog
%2FYOURBLOGHERE.tumblr.com%2Fpost&data%5B0%5D%3D%25FF%25D8%25FF
%25E0%2500%2510JFIF%2500%2501%2501%2501%2500H%2500H%2500%2500%25FF%25DB
%2500C
%2500%2506%2504%2504%2504%2505%2504%2506%2505%2505%2506%2509%2506%2505%2506%2509%250B
%2508%2506%2506%2508%250B%250C%250A%250A%250B%250A%250A%250C%2510%250C
%250C%250C%250C%250C%250C%2510%250C%250E%250F%2510%250F%250E%250C
%2513%2513%2514%2514%2513%2513%251C%251B%251B%251B%251C
%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%25FF%25DB%2500C
%2501%2507%2507%2507%250D%250C%250D%2518%2510%2510%2518%251A
%2515%2511%2515%251A
%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%2520%25FF
%25C0%2500%2511%2508%2500%2502%2500%2502%2503%2501%2511%2500%2502%2511%2501%2503%2511%2501%25FF
%25C4%2500%2514%2500%2501%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2508%25FF
%25C4%2500%2514%2510%2501%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%25FF
%25C4%2500%2514%2501%2501%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%25FF
%25C4%2500%2514%2511%2501%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%2500%25FF
%25DA%2500%250C%2503%2501%2500%2502%2511%2503%2511%2500%253F%2500T
%2583%25FF%25D9%26oauth_consumer_key%3DYOURKEY%26oauth_nonce
%3D31.1555291231%26oauth_signature_method%3DHMAC-SHA1%26oauth_timestamp
%3D1321925551%26oauth_token%3DYOURTOKEN%26oauth_version%3D1.0%26type
%3Dphoto
I had to make sure to use the Latin 1 character set when percent
encoding the binary data, and I had to make sure that the binary data
got percent encoded twice, but that "data[0]" only got percent encoded
once.
mohacs
mohacs
S. Douglass
http://sdouglassdev.tumblr.com/post/13137807163/snow-in-ct
(One normal photo and the test 2x2 white JPG file mentioned earlier in
this thread.)
You are correct, the base signature string I used is invalid. When I
put it into that first "oauthTester" you linked to, it complains that
"data[0]" should be encoded. If you change "data%5B0%5D" to "data
%255B0%255D" in the base string then the validator says it is valid.
Posts with valid base strings never worked for me though. I could only
get the posts to work by using the invalid "data%5B0%5D" in the base
string.
It would be great if the Tumblr team could address that issue, as well
as either specifying what character sets people should use (e.g. Latin
1) or changing to using UTF-8. Another option would be to switch to
multipart form data for binary posts.
On Nov 23, 3:59 am, mohacs <moh...@gmail.com> wrote:
> please check the base signature string
> herehttp://quonos.nl/oauthTester/
Steven Pears
have moved forward with such a large amount of test data and bottoming
out the inconsistencies I'm astonished and really pleased it's gotten
to where it has.
That said - it does sound like it's getting to a stage where a note or
comment from the Tumblr team would be good about now before we start
implementing what seems to be a less than perfect implementation.
Tumblr? Have you been monitoring this thread?
Mohac Bilecen
Mohac Bilecen
eros...@gmail.com
Mohac Bilecen
Mohac Bilecen
Mohac Bilecen
John Bunting
mohacs
Steven Pears
En route to the office, guess i know what I'm doing first!
Sent from my Windows Phone
From: John Bunting
Sent: 23/11/2011 21:43
Mohac Bilecen
Steven Pears
The python script you've given us and my C# interpretation of that
script both continue to give me 401 issues. I can't think of anything
different in this information to any other app, other than the fact
that my tokens are authorised via XAuth - but that shouldn't make a
difference.
Can you please confirm that there's no issue with the photo upload
implementation and XAuth apps, and is there anything else that could
be causing this?
Thanks in advance
Steven
John Bunting
John Bunting
--Edsger W. Dijkstra

tiome
Have you found a workaround ?
Steven Pears
John Bunting
Steven Pears
Steven Pears
The 20kb image I'm using as a second test had some small encoding issues I'm working through but there is definitely light appearing at the end of this particular tunnel. Happy days :)
Steven
Sent from my Windows Phone
From: John Bunting
Sent: 16/03/2012 17:41
Steven Pears
Steven Pears

Justin Lee
You can find me on the net at:
Steven Pears
Justin Lee
Justin Lee
Justin Lee
You can find me on the net at:
John Bunting

felix schwermut
John Bunting
felix schwermut
Justin Lee
So my question is, why should the nonce have mattered like that? It's just a numeric value to be ANDed and XORed and bit crammed with the various keys and secrets. I just don't see why the scale of the number should've made any difference whatsoever. Regardless, it now works so hooray for the home team, I guess.
And another thing. Why are errors returned from the the api with a 200 code even though the body lists a 401 (or whatever)? Why isn't *that* response code part of the response header like it should be? These are HTTP calls and I expect the response code to reflect the server response. Masking everything with that 200 code just obscures stuff and complicates response/error parsing.
You can find me on the net at:
felix bonkoski

GG

RickF
John Bunting
--
You received this message because you are subscribed to the Google Groups "Tumblr API Discussion" group.
To unsubscribe from this group and stop receiving emails from it, send an email to tumblr-api+...@googlegroups.com.
For more options, visit https://groups.google.com/groups/opt_out.

ramon
John Crepezzi
ramon
ramon
public void start(){
JumblrClient client = new JumblrClient("myConsumerkey", "myConsumerSecret", "myToken", "mySecret");
try {
PhotoPost pp = client.newPost(client.user().getName(), PhotoPost.class);
// Photo photo = new Photo(mImagePath);
pp.setCaption("Test");
// pp.setPhoto(photo);
pp.setSource("http://images.wikia.com/dragonball/images/5/5e/Naruto-Shippuden-UNS-3_Goku-752x600.jpg");
pp.setClient(client);
pp.save();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
John Crepezzi
--
ramon

{kind=link}
Jabari Hunt
On Thursday, November 17, 2011 8:42:00 PM UTC-6, S. Douglass wrote:
I know this is a well worn topic here, so my apologies for starting
yet another thread about this. I've tried to scour all the existing
threads and examples but things are still not entirely clear to me. I
was hoping that folks could settle a couple points of confusion for
me. It'd be great to have these details made plain, and not in example
code, so that anybody can look at it without having to know
programming language X or Y or Z.
1. Content-type - is it application/x-www-form-urlencoded or multipart/
form-data ???
2. How is the OAuth signature generated? The same as for every other
API call? Or differently? The Twitter documentation for their upload
API call (which looks to be using multipart/form-data) indicates that
the OAuth signature is generated differently in that case:
https://dev.twitter.com/discussions/1059
3. The binary data is supposed to be turned into a string then
encoded. Is it Base64 encoded? URL query parameter encoded? Both?
4. The parameter names, are they supposed to be named "data[0]",
"data[1]", "data[2]", etc? If I'm sending just one file do I use
"data" or "data[0]"?
I have looked at both the example gists on GitHub mentioned in
elsewhere here but it isn't clear to me from the comments if they
actually work, and also I'm not familiar with Python, so I'm not
really sure I'm interpreting the code 100% correctly. So I'm just
hoping for some non-code details about how it works. Thanks!