notebook rewrite

Ondrej Certik
I finally learned javascript and AJAX, so that I can help with the
notebook. I also studied it's sources.
First things I like:
* I like the user interface, it's usable, especially the attention to
little details, like borders around the cells, tab completion, tab
indentation and things like that.
Things I don't like:
* the javascript is really hackish overall, but two things really
caught my attention:
a) the keyboard handling is horrific, why not to use some standard
library for that, that works across all browsers
b) it uses some custom format for transfering data (which has bugs,
like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
why not to use JSON?
* it doesn't run on the google appengine (William mentioned in the
past, that he doesn't see any benefit to do that, or that it would be
slow)
Well, talk is cheap, so here is the code (a sample Firefox screenshot
is also attached in case it didn't work in your browser):
it uses jQuery all over, it uses a keyboard plugin for jQuery, it uses
JSON and it runs on the google appengine (and anywhere else too, it's
just a standard django app). I tested in Firefox and IE8. The keyboard
works, there are just some subtle bugs on IE8, see here:
http://github.com/certik/notebook/blob/375a2026ee7ea721904d05068724b3a7663d018e/todo
but none of it seems major to me, the keyboard seems to be working
just fine (or is IE8 not the most problematic? I'll try to test in
other browsers like Opera and Safari too). Here is the index.html with
all the javascript that I wrote:
http://github.com/certik/notebook/blob/375a2026ee7ea721904d05068724b3a7663d018e/templates/index.html
It handles most of the keyboard interaction. It doesn't have TAB
completion and inspection yet.
Well, let me say that I really like to run things on the appengine,
rather than to constantly maintain our own servers. I see no reason
why the notebook cannot run on the appengine, only the AJAX would talk
to our own server with Sage to actually evaluate the cells (and for
many people, I think appengine itself could actually be enough). I
have to think though what the best way to transfer data to the
database with worksheets is though.
I wanted to ask --- which parts of the Sage notebook are BSD licensed?
I used a bit of the CSS styles and and maybe one javascript function,
everything else was written by me. If possible, I'd like to use the
BSD license for the notebook (if I find time to work on it further),
so that ipython can use it by default.
Also, question to all, do you like the In [3] and Out[3] lines? I
don't have an opinion on it yet myself, so I implemented them, to see
how it looks like. Also, please let me know if it works in your
browser.
Ondrej

William Stein
> Hi,
>
> I finally learned javascript and AJAX, so that I can help with the
> notebook. I also studied it's sources.
>
> First things I like:
>
> * I like the user interface, it's usable, especially the attention to
> little details, like borders around the cells, tab completion, tab
> indentation and things like that.
>
> Things I don't like:
>
> * the javascript is really hackish overall, but two things really
> caught my attention:
> a) the keyboard handling is horrific, why not to use some standard
> library for that, that works across all browsers
Tom Boothby wrote all that in early 2006, and there wasn't something
good then. I don't think jquery even existed then.
> b) it uses some custom format for transfering data (which has bugs,
> like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
> why not to use JSON?
That would be a good idea.
> * it doesn't run on the google appengine (William mentioned in the
> past, that he doesn't see any benefit to do that, or that it would be
> slow)
Just because I don't see a benefit to something, doesn't mean there
aren't tons of benefits.
> Well, talk is cheap, so here is the code (a sample Firefox screenshot
> is also attached in case it didn't work in your browser):
>
> http://pythonnb.appspot.com/
>
> it uses jQuery all over,
Cool!
> it uses a keyboard plugin for jQuery, it uses
> JSON and it runs on the google appengine (and anywhere else too, it's
> just a standard django app). I tested in Firefox and IE8. The keyboard
> works, there are just some subtle bugs on IE8, see here:
>
> http://github.com/certik/notebook/blob/375a2026ee7ea721904d05068724b3a7663d018e/todo
>
> but none of it seems major to me, the keyboard seems to be working
> just fine (or is IE8 not the most problematic? I'll try to test in
> other browsers like Opera and Safari too). Here is the index.html with
> all the javascript that I wrote:
>
> http://github.com/certik/notebook/blob/375a2026ee7ea721904d05068724b3a7663d018e/templates/index.html
>
> It handles most of the keyboard interaction. It doesn't have TAB
> completion and inspection yet.
How are you doing the auto input cell resizing?
> Well, let me say that I really like to run things on the appengine,
> rather than to constantly maintain our own servers. I see no reason
> why the notebook cannot run on the appengine, only the AJAX would talk
> to our own server with Sage to actually evaluate the cells (and for
> many people, I think appengine itself could actually be enough). I
> have to think though what the best way to transfer data to the
> database with worksheets is though.
>
> I wanted to ask --- which parts of the Sage notebook are BSD licensed?
> I used a bit of the CSS styles and and maybe one javascript function,
> everything else was written by me. If possible, I'd like to use the
> BSD license for the notebook (if I find time to work on it further),
> so that ipython can use it by default.
Make precise what you used and we'll get it BSD licensed for you. We
have to see who wrote the particular code you're using.
> Also, question to all, do you like the In [3] and Out[3] lines?
> I don't have an opinion on it yet myself, so I implemented them, to see
> how it looks like. Also, please let me know if it works in your
> browser.
>
> Ondrej
-- William

Alex Clemesha
I'll reply from a purely codenode point of view. You sent this
email to both lists, but I'm only qualified to describe the details
of codenode's current architecture.
> a) the keyboard handling is horrific, why not to use some standard
> library for that, that works across all browsers
There is an *excellent* jQuery library for this called "js-hotkeys"
http://code.google.com/p/js-hotkeys, which is surely the one you are mentioning
that just did not exist when both notebooks began to really get going.
That said, it would be extremely beneficial to delegate the key-handling
to that library.
> b) it uses some custom format for transfering data (which has bugs,
> like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
> why not to use JSON?
codenode only sends data encoded in JSON. This is very important because
it totally decouples data from presentation. This is in fact one reason why the
switch to Django went very smoothly.
> * it doesn't run on the google appengine (William mentioned in the
> past, that he doesn't see any benefit to do that, or that it would be
> slow)
The codenode backend (as you know) does run on app-engine, and
I feel that this is the most important part because this is where all the
arbitrary code execution (the big security risk) happens. codenode
is now mostly Django so it does seem feasible to make everything work on
app-engine, but this would take a little work.
> I wanted to ask --- which parts of the Sage notebook are BSD licensed?
> I used a bit of the CSS styles and and maybe one javascript function,
> everything else was written by me. If possible, I'd like to use the
> BSD license for the notebook (if I find time to work on it further),
> so that ipython can use it by default.
We are actually going to be completely switching the codenode license to BSD,
(as nothing we depend on is GPL) and we hope to allow more people
to utilize what codenode has to offer.
Dorian and I have talked about this, and we feel that it is best. The
scipy/numpy/sympy/matplotlib
communities are ones that we know can benefit from a really good notebook,
and we hope that all our efforts combined can make it so.
We have not made the official switch yet, but we will be officially switching
to the BSD license in the next couple weeks.
thanks,
Alex

John H Palmieri
[snip]
> Also, question to all, do you like the In [3] and Out[3] lines? I
> don't have an opinion on it yet myself, so I implemented them, to see
> how it looks like.
> Also, please let me know if it works in your
> browser.
John

killian koepsell
very nice work!
On Mon, Jul 20, 2009 at 9:02 PM, Ondrej Certik<ond...@certik.cz> wrote:
> a) the keyboard handling is horrific, why not to use some standard
> library for that, that works across all browsers
> b) it uses some custom format for transfering data (which has bugs,
> like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
> why not to use JSON?
another option of course would be to use pyjamas:
http://code.google.com/p/pyjamas/
It has a lot of features and also the option to run it standalone,
without a browser, as a
desktop app.
Kilian
Ondrej Certik
I take the text, count number of "\n", handle line wrapping, calculate
the number of lines *occupied* in the textbox and set the number of
rows of the textbox. It just works in firefox, there is a little
glitch in IE8, that I have to put the backspace and enter into the
text before the calculation (e.g. the text is updated after the
keyboard handler). But I don't need to put the text to some div first,
measure it's height and set the height.
Seems like a similar glitch is in Opera.
As to which functions I used, I used this one:
function get_selection_range(input) {
/*
Return the start and end positions of the currently selected text
in the input text area (a DOM object).
INPUT:
input -- a DOM object (a textarea)
OUTPUT:
an array of two nonnegative integers
*/
// If the attribute input.selectionStart is present, use that:
if (input.selectionStart || input.selectionStart == 0) {
return Array(input.selectionStart, input.selectionEnd);
} else {
var start, end;
var range = document.selection.createRange();
var tmprange = range.duplicate();
tmprange.moveToElementText(input);
tmprange.setEndPoint("endToStart", range);
start = tmprange.text.length;
tmprange = range.duplicate();
tmprange.moveToElementText(input);
tmprange.setEndPoint("endToEnd", range);
end = tmprange.text.length;
return Array(start, end);
}
}
(I rewrote it it a bit, and I may have broken it on IE8, but I'll fix it. :)
Besides that, I used the following styles (again, I modifed them a
bit, but left the Sage notebook borders, because I like them). I fixed
the padding, so that (at least on firefox) if you focus a cell, only
the border changes, but the text doesn't move (in Sage notebook, the
text moves by 1 pixel, and I find it annoying).
textarea.cell_input {
color:#000000;
background-color: white;
border: 1px solid #a8a8a8;
font-family: monospace;
font-size:12pt;
overflow:hidden;
padding-left:6px;
padding-top:4px;
padding-bottom:4px;
margin-bottom:0px;
margin-top:0px;
line-height:1.2em;
float: left;
}
textarea.cell_input_active {
background-color: white;
border: 2px solid #8888FE;
font-family: monospace;
font-size:12pt;
overflow:hidden;
padding-left:5px;
padding-top:3px;
padding-bottom:4px;
margin-bottom:0px;
margin-top:0px;
line-height:1.2em;
float: left;
}
Besides that, I wrote everything from scratch.
Ondrej
Ondrej
Ondrej Certik
>
> Hi Ondrej,
>
> I'll reply from a purely codenode point of view. You sent this
> email to both lists, but I'm only qualified to describe the details
> of codenode's current architecture.
Yes. In fact, one reason I wrote it is so that you can use it in
codenode if you like it --- I really like the Sage style with borders
around cells etc.
>
>
>> a) the keyboard handling is horrific, why not to use some standard
>> library for that, that works across all browsers
> There is an *excellent* jQuery library for this called "js-hotkeys"
> http://code.google.com/p/js-hotkeys, which is surely the one you are mentioning
> that just did not exist when both notebooks began to really get going.
> That said, it would be extremely beneficial to delegate the key-handling
> to that library.
Yes, that's exactly what I use. It seems to be working just fine
everywhere and the interface is really nice and super easy, you just
attach a function for every key combination --- no need to have one
ugly handler for everything.
>
>
>> b) it uses some custom format for transfering data (which has bugs,
>> like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
>> why not to use JSON?
> codenode only sends data encoded in JSON. This is very important because
> it totally decouples data from presentation. This is in fact one reason why the
> switch to Django went very smoothly.
Yes, that's the way to go.
>
>
>
>
>> * it doesn't run on the google appengine (William mentioned in the
>> past, that he doesn't see any benefit to do that, or that it would be
>> slow)
> The codenode backend (as you know) does run on app-engine, and
> I feel that this is the most important part because this is where all the
> arbitrary code execution (the big security risk) happens. codenode
> is now mostly Django so it does seem feasible to make everything work on
> app-engine, but this would take a little work.
In fact, the backend can only run on the appengine if it's pure python
(like sympy), but not if it's some heavy C++ stuff, like our FEM
solvers. But the frontend can run in there, that's my idea.
>
>
>
>
>> I wanted to ask --- which parts of the Sage notebook are BSD licensed?
>> I used a bit of the CSS styles and and maybe one javascript function,
>> everything else was written by me. If possible, I'd like to use the
>> BSD license for the notebook (if I find time to work on it further),
>> so that ipython can use it by default.
>
> We are actually going to be completely switching the codenode license to BSD,
> (as nothing we depend on is GPL) and we hope to allow more people
> to utilize what codenode has to offer.
>
> Dorian and I have talked about this, and we feel that it is best. The
> scipy/numpy/sympy/matplotlib
> communities are ones that we know can benefit from a really good notebook,
> and we hope that all our efforts combined can make it so.
>
> We have not made the official switch yet, but we will be officially switching
> to the BSD license in the next couple weeks.
Ah, that is very nice! Indeed, there should be some default notebook
for python stuff, I view it like a part of the common platform, that
everyone needs.
How hard would be to (maybe optionally) use the Sage like look & feel
to codenode?
Ondrej
Ondrej Certik
>
> On Jul 20, 9:02 pm, Ondrej Certik <ond...@certik.cz> wrote:
>
> [snip]
>
>> Also, question to all, do you like the In [3] and Out[3] lines? I
>> don't have an opinion on it yet myself, so I implemented them, to see
>> how it looks like.
>
> How easy would it be to add a way to toggle them on and off?
That should be easy. It's written in a way, so that people can just
trivially modify the html template and very easily change things like
this.
>
>> Also, please let me know if it works in your
>> browser.
>
> In a brief test, it works in Safari and Firefox on my intel mac.
Thanks!
On Tue, Jul 21, 2009 at 12:18 AM, killian koepsell<koep...@gmail.com> wrote:
>
> Hi Ondrej,
>
> very nice work!
>
> On Mon, Jul 20, 2009 at 9:02 PM, Ondrej Certik<ond...@certik.cz> wrote:
>> a) the keyboard handling is horrific, why not to use some standard
>> library for that, that works across all browsers
>> b) it uses some custom format for transfering data (which has bugs,
>> like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
>> why not to use JSON?
>
> another option of course would be to use pyjamas:
> http://code.google.com/p/pyjamas/
> It has a lot of features and also the option to run it standalone,
> without a browser, as a
> desktop app.
Yes, that's the next thing that I want to learn and try to rewrite the
thing that I wrote so far into pyjamas, so that we can have everything
in Python.
I wanted to get my hands dirty first, to learn how javascript works,
because even though theoretically you don't have to touch it with
pyjamas, but in practise I am sure I will need to debug it why it
doesn't work in some particular browser.
Ondrej
Ondrej Certik
>>
>> * the javascript is really hackish overall, but two things really
>> caught my attention:
>
>
> Also -- I've been supporting Opera 8. jQuery doesn't work there, because it's buggy and just behaves strangely -- many of the hacks you see can be blamed on Opera 8. Now that Opera 9 is out and jQuery supports it, I am fully behind a complete transition to jQuery.
You did an amazing work. I didn't realize it was already in 2005. It
must have been terrible to make sure it works everywhere.
Fortunately, today there seems to be good javascript libraries for
everything and they seem to work pretty well almost everywhere.
>
>> a) the keyboard handling is horrific, why not to use some standard
>> library for that, that works across all browsers
>
> As noted, I did this before jQuery existed -- I searched hard and long before deciding to write my own keyboard handler, and every "clean" approach I took failed in a browser or two -- the "horrific" result works in every platform I've tried, so long as one stays away from the alt key in Safari, IIRC.
>
> Now that Opera is no longer an obstruction, there's only one reason not to use a standard library: it's been written, and it works. Rewrite it! I love seeing my javascript get rewritten!
I am thinking of using pyjamas, if it works for this, *that* be
awesome. Having everything in Python.
>
>> b) it uses some custom format for transfering data (which has bugs,
>> like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
>> why not to use JSON?
>
> Again... it worked after we wrote it. It became too much work to replace, so we kept cobbling more on.
Right. By no means it was meant to criticize your work. :) I was just
saying that we can do better today with all those nice js libraries.
>
>> * it doesn't run on the google appengine (William mentioned in the
>> past, that he doesn't see any benefit to do that, or that it would be
>> slow)
>>
>> Well, talk is cheap, so here is the code (a sample Firefox screenshot
>> is also attached in case it didn't work in your browser):
>>
>> http://pythonnb.appspot.com/
>
> Might have to take back what I said earlier... Shift-enter causes an extra newline to be placed in the cell below the current one in Opera 9.
This newline is a bick hackish still ---- basically the textarea
really sucks, it doesn't have a function for getting a cursor position
and it cannot resize automatically. Everything has to be written
indirectly.
>
>>
>> it uses jQuery all over, it uses a keyboard plugin for jQuery, it uses
>> JSON and it runs on the google appengine (and anywhere else too, it's
>> just a standard django app). I tested in Firefox and IE8. The keyboard
>> works, there are just some subtle bugs on IE8, see here:
>>
>> http://github.com/certik/notebook/blob/375a2026ee7ea721904d05068724b3a7663d018e/todo
>>
>> but none of it seems major to me, the keyboard seems to be working
>> just fine (or is IE8 not the most problematic? I'll try to test in
>> other browsers like Opera and Safari too). Here is the index.html with
>> all the javascript that I wrote:
>>
>> http://github.com/certik/notebook/blob/375a2026ee7ea721904d05068724b3a7663d018e/templates/index.html
>>
>> It handles most of the keyboard interaction. It doesn't have TAB
>> completion and inspection yet.
>
> Initial reaction: NICE!!! But... I only see about 20% of the functionality we really need, and the last 10% typically takes as long as the first 90%.
That's right.
>
> Criticism: when one presses the up arrow accidentally at the top of a cell, it is obnoxious for the cursor to jump to the top of the next cell up.
Yes, in fact this is the first thing in my the TODO file:
http://github.com/certik/notebook/blob/375a2026ee7ea721904d05068724b3a7663d018e/todo
>
> Suggestion: the introspection interface, as written, is utter shit. It's literally the first thing that I got to work, and it's never been reworked. I've been wanting to move the introspect "window" to a floating div that can be torn out of the window -- but I have little skill when it comes to using the new-fangled javascript libraries, so I haven't done this. At the very least, I think it should appear on the right-hand side of the window so one can both read the documentation, and the text at the top of their long cell.
Yes, I think this is the second thing that I want to write. Maybe
after pyjamas --- now, when I understand how to debug all those AJAX
requests, I am eager to look into that.
I really tried to avoid javascript and all this AJAX thing, but I must
say it's really exciting! :)
I think I will try to write GUI for our FEM stuff in the browser.
Browser is the best thing.
>
>>
>> Well, let me say that I really like to run things on the appengine,
>> rather than to constantly maintain our own servers. I see no reason
>> why the notebook cannot run on the appengine, only the AJAX would talk
>> to our own server with Sage to actually evaluate the cells (and for
>> many people, I think appengine itself could actually be enough). I
>> have to think though what the best way to transfer data to the
>> database with worksheets is though.
>>
>> I wanted to ask --- which parts of the Sage notebook are BSD licensed?
>> I used a bit of the CSS styles and and maybe one javascript function,
>> everything else was written by me. If possible, I'd like to use the
>> BSD license for the notebook (if I find time to work on it further),
>> so that ipython can use it by default.
>
> Every single line I have written for the notebook is BSD licensed. However, William, Alex Clemesha, Jason Grout, and Robert Bradshaw have all contributed javascript code, so I'd like to hear from them from making a blanket statement about the file. I believe that Dorian Raymer and Mike Hansen may have contributed, too. Am I missing anybody? Robert Miller?
>
>> Also, question to all, do you like the In [3] and Out[3] lines? I
>> don't have an opinion on it yet myself, so I implemented them, to see
>> how it looks like. Also, please let me know if it works in your
>> browser.
>
> NO! I think they're terrible. The more space a cell can occupy, the better. I dislike how much border & space the current Sage notebook has.
That was another thing --- I really want the notebook to be
configurable, so that it's easy to rebrand it (e.g. change Sage to
something else), easy to change look & feel, like the thing above.
Ideally just by changing the cell html prototype and CSS styles.
Ondrej

Stan Schymanski
I think it would be great to have the notebook (linked to Sage) run in
Google Apps.
Ondrej Certik wrote:
> [snip]
>
> Also, question to all, do you like the In [3] and Out[3] lines? I
> don't have an opinion on it yet myself, so I implemented them, to see
> how it looks like. Also, please let me know if it works in your
> browser.
>
I am used to the In [3] and Out [3] display from Mathematica and I liked
it. The sage notebook has similar tags internally, but for some reason
they are not displayed in the notebook. The good thing is that if you do
Evaluate all, the In [1] etc. are numbered consecutively and you can use
this to refer to bits of notebook code in a published notebook or a pdf
version of your notebook. This comes in very handy if you use a notebook
to derive equations used in e.g. Fortran and you would like to point to
the right place in the notebook in your Fortran code.
Stan

Jason Grout
> Hi,
>
> I finally learned javascript and AJAX, so that I can help with the
> notebook. I also studied it's sources.
>
> First things I like:
>
> * I like the user interface, it's usable, especially the attention to
> little details, like borders around the cells, tab completion, tab
> indentation and things like that.
>
> Things I don't like:
>
> * the javascript is really hackish overall, but two things really
> caught my attention:
> a) the keyboard handling is horrific, why not to use some standard
> library for that, that works across all browsers
> b) it uses some custom format for transfering data (which has bugs,
> like http://groups.google.com/group/sage-devel/browse_thread/thread/5ecd104b0aa85439),
> why not to use JSON?
> * it doesn't run on the google appengine (William mentioned in the
> past, that he doesn't see any benefit to do that, or that it would be
> slow)
>
> Well, talk is cheap, so here is the code (a sample Firefox screenshot
> is also attached in case it didn't work in your browser):
>
> http://pythonnb.appspot.com/
>
Very nice! The log shows you've been committing to it for only one day!
That's amazing.
It seems to work on Firefox 3.5.1 on Ubuntu 9.04 32-bit.
Jason

Robert Bradshaw
> Hi,
>
> I finally learned javascript and AJAX, so that I can help with the
> notebook. I also studied it's sources.
>
> First things I like:
>
> * I like the user interface, it's usable, especially the attention to
> little details, like borders around the cells, tab completion, tab
> indentation and things like that.
>
> Things I don't like:
>
> * the javascript is really hackish overall, but two things really
> caught my attention:
> a) the keyboard handling is horrific, why not to use some standard
> library for that, that works across all browsers
> b) it uses some custom format for transfering data (which has bugs,
> like http://groups.google.com/group/sage-devel/browse_thread/thread/
> 5ecd104b0aa85439),
> why not to use JSON?
> * it doesn't run on the google appengine (William mentioned in the
> past, that he doesn't see any benefit to do that, or that it would be
> slow)
Very cool! AJAX, and javascript libraries, and browsers have improved
a lot since the notebook was first written--I think a lot of this can
be cleaned up now.
> Well, talk is cheap, so here is the code (a sample Firefox screenshot
> is also attached in case it didn't work in your browser):
>
> http://pythonnb.appspot.com/
>
> it uses jQuery all over, it uses a keyboard plugin for jQuery, it uses
> JSON and it runs on the google appengine (and anywhere else too, it's
> just a standard django app). I tested in Firefox and IE8. The keyboard
> works, there are just some subtle bugs on IE8, see here:
>
> http://github.com/certik/notebook/blob/
> 375a2026ee7ea721904d05068724b3a7663d018e/todo
>
> but none of it seems major to me, the keyboard seems to be working
> just fine (or is IE8 not the most problematic? I'll try to test in
> other browsers like Opera and Safari too). Here is the index.html with
> all the javascript that I wrote:
>
> http://github.com/certik/notebook/blob/
> 375a2026ee7ea721904d05068724b3a7663d018e/templates/index.html
>
> It handles most of the keyboard interaction. It doesn't have TAB
> completion and inspection yet.
>
> Well, let me say that I really like to run things on the appengine,
> rather than to constantly maintain our own servers. I see no reason
> why the notebook cannot run on the appengine, only the AJAX would talk
> to our own server with Sage to actually evaluate the cells (and for
> many people, I think appengine itself could actually be enough). I
> have to think though what the best way to transfer data to the
> database with worksheets is though.
+1, though for Sage we rely heavily on compiled code. I wonder how
much introduced latency there would be if the backend were served on
a university computer, and the front end in appengine.
> I wanted to ask --- which parts of the Sage notebook are BSD licensed?
> I used a bit of the CSS styles and and maybe one javascript function,
> everything else was written by me. If possible, I'd like to use the
> BSD license for the notebook (if I find time to work on it further),
> so that ipython can use it by default.
I release everything I've contributed under sage/server/* under BSD.
Here's a complete list. It looks longer than it is, and I bet most of
these people only contributed once. It'll be cleaner when it's
separate into a separate spkg.
$ hg log sage/server/*/*.py* | grep "user:" | sort | uniq
user: "Justin C. Walker <jus...@mac.com>"
user: 'Martin Albrecht <ma...@informatik.uni-bremen.de>'
user: Alex Clemesha <clem...@gmail.com>
user: Alexandru Ghitza <agh...@alum.mit.edu>
user: Bobby Moretti <mor...@u.washington.edu>
user: Carl Witty <cwi...@newtonlabs.com>
user: Christian Wuthrich <christian...@gmail.com>
user: Dan Drake <dr...@kaist.edu>
user: Dan Drake <dr...@mathsci.kaist.ac.kr>
user: Dorian Raymer <deld...@gmail.com>
user: Harald Schilly <harald....@gmail.com>
user: Igor Tolkov <ito...@gmail.com>
user: J. H. Palmieri <palm...@math.washington.edu>
user: Jason Grout <gr...@rayunion.org>
user: Jason Grout <jason...@creativetrax.com>
user: John H. Palmieri <palm...@math.washington.edu>
user: Karl-Dieter Crisman <kcri...@gmail.com>
user: Marshall Hampton <hamp...@gmail.com>
user: Martin Albrecht <ma...@informatik.uni-bremen.de>
user: Mike Hansen <mha...@gmail.com>
user: Mitesh Patel <qed...@gmail.com>
user: Nick Alexander <ncale...@gmail.com>
user: Paul Dehaye <pauloli...@gmail.com>
user: Paul Zimmermann <zimm...@loria.fr>
user: Rob Beezer <bee...@ups.edu>
user: Robert Bradshaw <robe...@math.washington.edu>
user: Robert L. Miller <r...@rlmiller.org>
user: Robert Miller <rlmil...@gmail.com>
user: Timothy Clemans <timothy...@gmail.com>
user: Tom Boothby <boo...@u.washington.edu>
user: Wilfried Huss <hu...@finanz.math.tugraz.at>
user: William Stein <wst...@gmail.com>
user: William Stein <wst...@ucsd.edu>
user: Yi Qiang <yqi...@gmail.com>
user: agc@kubuntu
user: boo...@eight.math.washington.edu
user: boothby@localhost
user: boo...@localhost.localdomain
user: boo...@u.washington.edu
user: mabshoff@localhost
user: mabs...@sage.math.washington.edu
user: root@sage
user: sa...@ubuntu-server.localdomain
user: w...@bsd.local
user: w...@keyah.local
user: was@localhost
user: w...@localhost.localdomain
user: was@ubuntu
user: wst...@gmail.com
> Also, question to all, do you like the In [3] and Out[3] lines?
No, but maybe that's just me.
> I don't have an opinion on it yet myself, so I implemented them, to
> see
> how it looks like. Also, please let me know if it works in your
> browser.
Works great for me.
- Robert
Jason Grout
> I release everything I've contributed under sage/server/* under BSD.
I also release everything I've contributed up to this point under
sage/server/* under BSD.
Jason
--
Jason Grout

Marshall Hampton
case it matters:
I release everything I've contributed under sage/server/* under BSD.
learn some jQuery and it seems quite nice. It seems in the future
there will be more possibilities of moving things to javascript, as it
gets nicer and the implementations speed up (for example, the recent
work by William and John Palmieri on animations using javascript).
Cheers,
Marshall Hampton

Tim Dumol
I'm doing some work on converting the notebook to Jinja (
http://trac.sagemath.org/sage_trac/ticket/6568 ). It shouldn't be too
hard to convert my work from Jinja templates to Django templates, or
to switch the Django templating engine to Jinja.
I'd love to help in the notebook rewrite after I finish the
conversion. I can fork your project at that time, and help out.

Pat LeSmithe
Very promising! Just yesterday, I found Google's tutorial on writing a
Python application for their App Engine:
http://code.google.com/appengine/docs/python/gettingstarted/
There are some sample projects at
http://code.google.com/p/google-app-engine-samples/
Actually, I was motivated not to rewrite the notebook, but to adapt a
Python web server for controlling and monitoring the process of building
and testing Sage.
For example, we might use a local web dashboard to run doctests and
quickly get a list of the failures. Machines on a build farm could
occupy individual tabs. Maybe individual Sage developers could send
automated build reports (and logs, as necessary) to sagemath.org or a cloud.
How soon into the build process can we bring Sage to life, that is,
start running at least a minimal server?
Ondrej Certik
Awesome! I'll wait after you do it and then I'll just use your
templates. Just use jinja, it works great and django can use it too.
Ondrej
Ondrej Certik
>
> 2009/7/21 Ondrej Certik <ond...@certik.cz>:
>> but none of it seems major to me, the keyboard seems to be working
>> just fine (or is IE8 not the most problematic? I'll try to test in
>> other browsers like Opera and Safari too). Here is the index.html with
>> all the javascript that I wrote:
>
>
>> Also, question to all, do you like the In [3] and Out[3] lines? I
>> don't have an opinion on it yet myself, so I implemented them, to see
>> how it looks like. Also, please let me know if it works in your
>> browser.
>
> (in the same way as ipython) - but you can't. Also, when you insert a
I added this to the TODO.
> new cell the numbering gets out of order which looks messy. What is
> the value in having them numbered?
The cells have to have some numbers, but they can be internal of
course. It helped me as a developer to see which cell is what,
especially when merging them. It seems most people don't like the
In/Out labels, so I will make them off by default and implement an
option to turn them on.
>
> By the way, if you print you don't see the results.
Yes, I need to catch stdout and send it to the browsers. I added it to
the TODO list.
Many thanks for the feedback.
Ondrej
William Stein
>
> On Tue, Jul 21, 2009 at 3:49 AM, James Casbon<cas...@gmail.com> wrote:
>>
>> 2009/7/21 Ondrej Certik <ond...@certik.cz>:
>>> but none of it seems major to me, the keyboard seems to be working
>>> just fine (or is IE8 not the most problematic? I'll try to test in
>>> other browsers like Opera and Safari too). Here is the index.html with
>>> all the javascript that I wrote:
>>
>> Safari works for me.
>>
>>> Also, question to all, do you like the In [3] and Out[3] lines? I
>>> don't have an opinion on it yet myself, so I implemented them, to see
>>> how it looks like. Also, please let me know if it works in your
>>> browser.
>>
>> They're ok, but they implied to me I could use, e.g., _4 as a variable
>> (in the same way as ipython) - but you can't. Also, when you insert a
>
> I added this to the TODO.
>
>> new cell the numbering gets out of order which looks messy. What is
>> the value in having them numbered?
>
> The cells have to have some numbers, but they can be internal of
> course. It helped me as a developer to see which cell is what,
> especially when merging them. It seems most people don't like the
> In/Out labels, so I will make them off by default and implement an
> option to turn them on.
session with lots of random insertions of new cells, the numbers can
easily get confusing as one is just presented with a random list of
numbers.
That said, the capability of referring to the output of previous cells
via a notation like Out[17] is very handy, and a *lot* of users really
like it (Sage doesn't really have that). So a way to easily toggle
the numbers on and off like you suggest is probably best.
William
>>
>> By the way, if you print you don't see the results.
>
> Yes, I need to catch stdout and send it to the browsers. I added it to
> the TODO list.
>
> Many thanks for the feedback.
>
> Ondrej
>
> >
>
William Stein
Associate Professor of Mathematics
University of Washington
http://wstein.org
Ondrej Certik
Bradshaw<robe...@math.washington.edu> wrote:
>
> On Jul 20, 2009, at 9:02 PM, Ondrej Certik wrote:
>> Well, let me say that I really like to run things on the appengine,
>> rather than to constantly maintain our own servers. I see no reason
>> why the notebook cannot run on the appengine, only the AJAX would talk
>> to our own server with Sage to actually evaluate the cells (and for
>> many people, I think appengine itself could actually be enough). I
>> have to think though what the best way to transfer data to the
>> database with worksheets is though.
>
> +1, though for Sage we rely heavily on compiled code. I wonder how
> much introduced latency there would be if the backend were served on
> a university computer, and the front end in appengine.
I think none, it would be as fast as it is now (e.g. the browser
communicating directly with the engine).
I would like to decouple Sage as the *engine* from the rest. The
engine should handle evaluating cells and storing and retrieving the
state (I guess). Then it can be used in services like Google Wave that
Harald is experimenting with etc.
The AJAX in the browser should be talking directly to the engine (e.g.
just like it is now). Where the rest of it is running, that doesn't
really matter imho and it should be possible to run it on the
appengine.
Ondrej
William Stein
>
> On Tue, Jul 21, 2009 at 1:58 AM, Robert
> Bradshaw<robe...@math.washington.edu> wrote:
>>
>> On Jul 20, 2009, at 9:02 PM, Ondrej Certik wrote:
>
>>> Well, let me say that I really like to run things on the appengine,
>>> rather than to constantly maintain our own servers. I see no reason
>>> why the notebook cannot run on the appengine, only the AJAX would talk
>>> to our own server with Sage to actually evaluate the cells (and for
>>> many people, I think appengine itself could actually be enough). I
>>> have to think though what the best way to transfer data to the
>>> database with worksheets is though.
>>
>> +1, though for Sage we rely heavily on compiled code. I wonder how
>> much introduced latency there would be if the backend were served on
>> a university computer, and the front end in appengine.
>
> I think none, it would be as fast as it is now (e.g. the browser
> communicating directly with the engine).
involved instead of two? There would have to be a little extra
latency, i.e., whatever there is between appengine and the "sage
engine". That said, the internet is pretty fast these days :-). And
the scalability of a decoupled approach like we're talking about is a
big plus, if it works.
By the way, if you haven't already, I personally think you should
start a mailing list, web page, trac, etc. for a separate notebook
project, since you're already writing code. There's already some
confusion about where we are supposed to have this discussion -- and a
funny mix of sage-devel and codenode doesn't seem right.
> I would like to decouple Sage as the *engine* from the rest. The
> engine should handle evaluating cells and storing and retrieving the
> state (I guess). Then it can be used in services like Google Wave that
> Harald is experimenting with etc.
>
> The AJAX in the browser should be talking directly to the engine (e.g.
> just like it is now). Where the rest of it is running, that doesn't
> really matter imho and it should be possible to run it on the
> appengine.
>
> Ondrej
>
> >
>
Ondrej Certik
>
> On Tue, Jul 21, 2009 at 9:39 AM, Ondrej Certik<ond...@certik.cz> wrote:
>>
>> On Tue, Jul 21, 2009 at 1:58 AM, Robert
>> Bradshaw<robe...@math.washington.edu> wrote:
>>>
>>> On Jul 20, 2009, at 9:02 PM, Ondrej Certik wrote:
>>
>>>> Well, let me say that I really like to run things on the appengine,
>>>> rather than to constantly maintain our own servers. I see no reason
>>>> why the notebook cannot run on the appengine, only the AJAX would talk
>>>> to our own server with Sage to actually evaluate the cells (and for
>>>> many people, I think appengine itself could actually be enough). I
>>>> have to think though what the best way to transfer data to the
>>>> database with worksheets is though.
>>>
>>> +1, though for Sage we rely heavily on compiled code. I wonder how
>>> much introduced latency there would be if the backend were served on
>>> a university computer, and the front end in appengine.
>>
>> I think none, it would be as fast as it is now (e.g. the browser
>> communicating directly with the engine).
>
> How is it "none", given that there are now three separate computers
> involved instead of two? There would have to be a little extra
What I meant is that the latency in typing 1+1 into the cell and get
the output cell saying 2 should not change at all, because the
javascript in the browser sends a POST request to the Sage engine
(e.g. a web app with the url interface, just like it is now) and it
returns it back directly to the browser.
What changes is the database storage, e.g. either the javascript in
the browser, once it receives the output of the cells also sends it to
the appengine (or whenever the database is running), or the engine
sends it itself, I don't know yet which approach is better. So there
are some issues involved, like if one of those connections fail etc.
But as long as both connections are up and running, the user would not
recognize anything at all.
> latency, i.e., whatever there is between appengine and the "sage
> engine". That said, the internet is pretty fast these days :-). And
> the scalability of a decoupled approach like we're talking about is a
> big plus, if it works.
Right, it has to be tried to see if it works. But I think it's worthy.
>
> By the way, if you haven't already, I personally think you should
> start a mailing list, web page, trac, etc. for a separate notebook
> project, since you're already writing code. There's already some
> confusion about where we are supposed to have this discussion -- and a
> funny mix of sage-devel and codenode doesn't seem right.
Well, I hope codenode guys could pick this up and they would be the
notebook. I unfortunately probably can't spend too much time on this,
until september. But I wanted to get this going to see which approach
to take.
I wrote the above in about 2 days (roughly), but it's only the first
90%, e.g. the cells sort of works, but the rest 10%, like tab
completion, worksheets, saving. loading, publishing, users, fixing it
so that it works 100% in all browsers..... That would take a lot more,
and I can't do it yet. But I hope it's encouraging to all of you to
learn some AJAX too till September, so that we can work on this
together. :)
There is one more thing I want to try -- pyjamas, as pointed out
above. I already played with it yesterday, and what I saw so far is
*impressive*. So my next step will be to rewrite what I did into
pyjamas (e.g. just pure python both on the server and in the browser).
If that works and I think it could, well, that would be the way to go,
since I could debug all those functions like for calculating cursor
positions etc. in Python.
Ondrej
William Stein
Thanks for the clarification, since I clearly misunderstood you. Robert said "backend were served on a university computer, and the front end in appengine." You seem to be eliminating the frontend completely when computations are done. I.e., do you imagine appengine *just* serving some javascript and a database interface, and basically nothing else? So what would happen is the following:
1. User visits the appengine server and gets the javascript for the sage notebook (after authenticating).
2. User starts a worksheet. The javascript in the browser requests a "sage engine token", and the appengine allocates a "compute engine" somewhere for use by that user's worksheet.
3. The user types "factor(2^197-1)" and their javascript *directly* connects to the compute engine and runs the code "factor(2^197-1)". It also connects to the appengine and stores that "factor(2^197-1)" was input in the database.
4. The javascript in the browser gets back the answer to the factor query and displays the result.
5. The javascript in the browser later also stores the result in the app engine database.
I think there could be some weird security issues/tricks involved with the javascript in the browser directly doing AJAX calls to the "compute engine" above, but there are hacks to get around that. There's also twice the communications overhead between the user's javascript and remote machines than in the current Sage notebook model where everything goes through the notebook server. E.g., if the output of a Sage command (in step 4 and 5 above) is large, e.g., a 10MB image, then that image is going to go all over the place, both uploaded and downloaded, which will be incredibly expensive.
What changes is the database storage, e.g. either the javascript in
the browser, once it receives the output of the cells also sends it to
the appengine (or whenever the database is running), or the engine
sends it itself, I don't know yet which approach is better. So there
are some issues involved, like if one of those connections fail etc.
But as long as both connections are up and running, the user would not
recognize anything at all.
This is an interesting design. It hadn't occured to me before. It would be interesting to see whether it is any good or not (I can't tell).
I can tell you one thing, which is that when I start working on the notebook again seriously this September, my first goal will be to create a powerful system for simulating the load of n people all using the notebook at once in a potentially heterogenous way (say from several different computers, etc.). This testing code will be hopefully generic enough to work with codenode, sagenb, etc. I think having actual benchmark testing code will in the longrun be a better litmus test for designs than us just thinking about them in the abstract.
I could pronounce the design you suggest above as "bad" for several reasons, but what if I'm wrong and in fact the design above, with some tweaks and insights that would result from testing, turns out to be amazingly good?
Right, it has to be tried to see if it works. But I think it's worthy.
> latency, i.e., whatever there is between appengine and the "sage
> engine". That said, the internet is pretty fast these days :-). And
> the scalability of a decoupled approach like we're talking about is a
> big plus, if it works.
Well, I hope codenode guys could pick this up and they would be the
>
> By the way, if you haven't already, I personally think you should
> start a mailing list, web page, trac, etc. for a separate notebook
> project, since you're already writing code. There's already some
> confusion about where we are supposed to have this discussion -- and a
> funny mix of sage-devel and codenode doesn't seem right.
notebook. I unfortunately probably can't spend too much time on this,
until september. But I wanted to get this going to see which approach
to take.
Hey, same here. Yeah for September.
I wrote the above in about 2 days (roughly), but it's only the first
90%, e.g. the cells sort of works, but the rest 10%, like tab
completion, worksheets, saving. loading, publishing, users, fixing it
so that it works 100% in all browsers..... That would take a lot more,
and I can't do it yet. But I hope it's encouraging to all of you to
learn some AJAX too till September, so that we can work on this
together. :)
There is one more thing I want to try -- pyjamas, as pointed out
above. I already played with it yesterday, and what I saw so far is
*impressive*. So my next step will be to rewrite what I did into
pyjamas (e.g. just pure python both on the server and in the browser).
If that works and I think it could, well, that would be the way to go,
since I could debug all those functions like for calculating cursor
positions etc. in Python.
I strongly encourage you to test pyjamas with the above. I think that's the best possible next step.
-- William
Tim Dumol
>
> > It's working great in Firefox 3.5, Windows XP x32 and Linux x86_64.
>
> > I'm doing some work on converting the notebook to Jinja (
> > to switch the Django templating engine to Jinja.
>
> > I'd love to help in the notebook rewrite after I finish the
> > conversion. I can fork your project at that time, and help out.
>
> Awesome! I'll wait after you do it and then I'll just use your
> templates. Just use jinja, it works great and django can use it too.
>
> Ondrej
dependencies on the functions I replaced before I clean everything up.
The templates output pretty much the same output as the original
functions, as far as I can tell. I'll see if I can make things more
semantic after the migration -- <br>'s to <p>'s, and table layout to
CSS -- if there's no problem with that?

Dorian Raymer
I like what you have done!
This is very cool. The "notebook" is really the encapsulation of at least three different projects.
- A formal api interface to the Python or Sage interpreter (and that implementation of the interface for each of those systems)
- Some kind of canonical and portable persistent notebook format (and something to manage all your notebooks)
- The front end client (javascript/html/css) that is the notebook you actually use (really, a source code/text editor of which many projects simply trying to do this right (in the browser) exist)
In terms of distributing the components/responsibilities of the different parts (like what you are talking about with the AJAX computation requests to the sage server being different from the appengine frontend hosting, and then somehow integrating a possible third database element distinct from app engine (something I definitely want, because I want to own my data!!)), codenodes design is centered around this and has many cool (improving/improvable) solutions.
Although our current use case with app engine is a different permutation, as we are delegating all computation requests to it and keeping the data and frontend on our own server, the architecture is getting there to be able to do any permutation that makes sense.
I have been working on improving the backend and have recently made some great progress: http://github.com/deldotdr/codenode/commit/5a9ed5a19e0f71c48d8f62bb206f8b1aa347d1d6
Some of the key highlights:
- I want it to be trivial to add different backend engines as Plugins. This means things like Sage, and other non-python interpreters. There are a handful of major configuration items: path to interpreter bin, args, environment variables (the hardest part/most work for sage), and run path.
- frontend is able to know about multiple different backends (like app engine, a sage server, or another privately hosted server), each of those possibly having different engine plugins (i.e. Python and Sage at least).
- clear decoupling of the communication lines for administering all user data and backend permissions, getting/saving notebook data to a database, evaluating/tab completing/etc. code on an interpreter process.
It would be great to get feedback on this new stuff as I integrate it into the full system. There are a lot of design decisions in the same vein as your questions of the right way to separate the AJAX computation requests from saving to the database, etc.
Well, I hope codenode guys could pick this up and they would be the
>
> By the way, if you haven't already, I personally think you should
> start a mailing list, web page, trac, etc. for a separate notebook
> project, since you're already writing code. There's already some
> confusion about where we are supposed to have this discussion -- and a
> funny mix of sage-devel and codenode doesn't seem right.
notebook. I unfortunately probably can't spend too much time on this,
until september. But I wanted to get this going to see which approach
to take.
Cool! With codenode, we have strived to make the major components as decoupled as possible such that people can hack on any one of them (mostly) independent of the others. Like you, we really want to work on it all the time, full time, but we also have real jobs and other projects that take up our time. I think collaborating would be the best thing that could happen for the project and the evolution of the notebook.
We have put in significant effort in thought and code writing and, although it has not been very obviously presented in the past, we have the foundation for something that we strongly want to be the basis of the effort you are in the midst of now. We have been through the process you are in, and hopefully a fresh review of our source code (especially the javascript and the backend design) will resonate with your current thought process.
I wrote the above in about 2 days (roughly), but it's only the first
90%, e.g. the cells sort of works, but the rest 10%, like tab
completion, worksheets, saving. loading, publishing, users, fixing it
so that it works 100% in all browsers..... That would take a lot more,
and I can't do it yet. But I hope it's encouraging to all of you to
learn some AJAX too till September, so that we can work on this
together. :)
;-) Yes, it takes *a lot* more. A quick review of what codenode has sitting there already:
- Generalized notion of a cell in the notebook. Cells can contain anything, even more cells! This is great for handling different output cells (text, traceback, plots), different input formats, and doing col things like Mathematica does with nested sections -- maybe that is too much, but when used in the simplest case, it gets the job done smoothly. We have a cell id scheme worked out that allows any arbitrary addition, deletion, and rearrangement of cells.
- Tab completer, decoupled from cell evaluation. This has it's own javascript source code file, Completer.js
- Event Delegation and pretty simple (definitely refine-able) configuration of key + mouse combination event handling. This doesn't use the jQuery plugin yet, but it works great and shows how far down the path we have already gotten.
The sage notebook and codenode represent two extremes in design ideology/practicality, but they both already have great usable functionality supported by untold man hours of hard work and thought.
I think a lot of progress on a great generally usable notebook can be made with the help and drive of a third perspective like your own [Ondrej].
There is too much work remaining, work ranging from realizing un-implemented big features to last mile refinements, not to mention reconciling the awesome but coupled features of the sage notebook (plotting, interact, etc) into your (and codenode's) more general and decoupled model.
So, I am all for combining efforts and becoming more in tune with your end goal and motivation for improving the notebook.
-Dorian
Ondrej Certik
As to me, definitely use CSS for everything and remove all tables if
there are some. CSS is easy to customize by people.
Ondrej
Ondrej Certik
I agree with everything you wrote.
Only one suggestion -- could you take my simple frontend for the cells
and incorporate it in codenode? I mean how things *look* like, so that
it looks like the Sage notebook. The default codenode look & feel
doesn't work well in my browser, since I can't figure out where to
click to find the cell, the cursor changes in some weird way and
generally it's confusing to me etc. So that's a major problem, but the
fix is really easy, just change the bit of the javascript + CSS styles
and it will look like Sage. There could be some option to choose
between the two designs if you prefer the current codenode style.
Ondrej
Ondrej Certik
That's exactly correct.
Another possibility is to change 5) into 5'):
5') the Sage engine talks to the appengine database server directly.
The advantage of 5') over 5) is that the Sage engine should be running
on some fast network anyways (thus the communication Sage engine <->
app engine server will be fast), but the user's laptop can be on some
crappy connection.
>
> I think there could be some weird security issues/tricks involved with the
> javascript in the browser directly doing AJAX calls to the "compute engine"
> above, but there are hacks to get around that. There's also twice the
Right.
> communications overhead between the user's javascript and remote machines
> than in the current Sage notebook model where everything goes through the
> notebook server. E.g., if the output of a Sage command (in step 4 and 5
> above) is large, e.g., a 10MB image, then that image is going to go all
> over the place, both uploaded and downloaded, which will be incredibly
> expensive.
I agree, I think we should use 5'). E.g. if the database engine and
Sage engine is running on the same machine, that's the current design,
but if they are decoupled, but connected using fast internet, it could
work.
The appengine database backend has to have some notion of the engine
anyways, so it might as well retreive from it the results.
I agree that it might be too complex/tricky/error prone. I simply don't know.
>
>>
>> What changes is the database storage, e.g. either the javascript in
>> the browser, once it receives the output of the cells also sends it to
>> the appengine (or whenever the database is running), or the engine
>> sends it itself, I don't know yet which approach is better. So there
>> are some issues involved, like if one of those connections fail etc.
>> But as long as both connections are up and running, the user would not
>> recognize anything at all.
>
> This is an interesting design. It hadn't occured to me before. It would be
> interesting to see whether it is any good or not (I can't tell).
Me neither.
>
> I can tell you one thing, which is that when I start working on the notebook
> again seriously this September, my first goal will be to create a powerful
> system for simulating the load of n people all using the notebook at once in
> a potentially heterogenous way (say from several different computers,
> etc.). This testing code will be hopefully generic enough to work with
> codenode, sagenb, etc. I think having actual benchmark testing code will
> in the longrun be a better litmus test for designs than us just thinking
> about them in the abstract.
>
> I could pronounce the design you suggest above as "bad" for several reasons,
> but what if I'm wrong and in fact the design above, with some tweaks and
> insights that would result from testing, turns out to be amazingly good?
Exactly. I don't know myself and I am not sure about exact technical
details of my design, e.g. 5) vs 5') etc. But my motivation is that I
really want it to be able to run on the appengine completely if
needed, because there are tons of situations, where I just want to
show off some simple thing, be it sympy, or just some simple algorithm
in python and I really *don't* want to maintain my own server for
that.
At the same time however, I really would like to just create a simple
engine with web API (be it Sage, or anything else), and I would like
to maintain just this engine and if it dies, the frontend (running
somewhere else) would just use a different engine, or whatever.
So I would like to have that, but if it's possible to get everything
right and robust and fast, I simply don't know.
> I strongly encourage you to test pyjamas with the above. I think that's the
> best possible next step.
I will report later on this. It seems to work, but I can already see a
big issue -- it seems a bit slow (e.g. the generated javascript in the
browser). But it's too early to tell, once I implement the same thing,
we can then compare which approach is the best in the long run.
Ondrej
William Stein
more careful thought, the Sage engine has to have whatever
authentication credentials as the user, since the Sage engine suddenly
gets to change anything in the user's worksheets. This isn't
necessary a problem, but is something to think about.
>
>>
>> I think there could be some weird security issues/tricks involved with the
>> javascript in the browser directly doing AJAX calls to the "compute engine"
>> above, but there are hacks to get around that. There's also twice the
>
> Right.
>
>> communications overhead between the user's javascript and remote machines
>> than in the current Sage notebook model where everything goes through the
>> notebook server. E.g., if the output of a Sage command (in step 4 and 5
>> above) is large, e.g., a 10MB image, then that image is going to go all
>> over the place, both uploaded and downloaded, which will be incredibly
>> expensive.
>
> I agree, I think we should use 5'). E.g. if the database engine and
> Sage engine is running on the same machine, that's the current design,
> but if they are decoupled, but connected using fast internet, it could
> work.
>
able to open new outgoing connections to communicate with the database
server. This could be a problem if the sage engine is running in some
sort of locked down sandboxed environment. Again, this isn't
insurmountable, but you should keep it in mind.
> The appengine database backend has to have some notion of the engine
> anyways, so it might as well retreive from it the results.
>
> I agree that it might be too complex/tricky/error prone. I simply don't know.
things with a good design, you can sometimes build up very complicated
tricky systems that seem simple.
important for something like this, since javascript is already slow.

mmarco
cells in konqueror 3.5.10 (sage notebook doesn't look well in
konqueror, but most of the functionalities work).
Alex Clemesha
>> So, I am all for combining efforts and becoming more in tune with your end
>> goal and motivation for improving the notebook.
>
> I agree with everything you wrote.
>
> Only one suggestion -- could you take my simple frontend for the cells
> and incorporate it in codenode? I mean how things *look* like, so that
> it looks like the Sage notebook. The default codenode look & feel
> doesn't work well in my browser, since I can't figure out where to
> click to find the cell, the cursor changes in some weird way and
> generally it's confusing to me etc. So that's a major problem, but the
> fix is really easy, just change the bit of the javascript + CSS styles
> and it will look like Sage. There could be some option to choose
> between the two designs if you prefer the current codenode style.
I'll put it in as a setting, like the "open notebook in new window" setting
(which was motivated by you... thanks for that!)
Please keep requests like this coming.
--
I'm absolutely confident that the core architecture of codenode is
solid - a massive amount of effort has been put into designing it
to be formed from decouple pieces, making it easier to extend in
the long run. Dorian's detailed response describes this.
What codenode is still missing is the "last mile bits" from real world
users like yourself, and with your feedback and involvement,
we'll be able to create something that exactly solves the problems
you want to be solved.
-Alex
>
> Ondrej
>
> >
>
--
Alex Clemesha
clemesha.org

J Elaych
>
> There is one more thing I want to try -- pyjamas, as pointed out
> above. I already played with it yesterday, and what I saw so far is
> *impressive*. So my next step will be to rewrite what I did into
> pyjamas (e.g. just pure python both on the server and in the browser).
> If that works and I think it could, well, that would be the way to go,
> since I could debug all those functions like for calculating cursor
> positions etc. in Python.
>
> Ondrej
would compile the pyjamas python code into javascript, store it
on the server and send the js to the client browser.
William Stein
(1) Can pyjamas cleanly make use of arbitrary javascript libraries?
(2) Is there a list of nontrivial examples where pyjamas is actually
used to implement javascript apps?
-- William
Ondrej Certik
Yes. But you don't have to write javascript and if you do things
correctly, the same file executes on your desktop using python, thus
you can doctest the whole thing.
I already implemented the textbox resizing, here is the code:
---------------
import pyjd # this is dummy in pyjs.
from pyjamas.ui.RootPanel import RootPanel
from pyjamas.ui.Button import Button
from pyjamas.ui.HTML import HTML
from pyjamas.ui.Label import Label
from pyjamas import Window
from pyjamas.ui.TextArea import TextArea
from pyjamas.ui import KeyboardListener
def greet(fred):
print "greet button"
Window.alert("Hello, AJAX!")
class InputArea(TextArea):
def __init__(self, echo):
TextArea.__init__(self)
self.echo = echo
self.addKeyboardListener(self)
self.addClickListener(self)
self.set_rows(1)
self.setCharacterWidth(80)
def onClick(self, sender):
print "on_click"
def rows(self):
return self.getVisibleLines()
def set_rows(self, rows):
if rows in [0, 1]:
# this is a bug in pyjamas, we need to use 2 rows
rows = 2
# the number of rows seems to be off by 1, another bug in pyjamas
self.setVisibleLines(rows-1)
def cols(self):
return self.getCharacterWidth()
def occupied_rows(self):
text = self.getText()
lines = text.split("\n")
return len(lines)
def cursor_coordinates(self):
"""
Returns the cursor coordinates as a tuple (x, y).
Example:
>>> self.cursor_coordinates()
(2, 3)
"""
text = self.getText()
lines = text.split("\n")
pos = self.getCursorPos()
i = 0
cursor_row = -1
cursor_col = -1
#print "--------" + "start"
for row, line in enumerate(lines):
i += len(line) + 1 # we need to include "\n"
# print len(line), i, pos, line
if pos < i:
cursor_row = row
cursor_col = pos - i + len(line) + 1
break
#print "--------"
return (cursor_col, cursor_row)
def insert_at_cursor(self, inserted_text):
pos = self.getCursorPos()
text = self.getText()
text = text[:pos] + inserted_text + text[pos:]
self.setText(text)
def onKeyUp(self, sender, keyCode, modifiers):
#print "on_key_up"
x, y = self.cursor_coordinates()
rows = self.occupied_rows()
s = "row/col: (%s, %s), cursor pos: %d, %d, real_rows: %d" % \
(self.rows(), self.cols(), x, y, rows)
self.set_rows(rows)
self.echo.setHTML("Info:" + s)
def onKeyDown(self, sender, key_code, modifiers):
if key_code == KeyboardListener.KEY_TAB:
self.insert_at_cursor(" ")
print "TAB"
#def onKeyDownPreview(self, key, modifier):
# print "preview"
def onKeyPress(self, sender, keyCode, modifiers):
#print "on_key_press"
pass
if __name__ == '__main__':
pyjd.setup("../templates/Hello.html")
b = Button("Click me", greet, StyleName='teststyle')
h = HTML("<b>Hello World</b> (html)", StyleName='teststyle')
l = Label("Hello World (label)", StyleName='teststyle')
echo = HTML()
t = InputArea(echo)
RootPanel().add(b)
RootPanel().add(h)
RootPanel().add(l)
RootPanel().add(t)
RootPanel().add(echo)
pyjd.run()
---------------
And it mostly works, up to some bugs in pyjamas (like that the textbox
can't be set to just 1 row, only 2 rows or more), that I will try to
solve with pyjamas developers, hopefully they are simple to fix.
If you look at the cursor_coordinates() function, this is really PITA
to debug in javascript -- I mean, you essentially need tests for the
javascript etc. If this could be avoided, that'd be a huge win. The
generated javascript for the function above is:
cls_definition.cursor_coordinates =
pyjs__bind_method(cls_instance, 'cursor_coordinates', function() {
if (this.__is_instance__ === true) {
var self = this;
} else {
var self = arguments[0];
}
var text = self.getText();
var lines = text.split(String('\x0A'));
var pos = self.getCursorPos();
var i = 0;
var cursor_row = -1;
var cursor_col = -1;
var __temp_row = pyjslib.enumerate(lines).__iter__();
try {
while (true) {
var temp_row = __temp_row.next();
var row = temp_row.__getitem__(0); var
line = temp_row.__getitem__(1);
i += ( pyjslib.len(line) + 1 ) ;
if (pyjslib.bool((pyjslib.cmp(pos, i) == -1))) {
cursor_row = row;
cursor_col = ( ( ( pos - i ) +
pyjslib.len(line) ) + 1 ) ;
break;
}
}
} catch (e) {
if (e.__name__ != 'StopIteration') {
throw e;
}
}
return new pyjslib.Tuple([cursor_col, cursor_row]);
}
So that doesn't look bad. But it's definitely slower than it could be
if used javascript for loop directly. But as I said, let's wait until
I implement the whole thing and let's see. Also pyjamas allow to embed
javascript code, so we may write the critical code in javascript
itself.
Ondrej

Rob Beezer
> (1) Can pyjamas cleanly make use of arbitrary javascript libraries?
(its along the bottom edge of the map)
Demo: http://web2py.gdw2.com/maps/default/index
To my untrained eye it looks like there was some trivial overhead to
integrate the JQuery library, so it is not automatic. But maybe
"clean"?
Code: http://pastebin.com/fb45e73b
This is from the last post in:
http://groups.google.com/group/pyjamas-dev/browse_thread/thread/f403232f9216e135
Ondrej Certik
>
> On Tue, Jul 21, 2009 at 1:56 PM, J Elaych<micro...@gmail.com> wrote:
>>
>>
>>>
>>> There is one more thing I want to try -- pyjamas, as pointed out
>>> above. I already played with it yesterday, and what I saw so far is
>>> *impressive*. So my next step will be to rewrite what I did into
>>> pyjamas (e.g. just pure python both on the server and in the browser).
>>> If that works and I think it could, well, that would be the way to go,
>>> since I could debug all those functions like for calculating cursor
>>> positions etc. in Python.
>>>
>>> Ondrej
>>
>> Well technically it wouldn't be 'python in the browser', right? You
>> would compile the pyjamas python code into javascript, store it
>> on the server and send the js to the client browser.
>
> (1) Can pyjamas cleanly make use of arbitrary javascript libraries?
I think it can:
http://groups.google.com/group/pyjamas-dev/browse_thread/thread/639dffd00d6b7c7/
but I am still learning it.
>
> (2) Is there a list of nontrivial examples where pyjamas is actually
> used to implement javascript apps?
the examples directory is full of interesting examples --- well, it
depends what you mean nontrivial. Let me just implement it and let's
see after it.
Ondrej

Rado
(which I should polish and submit in the next few days), I think Sage
will greatly benefit from notebook rewrite. It is very possible to
make front-end applets like the graph editor once it is easy to talk
to the sage kernel, without going through the notebook.
However, both solutions (codenode and ondrej) seem to complicate
things for single users by making them set-up two servers (one not
even local). Is there a way to bundle django engine with twisted's
sage server? Or at least ship it with sage and start it on a separate
port when 'notebook' is executed. So that the user can have the sage
computational engine and the new notebook (probably done with django's
web platform) on the same machine.
Also I think codenode has a lot of potential, but it is lost on non-
Mathematica users who find it hard to manipulate cells. I teach
Mathematica-based math courses and know exactly how non-intuitive
students find the cell structure at first. Actually I thought Sage
model is weird at first (being used to Mathematica), by letting me
jump from cell to cell and erasing them so easy. Now I preferred it to
Mathematica's rigidness.
Rado

ghtdak
This thread has gotten long and there are many subjects embedded
within.
One of the problems I've had with the notebook implementation is that
the sage process supporting the notebook computation blocks on the
pipe between itself and the twistd server which spawns it. This means
that one can't build an asynchronous event handler without using
threads.
More conventional web server architectures use a callback style for
invocation making it much easier to splice in other events for
handling by the main thread (this is the general asynchronous
programming model and the heart of how Twisted works)
Perhaps it is a foregone conclusion that this approach will be taken
in the rewrite. if not, I'd like to suggest that it is an important
consideration.
-glenn

Dr. David Kirkby
I don't know about how the web server is implemented. I know it did not
work on my Solaris box, but that is another matter.
But actually including Apache might be a sensible choice. A lot of
people know how to administer Apache. It offers a lot of flexibility.
You can for example only serve pages to particular IP addresses.
Worth a thought anyway.
dave
Ondrej Certik
here is an early preview of the pyjamas version:
http://2.latest.pythonnb.appspot.com/
So far my experience is:
* it doesn't work in IE8 (that's a showstopper)
* it's fast enough
* implementing the cursor positions and resizing was a piece of cake
(I was very impressed)
* learning the whole framework took me some time, one has to read sources a lot
* if it doesn't work, it's a bit difficult to debug (because it's not
just javascript, I need to figure out where I made the mistake in the
python code), I basically use git a lot and always do a small change
and test, small change and test. If it fails, I break my changes in
half and test, etc.
Essentially, pyjamas provide a complete DOM access (just like jQuery),
but in Python, and then builds its own widgets on top of it.
I am now learning how to do AJAX with it. So far only the cursor
movement and cells work (the focus is not yet shown by a blue line,
I'll do that later). Try this:
def f(x):
<hit TAB couple times>
and then hit <backspace>, you will see that it deletes 4 spaces, but
in a clever way, e.g. if you are at a position 7, it goes to 4 first
and then to 0. This is how my vim is setup for python editing and I
like it a lot.
Let me know if it works in your browser so far. I only tested firefox
3.5, that works fine. IE8 doesn't load the javascript, e.g. you will
see no textbox. Also, in Firefox I get frequent error messages
(printed in the actual HTML):
"
JavaScript Error: Permission denied to get property
HTMLDivElement.parentNode at line number 9254. Please inform
webmaster.
"
It's a bug in pyjamas.
Ondrej
Alex Clemesha
>
> Having read a bit of the old notebook code, for the graph editor
> (which I should polish and submit in the next few days), I think Sage
> will greatly benefit from notebook rewrite. It is very possible to
> make front-end applets like the graph editor once it is easy to talk
> to the sage kernel, without going through the notebook.
>
> However, both solutions (codenode and ondrej) seem to complicate
> things for single users by making them set-up two servers (one not
> even local). Is there a way to bundle django engine with twisted's
> sage server?
and that is twisted. Django is running off of twisted's wsgi implementation.
The command-line utility, "codenode-admin", hides all this,
making what happens behind the scenes totally transparent to the
normal, every day user.
Or at least ship it with sage and start it on a separate
> port when 'notebook' is executed. So that the user can have the sage
> computational engine and the new notebook (probably done with django's
> web platform) on the same machine.
> Also I think codenode has a lot of potential, but it is lost on non-
> Mathematica users who find it hard to manipulate cells. I teach
> Mathematica-based math courses and know exactly how non-intuitive
> students find the cell structure at first. Actually I thought Sage
> model is weird at first (being used to Mathematica), by letting me
> jump from cell to cell and erasing them so easy. Now I preferred it to
> Mathematica's rigidness.
we must adopt the easier-to-user sage style interface. This will be done soon.
thanks,
Alex
>
> Rado
> >
>
--
Alex Clemesha
clemesha.org
Ondrej Certik
Also cell joining is not yet implemented. But it works in the Chrome
browser, so at least something.
Ondrej
Ondrej Certik
I implemented the AJAX thing as well, here is a working example (sort of):
http://3.latest.pythonnb.appspot.com/media_files/output/index.html
Besides what I wrote above, there is some problem with CSS styles,
which shows up when you evaluate some cell and see the output, the
"insert new cell blue thin line" is misplaced.
I implemented it in the "pyjamas" branch in my repository (link is on
the webpage), so there are some leftovers (like the jQuery.js library,
which is *not* needed anymore, etc.). The django backend didn't change
at all and now the whole notebook doesn't contain a single line of
javascript (everything is pure python). I think that itself is pretty
impressive. Here is the file, that gets translated:
http://github.com/certik/notebook/blob/001b4ddf444b480822adf9216419afa1adaf4818/media/index.py
In terms of lines of code, it's about the same as my previous version
in javascript:
http://github.com/certik/notebook/blob/ca4e6a90a3f0c10c78c8c99d4d55055ba5019c28/templates/index.html
But there are still some things missing (e.g. joining and deleting the
cells). The python code should be refactored first though, there
should be a class Cell, that should have references to it's children,
like the input/output cells etc. and this class should now how to turn
on/off the output cell etc. Currently I am using the DOM directly in a
bit hackish way, this should be polished. Essentially I was fighting
pyjamas to access the elements in the DOM, for example jQuery's
analogs of insert before and after are not available (resp. it's
tricky).
Nevertheless, overall, I like the pyjamas approach and the above
things can be fixed. Also now there is a nice possibility to mock up
the controls and run regular python unittests on the whole thing.
That's a big plus.
The remaining big problem is the IE8 support and the errors that
sometimes popup in firefox. I reported it here:
http://groups.google.com/group/pyjamas-dev/browse_thread/thread/f170c3709c7f12ed
and I was told I am pretty much on my own with IE8. So that's very
disappointing of course, but maybe the fix is easy. If it is not, then
that's a big problem.
Ondrej

javier
10.4 I cannot see the outputs. In Firefox, I also get some
"JavaScript Error: Permission denied to access property 'parentNode'
from a non-chrome context at line number 9254. Please inform
webmaster."
The AJAX version (the one starting with a 3) throws a
" JavaScript Error: Permission denied to access property 'parentNode'
from a non-chrome context at line number 9488. Please inform
webmaster."
in Firefox. In Safari, no JS errors, but the output text appears
"cut" (you can only see the lower half of it) until you mouse over
it.
Will test under linux when get to my office.
Cheers
Javier
> In terms of lines of code, it's about the same as my previous version
> in javascript:
>
> But there are still some things missing (e.g. joining and deleting the
> cells). The python code should be refactored first though, there
> should be a class Cell, that should have references to it's children,
> like the input/output cells etc. and this class should now how to turn
> on/off the output cell etc. Currently I am using the DOM directly in a
> bit hackish way, this should be polished. Essentially I was fighting
> pyjamas to access the elements in the DOM, for example jQuery's
> analogs of insert before and after are not available (resp. it's
> tricky).
>
> Nevertheless, overall, I like the pyjamas approach and the above
> things can be fixed. Also now there is a nice possibility to mock up
> the controls and run regular python unittests on the whole thing.
> That's a big plus.
>
> The remaining big problem is the IE8 support and the errors that
> sometimes popup in firefox. I reported it here:
>
Ondrej Certik
>
> For the pyjamas version, with Firefox 3.5.1 and Safari 4 under OS-X
> 10.4 I cannot see the outputs. In Firefox, I also get some
>
> "JavaScript Error: Permission denied to access property 'parentNode'
> from a non-chrome context at line number 9254. Please inform
> webmaster."
>
> The AJAX version (the one starting with a 3) throws a
> " JavaScript Error: Permission denied to access property 'parentNode'
> from a non-chrome context at line number 9488. Please inform
> webmaster."
> in Firefox. In Safari, no JS errors, but the output text appears
> "cut" (you can only see the lower half of it) until you mouse over
> it.
>
> Will test under linux when get to my office.
Many thanks for testing it. That's a bad news. On the very top of
pyjamas website they wrote:
"
Also, the AJAX library takes care of all the browser interoperability
issues on your behalf, leaving you free to focus on application
development instead of learning all the "usual" browser
incompatibilities.
"
But the reality is that it works, unless you run Firefox and unless
you run linux. :(
We'll see if it can be fixed. If not, we'll have to abandon this
approach and just use jQuery.
Ondrej
Ondrej Certik
[..]
>
> But the reality is that it works, unless you run Firefox and unless
> you run linux. :(
I mean as long as.
O.
ghtdak
On Jul 21, 6:40 pm, "Dr. David Kirkby" <david.kir...@onetel.net>
wrote:
WSGI and run Django quite well...
http://blog.dreid.org/2009/03/twisted-django-it-wont-burn-down-your.html
At least there are alternatives to apache which might be simpler.
The core question remains: While the presentation layer support is
defined by django, pyjamas etc, the integration with the underlying
sage process process is the issue, not the web presentation.
In the current architecture, a twistd daemon spawns a notebook server
which is responsible for doing "sage" stuff. twistd is fully
asynchronous, but the notebook process itself is a pexpect based
blocking process connected with pipes to twistd. As such, the block
on read by pexpect precludes the sage process servicing asynchronous
events.
IMHO, this architecture is incorrect and limited... Perhaps this is
part of what is being rethought... if not, I believe it should be.
A preferable architecture is an event loop which dispatches requests
within the sage process. Since Sage is written in python, I would
suggest Twisted for this but there might be better alternatives (I'd
be surprised, but its possible)
Using this approach, one could easily add other elements to the core
event loop to support asynchronous processing (timers, communication,
etc) without threads which are, in this case, unnecessary. Threads
when necessary are bad enough, when they're introduced because of
unnecessary blocking, one gets all the threading nightmare without any
benefit. (reminds me of health care reform)
Another benefit is that since asynchronous event processing is the
widely accepted approach to this type of problem, there are lots of
libraries / packages to "make it so".
-glenn
>
> dave
William Stein
3007 of worksheet.py):
try:
done, out, new = S._so_far(wait=wait,
alternate_prompt=SAGE_END+str(self.synchro()))
except RuntimeError, msg:
verbose("Computation was interrupted or failed.
Restarting.\n%s"%msg)
self.__comp_is_running = False
self.start_next_comp()
return 'w', C
The Sage notebook server does a blocking read from the
pexpect-controlled subprocess for "wait" seconds. The default value
of wait is 0.2 seconds. So indeed there is a block, but it is never
for more than 0.2 seconds. During that time other asynchronous
events can't be dealt with.
> IMHO, this architecture is incorrect and limited... Perhaps this is
> part of what is being rethought... if not, I believe it should be.
>
> A preferable architecture is an event loop which dispatches requests
> within the sage process. Since Sage is written in python, I would
> suggest Twisted for this but there might be better alternatives (I'd
> be surprised, but its possible)
>
> Using this approach, one could easily add other elements to the core
> event loop to support asynchronous processing (timers, communication,
> etc) without threads which are, in this case, unnecessary. Threads
> when necessary are bad enough, when they're introduced because of
> unnecessary blocking, one gets all the threading nightmare without any
> benefit. (reminds me of health care reform)
>
> Another benefit is that since asynchronous event processing is the
> widely accepted approach to this type of problem, there are lots of
> libraries / packages to "make it so".
>
> -glenn
>
>>
>> dave
> >
>
ghtdak
saying:
The notebook "server" is doing a blocking read with a timeout. The
server is a twistd process which multiplexes and processes in support
the browsers.
The "pexpect-controlled subprocess" is where Sage itself is.
The issue I was raising was with the latter (subprocess) although I
now think the server implementation might also be an issue.
when twisted spawns a sub-process, typically one registers a callback
to handle information from that sub-process. There should be no
reason to check for input. Generally a callback for signals is also
registered to sense the sub-process dying, the pipe being disconnected
etc. Unless I misunderstand (very possible), you're "polling" the set
of spawned Sage sub-processes for data.
While that doesn't sound good either, thats not the problem I was
describing.
My primary problem is that the Sage subprocess is blocking forever on
the other side of the pipe when its not computing... Therefore, I
can't have a Sage sub-process that I'm using in the notebook that is
also able to communicate with other processes as I can't
asynchronously receive data (or get timing interrupts). I've gotten
around this in the past by using threads as it was the only choice I
had.
-glenn
William Stein
> The "pexpect-controlled subprocess" is where Sage itself is.
> The issue I was raising was with the latter (subprocess) although I
> now think the server implementation might also be an issue.
>
> when twisted spawns a sub-process, typically one registers a callback
> to handle information from that sub-process.
The notebook server spawns that subprocess and controls it using pexpect.
> There should be no
> reason to check for input. Generally a callback for signals is also
> registered to sense the sub-process dying, the pipe being disconnected
> etc. Unless I misunderstand (very possible), you're "polling" the set
> of spawned Sage sub-processes for data.
> While that doesn't sound good either, thats not the problem I was
> describing.
>
> My primary problem is that the Sage subprocess is blocking forever on
> the other side of the pipe when its not computing... Therefore, I
> can't have a Sage sub-process that I'm using in the notebook that is
> also able to communicate with other processes as I can't
> asynchronously receive data (or get timing interrupts). I've gotten
> around this in the past by using threads as it was the only choice I
> had.
problem, without further clarification I don't think it will get fixed
in the near future.
William
ghtdak
>
> > My primary problem is that the Sage subprocess is blocking forever on
> > the other side of the pipe when its not computing... Therefore, I
> > can't have a Sage sub-process that I'm using in the notebook that is
> > also able to communicate with other processes as I can't
> > asynchronously receive data (or get timing interrupts). I've gotten
> > around this in the past by using threads as it was the only choice I
> > had.
>
> Thanks for the clarification. Since I don't really understand the
> problem, without further clarification I don't think it will get fixed
> in the near future.
its done servicing a request from the server. Instead of entering an
event loop, it blocks on the pipe.
The alternative would be to return after any request to an event
loop. Clearly, the primary requestor would be the notebook server,
but if you had a general event loop, the user could register any
number of other asynchronous sources or timers to respond to.
The adjustment I propose is in the sub-process (and probably would
extend this to the notebook but I'll withhold that for the time
being). Instead of initializing and entering the read-process-write
cycle, where read blocks waiting for a request, the sub-process would
initialize, register a callback to handle requests from the server
pipe, and enter the event loop. When a request came in, the primary
sage callback would "do the right thing" and return the result, hence
returning to the event loop.
Now, if a user wanted to handle other events or timers, they would
simply add those asynchronous systems to the event loop using whatever
means were provided. This is, essentially, the purpose of the Twisted
Reactor.
This sub-process adjustment could (maybe) be done initially without
changing anything on the notebook itself. The pipe callback would
receive the string, call a slightly modified sub-process method, get
the result and return it. Even if there are pexpect elements in the
sub-process, the callback could feed that.
Of course, once you put an event loop in the sub-process, much of
pexpect probably becomes unnecessary. Seems to me that Twisted could
do the spawning of the twisted sub-process and just shuffle strings
across. I don't really know pexpect but my guess is the things it
handles are also handled by twisted (although I don't actually know).
Its doubtful that there is sufficient complexity that pickle couldn't
handle the marshalling of data across the pipe.
Once this change was made, you'd have a full infrastructure with which
to build much more flexible applications yet still have the notebook
interface. This would also facilitate building distributed
computation engines, data collectors etc.
Furthermore, as things evolved, truly dynamic AJAX could be built
because the underlying Sage process could be asynchronously receiving
data, talking with other Sage processes, periodically polling other
servers (e.g. yahoo finance)
It seems this would be a fairly easy task and have substantial
payoff. I would have done it myself, but got bogged down when looking
through the pexpect code and the strings shoved over the pipe. I
figured that a few hours with the author would save a lot of time but
the runaway stack interfered.
-glenn
>
> William
>
>
>
>
>
> > -glenn
>
Dorian Raymer
Basically, the problem is that the Sage sub-process loses control when
>
> > My primary problem is that the Sage subprocess is blocking forever on
> > the other side of the pipe when its not computing... Therefore, I
> > can't have a Sage sub-process that I'm using in the notebook that is
> > also able to communicate with other processes as I can't
> > asynchronously receive data (or get timing interrupts). I've gotten
> > around this in the past by using threads as it was the only choice I
> > had.
>
> Thanks for the clarification. Since I don't really understand the
> problem, without further clarification I don't think it will get fixed
> in the near future.
its done servicing a request from the server. Instead of entering an
event loop, it blocks on the pipe.
The alternative would be to return after any request to an event
loop. Clearly, the primary requester would be the notebook server,
The essence of what you have described is architecture of Codenode. With out getting too much into a side by side comparison, this is how it works using our terminology:
An Engine is a computation process (like what you call a Sage sub-process).
An Engine contains two parts: First part, an object representing the Python (or Sage) interpreter, with methods like evaluate, and tab complete. Second part, a simple RPC server that adapts the interpreter object to a network transport; the current working implementation is an XML-RPC server.
The Interpreter object knows nothing about the RPC server, and the RPC server only has to map it's rpc methods to the interpreter object methods.
A Backend server creates and manages Engines.
The Backend server is a Twisted event loop.
It spawns, monitors, and terminates Engine Processes.
It relays all notebook AJAX requests to the appropriate engine via an XML-RPC client (which is non-blocking).
Since the Backend is a Twisted event loop, it handles all process spawning/monitoring, AJAX requests, and XML-RPC requests totally asynchronously.
It has no dependencies on the interpreter libraries that it runs, and does not need to understand the data going in and out of the engines.
Have a look at all the pieces currently work here.
I am currently improving this Backend concept and have a completely new iteration of code (still in development) that should be a bit more digestible (it's cleaner, among other improvements).
Once this change was made, you'd have a full infrastructure with which
to build much more flexible applications yet still have the notebook
interface. This would also facilitate building distributed
computation engines, data collectors etc.
Yes! Exactly. Combined with the third element (called the Frontend web application server who's most important job is storing users notebook data in a database), you have distributed notebook computation. We have successfully done deployments where the Frontend runs on one server, and the Backend on another server, usually in another City!
When the next piece of development is finished, a Frontend will be capable of supporting multiple Backends, again, no matter where they are on the network.
Furthermore, as things evolved, truly dynamic AJAX could be built
because the underlying Sage process could be asynchronously receiving
data, talking with other Sage processes, periodically polling other
servers (e.g. yahoo finance)
This is interesting, and sounds like something different than just a "Computation Engine".
I interpret this as a formalization of some kind of information base into a service accessible by the the notebook Engine processes.
The simple limit of this is the formalization of how a processes OS Environment Variables are set. For example, I could want to set up a environment supporting scientific analysis, so I would want to configure numpy and scipy to be in my Engine process python path.
This environment could also facilitate access to some kind of data set, like one produced by an Astrophysicist's galaxy simulation. The data set could be a file, a set of files, etc. Or, in the large limit, and coming back to your example, it could be a network service explicitly supported by the Backend, with accessibility permissions from each engine process explicitly configurable.
I'm not sure it makes sense, architecturally, for an Engine process to run an event loop, because it's principal purpose is to execute arbitrary code, and that must be generally assumed to be a blocking procedure. Maybe you can elaborate more on this idea; it's very interesting.
Take a look at codenode!
-Dorian
ghtdak
On Wed, Jul 22, 2009 at 10:11 PM, ghtdak <gl...@tarbox.org> wrote:
8747088439efce423cefd680eab2...>,
simple
RPC
8747088439efce423cefd680eab2...>that
working implementation is an XML-RPC server.
we really want is a "Sage Service" which can lie under any number of
transports. XML-RPC is certainly consistent with that approach
The Interpreter object knows nothing about the RPC server, and the
RPC
server only has to map it's rpc methods to the interpreter object
methods.
A Backend server creates and manages Engines.
The Backend server is a Twisted event loop.
It spawns, monitors, and terminates Engine Processes.
It relays all notebook AJAX requests to the appropriate engine via
an
XML-RPC client (which is non-blocking).
between a request and a response. This can be painful to implement
which is why Twisted introduces the deferred for a one time response
and more general callbacks when any number of responses (or
invocations in the case of peer-to-peer) may happen. None of this is
trivial and they don't call it Twisted for nothing, but once you
understand the foundation and rationale, it becomes pretty obvious.
Since the Backend is a Twisted event loop, it handles all process
spawning/monitoring, AJAX requests, and XML-RPC requests totally
asynchronously.
It has no dependencies on the interpreter libraries that it runs,
and
does
not need to understand the data going in and out of the engines.
chose to put authentication / encryption in this layer. Additionally,
pre and post processing can be added here leaving the "engines"
generic. But this is outside the scope of the discussion...
Have a look at all the pieces currently work
8747088439efce423cefd680eab2...>
.
completely
new
8b7658ebc51e7ab005e950f373a1...>(still
cleaner,
among other improvements).
> Once this change was made, you'd have a full infrastructure with
which
> to build much more flexible applications yet still have the
notebook
> interface. This would also facilitate building distributed
> computation engines, data collectors etc.
Yes! Exactly. Combined with the third element (called the Frontend
web
application server who's most important job is storing users
notebook
data
in a database), you have distributed notebook computation. We have
successfully done deployments where the Frontend runs on one
server,
and the
Backend on another server, usually in another City!
When the next piece of development is finished, a Frontend will be
capable
of supporting multiple Backends, again, no matter where they are
on
the
network.
Typically, LAN comms failure modes are less severe than WAN and often
involve a bunch more code to handle this wackiness... but this is also
painful stuff better left for you younger / more energetic folk... Too
many years spent on network failure issues myself... but its
fascinating and painful, two of my (former) favorites.
> Furthermore, as things evolved, truly dynamic AJAX could be
built
> because the underlying Sage process could be asynchronously
receiving
> data, talking with other Sage processes, periodically polling
other
> servers (e.g. yahoo finance)
This is interesting, and sounds like something different than just
a
"Computation Engine".
I interpret this as a formalization of some kind of information
base
into a
service accessible by the the notebook Engine processes.
was saying is that blocking is bad. I usually also say that Threads
are dangerous / hard... when one introduces Threads to get around
unnecessary blocking, we approach insane.
In my case, I have a need for the sage process to access other
"stuff" (technical term) but am unable to do it in the "main" sage
notebook thread because its sucking on a dry pipe from the twisted
server most of its life... so I had to do some tricky threaded
nonsense to get around it.
The simple limit of this is the formalization of how a processes
OS
Environment Variables are set. For example, I could want to set up
a
environment supporting scientific analysis, so I would want to
configure
numpy and scipy to be in my Engine process python path.
This environment could also facilitate access to some kind of data
set, like
one produced by an Astrophysicist's galaxy simulation. The data
set
could be
a file, a set of files, etc. Or, in the large limit, and coming
back
to your
example, it could be a network service explicitly supported by the
Backend,
with accessibility permissions from each engine process explicitly
configurable.
I'm sure all this is right but I was attacking a much simpler first
step. I currently have most of what I'm proposing built for my uses
and the technical configuration details are somewhat orthogonal to the
fundamental axioms... the most basic being "blocking is bad"
I'm not sure it makes sense, architecturally, for an Engine
process to
run
an event loop, because it's principal purpose is to execute
arbitrary
code,
and that must be generally assumed to be a blocking procedure.
Maybe
you can
elaborate more on this idea; it's very interesting.
First, why not. In the case I believe you're making, you're talking
about compute bound. If you're compute bound, you're bound. If you
have a lot of compute bound yet need interactive response, then you're
into multiple threads either through multi-process integration or
multi-threading. The former being more generally termed "message
passing" and the latter being "shared memory" architecture.
But, when not computing and is blocking on a read, it is an event loop
but masked to accept a single event. The simplest event loop example
is probably the unix select() statement where a set of file
descriptors are being listened to along with a timeout... when the
select returns its because something was received (or a write
operation completed) or a timeout occurred. Most of the higher layers
in an event loop are simply mechanisms to handle what can often become
very nasty code.
Sucking on a single pipe is a select statement with only one file
descriptor. But its still an event loop.
On the other hand, if one were to write a bunch of code to do request-
response processing, with an arbitrary number of requesters talking to
a bunch of different object instances in a process, it can get pretty
ugly. The deferred manages much of this plumbing although one needs
to become comfortable with getting a "promise" for a result at some
point in the future (which is what other asynchronous systems
sometimes call their deferreds)
But, once you get over that part, its trivial to have hundreds or
thousands of conversations going on with all the complexity being
hidden inside the reactor and the state maintained between the various
target objects and information in the deferred... all the while
avoiding any need for thread synchronization and its dual, the lack of
required synchronization causing much hair loss in us older folk.
Now, in the case of the sage notebook, the idea is, basically, that
there is state within the sage process which comes from more than one
source during the session. If I were to make an outgoing request, I
wouldn't be able to simultaneously wait for the response and wait for
requests from the browser simultaneously. My choice then becomes
block on the response which hangs the notebook, or block on the
notebook hoping that I get the thread of control back and whatever
response I got is in the buffer.
In the more general case, if I were receiving an outside feed (say
financial tick data) I would need an entirely separate process which
would then be polled if I wanted to use the notebook / sage for
exploitation. This is a bunch of extra and unnecessary work.
Then we get into a couple of areas that are very much related. The
first is distributed computing. Ideally, my "primary" sage process
should be able to farm out work and manage the overall set of
computations while I'm watching / doing other stuff in the notebook.
I shouldn't need to separate out a "coordinator" and shove state
around which naturally lives there.
Additionally, with AJAX, the browser code itself may be
asynchronous... meaning the sage notebook might send stuff up based on
timed events, or external communications from data sources or
indicating that a set of farmed out processes have completed.
In any of these cases, the critical element for implementation is the
event loop which serves as the management system to facilitate the
required multiplexing.
Lastly, none of this costs anything in terms of performance or code.
Twisted is already part of sage and it has a huge amount of
functionality supporting just about anything a normal human would
need. In fact, I used twisted in the sage notebook to do the things I
describe above although I needed to put twisted in a separate thread
and manage the threading issues with synchronization etc. It wasn't
all that bad but was unnecessary and is likely to bite me one of these
days with an intermittent / non-reproduce-able bug as threading tends
to do.
More generally, Sage needs a real architecture for distributed
computing which would facilitate combining multiple processes with
varying capabilities fairly easily. This is relatively simple to
accomplish given the tools available but some of the mechanisms
currently in place are somewhat dense... in particular the pexpect
code and the strings of python inside the python code... and the
special case handling etc... I have looked a couplea times and believe
that trying to decode its functionality is pretty hard so sorta needed
william / mabshoff to pull it off. Unfortunately, as I said earlier,
we never did get around to it.
But, since you're poking the beast anyways, we might as well slay the
dragon while we're there.
-glenn
-Dorian
> It seems this would be a fairly easy task and have substantial
> payoff. I would have done it myself, but got bogged down when
looking
> through the pexpect code and the strings shoved over the pipe.
I
> figured that a few hours with the author would save a lot of
time but
> the runaway stack interfered.
> -glenn
> > William
> > > -glenn
Glenn H. Tarbox, PhD || 206-274-6919
http://www.tarbox.org
Minh Nguyen
The following sage-devel thread is also about using XML-RPC with Sage:
http://groups.google.com/group/sage-devel/browse_thread/thread/202f9b2323d2771b/71fd656651eceb89
--
Regards
Minh Van Nguyen
Pat LeSmithe
> On Wed, Jul 22, 2009 at 2:19 PM, ghtdak<gl...@tarbox.org> wrote:
> > My primary problem is that the Sage subprocess is blocking forever on
> > the other side of the pipe when its not computing... Therefore, I
> > can't have a Sage sub-process that I'm using in the notebook that is
> > also able to communicate with other processes as I can't
> > asynchronously receive data (or get timing interrupts). I've gotten
> > around this in the past by using threads as it was the only choice I
> > had.
* Start, monitor, stop, and/or steer a long-running computation from
a browser. The computation runs in a main loop that periodically
checks for incoming messages upon which to act and sends out new
messages as necessary.
* Share a persistent instance of the Sage kernel among several open
worksheets, perhaps with a remote "desktop" capability, to
collaborate, teach, troubleshoot, etc. This could be a bit wavy.
* Filter data automatically through a sequence of independent
worksheet processes.
Pat LeSmithe
Oops. I should have noticed and clicked on "Newer >", where I might
have read about several examples. I apologize.
Robert Bradshaw
>
> On Jul 22, 9:23 pm, William Stein <wst...@gmail.com> wrote:
>> On Wed, Jul 22, 2009 at 2:19 PM, ghtdak<gl...@tarbox.org> wrote:
>>> My primary problem is that the Sage subprocess is blocking
>>> forever on
>>> the other side of the pipe when its not computing... Therefore, I
>>> can't have a Sage sub-process that I'm using in the notebook that is
>>> also able to communicate with other processes as I can't
>>> asynchronously receive data (or get timing interrupts). I've gotten
>>> around this in the past by using threads as it was the only choice I
>>> had.
It sounds like you're trying to use the notebook as a monitor for
long-running processes, which it wasn't designed for, but could be done.
>
> Are the following relevant, realistic examples? I wish to...
>
> * Start, monitor, stop, and/or steer a long-running computation from
> a browser. The computation runs in a main loop that periodically
> checks for incoming messages upon which to act and sends out new
> messages as necessary.
Sounds like dsage (or what dsage should become).
> * Filter data automatically through a sequence of independent
> worksheet processes.
Again, sounds a lot like what dsage should have been.
- Robert
Robert Bradshaw
It might be a bit off topic, but personally I think an actual multi-
threaded app, where some threads may be blocked (and that's not a
problem because the other threads can continue on) is sometimes
easier to reason about then having to do everything asynchronously.
The asynchronous model works well when processing each event is
relatively quick or has a natural callback, but otherwise it often
feels like having to manually enforce multitasking so as to not block
the entire reactor. Multithreading will have to be introduced at one
level or another to scale the notebook to more than a single
processor anyways.
- Robert
William Stein
Bradshaw<robe...@math.washington.edu> wrote:
> Multithreading will have to be introduced at one
> level or another to scale the notebook to more than a single
> processor anyways.
>
> - Robert
Huh? Why? I don't see any need for multithreading to solve the
above problem, or rather I don't understand what problem you're
talking about. The notebook already scales to more than a single
processor.
I also now know precisely what Glenn Tarbox's original problem is,
since I've recently also experimented with using the Interactive
Broker's API from the notebook. It's an interesting nontrivial
problem. I hope to provide some demo code for Glenn once I work this
out...
-- William
Robert Bradshaw
>
> On Wed, Aug 19, 2009 at 1:19 AM, Robert
> Bradshaw<robe...@math.washington.edu> wrote:
>> Multithreading will have to be introduced at one
>> level or another to scale the notebook to more than a single
>> processor anyways.
>>
>> - Robert
>
> Huh? Why? I don't see any need for multithreading to solve the
> above problem, or rather I don't understand what problem you're
> talking about. The notebook already scales to more than a single
> processor.
I am talking about the case where there are enough users that the notebook
process itself becomes the bottleneck. It all depends on how lightweight
the shuffling data between the underlying processes and the browser is,
and how many concurrent users one wants to support for a single notebook.
In the asynchronous model there is only one thread handling all of the
connections. (Also, anything long-running, e.g. taring up all a users
worksheets for download, needs to spawn a separate thread/process.)
Of course if the whole setup is running on a single machine, it may be
that the computational processes are always the bottleneck.
> I also now know precisely what Glenn Tarbox's original problem is,
> since I've recently also experimented with using the Interactive
> Broker's API from the notebook. It's an interesting nontrivial
> problem. I hope to provide some demo code for Glenn once I work this
> out...
Yes, my comment was completely independant of his original issue.
- Robert
William Stein
>
> On Wed, 19 Aug 2009, William Stein wrote:
>
>>
>> On Wed, Aug 19, 2009 at 1:19 AM, Robert
>> Bradshaw<robe...@math.washington.edu> wrote:
>>> Multithreading will have to be introduced at one
>>> level or another to scale the notebook to more than a single
>>> processor anyways.
>>>
>>> - Robert
>>
>> Huh? Why? I don't see any need for multithreading to solve the
>> above problem, or rather I don't understand what problem you're
>> talking about. The notebook already scales to more than a single
>> processor.
>
> I am talking about the case where there are enough users that the notebook
> process itself becomes the bottleneck. It all depends on how lightweight
> the shuffling data between the underlying processes and the browser is,
> and how many concurrent users one wants to support for a single notebook.
> In the asynchronous model there is only one thread handling all of the
> connections. (Also, anything long-running, e.g. taring up all a users
> worksheets for download, needs to spawn a separate thread/process.)
>
> Of course if the whole setup is running on a single machine, it may be
> that the computational processes are always the bottleneck.
Thanks for the clarification, which makes sense. There are other
approaches. If one had tens of thousands of simultaneous users,
instead of having multiple threads one could assign users to a
separate process (that could handle up to n users max) when they first
connect. That could scale better than SMP threads, since it is
easier to distribute the load across servers. Maybe this is just
orthogonal though.
Regarding the tar example, one solution might be to run it as a
separate process, then later check if that process finished -- it is
not necessary for the notebook server process to wait for a subprocess
doing tar to finish before continuing. Another possibility if the
tar'ing happens in the same process would be to use fork.
For fun, I just looked at Activity Monitor on OS X, and sorted the
tasks I'm running by number of threads. The top is Firefox and the
bottom is python.
-- William
Robert Bradshaw
Yep. If the worksheet data was backed by a (synchronzed) database then
this would work well.
> Regarding the tar example, one solution might be to run it as a
> separate process, then later check if that process finished -- it is
> not necessary for the notebook server process to wait for a subprocess
> doing tar to finish before continuing. Another possibility if the
> tar'ing happens in the same process would be to use fork.
The point is that you have to do this manually, rather than just letting
that thread block for a while. (I think the right asynchronous way to do
it would be to set up a callback for when it's done, rather than
repeatedly coming back to check on it.)
> For fun, I just looked at Activity Monitor on OS X, and sorted the
> tasks I'm running by number of threads. The top is Firefox and the
> bottom is python.
Not surprising. Also, I forgot about the GIL, which truely limits the
performance benifits of threading in Python. If anything ever kills
Python, I bet it'll be the GIL (but I'm hopeful that it'll get removed
before it causes an untimely death...)
- Robert
William Stein
Yes, this is one of the advantages of using a database (or a shared
filesystem like apache does!) to store the worksheet data.
>> For fun, I just looked at Activity Monitor on OS X, and sorted the
>> tasks I'm running by number of threads. The top is Firefox and the
>> bottom is python.
>
> Not surprising. Also, I forgot about the GIL, which truely limits the
> performance benifits of threading in Python. If anything ever kills
> Python, I bet it'll be the GIL (but I'm hopeful that it'll get removed
> before it causes an untimely death...)
Maybe you can remove it :-)
William
Jason Grout
>
> Not surprising. Also, I forgot about the GIL, which truely limits the
> performance benifits of threading in Python. If anything ever kills
> Python, I bet it'll be the GIL (but I'm hopeful that it'll get removed
> before it causes an untimely death...)
>
Has anyone here ever experimented with Stackless Python?
I've been wondering about it for a while.
Thanks,
Jason
ghtdak
> > Not surprising. Also, I forgot about the GIL, which truely limits the
> > performance benifits of threading in Python. If anything ever kills
> > Python, I bet it'll be the GIL (but I'm hopeful that it'll get removed
> > before it causes an untimely death...)
>
> Maybe you can remove it :-)
>
> William
python is insane... not only do you get the opportunity to learn all
about synchronization and thread management, you also enjoy non-
deterministic bugs which only take days or weeks to solve whereas more
conventional logic bugs take many many minutes, sometimes even hours.
(From a Keynesian economics perspective, going multi-threaded is
justified just by the added work)
Best of all: you don't get any performance benefit from threading!!!.
Imagine: we can get intermittent complex code which can't be easily
debugged (high cost) with no benefit. My guess is the government
would fund this work based on the cost-benefit analysis alone.
-glenn
Robert Bradshaw
>>> Not surprising. Also, I forgot about the GIL, which truely limits the
>>> performance benifits of threading in Python. If anything ever kills
>>> Python, I bet it'll be the GIL (but I'm hopeful that it'll get removed
>>> before it causes an untimely death...)
>>
>> Maybe you can remove it :-)
>>
>> William
>
> Of course, this is the penultimate reason that going multi-threaded in
> python is insane... not only do you get the opportunity to learn all
> about synchronization and thread management, you also enjoy non-
> deterministic bugs which only take days or weeks to solve whereas more
> conventional logic bugs take many many minutes, sometimes even hours.
> (From a Keynesian economics perspective, going multi-threaded is
> justified just by the added work)
My point was that there is benifit going mutli-threaded: you don't have to
manually set up callbacks/fork every time you might block. Whether this
simplification is worth the other complexities depends on the program at
hand (and probably the programer as well).
- Robert
ghtdak
>
> > Of course, this is the penultimate reason that going multi-threaded in
> > python is insane... not only do you get the opportunity to learn all
> > about synchronization and thread management, you also enjoy non-
> > deterministic bugs which only take days or weeks to solve whereas more
> > conventional logic bugs take many many minutes, sometimes even hours.
> > (From a Keynesian economics perspective, going multi-threaded is
> > justified just by the added work)
>
> My point was that there is benifit going mutli-threaded: you don't have to
> manually set up callbacks/fork every time you might block. Whether this
> simplification is worth the other complexities depends on the program at
> hand (and probably the programer as well).
spokesman) you'd be very surprised at how easy it becomes...
particularly given the capabilities of python.
A trivial (and likely syntactically incorrect) example
def doThings():
myDeferred = someting_that_blocks();
def doThingOne(result1):
print("doing ThingOne", result1)
return sqrt(result1)
myDeferred.addCallback(doThingOne)
def doThingTwo(result2):
print("doing ThingTwo", result2)
return another_thing_that_blocks(result2)
myDeferred.addCallback(doThingTwo)
def doThingThree(result3):
print("doing ThingThree", result3)
return result3*3.1415927
myDeferred.addCallback(doThingThree)
return myDeferred
Thats it. Note, that the implementation of doThingTwo uses something
that blocks and hence gets a deferred returned... but you don't worry
that part because the deferred return mechanism can take results or
deferreds. Once you start playing around, you find that the code is
very straightforward even if the callback chain gets complex... the
chain itself is managed by twisted... (the deferred mechanism actually
maintains two chains, one for exceptions and one for regular
results... start dealing with those issues and you quickly see why you
want a well thought out and robust infrastructure underlying all this)
All this magic is due to one key addition to the conventional notion
of callbacks... the deferred. It maintains state (btw, the deferred
can also take additional parameters to be used in the callback, hence
maintaining additional state should your application require
information available when the chain is constructed)
So, the code can be made to look very linear and intuitive. By
exploiting lambdas and closures, things become even cleaner but it
takes a slight bit more explanation.
As to the entire block of code required to initialize all this magic,
there is almost none and I reference a recent post where I list and
include a number of tutorials an introductions.
I claim, knowing quite about threading and using them heavily every
day in C++, that asynchronous programming is very simple relative to
threads. My C++ code uses both... and threads have their place. But
that place rarely exists in Python.
Finally, and this is critically important, virtually all of this can
be hidden from the vast majority of sage developers. Typically,
extensions to sage are compute bound. They're gonna get invoked and
return a result. Only folks who are doing IO or want timer callbacks
need touch this stuff. At that point, I claim you're already in need
of something and the system-wide architectural issues to support your
needs are likely much more straightforward with an asynchronous
core...
Which, by the way, is why virtually all systems of any degree of
complexity, especially distributed systems, have embraced this
approach... even as a front end to thread pools (called futures
typically... but they go by other names)
The idea that code is "cleaner" because a thread is allowed to block
misses the massive issues which become system-wide in larger codes...
and as sage is a huge code, this is even more true.
-glenn
>
> - Robert

Yoav Aner
Appengine is not the only option though (but maybe the cheapest at
least for now), you could probably use an Amazon EC2 instance just as
easily (and with some more facilities at your disposal, having a
virtual server running).
Some more input from a security perspective: De-coupling the notebook
and the processing engine is is one of the key recommendations on my
threat model (http://groups.google.com/group/sage-devel/browse_thread/
thread/4bf627a69e0401c0 more details will be available soon as I hope
to complete a draft of the entire paper, or the final version due by
4th September).
As far of having notebook running on appengine. It would probably be
more straight-forward to use Robert's model - i.e. user->notebook on
appengine->sage backend. Otherwise issues like user authentication
(token mangement), synchronisation etc sound like a potential
nightmare to me. This 'standard' architecture still has its own
issues, particularly with appengine. I don't believe google allows to
initiate ssh connections to a backend (for the pexpect interface),
only web-based requests. Google also try to push users to have a
google account to authenticate. It might be a good or a bad thing,
depending on your perspective. Amazon EC2 in that respect gives you
more flexibility I believe. I would personally avoid either from a
vendor lock-in perspective, but that's just me.
Another plus point for google appengine in terms of security - you get
the added security that the appengine provides over and above standard
python and you 'offload' any security problems with the notebook
itself to google. However, if someone does hack your notebook, not
sure whether google will simply shut you down (they probably will). Of
course it only applies to the Notebook code itself, and even then it
won't solve any XSS issues for you. It obviously won't help with any
security issue relating to the backend either, which is where the sage
'soft-spot' is currently.
Unrelated to appengine, using a web framework like django is a good
idea from a security standpoint. It should give you much more
flexibility in terms of user authentication and authorisation with
many backend support. That alone would make a good security
improvement too.
On Jul 21, 7:53 pm, William Stein <wst...@gmail.com> wrote:
> On Tue, Jul 21, 2009 at 10:21 AM, Ondrej Certik <ond...@certik.cz> wrote:
>
> > On Tue, Jul 21, 2009 at 10:44 AM, William Stein<wst...@gmail.com> wrote:
>
> > > On Tue, Jul 21, 2009 at 9:39 AM, Ondrej Certik<ond...@certik.cz> wrote:
>
> > >> On Tue, Jul 21, 2009 at 1:58 AM, Robert
> > >> Bradshaw<rober...@math.washington.edu> wrote:
>
> > >>> On Jul 20, 2009, at 9:02 PM, Ondrej Certik wrote:
>
> > >>>> Well, let me say that I really like to run things on the appengine,
> > >>>> rather than to constantly maintain our own servers. I see no reason
> > >>>> why the notebook cannot run on the appengine, only the AJAX would talk
> > >>>> to our own server with Sage to actually evaluate the cells (and for
> > >>>> many people, I think appengine itself could actually be enough). I
> > >>>> have to think though what the best way to transfer data to the
> > >>>> database with worksheets is though.
>
> > >>> +1, though for Sage we rely heavily on compiled code. I wonder how
> > >>> much introduced latency there would be if the backend were served on
> > >>> a university computer, and the front end in appengine.
>
> > >> I think none, it would be as fast as it is now (e.g. the browser
> > >> communicating directly with the engine).
>
> > > How is it "none", given that there are now three separate computers
> > > involved instead of two? There would have to be a little extra
>
> > What I meant is that the latency in typing 1+1 into the cell and get
> > the output cell saying 2 should not change at all, because the
> > javascript in the browser sends a POST request to the Sage engine
> > (e.g. a web app with the url interface, just like it is now) and it
> > returns it back directly to the browser.
>
> Thanks for the clarification, since I clearly misunderstood you. Robert
> said "backend were served on a university computer, and the front end in
> appengine." You seem to be eliminating the frontend completely when
> computations are done. I.e., do you imagine appengine *just* serving some
> javascript and a database interface, and basically nothing else? So what
> would happen is the following:
>
> 1. User visits the appengine server and gets the javascript for the sage
> notebook (after authenticating).
> 2. User starts a worksheet. The javascript in the browser requests a "sage
> engine token", and the appengine allocates a "compute engine" somewhere for
> use by that user's worksheet.
> 3. The user types "factor(2^197-1)" and their javascript *directly* connects
> to the compute engine and runs the code "factor(2^197-1)". It also connects
> to the appengine and stores that "factor(2^197-1)" was input in the
> database.
> 4. The javascript in the browser gets back the answer to the factor query
> and displays the result.
> 5. The javascript in the browser later also stores the result in the app
> engine database.
>
> I think there could be some weird security issues/tricks involved with the
> javascript in the browser directly doing AJAX calls to the "compute engine"
> above, but there are hacks to get around that. There's also twice the
That should only be possible if you use a common domain name i.e.
notebook.sagenb.org and engine.sagenb.org. It seems like Google
supports using your own domain names. It seems like a rather odd
architecture to me, and like I said - a potential nightmare to manage
and secure.
> communications overhead between the user's javascript and remote machines
> than in the current Sage notebook model where everything goes through the
> notebook server. E.g., if the output of a Sage command (in step 4 and 5
> above) is large, e.g., a 10MB image, then that image is going to go all
> over the place, both uploaded and downloaded, which will be incredibly
> expensive.
Also consider how you handle authentication here. Both the notebook
frontend and the sage backend need to know that the user is authorised
to run a computation. Now all users are 'equal', but in future if you
implement different permissions, it may determine their level of
access - e.g. which backend systems (python, shell, magma...) are
available to the user, even how much CPU/memory is allocated perhaps.
>
> > What changes is the database storage, e.g. either the javascript in
> > the browser, once it receives the output of the cells also sends it to
> > the appengine (or whenever the database is running), or the engine
> > sends it itself, I don't know yet which approach is better. So there
> > are some issues involved, like if one of those connections fail etc.
> > But as long as both connections are up and running, the user would not
> > recognize anything at all.
>
> This is an interesting design. It hadn't occured to me before. It would be
> interesting to see whether it is any good or not (I can't tell).
>
> I can tell you one thing, which is that when I start working on the notebook
> again seriously this September, my first goal will be to create a powerful
> system for simulating the load of n people all using the notebook at once in
> a potentially heterogenous way (say from several different computers,
> etc.). This testing code will be hopefully generic enough to work with
> codenode, sagenb, etc. I think having actual benchmark testing code will
> in the longrun be a better litmus test for designs than us just thinking
> about them in the abstract.
>
> I could pronounce the design you suggest above as "bad" for several reasons,
> but what if I'm wrong and in fact the design above, with some tweaks and
> insights that would result from testing, turns out to be amazingly good?
>
>
>
>
>
> > > latency, i.e., whatever there is between appengine and the "sage
> > > engine". That said, the internet is pretty fast these days :-). And
> > > the scalability of a decoupled approach like we're talking about is a
> > > big plus, if it works.
>
> > Right, it has to be tried to see if it works. But I think it's worthy.
>
> > > By the way, if you haven't already, I personally think you should
> > > start a mailing list, web page, trac, etc. for a separate notebook
> > > project, since you're already writing code. There's already some
> > > confusion about where we are supposed to have this discussion -- and a
> > > funny mix of sage-devel and codenode doesn't seem right.
>
> > Well, I hope codenode guys could pick this up and they would be the
> > notebook. I unfortunately probably can't spend too much time on this,
> > until september. But I wanted to get this going to see which approach
> > to take.
>
> Hey, same here. Yeah for September.
>
>
>
>
>
> > I wrote the above in about 2 days (roughly), but it's only the first
> > 90%, e.g. the cells sort of works, but the rest 10%, like tab
> > completion, worksheets, saving. loading, publishing, users, fixing it
> > so that it works 100% in all browsers..... That would take a lot more,
> > and I can't do it yet. But I hope it's encouraging to all of you to
> > learn some AJAX too till September, so that we can work on this
> > together. :)
>
> > There is one more thing I want to try -- pyjamas, as pointed out
> > above. I already played with it yesterday, and what I saw so far is
> > *impressive*. So my next step will be to rewrite what I did into
> > pyjamas (e.g. just pure python both on the server and in the browser).
> > If that works and I think it could, well, that would be the way to go,
> > since I could debug all those functions like for calculating cursor
> > positions etc. in Python.
>
> I strongly encourage you to test pyjamas with the above. I think that's the
> best possible next step.
>
> -- William
Yoav
Robert Bradshaw
This is easy to read for someone who already knows twisted, but I
have a hard time convincing myself that it's easier to read than
def doThings();
result1 = someting_that_blocks()
print("doing ThingOne", result1)
result2 = sqrt(result1)
print("doing ThingTwo", result2)
result3 = another_thing_that_blocks(result2)
print("doing ThingThree", result3)
return result3*3.1415927
I wonder if this has contributed to the lack of contributions to the
notebook relative to other parts of Sage. Also, the painful part is
often to write the "xxx_that_blocks," especially if it's "blocking"
because it's computationally expensive, rather than waiting on an
external event that naturally triggers a callback. One needs to
manually chop the computation into small enough bits that no one
piece takes too long, and this can't be hidden from the implementer.
(Either that, or run the computationally intensive part in a separate
thread/process and set up a callback, but the one isn't avoiding
multiple threads...) And the twisted model is non-deterministic
(hence harder to debug) as well.
I have to admit I'm playing a bit of the devil's advocate here, I've
used both twisted and threads (though admittedly I've never used
Python threads) and the twisted folks have implemented a very nice
model for dealing with this kind of thing. When there's a lot of
synchronization or global state threading can be a pain. But I think
it's far from obvious that the twisted model is a better fit (though
the notebook is a controller for multiple processes and simple
shuffler of data back and forth, so there is a strong case here).
- Robert
ghtdak
threading is that it can be hidden.
This was one of the difficulties that CORBA had early on as well...
since the proxy object being called caused all kinds of communications
to occur... sometimes even calling through a series of processors back
to itself. Unfortunately, the single threaded server was blocking
waiting for a response for itself, and it would deadlock...
Now, of course, it couldn't be the developers (no names but their
initials are MITRE), so CORBA was designated "not ready for prime
time"...
The point is that regardless of how clean the interface "appears", not
understanding whats going on is death. I claim (and of course, this
is widely accepted) that threads are a true nightmare in the hands of
those who don't understand.
Importantly the system you're building is extremely generic and nobody
with any experience with real systems would suggest that threading is
a rational approach to addressing IO blocking... in fact, its
typically the poster child for how not to use threads.
(I could post a few hundred links on this issue but googling "threads
considered harmful" would likely give you a good start)
This is all before we get into the issue of where did you spawn the
thread... what is the other "main" thread doing, what is going to
happen to exceptions, what strategy to join with this thread is to be
used etc...
But I digress. The point is there are things to learn and they need
to be understood. Syntatic issues in the above example are irrelevant
because things are actually happening which need to be understood.
>
> I wonder if this has contributed to the lack of contributions to the
> notebook relative to other parts of Sage.
kludgy and includes strings of python code which get injected into the
spawned notebook process amongst other issues. There's also lots of
handling of "corner cases" which have evolved over time. In my not so
humble opinion, it should all be ripped out and replaced with a proper
asynchronous interface. This could be accomplished with very little
effort, but it hasn't been a priority and it would require William's
buy-in and assistance. Until very very recently, this wasn't
feasible.
> Also, the painful part is
> often to write the "xxx_that_blocks," especially if it's "blocking"
> because it's computationally expensive, rather than waiting on an
> external event that naturally triggers a callback.
popular American concept and lies at the heart of the accelerating
decline of the US... again I digress)
> One needs to
> manually chop the computation into small enough bits that no one
> piece takes too long, and this can't be hidden from the implementer.
> (Either that, or run the computationally intensive part in a separate
> thread/process and set up a callback, but the one isn't avoiding
> multiple threads...) And the twisted model is non-deterministic
> (hence harder to debug) as well.
it :-)
>
> I have to admit I'm playing a bit of the devil's advocate here, I've
> used both twisted and threads (though admittedly I've never used
> Python threads) and the twisted folks have implemented a very nice
> model for dealing with this kind of thing. When there's a lot of
> synchronization or global state threading can be a pain.
> But I think
> it's far from obvious that the twisted model is a better fit (though
> the notebook is a controller for multiple processes and simple
> shuffler of data back and forth, so there is a strong case here).
(not that I'm reasonable... but I'm pretty sure I'm right)
-glenn
>
> - Robert

Thierry Dumont
>
> only web-based requests. Google also try to push users to have a
> google account to authenticate. It might be a good or a bad thing,
> depending on your perspective. Amazon EC2 in that respect gives you
> more flexibility I believe. I would personally avoid either from a
> vendor lock-in perspective, but that's just me.
>
software...I cannot imagine this.
But Appengine seems great, and Django is great.
Yours.
t.
William Stein
The Notebook has a major problem. The pexpect code is opaque and
> I wonder if this has contributed to the lack of contributions to the
> notebook relative to other parts of Sage.
kludgy and includes strings of python code which get injected into the
spawned notebook process amongst other issues. There's also lots of
handling of "corner cases" which have evolved over time. In my not so
humble opinion, it should all be ripped out and replaced with a proper
asynchronous interface. This could be accomplished with very little
effort,
Then why don't you do it? "Talk is cheap, show me the code."
but it hasn't been a priority and it would require William's
buy-in and assistance. Until very very recently, this wasn't
feasible.
Also, isn't Codenode already what you're asking for? Why don't you just use that instead of the Sage notebook?
> I have to admit I'm playing a bit of the devil's advocate here, I've
> used both twisted and threads (though admittedly I've never used
> Python threads) and the twisted folks have implemented a very nice
> model for dealing with this kind of thing. When there's a lot of
> synchronization or global state threading can be a pain.
> But I think
> it's far from obvious that the twisted model is a better fit (though
> the notebook is a controller for multiple processes and simple
> shuffler of data back and forth, so there is a strong case here).
Well, I suppose reasonable people can disagree.
(not that I'm reasonable... but I'm pretty sure I'm right)
You're lucky. I'm usually sure I'm not "right" about how to build software. Sometimes I even suspect there is no right answer to a lot of software engineering questions. For example, I always get a funny (unpleasant) feeling in my stomach when I here the phrase "best practices" in the context of software engineering.
-- William
Yoav Aner
On Aug 22, 6:04 am, Thierry Dumont <tdum...@math.univ-lyon1.fr> wrote:
> Yoav Aner a écrit :
>
> > only web-based requests. Google also try to push users to have a
> > google account to authenticate. It might be a good or a bad thing,
> > depending on your perspective. Amazon EC2 in that respect gives you
> > more flexibility I believe. I would personally avoid either from a
> > vendor lock-in perspective, but that's just me.
>
> If we need to have a Google Account tu use this, Sage is no more a free
> software...I cannot imagine this.
*only* on appengine. But if the notebook code is 100% appengine
compatible, I suppose it would make a good idea for anyone who wants
to use it there. They will still have to find a somewhere to run the
backend server though...
> But Appengine seems great, and Django is great.
> Yours.
> t.
>
> < 1KViewDownload
Alex Clemesha
>
> Sounds like a great idea to me to de-couple the notebook from sage.
> Appengine is not the only option though (but maybe the cheapest at
> least for now), you could probably use an Amazon EC2 instance just as
> easily (and with some more facilities at your disposal, having a
> virtual server running).
>
> Some more input from a security perspective: De-coupling the notebook
> and the processing engine is is one of the key recommendations on my
> threat model (http://groups.google.com/group/sage-devel/browse_thread/
> thread/4bf627a69e0401c0 more details will be available soon as I hope
> to complete a draft of the entire paper, or the final version due by
> 4th September).
and it's very impressive how in depth you go, nice job.
I wanted to point out a couple of things related to de-coupling the notebook
from sage, and the current security situation in the sage notebook.
A good portion of the 'security' related code (HTTP sessions) in the
sage notebook was written by
me (see 'sage/server/notebook/avatars.py' or
'sage/server/notebook/run_notebook.py', etc)
and is old and crufty, and probably has some security vulnerabilities.
I've long since realized that trying to
write you own http sessions framework is a bad idea (obviously).
As you point out, decoupling the notebook from sage, and using more
well established
frameworks (like Django) is an excellent way to improve security
because you have hundreds
to people testing, using, and writing the code for you. In fact, I
have started a project
called codenode (used to be called Knoboo, or sometime badly spelled as Knooboo)
that is exactly what you speak of: a de-coupled sage notebook that use Django.
See here: http://codenode.org and here: http://github.com/codenode/codenode
>
> As far of having notebook running on appengine. It would probably be
> more straight-forward to use Robert's model - i.e. user->notebook on
> appengine->sage backend. Otherwise issues like user authentication
> (token mangement), synchronisation etc sound like a potential
> nightmare to me. This 'standard' architecture still has its own
> issues, particularly with appengine. I don't believe google allows to
> initiate ssh connections to a backend (for the pexpect interface),
> only web-based requests. Google also try to push users to have a
> google account to authenticate. It might be a good or a bad thing,
> depending on your perspective. Amazon EC2 in that respect gives you
> more flexibility I believe. I would personally avoid either from a
> vendor lock-in perspective, but that's just me.
is awesome because you get the security benefits that comes along with
running arbitrary code on google's servers. You can try it out
right now here: http://live.codenode.org
Additionally, codenode works fine using EC2 as a backend as well.
In fact, the backend of live.codenode.org used to be EC2, but it was a little
expensive, so we are using app engine for the time being (even though
app engine is more limited). EC2 is essentially just a
"full capabilities virtual machine instance" that is no different that running
(say) a Virtualbox or VMware instance on servers that you own yourself.
>
> Another plus point for google appengine in terms of security - you get
> the added security that the appengine provides over and above standard
> python and you 'offload' any security problems with the notebook
> itself to google. However, if someone does hack your notebook, not
> sure whether google will simply shut you down (they probably will). Of
> course it only applies to the Notebook code itself, and even then it
> won't solve any XSS issues for you. It obviously won't help with any
> security issue relating to the backend either, which is where the sage
> 'soft-spot' is currently.
>
> Unrelated to appengine, using a web framework like django is a good
> idea from a security standpoint. It should give you much more
> flexibility in terms of user authentication and authorisation with
> many backend support. That alone would make a good security
> improvement too.
You can get started by typing "easy_install codenode", or check out the
latest code at http://github.com/codenode/codenode
-Alex
Alex Clemesha
clemesha.org

Brian Granger
In the current architecture, a twistd daemon spawns a notebook server
which is responsible for doing "sage" stuff. twistd is fully
asynchronous, but the notebook process itself is a pexpect based
blocking process connected with pipes to twistd. As such, the block
on read by pexpect precludes the sage process servicing asynchronous
events.
IMHO, this architecture is incorrect and limited... Perhaps this is
part of what is being rethought... if not, I believe it should be.
As an avid Twisted user, I too thought this initially (why use pexpect, when you could use Twisted). But after looking at this issue further, I think using pexpect is not that bad. Here is why:
1. If you were to use Twisted, while the process was running user's code, Twisted would still block. Using threads (running the Twisted event loop in a thread) only partially solves this problem as the python intepreter can't switch threads while no GIL-releasing C/C++ code is running. We ran into this in early versions of IPython's parallel stuff - it worked great (asynch) until the second we went to do something like diagonalize a matrix using scipy. Then everything would block. We have had to work very hard to get around this GIL induced limitation of using Twisted.
2. Both dsage and parallel ipython clients use Twisted. For this to work, these clients need to run the Twisted reactor in a different thread than user code is executed. Currently, these work fine in the notebook, because they can start the reactor in this way by themselves. If the notebook itself used Twisted, great care would need to be used to make sure these things still worked. You would have to run user code in the main thread and run all the twisted stuff in a different thread. User code needs to be in the main thread if you want users to be able to run real GUI code (I do this sometimes!).
To summarize, you could implement this by running user code in the main thread and and the twisted reactor in a second thread *but*, you don't gain much over pexpect because everything will still block when non-GIL releasing C code is run. Furthermore, pexpect is pretty simple and just works.
With that said, there are other reasons that doing this using Twisted would be nice. Namely, you could potentially distribute the running of user code to other hosts. That would be very nice.
Cheers,
Brian
William Stein
>
>> In the current architecture, a twistd daemon spawns a notebook server
>> which is responsible for doing "sage" stuff. twistd is fully
>> asynchronous, but the notebook process itself is a pexpect based
>> blocking process connected with pipes to twistd. As such, the block
>> on read by pexpect precludes the sage process servicing asynchronous
>> events.
>>
>> IMHO, this architecture is incorrect and limited... Perhaps this is
>> part of what is being rethought... if not, I believe it should be.
>
> As an avid Twisted user, I too thought this initially (why use pexpect, when you could use Twisted). But after looking at this issue further, I think using pexpect is not that bad. Here is why:
>
> 1. If you were to use Twisted, while the process was running user's code, Twisted would still block. Using threads (running the Twisted event loop in a thread) only partially solves this problem as the python intepreter can't switch threads while no GIL-releasing C/C++ code is running. We ran into this in early versions of IPython's parallel stuff - it worked great (asynch) until the second we went to do something like diagonalize a matrix using scipy. Then everything would block. We have had to work very hard to get around this GIL induced limitation of using Twisted.
>
> 2. Both dsage and parallel ipython clients use Twisted. For this to work, these clients need to run the Twisted reactor in a different thread than user code is executed. Currently, these work fine in the notebook, because they can start the reactor in this way by themselves. If the notebook itself used Twisted, great care would need to be used to make sure these things still worked. You would have to run user code in the main thread and run all the twisted stuff in a different thread. User code needs to be in the main thread if you want users to be able to run real GUI code (I do this sometimes!).
The Sage notebook is a lot like the command line tools bash or screen
or even ssh. The pexpect library is just a collection of Python
bindings to pseudotty that make it easy for one process to spawn and
run subprocesses.
Moreover, as long as the worksheet and the notebook server are
distinct processes (as they should be, IMHO), the difference between
using pexpect, or xmlrpc, or anything else, for them to communicate is
completely and totally irrelevant, since it is a black box to the
entire rest of the program.
Also, to correct another possible misconception, communication between
a processes and a subprocess using pexpect is not blocking. The
master processes can listen for however long it wants to the
subprocess, then stop listening. That's why when you do
for i in range(10):
sleep(1)
print(i)
in the Sage notebook, you see the output as it is computed. The
notebook server just uses pexpect to "peak" at the output of the
subprocess doing the actual work and look to see what has been output
so far.
Another misconception is that pexpect is restricted to local
processes. It's easy to control a process via pexpect over the
network via ssh. This has been in Sage since 2005, and can already
be used for worksheet subprocesses *now* as long as you have a shared
filesystem (just use the server_pool option). Here is an example on
the command line. I have ssh keys setup so I can do "ssh
sage.math.washington.edu" and login without typing a password. I
start Sage on my laptop in a coffee shop, and make a connection to a
remote Sage that gets started running on sage.math, and I run a
calculation.
flat:sageuse wstein$ sage
----------------------------------------------------------------------
| Sage Version 4.1.1, Release Date: 2009-08-14 |
| Type notebook() for the GUI, and license() for information. |
----------------------------------------------------------------------
sage: s = Sage(server="sage.math.washington.edu")
No remote temporary directory (option server_tmpdir) specified, using
/tmp/ on sage.math.washington.edu
sage: s.eval("2+2")
'4'
sage: s.eval("os.system('uname -a')")
'Linux sage.math.washington.edu 2.6.24-23-server #1 SMP Wed Apr 1
22:14:30 UTC 2009 x86_64 GNU/Linux\n0'
sage:
The above used pexpect. You can even interact with remote objects:
sage: e = s("EllipticCurve([1..5])")
sage: e.rank()
1
You can do the same with Mathematica, etc. by the way:
sage: s = Mathematica(server="sage.math.washington.edu")
sage: s("Factorial[50]")
30414093201713378043612608166064768844377641568960512000000000000
Compare my laptop to sage.math's mathematica:
sage: s("Timing[Factorial[10^6]][[1]]") # sage.math
1.1099999999999999
sage: mathematica("Timing[Factorial[10^6]][[1]]") # laptop
0.8902620000000001
(I guess Mathematica 7.0 is faster at factorials than Mathematica 6.0.)
This tests latency:
sage: timeit('s.eval("2+2")') # over web via ssh
5 loops, best of 3: 56.3 ms per loop
sage: timeit('mathematica.eval("2+2")') # local
625 loops, best of 3: 209 µs per loop
Of course latency is long over the net, since I'm in a random coffee shop.
This remote server stuff has been in sage since 2005, and hasn't been
changed in the slightest bit since then. That's why I'm advertising
it now, since it would be cool to see some people work on it and
improve it. For example, for people without ssh keys, one could
*easily* make it so the following works:
sage: s = Mathematica(server="sage.math.washington.edu")
password: xxx
sage: s = Mathematica(server="w...@sage.math.washington.edu")
password: xxx
Scripted logins via pexpect are in fact the raison d'etre for pexpect
in the first place, and would be easy to add. There are also bound
to be all kinds of subtle issues with server=... that haven't been
found due to lack of use. A good test would be to try to force the
gap or maxima interfaces to run 100% remotely (by editing
interfaces/gap.py or interface/maxima.py), then try to run the Sage
test suite and see what goes wrong.
With respect to the notebook, there is currently some reliance on a
shared filesystem for the worksheet processes. This could be I think
easily fixed via some slight redesign, and I'll do this in October.
I could even make it so that there is an option for a given worksheet
(set in say a worksheet configuration pane) for that worksheet to run
as a given user on a given remote system. Then whenever you use that
worksheet, you would have to login to the remote system to start it
running, and afterwards all computations would happen using the
default "sage" command on that remote system over ssh. I think
implementing this would be completely straightforward given the
current notebook design, and already this would provide a level of
flexibility and power that rivals anything the codenode design or
anybody else has suggested. In case the above wasn't clear, one
could go to say https://sagenb.org, login, but then have persistent
worksheet processes that run on sage.math.washington.edu, or any other
powerful specific computer you have an account on. This would give
you access to your own build of Sage, commercial software on that
machine, etc.
So there is still some potential to the pseudotty approach to
controlling processes. The main drawback in my mind is that it
works differently (and maybe not so well) on Windows (though it does
actually work, but via the "Console API").
-- William
Brian Granger
Thanks for clarifying some of the details of pexpect. I do really want to understand this because I am starting to use the notebook more and currently IPython's parallel stuff works fine (there are a few things that need to be fixed on our side to make it easier though).
Moreover, as long as the worksheet and the notebook server are
distinct processes (as they should be, IMHO), the difference between
using pexpect, or xmlrpc, or anything else, for them to communicate is
completely and totally irrelevant, since it is a black box to the
entire rest of the program.
I agree with you that for the rest of the program (the notebook) this detail is completely hidden. But I guess I don't quite follow your statement that the differences of using pexpect/twisted to manage this are irrelevant. In my mind there is a big different between pexpect and twisted:
* pexpect simply controls and observes the worksheet process (I now understand that this can be asynchronous). The worksheet process doesn't have *any* custom code to enable this to work and probably doesn't even import pexpect (unless it does so for a completely different reason - like talking to Mathematica, etc.).
* To get Twisted to make two processes talk over TCP/IP (I am ignoring Twisted's ability to talk to a process in the same manner as pexpect, which I think it might be able to do - are you thinking of this?) *both* processes must start the Twisted reactor. Thus, if you wanted the notebook server and a worksheet process to talk over xmlrpc or pb, the worksheet process must be re-designed to run the Twisted reactor. To use IPython or dsage in a context like that, the Twisted reactor and user code must be run in different threads. This is a super subtle aspect of using Twisted in a blocking manner like the dsage and IPython clients do. I can give more details about this aspect if needed.
Also, to correct another possible misconception, communication between
a processes and a subprocess using pexpect is not blocking. The
master processes can listen for however long it wants to the
subprocess, then stop listening. That's why when you do
for i in range(10):
sleep(1)
print(i)
in the Sage notebook, you see the output as it is computed. The
notebook server just uses pexpect to "peak" at the output of the
subprocess doing the actual work and look to see what has been output
so far.
Not that you mention this I vaguely remember this about pexpect.
Another misconception is that pexpect is restricted to local
processes. It's easy to control a process via pexpect over the
network via ssh. This has been in Sage since 2005, and can already
be used for worksheet subprocesses *now* as long as you have a shared
filesystem (just use the server_pool option). Here is an example on
the command line. I have ssh keys setup so I can do "ssh
sage.math.washington.edu" and login without typing a password. I
start Sage on my laptop in a coffee shop, and make a connection to a
remote Sage that gets started running on sage.math, and I run a
calculation.
Wow, I had no idea that this was possible! I will definitely keep this in mind as it is very nice.
This is truly great stuff and I am glad you are advertising it. I need to look at pexpect more because it might come in useful for some things we do with IPython. We really like Twisted, but for somethings Twisted doesn't make sense.
So there is still some potential to the pseudotty approach to
controlling processes. The main drawback in my mind is that it
works differently (and maybe not so well) on Windows (though it does
actually work, but via the "Console API").
Question then: are you planning on continuing to use pexpect to communicate between the notebook server and worksheet or are you planning on moving to Twisted for that?
Cheers,
Brian
William Stein
William,
Thanks for clarifying some of the details of pexpect. I do really want to understand this because I am starting to use the notebook more and currently IPython's parallel stuff works fine (there are a few things that need to be fixed on our side to make it easier though).
Moreover, as long as the worksheet and the notebook server are
distinct processes (as they should be, IMHO), the difference between
using pexpect, or xmlrpc, or anything else, for them to communicate is
completely and totally irrelevant, since it is a black box to the
entire rest of the program.
I agree with you that for the rest of the program (the notebook) this detail is completely hidden. But I guess I don't quite follow your statement that the differences of using pexpect/twisted to manage this are irrelevant. In my mind there is a big different between pexpect and twisted:
Sorry. I really only meant to convey precisely the part of the statement that you agree with. I didn't express myself clearly enough. I should have added that this is only irrelevant for the rest of the notebook code. That's all I meant.
* pexpect simply controls and observes the worksheet process (I now understand that this can be asynchronous). The worksheet process doesn't have *any* custom code to enable this to work and probably doesn't even import pexpect (unless it does so for a completely different reason - like talking to Mathematica, etc.).
That is correct. The worksheet processes are pure Python processes that do not need to use pexpect at all themselves, except to talk to other systems of they so choose. Also, the communication is precisely as powerful as communication between *you* and a program you are using interactively at the command line. For example, if you are sitting there using the program, then you go make a cup of tea, the program can't do anything at all to get your attention. In the same way, a worksheet process under pexpect will be completely ignored by the notebook server process until the notebook server process chooses to look at the worksheet process.
* To get Twisted to make two processes talk over TCP/IP (I am ignoring Twisted's ability to talk to a process in the same manner as pexpect, which I think it might be able to do - are you thinking of this?) *both* processes must start the Twisted reactor. Thus, if you wanted the notebook server and a worksheet process to talk over xmlrpc or pb, the worksheet process must be re-designed to run the Twisted reactor. To use IPython or dsage in a context like that, the Twisted reactor and user code must be run in different threads. This is a super subtle aspect of using Twisted in a blocking manner like the dsage and IPython clients do. I can give more details about this aspect if needed.
That sounds right to me. I have never thought of using twisted in the same way as pexpect. Yes, using xmlrpc would require putting the worksheet process in a special listening mode and would either require two threads or having the worksheet's side of xmlrpc simply go dead whenever the worksheet is working, which would be completely unacceptable given that users need to see the output as it is produced. So yes, two threads are needed.
I should expand this out into a nice ReST document and put it in the Sage reference manual.
So there is still some potential to the pseudotty approach to
controlling processes. The main drawback in my mind is that it
works differently (and maybe not so well) on Windows (though it does
actually work, but via the "Console API").
Question then: are you planning on continuing to use pexpect to communicate between the notebook server and worksheet or are you planning on moving to Twisted for that?
By far the fastest path to Sage-on-windows right now is via Cygwin, and for that pexpect works perfectly well. For native MSVC, we did port pexpect, and it might work. Frankly, I don't really have a plan for the MSVC notebook communicating with worksheets. Hopefully whatever happens, if it is a good solution it'll just be a black box somewhere, and it won't impact anything else in the system. So one could do everything else first.
William
Yoav Aner
On Aug 23, 4:51 pm, Alex Clemesha <cleme...@gmail.com> wrote:
>
> > Sounds like a great idea to me to de-couple the notebook from sage.
> > Appengine is not the only option though (but maybe the cheapest at
> > least for now), you could probably use an Amazon EC2 instance just as
> > easily (and with some more facilities at your disposal, having a
> > virtual server running).
>
> > Some more input from a security perspective: De-coupling the notebook
> > and the processing engine is is one of the key recommendations on my
> > threat model (http://groups.google.com/group/sage-devel/browse_thread/
> > thread/4bf627a69e0401c0 more details will be available soon as I hope
> > to complete a draft of the entire paper, or the final version due by
> > 4th September).
>
> I just read your paper (http://www.gingerlime.com/sageNotebookThreatModel.pdf),
> and it's very impressive how in depth you go, nice job.
paper very soon.
> I wanted to point out a couple of things related to de-coupling the notebook
> from sage, and the current security situation in the sage notebook.
>
> A good portion of the 'security' related code (HTTP sessions) in the
> sage notebook was written by
> me (see 'sage/server/notebook/avatars.py' or
> 'sage/server/notebook/run_notebook.py', etc)
> and is old and crufty, and probably has some security vulnerabilities.
> I've long since realized that trying to
> write you own http sessions framework is a bad idea (obviously).
>
> As you point out, decoupling the notebook from sage, and using more
> well established
> frameworks (like Django) is an excellent way to improve security
> because you have hundreds
> to people testing, using, and writing the code for you. In fact, I
side, it's more likely django will get the necessary security
'attention' as so many people rely on it, but then also attackers will
be more motivated to try to poke holes at it. Overall, my personal
feeling is that it is the right direction. It provides a more solid
and extensible framework to rely on, particularly with regards to
using different authentication and authorisation options.
> called codenode (used to be called Knoboo, or sometime badly spelled as Knooboo)
> that is exactly what you speak of: a de-coupled sage notebook that use Django.
> See here:http://codenode.organd here:http://github.com/codenode/codenode
there two projects? or perhaps, looking from a different angle, why
doesn't sage simply use codenode as the front-end? I see there's a
very healthy collaboration between the two projects, so wouldn't it be
more sensible to join forces here, rather than maintaining two
'versions' of the notebook?
>
>
> > As far of having notebook running on appengine. It would probably be
> > more straight-forward to use Robert's model - i.e. user->notebook on
> > appengine->sage backend. Otherwise issues like user authentication
> > (token mangement), synchronisation etc sound like a potential
> > nightmare to me. This 'standard' architecture still has its own
> > issues, particularly with appengine. I don't believe google allows to
> > initiate ssh connections to a backend (for the pexpect interface),
> > only web-based requests. Google also try to push users to have a
> > google account to authenticate. It might be a good or a bad thing,
> > depending on your perspective. Amazon EC2 in that respect gives you
> > more flexibility I believe. I would personally avoid either from a
> > vendor lock-in perspective, but that's just me.
>
> One of the "backends" of codenode can be google app engine, which
> is awesome because you get the security benefits that comes along with
> running arbitrary code on google's servers. You can try it out
> right now here:http://live.codenode.org
google seem to have done a good job at placing security around
untrusted code - and they take the risk to a great extent (if someone
tries to run malicious code - it runs on google). The downside is of
course the fact that you're locked into google. If users do try to run
malicious code, they might block your account, they might ask you to
pay increasing fees over time, and there's no real competition to
their service at the moment. So from a slightly longer term security
perspective, you might be better off developing your own security
mechanisms that you could port and use with any hosting provider and
using a generic service.
> Additionally, codenode works fine using EC2 as a backend as well.
> In fact, the backend of live.codenode.org used to be EC2, but it was a little
> expensive, so we are using app engine for the time being (even though
> app engine is more limited). EC2 is essentially just a
> "full capabilities virtual machine instance" that is no different that running
> (say) a Virtualbox or VMware instance on servers that you own yourself.
competitive prices than EC2. You may not get the same availability and
flexibility (you pay monthly rather than per hour). I have used and
can personally recommend linode in the US, and xencon in Germany, both
are Xen based virtual machines. From a 'product packaging' perspective
however, I suppose it's easier to build an amazon machine image which
people can then use(??), whereas if you set up your own virtual host,
you'll have to know how to set it up the server, download sage/
codenode onto it and install it. For some people that's not a problem,
but it might be harder for others.
>
>
>
>
> > Another plus point for google appengine in terms of security - you get
> > the added security that the appengine provides over and above standard
> > python and you 'offload' any security problems with the notebook
> > itself to google. However, if someone does hack your notebook, not
> > sure whether google will simply shut you down (they probably will). Of
> > course it only applies to the Notebook code itself, and even then it
> > won't solve any XSS issues for you. It obviously won't help with any
> > security issue relating to the backend either, which is where the sage
> > 'soft-spot' is currently.
>
> > Unrelated to appengine, using a web framework like django is a good
> > idea from a security standpoint. It should give you much more
> > flexibility in terms of user authentication and authorisation with
> > many backend support. That alone would make a good security
> > improvement too.
>
> Completely agreed. I invite you to check out codenode in more detail.
> You can get started by typing "easy_install codenode", or check out the
> latest code athttp://github.com/codenode/codenode
threat modelling process as I did for Sage (it is an MSc project paper
after all and I've spent a few months working on it), but I'll be
happy to help if I can. On a high level, I imagine that the threats
and issues Sage is facing are very similar - identical some times, to
the ones you'll need to consider for codenode.
>
> -Alex
William Stein
I'm reviving this thread, since I just got very curious about how to
solve the problem you (=Robert Bradshaw) were alluding to above in a
particular case, since I'm working on the notebook all weekend. As a
reminder, here is the problem: In the Sage notebook, we want to have
a feature where the user can click "Download all worksheets" and the
notebook server will prepare a zip archive of all their worksheets,
then hand it to the user. Robert Bradshaw implemented a function to
do this a few months ago, but it is disabled on the public Sage
notebook servers. Why? Because while the zip archive is being
created the notebook server simply ignores all other requests. In
particular, let's say I have 500 worksheets and creating sws files and
zipping them all up takes 30 seconds (that's about how long it
actually takes), then when I click that "Download all link" the entire
http://sagenb.org will appear to be down to everybody in the world for
the next 30 seconds. Not good, especially given that
http://sagenb.org has over 4000 more users now than it did a month
ago...
The Sage Notebook is a Twisted application, and Twisted's "deferreds"
might seem like a good idea for solving the above problem. However,
they are actually *not* at all meant to solve the above sort of
problem, which is made I think very clear by the Twisted
documentation, which lists two types of async problems -- cpu bound
and "waiting for a resource" bound. The problem, at its simplest
level, is that no matter you do with Twisted deferreds -- making the
zip file little by little -- everything happens in a single thread,
and a total of at least 30 seconds of CPU time has to be spent by the
Sage notebook server making that zip archive. And that's 30 seconds
that the notebook server isn't responding to users, so overall the
notebook is going to feel sluggish to users. Also, it just seems
dumb to slow the notebook server down like this, given that, e.g.,
sagenb.org is running on an 8-core multicore virtual machine.
Fortunately,
http://twistedmatrix.com/projects/core/documentation/howto/gendefer.html
gives an example similar to this problem as an example, and explains
how to easily solve it in two lines using *threads*. So I took the
big chunk of scary blocking code that Robert Bradshaw wrote, put it in
a closure (a little next function f), and added the following two
lines to the server:
from twisted.internet import threads
return threads.deferToThread(f)
That's it. It worked first try, and solves the problem. What
happens behind the scenes is that Twisted uses a separate thread to
run the one function f, then when f completes it returns the output of
f. So it wraps the idea of "do something in a thread" with a
deferred.
Twisted experts -- please explain the drawbacks of this approach...
By the way, the Twisted documentation has got way way better than I
remember it being in 2006.
-- William
Glenn Tarbox, PhD
This sounds fine to me. Threads are nasty when they can clobber each other. This function "appears" to be off in its own little corner doing its own thing. Doing a bunch of work to segment the zipping seems a bit overkill unless you fall into GIL madness and the entire process bogs down from the lock (all depends on how zip is implemented in python)
I don't know how the zipping is done, but one alternative is to spawn a child process using Twisted which also uses a deferred which fires when the child dies. The advantage here would be other cores doing the work... This probably only makes sense if a command line zip mechanism is easy.
By the way, the Twisted documentation has got way way better than I
remember it being in 2006.
Horrors!!! This must be stopped! What happens if this sort of thing catches on and, say, somebody documents Linux. All the benefits of being "gurus" would disappear... think of it... personal hygiene, appearance... even.... I hesitate to say... girls (or guys... you get the picture)...
We'd just be geeks all over again... 40 years of liberation and dominance wiped out.
-- William
--
Glenn H. Tarbox, PhD || 206-274-6919 || gl...@tarbox.org - xmpp || ghtdak - aim,jabber,IRC,yahoo

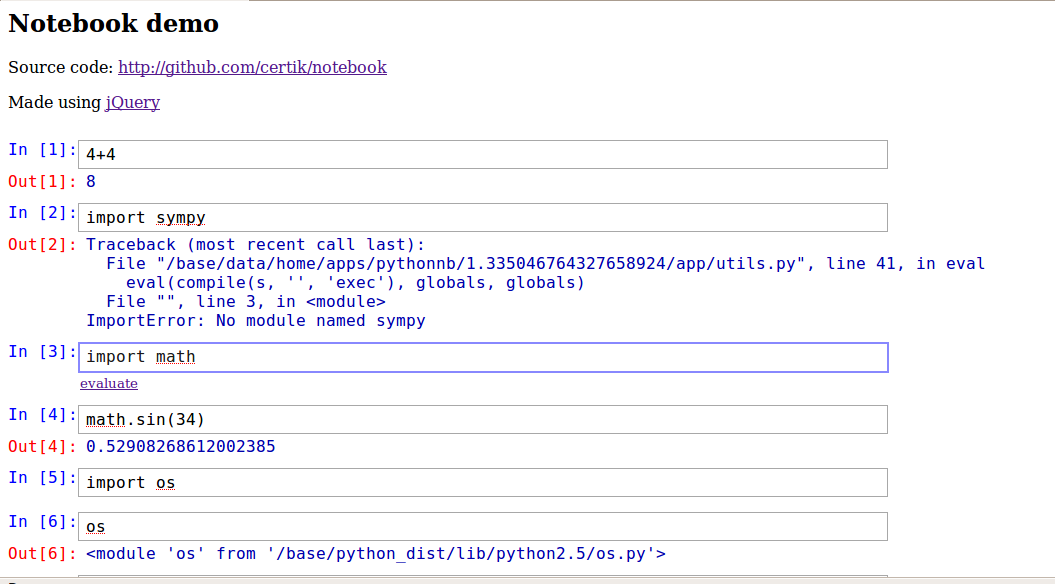{kind=link}
Harald Schilly
> That's it. It worked first try, and solves the problem.
I'm not a twisted expert, but i know a lot about threads and sub
processes. The basic problem is, that the user calls something
synchronized when he/she requests a zip, but behind the scenes it's
done asynchronous. If you have solved this, perfect. The only case you
should try to catch is, when the subprocess takes a little bit longer
and the user thinks it didn't work and starts the zipping again. Does
it prevent double invocations and is there a feedback if the process
fails / takes too long (timeout) ? These are the things that come to
my mind ... just in case you haven't already thought about them ;)
H