Easy way to turn *off* certain jobs?

Jake Biesinger

Leo Goodstadt
Dr. Leo Goodstadt
Jacob Biesinger
The way to turn it off would be to remove its downstream dependencies, I suppose. Would that make sense?I could add an extra keyword @inactive or @active, but only if it would be of general use, and I can't see that at the moment.
What about a pipeline_remove_task function?
Leo Goodstadt
Jacob Biesinger
The @active or @inactive keyword was intended exactly in the sense of @conditional_run.The major point about adding decorators isn't the changes required but making sure thatthe number of decorators don't spiral out of control: keywords are a precious resource!
How about1) Let me ask around to see if anybody objects to have some such facility, or have other opinions on it,or perhaps are desperate for such a feature.
2) We try to come up with a really good name. Something more immediately obvious than@conditional_run (This is my subjective judgement: I am open to persuasion.)Suggestions include@active_if
@include_task_if
@run_if
3) If we implement this, let us not export this keyword automatically. So you wouldneed to write eitherfrom ruffus import conditional_run
import ruffusrf = ruffus
What do you think?
Leo Goodstadt
>> @active_if
>
>
> + 1 for active_if -- much better than my conditional_run
Agreed
>
>
>>
>>
>> 3) If we implement this, let us not export this keyword automatically.
>
> this would be fine-- I never do a 'from ruffus import *' anyway as I like to know where those functions and decorators are coming from.
Agreed. That is what I do as well. But other people do
from ruffus import *
which is, I guess, my fault for the examples in the docs.
So I was talking nonsense. What I actually meant was having an *additional* nested name space within ruffus for less mainstream or more experimental decorators or syntax.
So it would have to be
from ruffus import XXX.active_if
(Is this the right python syntax?)
Suggestions for XXX are also welcome.
Names turn out to be the second most painful part of changing ruffus. Writing docs is a whole other level of torture...
I am on the road so this will have to await my return next week.
Leo

Bernie Pope
> 2) We try to come up with a really good name. Something more immediately obvious than
> @conditional_run (This is my subjective judgement: I am open to persuasion.)
> Suggestions include
> @active_if
> @include_task_if
> @run_if
How about:
@when
(which was inspired by the monadic function in Haskell of the same name).
Cheers,
Bernie.
Leo Goodstadt
Jacob Biesinger
@when would be among my first choices but are not such simple names a liability in terms of clashes with variable names?
Jacob Biesinger
So I was talking nonsense. What I actually meant was having an *additional* nested name space within ruffus for less mainstream or more experimental decorators or syntax.
So it would have to be
from ruffus import XXX.active_if(Is this the right python syntax?)
Suggestions for XXX are also welcome.
Leo Goodstadt
Bernard Pope
Cheers,
Bernie.
Leo Goodstadt
Jake Biesinger

Leo Goodstadt
Just wanted to say I think this is a *necessary* feature for the future of ruffus.
and task3 is inactive, then task2 will still run as well as task1-task8

Giovanni Marco Dall'Olio
In principle, a real pipeline (the one with the tubes and water in it) doesn't have "if" conditions. It is not that the water can choose whether to enter or not in pipe given some conditions, or that the pipeline changes its structure depending whether there is oil or water running in it.
With Makefiles, you usually tend to avoid conditions and loops because they make the code difficult to understand.
What I am saying is that you should keep your pipeline as simple as possible and leave the if conditions inside the function called. So, if you think that it is not appropriate to call GLITR every time, just write the condition within function that calls it and this will make your pipeline easier to understand. In principle, each run of the pipeline, with different data, should follow the same steps.
Giovanni Dall'Olio, phd student
Department of Biologia Evolutiva at CEXS-UPF (Barcelona, Spain)
My blog on bioinformatics: http://bioinfoblog.it
Leo Goodstadt

Ryan dale
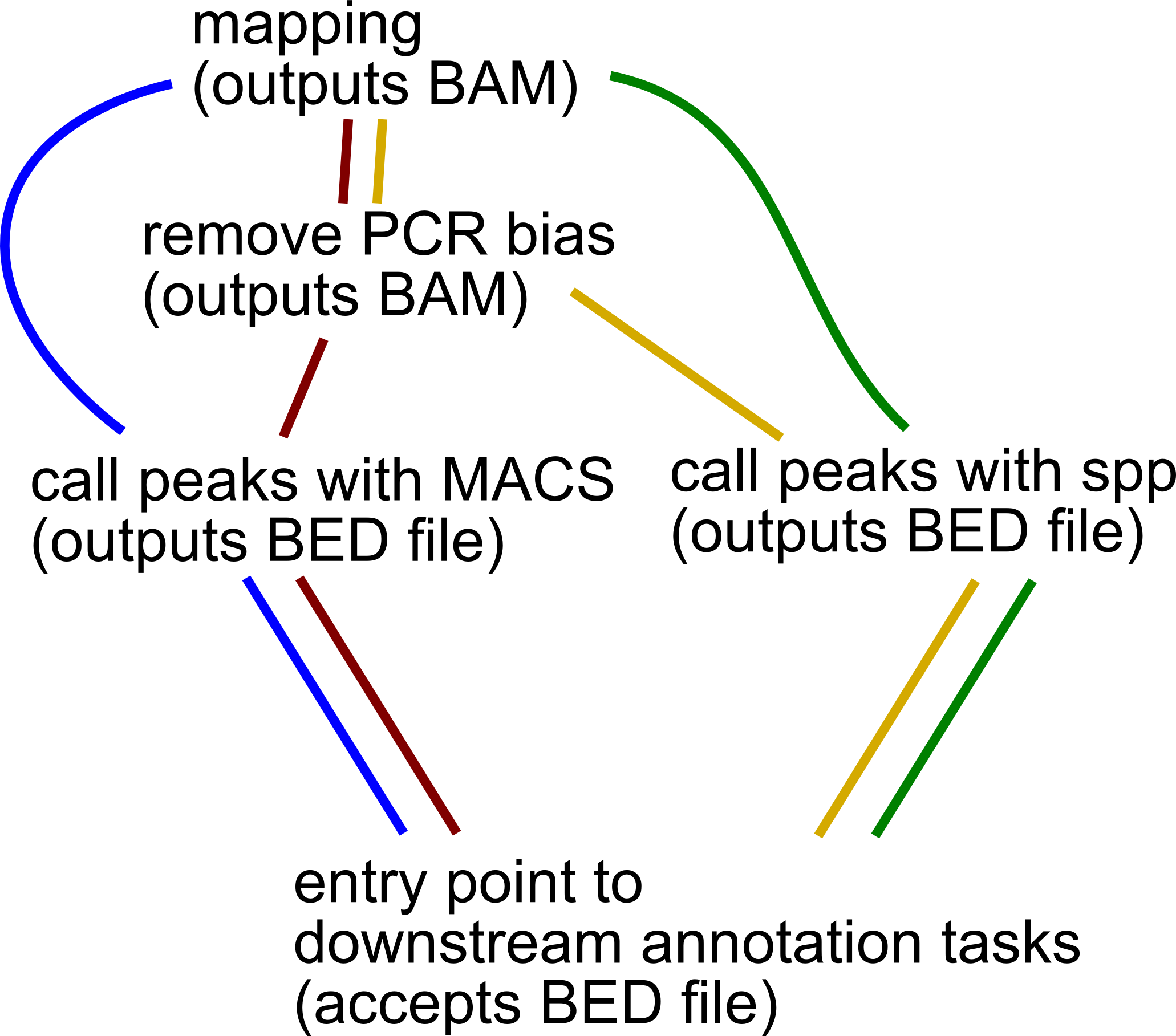
As a concrete example, I've attached what I'd consider to be typical pipeline tasks. I've connected them in different ways (each path colored differently) that would be nice to enable/disable based on a config file as has been discussed.
This actually shows two different kinds of steps. The PCR-bias filter step is optional (e.g. via the @active_if decorator). So that's an on/off state. But the peak calling is an either/or choice.
How about an @optional_after and @alternative_after, in addition to @active_if, to better specify what should happen downstream?
Mock-up code below. Basically the PCR-bias filtering step is marked as optional, while the peak calling steps are marked as alternatives. The @transform decorators accept alternatives() calls to indicate which tasks they should look upstream for to get their inputs from.
Just tossing out ideas, who knows if what I've written below would actually work. But definitely +1 from me for adding some sort of pipeline-changing functionality, in whatever form it ends up taking.
def mapping(infile,outfile):
# make bam file
pass
@optional_after(mapping)
@active_if(config.pcr)
@transform( mapping, "*.bam", "*.bias-removed.bam")
def pcr_bias_filter(infile,outfile):
# make filtered bam file
pass
@tranform( alternatives(pcr_bias, mapping), suffix("*.bam"), "*.bed")
@alternative_after(pcr_bias, mapping)
@active_if(config.macs)
def run_macs(infile,outfile):
# make bed file
pass
@tranform( alternatives(pcr_bias, mapping), suffix("*.bam"), "*.bed")
@alternative_after(pcr_bias,mapping)
@active_fi(config.spp)
def run_spp(infile,outfile):
# make bed file
pass
@transform( alternatives(run_macs, run_spp), suffix("*.bed"), ".annotation")
def annotation(infile,outfile):
pass
-ryan
-- Ryan Dale, PhD Bioinformatics Scientist, NIH/NIDDK Contractor, Kelly Government Solutions
Leo Goodstadt
Giovanni Marco Dall'Olio
[jobs_that_need_macs, other_jobs] = determine_which_jobs_need_macs()
make_macs(jobs_that_need_macs)
make_other_jobs(other_jobs)
resume_results()
For example, on your pipeline:
# mapping
all_bams = mapping()
# applying PCR filters
[PCR_biased_bams, other_bams] = determine_which_bams_are_biased(all_bams)
filtered_bams = biasfilter(PCR_biased_bams)
all_bams_including_filtered = merge(other_bams, filtered_bams)
# determine call method. Notice how this can now be moved a step after bias filter
[bams_to_be_analyzed_with_MACS, bams_to_be_analyzed_with_spp] = determine_calling_method (all_bams_including filter)
macs_beds = call_peaks_with_MACS(bams_to_be_analyzed_with_MACS)
spp_beds = call_peaks_with_spp(bams_to_be_analyzed_with_spp)
all_beds = merge(macs_beds, spp_beds)
# final point
entry_point_downstream_annotation(all_beds)
This is not very different from what you have posted, but here the decisions are made inside a function. To me, this looks easier to read; moreover, it's easier to parallelize.
Hope it will be useful for you.
Ryan dale
So I am extremely, extremely loathe to make things more complicated rather thansimpler.
I like the "if use_task_1 else None" idea with @transform. Assuming the addition of @active_if, I think the code below would run the example pipeline in my previous message (I could be wrong though) :
apply_filter = True
use_macs = True
use_spp = False
def mapper(infile,outfile):
pass
@transform(mapper if apply_filter else None, suffix('.bam'), '.filtered.bam')
def pcr_filter(infile,outfile):
pass
@active_if(use_macs)
@transform(pcr_filter if apply_filter else mapper,
suffix('.bam'), '.macs.peaks.bed')
def run_macs(infile,outfile):
pass
@active_if(use_spp)
@transform(pcr_filter if apply_filter else mapper,
suffix('.bam'), '.spp.peaks.bed')
def run_spp(infile,outfile):
pass
@transform(run_spp if use_spp else run_macs)
def downstream(infile, outfile):
pass
One limitation to this is that the downstream() task forces a binary choice between peak callers.
One way around this could be to provide a function that returns an upstream task to use as the "parent" to downstream().
def parent_tasks_of_downstream():
if use_spp:
return run_spp
if use_macs:
return run_macs
if use_pics:
return run_pics
But this function would awkwardly have to be declared right before downstream() so as to have the run_spp, run_macs, and run_pics tasks already defined.
Perhaps another option would be to allow string task names, like @follows does. Then the trick is to decide what should be considered a task name and what should be a filename.
-ryan
Jacob Biesinger
I like the "if use_task_1 else None" idea with @transform. Assuming the addition of @active_if, I think the code below would run the example pipeline in my previous message (I could be wrong though) :
Perhaps another option would be to allow string task names, like @follows does. Then the trick is to decide what should be considered a task name and what should be a filename.
@transform(((task1 if use_task_1 else IGNORE_TASK),task2 if use_task_2 else IGNORE_TASK)), suffix(".bam"), ".alt.bam")def real_bammer(infile,outfile):pass
This syntax is more python-y rather than ruffus-y in approach.
The alternative would be have some sort of conditional wrapper around each task,sort of along the lines your suggest, and analogous to @active_if to indicate whetherthe task should be a real dependence.
Here is some possible syntax:
The new keyword would beget_input_if(This is really awful name: suggestions welcome).
I wonder whether it is correct to have 'if' statements in a pipeline.
In principle, a real pipeline (the one with the tubes and water in it) doesn't have "if" conditions. It is not that the water can choose whether to enter or not in pipe given some conditions, or that the pipeline changes its structure depending whether there is oil or water running in it.
With Makefiles, you usually tend to avoid conditions and loops because they make the code difficult to understand.
What I am saying is that you should keep your pipeline as simple as possible and leave the if conditions inside the function called. So, if you think that it is not appropriate to call GLITR every time, just write the condition within function that calls it and this will make your pipeline easier to understand. In principle, each run of the pipeline, with different data, should follow the same steps.
2) If the inactive task was up to date and did not produce any output
I think this means that all tasks functions of an entire branch *may* have to be tagged with @active_if.
This does mean that if you have the following scenario
-> task2 -> task3-> task4task1 -> task8-> task5 -> task6 -> task7
and task3 is inactive, then task2 will still run as well as task1-task8task4 will have no inputs unless it has extra dependencies which arenot inactive.
Jacob Biesinger
In order to avoid conditions, you just have to put the decisions inside a function. For example:
[jobs_that_need_macs, other_jobs] = determine_which_jobs_need_macs()
make_macs(jobs_that_need_macs)
make_other_jobs(other_jobs)
resume_results()
Giovanni Marco Dall'Olio
[jobs_that_need_macs, other_jobs] = determine_which_jobs_need_macs()
run_macs(jobs_that_need_macs)
run_other_jobs(other_jobs)
resume_results()
Look at the complete example in my previous mail, that should be clearer.
Jacob Biesinger
run_other_jobs(other_jobs)
resume_results()
Leo Goodstadt
Dale, Ryan (NIH/NIDDK) [C]
________________________________________
From: Jacob Biesinger [jake.bi...@gmail.com]
Sent: Friday, February 25, 2011 8:30 PM
To: ruffus_...@googlegroups.com
Cc: Dale, Ryan (NIH/NIDDK) [C]; Leo Goodstadt
Subject: Re: Easy way to turn *off* certain jobs?
Leo Goodstadt
Jacob Biesinger
--
Jake Biesinger
Graduate Student
Xie Lab, UC Irvine
Jacob Biesinger
Jake Biesinger
Graduate Student
Xie Lab, UC Irvine
Jacob Biesinger
Jake Biesinger
Graduate Student
Xie Lab, UC Irvine
Bernie Pope
Sorry to dig up an old thread. I find myself in the position of needing conditionals in my pipeline and I can't see an easy workaround.
I wonder if this feature has been implemented/included?
Cheers,
Bernie.
> <task.py.active_if.diff><ruffus_test.py><ruffus_utils.py>
Jacob Biesinger
--
Jake Biesinger
Graduate Student
Xie Lab, UC Irvine
Bernie Pope
On 30/09/2011, at 4:55 PM, Jacob Biesinger wrote:
> It takes a boolean, a list of booleans, or a function that returns one of those, and doesn't run if any of the booleans are False.
That looks quite cool.
> Another way of doing the conditionals is shown in Ryan Dale's code here:
> https://github.com/daler/pipeline-example/blob/master/pipeline-3/pipeline.py
Oh great, that looks like it will do what I want.
Cheers,
Bernie.
Leo Goodstadt
I implemented the @active_if decorator in https://github.com/jakebiesinger/ruffus
| 1954 | # I thought overwriting the param_generator_func et al would lead to | |
| 1955 | # trouble with the order of decorator nesting, but it seems to work fine |
Another way of doing the conditionals is shown in Ryan Dale's code here:
top level functions in multiprocessing (pickling)...
Leo Goodstadt
On 30 September 2011 07:55, Jacob Biesinger <jake.bi...@gmail.com> wrote:I implemented the @active_if decorator in https://github.com/jakebiesinger/ruffusYour @active_if code looks great. Would you mind contributing it to the main Ruffus code?
Would you like to be listed as a contributor / co-author?
pipeline_active_if = None
# # task with active state switching # @active_if(lambda:pipeline_active_if) @transform(...) def test_task(...): pass
# activate task pipeline_active_if = True pipeline_run([test_task], ...)
# inactivate task pipeline_active_if = False pipeline_run([test_task], ...)
self.param_generator_func self.needs_update_func
make_job_parameter_generator(...) printout(...) signal(...)
Leo Goodstadt

{kind=link}
Eleftherios Avramidis
Leo Goodstadt
inputs, and whose
activation / deactivation logic is the OPPOSITE of task3?
You can think of task3 and anti_task3 as switches in a pipelines so
that the water
(your data) flows one way or another.
This seems to be slightly less magical but clearer. I am trying to
steer clear of
magic in Ruffus now!
Leo
On Dec 16, 5:17 pm, Eleftherios Avramidis
Eleftherios Avramidis
Though there is nothing magical in case one job should be skipped. It is a rather common experimental pipeline case to turn off one job, and then get the requirements of the dependant (next) job directly from the input of the skipped job.
If this "input passing" is not supported, then when I turn off one job, I have to either change the dependencies of the next job, or write an anti-job to copy/link the files. Which is not much of an offer from @active_if, because I could not use this decorator at all, and write an if(disable_check): shutil.link(input, output) in the job; which by the way is what I have ended up doing for all of my jobs that may need turning off.
Eleftherios Avramidis
I.e. the following gives an error if features_lm_target has been deactivated
@active_if(cfg.exists_lm(target_language))
@transform(data_fetch, suffix(".orig.jcml"), ".lm.%s.f.jcml" % target_language, target_language, cfg.get_lm_name(target_language))
def features_lm_target(input_file, output_file, language, lm_name):
#code goes here
@collate([data_fetch features_lm_target], regex(r"([^.]+)\.(.+)\.f.jcml"), r"\1.all.f.jcml")
def features_gather(singledataset_annotations, gathered_singledataset_annotations):
#code goes here
I would need a way to check that the items in the @collate input are active, before importing them. Any suggestion?
Jacob Biesinger
In a command which is merging/collating output from several tasks, how can include output from the previous steps which have not been inactive?
I.e. the following gives an error if features_lm_target has been deactivated
@active_if(cfg.exists_lm(target_language))
@transform(data_fetch, suffix(".orig.jcml"), ".lm.%s.f.jcml" % target_language, target_language, cfg.get_lm_name(target_language))
def features_lm_target(input_file, output_file, language, lm_name):
#code goes here
@collate([data_fetch] + [features_lm_target] if cfg.exists_lm(target_language) else [], regex(r"([^.]+)\.(.+)\.f.jcml"), r"\1.all.f.jcml")