How to avoid callback hell?

Matthew Hazlett
connects to a tcp port.
I can get the query working if I do everything as callbacks:
db.open(... fn() {
db.collection(.... fn() {
db.query(...... fn() {
});
});
});
But as you can see this creates callback hell.
What I would like to do is have a class, but being as everything is
async it makes it incredibly difficult to ensure all your variables are
set.
var client;
db.connect(connect, fn(){
client = connect;
});
client.close();
Will cause an error because client hasn't been set yet. Another thing I
thought of doing was chaining it all together:
db.connect(connect, fn(){
...
process.nextTick(fn(){ doNext(); });
});
this gets very messy and hard to manage, how can I deal with callback hell?

Alexey Petrushin
It seems this is the most popular type of question in the Node community :)There are tons of libraries to fight it, async.js (allow to write state machine instead of callbacks), iced coffee script (code manipulation, really cool thing), fibers (node extension to create pseudo - syncronous code).I personally prefer fibers, You may take a look at this spec/test as a sample of how to use fibers with DB calls https://github.com/alexeypetrushin/mongo-lite/blob/master/test/collection.coffee , more details here http://alexeypetrushin.github.com/synchronize .
Alexey Petrushin

Mark Hahn

Matt Patenaude
db.query(query, callback);
});
});
> But as you can see this creates callback hell.It doesn't look that bad to me.
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
nodejs+un...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/nodejs?hl=en?hl=en
Matthew Hazlett
Matt Patenaude
Matt Patenaude

Marak Squires
Matthew Hazlett

Bryan Donovan
Sent from an iPhone.
Matthew Hazlett
getApp: function(appid) {
this.useConnection( function(db, client) {
this.useCollection(db, 'authors', function(collection) {
this.useQuery(collection, {'apps.id':appid}, function(data) {
console.log(data);
}.bind(this));
}.bind(this));
}.bind(this));

mscdex
> It works but its still calllback hell :-( The db connection gets reused
> tho.
callbacks:
1. Pull out some or most of the anonymous functions/callbacks, change
them to named functions, place them outside of the current function
scope (I usually put them in the global/module-level scope), and use
those named functions instead.
2. Use async.js for anything that can't be easily handled/abstracted
by #1: `npm install async` or: https://github.com/caolan/async. It
doesn't use fibers, coroutines, threads, etc, just plain helper
functions to perform asynchronous tasks in a more organized fashion.
Marak Squires
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
nodejs+un...@googlegroups.com
For more options, visit this group at
http://groups.google.com/group/nodejs?hl=en?hl=en

knc
For more options, visit this group at
http://groups.google.com/group/nodejs?hl=en?hl=en
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
For more options, visit this group at
http://groups.google.com/group/nodejs?hl=en?hl=en
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
Mark Hahn
@useConnection (db, client) =>
@useCollection db, 'authors', (collection) =>
@useQuery collection, 'apps.id':appid, (data) ->
console.log data

Glenn Block
Mark Hahn

Bruno Jouhier

Roly Fentanes
Matthew Hazlett
if the connection already exists it doesn't recreate it, It passes the existing one to the callback.

Martin Wawrusch

Tim Caswell
First of all, three levels deep is not that bad at all. My personal threshold is around 5 levels. Also, despite being the author of half a dozen control flow libraries, I never use any of them anymore. I don't like the extra dependency on my library or app, and most importantly, I don't like all the inserted frames in my stack traces.
My favorite techniques are:
- Function composition. Take common steps that involve two or more a sync layers and write common functions for then. Pass in all the needed state as arguments so they don't need to be nested. Or if there is a lot of needed state, next it in one or more layers, and pass in just some state. The trick is to find places where your business logic naturally form narrow points and cross there.
- Serial actions I just nest. This is true especially if each step depends on state from a previous step. If it didn't depend on the outcome of a previous step, then why not do them in parallel? The natural closures that nesting provides gives you access to all the state you need.
- For parallel work I just create a descriptive counter variable and call a common named `check` function that decrements the counter and checks if it should move on to the next named step function.
The take away is less is more. 90% of the time you don't need a library at all. Just be aware of how closures and named functions work and take advantage of the tools the language already provides.
- Tim Caswell
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
Mark Hahn
Bruno Jouhier
If (f1(_).p1 < f2(_).p2) return f3(_).f4();
Libraries don't help much with that kind of simple logic.

jan zimmek
rules which are implemented in dozens of nested callbacks. we use
coffeescript and most code have already been encapsulated in functions
to lessen the complexity.
but i would be more than happy to get rid of most of the (unnecessary)
callbacks and being able to use condition/loops/etc. again.
also it looks like a wonderful solution i am still a bit worried about
using streamline. is it mature enough to be used in production, are
there any projects already using it ?
jan

Joe Ferner
node-fibers) under the covers and fibers requires isolates which is
now deprecated and is going to be removed if it hasn't already. I also
think that the way it works under the covers also incurs performance
impacts because it ends up implementing threading which is slow. If
you like non-callback APIs I just wouldn't use node if I were you.
I like using the async library when things get complicated.

Marco Rogers
Joe Ferner
work.
On Apr 9, 6:08 pm, Marco Rogers <marco.rog...@gmail.com> wrote:
> I'm confused about this. Isolates is being removed from node, not from v8.
> node-fibers should still be able to use them right?
>
>
>
>
>
>
>
> On Monday, April 9, 2012 2:51:24 PM UTC-7, Joe Ferner wrote:
>
> > Many streamline like APIs use node-fibers (https://github.com/laverdet/

Rehan Iftikhar

Ryan Schmidt
On Apr 9, 2012, at 16:28, jan zimmek wrote:
[snip]
> i am still a bit worried about
> using streamline. is it mature enough to be used in production, are
> there any projects already using it ?
The claim I've seen made on this list several times is that streamline is robust enough to use in production. I don't know any specific sites using it.
There's another solution, TameJS, by the creators of OkCupid:
They used it to build their large dating site, so it's demonstrably ready for production.

Andy
If your code is private, if it's no API, use promises my friend! You'll soon see why!
Tired of error passing? Tired of nests? With deferred functions, you will have no stress!
var q = require('q');
q.ncall(db.open, db)
.then(function() {
// What we are doing here is WHEN the db.open statement is finished
// we return a NEW promise saying that hey, we want to wait for
// db.collection to finish.
return q.ncall(db.collection, db, 'collection name')
}).then(function(collection) {
// Now we know our db.colleciton statement is done. What if
// there is no collection!?
// Example for what to do if you need conditional logic
if(!collection) {
return q.ncall(db.createCollection, db, 'colllection name');
}
}).then(function(collection) {
return q.ncall(db.query, db, collection, 'query');
}).then(function (queryResults) {
// I have query results! yay!!
console.log(queryResults);
}).fail(function(err) {
console.log('one of the above steps went irreversibly wrong!', err);
});
But what, you ask, about external libs? Ones that need to use your code? Won't with q they quib?
It's simple you see. For them you say:
I can use q all I want. But when I'm done, I'll send a callback your way!
Bruno Jouhier
Streamline does not rely on any c++ or threads.. It is a pure JS solution and it runs in browsers (someone is using it with iPhone safari).
There is an option to use fibers but it is just an option.
Fibers does not use isolates. It uses threads.
In short you got it all wrong!
Bruno Jouhier

Nuno Job
Bruno Jouhier
I cannot disclose what we are doing with it yet. But Sage is a well established company and our team has been using it for more than a year.
Matthew Hazlett
I will say that, I opted not to use any sort of Async library, but
instead opted to build my application the way the framework was
designed. Thanks again.
Matthew

Richard Marr
+1

Mariusz Nowak

Marcel Laverdet
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
Alexey Petrushin

Jorge
> Many streamline like APIs use node-fibers <https://github.com/laverdet/node-fibers> under the covers and fibers requires isolates which is now deprecated and is going to be removed if it hasn't already.
Isolates are *not* a feature of node, Isolates are a part of v8 and aren't deprecated nor going to be removed.
> I also think that the way it works under the covers also incurs performance impacts because it ends up implementing threading which is slow.
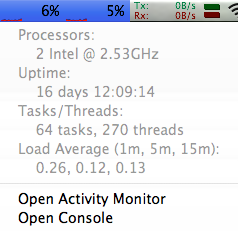
That's funny because every process in your machine *is* a thread (at least one thread), and nearly 100% of them have more than a thread, e.g. FYI a node process normally uses 3 (and up to 5) threads itself. Right now in my Mac as I write this, there are 64 processes and 270 threads running, simply because threads are the essential building block to achieve concurrency and parallelism:

Oliver Leics
>> If
>> you like non-callback APIs I just wouldn't use node if I were you.
>
Over the years I have seen uncountable pieces of code and grownup
software with 'hard-to-follow' logic, the majority being quite
synchronous code.
Jorge
> (...)
>
> if you wish to use fibers go ahead and do so. Please put it in the readme of your project so I know not to use it.
"so I know not to use it"
What a fine example of fundamentalism. Couldn't you simply express gratitude to Marcel for his (awesome) contribution instead? Or are we going to start throwing stones at each other? If so, Houston, there's a problem.
--
Jorge.

Yi Tan
you really should spend a few hours learning coffee script if the js callback syntax make you uncomfortable
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
Bruno Jouhier
It's like you have to follow the dogma and the last thing you should do is try things out and make up your own mind.
Come on guys, I don't care if you'll end up using streamline or not but please BE CURIOUS AND TRY THINGS OUT.
Joe Ferner
> On Apr 9, 2012, at 11:51 PM, Joe Ferner wrote:
>
> > Many streamline like APIs use node-fibers <https://github.com/laverdet/node-fibers> under the covers and fibers requires isolates which is now deprecated and is going to be removed if it hasn't already.
>
> Isolates are *not* a feature of node, Isolates are a part of v8 and aren't deprecated nor going to be removed.
>
streamline was using fibers exclusively since it showed up in the
fibers wiki and I couldn't find the source on github because there
wasn't a link in npm. After glancing at the code it looks to be
overriding the require statement and modifying the Javascript.
> > I also think that the way it works under the covers also incurs performance impacts because it ends up implementing threading which is slow.
>
> That's funny because every process in your machine *is* a thread (at least one thread), and nearly 100% of them have more than a thread, e.g. FYI a node process normally uses 3 (and up to 5) threads itself. Right now in my Mac as I write this, there are 64 processes and 270 threads running, simply because threads are the essential building block to achieve concurrency and parallelism:
>
thread switching, locks, etc. Sure node has 3 threads but that is very
small compared to say a Java server or a Ruby server which could have
100s. I should have said thread "like" because it is doing a type of
threading (coroutines) as your code gets called it is swapping out the
execution stack from a previously saved state which does have
performance implications.
> PastedGraphic-2.png
> 41KViewDownload
>
>
> > If
> > you like non-callback APIs I just wouldn't use node if I were you.
>
>
>
My main point is that if you don't like callbacks then node might not
be the language for you. Adding layers just slows the performance and
defeats some of the benefits to using node. You would have probably
been better off just writing your app in Ruby, Java, or Dart for that
matter. I would love to see real world benchmarks to prove me wrong
because the idea of not having many nestings of callbacks would be
nice.
> --
> Jorge.
Bruno Jouhier
You are just such a concentrate of preconceived ideas.
Take a realistic bench case, implement it with streamline and fibers and then come back to us with figures. From my experience there are code patterns where fibers beats callbacks 10 to 1.
Si please stop your bs and get real.
Joe Ferner
> @joeferner
>
> You are just such a concentrate of preconceived ideas.
>
> Take a realistic bench case, implement it with streamline and fibers and then come back to us with figures. From my experience there are code patterns where fibers beats callbacks 10 to 1.
>
> Si please stop your bs and get real.
I think it demonstrates the calling overhead quite well.
https://gist.github.com/2351793
On my machine I get 75ms for the streamline example and 3ms for the
pure node example. That's 25 times slower. I will agree that for many
real world cases this is a tiny piece of the overall time, but it does
exist, and for me I'm not willing to take that on.
Now that I've used streamline, I'm also not excited about having to
run _node or precompiling my javascript using "node -c". Running my
unit tests and deploying to my servers just got one step harder and
added to the overall complexity.
Bruno Jouhier
Streamline does not transform sync fonctions. So the Streamline version of this bench should take 3 ms.
Callback != asynchronous
Try again with an async call
Joe Ferner
with some async code https://gist.github.com/2352116 again a bit
contrived because I really didn't want to spend much time on this.
streamline did close the gap a bit which is what I suspected when I
said "I will agree that for many real world cases this is a tiny piece
of the overall time". But it was still twice as slow. (node 565ms and
streamline 1049ms)

Axel Kittenberger
> you really should spend a few hours learning coffee script if the js
> callback syntax make you uncomfortable
Unless coffee script fixes its "implicit local variable is global if
the names match and just dont take care to not accidently name it
equally" I will not touch it with a long stick.
Anyway, I find this node.js and callback arguments popping up again
and again very similar to what happens when asking the PHP guys and
gals why func()[1] is not a valid language construct? They get all
miffed usual arguments follow, and it happens all the time again. I
suppose simply because deeply within they know there is some
fundamental problem, but convince themselves with far fetched
arguments like "just get a larger screen" etc. at least as much as the
repeated questions. Only long after the lifecycle of software solution
people come, well yes that sucked didn't it? We kinda knew it all the
way, but we just decided to ignore it.
Maybe you have other good examples?
Ask GNOME 3 why the panel is no longer customizeable.
Ask TCL what the they where thinking when they handled every integer
variable as string.
Ask Java why multiple inheritence was that bad after all, and all the
workarounds they later needed for it. You got an Inputstream object
and Outputstream object, but how to get an InputOutputStream?
Ask Javascript, about 'this'.
Ask terminal guys, about why terminal emulations are that complicated
and never compitabitle to anything else.
Ask Windows why \r\n, ask why they never ever managed to abolish drive letters.
Ask Apple why \n\r
Ask Linux why inotify and fanotify while both being non-satisfactory
for any usecase but the single one they were designed for.
etc.
So now that I annoyed every tech group there is, I better get logged
of for a while :-)))
Marcel Laverdet
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
Axel Kittenberger
> func()[1] not being allowed in PHP is just a silly deficiency in the
> language grammar and runtime. I "fixed" it in 2009 with a rewrite rule
> (right before APC in the compile chain). func()[1] -> _helper(func(), 1). I
> have a habit of not accepting languages the way they're given to me I guess.
You are right, the problems don't compare well, but I compared the
community reactions when yet another time someone new mentions it, yet
another time, and everybody goes "oh no, not again. stop trolling us.
you can work around this or that or thut way." but in the core its a
silly deficiency.
I suppose when generators come to V8 we might see a new generation of
workarounds 'ehhh I mean solutions.
Bruno Jouhier
* The streamline program calls socket.write from the callback of the previous socket.write. So it does proper flow control and it won't overflow output buffers.
* The callback program calls socket.write in a loop, without chaining them through the callbacks. No flow control here!
So please, go back to the drawing board and come back with a fair bench.
Hint: the callback version should not run the bench with a for loop, it should transform the loop into a recursion (which is what streamline does).
Alexey Petrushin
Joe Ferner
benchmark that shows streamline is faster I'm still not going to use
it and I couldn't recommend anyone else use it either. The community
as a whole doesn't back that kind of syntax so I couldn't submit a
module to npm if I wrote it using streamline. As I said before I can't
easily run my unit tests or deploy to my server environment. From the
little that I used it, it screws up the stack trace, you get weird
errors like "Function contains async calls but does not have _
parameter" which IMO shouldn't be an error at all. And it obscures
what is really going on under the covers which you pointed out quite
well in your most recent comments.
On Apr 10, 3:24 pm, Bruno Jouhier <bjouh...@gmail.com> wrote:
> Still, your bench is wrong because the two programs do different things:
>
> * The streamline program calls socket.write from the callback of the
> previous socket.write. So it does proper flow control and it won't overflow
> output buffers.
> * The callback program calls socket.write in a loop, without chaining them
> through the callbacks. No flow control here!
>
> So please, go back to the drawing board and come back with a fair bench.
>
> Hint: the callback version should not run the bench with a for loop, it
> should transform the loop into a recursion (which is what streamline does).
>
>
>
>
>
>
>
> On Tuesday, April 10, 2012 5:32:45 PM UTC+2, Joe Ferner wrote:
>
> > On Apr 10, 11:12 am, Bruno Jouhier <bjouh...@gmail.com> wrote:
> > > Your bench does not make sense. There is no async call at all. So there
> > is no reason to have an _ in the streamline source.
>
> > > Streamline does not transform sync fonctions. So the Streamline version
> > of this bench should take 3 ms.
>
> > > Callback != asynchronous
>
> > > Try again with an async call
>
> > I was trying to demonstrate the call overhead but here is an example
Axel Kittenberger
> parameter" which IMO shouldn't be an error at all.
By all respect you just got little clue. This error is *good*, since
it does not allow functions to "yield under your ass", which would
technically be impossible in streamline anyway.
Rest of the argument now you fail with benchmarking is "because I say
so.". Streamline will run in full potential since it does nothing else
than to write the correct javascript for you. The only drawback is,
that its syntax is not natively understood by V8 thus error messages
contain different text, and if you are using some debugger, it might
look a different else than what you expected.

Naouak
Bruno Jouhier
function foo(x, y, _) { ... }
Normal JS modules (not written with streamline) will be able to call it as:
foo(x, y, function(err, result) { ... });
Streamline is just a tool that helps you write your code. This tool produces vanilla JS that follows the standard node callback conventions. So you can publish it to NPM, you won't be forcing anyone else to use streamline. That's like coding a module in CoffeeScript.
Regarding the stack traces, streamline reconstructs the "synchronous" stack that led to the exception. This is a big plus as the callback stack is usually not very helpful (and if you really want it, you have it with ex.rawStack).
The error message that bugs you is a feature. It ensures that all the yielding points are explicit.
Regarding performance, there is still a need for real benchmarks that compare apples with apples (code that does flow control with code that does flow control). Your half baked pseudo benches are just useless.
Bruno
Joe Ferner
> > errors like "Function contains async calls but does not have _
> > parameter" which IMO shouldn't be an error at all.
>
> By all respect you just got little clue. This error is *good*, since
> it does not allow functions to "yield under your ass", which would
> technically be impossible in streamline anyway.
>
socket.connect(1111, 'localhost', function() {
...
});
instead of
socket.connect(1111, 'localhost', _);
If I want to mix the syntax, let me, don't error out.
> Rest of the argument now you fail with benchmarking is "because I say
> so.". Streamline will run in full potential since it does nothing else
> than to write the correct javascript for you. The only drawback is,
> that its syntax is not natively understood by V8 thus error messages
> contain different text, and if you are using some debugger, it might
> look a different else than what you expected.
come up with Bruno will find another reason why it isn't valid.
It's not just different text it's a completely different stack trace
so I would have no hope in finding out what failed, especially if it
happened in production. As far as debuggers go, the code looks
completely different not just a little different, it does give me line
numbers which is nice.
Axel Kittenberger
I lets you mix it, you just have to do it correctly. E.g: this works
without error:
function foo(_) {
process.nextTick(_);
console.log('a');
process.nextTick(function() {
console.log('b');
});
}
foo(_);
Don't blame streamline for your own shortcomings. I know of its
drawbacks in debugging mode, but thats about it, i get tired and angry
about the FUD spread around it, and you made a ton of it.
> I just don't have time to write more benchmarks that no mater what I
> come up with Bruno will find another reason why it isn't valid.
Its not like Bruno is doing an evil plot here. Since as long your
benchmark does not compare apple with oranges, it will always be just
as fast as vanilla written code, since in the end, it translates to
vanilla code.
Mark Hahn
the names match and just dont take care to not accidently name it
equally" I will not touch it with a long stick.
Marcel Laverdet
Joe Ferner
On Apr 10, 5:01 pm, Axel Kittenberger <axk...@gmail.com> wrote:
> > If I want to mix the syntax, let me, don't error out.
>
> I lets you mix it, you just have to do it correctly. E.g: this works
> without error:
>
> function foo(_) {
> process.nextTick(_);
> console.log('a');
> process.nextTick(function() {
> console.log('b');
> });}
>
> foo(_);
>
> Don't blame streamline for your own shortcomings. I know of its
> drawbacks in debugging mode, but thats about it, i get tired and angry
> about the FUD spread around it, and you made a ton of it.
and from what I can tell it looks to follow your pattern...
var net = require('net');
function foo(_) {
var socket = new net.Socket();
socket.connect(1111, 'localhost', function() {
var start = new Date();
for (var i = 0; i <= 100000; i++) {
socket.write(new Buffer([i]), _);
}
var end = new Date();
console.log("done: " + (end - start));
socket.end();
});
}
foo(_);
>
> > I just don't have time to write more benchmarks that no mater what I
> > come up with Bruno will find another reason why it isn't valid.
>
> Its not like Bruno is doing an evil plot here. Since as long your
> benchmark does not compare apple with oranges, it will always be just
> as fast as vanilla written code, since in the end, it translates to
> vanilla code.
purely compare the overhead of calling functions using traditional
methods vs streamline. Methods with callbacks are not required to have
async code in them, they just generally do. If you replace doIt with
say a getUserFromCache method where 99% of the time you get cache hits
and the function just returns the user this would be completely valid
and you would incur the penalty. But I played along and tossed in an
async call. Benchmark 2 is valid if you want to send data as fast as
possible to the other side. I would love to see this magical
benchmark that streamline is as fast or faster than node but I have
yet to see it.
Joe Ferner
followers but if you listen to any of the node core team I think you
would hear quite a different story.
Mark Hahn
followers but if you listen to any of the node core team I think you
would hear quite a different story.
Joe Ferner
railed on it for 10 minutes. There is also a pull request (https://
github.com/joyent/node/pull/2472) where they complain about it that is
pretty funny.
Joe Ferner
function(_) {" (missing underscore here).
Mark Hahn
railed on it for 10 minutes. There is also a pull request (https://
github.com/joyent/node/pull/2472) where they complain about it that is
pretty funny.
Joe Ferner
the text of the episodes. They are definitely not coffeescript fans if
you listen through a couple of the episodes.
Mark Hahn

Mikeal Rogers
While our personal views about coffeescript may be negative node is committed to support (but not include or bundle) the use compile target languages. No one will ever have the level of support that javascript has but we won't be going out of our way to disable it.
GitHub Followers are a good indication that something is interesting, they should not be considered supporters or an accurate representation of adoption. For instance:
express: 5,823
npm: 2,605
There is no question that npm has wider adoption than express. While express is hugely popular it *requires* npm to be installed :)
One thing I've noticed is that GitHub followers mean you have something interesting, not that you have something they use. My suspicion is that many followers don't actually use the project they are following but find it interesting enough to keep an eye on.
The closest metric we have for adoption is "depended on" http://search.npmjs.org/. But, this metric also falls short. For instance, depending on express is an indicator of how well it's been adopted by people building plugins, same with connect, but not a good indicator for it's actual adoption since web frameworks are mainly used by applications which are not pushed to the registry. Similarly, coffeescript has a larger representation that it's actual usage since *any* module written in coffeescript includes it as a dependency.
Fibers has about 12 modules that depend on it. Streamline has about 4. If you want to compare that against common utilities that use standard node practices for async (request:420,socket.io.202,redis:175) it's quite low. Even comparing fibers and streamline to popular flow control libraries that use standard node practices (async:354,step:64) fibers and streamline have sparse adoption.
Not saying nobody uses them or that they don't have a bit of a following, but by the actual numbers we have their adoption is quite limited compared with standard node practices, especially when compared to how vocal they are championed on this list whenever a thread like this appears.
It would seem that the majority of node developers are content with standard callbacks and find ways to deal with them and are not running towards blocking style abstractions, they just don't care enough to yell a lot on every thread like the authors of alternatives.
Mikeal Rogers
> They are definitely not coffeescript fans if you listen through a couple of the episodes.I'll take your word for it. I can see where people working at the core level may not be excited about higher-level languages. These same people use c++.
I'm working at the app level and I have 10,000 lines of coffeescript. I can't imagine coding all that in javascript.

Isaac Schlueter
> NodeUp is not exclusively node core committers nor has it ever included the full list of committers so the views represented should not be viewed as "core".
I think Felix and I are the only core committers that have been on NodeUp.
> While our personal views about coffeescript may be negative node is committed to support (but not include or bundle) the use compile target languages.
Node is committed to supporting JavaScript programs. How you write
those JavaScript programs is your own business.
In retrospect, I think require.extensions was a mistake. But it's a
mistake we're stuck with. It mostly stays out of the way, which is
good, I suppose.
> One thing I've noticed is that GitHub followers mean you have something interesting, not that you have something they use. My suspicion is that many followers don't actually use the project they are following but find it interesting enough to keep an eye on.
It also indicates that you need to know when to update a thing. npm
gets updated whenever you get a new version of node. However, a lot
of people post bugs with Express, contribute to it, etc. It's a
run-time dependency, not a dev-time one.
The primary major goal of the Node.js project is to make easy to build
fast network programs. Making things simpler makes them easier, and
hiding the true nature of IO only makes it harder in the long run.
It is not our goal to fix JavaScript syntax (that's tc-39's job).
It is not our goal to make programs look blocking when they are in
fact parallel (that's a bad complexity trade-off).
> I'll take your word for it. I can see where people working at the core level may not be excited about higher-level languages. These same people use c++.
We are excited about writing high performance network programs.
JavaScript is a very easy and effective way to do that. Most of
Node.js is in JavaScript. JavaScript is a higher-level language.
We're very interested in it.
Isaac Schlueter
> It is not our goal to make programs look blocking when they are in
> fact parallel (that's a bad complexity trade-off).
s/parallel/nonblocking/
Mark Hahn
Bruno Jouhier
> For more options, visit this group at
> http://groups.google.com/group/nodejs?hl=en?hl=en
Axel Kittenberger
> use absolutely nothing but coffeescript and I can't imagine living without
> it.
Yes it's a make or break for me. A language that doesn't even get its
scoping at least somewhat right is a no-go for me .Introducing a new
global variable messes up some code that worked before far below just
because it happens to have a local variable named the same way? I
don't even understand what a "great idea" it was to go back to
implicit variable declaration, global or local, while everyone else
after years of experience is pushing that down, a few characters for
declaring a varible (local and global) is nothing compared to the
hours of joy debugging. Javascript idiosyncratic scoping is already
scraping that limit for me, and if it wouldn't have the momentum of
being the web language, I'd already frown about that.
Axel Kittenberger
No, as long the two "benchmarks" behave different IO wise, they are
incorrect and you compare apples with oranges. E.g. If you want to
fill buffers to full limit, and do it both wise. And try to come up
with aproperiate flow control in vanilla code, yes its not uber
trivial to write. Thats the whole point. There is no overhead in
runtime, since streamline will translate to script you would write
anyway. The only overhead is during startup when streamline does the
parsing/generating.
Mark Hahn
The lack of the var statement is the only thing wrong with scoping at the moment and I showed you a nice workaround. Otherwise scoping is more than "somewhat" right and a big improvement over javascript.
Axel Kittenberger
Its not like you got much choice when you do client-side web
development. Default to local is IMHO not any better than default to
global. Why default to anything? Jhint warns nicely about any default
to globals.
> The lack of the var statement is the only thing wrong with scoping at the
> moment and I showed you a nice workaround. Otherwise scoping is more than
> "somewhat" right and a big improvement over javascript.
Bringing us back to the topic of "workarounds" to "problems" not
acknowledged as problems but canted to the "way of [X]".
If I ever put up the focus, I'd rather get my own
javascrip-meta-language that eases/encorages heavy use of immutables
to get another advantage of functional programming in.
Mark Hahn
Axel Kittenberger
translates to Javascript, node.js is the way to go.
On Wed, Apr 11, 2012 at 9:37 AM, Mark Hahn <ma...@hahnca.com> wrote:
> You would obviously be happy with Erlang. Can't you code server-side in
> Erlang?
>
>
> --
> Job Board: http://jobs.nodejs.org/
> Posting guidelines:
> https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
> You received this message because you are subscribed to the Google
> Groups "nodejs" group.
> To post to this group, send email to nod...@googlegroups.com
> To unsubscribe from this group, send email to
> nodejs+un...@googlegroups.com
Richard Marr
> It's like you have to follow the dogma and the last thing you should do is try things out and make up your own mind.
>
> Come on guys, I don't care if you'll end up using streamline or not but please BE CURIOUS AND TRY THINGS OUT.
Considering the variety of replies in the thread I don't think its
fair to call it dogma.
Absolutely people should try new things out, but some have implied in
this thread that suggesting that the solution to (not knowing what to
do about) 'callback hell' is to add abstractions and meta-languages...
which seems hasty to me.
I'd be surprised if didn't agree on some level that it's worthwhile
encouraging incoming coders to first reach a fairly basic level of
familiarity before they explore that stuff.
Isaac Schlueter
Also, you should learn JavaScript. It's unavoidable, after all, so
you'll always end up dealing with it somehow. (For similar reasons,
you should learn C as well.)
A lot of people seem to be ok with using JavaScript without any meta
language in front of it. Some of them even claim it's better than the
alternatives, and they have some tricks and practices that make
callbacks decidedly un-hellish. So maybe try that out, too.
Mariusz Nowak
Nuno Job

Jann Horn
> In coffeescript it is only nesting heck.
And in coco, it is often not even nesting heck. :)
coffeescript:
foo (resultA) ->
bar (resultB) ->
baz()
coco:
(resultA) <- foo!
(resultB) <- bar!
baz!
Jann Horn
> On Tue, Apr 10, 2012 at 3:37 PM, Yi Tan <yi2...@gmail.com> wrote:
> > you really should spend a few hours learning coffee script if the js
> > callback syntax make you uncomfortable
>
> Unless coffee script fixes its "implicit local variable is global if
> the names match and just dont take care to not accidently name it
> equally" I will not touch it with a long stick.
<fanboy>Use coco, it's much better there! And it's cooler
anyway. :)</fanboy>
> Ask Javascript, about 'this'.
Uh... anything wrong about that?
Jann Horn
> > I'm working at the app level and I have 10,000 lines of coffeescript. I can't imagine coding all that in javascript.
>
> I have about 10 times that in javascript and it's quite easy, when things break I even get line numbers :)
Hey! There are patches for error reporting with token precision!
https://github.com/jashkenas/coffee-script/pull/2050
(well, apart from string interpolations, correct source positions are a
bit tricky for those)
Jorge
> (...) Methods with callbacks are not required to have async code in them, they just generally do. If you replace doIt with say a getUserFromCache method where 99% of the time you get cache hits and the function just returns the user this would be completely valid (...)
You can do that but I think the consensus is that it's not a good idea because it complicates reasoning about your code:
method(params, cb);
doSomethingElse();
Will doSomethingElse() run before or after cb() ?
--
Jorge.

Roly Fentanes
--
Job Board: http://jobs.nodejs.org/
Posting guidelines: https://github.com/joyent/node/wiki/Mailing-List-Posting-Guidelines
You received this message because you are subscribed to the Google
Groups "nodejs" group.
To post to this group, send email to nod...@googlegroups.com
To unsubscribe from this group, send email to
Roly Fentanes
Jorge
> When a question rises again and again it's a good sign of problem.
>
> To make clear I'm not in any way blame the node on it, it has tons of advantages and it's ok to have problem.
> Every advanced machinery have some sort of problems or limitations - it's ok.
>
> But what's not ok - is to have false delusion, to believe that a problem is a feature, or even worse - call it "The Rails/Node way".
>
> Because if You call the problem as it deserves - the problem - there's always room for progress and improvement. And maybe someday it will be completely fixed and become not a problem but another advantage.
>
> But when You ignore it or believe that it's a "feature" or "the right way" - the problem always will be there, it's a way to stagnation.
>
> Yes You can become tolerable to ugly code and buy wider screen to fit all those callbacks, but it doesn't matter.
> Perceptions doesn't change the objective reality, no matter how much people believe that false is true, false still and always will be the false.
>
> So, maybe it's worth to stop call this problem a "feature"?
+1
--
Jorge.
Jorge
> I think I'm done writing benchmarks. Even if I come up with a
> benchmark that shows streamline is faster I'm still not going to use
> it and I couldn't recommend anyone else use it either. The community
> as a whole doesn't back that kind of syntax so I couldn't submit a
> module to npm if I wrote it using streamline.
You could of course, yes. There's people writing their modules in CS and publishing/pushing just the JS output to npm. E.g. pdfkit:
<https://github.com/devongovett/pdfkit/commit/08c1b65067df7dba18b9e87fd822134eb61cca56>
> (...)
--
Jorge.
Jorge
>> On Thu, Apr 12, 2012 at 2:27 AM, Jorge <jo...@jorgechamorro.com> wrote:
>>> On Apr 11, 2012, at 2:16 AM, Joe Ferner wrote:
>>>
>>> (...) Methods with callbacks are not required to have async code in them, they just generally do. If you replace doIt with say a getUserFromCache method where 99% of the time you get cache hits and the function just returns the user this would be completely valid (...)
>>
>> You can do that but I think the consensus is that it's not a good idea because it complicates reasoning about your code:
>>
>> method(params, cb);
>> doSomethingElse();
>>
>> Will doSomethingElse() run before or after cb() ?
>
> If your function is asynchronous only sometimes, consider getting rid of that ambiguity by using process.nextTick() on your callback in the cases where calling it won't be async.
Exactly...
--
Jorge.
Oliver Leics
> Am I the only one that thinks that we talk about Callback Hell only because
> we are not used to used callback everywhere ?
No. *wink*
Bruno Jouhier
On Monday, April 9, 2012 2:42:14 AM UTC+2, Matthew Hazlett wrote:
I'm trying to write a simple app that preforms a db query when a user
connects to a tcp port.I can get the query working if I do everything as callbacks:
db.open(... fn() {
db.collection(.... fn() {
db.query(...... fn() {
});
});
});But as you can see this creates callback hell.
What I would like to do is have a class, but being as everything is
async it makes it incredibly difficult to ensure all your variables are
set.var client;
db.connect(connect, fn(){
client = connect;
});
client.close();Will cause an error because client hasn't been set yet. Another thing I
thought of doing was chaining it all together:db.connect(connect, fn(){
...
process.nextTick(fn(){ doNext(); });
});this gets very messy and hard to manage, how can I deal with callback hell?

{kind=link}
r...@tinyclouds.org
> I posted a follow-up on my blog:
> http://bjouhier.wordpress.com/2012/04/14/node-js-awesome-runtime-and-new-age-javascript-gospel/
Bruno, we are evangelizing callbacks because this is the only it can
possibly work in JavaScript. You can add a preprocessing step (which
is apparently what streamline is doing) - we will not do that. You can
add some crazy longjmp in your extension and juggle executions stacks
and try to forget how much memory they are or fight with stack over
flows - we will not do that. JavaScript has a run-to-completion model
which we do not seek to circumvent. Node is JavaScript - even more
than that - Node is V8 JavaScript. If V8 adds generators, we will have
them - if not then not. One of the key reasons Node is successful
(unlike all of other server-side JS systems) is because it actually
uses JavaScript and not some JavaScript-like language.
I'm glad you like Node. As you said, it is simple and fast. It got
that way by keeping things simple and fast. It will remain simple and
fast by continuing to strive for those goals.
This is a discussion to bring up with the EcmaScript committee.