Warning if not enough worker

Thomas Guettler
do you get a warning if you run out of worker processes?
I have this config:
WSGIDaemonProcess modwork_fm_p user=modwork_fm_p group=users threads=1 processes=8 maximum-requests=100
WSGIScriptAlias /modwork /home/modwork_fm_p/modwork_fm/apache/django_wsgi.py
<Location "/modwork/">
WSGIProcessGroup modwork_fm_p
WSGIApplicationGroup %{GLOBAL}
</Location>
Version: apache2-mod_wsgi-3.3-1.8.x86_64 apache2-prefork-2.2.15-3.7.x86_64
SuSE 11.3 Linux vis-work 2.6.34.8-0.2-default #1 SMP 2011-04-06 18:11:26 +0200 x86_64 x86_64 x86_64 GNU/Linux
I guess I was hit by running out of wsgi workers. Is there a way to debug the usage of workers (how many
are idle, ...)?
Thomas
--
Thomas Guettler, http://www.thomas-guettler.de/
E-Mail: guettli (*) thomas-guettler + de

Graham Dumpleton
> Hi,
>
> do you get a warning if you run out of worker processes?
No. To be able to detect such a condition across a lot of process is a
bit tricky. Apache itself uses a shared memory segment to track
utilisation of its own child process to generate errors about lack of
workers.
> I have this config:
> WSGIDaemonProcess modwork_fm_p user=modwork_fm_p group=users threads=1 processes=8 maximum-requests=100
Why are you setting maximum-requests=100? Setting it to such a low
value would generally be a bad idea if you have a fair bit of traffic.
How requests per minute do you get and how many are long running?
> WSGIScriptAlias /modwork /home/modwork_fm_p/modwork_fm/apache/django_wsgi.py
> <Location "/modwork/">
> WSGIProcessGroup modwork_fm_p
> WSGIApplicationGroup %{GLOBAL}
> </Location>
> Version: apache2-mod_wsgi-3.3-1.8.x86_64 apache2-prefork-2.2.15-3.7.x86_64
> SuSE 11.3 Linux vis-work 2.6.34.8-0.2-default #1 SMP 2011-04-06 18:11:26 +0200 x86_64 x86_64 x86_64 GNU/Linux
>
> I guess I was hit by running out of wsgi workers. Is there a way to debug the usage of workers (how many
> are idle, ...)?
Not at present. I have previously started to add instrumentation to
mod_wsgi to make such information available but pulled the code out as
there was nothing around to monitor it and make it useful. That
situation has changed now and I will be adding back instrumentation to
track utilisation of process/threads and anything else I can think of
so it can be sucked into tools like New Relic application performance
monitoring system which I so happen to be working on.
Even before doing that there is a round about way of doing it. What
you can do is add to Apache configuration if you have mod_headers
enabled:
RequestHeader add X-Queue-Start "%t"
This will result in the WSGI application seeing a WSGI environ variable:
HTTP_X_QUEUE_START
where value is of form:
t=121212121221
The number is time in number of microseconds. You can compare that to
current time and find out how much time was taken for request between
point that it was accepted by Apache and when WSGI application finally
got to handle it.
self._queue_start = 0.0
value = environ.get('HTTP_X_QUEUE_START', None)
if value and isinstance(value, basestring):
if value.startswith('t='):
try:
self._queue_start = int(value[2:])/1000000.0
except:
pass
The latest version of mod_wsgi in source code repository doesn't even
need to the mod_headers configuration added, as it will itself add a
mod_wsgi.queue_start variable to WSGI environment that can be picked
out as:
if self._queue_start == 0.0:
value = environ.get('mod_wsgi.queue_start', None)
if value and isinstance(value, basestring):
try:
self._queue_start = int(value)/1000000.0
except:
pass
I have both of those checks above in stuff am working on.
End result is the queue start variable as the time.
In the simplest case you could add a WSGI middleware that calculates
what the queue time is and log an error if it is longer than some
certain threshold.
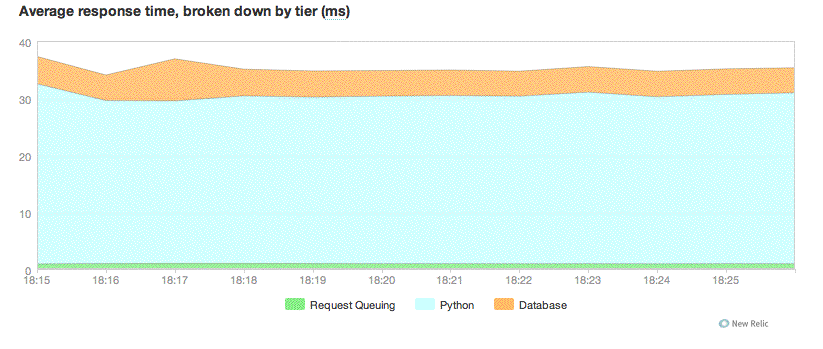
For something much more fancy, see image 056 attached to this email.
The traffic here is produced by:
siege -c 5 -i -f urls.txt -d 10
The request queuing time is represented by that green area in the
graph. It is tracking at around about 1ms and is flat. This is with
persistent processes, ie., no maximum-requests option.
Now, if you use maximum-requests to regular restart processes, or you
don't have enough processes/threads in daemon process to handle
request loaded, then you can expect requests to get accepted by Apache
and then queue up waiting to be proxied to available daemon mode
process to handle. That means that queue time will grow and vary
depending on how starved you are for free processes/threads.
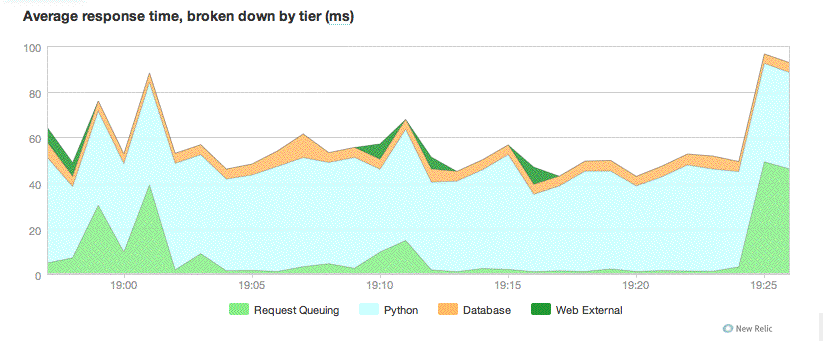
Now consider image 057 attached.
In this case I have increased the number of simulated clients and have
set maximum-requests to 20 to show what happens when you have too
frequent restarts for traffic volume. The siege parameters are:
siege -c 20 -i -f urls.txt -d 10
As you can see, a lot more lumpy and uneven response times compared to
before. You also start to see some external requests that didn't
appear before and that is because this application was doing some
external requests on process start to cache some data to be used in
serving up requests and that shows up sometimes when external network
is slow.
Some of the worst peaks would coincide with when multiple processes
were restarting around the same time.
In both tests I was using processes=4 threads=1.
So in summary, you can use the time between when Apache accepts
requests as set by X-Queue--Start using mod_headers, and when WSGI
application starts handling the request as a measure of whether you
have enough processes/threads. This is because that time will increase
and/or vary over time depending on whether you have enough
processes/threads configured to handle the request and whether you are
forcing process restarts on regular basis which has the side effect of
chewing up a process for a while as it restarts and loads your
application.
You will just need to work out what a reasonable acceptable maximum
queue time is for your setup. In this example a good value under good
conditions was 1ms, so if it was more than 5-10 milliseconds on a
regular basis would be concerned.
Graham
{kind=link}
{kind=link}