Announcing the High Replication Datastore for App Engine

Ikai Lan (Google)
Announcing the High Replication Datastore for App Engine
When App Engine launched over two years ago, we offered a Datastore that was designed for quick, strongly consistent reads. It was based on a Master/Slave replication topology, designed for fast writes while still allowing applications to see data immediately after it was written. For the past six months, as you are probably aware, we’ve been struggling with some reliability issues with the App Engine Datastore. Over the course of the past few months, we’ve made major strides in fixing these issues. However, our experience with these issues has made us rethink some of our design assumptions. As we promised you in some of our outage reports earlier this year, we wanted to give you a more fundamental solution to the problem.
Today I’m proud to announce the availability of a new Datastore configuration option, the High Replication Datastore. The High Replication Datastore provides the highest level of availability for your reads and writes, at the cost of increased latency for writes and changes in consistency guarantees in the API. The High Replication Datastore increases the number of data centers that maintain replicas of your data by using the Paxos algorithm to synchronize that data across datacenters in real time. One of the most significant benefits is that all functionality of your application will remain fully available during planned maintenance periods, as well as during most unplanned infrastructure issues. A more detailed comparison between these two options is available in our documentation.
From now on, when creating a new application, you will be able to select the Datastore configuration for your application. While the current Datastore configuration default remains Master/Slave, this may change in the future.
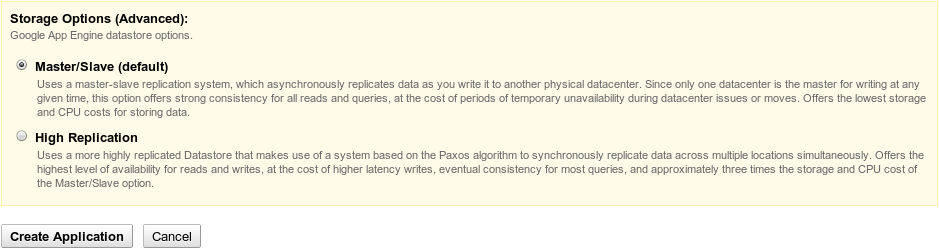
The datastore configuration option can not be changed once an application is created, and all existing applications today are using the Master/Slave configuration. To help existing apps migrate their data to an app using the High Replication Datastore, we are providing some migration tools to assist you. First, we have introduced an option in the Admin Console that allows an application toserve in read-only mode so that the data may be reliably copied between apps. Secondly, we are providing a migration tool with the Python SDK that allows you to copy from one app to another. Directions on how to use this tool for Python and Java apps is documented here.
Now, a word on pricing: Because the amount of data replication significantly increases with the High Replication datastore, the price of this datastore configuration is different. But because we believe that this new configuration offers a significantly improved experience for some applications, we wanted to make it available to you as soon as possible, even though we haven’t finalized the pricing details. Thus, we are releasing the High Replication Datastore with introductory pricing of 3x that of the Master/Slave Datastore until the end of July 2011. After July, we expect that pricing of this feature will change. We’ll let you know more about the pricing details as soon as they are available, and remember, you are always protected when pricing changes occur by our Terms of Service. Due to the higher cost, we thus recommend the High Replication Datastore primarily for those developers building critical applications on App Engine who want the highest possible level of availability for their application.
Thank you, everyone, for all the work you’ve put into building applications on App Engine for the past two years. We’re excited to have High Replication Datastore as the first of many exciting launches in the new year, and hope you’re excited about the other things we’ve got in store for App Engine in 2011.
Posted by Kevin Gibbs, The App Engine Team--
Developer Programs Engineer, Google App Engine
Ikai Lan (Google)
--
Developer Programs Engineer, Google App Engine

Raymond C.

James Broberg
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.

Nickolas Daskalou

Martin Ceperley

Matija

Fabrizio Accatino
can you elaborate a bit more? Will it be available a java sdk in the future?

Alexander Maslov

Ice13ill
applications that use (and will use) Master/Slave ? (hopefully in a
better way)
I was wondering if the increase of the latencies and errors in the
last few months were caused by the intense work of making the new
option available.

Jeff Schwartz
Well said, Alexander, and I wholeheartedly agree. The migration path should be automated from the back end when the developer selects the HRD from the admin application configuration console. I can see the lack of automation here as being a major impediment to the HRD's adaption for developers with existing applications.The process as it now stands exposes live data to possible erroneous migration processes that we create to migrate live data which could cause integrity issues if we don't get it 100% right the first time. And having to create a new application in order to migrate is a no starter IMO.
Come on, Google guys and gals, you are definitely talented enough to automate the migration which would eliminate any chance of damaging live data and eliminate the need to create a new application.
Sincerely,
Jeff
Speaking about current implementation. It's really weird that we do not have any way to migrate to High Replication Datastore without creating new application. It mite look not a big issue from Google's point of view, but that makes a lot of troubles to those developers, who use appspot.com domain to host applications. New application name means new domain name, etc.
--
You received this message because you are subscribed to the Google Groups "Google App Engine" group.
To post to this group, send email to google-a...@googlegroups.com.
To unsubscribe from this group, send email to google-appengi...@googlegroups.com.
For more options, visit this group at http://groups.google.com/group/google-appengine?hl=en.
--
Jeff Schwartz

stevep
architecture changes (original thread below).
If I'm reading this right, I can set up a separate High Reliability
application that will handle the put().
These puts are much lower volume than other client activities, but I
really need high reliability for them.
So architecture at a summary level is:
1) Client initiates the put to MS application.
2) MS application launches a task queue task to HR application.
3) MS replies back to client that HR task is launched.
4) Client pings HR application to confirm write (showing appropriate
dialog).
5) HR task queue puts record.
6) Client now gets HR confirmation to ping and shows confirmation
dialog.
If I've missed something please advise. The higher cost and higher cpu
cycles for HR (link below) are not issues as only a subset of
critical, lower volume puts get HR costing.
If I've not missed anything, then pleased to say in advanced (before
refactoring code) "Thanks Google".
Links:
Previous write architecture thread:
http://groups.google.com/group/google-appengine/browse_thread/thread/c0e44d36d54384a3
MS vs. HR performance testing (thanks kaekon):
http://groups.google.com/group/google-appengine/browse_thread/thread/5fc3b6a4366de62f
Ikai Lan (Google)
--
Developer Programs Engineer, Google App Engine

Robert Kluin
One more question: What about people serving from appspot.com?
Changing the appid means customers need reeducated, and could
generally be really inconvenient for anyone with an established app.
Any thought on that issue?
Robert

Stephen
On Thursday, January 6, 2011 11:09:24 PM UTC, Ikai Lan (Google) wrote:
- Typically, how long does it take for HR query data to become consistent (a ballpark figure)?100ms is the estimate. However - we have seen cases where this can be higher. If you were to use the eventual consistency read option in the master-slave configuration, we've seen that the average replication lag is about 3 minutes with an upper bound of 10 minutes.
What are the timings for the master/slave datastore with the EVENTUALLY_CONSISTENT option?
Ikai Lan (Google)
--
Developer Programs Engineer, Google App Engine
--
Robert Kluin
Stephen
On Friday, January 7, 2011 12:04:36 AM UTC, Ikai Lan (Google) wrote:
Stephen,The times I gave earlier were estimates of how much replication delay is introduced in each replication scheme. The "eventually consistent" flag is for reads only and dictates whether or not you care to read from the "Master" datastore - reads will go to a slave if there are issues reaching the master.
Ah, I misread your original answer as relating only to the high replication datastore - thanks.
This is kind of a surprising answer: replication between data centres (hi-rep) takes 100ms; replication within a data centre (M/S) takes 3000-10000ms. I suppose this is a trade-off: because the default for MS is strong consistency you can sacrifice replication lag for higher throughput...?
After I asked the question I came across the original blog announcement for the EVENTUALLY_CONSISTENT option, and it already contains the answer:
http://googleappengine.blogspot.com/2010/03/read-consistency-deadlines-more-control.html
"The secondary location may not have all of the changes made to the primary location at the time the data is read, but it should be very close. In the most common case, it will have all of the changes, and for a small percentage of requests, it may be a few hundred milliseconds to a few seconds behind."
Which is somewhat different than an avg of 3000ms and up to 10000ms. The figures from the blog post suggests to me that a query with the EVENTUALLY_CONSISTENT flag is basically not-quite-transactional, where as the latest figures of 3-10mins sounds more like stale results. Is this a policy change?
Regardless, it would be good to have these figures directly in the docs to help folks decide when they can use this feature and to decide between hi-rep and m/s.
Couple of other questions related to this:
- What percentage of reads block due to unavailability of a primary? That is, how often is setting the EVENTUALLY_CONSISTENT flag likely to make any difference at all?
- For reads which do block, what is the average wait time for successful waits and the failure rate for reads which timeout (without an explicitly set deadline)?
- And, how is unavailability of a primary determined? Is it a time out, and if so, how long? (I would use this figure to help determine a suitable deadline for queries which I want to fail over with eventual consistency.)
Thanks.

Stephen Johnson
"the average replication lag is about 3 minutes with an upper bound of 10 minutes." He says "minutes" not milliseconds.
so that's not 3000ms to 10000ms, that is 180000ms to 600000ms
if I'm reading your comments correctly. So is it minutes or milliseconds???
Stephen
On Friday, January 7, 2011 5:51:06 PM UTC, Stephen Johnson wrote:
In Ikai's post he says it takes
"the average replication lag is about 3 minutes with an upper bound of 10 minutes." He says "minutes" not milliseconds.
so that's not 3000ms to 10000ms, that is 180000ms to 600000ms
if I'm reading your comments correctly. So is it minutes or milliseconds???
Yes, I should have wrote '3-10 minutes'.
Ikai Lan (Google)
Developer Programs Engineer, Google App Engine

Waldemar Kornewald
Hey guys, some answers to your questions that we've compiled from various team members (mostly Alfred, presenter of "Next Gen Queries" and the fourth one from the left in this video http://www.youtube.com/watch?v=dg0TEIRQePg):- Typically, how long does it take for HR query data to become consistent (a ballpark figure)?100ms is the estimate. However - we have seen cases where this can be higher. If you were to use the eventual consistency read option in the master-slave configuration, we've seen that the average replication lag is about 3 minutes with an upper bound of 10 minutes.
Ikai Lan (Google)
--
Developer Programs Engineer, Google App Engine
--
Waldemar Kornewald
The replication lag affects actual entity data as well as indexes.
Stephen
OK. So according to 2 and 3, almost always (99+%) you will hit a
master server, so specifying eventual consistency makes no difference.
So for the MS datastore this flag affects robustness not performance,
right?
Couple more questions...
What about the HR datastore -- are queries across entity groups also
likely to be 99+% consistent, or is the figure different?
As cross-entity group HR queries are eventually consistent by default,
is there ever a reason to use the eventually consistent flag, such as
when querying a single entity group?
Is there any difference between queries, gets, puts or deletes related
to consistency, HR or MS datastore, or do the rules apply equally no
matter the datastore operation?
Thanks for taking the time to explain this so far -- much appreciated.
Ikai Lan (Google)
master server, so specifying eventual consistency makes no difference.
So for the MS datastore this flag affects robustness not performance,
right?
4. What about the HR datastore -- are queries across entity groups also
likely to be 99+% consistent, or is the figure different?
5. As cross-entity group HR queries are eventually consistent by default,
is there ever a reason to use the eventually consistent flag, such as
when querying a single entity group?
6. Is there any difference between queries, gets, puts or deletes related
to consistency, HR or MS datastore, or do the rules apply equally no
matter the datastore operation?
Developer Programs Engineer, Google App Engine